pytorch 工具箱
pytorch 工具箱
# 1. PyTorch 神经网络工具箱
# 1.1 神经网络核心组件
当把神经网络的核心组件确定后,这个神经网络基本就确定了。这些核心组件包括:
- 层:神经网络的基本结构,将输入张量转换为输出张量。
- 模型:层构成的网络。
- 损失函数:参数学习的目标函数,通过最小化损失函数来学习各种参数。
- 优化器:如何是损失函数最小,这就涉及到优化器。
多个层链接在一起构成一个模型或网络,输入数据通过这个模型转换为预测值,然后损失函数把预测值与真实值进行比较,得到损失值(损失值可以是距离、概率值等),该损失值用于衡量预测值与目标结果的匹配或相似程度,优化器利用损失值更新权重参数,从而使损失值越来越小。这是一个循环过程,损失值达到一个阀值或循环次数到达指定次数,循环结束。
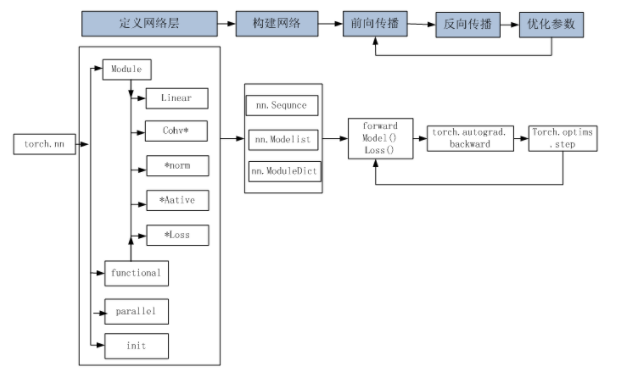
- 构建网络层可以基于Module类或函数(nn.functional)。nn.functional 中函数与 nn.Module 中的 layer 的主要区别是后者继承 Module 类,会自动提取可学习的参数。而 nn.functional 更像是纯函数。
# 1.2 如何构建神经网络
我们用 nn 工具箱,搭建一个神经网络,步骤好像不少,但关键就是选择网络层,构建网络,然后选择损失和优化器。
# 1)构建网络层
我们可以使用 torch.nn.Sequential() 构建网络层,使用起来就像搭积木一样,非常方便。
nn.Sequential: A sequential container. Modules will be added to it in the order they are passed in the constructor. Alternatively, an ordered dict of modules can also be passed in.
一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数。
一个三层网络的示例:
class Net(nn.Module):
def __init__(self, in_dim, n_hidden_1, n_hidden_2, out_dim):
super().__init__()
self.layer = nn.Sequential(
nn.Linear(in_dim, n_hidden_1),
nn.ReLU(True),
nn.Linear(n_hidden_1, n_hidden_2),
nn.ReLU(True),
# 最后一层不需要添加激活函数
nn.Linear(n_hidden_2, out_dim)
)
def forward(self, x):
x = self.layer(x)
return x
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
如果要对每层定义一个名称,我们可以采用 Sequential 的一种改进方法,在 Sequential 的基础上,通过add_module() 添加每一层,并且为每一层增加一个单独的名字。此外,还可以在 Sequential 基础上,通过字典的形式添加每一层,并且设置单独的层名称:
class Net(torch.nn.Module):
def __init__(self):
super(Net4, self).__init__()
self.conv = torch.nn.Sequential(
OrderedDict(
[
("conv1", torch.nn.Conv2d(3, 32, 3, 1, 1)),
("relu1", torch.nn.ReLU()),
("pool", torch.nn.MaxPool2d(2))
]
))
self.dense = torch.nn.Sequential(
OrderedDict([
("dense1", torch.nn.Linear(32 * 3 * 3, 128)),
("relu2", torch.nn.ReLU()),
("dense2", torch.nn.Linear(128, 10))
])
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 2)前向传播
定义好每层后,最后还需要通过前向传播的方式把这些串起来。forward 函数的任务需要把输入层、网络层、输出层链接起来,实现信息的前向传导。该函数的参数一般为输入数据,返回值为输出数据。
在forward函数中,有些层来自 nn.Module,也可以使用 nn.functional 定义。来自 nn.Module 的需要实例化,而使用 nn.functional 定义的可以直接使用。
# 3)反向传播
关键是利用复合函数的链式法则。Pytorch 提供了自动反向传播的功能,使用 nn 工具箱,我们无需自己编写反向传播,直接让损失函数(loss)调用 backward() 即可,非常方便和高效。
# 4)训练模型
层、模型、损失函数和优化器等都定义或创建好,接下来就是训练模型。训练模型时需要注意使模型处于训练模式,即调用model.train()。
- 训练模型时需要注意使模型处于训练模式,即调用
model.train()。调用model.train()会把所有的module设置为训练模式。 - 测试或验证阶段则需要使模型处于验证阶段,即调用
model.eval()。调用model.eval()会把所有的training属性设置为 False。
缺省情况下梯度是累加的,需要手工把梯度初始化或清零,调用 optimizer.zero_grad() 即可。训练过程中,正向传播生成网络的输出,计算输出和实际值之间的损失值。 调用 loss.backward() 自动生成梯度,然后使用 optimizer.step() 执行优化器,把梯度传播回每个网络。
