 初识容器
初识容器
参考:Kubernetes 入门实战课 | 极客时间 (opens new window) 第 1-8 讲
# 1. 初识 Docker:万事开头难
# 1.1 Docker 的形态
目前使用 Docker 基本有两个选择——Docker Desktop 和 Docker Engine:
- Docker Desktop:专门针对个人使用而设计,支持 Mac 和 Windows 的快速安装,并具有直观的图形界面,但仅限个人使用,不能商用。
- Docker Engine:完全免费,只能在 Linux 中运行,血脉最纯正。
如无特别说明,本专栏接下来所说的 Docker 指的都是 Docker Engine。
# 1.2 Docker 的安装
- 首先安装 docker:
sudo apt install docker.io - 然后启动 Docker 服务:
sudo service docker start- 这一步就是启动 Docker 的后台服务
- 然后将当前用户加入 docker 组:
sudo usermod -aG docker ${USER}- 这一步是把当前的用户加入Docker的用户组。这是因为操作Docker必须要有root权限,而直接使用root用户不够安全,加入Docker用户组是一个比较好的选择,这也是Docker官方推荐的做法。
上述命令执行完后,我们需要退出系统(exit),然后再重新登陆一次,这样才能让修改用户组的命令 usermod 生效。
可以通过 docker version 和 docker info 来验证是否安装成功。
docker version会输出 Docker 客户端和服务器各自的版本信息docker info会显示当前 Docker 系统相关的信息,例如CPU、内存、容器数量、镜像数量、容器运行时、存储文件系统等等
# 1.3 Docker 的使用
docker ps:列出当前系统中正在运行的容器,加上-a就可以看到所有已运行完毕的容器docker pull:拉取 docker imagedocker images:列出当前 Docker 所存储的所有 imagesdocker run:从 image 启动 container
Docker 使用 busybox
busybox 是一个小巧精致的“工具箱”,把诸多 Linux 命令整合在一个可执行文件里,体积一般不超过 2MB,非常适合测试任务或嵌入式系统。
docker pull busybox # 拉取busybox镜像
docker run busybox echo hello world
2
# 1.4 Docker 的架构简介
下图是 Docker 官网的一张图,描述了 Docker Engine 的内部角色和工作流程:
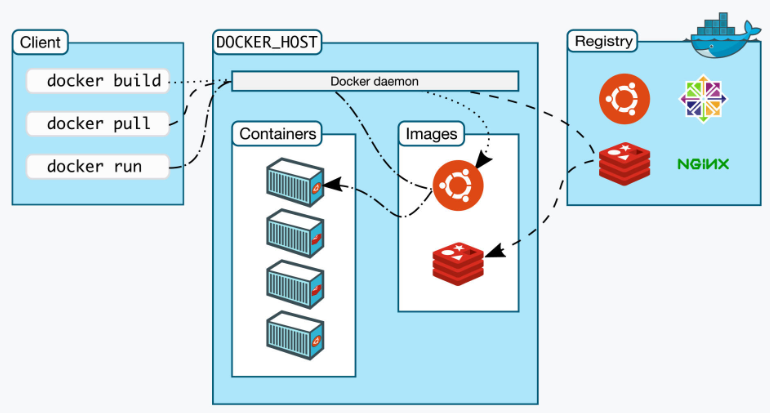
刚才我们敲的命令行 docker 实际上是一个客户端 client,它会与 Docker Engine 里的后台服务 Docker daemon 通信,而镜像则存储在远端的仓库 Registry 里,客户端并不能直接访问镜像仓库。
