 批处理系统
批处理系统
带有太强个人色彩的系统难以大获成功。一旦最初设计基本完成且足够鲁棒时,由于经验迥然、观点各异的人的加入,真正的测试才刚刚开始。
—— Donald Knuth
本书前面主要讨论的是“请求应答”风格的数据处理,由于 Web 服务和日期增长的基于 HTTP/REST 的 API,让请求/应答风格的交互如此普遍。但这并非是唯一的系统构建方式。我们对下面三种类型的系统进行考察:
- 服务(在线系统,online systems):server 接收 client 发来的请求,并试图尽快处理然后应答。响应时间通常是衡量一个服务性能的最主要指标,且可用性通常很重要。
- 批处理系统(离线系统,offline systems):一个批处理系统接收大量数据作为输入,然后在这批数据上跑 job,进而产生一些数据作为输出。吞吐量(throughput,处理单位数据量所耗费的时间)通常是衡量批处理任务最主要指标。
- 流式系统(近实时系统,near-real-time systems):流式处理介于在线处理和离线处理(批处理)之间。流式任务通常会在事件产生不久后就对其进行处理,与之相对,一个批处理任务通常会攒够一定尺寸的输入数据才会进行处理。这种区别让流式处理系统比同样功能的批处理系统具有更低的延迟。
批处理是我们寻求构建可靠的、可扩展的、可维护的应用的重要组成部分。例如 MapReduce,一个发表于 2004 年的批处理算法,使得“谷歌具有超乎寻常可扩展能力”。该算法随后被多个开源数据系统所实现,包括 Hadoop,CounchDB 和 MongoDB。
本章将会介绍 MapReduce 和其他几种批处理算法和框架,并探讨下他们如何用于现代数据系统中。作为引入,首先会看下标准 Unix 工具如何用于数据处理,进而将这些哲学和经验运用到大规模、异构的分布式数据系统中。
# 1. 使用 Unix 工具进行批处理
从一个简单的例子开始。设你有一个 web 服务器,并且当有请求进来时,服务器就会向日志文件中追加一行日志:
216.58.210.78 - - [27/Feb/2015:17:55:11 +0000] "GET /css/typography.css HTTP/1.1"
200 3377 "http://martin.kleppmann.com/" "Mozilla/5.0 (Macintosh; Intel Mac OS X
10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.115
Safari/537.36"
2
3
4
注:上面文本其实是一行,只是为了阅读性,拆成了多行。
这行日志信息量很大。为了便于理解,你可能首先需要了解其格式:
$remote_addr - $remote_user [$time_local] "$request"
$status $body_bytes_sent "$http_referer" "$http_user_agent"
2
# 1.1 简单的日志分析
这里我们只使用基本的 Unix 命令来做一个工具:获取网站上访问频次最高的五个页面。在 Unix Shell 中输入如下:
cat /var/log/nginx/access.log | #(1)
awk '{print $7}' | #(2)
sort | #(3)
uniq -c | #(4)
sort -r -n | #(5)
head -n 5 #(6)
2
3
4
5
6
每一行作用如下:
- 读取给定日志文件
- 将每一行按空格分成多个字段,然后取出第七个,即我们关心的 URL 字段。在上面的例子中,即:
/css/typography.css - 按字符序对所有 url 进行排序。如果某个 url 出现了 n 次,则排序后他们会连着出现 n 次。
uniq命令会将输入中相邻的重复行过滤掉。-c选项告诉命令输出一个计数:对于每个 URL,输出其重复的次数。- 第二个
sort命令会按每行起始数字进行排序(-n),即按请求次数多少进行排序。-r的意思是按出现次数降序排序,不加该参数默认是升序的。 - 最后,
head命令会只输出前 5 行,丢弃其他多余输入。
对日志文件执行这一系列命令,会得到类似如下结果:
4189 /favicon.ico
3631 /2013/05/24/improving-security-of-ssh-private-keys.html
2124 /2012/12/05/schema-evolution-in-avro-protocol-buffers-thrift.html
1369 /
915 /css/typography.css
2
3
4
5
如果你熟悉 Unix 工具链,会发现他们非常强大,这个组合可以在数秒内处理上 G 的日志文件。
本书中没有余力去详细讨论所有 Unix 工具使用细节,但他们都很值得一学。你可以在短短几分钟内,通过灵活组合 awk, sed, grep, sort, uniq, 和 xargs 等命令,应对很多数据分析需求,并且性能都相当不错。
# 1.2 链式命令 vs 专用程序
除了链式组合 Unix 命令,你也可以写一个简单的小程序来达到同样的目的。如,使用 Ruby,会有类似如下代码:
counts = Hash.new(0) # (1)
File.open('/var/log/nginx/access.log') do |file|
file.each do |line|
url = line.split[6] # (2)
counts[url] += 1 # (3)
end
end
top5 = counts.map{|url, count| [count, url] }.sort.reverse[0...5] # (4)
top5.each{|count, url| puts "#{count} #{url}" } # (5)
2
3
4
5
6
7
8
9
10
11
标号对应代码功能如下:
counts是一个哈希表,为每个出现过的 URL 保存一个计数器,计数器初始值为 0。- 对于每行日志,提取第六个字段作为 URL( ruby 的数组下标从 0 开始)。
- 对当前行包含的 URL 的计数器增加 1 。
- 对哈希表中的 URL 按计数值降序排序,取前五个结果。
- 打印这五个结果。
该程序虽不如使用 Unix 管道组合的命令行简洁,但可读性也很好,喜欢使用哪种方式是一个偏好问题。然而,两者上除了表面上的语法区别,在执行流程上差别也很大。在你分析海量数据时,这一点变的尤为明显。
# 1.3 排序 vs 内存聚合
Ruby 脚本在内存中保存了 URL 的哈希表,记录每个 URL 到其出现次数的映射。Unix 管道例子中并没有这样一个哈希表。作为替代,它将所有 URL 进行排序,从而让所有相同的 URL 聚集到一块,从而对 URL 出现次数进行统计。
那种方法更好一些呢?这取决于你有多少个不同的 URL:
- 如果工作集足够小,则基于内存的哈希表能够很好地工作——即使在笔记本电脑上。
- 但如果任务的工作集大于可用内存,则排序方式更有优势,因为能够充分利用磁盘空间。因为可以使用磁盘上的归并排序。
GNU 核心工具包中的 sort 命令,会自动的处理超过内存大小的数据集,将一些数据外溢(spill)到磁盘上;此外,该工具还可以充分利用多核 CPU 进行并发地排序。这意味着,我们之前例子中的对日志处理的 Unix 命令行能够轻松应对大数据集,而不会耗尽内存(OOM)。不过,性能瓶颈会转移到从磁盘读取输入文件的 IO 上。
# 1.4 Unix 哲学
我们能够通过简单的组合 Unix 工具来进行复杂的日志文件处理并非巧合:这正是 Unix 的核心设计思想之一,且该思想在今天也仍然非常重要。让我来深入的探究一下其背后哲学,以看看有什么可以借鉴的。
Doug McIlroy,Unix 管道(pipe)的发明人,在 1964 年是这样描述管道的:“我们需要一种像软管一样可以将不同程序连接到一块的方法——当数据准备好以其他方式处理时,只需要接上就行。 IO 也应该以这种方式工作”。管道的类比到今天仍然存在,并且成了 Unix 哲学的一部分。Unix 哲学是一组在 Unix 用户和开发者中很流行的设计原则,在 1978 年被表述为:
- 每一个程序专注干一件小事。在想做一个新任务时,新造一个轮子,而非向已有的程序中增加新的“功能”。
- 每个程序的输出成为其他程序(即便下一个程序还没有确定)的输入。不要在输出中混入无关信息(比如在数据中混入日志信息),避免使用严格的列式数据(数据要面向行,以行为最小粒度?)或者二进制数据格式。不要使用交互式输入。
- 尽快的设计和构建软件,即便复杂如操作系统,也最好在几周内完成(译注:这里翻译稍微有些歧义,即到底是尽快迭代还是尽早让用户试用,当然他们最终思想差不多,即构造最小可用模型,试用-迭代)。对于丑陋部分,不要犹豫,立即推倒重构。
- 优先使用工具来减轻编程任务,即使你不得不额外花费时间去构建工具,并且预期在使用完成后会将其中一些工具扔掉。
这些手段——尽可能自动化、快速原型验证、小步增量迭代、易于实验测试,将大型工程拆解成一组易于管理的模块——听起来非常像今天的敏捷开发和 DevOps 运动。令人惊讶的是,很多软件工程的核心思想在四十年间并没有太多变化。
Unix 中的 sort 工具是一个程序只干好一个事情的非常典型的案例。相对大多数编程语言的标准库函数(即使在能明显提升性能时,也不能利用磁盘空间、不能利用多核性能),它给出了一个更好的实现。不过,单独使用 sort 威力还不是那么大。只有在与其他 Unix 工具(如 uniq)组合时,sort 才会变的相当强大。
使用 Unix Shell 如 bash 让我们能够轻易的将这些工具组合以应对数据处理任务。即使大部分的工具都是由不同人编写的,也可以很容易的组合到一块。我们不禁会问,Unix 做了什么让其有如此强的组合能力?
# 1.4.1 统一的接口
如果你希望一个程序的输出可以作为其他程序的输入,就意味着这些程序需要使用同样的数据格式,也就是这些程序需要同样的输入输出接口。
在 Unix 中,这种接口是文件(更准确来说是 file descriptor)。其本质上是一种有序的字节序列。这种接口是如此简约,以至于很多不同的实体都可以共用该接口:文件系统中真实的文件、与其他程序的通信渠道(Unix socket,标准输入 stdin,标准输出 stdout)、设备驱动(如 /dev/audio 或者 /dev/lp0)、以 socket 表示的 TCP 连接等等。现在回过头去看,在当时能让这么多不同的东西使用统一的接口是一种非常了不起的设计,唯其如此,这些不同的东西才能进行任意可插拔的组合。
另外一个非常成功的接口设计是:URL 和 HTTP,互联网的基石。一个 URL 能够唯一的定位网络中的一个资源。
通常来说,大部分(并不是所有)的 Unix 程序将这些字节序列看做是 ASCII 文本。大部分程序将其输入文件视为由 \n 分隔的一系列记录。但相对来说,大部分程序对于每一行记录的解析却是相对模糊和非统一的。Unix 工具通常使用空格或者 tab 作为分隔符将一行分解成多个字段,但有时也会用 CSV(逗号分割)、管道分割等其他编码。
尽管很多设计并不完美,在数十年后的今天,Unix 统一的接口设计仍然堪称伟大。没有多少软件模块可以像 Unix 工具这样进行任意交互和组合。
即使两个数据库的数据具有相同的数据模型(Schema),也很难快速的将数据在两个数据库间导来导去。多个系统间缺少有效整合使得数据变得巴尔干化 (opens new window)(一种相对贬义的地缘政治学术语,指较大国家分裂成互相敌对的一系列小国的过程)。
# 1.4.2 逻辑和接线(数据流组织)分离
Unix 工具的另外一个显著特征是其对于标准输入(stdin)和标准输出(stdout)的使用。管道(pipe)能让你将一个程序的标准输出(即编码实现该程序时,程序视角的 stdout)重定向到另外一个程序的标准输入(仅需要一个比较小的缓冲区足矣,并不需要将所有的中间数据流写入磁盘)。
程序在需要时当然可以直接读写文件,但若不关心具体的文件路径,而仅面向标准输入和标准输出进行编程,可以在 Unix 环境下和其他工具进行更好地协同。这种设定,让 shell 用户可以按任意方式对多个程序的输入输出进行组织(也即接线,wire up);每个程序既不需要关心输入来自何处,也不需要知道输出去往何方(我们有时也将这种设计称为松耦合,延迟绑定或者控制反转)。将程序逻辑和数据流组织分离,能让我们轻松地组合小工具,形成复杂的大系统。只要你的工具是从 stdin 读取数据,并将处理结果写入到 stdout,就能作为一环嵌入到 Unix 的数据处理流水线中。
不过,只是用 stdin 和 stdout 编程是有很多限制的。比如难以让程序使用多个输入或者产生多个输出。
# 1.4.3 透明性和实验性
Unix 工具生态如此成功的另外一个原因是,可以很方便让用户查看系统运行的状态:
- Unix 命令的输入文件通常被当做是不可变的。这意味着,你可以使用不同命令行参数,针对同样的输入跑很多次,而不用担心会损坏输入文件。
- 你可以在多个命令组成的处理流水线的任意环节停下来,将该环节的输出打到
less工具中,以查看输出格式是否满足预期。这种可以对运行环节随意切片查看运行状态的能力对调试非常友好。 - 你可以将一个流水线环节的输出写入到文件中,并将该文件作为流水线下一个环节的输入。这样即使你中断了流水线的执行,之后想重启时就不用重新跑流水线所有环节。
因此,虽然相比关系型数据库中的查询优化,Unix 工具非常粗陋、简单,但却非常好用,尤其是在做简单的实验场景下。
然而,Unix 工具最大的局限在于只能运行在单机上——这也是大数据时代人们引入 Hadoop 的进行数据处理的原因——单机尺度已经无法处理如此巨量的数据。
# 2. MapReduce 和分布式文件系统
MapReduce 看起来简单粗暴,但非常强大。
一个 MapReduce 任务就像一个 Unix 进程:接受一到多个输入,产生一到多个输出,且不会修改输入文件,除了产生输出外没有其他副作用。输出文件都是单次写入、顺序追加而成,一旦文件写完,就不会再有任何改动。
MapReduce 任务的输入和输出都是分布式文件系统上的文件,在 Hadoop 实现中就是 HDFS。
除了 HDFS 外,市面上还有很多其他的分布式文件系统,如 GlusterFS 和 QFS(Quantcast File System)。对象存储,如 Amazon S3,Azure Blob Storage 和 OpenStack Swift 也有诸多相似之处。本章我们主要以 HDFS 为例,但这些原则也适用于其他分布式文件系统。
HDFS 和对象存储不同点之一是,HDFS 能够将计算就近的调度到存储所在的机器上(调度亲和性,本质原因在于计算和存储在同一个集群,有好处也有劣势),但对象存储会将存储和计算分离。如果网络带宽是瓶颈,从本地进行文件读取要在性能上更优。需要注意的是,如果使用 EC 编码,这些局部性就会丧失,因为所有的读取都打散到多台机器上,然后还原出原始数据。
HDFS 的基本设计理念是 shared-nothing(机器间不共享任何特殊硬件,纯通过网络来通信)架构。这种架构不要求任何专用硬件,只要一组使用常规数据中心网络串联起来的主机即可。
HDFS 运行原理:HDFS 由一组运行在每个主机上的守护进程(Daemon Process)组成,对外暴露网络接口,以使其他的节点可以访问存储于本机的数据文件(假设数据中心中的通用机器节点上都附有一定数量的磁盘)。一个叫做 NameNode 的中心节点会保存文件块和其所在机器的映射(也即文件块的 placement 信息)。因此,HDFS 可以利用所有运行有守护进程的机器上(DataNode)存储空间,在逻辑上对外提供单一且巨大的文件系统抽象。
当然现代大型数据中心的机型有一个专用化趋势,比如面向存储的机型,每个机器会挂很多硬盘,但计算能力较弱;比如面向 AI 的机型,会集成很多 GPU 。
为了容忍机器和磁盘的故障,所有的文件块(file blocks)都会在多机上进行冗余。冗余策略有两种主要流派:
- 多副本:在多机上存储同样数据的多个副本。
- 冗余编码:使用纠删码(erasure coding,如里索码,Reed-Solomon codes )的方式以更小的存储放大的方法对一份数据进行冗余。
后者类似于在单机多盘上提供数据冗余的 RAID(磁盘冗余阵列);不同之处在于,在 HDFS 这类分布式文件系统中,文件访问和数据冗余仅通过普通网络连接,而无需专用硬件的支持。
HDFS 能够很好地进行扩容:在本书写作时(2017 年),最大的 HDFS 集群运行在了数千台机器上,具有上 PB 的容量。这种尺度的数据存储服务的商业落地,得益于使用了开源软件,且廉价硬件的成本要远低于提供同等容量的专用硬件解决方案。
# 2.1 MapReduce 任务执行
MapReduce 是一个编程框架,你可以基于 MapReduce 编写代码以处理存储在分布式文件系统(如 HDFS)上的超大数据集。
MapReduce 的任务执行流程:
- HDFS 中的数据集被切分成一个个 record
- 每个 record 经过 Mapper 被抽取为多个 KV pair
- 相同 key 的 KV pair 经过排序被聚集到一起形成一堆 pairs,以迭代器的形式传给 Reducer
- 每次 Reducer 会生成一组 records 放入 HDFS 中
因此,为了创建 MapReduce 任务,你需要实现两个回调函数:mapper 和 reducer,其行为如下:
- Mapper:对于每个输入 record 都会调用一次 mapper 函数,其任务是从记录中抽取 key 和 value。对于每一个输入记录,都有可能产生任意数量(包括 0 个)的 kv 对。框架不会保存任何跨记录的状态,因此每个记录都可以独立的被处理(即 mapper 可以进行任意并发的运行)。
- Reducer:MapReduce 框架会拿到 mapper 输出的 kv 对,通过排序将具有相同 key 的 value 聚集到一块,以迭代器的形式给到 reducer 函数。reducer 会继续输出一组新的记录(如 URL 的出现频次)。
两个 MapReduce 任务可以连接起来,也就是让第一个 MapReduce 的输出作为第二个 MapReduce 的输入。
# 2.1.1 MapReduce 的分布式执行
与 Unix 工具流水线的相比,MapReduce 的最大区别在于可以在多台机器上进行分布式的执行,但并不需要用户显式地写处理并行的代码。mapper 和 reducer 函数每次只处理一个记录;他们不必关心输入从哪里来,输出要到哪里去,框架会处理分布式系统所带来的的复杂度(如在机器间移动数据的)。
mapper 和 reducer 通常是用通用编程语言来实现。在 Hadoop MapReduce 中,mapper 和 reducer 是需要实现特定接口的 Java class。在 MongoDB 和 CouchDB 中,mapper 和 reducer 是 JavaScript 函数。
图 10-1 中展示了 Hadoop MapReduce 任务中的数据流。其并行是基于分片的的:任务的输入通常是 HDFS 中的一个文件夹,输入文件夹中的每个文件或者文件块是一个可被 Map 子任务(task)处理的分片。
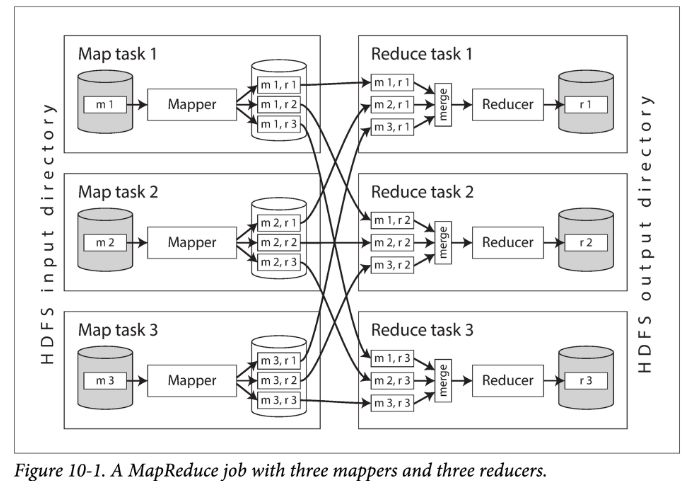
每个输入文件通常有数百 M,每个输入通常有多个副本,分散在多个机器上。MapReduce 的调度器(图中没有显示)在调度时,会在这多个副本所在机器上选择一个具有足够内存和 CPU 资源运行该 mapper 任务的机器,将 map 任务调度过去。这个策略也被称为:将计算调度到数据上。从而省去在网络中拷贝数据的环节,提高了局部性,减少了网络带宽消耗。
多数情况下,应用层的代码通常不会存在于 map 任务调度到的机器上。因此,MapReduce 框架首先会将用户代码(如 jar 包)序列化后复制过去。然后在对应机器上,动态加载这些代码,继而执行 map 任务。读取输入文件,逐个解析数据记录(record),传给 mapper 回调函数执行。每个 mapper 会产生一组 KV pairs。
reduce 侧的计算也是分片的。对于 MapReduce 任务来说:
- map 任务的数量,取决于该任务的输入文件数(或者文件 block 数)的数量;
- reduce 任务的多少,可以由用户显式的配置(可以不同于 map 任务的数量)。
为了保证所有具有相同 key 的 KV 对被同一个 reducer 函数处理,框架会使用哈希函数,将所有 mapper 的输出的 kv 对进行分桶(桶的数量就是 reducer 的数量),进而路由到对应的 reducer 函数。
根据 MapReduce 的设定,reducer 接受的 kv 对需要是有序的,但任何传统的排序算法都无法在单机上对如此大尺度的数据进行排序。为了解决这个问题,mapper 和 reducer 间的排序被分成多个阶段。
- 首先,每个 map 任务在输出时,会先将所有输出哈希后分片(一个分片对应一个 reducer),然后在每个分片内对输出进行排序。由于每个分片的数据量仍然可能很大,因此使用外部排序算法。
- 当某个 mapper 任务读取结束,并将输出排好了序,MapReduce 调度器就会通知所有 reducers 来该 mapper 机器上拉取各自对应的输出。最终,每个 reducer 会去所有 mapper 上拉取一遍其对应分片数据数据。这里有个推还是拉的设计权衡,拉的好处在于 reducuer 失败后,可以很方便地进行重试,再次拉取计算即可。
这个分片-排序-复制的过程也被称为 shuffle。注意,虽然叫做 shuffle,但这个过程并没有随机性,都是确定的。最终,不同 mapper 产生的具有相同 key 的记录就会被聚集到一块。
总结来说,map 和 reduce 间的排序分为两个阶段:
- 在每个 mapper 上对输出分片后各自排序。
- 在每个 reducer 上对输入(有序文件)进行归并排序。
reducer 在调用时会传入一个 key 一个 Iterator(迭代器),使用该迭代器能够访问所有具有相同 key 的记录(极端情况下,内存可能放不下这些记录,因此是给一个迭代器,而非内存数组)。reducer 函数可以使用任意的逻辑对这些记录进行处理,并可以产生任意数量的输出。这些输出最终会被写到分布式文件系统中的文件里(通常该输出文件会在 reducer 机器上放一个副本,在另外一些机器上放其他副本)。
# 2.1.2 MapReduce 工作流
很多时候我们需要将多个 MapReduce 任务首尾相接串成工作流(workflow)。但 Hadoop MapReduce 框架本身并没有任何关于工作流的支持,因此通常依赖文件名进行隐式的链式调用:
- 第一个 MapReduce 任务将其输出写入特定的文件夹。
- 第二个 MapReduce 任务读取这些文件夹中文件作为输入。
这种链式调用的方式不太想 pipeline,而是“对中间结果进行物化”的一种解决方案,之后会对其讨论。
MapReduce 中仅当一个任务完全成功的执行后,其输出才被认为是有效的(也即,MapReduce 任务会丢掉失败任务的不完整输出)。因此,workflow 的任务只有在前一个任务结束后才能启动下一个。为了处理多个任务之间执行的依赖关系(比如 DAG 依赖),人们开发了很多针对 Hadoop 的工作流调度框架,如 Oozie,Azkaban,Luigi,Airflow 和 Pinball。
在需要调度的任务非常多时,这些工作流管理框架非常有用。在构建推荐系统时,一个包含 50 到 100 个 MapReduce 的工作流非常常见。此外,在大型组织中,不同团队的任务相互依赖非常常见。在这些复杂的工作流场景中,借助工具十分必要。很多基于 Hadoop 的高维工具:如 Pig,Hive,Cascading,Crunch 和 FlumeJava,也会对一组 MapReduce 任务,按照合适的数据流走向,进行自动地组合。
# 2.2 Reduce 侧的 Join 和 Group
在很多场景中,一个 record 与其他 records 有关联(association)是一个很常见的现象:关系模型中的 foreign key,文档模型中的 document reference,图模型中的 edge。当需要访问具有 association 的 records 时,就需要 Join。
在数据库中通常会利用多个索引来实现 join,但 MapReduce 中并没有索引的概念,当一个 MapReduce 拿到一个任务时,它会进行整个数据集的全盘扫描,这个操作是很重的。但其实在 OLAP 查询中,针对一个非常大的数据集进行聚集性运算非常常见,在这种场景下,全盘扫描所有的输入还算是说的过去,尤其是你能在多机并行地进行处理。
本书中讨论的 join 多是最常见的 join 类型——等值 join(equal-joins),即有关联的两个记录在某个列(如 ID)上具有相同的值。有些数据库支持更一般化的 Join,如外连接,左外连接,右外连接,这里不展开讨论了。
当在批处理的上下文中讨论 Join 时,我们是想找到所有相关联的记录,而不仅仅是某一些记录。比如,我们会假定一个任务会同时针对所有用户进行处理,而不是仅仅查找某个特定用户的数据(特定用户的话,使用索引肯定更为高效)。
以下面这个例子为例,如果一个任务需要协同处理 user activity 和 user info,那就需要同时对两个表进行 Join:
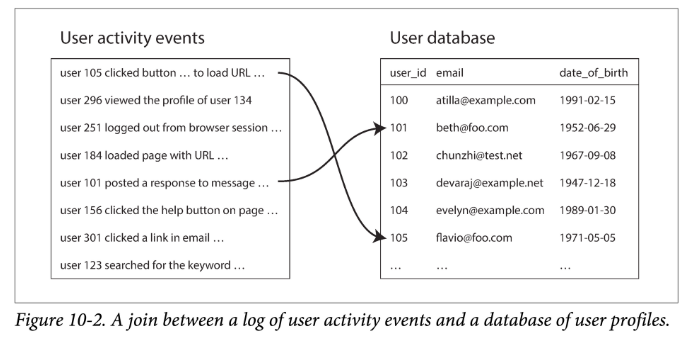
最简单的方法:对activity event 中一个事件所包含的 user ID,都去 user database 中(存在远程服务器上)进行一次查询。这种方法虽然可行,但性能极差:
- 不做任何优化,则数据处理带宽会受制于与用户数据库通信开销
- 如果使用缓存,本地缓存的有效性受制于行为事件数据中用户 ID 的分布
- 如果使用并发,则大量的并发查询很可能把数据库打垮
在批处理中为了获取足够好的性能,需要把计算尽可能的限制在机器本地。如果对于某个待处理记录,都要进行随机的网络访问,性能将会非常差。此外,不断的查询远程数据库也会导致数据库处理的不确定性,毕竟在你的多次查询间,数据库的数据可能会发生变化。
因此,一个更好的方式是将所需数据库数据的一个副本通过 ETL 拿到用户行为数据所在的分布式文件系统。于是,用户资料在 HDFS 中的一些文件中,用户行文在 HDFS 的另外一些文件中,此时就可以使用 MapReduce 任务来关联两者,进行分析。
下面讲实现 Join 的方法,这一节所讲的都是在 reduce 阶段真正执行 join 逻辑,因此也被称为 Reduce 侧的 Join。
# 2.2.1 基于排序-合并的 Join
mapper 的职责是 record -> KV pairs,对于上面的例子,key 就是 userId,然后我们使用一种 mapper 从 activity events 中提取 userId 和 event 作为 KV,另一种 mapper 从 user database 中提取 userId 和 userInfo 作为 KV。这两个 mapper 同属于一个 MapReduce 任务,如下图:
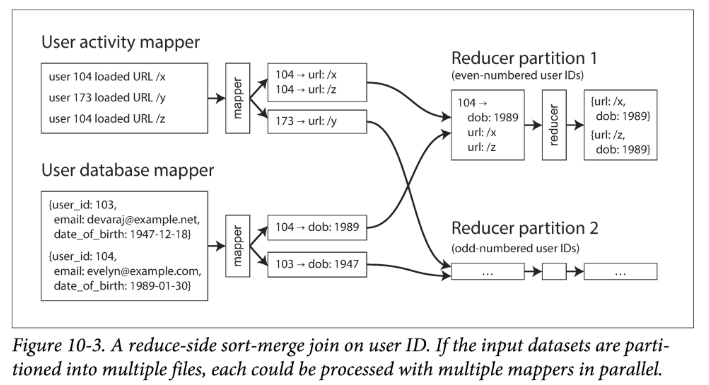
当这个任务经过 shuffle 后,具有同样 userId 的 KV pairs 就被聚集到了一块传给 reducer,这些 pairs 中有 activity event,也有 userInfo。MapReduce 任务可以使用二级排序技术将这些 pairs 进行再组织,以使 reducer 先看到一个 userId 的 userInfo,再看到他的 activity events。
基于此,reducer 可以轻松地进行 Join:reducer 函数会在每一个用户 ID 上进行调用,由于使用了二级排序,reducer 会先看到该用户的 userInfo。在 reducer 实现中,可以先将 userInfo 保存到局部变量里,然后对他的所有 activity events 进行迭代,提取出相关信息,输出 <viewed-url, viewed-age> 的 KV pairs。之后再接一个 MapReduce 任务,对每个 url 访问的 user age 进行统计。
由于 reducer 会在单个函数里处理所有同一个 userId 的记录,因此一次只需要在内存中保存一个用户的 userInfo,并且不用进行任何网络请求。上面讲的这种算法也被称为基于排序和归并的 Join(sort-merge join)。
# 2.2.2 将相关数据聚到一块
在排序-归并 join 中,mapper 和排序过程确保会将同一个 userId 的所有用于 join 的必要数据都放到一起交给一次 reducer 中。预先让所有相关数据聚集到一起,可以让 reducer 逻辑非常简单,并且可以仅使用单个线程,就能进行高吞吐、低耗存地执行。这就是“将相关数据聚到一块”(bring related data to the same place)的经典模式。
MapReduce 的编程模型,可以将计算的物理拓扑与应用逻辑解耦开来,让应用层免于关心“部分失败”和“重试”等细节。
# 2.2.3 Group By
除了 Join,另一种“将相关数据聚到一块”的用法是:Group By:首先按照 key 将 records 分组,然后对这些分组分别执行 aggregation 操作。
aggregation 操作举例:
- 统计每个分组中的记录数(对应 SQL 中的
COUNT(*))- 将某个 field 进行累加(对应 SQL 中的
SUM(fieldname))- 根据排序函数排序后取前 k 个记录
使用 MapReduce 实现 Group By 语义,最简单的方法是在 mapper 中抽取 key 为待分组的 key。MapReduce 框架就会按照这些 key 将所有 mapper 的输出记录进行分区和排序,然后按 key 聚集给到 reducer。本质上,使用 MapReduce 来实现 group 和 join ,逻辑是极为相似的。
分组的另外一个使用场景是:收集某个用户会话中的所有用户活动——也称为会话化(sessionization)。例如,可以用来对比用户对于新老版本网站的分别购买意愿(A/B 测试)或者统计某些市场推广活动是否起作用。
假设你的 web 服务架设在多台服务器上,则某个特定用户的活动日志大概率会分散在不同服务器上。这时,你可以实现一个会话化的 MapReduce 程序,使用会话 cookie、用户 ID或者其他类似的 ID 作为分组 key,以将相同用户的所有活动记录聚集到一块、并将不同用户分散到多个分区进行处理。
# 2.3 处理偏斜(skew)
如果某个 key 的数据量超级大,则“将相同 key 的数据聚集到一块” 的模型将不再适用。这些数据量很大的 key 称为关键对象(linchpin objects)或者热键(hot keys)。
在单个 reducer 中处理 hot key 可能会造成严重的数据倾斜(skew)—— 即一个 reducer 处理的数据量远超其他。由于只有其所属的所有 mappers 和 reducers 执行完时,该 MapReduce 任务才算完成,该 MapReduce 之后的任何任务都需要等待最慢的 reducer (长尾任务)完成后才能启动。
如果某个 join 的输入存在热点数据,你可以借助一些算法来进行缓解。例如,Pig 中的偏斜 join(skewed join)方法会事先对所有 key 的分布进行采样,以探测是否有热点 key。然后,在执行真正的 Join 时,对于 Join 有热点 key 的这一测,mapper 会将含有热点 key 的记录发送到多个 reducer(每次随机挑选一个,相比之下,常规的 MapReduce 只会根据 key 的哈希确定性的选择一个 reducer);对于 Join 的另一侧输入,所有包含热点 key 的相关记录需要每个给每个具有该 key 的 reducer 都发一份。
该技术将处理热点 key 的工作分摊到多个 reducer 上,从而可以让其更好的并行,当然代价就是需要将 join 的非热点侧的数据冗余多份。Crunch 中的分片连接(shared join)也使用类似的技术,但需要显式地指定热点 key,而非通过采样来自动获取。这种技术很像我们在负载偏斜和热点消除 (opens new window)中讨论过的相关技术,在多分片数据中,使用随机分片的方法来消除热点。
Hive 的偏斜连接(skewed join)采用了另外一种方法来进行优化。Hive 要求在表的元信息中显示的指出热点 key,在收到这些 key 时会将其存到单独文件中。在对这种表进行 join 时,会使用 map 侧的 join(见下一小节)来处理热点 key。当对热点 key 进行分组聚集(group)时,可以将分组过程拆成两个阶段,即使用两个相接的 MapReduce。第一个 MapReduce 会将记录随机得发给不同的 reducer,则每个 reducer 会对热点 key 的一个子集执行分组操作,并且产生一个更为紧凑的聚合值(aggregated value,如 count,sum,max 等等)。第二个 MapReduce 操作会将第一阶段中 MapReduce 产生的同一个 key 的多个聚合值进行真正的归并。总结来说,就是第一阶段进行预分组,减小数据量;第二阶段真正的全局分组。可以想象这种方式,要求聚合操作满足交换律和结合律,比如 sum 可以,但计算 average 不行。
# 2.4 Map 侧的 Join
前面讲了 Reduce 侧的 Join,它有好有坏:
- 好处在于,你不需要对输入数据有任何的假设:不管输入数据具有怎样的属性和结构,mappers 都可以进行合适的预处理后送给 reducers 进行连接。
- 缺点在于 shuffle 过程开销很大。根据可用内存缓存大小不同,数据在流经 MapReduce 中各阶段时可能会被写入多次(写放大)。
但如果,输入数据满足某种假设,就可以利用所谓的 Map 侧连接(map-side join)进行更快的连接。这种方式利用了一种简化过的 MapReduce 任务,去掉了 reducer,从而也去掉了对 mapper 输出的排序阶段。此时,每个 mapper 只需要从分布式文件系统中的输入文件块中读取记录、处理、并将输出写回到文件系统,即可。
我们可以通过某种方式来告诉 MapReduce 框架不用做 reduce 了。
# 2.4.1 广播哈希 Join
使用 Map 侧 Join 的一个最常见的场景是:一个大数据集和一个小数据集进行 join。此种情况下,小数据集需要小到能全部装进 mapper 进程所在机器的内存。
如,设想在图 10-2 对应的场景中,userInfo 的数据足够小,能够装入内存。在这种情况下,当 mapper 启动时,可以先将 userInfo 分布式文件系统中读取到内存的哈希表中。一旦加载完毕,mapper 可以扫描所有的 user activity events,对于每一个 event,在内存哈希表中查找该事件对应 userInfo,然后 join 后,输出一条数据即可。
但仍然会有多个 mapper 任务:join 的大数据量输入侧中每个文件块一个 mapper。其中 MapReduce 任务中的每个 mapper 都会将小数据量输入侧的数据全部加载进内存。
