 数据存储与检索
数据存储与检索
本章聚焦数据库底层如何处理查询和存储。这其中有个逻辑链条:使用场景→ 查询类型 → 存储格式。
查询类型主要分成两大类:
| 引擎类型 | 请求数量 | 数据量 | 瓶颈 | 存储格式 | 用户 | 场景举例 | 产品举例 |
|---|---|---|---|---|---|---|---|
| OLTP | 相对频繁,侧重在线交易 | 总体和单次查询都相对较小 | Disk Seek | 多用行存 | 比较普遍,一般应用用的比较多 | 银行交易 | MySQL |
| OLAP | 相对较少,侧重离线分析 | 总体和单次查询都相对巨大 | Disk Bandwidth | 列存逐渐流行 | 多为商业用户 | 商业分析 | ClickHouse |
其中,OLTP 侧,常用的存储引擎又有两种流派:
| 流派 | 主要特点 | 基本思想 | 代表 |
|---|---|---|---|
| log-structured 流 | 只允许追加,所有修改都表现为文件的追加和文件整体增删 | 变随机写为顺序写 | Bitcask、LevelDB、RocksDB、Cassandra、Lucene |
| update-in-place 流 | 以页(page)为粒度对磁盘数据进行修改 | 面向页、查找树 | B族树,所有主流关系型数据库和一些非关系型数据库 |
此外,针对 OLTP, 还探索了常见的建索引的方法,以及一种特殊的数据库——全内存数据库。
对于数据仓库,本章分析了它与 OLTP 的主要不同之处。数据仓库主要侧重于聚合查询,需要扫描很大量的数据,此时,索引就相对不太有用。需要考虑的是存储成本、带宽优化等,由此引出列式存储。
# 1. 驱动数据库的底层数据结构
本节由一个 shell 脚本出发,到一个相当简单但可用的存储引擎 Bitcask,然后引出 LSM-tree,他们都属于日志流范畴。之后转向存储引擎另一流派——B 族树,之后对其做了简单对比。最后探讨了存储中离不开的结构——索引。
首先来看,世界上“最简单”的数据库,由两个 Bash 函数构成:
#!/bin/bash
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
2
3
4
5
6
7
8
这两个函数实现了一个基于字符串的 KV 存储(只支持 get/set,不支持 delete):
$ db_set 123456 '{"name":"London","attractions":["Big Ben","London Eye"]}'
$ db_set 42 '{"name":"San Francisco","attractions":["Golden Gate Bridge"]}'
$ db_get 42
{"name":"San Francisco","attractions":["Golden Gate Bridge"]}
2
3
4
来分析下它为什么 work,也反映了日志结构存储的最基本原理:
- set:在文件末尾追加一个 KV 对。(日志就是一个仅支持追加式更新的数据文件)
- get:匹配所有 Key,返回最后(也即最新)一条 KV 对中的 Value。
可以看出:写很快,但是读需要全文逐行扫描,会慢很多。典型的以读换写。为了加快读,我们需要构建**索引:**一种允许基于某些字段查找的额外数据结构。
索引是基于原始数据派生而来的额外数据结构。由于每次写数据时,需要更新索引,因此任何类型的索引通常都会降低写的速度。
这便是数据库存储引擎设计和选择时最常见的权衡(trade off):
- 恰当的存储格式能加快写(日志结构),但是会让读取很慢;也可以加快读(查找树、B族树),但会让写入较慢。
- 为了弥补读性能,可以构建索引。但是会牺牲写入性能和耗费额外空间。
存储格式一般不好动,但是索引构建与否,一般交予用户选择。
# 1.1 哈希索引
本节主要基于最基础的 KV 索引。
log-structured 存储中,所有数据顺序追加到磁盘上。为了加快查询,我们在内存中构建一个哈希索引:
- Key 是查询 Key
- Value 是 KV 条目的起始位置(也称 byte offset)和长度。
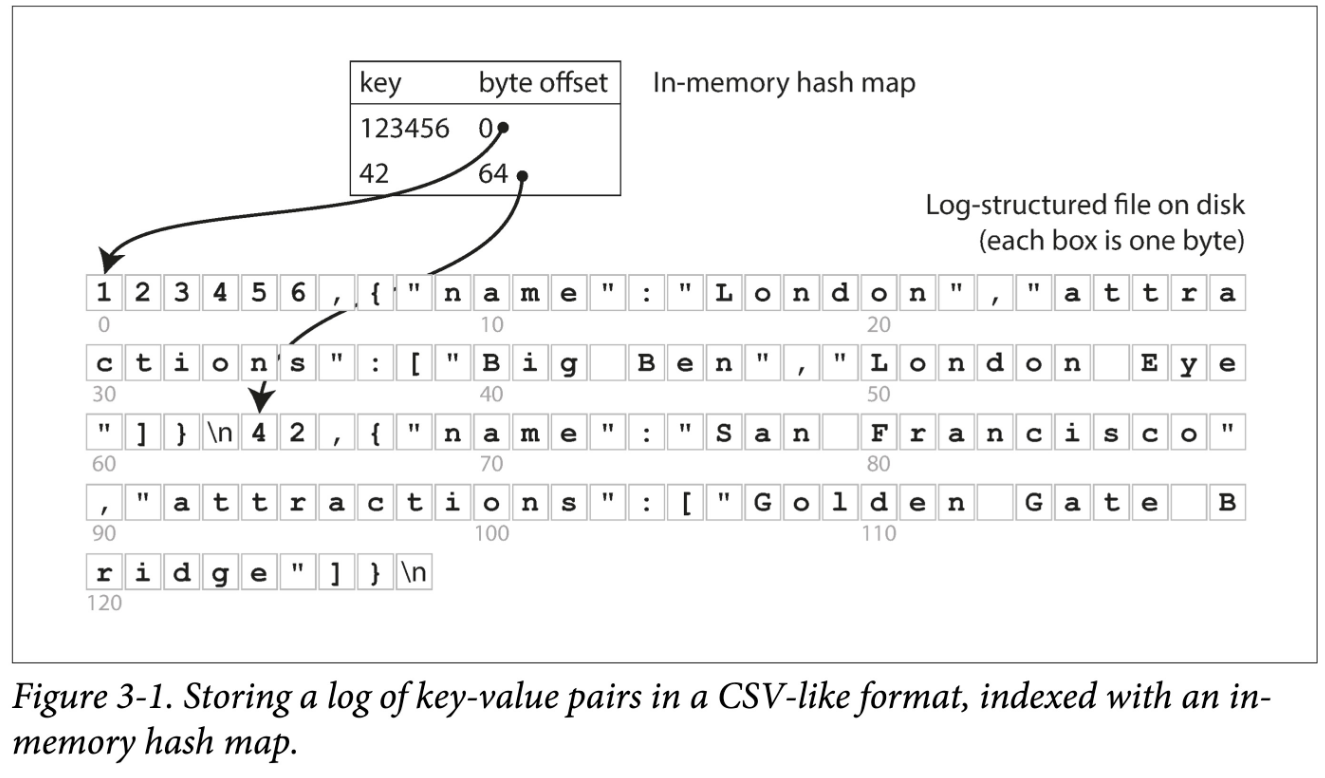
