 知识图谱问答
知识图谱问答
# 1. 智能问答概述
# 1.1 智能问答的发展历史
# 1.1.1 特定领域的问答系统
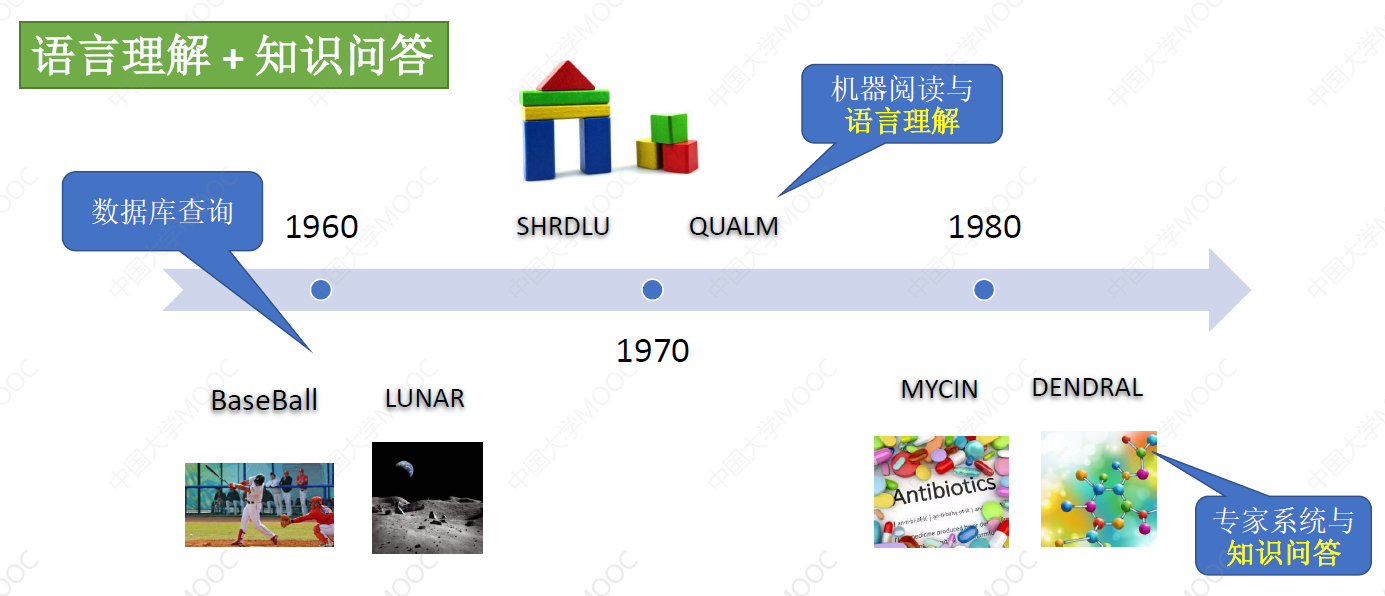
- BaseBall 和 LUNAR 大量依靠人类撰写的规则模板,实现从自然语言到结构化查询语句的转化
- MYCIN 系统通过一个由 600 多条的规则组成的知识库和一个推理引擎,为用户提供抗生素的问答服务,这类系统要求像人一样具有丰富的知识,并通过知识和推理来回答人类的问题
可以看出,解决人机交互问答问题,有两个重要的手段:自然语言理解和知识表示与推理。
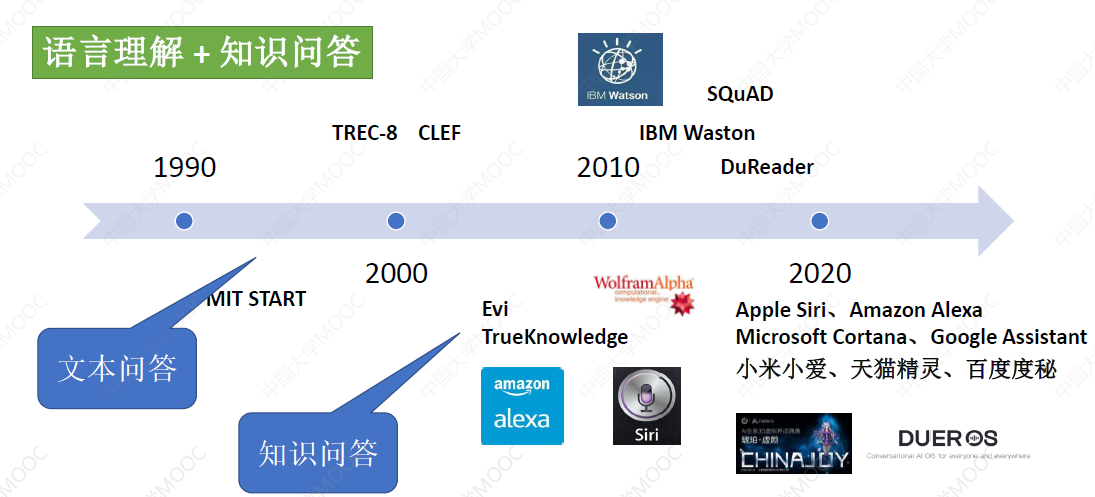
# 1.1.2 开放领域的问答系统
# 1.2 智能问答分类
# 1.2.1 按答案来源分
- 知识图谱问答:以结构化的知识库作为问答的语料
- 表格问答:主要针对表格和列表数据进行问答(比如给定一个 Excel)
- 文本问答:要求机器能够从一段文字中精确识别一个问题的答案(类似于英语阅读理解)
- 社区问答:以问答对的形式(如知乎)
- 视觉问答:要求针对图片或视频中的内容进行问答
# 1.2.2 按问句类型分

这里的主题是知识图谱问答,相比于文本,结构化的 KG 能够提供更为精准的答案,并且能依赖 KG 中的实体关联关系,非常方便地扩展相关的答案。
# 1.3 各种类型的 QA
# 1.3.1 KBQA
一种实现 KBQA 的方式是,将一个自然语句解析成一个结构化的查询语句,再对知识图谱进行查询匹配,或者直接依据问句的特征,对知识图谱中的候选实体进行打分排序。具体的技术在后面介绍。
# 1.3.2 Textual QA
文本问答,要求给定一段自然语言文本,并从文本中准确地定义答案。例如 Stanford SQuAD 就要求从文本中提取答案:

这也许是 QA 的理想形式,具体实现方式上,这里分成了两派:
- 一派认为通过语言预训练的模型,可以学习出文本中的知识并用于智能问答
- 另外一派则认为必须要构建结构化的知识图谱,才能支持智能问答的实现
其实这两者并非替代关系,而是都要用到的技术手段。但本章将不再介绍 Textual QA 的相关技术。
# 1.3.3 Table QA
表格也是一种常见的结构化数据的组织形式,很多数据无需组织为 graph,相比之下 table 的形式更加简洁明了,同时 table 的处理也相比 graph 更加简单,处理效率也更高。因此,Table QA 也是很多问答系统的重要模块。
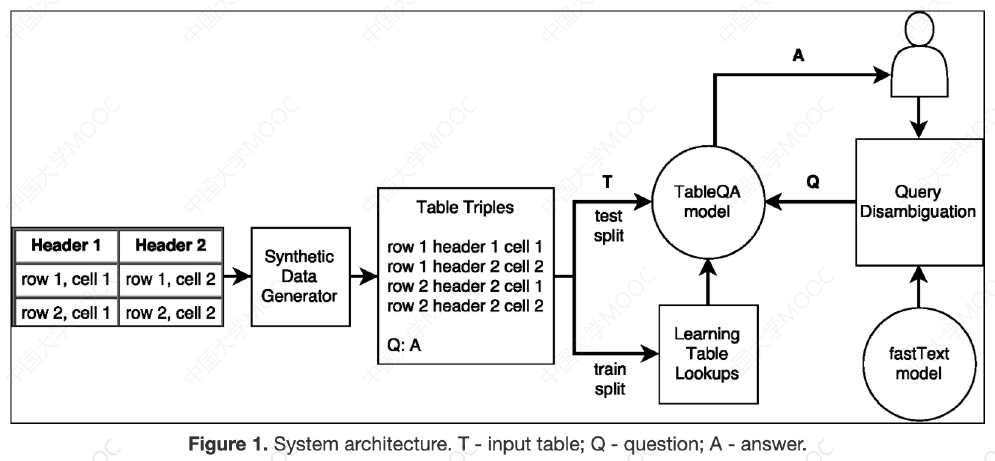
该任务又细分为表格检索和答案生成两步,前者从表格集合中找出与输入问题最相关的表格,后者负责基于检索回来的表格生成答案。
# 1.3.4 Community QA
社区问答主要以“问答对”的形式组织数据,通常这些问答对都是从问答社区(如知乎)获取的问答对的数据集合。
由于这些问答对数据实际上是由人工众包获取的专家经验型知识,这类知识通常比较难于直接从文本中自动抽取获得,因此对于构建智能问答系统有重要的价值。
基于问答对的社区问答实现,在形式上也比较简洁,我们可以直接训练一个模型来计算问句和答案之间的语义相似性就可以了。当然,问答对的形式也可以和知识图谱问答模型、文本问答模型混合起来使用以提升问答的效果。
# 1.3.5 Visual QA
它也是一种 QA 的终极形式,要求机器能够正确理解图片或视频中的语义内容,才能完成复杂的问句问答。