Docker client可以通过 build、 pull、 run 等命令向Docker daemon发送请求,而Docker daemon则是容器和镜像的“大管家”,负责从远端拉取镜像、在本地存储镜像,还有从镜像生成容器、管理容器等所有功能。所以,在Docker Engine里,真正干活的其实是默默运行在后台的Docker daemon,而我们实际操作的命令行工具“docker”只是个“传声筒”的角色。
# 2. 被隔离的进程:一起来看看容器的本质
广义上来说,容器技术是动态的容器、静态的镜像和远端的仓库这三者的组合。今天就来看看究竟什么是容器(即狭义的、动态的容器)。
# 2.1 容器到底是什么
容器封装了运行中的进程,并把进程与外界环境隔离开,让进程与外部系统互不影响。它就是一个特殊的隔离环境,它能够让进程只看到这个环境里的有限信息,不能对外界环境施加影响。
容器技术的另一个本领就是为应用程序加上资源隔离,在系统里切分出一部分资源,让它只能使用指定的配额。这可以避免容器内进程的过渡系统消耗,并充分利用计算机硬件,让有限的资源能够提供稳定可靠的服务。
# 2.2 隔离是怎么实现的
奥秘在于 Linux 内核所提供的三个技术:namespace、cgroup 和 chroot,虽然这三个技术的初衷都不是为了实现容器,但结合在一起就会发生奇妙的”化学反应“。
- namespace:它可以创建出独立的文件系统、主机名、进程号、网络等资源空间,相当于给进程盖了一间小板房,这样就实现了系统全局资源和进程局部资源的隔离。
- cgroup:全称是 Linux Control Group,用来实现对进程的 CPU、内存等资源的优先级和配额限制,相当于给进程的小板房加了一个天花板。
- chroot:它可以更改进程的根目录,也就是限制访问文件系统,相当于给进程的小板房铺上了地砖。
综合运用以上三个技术,一个四四方方、具有完善的隔离特性的容器就此出现了,进程也就可以搬进去快乐生活啦。
目前容器技术基本不再使用古老的 chroot 了,而是改用 pivot_root。
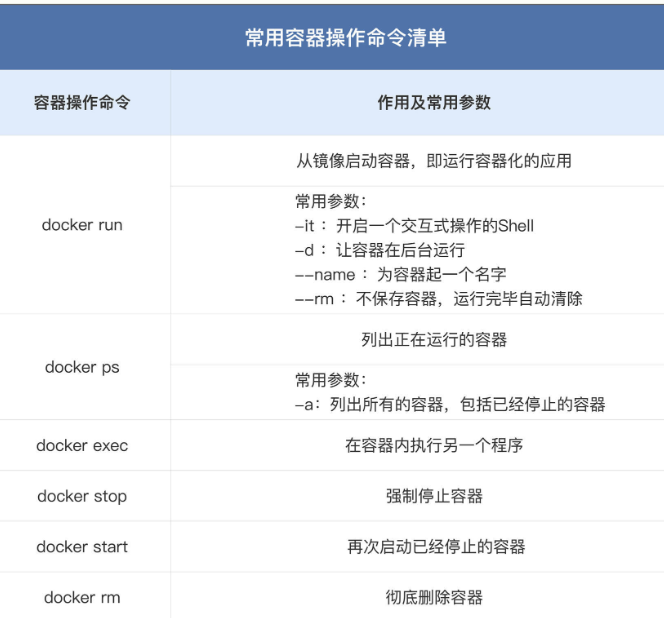
# 2.3 容器的常见操作命令
# 3. 如何编写正确、高效的 Dockerfile
这一大节来讲解镜像的内部机制,还有高效、正确地编写 Dockerfile 制作容器镜像的方法。
# 3.1 镜像的内部机制:分层
镜像就是一个打包文件,里面包含了应用程序及依赖环境,例如文件系统(fs)、env 以及 config params 等。这里面真正麻烦的是 fs,为了保证容器运行环境的一致性,镜像必须把 rootfs 都包含进来。
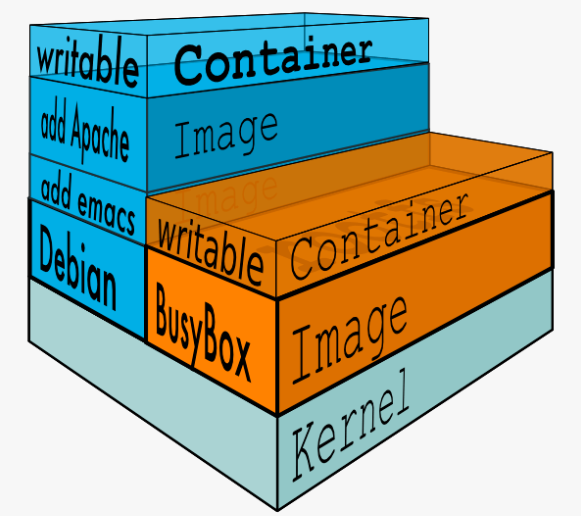
尽管 image 中不包含系统内核(因为 containers 共享了宿主机内核),但如果每个 image 都这样重复打包,会产生大量冗余(比如 1000 个 image 可能会有 1000 个 Ubuntu rootfs),对磁盘存储和网络传输都是很大的浪费。很自然地,我们可以想到应该把重复的部分抽取出来,也就是只存一份 Ubuntu rootfs,然后让所有基于此的 image 都共享这部分数据。这个思路就是 container image 的一个重大创新点:分层(Layer)。
容器镜像内部并不是一个平坦的结构,而是由许多的镜像层组成的,每层都是只读不可修改的一组文件,相同的层可以在镜像之间共享,然后多个层像搭积木一样堆叠起来,再使用一种叫“Union FS 联合文件系统”的技术把它们合并在一起,就形成了容器最终看到的文件系统:
使用 docker inspect nginx:alpine 可以看到镜像的分层信息,在输出的”RootFS“部分:
$ docker inspect nginx:alpine
...
"RootFS": {
"Type": "layers",
"Layers": [
"sha256:9d982e0ac7aee7e383989508c9b7175fae67221f80323067252a0442c632a67f",
"sha256:2ec9d5e75f88b8fa7403e3c42d85194c2bf6b9cc7f93c84e2fdd1949927a7eb5",
"sha256:52207ccd9e991181a2faebabaf7530e57a14221460f841c820874d90acb0b29a","sha256:33dba95a3cfec929519ae7232359c2212eb68d807c663f3adf807e3d635850e0","sha256:42939f4641510d4b8c971124cd0a8f644e9b48934dbb5c689aa010a5169ecb0e","sha256:6003157f5511d91798b880a6309a7d674c2e4978f6b79a1c24f0225344aa4811"
]
}
2
3
4
5
6
7
8
9
10
11
- 从上例可以看到,nginx:alpine 镜像里一共有 6 个 layer。
当你 docker pull 下载镜像时,Docker 会检查是否有重复的层,如果本地已存在就不会重复下载;同样在 docekr rmi 时如果 layer 被其他镜像共享的话,也不会被删除。
笔记
重点理解好:容器镜像是由多个只读的Layer构成的,同一个Layer可以被不同的镜像共享,减少了存储和传输的成本。
# 3.2 Dockerfile 是什么
Dockerfile 就是一个纯文本,里面记录了一系列的构建指令,每个指令都会生成一个 layer,Docker 会顺序执行这些指令并最终创建出一个新的 image 出来。
下面是一个 Dockerfile 示例:
# Dockerfile.busybox
FROM busybox # 选择基础镜像
CMD echo "hello world" # 启动容器时默认运行的命令
2
3
然后可以使用 docker build 来创建镜像:
$ docker build -f Dockerfile.busybox .
Sending build context to Docker daemon 7.68kB
Step 1/2 : FROM busybox
---> d38589532d97
Step 2/2 : CMD echo "hello world"
---> Running in c5a762edd1c8
Removing intermediate container c5a762edd1c8
---> b61882f42db7
Successfully built b61882f42db7
2
3
4
5
6
7
8
9
10
-f参数指定 Dockerfile 文件名- 最后需要跟一个文件路径,叫做构建上下文(build’s context)。这里只有一个简答的点号,表示当前路径的意思。
# 3.3 怎样编写正确、高效的 Dockerfile
这里讲一下编写 Dockerfile 的一些常用指令和最佳实践。
# 1)FROM
首先因为构建镜像的第一条指令必须是 FROM,所以基础镜像的选择非常关键。如果关注的是镜像的安全和大小,那么一般会选择 Alpine;如果关注的是应用的运行稳定性,那么可能会选择 Ubuntu、Debian、CentOS。
# 2)COPY
然后可以使用 COPY 命令将构建上下文中的一些文件打包到镜像中。注意,不能使用构建上下文之外的文件。
COPY ./a.txt /tmp/a.txt # 把构建上下文里的a.txt拷贝到镜像的/tmp目录
COPY /etc/hosts /tmp # 错误!不能使用构建上下文之外的文件
2
# 3)RUN、ARG 和 ENV
RUN 命令可以执行任意的 shell 命令,比如更新系统、安装应用、下载文件、创建目录、编译程序等等,实现任意的镜像构建步骤,非常灵活。
RUN 通常会是Dockerfile里最复杂的指令,会包含很多的Shell命令,但Dockerfile里一条指令只能是一行,所以有的 RUN 指令会在每行的末尾使用续行符 \,命令之间也会用 && 来连接,这样保证在逻辑上是一行,就像下面这样:
RUN apt-get update \
&& apt-get install -y \
build-essential \
curl \
make \
unzip \
&& cd /tmp \
&& curl -fSL xxx.tar.gz -o xxx.tar.gz\
&& tar xzf xxx.tar.gz \
&& cd xxx \
&& ./config \
&& make \
&& make clean
2
3
4
5
6
7
8
9
10
11
12
13
有的时候在Dockerfile里写这种超长的 RUN 指令很不美观,而且一旦写错了,每次调试都要重新构建也很麻烦,所以你可以采用一种变通的技巧:把这些Shell命令集中到一个脚本文件里,用 COPY 命令拷贝进去再用 RUN 来执行:
COPY setup.sh /tmp/ # 拷贝脚本到/tmp目录
RUN cd /tmp && chmod +x setup.sh \ # 添加执行权限
&& ./setup.sh && rm setup.sh # 运行脚本然后再删除
2
3
4
RUN 指令实际上就是Shell编程,如果你对它有所了解,就应该知道它有变量的概念,可以实现参数化运行,这在 Dockerfile 里也可以做到,需要使用两个指令 ARG 和 ENV:
- ARG:它创建的变量只在镜像构建过程中可见,容器运行时不可见
- ENV:它创建的变量不仅能够在构建镜像的过程中使用,在容器运行时也能够以环境变量的形式被应用程序使用
# 4)EXPOSE
它用来声明容器对外服务的端口号:
EXPOSE 443 # 默认是 tcp 协议
EXPOSE 53/udp # 可以指定 udp 协议
2
讲了这些 Dockerfile 指令之后,我还要特别强调一下,因为每个指令都会生成一个镜像层,所以 Dockerfile 里最好不要滥用指令,尽量精简合并,否则太多的层会导致镜像臃肿不堪。
# 3.4 docker build 是怎么工作的?
“构建上下文”是什么意思呢?
