 知识图谱的抽取与构建
知识图谱的抽取与构建
知识图谱是一个交叉领域:

# 1. 重新理解知识工程与知识获取
符号主义的核心思想:人工智能源于数理逻辑、智能的本质是符号的操作和运算
Knowledge is the power in AI,知识工程是以知识为处理对象,研究知识系统的知识表示、处理和应用的方法和开发工具的学科。
上世纪的七八十年代,传统知识工程的确解决了很多问题,但大部分都在规则明确、边界清晰、应用封闭的场景取得了成功,而对于开放的问题则难以实现。传统知识工程往往是自上而下实现,由专家去表达知识、运用知识,这会存在很多问题:
- 人工构建的知识库规模和知识覆盖率很有限
- 专家对知识的认知也很难统一且具有高度的不确定性和不精确性
知识获取的瓶颈:成年人脑包含近1000亿神经元,每个神经元都可能有近1000的连接。模拟这样的人脑需要约100TB的参数,如果需要获取全体人类知识,这靠人工编码是无法完成的。
知识图谱工程:简化的知识工程:

从不同来源、不同结构的数据中进行知识提取,形成知识存入到知识图谱:
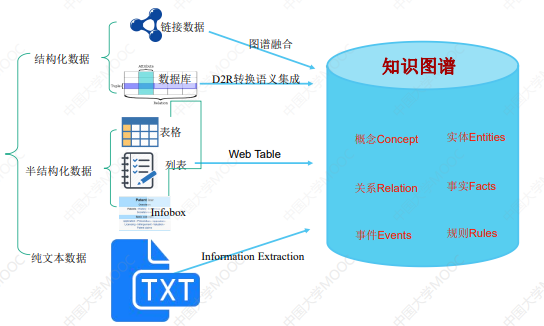
# 1)从关系数据库获取知识
定义一个本体,利用映射语言将关系模型映射到本体语言。
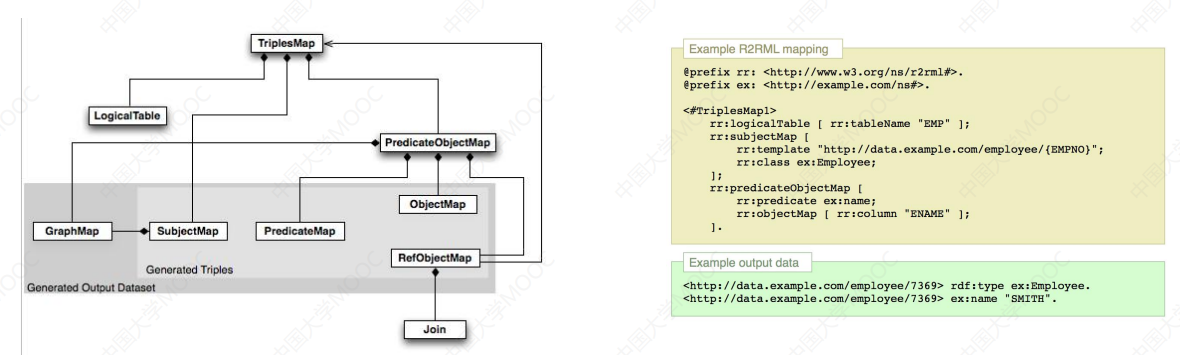
- 利用 W3C 的 r2rml (opens new window) 映射语言
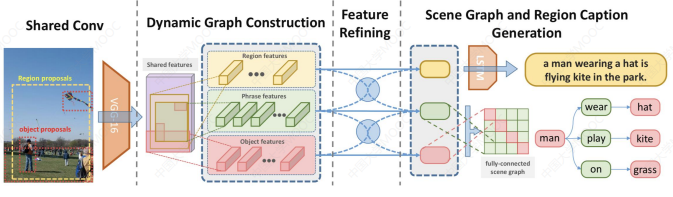
# 2)从视觉数据获取知识
在 CV 领域有一个 Scene Graph Construction,旨在识别对象的基础之上,进一步识别对象之间的关联关系并形成关系图。
# 3)从文本获取知识
- 命名实体识别:

- 术语抽取(概念抽取):从语料中发现多个单词组成的相关术语
- 关系抽取:从句子中抽取出实体关系:

- 事件抽取:事件是更为复杂的结构化数据,事件抽取可以看成一组三元组联合抽取的过程:

小结:知识图谱 ≠ 专家系统,知识图谱是新一代的知识工程,不再过于依赖人工,像百度、阿里等公司的知识图谱已经达到了百亿、千亿的规模。
# 2. 知识抽取——实体识别与分类
# 2.1 什么是实体识别
实体识别的主要目标:从文本中识别实体边界及其类型
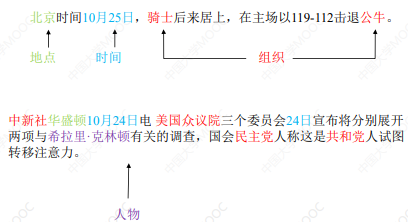
# 2.2 实体识别的常用方法
# 2.2.1 基于模板和规则
将文本与规则进行匹配来识别出命名实体,定义很多正则表达式来描述这些规则。
- 优点:准确,有些实体识别只能依靠规则抽取
- 缺点:
- 需要大量的语言学知识
- 需要谨慎处理规则之间的冲突问题
- 构建规则的过程费时费力、可移植性不好
# 2.2.2 基于序列标注的方法
利用机器学习算法,将实体识别任务视为一个序列标注问题,通过 classifier 给每一个词打一个标签,这需要设计各种类型的特征来训练这个 classifier,比如:
- 词本身的特征:边界特征(边界词概率)、词性、依存关系
- 前后缀特征:姓氏、地名(xx省、xx市)
- 字本身的特征:是否是数字、是否是字符
这样首先就要确定实体识别的序列标签体系:
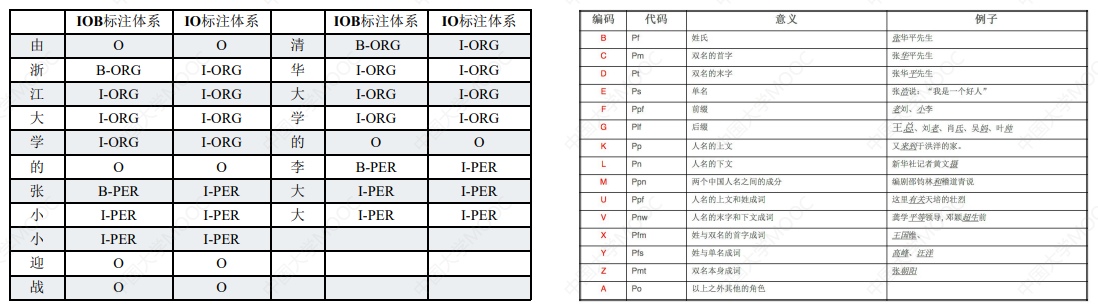
# 2.3 常见序列标注模型:HMM(隐马尔可夫模型)
HMM 是非常传统的实体识别模型,虽然这些模型都已逐渐被深度学习所替代,但了解这些基本知识对理解事物的本质是非常重要的。
HMM 是有向图模型,基于马尔可夫性,假设特征之间是独立的。图中的节点分为两类:隐变量代表需要预测的标签,观测变量是句子本身:
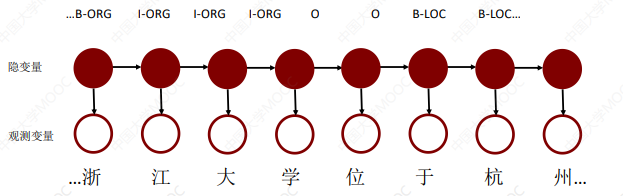
这里不再介绍 HMM
# 2.4 常见序列预测模型:CRF 条件随机场
// TODO
# 2.5 基于深度学习的实体识别方法
// TODO
小结
- 实体识别仍面临着标签分布不平衡,实体嵌套等问题,制约了现实应用
- 中文的实体识别面临一些特有的问题,例如:中文没有自然分词、用字变化多、简化表达现象严重等等
- 实体识别是语义理解和构建知识图谱的重要一环,也是进一步抽取三元组和关系分类的前提基础
# 3. 知识抽取——关系抽取与属性补全
// TODO