有时,为了实现 Visual QA,也需要引入外部的知识作为辅助。
# 1.3.6 文本问答 + 知识图谱问答
Question Answering on Knowledge Bases and Text using Universal Schema and Memory Networks. ACL2017
KG 问答也经常用于提升文本问答和 Visual QA 的效果。比如下面的工作,将结构化的知识与文本中的实体与关系描述先进行对齐,然后将 KG 与文本一同作为 model 训练的输入。文本的好处是答案的覆盖面广,语料容易获得;KG 的好处是能够提供精准的答案,但通常对答案的覆盖面不够。通过两者的结合可以提升问答的效果。
# 1.3.7 Visual QA + KBQA
可以先对 image 中的实体做识别,然后与外部的 KG 进行链接,这样就可以利用外部 KG 的实体关系来进一步拓展 Visual QA 的效果。
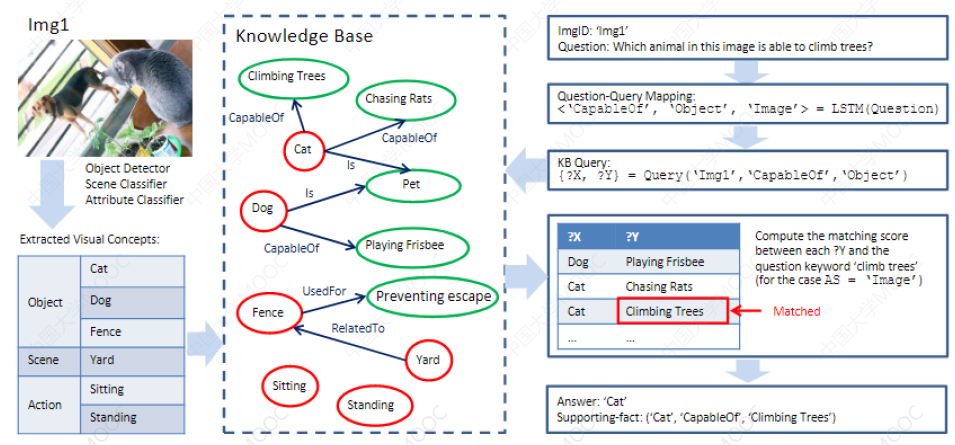
后续将主要介绍与知识图谱问答有关的技术。
# 1.4 实现 KBQA 的主要技术方法
KBQA 的设定是给定自然语言问句,要求从知识图谱中寻找答案。
- 一种思路是将输入的自然语言问句解析成结构化的逻辑查询语句,然后直接对 KG 进行查询并获取答案。这个解析的过程有两种实现思路:1. 人工定义问句模板 2. 训练一个语义解析器
- 一种思路是采用类似信息检索的方法,我们把查询问答问题转换为对 KG 中候选答案实体进行匹配和排序的问题。随着 DL 的崛起,基于 Neural Network 的方法也被广泛用来实现知识图谱的问答。
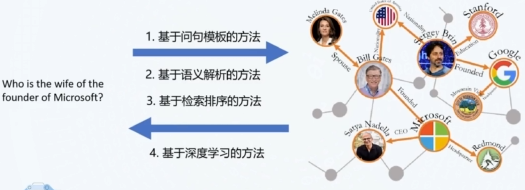
可以看到,NN 的方法主要用来改进语义解析技术和重构检索排序,后面将分别对这些技术进行介绍。
# 1.5 问句解析 VS 检索排序
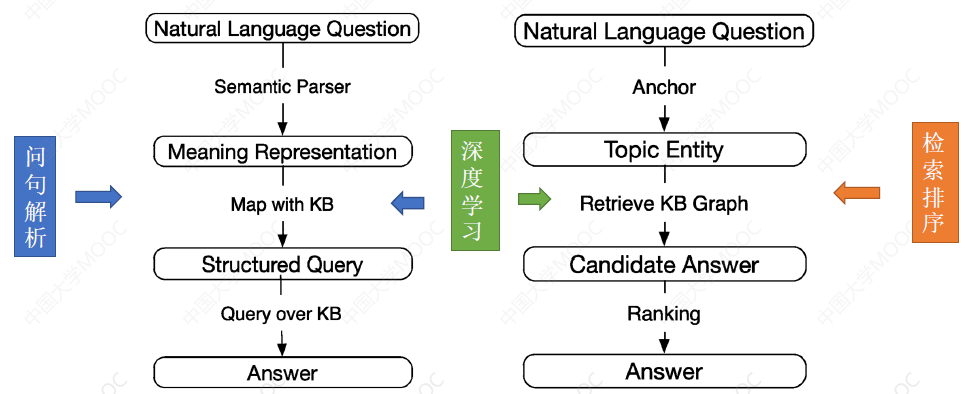
语义解析方法的核心是实现一个 Semantic Parser,它将 Question 转化为一个在 KG 上的 Structured Query,但问题是实现一个通用的 Semantic Parser 并不容易,这往往需要依赖人工模板实现解析,因而可复用性不太好。
基于检索排序的方法通常首先对问句进行实体和关系的识别,然后锁定问题的主题实体(Topic Entity),进而在 KG 中以这个 topic entity 出发,寻找候选实体,最后通过一个排序机制来对候选实体进行排序。这种方法不依赖于人工模板,可复用性好,但这由于对问题的语义理解不够深入,通常不容易获得精准的答案。
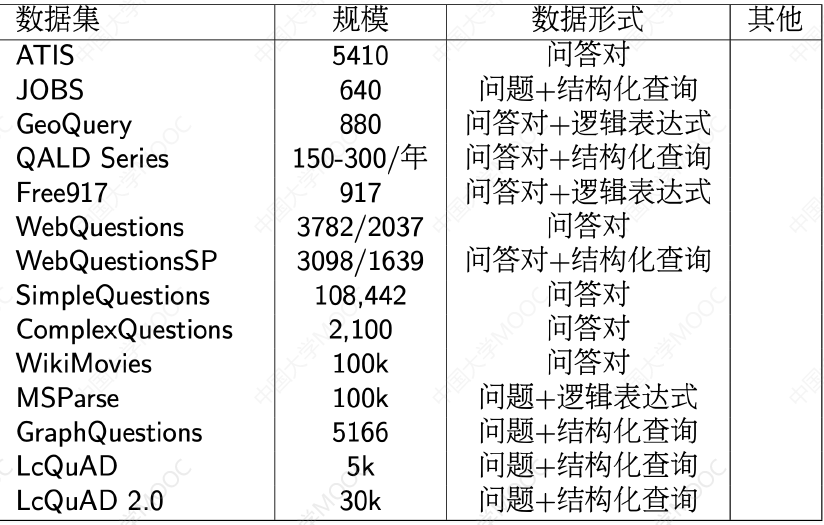
# 1.6 知识图谱问答测评数据集
# 1.6.1 QALD
QALD:Question Answering over Linked Data
ESWC 上开展,旨在建立一个统一的知识图谱测评基准。每年 100 个问题左右,从 2011 年开始。数据来源包括 Dbpedia 、 YAGO 和 MusicBrainz。主要任务有三类:
- 多语种问答,基于 Dbpedia
- 基于链接数据(interlinked data)的跨数据集问答
- 融合文本数据的 Hybrid QA,基于 RDF and free text data

# 1.6.2 WebQuestions
WebQuestions 也是用于对 KG 问答进行基准测试的常用数据集,面向的是通用领域的问答。该数据集包含 6642 个问答对,问题主要围绕单个命名实体,每个问题都有为一个的 ID,基于 Freebase 的答案进行问题标注。

https://github.com/brmson/dataset-factoid-webquestions
# 1.6.3 SimpleQuestions
SimpleQuestions 是一个对简单知识图谱问答进行基准测试的常用数据集。数据集总共包含 108,442 个自然问题,每个问题都与一个对应的事实配对,对应了知识图谱中的一个三元组,训练集、验证集、测试集的比例是 7:1:2 。

https://research.fb.com/downloads/babi/
# 1.6.4 MetaQA
MetaQA 是一个针对垂直电影领域的知识图谱问答进行基准测试的常用数据集。其知识图谱包含电影领域中的演员、导演、编剧、电影及其类型等内容,总计包含超过 40 万个问题,问题的形式包含文本形式和语音形式。典型特点是关注多跳问答, 1 跳、 2 跳、 3 跳的样本大致是 1:1:1。
https://github.com/yuyuz/MetaQA
# 1.6.5 More
小结
- 目前常见的智能问答技术包括文本问答、知识图谱问答、社区问答(问答对)、表格问答、视觉问答等多种形式,其中,知识图谱问答是起到各类问答核心桥梁作用的问答形式,通常会与文本、视觉、社区等问答形式混合搭配起来使用。
- 实现人与机器之间更为自然的交互方式也是人工智能追求的终极目标之一,这涉及怎样让机器理解人的自然语言,以及怎样让机器获取和表示知识两个方面的问题。这两个问题的解决仍然面临很多挑战需要解决。
# 2. 基于问句模板的 KBQA
基于问句模板的方法虽然很笨,但却能够提供非常精准的语义解析,在实际工业落地中仍然被广泛应用。
# 2.1 KBQA 的主要挑战
两个核心挑战:
- 怎样表示问句,并正确理解问句中的语义
- 怎样将问句的语义与 KG 中的 entity 和 relation 进行匹配

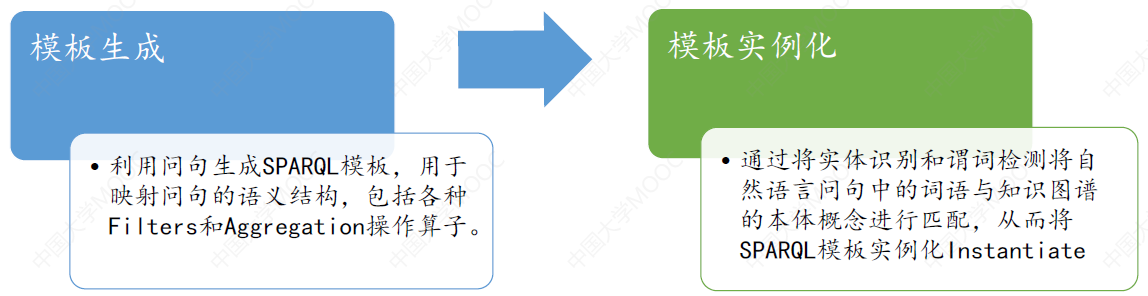
# 2.2 模板方法的一般流程

- 定义模板
- 通过问句与 KB 的映射完成模板的实例化
- 对实例化的所有可能查询进行排序
- 选择最好的查询,并对 KG 进行查询操作获得结果
# 2.3 问句模板实现举例:TBSL
TBSL (Unger et al., 2012)
TBSL 是通过模板的方法,将自然语言问句转化为一个 SPARQL 查询,进而从 SPARQL 从 KG 中寻找答案。
# 2.3.1 TBSL 基本思路
- 词的理解:通常是 KG-Dependent
- Abranham Lincoln -> res:AbranhamLincoln
- died in -> dbo:deathPlace
- 问句的语义结构:通常是 KG-Independent
- who ->
SELECT ?x WHERE {...} - the most N ->
ORDER BY DESC(COUNT(?N)) LIMIT 1 - more than i N ->
HAVING COUNT(?N) > i
- who ->
# 2.3.2 TBSL 核心步骤
目标:将问句的语义结构分析和词语向 KG 的映射结合起来
一个示例:问句“Who produced the most films?”可以进行如下转换:

接下来,我们一步步介绍具体的实现过程。
# Step 1:Template Generation
结合KG 的结构和问句的句式,进行模板定义,通常没有统一的标准或格式。
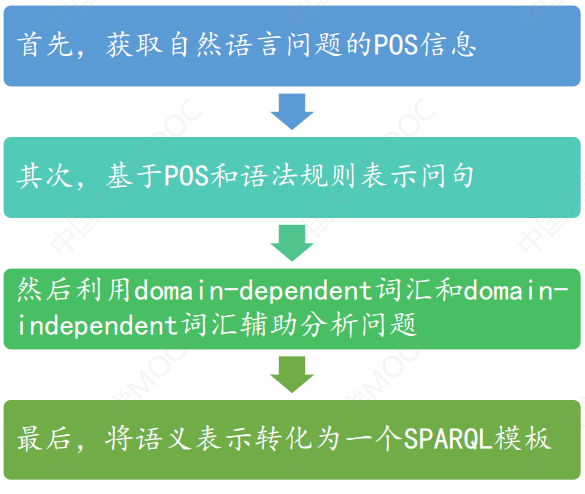
这里举个例子,如下图,对一个句子,通过分析它的词,可以将其对应到一个 SPARQL 模板上:

可以看出,一个问题可能有多个查询模板。
# Step 2:Template Instantiation
这一步就是将 SPARQL 模板实例化,也就是将自然语言问句与 KG 中的本体概念相映射。
- 对于 Resources 和 Classes:
- 可用 WordNet 获取知识图谱中对应标签的同义词,然后计算字符串相似度获得映射关系
- 最高排位的概念将作为填充查询槽位的候选
- 对于 Property
- 还需要与模式库中的自然语言表示进行比较,有可能会需要将单个 Property 分解为多个谓词 的组合描述
如下面这个例子,这里 films 和 produced 可以被映射到 KG 上多个可能的类或关系上:

从这里也可以看出,一个查询模板,也可能生成多个查询实例。再加上前面说的一个问题可能有多个查询模板,因此一个问题最终可能产生很多个查询实例。
# Step 3:查询排序与答案选择
模板实例化会产生很多可以直接执行的查询语句,哪个查询获得的答案最好呢?因此还需要一些方法对查询语句句进行排序以获取最优答案。
一般的做法如下:
- 每个匹配的 Resource(Class, Property, Entity)根据 String Similarity 和 Prominence 获得一个打分
- 一个查询模板实例的分值根据替换相应 Slots 的多个资源的平均打分。
- 利用类型检查排除掉不正确的匹配:例如需要检查 property 的 domain/range 是否与 <class> 一致
- 对于全部的查询集合,仅返回打分最高的。
如下图的例子,我们依据模板与 KG 映射的匹配程度来对实例化的模板进行打分,得分最高的被认为是最正确的问句解析结构,将被用来在 KG 中查询获取最终的答案。