看来很简单,但这正是 Bitcask (opens new window) 的基本设计,但关键是,他 Work(在小数据量时,即所有 key 都能存到内存中时):能提供很高的读写性能:
- 写:文件追加写。
- 读:一次内存查询,一次磁盘 seek;如果数据已经被缓存,则 seek 也可以省掉。
如果你的 key 集合很小(意味着能全放内存),但是每个 key 更新很频繁,那么 Bitcask 便是你的菜。举个例子:频繁更新的视频播放量,key 是视频 url,value 是视频播放量。
但有个很重要问题,单个文件越来越大,磁盘空间不够怎么办?一种解决方法是将这些数据拆分到多个文件中,每个文件也称为段文件。这样,当由新的数据需要追加时,只追加到最后一个段文件中,当一个段文件的大小超过一定阈值后,就创建一个新的段文件并将后续数据写入到新的段文件中。
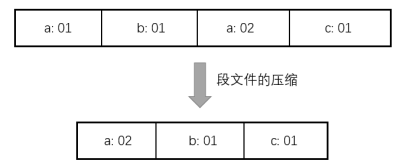
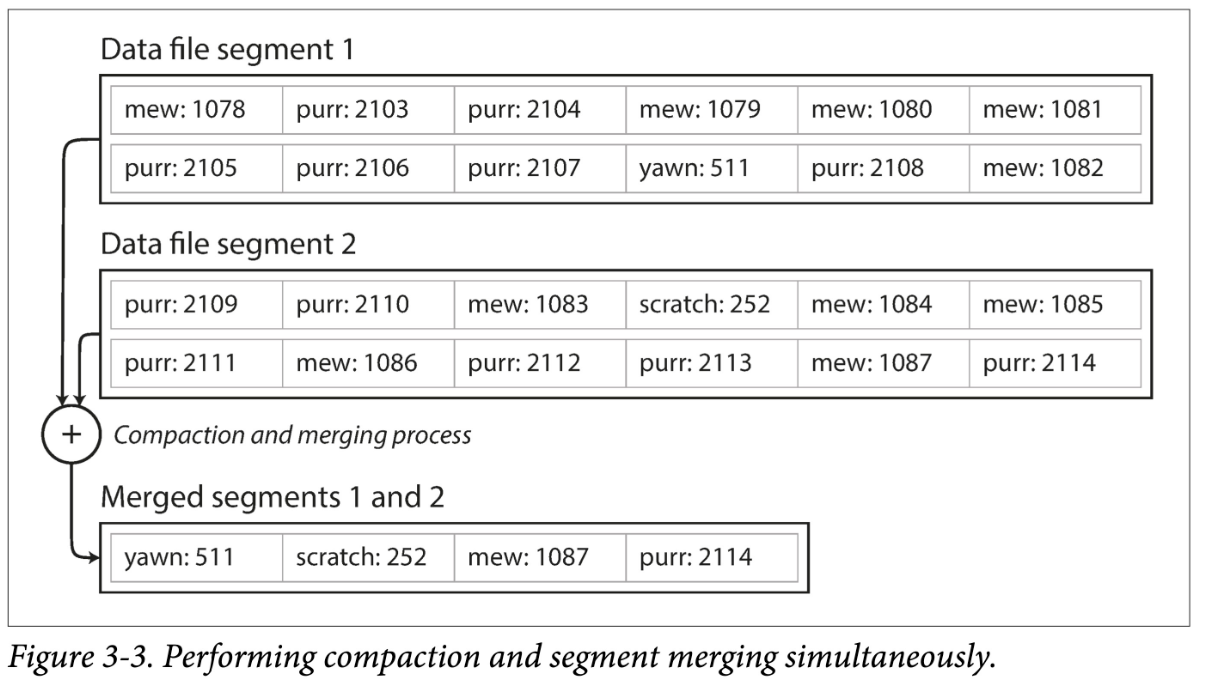
每次创建新的段文件时,存储引擎还需要对旧的段文件执行单个段文件的压缩和多个段文件的合并。单个段文件的压缩指的是将具有重复 key 的记录仅保留最新的记录。多个段文件的合并指的是将两个旧的段文件合并为一个段文件,同时将两个文件中具有重复 key 的记录仅保留最新的记录。这两个过程可以交由一个单独的后台进程来完成。
单个段文件的压缩如下图所示:
多个段文件的合并如下图所示:
当然,如果我们想让其工业可用,还有很多问题需要解决:
- 文件格式。对于日志来说,CSV 不是一种紧凑的数据格式,有很多空间浪费。比如,可以用 length + record bytes。
- 记录删除。之前只支持 put\get,但实际还需要支持 delete。但日志结构又不支持更新,怎么办呢?一般是写一个特殊标记(比如墓碑记录,tombstone)以表示该记录已删除。之后 compact 时真正删除即可。
