 知识图谱的表示
知识图谱的表示
# 1. 什么是知识表示
具有获取、表示和处理知识的能力是人类心智区别于其它物种心智的最本质特征,也是人脑智能的最本质特征。
以前可以根据知识来建立一个专家系统:
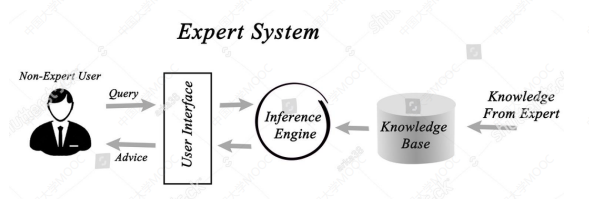
知识表示(Knowledge Representation,KR)就是用易于计算机处理的方式来描述人脑的知识的方法。KR不是数据格式、不等同于数据结构、也不是编程语言,对于人工智能而言,数据与知识的区别在于 KR 支持推理。
R. Davis, H. Shrobe, and P. Szolovits. What is a Knowledge Representation? AI Magazine, 14(1):17- 33, 1993. 这篇论文给出了关于知识表示的很好的解释。
知识的符号表示:
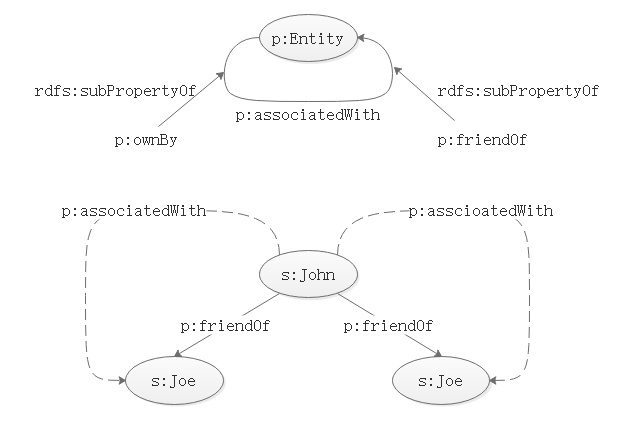
从符号表示到向量表示:

# 2. 人工智能历史发展长河中的知识表示

# 2.1 描述逻辑(Description Logic)
描述逻辑是一阶谓词逻辑的可判定子集,主要用于描述本体概念和属性,对于本体知识库的构建提供了便捷的表达形式,是与知识图谱最密切相关的知识表示方法之一。
核心表达要素:
- 概念 Concepts — 解释为一个领域的子集
- 例如:学生,已婚者:{x| Student(x) },{x| Married(x) }
- 关系 Relations — 解释为指该领域上的二元关系
- 例如:朋友,爱人:{ | friend(x,y) } ,{ | loves(x,y) }
- 个体 Individuals — 一个领域内的实例
- 例如:小明,小红:{ Ming, Hong }
描述逻辑的知识库
- TBox 包含内涵知识,描述概念的一般性质
- 定义: 引入概念以及关系的名称,例如:Mother, Person, has_child
- 包含:声明包含关系的公理,例如:Mother ⊑ ∃ has_child.Person
- ABox 包含外延知识 (又称断言知识),描述论域中的特定个体
- 概念断言—表示一个对象是否属于某个概念,例如:Mother(Helen)
- 关系断言—表示两个对象是否满足一定的关系,例如:has_child(Helen, Jack)
# 2.2 Horn Logic
Horn Logic 是一阶谓词逻辑的子集,主要特点是表达形式简单,复杂度低。 著名的 Prolog 语言就是基于 Horn 逻辑设计实现的
核心表达要素:
- 原子 Atoms
- p(t1, t2 ..., tn),p 是谓词,ti 是项(变量或者常量),例子: has_child(X, Y)
- 规则 Rules
- 由原子构建 : H :– B1, B2, ..., Bm.
- H 称为 Head ;
- B1, B2, ..., Bm 称为 Body ,例子: has_child (X, Y) :- has_son (X, Y)
- 由原子构建 : H :– B1, B2, ..., Bm.
- 事实 Facts
- 没有体部且变量的规则,例子: has_son (Helen, Jack) :-
一阶谓词逻辑优缺点比较
- 优点:接近自然语言,易于表示精确知识;有严格的形式定义和推理规则,易于精确实现
- 缺点:
- 无法表示不确定性知识,难以表示启发性知识及元知识
- 组合爆炸,经常出现事实、规则等的组合爆炸,导致效率低,推理复杂度通常较高
- 是以人的逻辑为主导的表示方式,可能并不适合及其,机器可能有自己的逻辑表示
# 2.3 产生式系统(Production Systems)
产生式系统是一种更广泛意义的规则系统,专家系统多数是基于产生式系统。其核心表达形式是 IF P THEN Q, CF = [0, 1],其中 P 是产生式的前提,Q 是一组结论或操作,CF(Certainty Factor)是确定性因子,也称置信度。
举例:IF 本微生物的染色斑是革兰氏阴性, 本微生物的形状呈杆状, 病人是中间宿主 THEN 该微生物是绿脓杆菌,置信度为 CF=0.6
产生式系统的优缺点
- 优点:
- 自然性:产生式系统采用人类常用的因果关系知识 表示形式,既直观、自然,又便于进行推理。
- 模块性:产生式规则形式相同,易于模块化管理。
- 有效性:能表示确定性知识、不确定性知识、启发性知识、过程性知识等。
- 清晰性:产生式有固定的格式,既便于规则设计, 又易于对规则库中的知识进行一致性、完整性检测。
- 缺点:
- 效率不高:产生式系统求解问题的过程是一个反复进行“匹配一冲突消解一执行”的过程。而规则库一般都比较大,匹配又十分费时,因此其工作效率不高。
- 在求解复杂问题时容易引起组合爆炸。
- 不能表达结构性知识:产生式系统对具有结构关系的知识无能为力,它不能把具有结构关系的事物间的区别与联系表示出来。
# 2.4 框架系统(Frame System)
基本思想:认为人们对现实世界中事物的认识都是以一种类似于框架的结构存储在记忆中。当面临一个新事物时,就从记忆中找出一个合适的框架,并根据实际情况对其细节加以修改、补充,从而形成对当前事物的认识。框架系统在很多 NLP 任务如 Dialogue 系统中都有广泛的应用。

框架系统的优缺点:
- 优点:对于知识的描述完整和全面;基于框架的知识库质量高;框架允许数值计算。
- 缺点:框架构建成本高,质量要求高;框架的表达形式不灵活,很难同其它形式的数据集相互关联使用。
# 2.5 语义网络 Semantic Network
WordNet 主要定义了名词、动词、形容词和副词之间的语义关系。例如名词之间的上下位关系(如:“猫科动物”是“猫”的上位词),动词之间的蕴 含关系(如:“打鼾”蕴含着“睡眠”)等。它是最著名的词典知识库,主要用于词义消歧,WordNet 3.0 已经包含超过15万个词和20万个语义关系。
语义网络优缺点:
- 优点:
- 结构性:语义网络是一种结构化的知识表示方法,它能把事物的属性以及事物间的各种语义联想显式地表示出来。
- 联想性:最初是作为人类联想记忆模型提出来的。