因为命令行 docker 只是一个简单的客户端,真正的镜像构建工作是由服务端的 Docker daemon 来完成的,所以 docker 客户端就只能把构建上下文目录打包上传(显示信息 Sending build context to Docker daemon ),这样服务器才能够获取本地的这些文件。
但把构建上下文打包的过程可能会把一些无用的文件(比如 README、.git 等)也拷贝进镜像了,为避免这个文件,你可以在构建上下文目录中建一个 .dockerignore 文件,语法与 .gitignore 类似,用来排除掉那些不需要的文件。
下面是一个简单的示例,表示不打包上传后缀是“swp”“sh”的文件:
# docker ignore
*.swp
*.sh
2
3
另外关于Dockerfile,一般应该在命令行里使用 -f 来显式指定。但如果省略这个参数, docker build 就会在当前目录下找名字是 Dockerfile 的文件。所以,如果只有一个构建目标的话,文件直接叫“Dockerfile”是最省事的。
在构建时,也可以加一个 -t 参数,也就是指定镜像的 tag,这样 Docker 在构建完成后会自动给镜像添加名字。当然,名字必须要符合上节课里的命名规范,用 : 分隔名字和标签,如果不提供标签默认就是“latest”。
关于镜像的构建,还有很多高级技巧等待你去探索,比如使用缓存、多阶段构建等等,你可以再参考 Docker 官方文档 (opens new window),或者一些知名应用的镜像(如 Nginx、Redis、Node.js 等)进一步学习。
# 3.5 课外小贴士
- 我们也可以使用命令“docker commit”从运行中的容器直接生成镜像,但这样不具有 Dockerfle“ 文档化的优点,一般不推荐使用。
- Docker 镜像遵循的是 OCI (Open Container Initi-atve)标准,所以制作出来的镜像文件也能够被其他的容器技术 (如 Kata、Kubernetes) 识别并运行。
- Union FS 有 多 种实 现,例 如 aufs、btrfs、de-vice-mapper 等,目前 Docker 使用的是 overlay2,可以在“docker info”中查看。
- 在 Dockerfle 里还可以使用另一个与“COPY”很类似的“ADD”指令,它不仅能够拷贝文件,还支持下载和自动解压缩,但过多的操作让它的含义比较模糊,不容易控制,个人不推荐使用。
- “ENTRYPOINT”是一个与“CMD”类似的指令,也可以定义启动命令,相当于“docker run xxx ENTRY-POINT CMD”,不过没有“CMD”常用。
- 可以使用“docker history”命令回放完整的镜像的构建过程,有的时候对于镜像排错很有用。
# 4. 该怎样用好 Docker Hub 这个宝藏
镜像文件该如何管理呢?
# 4.1 Registry
镜像仓库 Registry 就是所有镜像都在这里登记保管,就像是一个巨大的档案馆。docker pull 命令就是让 Docker daemon 去 Registry 下载镜像。Registry 除了提供拉取镜像的功能外,还提供了上传、查询、删除等多个功能。
# 4.2 Docker Hub
默认的镜像仓库就是 Docker Hub (opens new window),它是官方 Registry 服务。里面不仅有 Docker 自己打包的镜像,而且还对公众免费开放。
# 4.3 如何在 Docker Hub 上挑选镜像
在Docker Hub上有官方镜像、认证镜像 和非官方镜像的区别。
- 官方镜像:由 Docker 公司提供,经过了严格的漏洞扫描和安全检测,支持x86_64、arm64等多种硬件架构,还具有清晰易读的文档,一般来说是我们构建镜像的首选,也是我们编写Dockerfile的最佳范例。这种镜像会有一个“Official image”的标记。
- 认证镜像:有一个“Verified publisher”的标记,就是认证发行商,比如Bitnami、Rancher、Ubuntu等。它们都是颇具规模的大公司,类似于微博的“大V”。
- 非官方镜像:有一种是“半官方镜像”,因为经过 Docker 认证是要交钱的,很多公司不想交钱,就没有经过认证,但这类也比较可靠。剩下的就是民间镜像了,这类往往由于条件所限,质量难以保证。
除了查看镜像是否为官方认证,我们还应该再结合其他的条件来判断镜像质量是否足够好。做法和GitHub差不多,就是看它的下载量、星数、还有更新历史,简单来说就是“好评”数量。最好还是随大流。
Dockerhub 上镜像的命名方式是“用户名/应用名”的形式,比如 ubuntu/nginx 等。所以,我们在使用 docker pull 下载这些非官方镜像的时候,就必须把用户名也带上,否则默认就会使用官方镜像。
# 4.4 Docker Hub 上镜像命名的规则是什么
镜像还存在许多版本,也就多个 tag。直接使用默认的“latest”虽然简单方便,但在生产环境里是一种非常不负责任的做法,会导致版本不可控。所以我们还需要理解Docker Hub上标签命名的含义,才能够挑选出最适合我们自己的镜像版本。
下面拿官方的Redis镜像作为例子,解释一下这些标签都是什么意思。

通常来说,镜像标签的格式是 应用的版本号加上操作系统。
版本号你应该比较了解吧,基本上都是 主版本号+次版本号+补丁号 的形式,有的还会在正式发布前出rc版(候选版本,release candidate)。而操作系统的情况略微复杂一些,因为各个Linux发行版的命名方式“花样”太多了。
Alpine、CentOS的命名比较简单明了,就是数字的版本号,像这里的 alpine3.15 ,而Ubuntu、Debian则采用了代号的形式。比如Ubuntu 18.04是 bionic,Ubuntu 20.04是 focal,Debian 9是 stretch,Debian 10是 buster,Debian 11是 bullseye。
另外,有的标签还会加上 slim、 fat,来进一步表示这个镜像的内容是经过精简的,还是包含了较多的辅助工具。通常 slim 镜像会比较小,运行效率高,而 fat 镜像会比较大,适合用来开发调试。
下面我就列出几个标签的例子来说明一下。
- nginx:1.21.6-alpine,表示版本号是1.21.6,基础镜像是最新的Alpine。
- redis:7.0-rc-bullseye,表示版本号是7.0候选版,基础镜像是Debian 11。
- node:17-buster-slim,表示版本号是17,基础镜像是精简的Debian 10。
# 4.5 离线环境该怎么办
Docker 提供了:
- save 命令将 image 导出为压缩包:
docker save ngx-app:latest -o ngx.tar - load 命令从压缩包导入 Docker:
docker load -i ngx.tar或docker load --input ngx.tar
# 4.6 课后小贴士
- 由于 Docker Hub 服务器在国外,国内访问会比较慢所以就出现了不少镜像加速网站,可以在“/etc/dock-er/daemon.json”里配置。但不知道出于什么原因,近几年很多网站都停止了这项服务,十分可惜。
