 认识分布式系统与系统模型
认识分布式系统与系统模型
# 1. 认识分布式系统
# 1.1 定义
分布式系统有许多种定义,这里采用如下:
分布式系统是一个其组件分布在不同的、联网的计算机上,组件之间通过传递消息进行通信和协调,共同完成一个任务的系统。
一个分布式系统有如下的特点:
- 多进程。分布式系统中有多个进程并发运行。
- 不共享操作系统。只通过网络来传递消息进行协作。
- 不共享时钟。所以很难只通过时间来定义两个事件的发生。
在分布式系统的语境下,节点、进程、计算机、服务器、组件、副本等术语,所表达的意思往往是一样的,就是指分布式系统中的一员,在不同的参考资料或主题下可能用不同的称谓,但都是一个意思——分布式系统中的一员。
# 1.2 为什么需要分布式系统
选用分布式系统的原因:
- 高性能
- 可扩展性
- 高可用性
- 必要性:很多任务的完成涉及到多个系统的合作,这天然就是分布式的。
# 1.3 分布式系统的示例
# 1.3.1 搜索引擎
Google 为了支撑其搜索和其他应用,在分布式基础设施上做出了巨大努力:
- 一个全球化、巨大的多数据中心
- 分布式文件系统:GFS
- 高性能、可扩展、用于存储大规模结构化数据的存储系统:Bigtable
- 分布式锁服务:Chubby
- 并行和分布式计算的编程模式:MapReduce
- 分布式数据库:Spanner
关于 Google 的架构,可以参考 Building Software Systems At Google and Lessons Learned 这一篇演讲。
# 1.3.2 加密货币
Bitcon 的奠基性论文:Bitcoin: A Peer-to-Peer Electronic Cash System (opens new window)
从分布式系统的角度来看,比特币的根本性贡献在于首次实现和验证了一种实用的、去中心化和拜占庭容错的共识算法,从此打开了通往区块链新时代的大门。区块链技术也让 IT 行业日益重视隐私和数据保护方面的优点。
# 1.4 分布式系统的挑战
可以参考 DDIA 分布式系统的挑战
如果我们根据单机系统上的经验来做出假设进行分布式系统的设计、构建和验证时,就会碰到不知所措的问题。
Sun Microsystems 公司总结出了分布式计算的谬误:
- 网络是可靠的
- 延迟为零
- 带宽是无限的
- 网络是安全的
- 拓扑结构是不会改变的
- 单一管理员
- 传输陈本为零
- 网络是同构的
此外还有部分失效问题和时钟问题。我们重点讨论其中几个:
# 1.4.1 网络延迟问题
多个节点通过网络进行通信,但网络并不能保证数据什么时候到达,以及是否一定到达,有时网络甚至是不安全的。这些导致的反直觉问题在单机系统中并不会出现。
也许 TCP 这样封装好的协议让开发者很容易相信网络是可靠的,但这只是一种错觉,我们应该明白,网络是建立在硬件上的,这些硬件也会在某些时候出现故障,比如电缆突然被鲨鱼咬断了。
# 1.4.2 部分失效问题
单机程序要么正常工作,要么彻底出错。
但在分布式系统中,可能出现一部分节点正常工作,而另一部分节点停止运行,或者由于网络中断导致某些部分以不可预知的方式宕机,这被称为部分失效问题。
部分失效问题让分布式系统难以捉摸和调试,尤其是当你的操作需要原子性的时候。
# 1.4.3 时钟问题
在单机系统中,所有进程都有一个共同的时间。但在分布式系统中,每个机器都有自己的时钟,他们几乎不可能精确同步,这使得很难确定涉及到多台机器时事件发生的顺序。
# 2. 每个程序员都应该知道的数字
Jeff Dean 在分布式系统分享 (opens new window)中列出了“每个程序员都应该知道的数字”,对计算机的各类操作的耗时做了大致估计:

尽管这些数字有些过时,但重点在于它们之间的数量级和比例,而不是具体的大小。一个 2020 年的版本:
| 操作 | 延迟 |
|---|---|
| 执行一个指令 | 1 ns |
| L1 缓存查询 | 0.5 ns |
| 分支预测错误(Branch mispredict) | 3 ns |
| L2 缓存查询 | 4 ns |
| 互斥锁/解锁 | 17 ns |
| 在 1Gbps 的网络上发送 2KB | 44 ns |
| 主存访问 | 100 ns |
| Zippy 压缩 1KB | 2,000 ns |
| 从内存顺序读取 1 MB | 3,000 ns |
| SSD 随机读 | 16,000 ns |
| 从 SSD 顺序读取 1 MB | 49,000 ns |
| 同一个数据中心往返 | 500,000 ns |
| 从磁盘顺序读取 1 MB | 825,000 ns |
| 磁盘寻址 | 2,000,000 ns (2 ms) |
| 从美国发送到欧洲的数据包 | 150,000,000 ns(150 ms) |
很多算法和系统设计案例的背后,都是让操作尽量处于这个表的前几行,而避免做后几行的操作。
# 3. 两将军问题和拜占庭将军问题
这是分布式系统中的两个经典的思想实验,便于我们抽象出分布式系统的模型。
# 3.1 两将军问题
两将军问题(Two Generals' Problem)指两支由不同的将军领导的军队,正准备进攻一座坚固的城市。两个将军交流的唯一方法是派遣信使穿越山谷。然而,山谷被城市的守卫者占领,并且途经该山谷传递信息的信使有可能会被俘虏:
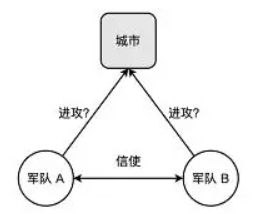
两个军队必须同时进攻才能成功,否则战败,因此必须通过信息沟通并约定时间,并确保另一位将军知道自己已同意了进攻计划。
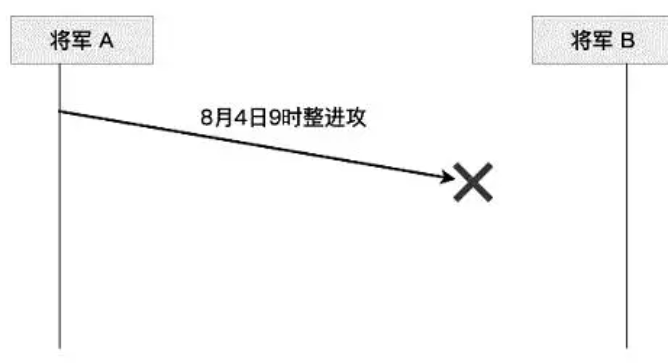
首先,将军A向将军B传递消息“8月4日9时整进攻”。然而,派遣信使后,将军A不知道信使是否成功穿过敌方领土,如下图所示。由于担心自己成为唯一的进攻军队,将军A可能会犹豫是否按计划进攻:
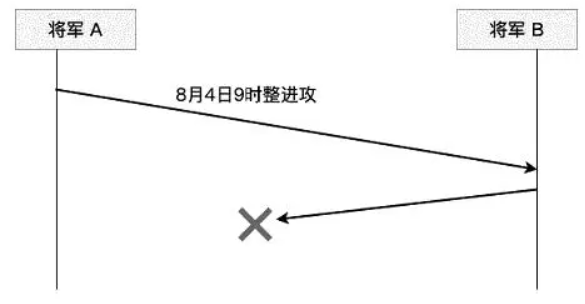
为了消除不确定性,将军B可以向将军A返回确认消息:“我收到了您的消息,并将在8月4日9时整进攻”。但如下图所示,传递确认消息的信使同样可能会被敌方俘虏。由于担心将军A在没有收到确认消息的情况下退缩,将军B又会犹豫是否按计划进攻:
再次发送确认消息看上去可以解决问题—将军A再让新信使发送确认消息:“我已收到您对8月4日9时攻击计划的确认”。但是,将军A的新信使也可能被俘虏。显然,无论进行多少轮确认,都无法使两位将军确保对方已同意进攻计划。两位将军总是会怀疑他们派遣的最后一位使者是否顺利穿过敌方领土。
两将军问题虽然已被证明无解,但计算机科学家们仍然找到了工程上的解决方案,我们熟悉的传输控制协议(TCP)的“三次握手”就是两将军问题的一个工程解。
这个思想实验还表明,在一个分布式系统中,一个节点没有办法确认另一个节点的状态,一个节点想要知道某个节点的状态的唯一方法是通过发送信息进行交流来尽量得知。
# 3.2 拜占庭将军问题
该问题将两将军问题拓展为多个将军进行协商,同时将军中可能出现叛徒,他们会试图故意误导其他将军来破坏整个军事行动。拜占庭将军问题就是要确保所有忠实的将领在同一个计划上达成共识。
将上面的故事映射到分布式系统中,将军便是计算机,新式便是通信系统,而拜占庭故障模型描述的就是系统中某些成员不仅可能发生故障,甚至可能会故意篡改和破坏系统的一种系统模型。
# 4. 系统模型
我们的系统就是根据不同种类的故障抽象出来的,这里按网络、节点故障和时间三中类型划分系统模型:
# 4.1 网络链路模型
网络是不可靠的,在分布式系统中,网络出错常导致网络分区问题:指由于网络设备故障,网络被分裂成了多个独立的组,也就是节点仍然正常工作,但他们之间的通信已经中断。
大多数分布式算法都假设网络是点对点的单播通信,因此我们从单播通信进行介绍。假设有一个发送者和接收者,两者通过一个双向的链路通信。这时网络链路分为以下几种模型:可靠链路、公平损失链路和任意链路。
# 1)可靠链路
可靠链路(Reliable Link)既不会丢失消息,也不会凭空捏造消息,但可能对消息重新排序。
TCP 就是一种可靠链路,但 TCP 还保证了消息排序。
# 2)公平损失链路
公平损失链路(Fair-Loss Link)的消息可能会丢失、重复或者重新排序,但消息最终总会到达。
特点:
- 公平损失:发送方不断重复发送消息,则消息总会到达;
- 有限重复:消息只会重复发送有限的次数;
- 不会无中生有:链路不会自己生成消息
这种假设意味着网络中断只会持续有限的时间。
# 3)任意链路
任意链路(Arbitrary Link)允许任意的网络链路执行任何操作,可能有恶意软件修改网络数据包和流量。
三种链路模型可以互相转换:
- 对于公平损失链路,通过让 sender 重传,receiver 过滤重复消息,可以变成可靠链路;
- 对于任意链路,施加加密技术(如 HTTPS),就变成了公平损失链路。
# 4.2 节点故障类型
节点在回复消息时可能出现故障,从而导致该消息永久丢失,这就是节点故障问题。
节点故障类型有多种,这里分为三类:崩溃-停止、崩溃-恢复、拜占庭故障。
- 崩溃-停止(fail-stop or crash-stop):一个节点停止工作后永远不能恢复。比如机器永久失灵。
- 崩溃-恢复(fail-recover or crash-recover):允许节点重新启动并继续执行剩余的步骤,一般通过持久化存储必要的状态信息来容忍这种故障类型。
- 拜占庭故障:故障的节点可能不只会宕机,还可能以任意方式偏离算法,甚至破坏系统。
大多数算法都是基于崩溃模型来解决问题的,但对于性命攸关的航天系统或去中心化的加密货币都需要实现拜占庭容错。
# 4.3 按时间划分的系统模型
- 同步系统模型:一个消息的响应时间在一个有限且已知的时间范围内。
- 异步系统模型:一个消息的响应时间是无限的,无法知道一条消息什么时候会到达。
这里所说的“同步/异步”与编程中的“同步/异步”不太一样,这里特指分布式系统中的定义。
异步系统更接近现实,因为我们无法确保整个系统的所有组件都正常运行,因此两地之间发送消息便得不到有限时间内响应的保证。
但不幸的是,分布式系统中一些问题无法在异步系统中解决,比如 FLP 不可能定理,该定理证明了在异步系统中我们难以找到一个满足要求的共识算法。因此引出了第三种模型:部分同步系统:假设系统大部分时间都是同步的,但偶尔会因为故障转变为异步系统。这个模型更加贴近现实需要。
# 5. 消息传递语义
分布式系统中各节点通过互相传递消息来协作,但由于网络和节点的不可靠,可能会出现消息重传的现象,这种重复传递消息的行为可能会产生灾难性的副作用:如果重传的消息正好是用户扣款信息,处理不当的话可能引起两次扣款。
上述问题最常见的解决办法是使用幂等操作:指多次操作产生相同的结果,且不会有任何影响,即
按照消息传递和处理次数,有如下几种可能的消息传递语义:
- 最多一次(At Most Once):消息最多传递一次,可能丢失,但不会重复。
- 至少一次(At Least Once):系统保证每条消息至少会发送一次,消息不会丢失,但在有故障的情况下可能导致消息重复发送。
- 精确一次(Exactly Once):消息只被精确传递一次,这种语义是人们实际想要的,有且仅有一次,消息不丢失不重复。
精确传递一次难以实现,因为重传消息才能建立可靠链路,于是我们尽可能做到精确处理一次消息,然后通过忽略后续重复的消息来达到看起来是精确一次的效果。
对于一些流处理框架或消息队列来说,实现精确一次的语义是非常重要的。