如果希望用 GPU 训练,需要把模型、训练数据、测试数据发送到 GPU 上,即调用 .to(device)。如果需要使用多 GPU 进行处理,可使模型或相关数据引用 nn.DataParallel。
# 1.3 nn.Module 和 nn.functional
前面我们使用 autograd 及 Tensor 实现机器学习实例时,需要做不少设置,如对叶子节点的参数 requires_grad 设置为 True,然后调用 backward,再从 grad 属性中提取梯度。对于大规模的网络,autograd 太过于底层和繁琐。而 nn.Module 能够自动检测到自己的 Parameter,并将其作为学习参数,且针对 GPU 运行进行了 CUDA 优化。
nn 中的层,一类是继承了 nn.Module,其命名一般为 nn.Xxx(第一个是大写),如 nn.Linear、nn.Conv2d、nn.CrossEntropyLoss等。另一类是 nn.functional 中的函数,其名称一般为nn.funtional.xxx,如 nn.funtional.linear、nn.funtional.conv2d、nn.funtional.cross_entropy等。从功能来说两者相当,基于 nn.Module 能实现的层,使用 nn.funtional 也可实现,反之亦然,而且性能方面两者也没有太大差异。不过在具体使用时,两者还是有区别,主要区别如下:
- nn.Xxx 继承于 nn.Module,nn.Xxx 需要先实例化并传入参数,然后以函数调用的方式调用实例化的对象并传入输入数据。它能够很好的与 nn.Sequential 结合使用,而 nn.functional.xxx 无法与 nn.Sequential 结合使用。
- nn.Xxx 不需要自己定义和管理weight、bias参数;而 nn.functional.xxx 需要你自己定义weight、bias,每次调用的时候都需要手动传入weight、bias等参数, 不利于代码复用。
- dropout 操作在训练和测试阶段是有区别的,使用 nn.Xxx 方式定义dropout,在调用 model.eval() 之后,自动实现状态的转换,而使用 nn.functional.xxx 却无此功能。
总的来说,两种功能都是相同的,但 PyTorch 官方推荐:具有学习参数的采用nn.Xxx 方式;没有学习参数的等根据个人选择使用 nn.functional.xxx 或者 nn.Xxx 方式。
# ● Linear Layer(Fully-connected Layer)
nn.Linear(in_features, out_features)
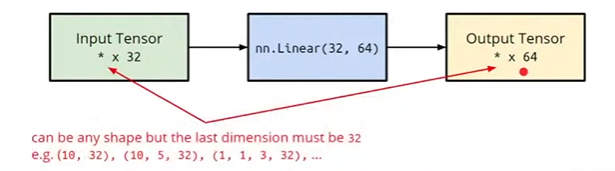
- 注意输入 Tensor 的前面的维度可以是任意的。
上面那一层的计算过程如下:
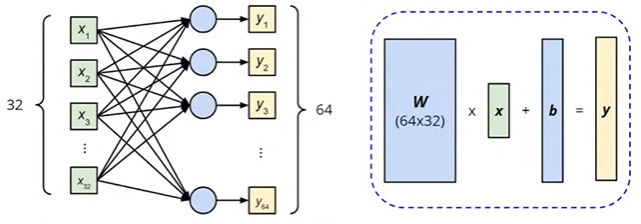
# 1.4 优化器
PyTorch 常用的优化方法都封装在 torch.optim 里面,其设计很灵活,可以扩展为自定义的优化方法。所有的优化方法都是继承了基类 optim.Optimizer。并实现了自己的优化步骤。最常用的优化算法就是梯度下降法及其各种变种,这类优化算法使用参数的梯度值更新参数。
使用优化器的一般步骤为:
# 1)建立优化器实例
导入 optim 模块,实例化 SGD 优化器,这里使用动量参数 momentum(该值一般在(0,1)之间),是 SGD 的改进版,效果一般比不使用动量规则的要好:
import torch.optim as optim
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum)
2
以下步骤在训练模型的 for 循环中。
# 2)前向传播
把输入数据传入神经网络 Net 实例化对象 model 中,自动执行 forward 函数,得到 out 输出值,然后用 out 与标记 label 计算损失值 loss。
out = model(img)
loss = criterion(out, label)
2
# 3)清空梯度
缺省情况梯度是累加的,在梯度反向传播前,先需把梯度清零。
optimizer.zero_grad()
# 4)反向传播
基于损失值,把梯度进行反向传播。
loss.backward()
# 5)更新参数
基于当前梯度(存储在参数的 .grad 属性中)更新参数。
optimizer.step()
# 1.5 动态修改学习率参数
修改参数的方式可以通过修改参数 optimizer.params_groups 或新建 optimizer:
新建 optimizer 比较简单,optimizer 十分轻量级,所以开销很小。但是新的优化器会初始化动量等状态信息,这对于使用动量的优化器(momentum参数的 sgd)可能会造成收敛中的震荡。
optimizer.param_groups:长度1的list。optimizer.param_groups[0]是长度为 6 的字典,包括权重参数、lr、momentum 等参数。示例如下:for epoch in range(num_epoches): if epoch % 5 == 0: optimizer.param_groups[0]['lr'] *= 0.1 # 动态修改参数学习率 print(optimizer.param_groups[0]['lr']) for img, label in train_loader: ...1
2
3
4
5
6
# 2. PyTorch 数据处理工具箱
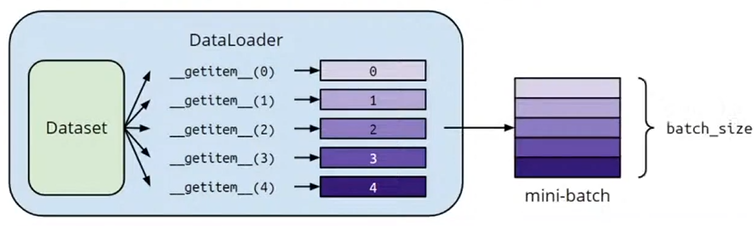
# 2.1 Dataset & Dataloader
定义 Dataset:

实例化 dataset 和 dataloader:

两者关系: