 数据库事务处理技术
数据库事务处理技术
# 1. 事务调度
# 1.1 什么是事务
数据库可能存在不一致的情况,比如大家同时买起点终点、日期、车次相同的车票,可能会买到座位相重复的车票。
三种典型的不一致现象:丢失修改、不可重复读、脏读。
事务是数据库管理系统提供的控制数据操作的一种手段,通过这一手段,应用程序员将一系列的数据库操作组合在一起作为一个整体进行操作和控制, 以便数据库管理系统能够提供一致性状态转换的保证。
比如银行转账业务,A 转 100 元给 B,必须 A - 100,B + 100 作为一个事务。
# 1.2 事务的宏观性和微观性
事务的宏观性(应用程序员看到的事务):一个存取或改变数据库内容的程序的一次执行,或者说一条或多条 SQL 语句的一次执行被看作一个事务。
Begin Transaction
exec sql …
…
exec sql …
exec sql commit work | exec sql rollback work
End Transaction
2
3
4
5
6
事务的微观性(DBMS看到的事务): 对数据库的一系列基本操作(读、写) 的一个整体性执行。
并发控制就是通过事务微观交错执行次序的正确安排,保证事务宏观的独立性、完整性和正确性。
# 1.3 事务的 ACID 特性
- 原子性 Atomicity:DBMS 能够保证事务的一组更新操作是原子不可分的,即对 DB 而言,要么全做,要么全不做。
- 一致性 Consistency:DBMS 保证事务的操作状态是正确的,符合一致性的操作规则,不能出现三种典型的不一致性。它是进一步由隔离性来保证的。
- 隔离性 Isolation:DBMS 保证并发执行的多个事务之间互相不受影响。例如两个事务 T1 和 T2,即使并发执行,也相当于或者先执行了 T1,再执行 T2;或者先执行了 T2,再执行 T1。
- 持久性 Durability:DBMS 保证已提交事务的影响是持久的,被撤销事务的影响是可恢复的。
具有 ACID 特性的若干数据库基本操作的组合体被称为事务。
# 1.4 事务调度与可串行性
事务调度:一组事务的基本步(读、写、其他控制操作如加锁、解锁等)的一种执行顺序称为对这组事务的一个调度。
并发调度的正确性:当且仅当在这个并发调度下所得到的新数据库结果与分别串行地运行这些事务所得的新数据库完全一致,则说调度是正确的、
那么问题来了:怎样判断一个并发调度是正确的?怎样产生一个正确的?
可串行性:如果不管数据库初始状态如何,一个调度对数据库状态的影响和某个串行调度相同,则我们说这个调度是可串行化的。
可串行性的几个结论
- 可串行化调度一定是正确的并行调度,但正确的并行调度,却未必都是可串行化的调度。PS:可串行化后,与某个串行调度结果相同,一定是正确的;但某些正确的并行调度,通过在微观上对某些操作进行一些技巧上的操作变换使其结果正确,但并不能用某个串行调度来模拟出来。
- 并行调度的正确性是指内容上结果正确性,而可串行性是指形式上结果正确性,便于操作。
- 可串行化的等效串行序列不一定唯一。
表达事务调度的一种模型:
# 1.5 冲突可串行性
冲突:调度中一对连续的动作,它们满足——如果它们的顺序交换,那么涉及的事务中至少有一个事务的行为会改变。
🖊 有冲突的两个操作是不能交换次序的,没有冲突的两个事务是可交换的。
几种冲突的情况:
- 同一事务的任两个操作都是冲突的:
- 不同事务对同一元素的两个写操作是冲突的:
- 不同事务对同一元素的一读一写操作是冲突的:
冲突可串行性: 一个调度,如果通过交换相邻两个无冲突的操作能够转换到某一个串行的调度,则称此调度为冲突可串行化的调度。
- 「冲突可串行性」是比「可串行性」要严格的概念。
- 满足冲突可串行性,一定满足可串行性;反之不然。
并发调度的正确性
可串行性 冲突可串行性
# 冲突可串行性判别算法:
- 构造一个前驱图(有向图)
- 结点是每一个事务
- 测试检查:如果此有向图没有环,则是冲突可串行化的
# 2. 基于封锁的并发控制方法
# 2.1 什么是锁
锁是控制并发的一种手段
- 每一数据元素都有一唯一的锁
- 每一事务读写数据元素前,要获得锁
- 如果被其他事务持有该元素的锁,则要等待
- 事务处理完成后要释放锁
调度器可利用锁来保证冲突可串行性。但锁本身并不能保证冲突可串行性,锁为调度提供了控制的手段。但如何用锁,仍需说明——不同的协议。
# 2.2 封锁协议
# 2.2.1 锁的类型
- 排他锁 X (eXclusivelocks):只有一个事务能读、写,其他任何事务都不能读、写
- 共享锁 S (Sharedlocks):所有事务都可以读,但任何事务都不能写