这种简单高效的算法称为广播哈希连接(broadcast hash joins):
- 广播(broadcast):处理大数据测每个分片的 mapper 都会将小数据测数据全部载入内存。从另外一个角度理解,就是将小数据集广播到了所有相关 mapper 机器上。
- 哈希(hash):即在将小数据集在内存中组织为哈希表。
Pig(replicated join)、Hive(MapJoin)、Cascading 和 Crunch 都支持这种连接方法。
# 2.4.2 分区哈希 Join
如果待 join 的多个输入,能够以同样的方式进行分区,则每个分区在处理时可以独立地进行 join。
比如在图 10-2 的示例中,可以对 activity event 和 user database 中的数据按照 userId 的最后一位进行分片,这样 mapper-3 首先将 userId 以 3 结尾的 user info 加载到内存哈希表中,然后扫描所有 userId 以 3 结尾的 activity event 进行 Join。
如果分区方式正确,则所有需要连接的双方都会落到同一个分区内,因此每个 mapper 只需要读取一个分区就可以获取待连接双方的所有记录。这样做的好处是,每个 mapper 所需构建哈希表的数据集要小很多(毕竟被 partition 过了)。
在 Hive 中,分区哈希 Join 也被称为分桶 Map 侧 Join(bucketed map join)。
# 2.4.3 Map 侧归并 Join
map 侧连接的另一个变种是,当 map 的输入数据集不仅以相同的方式分片过了,而且每个分片是按该 key 有序的。在这种情况下,是否有足够小的、能够载入内存的输入已经无关紧要,因为 mapper 可以以类似普通 reducer 的方式对输入数据进行归并:都以 key 递增(都递减也可以,取决于输入文件中 key 的顺序)的顺序,增量式(迭代式)的读取两个输入文件,对相同的 key 进行匹配连接(比如对每个输入使用一个指针,进行滑动匹配即可)。
如果我们可以在 map 侧进行归并 join,说明前一个 MapReduce 的输入已经将文件分好了组、排好了序。原则上,在这种情况下,join 完全可以在前一个 MapReduce 的 reduce 阶段来做。然而,使用额外的一个 MapOnly 任务来做连接也是有适用场景的,比如分区且有序的文件集还可以被其他任务复用时。
# 2.4.4 使用 Map 侧 Join 的 MapReduce 工作流
当 MapReduce 连接的输出为下游任务所用时,会因为 map 侧还是 reduce 侧的不同而影响输出结构:
- 使用 reduce 侧的 join 时,输出会按照 join key 进行分区和排序;
- 使用 map 侧的 join 时,输出会和较大数据量输入侧顺序一致(不论是使用 partitioned join 还是 broadcast join,对于大数据量侧,都是一个文件块对应一个 map 子任务)。
如前所述,使用 map 侧的 join 时,会对输入数据集的尺寸、有序性和分区性有更多的要求。事先知道输入数据集在分布式文件系统上的分布对优化 join 策略至关重要:只是知道文件的编码格式和文件是否有序是不够的;你必须进一步知道输入文件的分区数量,以及文件中的数据是按哪个字段进行分区和排序的。
在 Hadoop 生态中,这些如何分区的元信息通常会在 HCatalog 和 Hive 元信息存储中维护。
# 2.5 批处理工作流的输出
我们已经串起 MapReduce 工作流的一些算法,下面讨论一个问题:当工作流结束后,处理结果是什么?
对于数据库查询场景,我们会分为 OLTP 和 OLAP 的场景。但批处理既不是事务型,也不是分析型。从数据输入量的角度来看,批处理类似于 OLAP,但 MapReduce 任务的输出却不是 OLAP 输出报表那样,它输出的是另外某种格式的数据。
# 2.5.1 构建查询索引
Google 最初发明 MapReduce 就是为搜索引擎构建索引。仔细考察构建索引的过程,有助于了解 MapReduce。
即使到今天, Hadoop MapReduce 仍不失为一个给 Lucene/Solr 构建索引的好办法。
如果你想在一个固定文档集合上构建全文倒排索引,批处理非常合适且高效:
- mapper 会将文档集合按合适的方式进行分区
- reducer 会对每个分区构建索引
- 最终将索引文件写回分布式文件系统
构建这种按文档分区(document-partitioned,与 term-partitioned 相对)的索引,可以很好地并发生成。由于使用关键词进行索引查询是一种只读操作,因此,这些索引文件一旦构建完成,就是不可变的(immutable)。
如果被索引的文档集发生变动,一种应对策略是,定期针对所有文档重跑全量索引构建工作流(workflow),并在索引构建完时使用新的索引对旧的进行整体替换。如果两次构建之间,仅有一小部分文档发生了变动,则这种方法代价实在有点高。但也有优点,索引构建过程很好理解:文档进去,索引出来。
当然,我们也可以增量式的构建索引。我们在第三章讨论过,如果你想增加、删除或者更新文档集,Lucene 就会构建新的索引片段,并且异步地将其与原有索引进行归并(merge)和压实(compact)。我们将会在第十一章就增量更新进行更深入的讨论。
# 2.5.2 以 KV 存储承接批处理的输出
批处理其他的用途还包括构建机器学习系统,如分类器和推荐系统。
这些批处理任务的输出通常在某种程度是数据库:如,一个可以通过用户 ID 来查询其可能认识的人列表的数据库,或者一个可以通过产品 ID 来查询相关产品的数据库。web 应用会查询这些数据库来处理用户请求,这些应用通常不会跟 Hadooop 生态部署在一块。那么,如何让批处理的输出写回数据库,以应对 web 应用的查询?