# 2.4 模板是否可以自动生成?
模板的定义耗费人力,且需要不断根据新的问句而增加新的模板,那么模板是否可以通过更加自动化的方式来自动生成呢?这里介绍一个可以自动生成模板的工作:QUINT。
Automated Template Generation for Question Answering over Knowledge Graphs (Abujabal et al, WWW 2017)
QUINT 能够根据问句-答案对, 使用依存树自动学习模板:
- 模板的学习使用远程监督的方法,支持自动识别问题答案的类型。
- 使用整数线性规划(ILP)学习问句-答案之间的对齐。
利用自然语言的组成特点,实现从简单问题中学到的模板来解决复杂问题:
- 将一个复杂问题分解为子句,并用模板回答每一个子句。
- 再结合每一个子句的答案来获得最终复杂问题的答案。
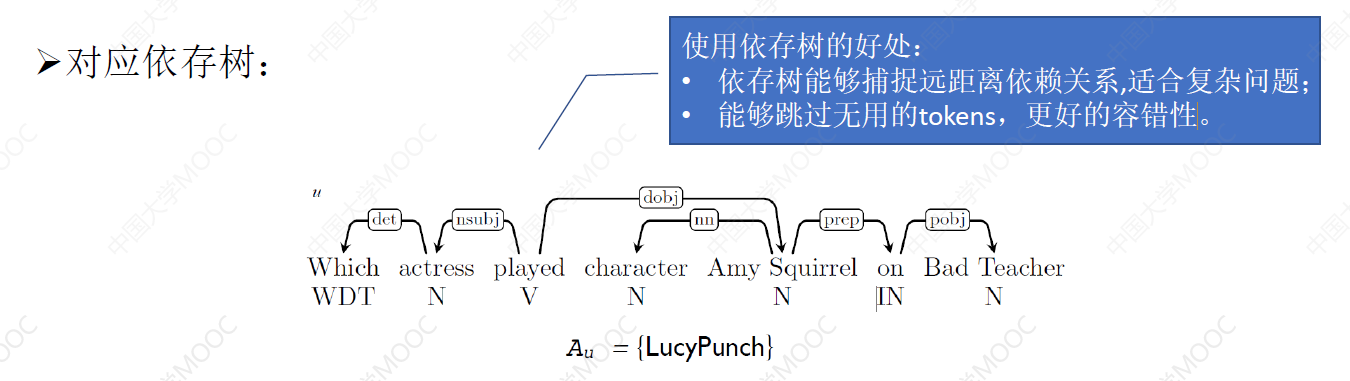
# 2.4.1 模板生成 —— 问句依存文法分析
训练阶段的输入是问题 utterance u 和它对应的答案集合 Au,输入示例:
- utterance u =“Which actress played character Amy Squirrel on Bad Teacher?”
- Au = {LucyPunch}
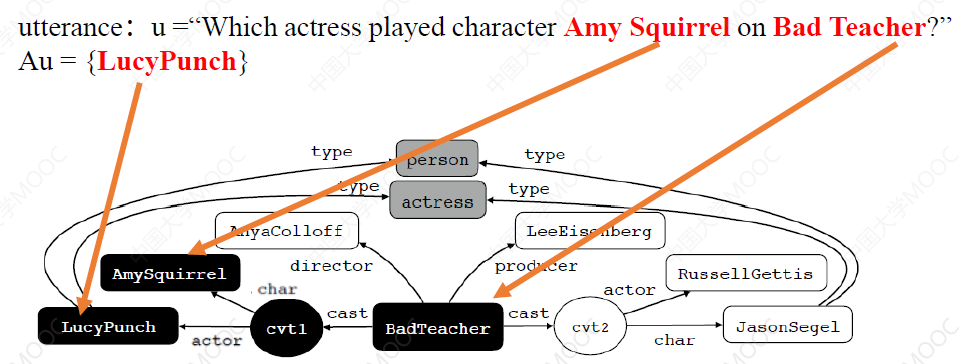
# 2.4.2 模板生成 —— 为问句构建查询子图
根据问句和答案中的实体,使用实体链接工具与知识图谱中的实体进行链接,并从 KG 中得到相应的最小子图。
黑点构成最小子图,进一步将 answer 与 cvt 替换为变量 ?x、?cvt,并添加 answer 上的 type 边,即问题的答案类型,形成带变量的子图。
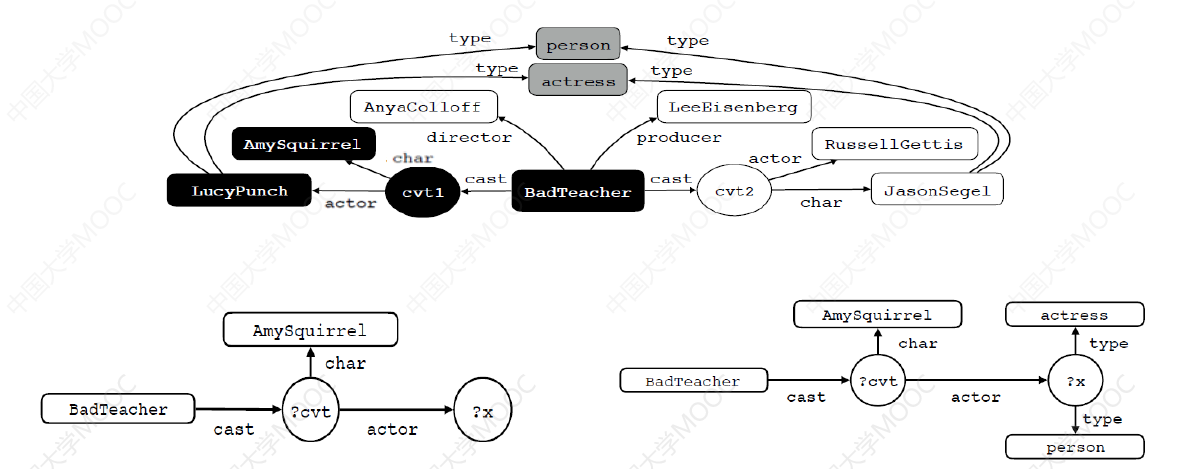
# 2.4.3 模板生成 —— 问句与查询的对齐
这里主要要实现三种类型的对齐:
- Entity 对齐:如 AmySquirrel、BadTeacher 等
- Type 对齐:如 actress 等
- 谓词对齐:如 played on 与 cast.actor 对齐等
要实现问句与查询的对齐并没有那么简单,通常需要构建足够丰富的词典库才能实现有效、准确的对齐。
通常需要构建两类词典库:Predicate Lexicon(
比如我们可以把语料中的实体对与 KG 中对应的实体对进行对齐,如果某对实体对能够与很多语料都进行对齐,便可以认为它们存在映射关系,如语料中的 was born in 与 KG 中的 birthPlace:

有了词典库的帮助还不够,更进一步,我们将问题分块,得到多个 phrase 短语,然后将问题中的短语与 KG 对齐,如下图所示:
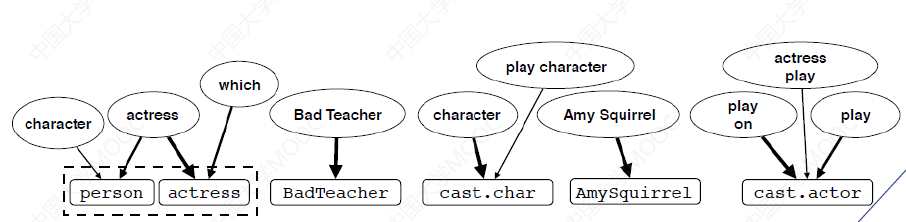
- 下图的上面部分是问句中的短语 来自问句的子串
- 下图的下面部分是查询子图中的语义项,来自知识图谱中的实体、类、属性和关系定义
使用词典 L 对齐和添加边,出现歧义(问题歧义,词典噪声)使用 ILP(整数线性规划) 来确定最优边。这里有一个约束:函数限制条件:每个 semantic items 都需要一条边 。 每个 phrase 只能对应一 个 semantic items 。 Type 边只能选择一个 。
# 2.4.4 模板生成
进一步依据问句与查询对齐的结果,生成可能的模板。如下图所示,我们将左边对齐后的子图中的节点,进一步做相关的替换,就可以生成最终的、我们想要的查询模板,并存入到模板库中。
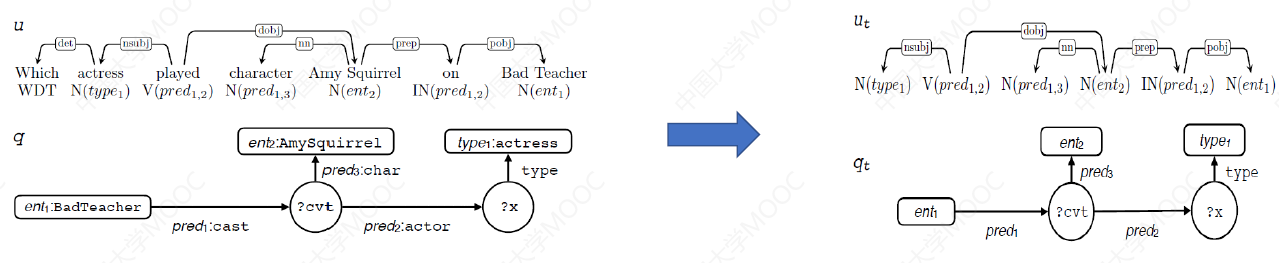
# 2.4.5 模板实例化
- 对于新问题首先进行依存分析,并使用实体链接工具与知识图谱建立链接。
- 使用子图同构去模板库中进行匹配,图中加粗的黑线为匹配部分。
- 再使用词典 L 对模板中的项进行映射和实例化。

