 基于深度神经网络的聚类算法
基于深度神经网络的聚类算法
参考视频:第40期:基于深度神经网络的聚类算法 —— 郭西风 (opens new window)
更多资料:
# 1. Background
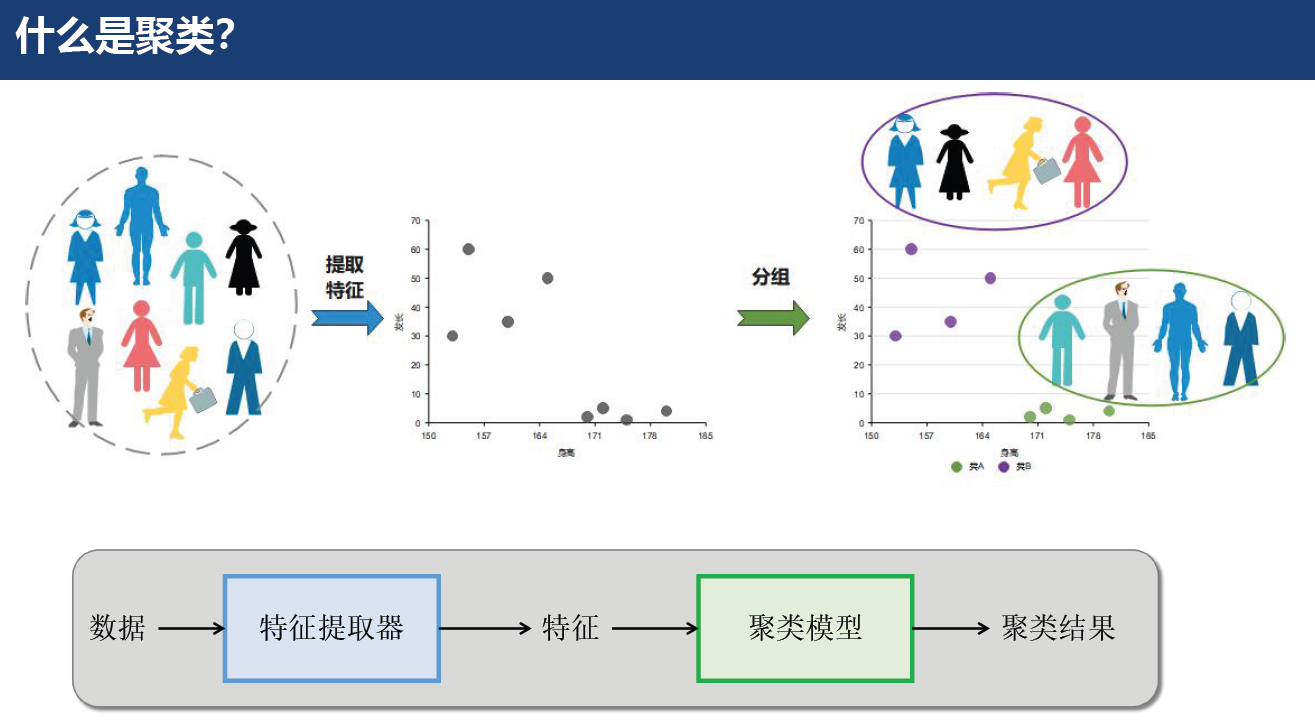
# 1.1 什么是聚类?
物以类聚,人以群分:
# 1.2 什么是深度聚类?
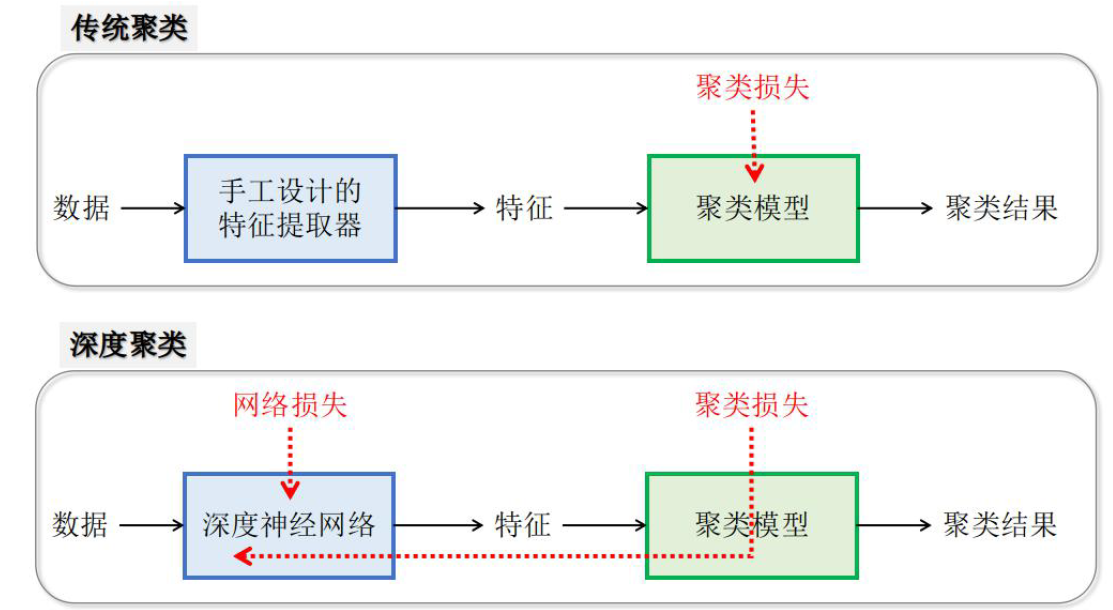
- 传统聚类存在的问题主要是,这种手工设计的 feature extractor 得到的 feature 并不一定是好的 feature,而且 extractor 与聚类模型也没有交互
- 深度聚类在提取 feature 的时候就已经会考虑 clustering 的目的,两个过程会相互促进,从而达到好的效果。
因此深度聚类的核心思想:学习到的高质量的特征有助于提升聚类算法的性能,而聚类结果反过来可以引导神经网络学习更好的特征。其流程与有监督深度学习类似,都是同时完成特征学习任务和后续任务(分类、回归)。
深度聚类的一般范式:网络损失与聚类损失的组合

# 1.3 从两个视角来看 Deep Clustering
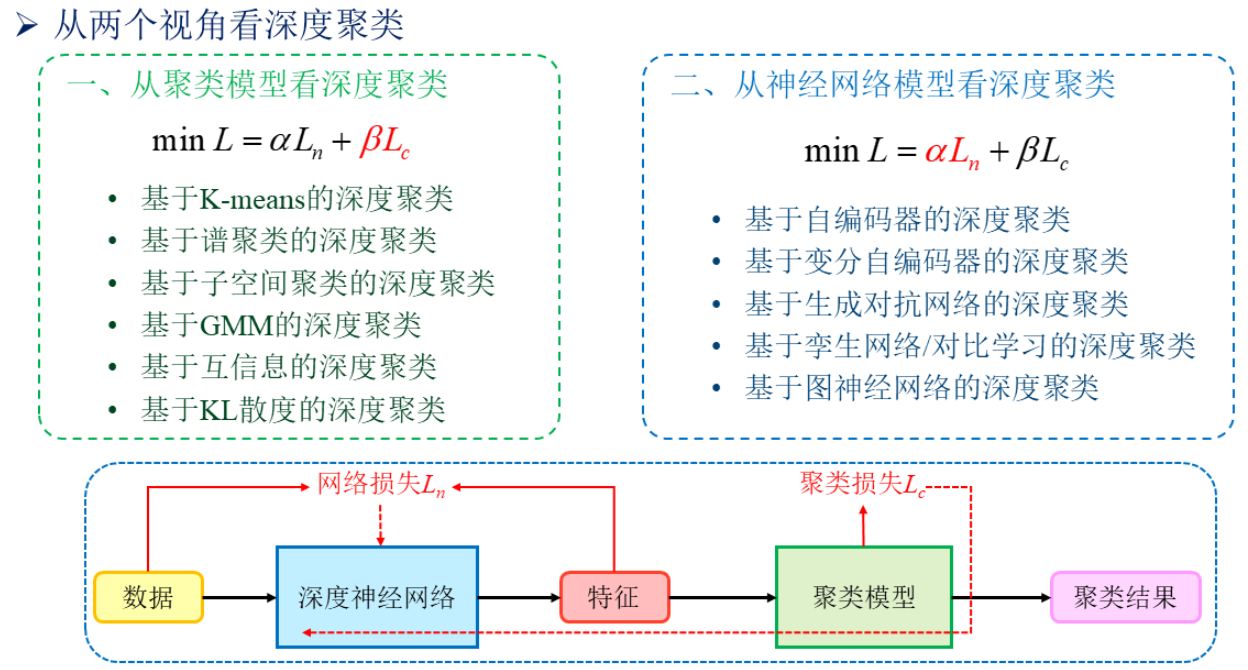
# 2. 从聚类模型看 Deep Clustering
# 2.1 基于 K-Means 的 Deep Clustering
先看一下 K-Means 是怎么做的:
review: K-Means
给定 n 个样本 x 和 K 个初始化的聚类中心
其中,
- 这里的损失其实就是每个样本距离它最近聚类中心的距离的累加
- K-means 所要优化的是聚类的中心
这种方式存在的一个问题是,x 是一个样本 feature,如果 x 在它所在的 feature space 中不容易被区分,那整体的聚类效果将不太好。所以一个想法是如果 x 经过某种变换,变换到一个新的空间里面,如果在新的 space 里面比较容易做 clustering,那效果就会不错,而基于神经网络的 deep clustering 其实就是这种思路,这种 feature space 的变换就交给了神经网络。
用
这里需要使用 loss 同时对
但由于神经网络的映射能力特别强,直接最小化这个 loss function 有可能得到退化解:神经网络
因此需要加入额外约束消除退化解,比如加入网络损失
优缺点:
- 优点:简单直观,与单独使用 KMeans 相比聚类性能有较大幅度提升。
- 缺点:继承了 KMeans 受初始化影响大、不能处理簇形状非凸的数据、无法得到全局最优解等
参考文献:
[1] YANG B, et al. Towards kmeansfriendly spaces: Simultaneous deep learning and clustering[C]//ICML. 2017: 3861-3870. [2] TIAN K, et al. Deepcluster: A general clustering framework based on deep learning[C]//ECML/PKDD. 2017: 809-825. [3] ALQAHTANI A, et al. A deep convolutional autoencoder with embedded clustering[C]//ICIP. 2018: 4058-4062. [4] MA Q, et al. Learning representations for time series clustering[C]//NeurIPS. 