- 自然性:直观地把事物的属性及其语义联系表示出来,便于理解,自然语言与语义网络的转换比较容易实现,故语义网络表示法在自然语言理解系统中应用最为广泛。
- 缺点:
- 非严格性:语义网络没有公认的形式表示体系。一个给定的语义网络所表达的含义完全依赖于处理程序如何对它进行解释。
- 通过推理网络而实现的推理不能保证其正确性。支持全称量词和存在量词的语义网络在逻辑上是不充分的,不能保证不存在二义性。
- 处理上的复杂性:语义网络表示知识的手段多种多样,灵活性高,但由于表示形式不一致使得处理复杂性高,对知识的检索相对复杂。
这些方法各有优缺点,但都有一个共同的缺点是知识的获取过程主要依靠专家和人工,越复杂的知识表示框架知识获取过程越困难。
# 3. 知识图谱的符号表示方法
# 3.1 属性图(Property Graph)
属性图是图数据库 Neo4J 实现的图结构表示模型。其存储充分利用图的结构进行优化,因此查询计算方面效率较高,但缺乏工业标准规范的支持。它由于不关注更深层的语义表达,不支持符号逻辑推理。
属性图由顶点(Vertex)、边(Edge)、标签(Label)、关系类型还有属性(Property)组成的有向图。
- 顶点也称为节点(Node),边也称为关系(Relationship)
- 在属性图中,节点和关系是最重要的实体。节点上包含属性,属性可以以任何键值形式存在。
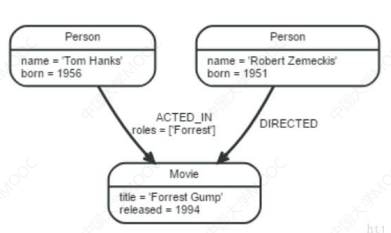
关系连接节点,每个关系都有拥有一个方向、一个标签、一个开始节点和结束节点。关系的方向的标签使得属性图具有语义化特征。
和节点一样,关系也可以有属性,即边属性,可以通过在关系上增加属性给图算法提供有关边的元信息,如创建时间等,此外还可以通过边属性为边增加权重和特性等其他额外语义。
# 3.2 RDF
可参见“语义网”部分。
属性图 vs. RDF vs. OWL
- 属性图是工业界最常见的图谱建模方法,属性图数据库充分利用图结构特点做了性能优化,实用度高,但不支持符号推理。
- RDF 是 W3C 推动的语义数据交换标准与规范,有更严格的语义逻辑基础,支持推理,并兼容更复杂的本体表示语言OWL。
- 在三元组无法满足语义表示需要时,OWL 作为一种完备的本体语言,提供了更多可供选用的语义表达构件
- 描述逻辑可以为知识图谱的表示与建模提供理论基础。描述逻辑之于知识图谱,好比关系代数之于关系数据库。
# 4. 知识图谱的向量表示方法
Embeddings:Distributed Vector Representation
- 自然语言:为句子中的每个词学一个向量表示
- 知识图谱:为每个实体和关系学习一个向量表示
- 图像视频:为视觉中的每个对象学习一个向量表示
# 4.1 词的向量表示
# 4.1.1 one-hot

# 4.1.2 Bag-of-words
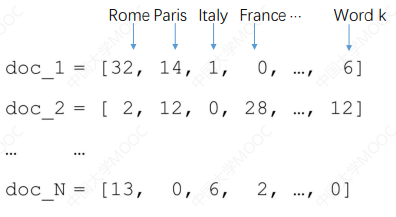
# 4.1.3 词的分布式向量表示
这部分可参考“自然语言处理”
词是符号化的,词的语义由它被使用的上下文确定。
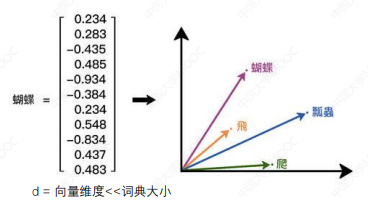
词向量的学习模型:CBow、Skip-gram ...