# 2.4.6 候选查询排序
与之前一样,这里也需要对实例化的模板进行排序。
产生多个候选查询的原因:
- 模板可能匹配多个
- 实体链接可能匹配图谱中的多个实体
可以使用多种方法如 Random Forest 学习两个查询之间的顺序。
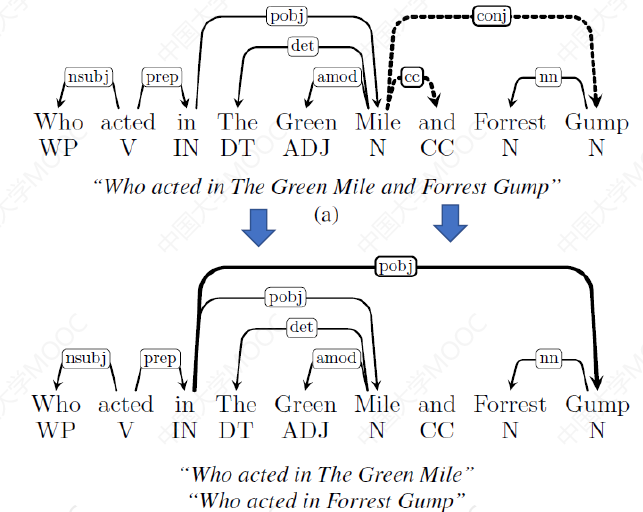
# 2.4.7 复杂问题处理
QUINT 还提供了复杂问题的处理方法,比如下图上面的问题,就被分成了下面的两个子问题的查询:
这个过程如下图:
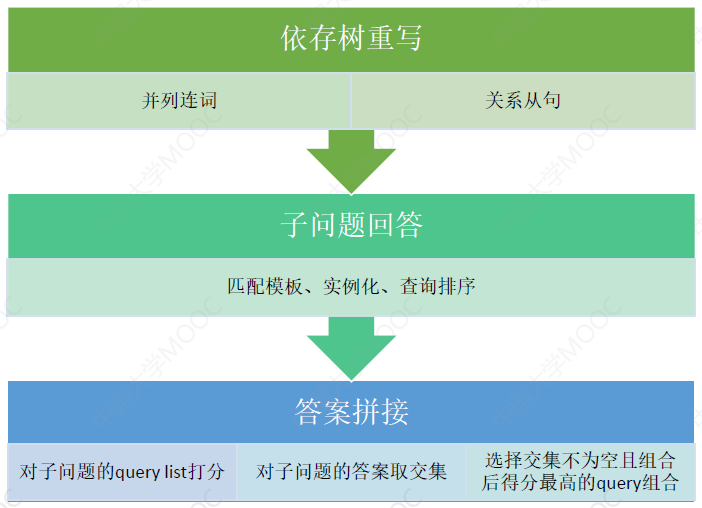
小结
- 模板方法的优点:
- 模板查询响应速度快
- 准确率较高,可以回答相对复杂的复合问题
- 模板方法的缺点:
- 人工定义的模板结构经常无法与真实的用户问题进行匹配
- 如果为了尽可能匹配上一个问题的多种不同表述,则需要建立庞大的模板库,耗时耗 力且查询起来效率降低。
# 3. 基于语义解析的知识图谱问答
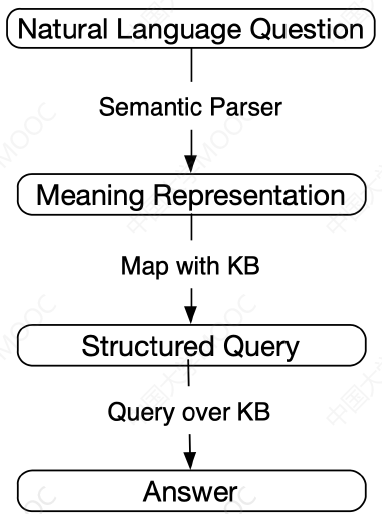
语义解析的目标也是要生成一个结构化的逻辑查询,并在 KG 上直接查询获得结果。但与问句模板方法不同的是,语义解析是希望直接把问句解析为对应的逻辑表达式,而不是拿问句去匹配模板库。
这种方法通常包括逻辑表达式、语义解析算法、语义解析模型训练三个方面。
# 3.1 一步语义解析
这种实现方法是直接将给定的自然语言问句解析成形式化的逻辑表达式,如下图,直接将自然语言问句解析成 lambda 演算子:
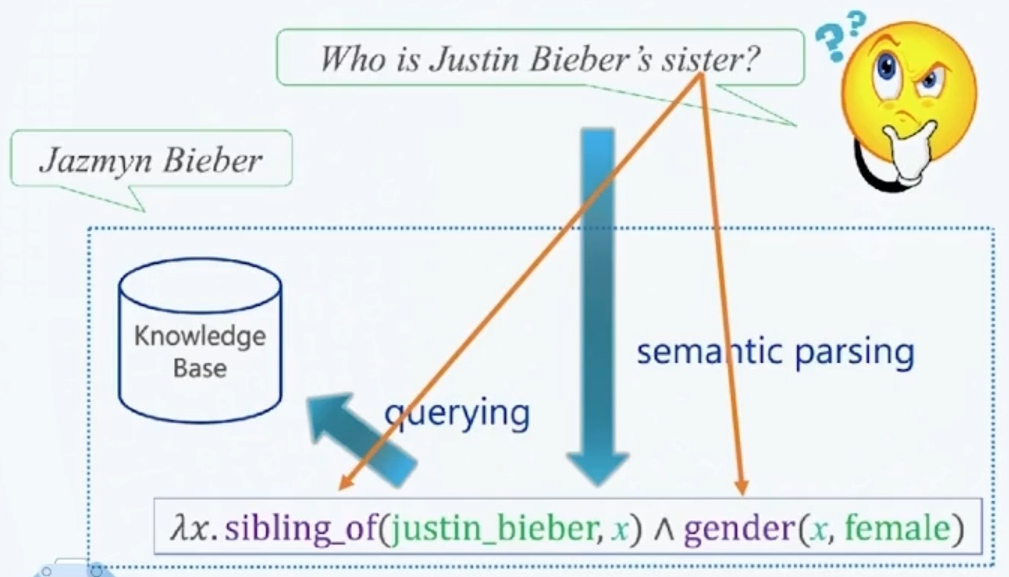
观察一下可以发现,这样的解析存在两个困难:
- 问句中的实体或关系名称(如 sister)与 KB 中的实体或关系描述(如 sibling-of)不能直接匹配
- 问句中只有一个谓词关系 sister,但 KB 中需要两个谓词关系(sibling-of 和 gender)才能表达相同的语义
# 3.2 二步语义解析
上面的方法正是由于存在困难,因此更合理的方法是将问句解析分成两步:首先将问句解析成中间表示,再将中间表示翻译成与 KG 对应的最终逻辑表示。
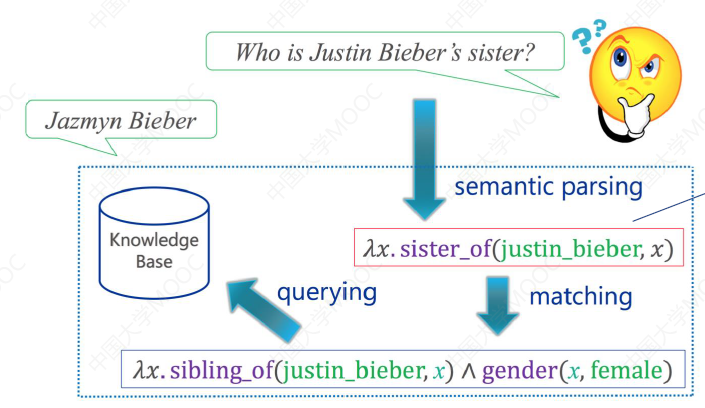
这样的好处是,问句的解析更加精细,知识图谱的对齐也更加容易。
# 3.3 逻辑表达式:λ-Calculus
有很多种可用的逻辑表达语言,