2019: 3776-3786. [5] CARON M, et al. Deep clustering for unsupervised learning of visual features[C]//ECCV. 2018: 139-156.
# 2.2 基于谱聚类的深度聚类
review 一下 spectral clustering,它把聚类的过程转换成了一个图分割的问题。
Spectral Clustering
给定样本集 x 和聚类个数 K 后,先根据样本之间的距离构建相似性矩阵 A,然后通过最小化下列损失 函数求解谱嵌入特征 Z:
其中
扩展到 deep clustering 也很自然,谱聚类并没有显式求出样本
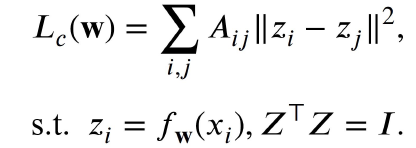
它的核心思想就是:用神经网络来显式地刻画样本 x 到它谱空间的嵌入。
当然它也存在不少问题:
- 性能受限于相似性矩阵 A 的质量,Yang等[1]使用自编码器的嵌入层特征作为 SpectralNet[2] 输入。
- Huang等[3]将 SpectralNet 扩展到多视图场景。
- Yang等[4]扩展了谱嵌入的方式,由原来的最小化在嵌入空间的欧式距离变为最小化样本之间的 后验概率分布
但是以上的改进的核心思想仍然不变。
优缺点:
- 优点:通过显式求解特征映射,可以使用批量训练的策略,提高向大规模数据的可扩展性。同时与基于 K-Means 的深度聚类算法相比,能充分利用数据的拓扑结构,实现对非凸数据的聚类。
- 缺点:显式求解的特征映射不能保证是全局最优的。使用同样的相似性矩阵 A,性能更差。
参考文献:
[1] YANG X, et al. Deep spectral clustering using dual autoencoder network[C]//CVPR. 2019:4066-4075. [2] SHAHAM U, et al. Spectralnet: Spectral clustering using deep neural networks[C]//ICLR. 2018. [3] HUANG S, et al. Multi-spectralnet: Spectral clustering using deep neural network for multiview data[J]. IEEE Transactions on Computational Social Systems, 2019, 6:749-760. [4] YANG L, et al. Deep clustering by gaussian mixture variational autoencoders with graph embedding[C]//ICCV. 2019:6439-6448.
# 2.3 基于子空间聚类的深度聚类
// TODO