- 更新锁 U (Updatelocks):用来预定要对此页施加 X 锁,它初始允许其他事务读,但不允许再施加 U 锁或 X 锁;当被读取的页将要被更新时,则升级为 X锁;U 锁一直到事务结束时才能被释放
- 增量锁 I (Incrementallock):对于一部分数据库,对数据库的操作仅仅只涉及加与减操作。在只有增量操作的数据库中,我们把增加这一动作单独的提取出来,记为
inc(A, c),A 为属性,c 为增加的量。只有在事务获取了增量锁的前提下,才能够进行增量操作
# 2.2.2 相容性矩阵
相容性矩阵表示当某事务对一数据对象持有一种锁时,另一事务再申请对该对象加某一类型的锁,是允许(√)还是不允许(×)。
读写锁协议:
| S 锁 | X 锁 | |
|---|---|---|
| S 锁 | √ | × |
| X 锁 | × | × |
- 左 1 竖列表示持有的锁,上 1 横行表示申请的锁
更新锁协议:
| S 锁 | X 锁 | U 锁 | |
|---|---|---|---|
| S 锁 | √ | × | √ |
| X 锁 | × | × | × |
| U 锁 | × | × | × |
增量锁协议:(不重要)
| S 锁 | X 锁 | I 锁 | |
|---|---|---|---|
| S 锁 | √ | × | × |
| X 锁 | × | × | × |
| I 锁 | × | × | √ |
# 2.3 SQL 的隔离性级别 ⭐️
# 2.3.1 脏读、不可重复读、幻读
- 脏读:事务 B 去查询了事务 A 修改过的数据,但是此时事务 A 还没提交,所以事务 A 随时会回滚导致事务 B 再次查询就读不到刚才事务 A 修改的数据了,即 B 读到了一个脏数据。
- 脏写:事务 B 去修改了事务 A 修改过的值,但是此时事务 A 还没提交,所以事务 A 随时会回滚,导致事务 B 修改的值也没了。
无论是脏写还是脏读,都是因为一个事务去更新或者查询了另外一个还没提交的事务更新过的数据。因为另外一个事务还没提交,所以它随时可能会回滚,那么必然导致你更新的数据就没了,或者你之前查询到的数据就没了,这就是脏写和脏读两种场景。
- 不可重复读:事务 B 首先读取了一条数据,然后执行逻辑的时候,事务 A 将这条数据改变了,然后事务 B 再次读取的时候,发现数据无法重复读到刚刚的数据了。
- 幻读:事务 B 首先根据条件索引得到 N 条数据,然后事务 A 改变了这 N 条数据之外的 M 条或者增添了 M 条符合事务A搜索条件的数据,导致事务 B 再次搜索发现有 N+M 条数据了,就产生了幻读。
对幻读的一个举例:第一个事务对一个表的所有数据进行修改,同时第二个事务向表中插入一条新数据。那么操作第一个事务的用户就发现表中还有没有修改的数据行, 就像发生了幻觉一样。解决幻读的方法是增加范围锁或者表锁。
# 2.3.2 四种隔离性级别
🖊 0 级协议(0-LP),对应读未提交(read uncommitted):事务中的修改,即使没有提交,其他事务也可以看得到,会导致“脏读”、“幻读”和“不可重复读取”。

- 有写要求的数据对象A加排他锁,不再访问后即刻解锁。可防止丢失修改,但允许脏读,允许重复读错误。
🖊 1 级协议(1-LP),对应读已提交(read committed):保证了一个事务不会读到另一个并行事务已修改但未提交的数据,避免了“脏读取”,但不能避免“幻读”和“不可重复读取”。该级别适用于大多数系统。

- 有写要求的数据对象 A 加排他锁,事务提交时刻解锁。可防止丢失修改,可恢复,防止脏读,允许重复读错误
🖊 2 级协议(2-LP),对应可重复读(repeatable read):保证了一个事务不会修改已经由另一个事务读取但未提交(回滚)的数据。避免了“脏读取”和“不可重复读取”的情况,但不能避免“幻读”,但是带来了更多的性能损失。
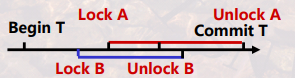
- 有写要求的数据对象 A 加排他锁,事务提交时刻解锁。有读要求的数据对象 B 加共享锁,不再访问后即刻解锁。可防止丢失修改,防止脏读,不允许重复读错误。
🖊 3 级协议(3-LP),对应可重复读(serializable):最严格的级别,事务串行执行,资源消耗最大。
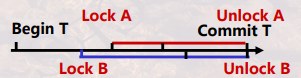
- 有写要求的数据对象 A 加排他锁,事务提交时刻解锁。有读要求的数据对象 B 加共享锁,事务提交时刻解锁。防止所有不一 致性。 (如幻读---可查阅资料理解之)。
# 2.4 封锁粒度
封锁对象的大小称为封锁粒度。
粒度单位::属性值 -> 元组 -> 元组集合 -> 整个关系 -> 整个 DB 某索引项 -> 整个索引。
- 由前往后: 并发度小,封锁开销小。
# 2.5 两段锁协议
// TODO