- 宕机恢复。在机器重启时,内存中的哈希索引将会丢失。当然,可以全盘扫描以重建,但通常一个小优化是,对于每个 segment file, 将其索引条目和数据文件一块持久化,重启时只需加载索引条目即可。
- 记录写坏、少写。系统任何时候都有可能宕机,由此会造成记录写坏、少写。为了识别错误记录,我们需要增加一些校验字段,以识别并跳过这种数据。为了跳过写了部分的数据,还要用一些特殊字符来标识记录间的边界。
- 并发控制。由于只有一个活动(追加)文件,因此写只有一个天然并发度。但其他的文件都是不可变的(compact 时会读取然后生成新的),因此读取和紧缩可以并发执行。
乍一看,基于日志的存储结构存在折不少浪费:需要以追加进行更新和删除。但日志结构有几个原地更新结构无法做的优点:
- 以顺序写代替随机写。对于磁盘和 SSD,顺序写都要比随机写快几个数量级。
- 简易的并发控制。由于大部分的文件都是**不可变(immutable)**的,因此更容易做并发读取和紧缩。也不用担心原地更新会造成新老数据交替。
- 更少的内部碎片。每次紧缩会将垃圾完全挤出。但是原地更新就会在 page 中留下一些不可用空间。
当然,基于内存的哈希索引也有其局限:
- 所有 Key 必须放内存。一旦 Key 的数据量超过内存大小,这种方案便不再 work。当然你可以设计基于磁盘的哈希表,但那又会带来大量的随机写。
- 不支持范围查询。由于 key 是无序的,要进行范围查询必须全表扫描。
后面讲的 LSM-Tree 和 B+ 树,都能部分规避上述问题。
# 1.2 SSTables 和 LSM-Trees
# 1.2.1 什么是 SSTables?
这一节层层递进,步步做引,从 SSTables 格式出发,牵出 LSM-Trees 全貌。
对于 KV 数据,前面的 BitCask 存储结构是:
- 外存上日志片段(其中的数据是简单追加写而形成的,并没有按照某个字段有序)
- 内存中的哈希表
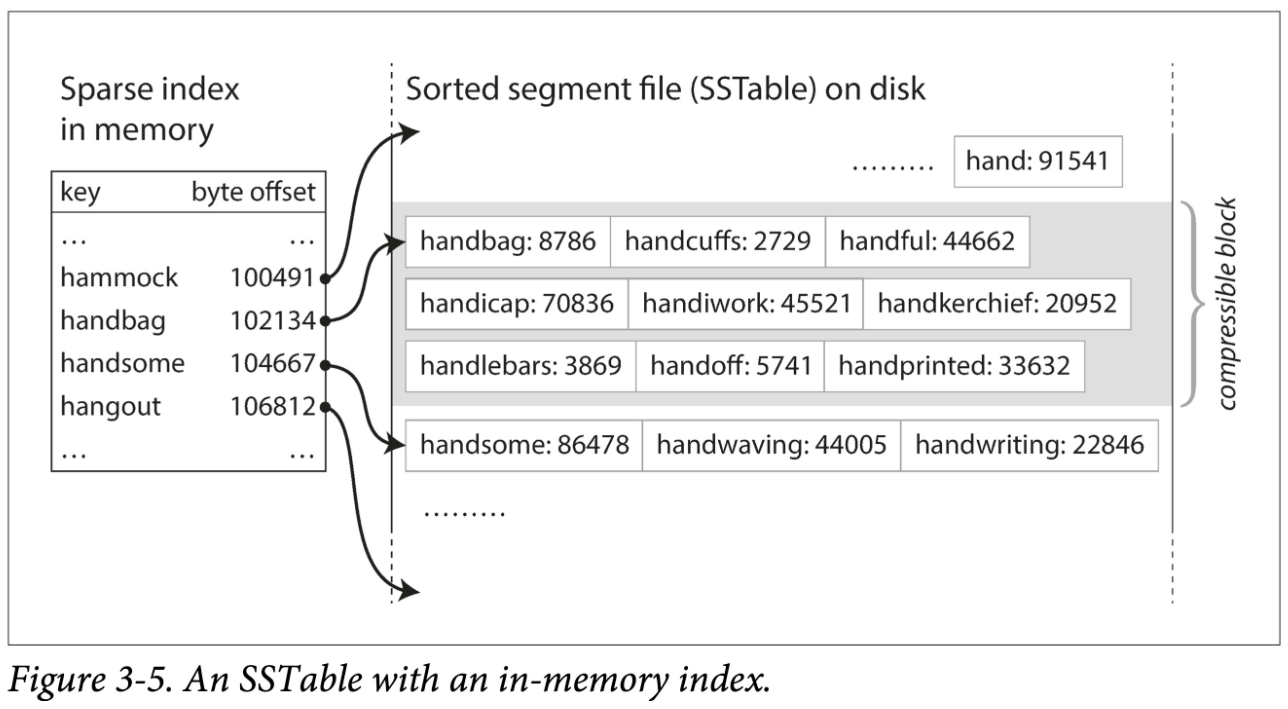
假设加一个限制,让这些文件按 key 有序。我们称这种格式为:SSTable(Sorted String Table)。
这种文件格式有什么优点呢?