# 3.4 逻辑表达式:λ-DCS
这是 Stanford 提出的一种语义逻辑表示方法,这一形式语言的定义更加适合 KG 的存储结构。
λ-DCS: Lambda Dependency based Compositional Semantics
下图展示了这种方法面对一个自然语言问句,是如何自底向上地组成一个复杂语义规则的:
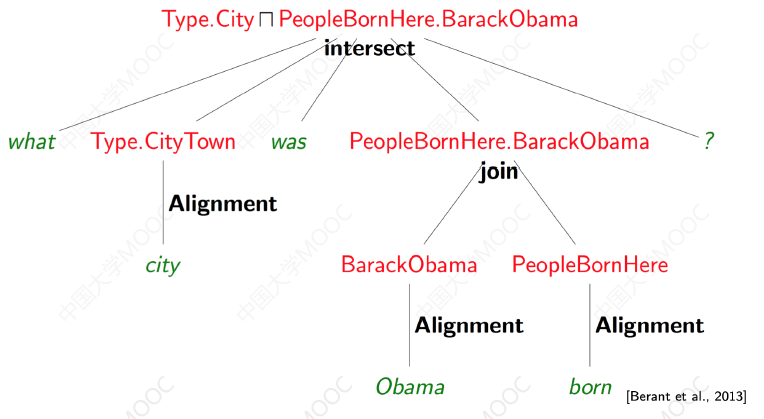
- 组合语法更加简单
- 支持最基本的实体、关系、Join/Intersection 操作
- 支持桥接操作 —— Bridging
https://time.geekbang.org/course/detail/100046401-256114?utm_source=related_read&utm_medium=article&utm_term=related_read
# 3.5 逻辑表达式:CCG
组合范畴语法(Combinatory Categorial Grammar)是另外一种常用的逻辑表达式语言。这里不再详细展开。
# 3.6 语义解析的基本步骤
无论采用哪种逻辑表达语言,语义解析的基本步骤都需要经过短语检测、资源映射、语义组合和逻辑表达式生成四个部分。
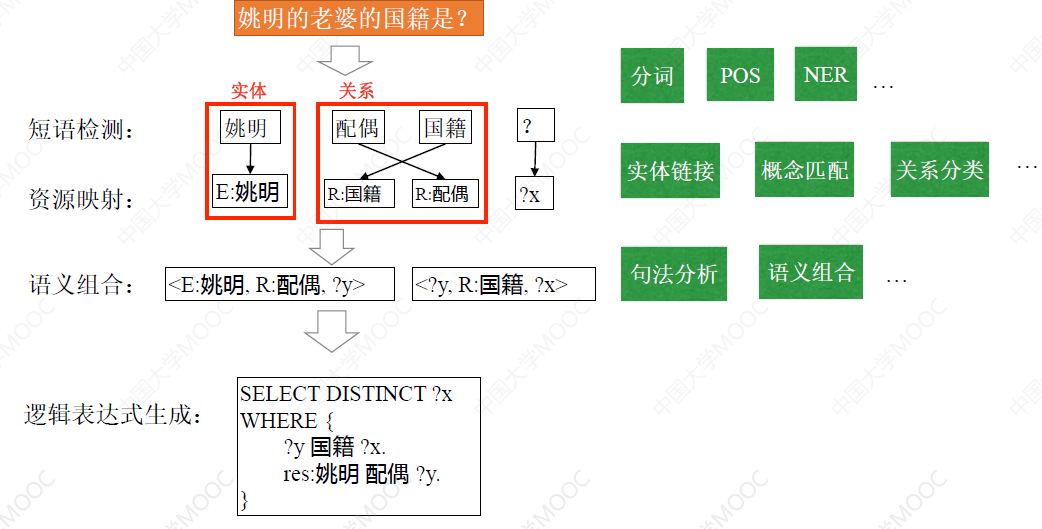
- 其中短语检测部分是与知识图谱无关的,主要目标是识别出问句中的实体、关系谓词等各种短语
- 资源映射的目标是要建立问句与知识图谱的映射,这包括实体链接、概念匹配和关系分类这三个核心步骤:
- 实体链接完成问句中的实体与 KG 中的实体的关联
- 概念匹配将问句中的概念与 KG 中的类型进行关联
- 关系分类则是对问句中的谓词进行处理,并映射到 KG 中的关系上
- 语义组合就是将各种要素进行组合,这需要做句法分析、组合模型训练等工作
- 最后利用组合生成的、可以执行的逻辑表达式来获得最终的答案
# 3.7 语义解析举例
第一步:获得与知识图谱无关的问句解析。这一步中,主要识别哪些短语代表概念、哪些短语代表实体、哪些短语代表无关性谓词等。
第二步:与知识图谱建立各种关联。这里的核心技术就是三个:概念匹配、关系抽取和分类、实体链接。
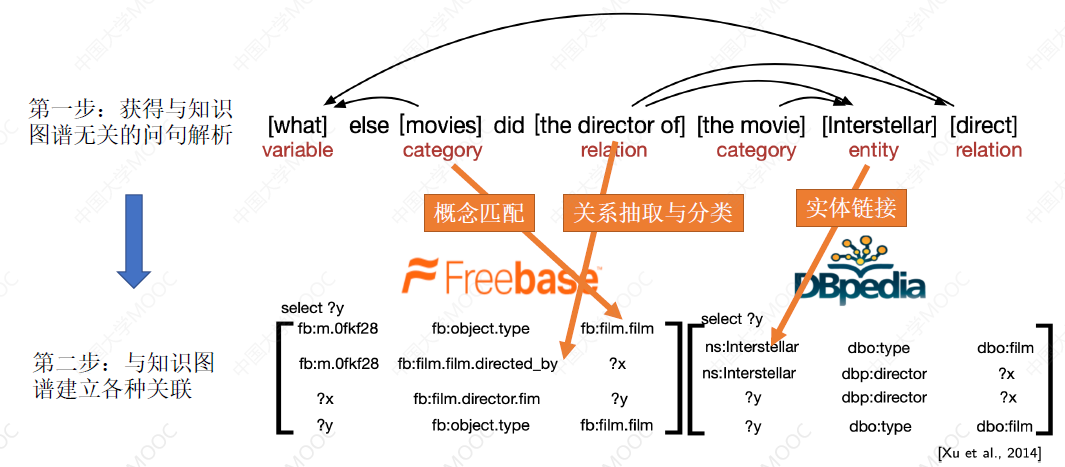
如下面这个例子:
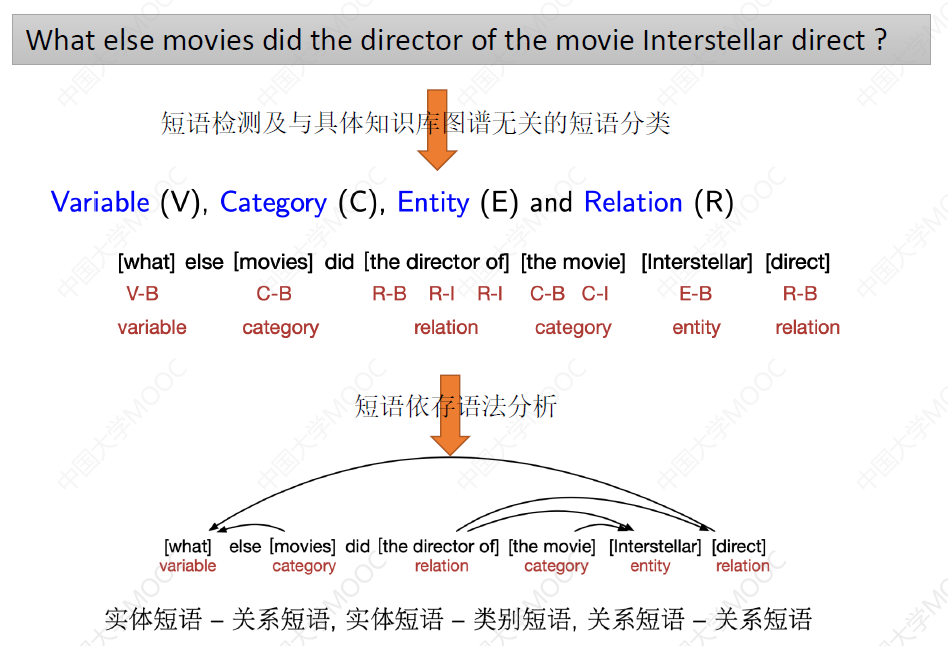
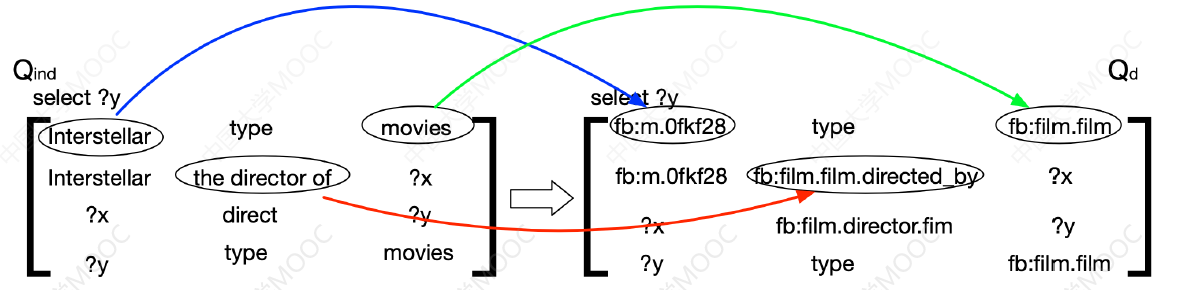
- 最后得到的这个短语依赖关系,一方面有助于后续 Grounding 的实现,也是进一步组合这些短语要素的主要的输入。
接下来就要完成从短语到 KG 的映射,即 Grounding 的操作。如下图,左边的矩阵代表我们将问句的原始短语组织成对应的逻辑结构的形式,然后我们需要分别将其中的自然语言描述映射到 KG 的要素中,这一步往往需要借助实体对齐等技术,但往往也需要用词典来辅助:
# 3.8 语义解析器的训练
既然在语义组合阶段,最终问句的对应组合方式有很多种,那我们自然可以想到是否可以使用机器学习训练一个模型,来识别最优的、有效的逻辑表达式。
目标:通过大规模知识库上的问题答案对集合训练 Parser。
输入输出如下图:

训练方式:

- 这里主要就是建立一个 feature,然后就可以套用常规的机器学习方法了
下面在单独介绍两个与语义解析相关的问题:
# 3.9 补充问题:Bridging 操作
通常谓词不是明确表示的,导致问句中的谓词无法与知识图谱中的关系直接映射。比如下面这个“Which college did Obama go to?”问句中没有明显的谓词,但问句又确实描述了某种关系语义,因此为了对应到 KG 中,需要对其进行拆解。

在这种无法直接映射谓词的情况下,我们通常需要把实体周边的谓词进行一些桥接操作,才能和问句中真正的谓词以及语义对应上。这种 Bridging 操作可以借助定义桥接模板来实现,也可以通过定义一些特征来训练一些机器学习模型来实现。
# 3.10 补充问题:Paraphrasing
我们可以意识到,自然语言问句的形式是非常多样的,知识图谱构建不可能覆盖所有的自然语言描述。通常情况下,KG 是高度不完备的。比如 Reverb 中只有 2% 的 relation phrase 可以与 Freebase 对齐,这就意味着我们需要构建非常庞大的词典来辅助实现高质量的短语映射。而短语重写就是缓解这类问题的一种方法。
短语重写(Paraphrasing)的思想很简单:对于给定的问句,我们可以把它重写为各种形式不同但语义一样的问句形式。
- 一方面,我们可以利用重写得到的新语句来扩展答案,因为一种形式的问句可能无法与 KG 进行匹配,但另一种形式的问句却可以与 KG 进行精确地匹配。
- 另一方面,我们可以训练一个模型,给定普通的问句,输出用语规范、逻辑完整的问句,这种用语规范、逻辑完整的问句,可以更加容易地建立到 KG 的映射。这里的关键是要收集足够多的高质量的相似语句语料来训练这个 Paraphrasing 模型。