# 4.2 知识图谱嵌入
从词嵌入到知识图谱嵌入:
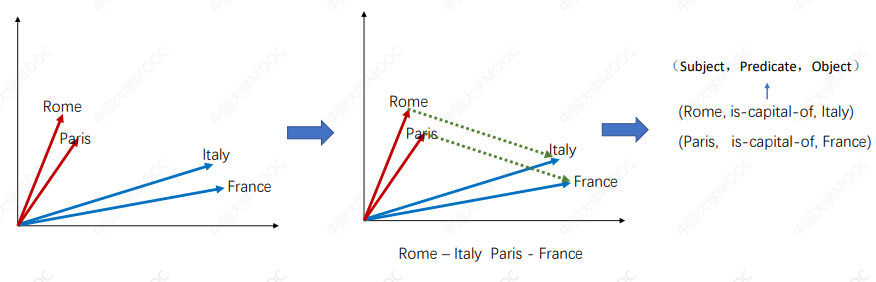
# 4.2.1 知识图谱嵌入模型:TransE

每个三元组
那么可以得到损失函数: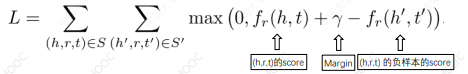
- 负样本(不真实存在的三元组)的构造:随机替换 h 或 t
陈华钧:这个优化目标就是让真实存在的三元组得分尽可能高,而让不存在的三元组的得分尽可能小。
我们可以使用简单的梯度下降的优化方法,先随机初始化所有实体和关系的向量表示,然后一轮一轮地优化向量中的参数,如果优化目标能够收敛,最后学习到的绝大部分的实体和关系的向量表示,就应该满足
这个假设。
# 4.2.2 知识图谱嵌入模型:DistMult

# 4.2.3 评估知识图谱嵌入模型 —— 推理问题
测试三元组 (h, r, t),尾实体预测( h, r, ? ) ,头实体预测 (?, r, t )。
比如:
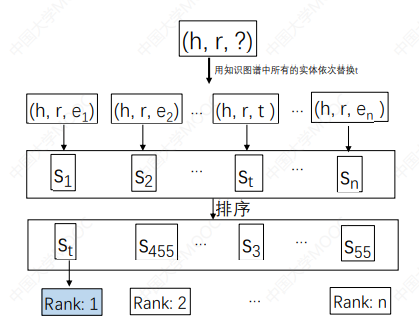
- 如果待预测的实体 t 得分最高,那么说明这个模型的学习效果非常好。
陈华钧:当深入考查一个知识图谱的结构特性时,会发现单纯借助于三元组的信号来学习是远远不够的,如果我们想要向量表示能像符号表示那样,精确地刻画知识结构中的逻辑和语义推理,就需要对学习的过程增加更多的约束,比如增加能够存储和捕获一对多、多对一关系的额外参数。但这又会增加学习的负担,同时对训练语料的要求更高。这就陷入两难,一方面知识逻辑复杂,一方面训练代价、语料不充分。所以知识图谱的表示学习比文本的表示学习更加复杂。
# 总结
- 知识表示是传统符号人工智能研究的核心,知识表示的方法在早期语义网的发展过程主要用来为知识图谱的概念建模提供理论基础
- 现实的知识图谱项目由于规模化构建的需要,常常降低表示的逻辑严格性,目前较为常见的知识图谱实践包括RDF图模型和属性图模型
- 尽管很多知识图谱并没有应用复杂的知识表示框架,Schema工程对于知识图 谱的构建仍然是基础性和必要性的工作,高质量的知识图谱构建通常从 Schema 开始
- 在知识图谱的深度利用中,如复杂语义的表达、规则引擎的构建、推理的实现,会对更有丰富表达能力的知识表示方法有更多的需求
- 图模型是更加接近于人脑认知和自然语言的数据模型,RDF 作为一种知识图谱表示框架的参考标准,向上对接 OWL 等更丰富的语义表示和推理能力,向下对接简化后的属性图数据库以及图计算引擎,仍然是最值得重视的知识图谱表示框架
- 知识(图谱)的表示学习是符号表示与神经网络相结合比较自然且有前景的方向。知识的向量表示有利于刻画那些隐含不明确的知识,同时基于神经网络和表示学习实现的推理一定程度上可以解决传统符号推理所面临的鲁棒性不高不容易扩展等众多问题