最直观的做法是:mapper 或 reducer 的输出直接写入数据库中,每次一个记录。但这往往并不是一个好方法:
- 吞吐不匹配:通过网络一条条写入记录的吞吐要远小于一个批处理任务的吞吐。即使数据库的客户端通常支持将多个 record 写入 batch 成一个请求,性能仍然会比较差。
- 数据库过载。MapReduce 往往并行跑多个子任务,同时往数据库输出会拖垮数据库的可用性。
- 可能产生副作用。MapReduce 通常对外提供全部成功或彻底失败,从而便于重试。如果写入外部服务,会出现部分失败的状态。
一个更好的方案是,在批处理任务内部生成全新的数据库,并将其以文件的形式写入分布式系统的文件夹中。一旦任务成功执行,这些数据文件就会称为不可变的(immutable),并且可以批量加载(bulk loading)进只处理只读请求的服务中。很多 KV 存储都支持使用 MapReduce 任务构建数据库文件,比如 Voldemort,Terrapin, ElephantDB 和 HBase bulk loading。另外 RocksDB 支持 ingest SST 文件,也是类似的情况。
直接构建数据库底层文件,就是一个 MapReduce 应用的绝佳案例:使用 mapper 抽取 key,然后利用该 key 进行排序,已经覆盖了构建索引中的大部分流程。由于大部 KV 存储都是只读的(通过批处理任务一次写入后,即不可变),这些存储的底层数据结构可以设计的非常简单。例如,不需要 WAL
当数据加载进 Voldemort 时,服务器可以利用老文件继续对外提供服务,新文件会从分布式文件系统中拷贝的 Voldemort 服务本地。一旦拷贝完成,服务器可以立即将外部查询请求原子地切到新文件上。如果导入过程中发生了任何问题,也可以快速地切回,使用老文件提供服务。因为老文件是不可变的,且没有立即被删除。
# 2.5.3 批处理输出的哲学
本章稍早我们讨论过 Unix 的设计哲学,它鼓励在做实验时使用显式的数据流:每个程序都会读取输入,然后将输出写到其他地方。在这个过程中,输入保持不变,先前的输出被变换为新的输出,并且没有任何其他的副作用。这意味着,你可以任意多次的重新跑一个命令,每次可以对命令或者参数进行下微调,或者查看中间结果进行调试,而不用担心对你原来系统的状态造成任何影响。
MapReduce 任务在处理输出时,遵从同样的哲学。通过不改变输入、不允许副作用(比如输出到外部文件),批处理不仅可以获得较好的性能,同时也变得容易维护:
- 容忍人为错误。如果你在代码中不小心引入了 bug,使得输出出错,你可以简单地将代码回滚到最近一个正确的版本,然后重新运行任务,则输出就会变正确。或者,更简单地,你可将之前正确的输出保存在其他的文件夹,然后在遇到问题时简单的切回去即可。使用读写事务的数据库是没法具有这种性质的:如果你部署了有 bug 的代码,并且因此往数据库中写入了错误的数据,回滚代码版本也并不能修复这些损坏的数据。(从有 bug 的代码中恢复,称为容忍人为错误,human fault tolerance)。这其实是通过牺牲空间换来的,也是经典的增量更新而非原地更新。
- 便于敏捷开发。相比可能会造成不可逆损坏的环境,由于能够很方便地进行回滚,可以大大加快功能迭代的速度(因为不需要进行严密的测试即可上生产)。最小化不可逆性(minimizing irreversibility)的原则,有助于敏捷软件开发。
- 简单重试就可以容错。如果某个 map 或者 reduce 任务失败了,MapReduce 框架会自动在相同输入上对其重新调度。如果失败是由代码 bug 引起的,在重试多次后(可以设置某个阈值),会最终引起任务失败;但如果失败是暂时的,该错误就能够被容忍。这种自动重试的机制之所以安全,是因为输入是不可变的,且失败子任务的输出会被自动抛弃。
- 数据复用。同一个文件集能够作为不同任务的输入,包括用于计算指标的监控任务、评估任务的输出是否满足预期性质(如,和之前一个任务的比较并计算差异)。
- 逻辑布线分离。和 Unix 工具一样,MapReduce 也将逻辑和接线分离(通过配置输入、输出文件夹),从而分拆复杂度并且提高代码复用度:一些团队可以专注于实现干好单件事的任务开发;另一些团队可以决定在哪里、在何时来组合跑这些代码。
在上述方面,Unix 中用的很好地一些设计原则也适用 Hadoop——但 Unix 工具和 Hadoop 也有一些不同的地方。比如,大部分 Unix 工具假设输入输出是无类型的文本,因此不得不花一些时间进行输入解析。在 Hadoop 中,通过使用更结构化的数据格式,消除了底层的一些低价值的语法解析和转换:Avro (参见Avro (opens new window))和 Parquet 是较常使用的两种编码方式,他们提供基于模式的高效编码方式,并且支持模式版本的演进。