Scaling up via alignment / bridging [EMNLP 2013]
小结
- 与模板方法类似,语义解析最终也希望得到一个可以直接在知识图谱上查询的逻辑表达式。但不同的是,语义解析方法期望直接从问句解析获得对应的逻辑形式。
- 不论采用哪种逻辑表达式,语义解析都需要经过短语检测、资源映射、语义组合和逻辑表达式生成四个步骤。
- 不论是模板还是语义解析的方法关注的重点还是问句本身,最大缺点是对知识图谱中资源的利用程度不够,事实上,知识图谱中的海量知识是可以极大的增强问句的理解过程的。更好的方法应该充分深挖问句和知识图谱两方面资源所蕴含的信息。
# 4. 基于检索排序的知识图谱问答
这种方式是应用较广、较为成熟的方法。
# 4.1 基本流程
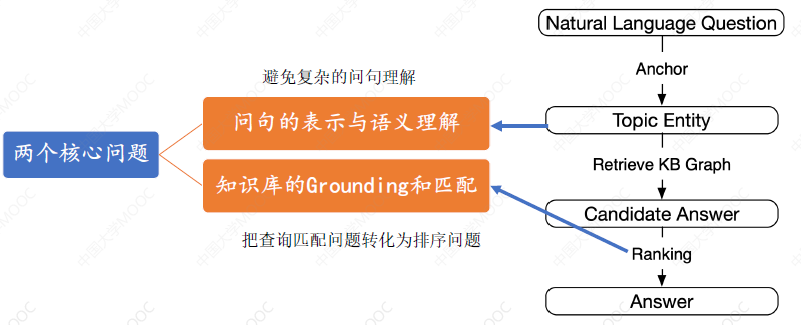
基于检索排序的 KBQA 方法不再以问句为中心解决问题,而是以 KG 为中心,把查询匹配问题转化为一个检索排序的问题,这种方法的基本流程是:
- 给定一个自然语言问句,我们首先通过实体链接技术,定位这个问题的中心实体
- 再从 KG 中获取与中心实体相关的实体作为候选答案
- 这个过程可以结合实体识别和关系抽取的方法来解决,关系抽取就是从问句中抽取出涉及的关系,并将关系组成一条知识图谱上的路径,这样的路径连接了中心实体与候选实体,使我们能够通过中心实体检索到相关的候选实体来作为答案。
- 最后对候选答案进行排序,选出得分最高的实体作为答案
比如给定问句“Who is the brother of Justin Bieber?”,首先通过实体链接技术,定位到中心实体是 Justin Bieber,然后通过实体消歧找到 KG 中对应的 Justin Bieber 这一实体,再通过周围的关系能够找到很多的候选实体,最终通过对候选答案进行排序,我们能够得到对应的答案。
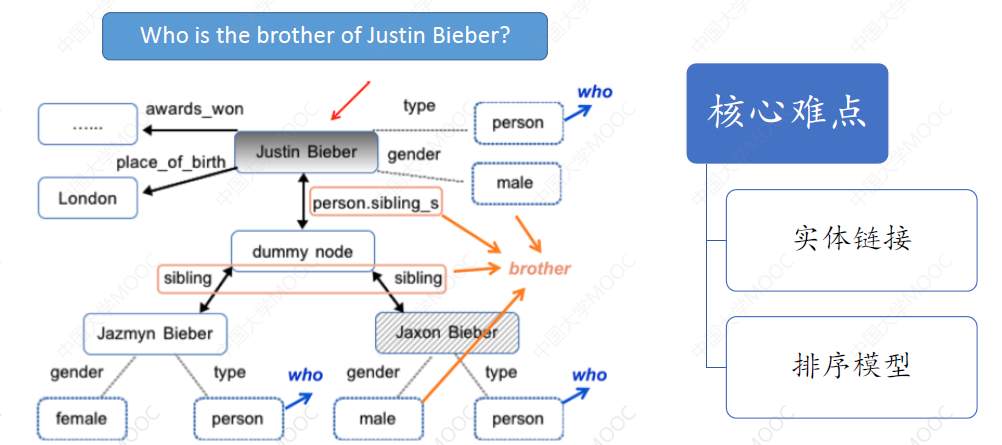
这里的核心难点是:
- topic entity 的定位:因为 topic entity 是寻找后续答案的起点,如果这个实体定位错了,后面就会谬之千里
- 排序模型的选择:排序模型的选择决定了排序的效率。这里可以采用 DL 的方法,为每个候选实体学习出一个 vector representation,然后计算这些 representation 与问句的 representation 之间的相似度
由此可以看出,基于检索排序的方法有如下优缺点:
- 优点:避免了问句的语义理解过程
- 缺点:无法保证答案的准确性
# 4.2 实体链接
# 4.2.1 实体链接:任务定义
实体链接(Entity Linking)是一项在文本等载体中对知识图谱中的命名实体进行识别和消歧的任务。通俗来说,给定一个问题,我们首先的目标是识别这个问句的 topic entity,也就是确定这个问题是关于哪个话题或事物的问题。这通常可以分成两步:
- 命名实体识别
- 链接消歧:也就是对所识别的实体进行消歧,并对应到 KG 中的相应实体
例子:
- 小米营养丰富,是传统健康食品,可熬粥。
- 小米粥口味清淡,健胃消食。
识别难度:小米粥不可忽略“粥”字并将其识别为“小米”。
消歧难度:小米可能指食品、手机品牌或公司名,需要结合上下文语义等信息消歧。
# 4.2.2 实体链接:方法举例
End to end Neural Entity Linking. CoNLL2018
这种方法是:将实体链接问题的两部分-识别和消歧-作为一个联合任务,使用端到端的神经网络进行优化。
- 认为识别和消歧是可以互相提升效果。
- 在消歧的过程中考虑所识别的所有候选实体能提高模型的语义理解能力。
# 4.2.3 实体链接:多语言实体链接
在实际应用中,我们经常需要把多语言的文本中的实体链接到一个或多个不同语种的知识图谱上,这类型的设定被称为是跨语言实体链接。
- 当语种数目足够多时,会出现低资源语种或实体对应的训练数据极少的情况,因此,需要格外关注零样本和少样本的情形。
论文 Entity Linking in 100 Languages.(EMNLP2020) 中的模型融合负样本挖掘、辅助的实体配对任务,得到一个能对 100 种语种的 2000 万个实体进行实体链接的模型,取得很好的效果。
# 4.3 排序模型
有很多种实现候选答案排序的方法。
# 4.3.1 基于特征的检索排序
传统的基于特征工程的方法需要针对每个答案构建 N 维特征表示,这些特征反映了问题和检索所得的答案候选在某个维度上的匹配程度,用于排序。

