 Few-shot Learning
Few-shot Learning
参考视频:Few-Shot Learning (1/3): 基本概念 | bilibili (opens new window)
# 1. 基本概念
# 1.1 Introduction
先用一个问题引入,先给你看这四张图片:

这里有两类动物:Armadillo 和 Pangolin,现在你先看清楚了,然后再给你一张新的图片,问问你这是哪种动物:

即使很多人分不清两种动物,但如果你看过了前面四张图片,那面对 Query 其实很容易就做出正确答案。
注意这里的术语,Support Set 代表一个很小的数据集,比如有两类,每类有两张图片,这种集合不足以训练一个大的神经网络,它只能提供一些参考信息,而要讲的 Few-shot Learning 就是这种小样本分类问题。
Few-shot Learning 与传统的监督学习有所不同,它的目标不是让 machine 识别 training set 中的图片,然后泛化到 testing set,Few-shot Learning 的目标是让 machine 自己学会学习。比如我们给他一个下面的 training set,我们的目标不是让 model 去学习没见过的大象和老虎,学习的目的是让 model 学会识别事物的异同,让模型知道两张图片是相同的东西还是不同的东西:

当 model 训练完之后,你可以问 model 这样的问题:

注意我们的 training set 中不存在松鼠的类别,但 model 应该可以识别出这两张图片的动物很像,属于同一种动物。
现在换一种问法,如下图,我们有一张 Query 的图片,而神经网络由于没有在 training set 中见过这种东西,它肯定一脸懵逼,这时再给它一个 Support Set,里面有六张图片和对应的 label,而这时神经网络只需要根据 Support Set 来找出与 Query 最相似的图片,从而知道 Query 是哪种动物:

注意 Support Set 与 Training Set 的区别,training set 很大,每个 class 下都有很多张 image,相比之下 Support Set 很小,每个 class 下只有一张或者很少几张 image,它不足以训练一个完整的神经网络,它只能在预测的时候提供一些额外的参考信息。
# 1.2 Few-shot learning 与 Meta learning
- Few-shot learning is a kind of meta learning.
- Meta learning: learn to learn.

培养上面这个小朋友自主学习能力的过程,就是 Meta Learning。
# 1.3 Supervised Learning vs. Few-shot Learning
- Traditional supervised learning:
- Test samples are never seen before.
- Test samples are from known classes.

- Few-shot learning
- Query samples are never seen before.
- Query samples are from unknown classes.

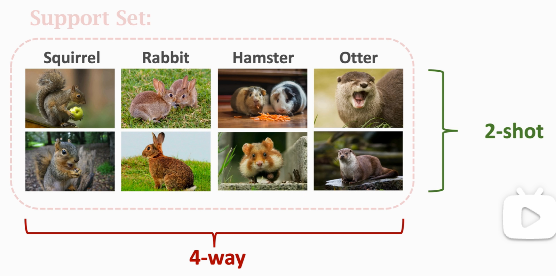
# 1.4 k-way n-shot Support Set
- k-way:the support set has k classes.
- n-shot:every class has n samples.
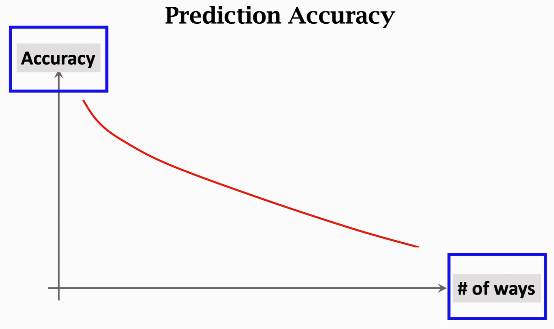
假如你做 few-shot 分类,那么预测准确率会受到 support set 中类别数量和样本数量的影响,比如下图中横坐标是 number of ways,可以看到,随着类别的增加,分类准确率会降低:
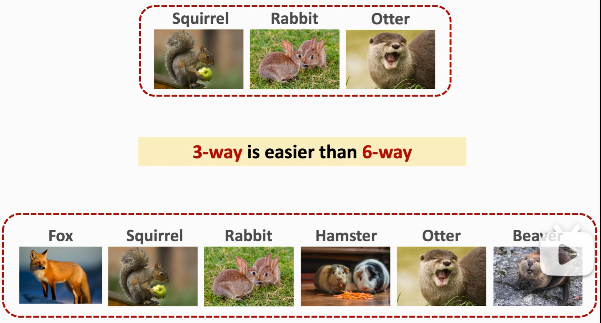
原因在于,对于小朋友而言,三选一会比六选一简单许多:
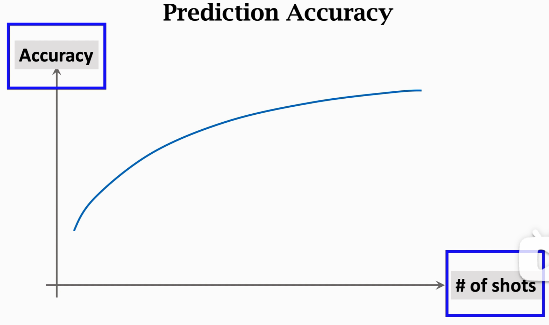
再看下图,随着 number of shots 的增加,accuracy 也会增大:
其中的原理也很容易理解:

# 1.5 怎么解决 Few-shot learning?
Idea: Learn a Similarity Function

具体可以这样做:
- First, learn a similarity function from large-scale training dataset.
- Then, apply the similarity function for prediction.
- Compare the query with every sample in the support set.
- Find the sample with the highest similarity score.

# 2. Dataset
# 2.1 Omniglot
这个 dataset 不大,只有几兆,很适合学术界:
它类似 minist,有很多类,但每个类只有很少的样本:
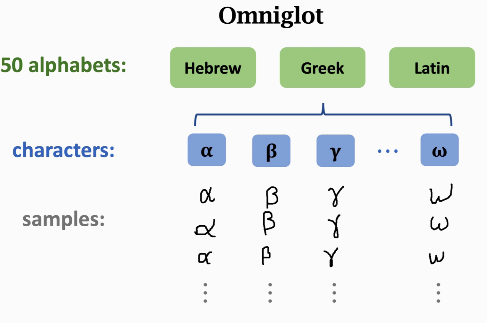
概括一下这个数据集:
- 50 different alphabets. (Every alphabet has many characters.)
- 1,623 unique characters. (i.e., classes)
- Each character was written by 20 different people. (i.e., each class has 20 samples.)
- The samples are 105 * 105 images.
- Training set:
- 30 alphabets, 964 characters (classes), and 19,280 samples.
- Test set:
- 20 alphabets, 659 characters (classes), and 13,180 samples.
# 2.2 Mini-ImageNet

它的样本都是 84 * 84 的小图片。