- 高效的数据文件合并。即有序文件的归并外排,顺序读,顺序写。

- 不需要在内存中保存所有数据的索引。仅需要记录下每个文件界限(以区间表示:[startKey, endKey],当然实际会记录的更细)即可。查找某个 Key 时,去所有包含该 Key 的区间对应的文件二分查找即可。
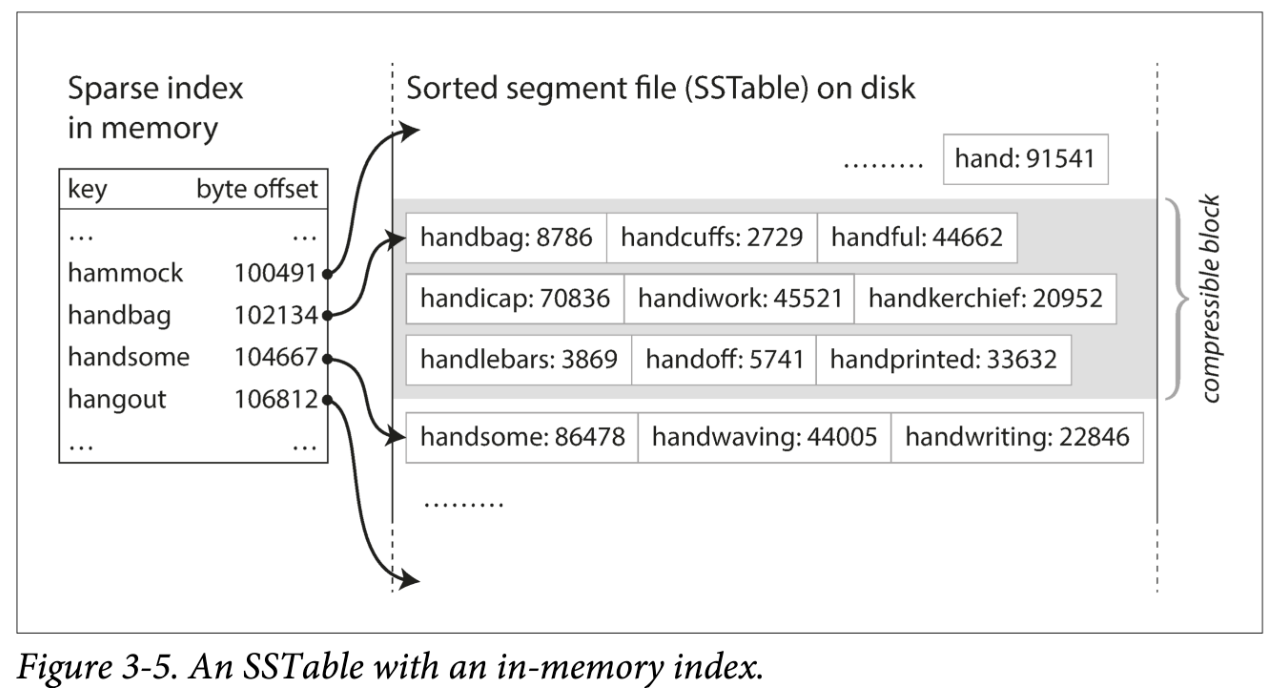
- 分块压缩,节省空间,减少 IO。相邻 Key 共享前缀,既然每次都要批量取,那正好把一组 key batch 到一块,称为 block,且只记录 block 的索引。
# 1.2.2 构建和维护 SSTables
SSTables 格式听起来很美好,但须知数据是乱序的来的,我们如何得到有序的数据文件呢?这可以拆解为两个小问题:
- 如何构建?