常用的问题特征主要包括:
- 疑问词特征
- 问题实体特征
- 问题类型特征
- 问题动词特征
- 问题上下文特征
- 常用的答案特征包括
常见的答案特征包括:
- 谓词特征
- 类型特征
- 上下文特征
# 4.3.2 基于子图匹配的检索排序
具体做法是:从输入问题中定位问题实体,随后答案候选检索模块以该问题实体为起点,按照特定规则从知识图谱中选择答案候选,接下来,答案子图生成模块为每个答案候选实体从知识图谱中抽取出一个子图,作为该答案实体的一种表示。最后答案检索排序模块计算输入问题和每个答案子图之间的相似度,用来对子图对应的答案候选进行打分,从而排序得到最终答案。
Gao. Semantic Parsing via Staged Query Graph Generation: Question Answering with Knowledge Base. ACL, 2015.
这篇 paper 是一个具有代表性的基于子图匹配的检索排序知识图谱问答方法
# 4.3.3 基于向量表示的检索排序
具体做法:为输入问题 Q 和答案候选 A 分别学习两个稠密的向量表示 f(Q) 和 g(A),并在向量空间中计算问题向量和答案向量之间的相似度,用于对不同的答案候选进行打分。
- Question Answering with Subgraph Embeddings. EMNLP, 2014
- Open Question Answering with Weakly Supervised Embedding Models. ECML PKDD, 2014
# 4.3.4 基于记忆网络的检索排序
这种方法除问答模块之外,引入记忆网络模块,记忆网络模块负责将有限的记忆单元表示为向量,问答模块从记忆网络模块中寻找与问题有关的答案。
Miller 等人提出基于 Key value Memory Network 的问答模型,将外部数据输入表示为记忆单元,通过问句与记忆单元之间的计算来寻找答案。
- Jason Weston, Sumit Chopra, Antoine Bordes Memory Networks. ICLR, 2015.
- Antoine Bordes Nicolas Usunier Sumit Chopra, Jason Weston. Large scale Simple Question Answering with Memory Network. ICLR, 2015.
- Sarthak Jain. Question Answering over Knowledge Base using Factual Memory Network. NAACL, 2015.
小结
基于检索排序的知识图谱问答:
- 优势:
- 框架灵活、实用
- 易于融合多种线索、特征
- 容易与其他方法、框架结合
- 适用多种类型资源
- 缺点:
- 依赖特征工程
- 易受错误传递影响
- 不擅长处理语义组合
- 难以处理推理问题
# 5. 基于深度学习的知识图谱问答
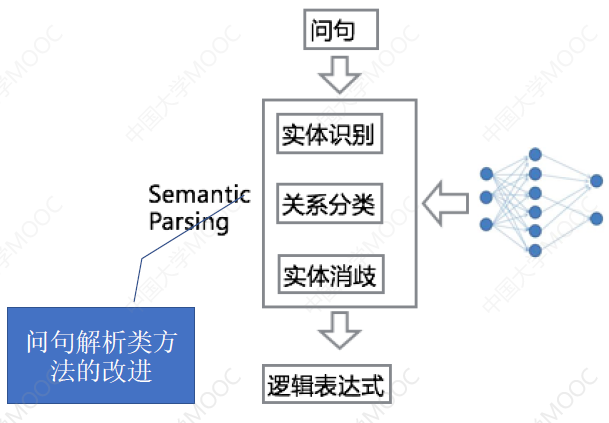
DL 的方法被广泛用到 KBQA 中。总的来说,深度学习在这里有两种用法:
- 利用深度学习对某个模块进行改进,多用于改进问句解析模型,以提升整体的效果。比如用于改进实体识别、关系分类、实体消歧等模块
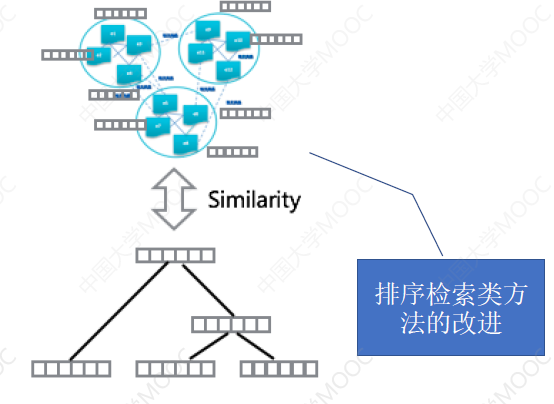
- 基于深度学习的 End2End 模型,多用于改进端到端的排序检索模型。
# 5.1 对语义解析的改进:STAGG
语义解析主要将问句映射为一种逻辑表达形式,然后再翻译为 KB 的查询语句。然而大多数传统的语义解析框架都没有充分利用 KG 中的信息,因此,在拓展性和实用性方面面临着一些挑战。
比如,当逻辑表达形式的使用与 KG 中定义的谓词不同时,就需要额外的方法来做本体概念的匹配。这里介绍一种新的方法 —— STAGG: Staged Query Graph Generation。
Semantic parsing via staged query graph generation: Question answering with knowledge base ACL (2015)
STAGG 充分利用 KG 来减小问句解析的搜索空间,通过搜索逐步构建查询图,从而简化语义查询问题。
具体来说,这个框架首先定义了一个可以将问句直接转化为 lambda 演算的查询图,然后将语义解析的过程转变为查询图生成的过程,最后对生成的查询图进行排序,得到最终的答案。
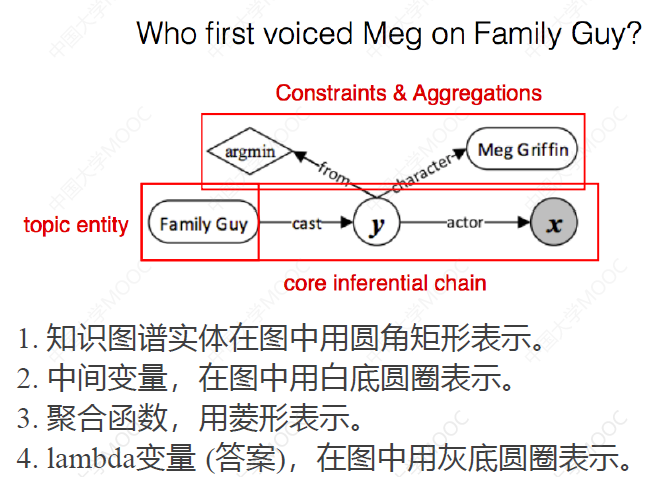
查询图的生成主要有三个主要工作:实体链接、属性识别和约束挂载。具体的做法可以参考网课和相关资料。
# 5.2 End-to-End 模型:Simple Embeddings
Question Answering with Subgraph Embeddings. EMNLP (2014)
这个模型的目的是将问题中出现的单词、短语、KG 中的候选实体、关系类型等都映射到一个低维 embedding 空间中,使得问题和相应的答案在联合的 embedding 空间中彼此接近。
其中,候选答案实体用三种向量进行表示:答案实体本身、答案实体与组实体关系路径、与答案相关的 subgraph。
然后通过这些 representation 来计算问题和答案的相似度,以选出正确的答案。
在不依赖词表、规则、句法、依存树解析等条件下,作为 end2end 模型,它超越了当时最好的结果。
# 5.3 End-to-End 模型:CNN + Attention
Question answering over freebase with multi-column convolutional neural networks. ACL (2015)
前述模型针对问句编码采用词袋模型,没有考虑词序对句子的影响,也没有考虑不同类型属性的不同特性。这里提出的网络分别对 Answer Path、Answer Context 和 Answer Type 进行编码,以获取不同的语义表示,问句通过一个 multi-column 的卷积神经网络获得多个向量表示,然后分别与 Answer Path、Answer Context 和 Answer Type 这三方面的答案信息进行相似度计算,三者通过加权计算获得最后结果。
这个模型验证了考虑词序信息、问句与答案的关系对 KBQA 效果的提升是有效的。
# 5.4 End-to-End 模型:Attention + Global Knowledge
An End to End Model for Question Answering over Knowledge Base with Cross Attention Combining Global Knowledge. ACL (2017)
已有的方法多采用 Word Embedding 的平均对问句进行语义表示,这样的问句表示过于简单。关注答案的不同部分,问句的表示应该是不一样的,针对这个问题,这里的工作提出了基于 Cross-Attention 的神经网络来刻画问句表述与答案之间的关联。
这个模型通过 TransE 与 Cross-Attention 联合训练,融入了知识图谱的全局信息,减轻了 OOV 的坏影响,有效提升了问答的效果。
# ⭐️ 5.5 End-to-End 模型:Key-Value Memory Networks
Key-Value Memory Networks for Directly Reading Documents. ACL (2016)
在 KV Memory Networks 中,对于每个问题,都会进行一个 key hashing 的预处理,从知识源中选择出与之相关的记忆,也就是 fact,然后再进行模型的训练。
知识源可以是知识图谱,或者文本的维基百科,或者是通过搜索引擎得到的结果。KV Memory Network 的一个显著好处就是可以对先验知识进行编码,这样就可以方便让每个本领域的人将本领域的背景知识编码入记忆中,从而训练自己的问答系统。
这种类型的网络还支持浅层推理。如工作:Enhancing Key-Value Memory Neural Networks for Knowledge Based Question Answering. ACL (2019)
# 5.6 End-to-End 模型:Neural Symbolic Machines
Neural Symbolic Machines: Learning Semantic Parsers on Freebase with Weak Supervision. ACL (2017)
它的效果也很不错,参考网课和相关论文资料。
小结:深度学习方法的优缺点
优点:深度学习模型能够深入的表征问句,并深挖知识图谱内部的实体和关系表示,因而在 问句的理解、候选答案的排序计算方法都能取得更好的效果。
缺点:
- 深度学习模型对于相对简单的问题效果比较好,由于深度模型通常依赖大量的训练语料,对于逻辑更加复杂的问句由于训练语料未必充分,可能不如传统的方法好。
- 很多知识图谱问答设计比较、排序、逻辑推断等任务,深度学习模型在解决这类涉及推理类的问句方面仍然做得不够好。
- 深度学习模型相比传统问答模型,可解释性不好。
# Summary
- 语言理解和知识表示是解决智能问答系统最核心的两个要素。由于问句理解通常也离不开知识的辅助,知识图谱在问答系统中实际居于非常核心的位置。
- 常用的知识图谱问答技术包括:基于查询模板的方法、基于语义解析的方法、基于检索排序的方法和基于深度学习的方法。
- 基于模板的方法需要人工维护大量模板,虽然实现较为笨拙,但通常能够保证问答的响应速度和准确性,因而在很多真实的工业场景中仍然被广泛使用。
- 基于语义解析的方法侧重于从问句出发,通过将问句解析为逻辑表达式来获取最终答案。基于检索排序的方法则侧重于从知识图谱出发,将查询问题转化为候选答案的排序问题,从而避免了复杂的问句语义理解难题。
- 深度学习方法既被用来改进语义解析模型,也被用来改进检索排序模型,是知识图谱技术发展主要趋势。但在复杂问句处理、推理支持和可解释性方面还需进一步提升。