- 如何维护?
✨ 构建 SSTables 文件。将乱序数据在外存(磁盘 or SSD)中上整理为有序文件,是比较难的。但是在内存就方便的多。于是一个大胆的想法就形成了:
- 在内存中维护一个有序结构(称为 MemTable)。红黑树、AVL 树、条表。
- 到达一定阈值之后全量 dump 到外存。
✨ 维护 SSTables 文件。为什么需要维护呢?首先要问,对于上述复合结构,我们怎么进行查询:
- 先去 MemTable 中查找,如果命中则返回。
- 再去 SSTable 按时间顺序由新到旧逐一查找。
如果 SSTable 文件越来越多,则查找代价会越来越大。因此需要将多个 SSTable 文件合并,以减少文件数量,同时进行 GC,我们称之为紧缩(Compaction)。
总结:SSTables 的构建与维护
SSTables 的构建与维护的具体流程如下:
- 当需要插入一个新数据时,先将该记录插入到一个位于内存中的红黑树中;
- 当所建立的红黑树大小超过一定阈值时,将该红黑树转化为一个 SSTable 文件并写入磁盘中;
- 当数据库需要查询某个 key 时,首先在红黑树中查找这个 key,命中则返回,否则再从磁盘中最新的 SSTable 文件中查找,命中则返回,否则继续到次新的 SSTable 中查找;
- 单独一个后台进程会每隔一段时间执行一次 SSTable 文件(即段文件)的压缩与合并。
该方案的问题:如果出现宕机,内存中的数据结构将会消失。 解决方法也很经典:WAL。也就是可以在磁盘上保留单独的日志,每个写入都会立即追加到该日志,这个日志文件不需要按键排序,因为它的唯一目的就是在崩溃后恢复内存表,所以每当内存表写入 SSTables 时,响应的日志就可以被丢弃。
# 1.2.3 从 SSTables 到 LSM-Tree
将前面几节的一些碎片有机的组织起来,便是时下流行的存储引擎 LevelDB 和 RocksDB 后面的存储结构:LSM-Tree:
这种数据结构是 Patrick O’Neil 等人,在 1996 年提出的:The Log-Structured Merge-Tree (opens new window)。
Elasticsearch 和 Solr 的索引引擎 Lucene,也使用类似 LSM-Tree 存储结构。但其数据模型不是 KV,但类似:word → document list。
# 1.2.4 性能优化
如果想让一个引擎工程上可用,还会做大量的性能优化。对于 LSM-Tree 来说,包括:
- 优化 SSTable 的查找:原因:当查找数据库中某个不存在的键时,LSM-Tree 算法可能很慢,因为在确定键不存在之前,必须先检查内存表,然后将段一直回溯访问到最旧的段文件。优化手段常用 Bloom Filter (opens new window)。该数据结构可以使用较少的内存为每个 SSTable 做一些指纹,起到一些初筛的作用。
- 层级化组织 SSTable。以控制 Compaction 的顺序和时间。常见的有 size-tiered 和 leveled compaction。LevelDB 便是支持后者而得名。前者比较简单粗暴,后者性能更好,也因此更为常见。

对于 RocksDB 来说,工程上的优化和使用上的优化就更多了。在其 Wiki (opens new window) 上随便摘录几点:
- Column Family
- 前缀压缩和过滤
- 键值分离,BlobDB
但无论有多少变种和优化,LSM-Tree 的核心思想——保存一组合理组织、后台合并的 SSTables ——简约而强大。可以方便的进行范围遍历,可以变大量随机为少量顺序。