- 虽然 Docker Hub 一家独大,但市面上仍然有其他的竞争者,它们不甘心“ 寄人篱下 ”,就自己开了独立的镜像仓库,典型的有 Red Hat 的 quay.io、Google 的gcr.io、还有 GitHub 的 ghcr.io。
- Docker 官方镜像也有用户名,就是“library”,例如“library/nginx”,但一般都省略不写。
- 我们也可以用命令行
docker search来快速查找 Docker Hub 里的镜像。
# 5. 打破次元壁:容器该如何与外界互联互通
这一大节讲讲有哪些手段能够在容器与外部系统之间沟通交流。
# 5.1 如何拷贝容器内的数据
docker cp 命令可以在宿主机和容器之间拷贝文件:
docker cp a.txt 062:/tmp # 外界 -> 容器内
docker cp 062:/tmp/a.txt ./b.txt # 容器内 -> 外界
2
# 5.2 如何共享主机上的文件
挂载 volume 即可。在 docker run 命令运行时,指定 -v 参数,格式是 “宿主机路径:容器内路径”,代表让容器宿主机的某个目录。
# 5.3 如何实现网络互通
网络互通的关键在于“打通”容器内外的网络,而处理网络通信无疑是计算机系统里最棘手的工作之一,有许许多多的名词、协议、工具,在这里我也没有办法一下子就把它都完全说清楚,所以只能从“宏观”层面讲个大概,帮助你快速理解。
Docker提供了三种网络模式,分别是 null、 host 和 bridge:
# 1)null 模式
null 是最简单的模式,也就是没有网络,但允许其他的网络插件来自定义网络连接,这里就不多做介绍了。
# 2)host 模式
host 的意思是直接使用宿主机网络,相当于去掉了容器的网络隔离(其他隔离依然保留),所有的容器会共享宿主机的IP地址和网卡。这种模式没有中间层,自然通信效率高,但缺少了隔离,运行太多的容器也容易导致端口冲突。
host 模式需要在 docker run 时使用 --net=host 参数,下面我就用这个参数启动 Nginx:
docker run -d --rm --net=host nginx:alpine
为了验证效果,我们可以在本机和容器里分别执行 ip addr 命令,查看网卡信息:
ip addr # 本机查看网卡
docker exec xxx ip addr # 容器查看网卡
2
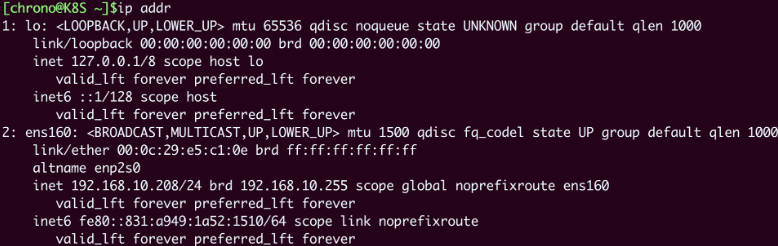
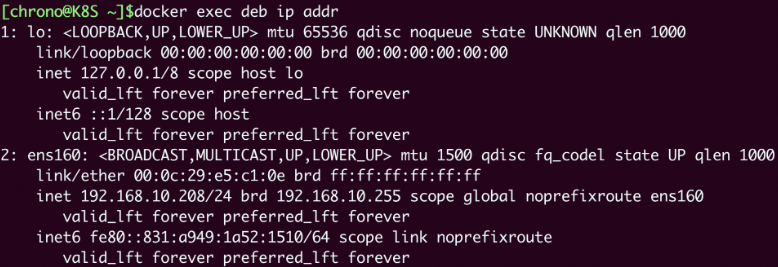
可以看到这两个 ip addr 命令的输出信息是完全一样的,比如都是一个网卡ens160,IP地址是“192.168.10.208”,这就证明Nginx容器确实与本机共享了网络栈。
# 3)bridge 模式
第三种 bridge,也就是桥接模式,它有点类似现实世界里的交换机、路由器,只不过是由软件虚拟出来的,容器和宿主机再通过虚拟网卡接入这个网桥(图中的docker0),那么它们之间也就可以正常的收发网络数据包了。不过和host模式相比,bridge模式多了虚拟网桥和网卡,通信效率会低一些。
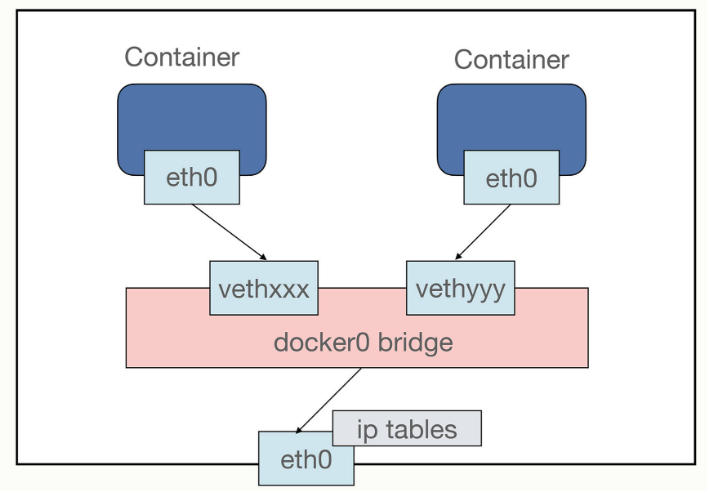
和host模式一样,我们也可以用 --net=bridge 来启用桥接模式,但其实并没有这个必要,因为Docker默认的网络模式就是bridge,所以一般不需要显式指定。
下面我们启动两个容器Nginx和Redis,就像刚才说的,没有特殊指定就会使用bridge模式:
docker run -d --rm nginx:alpine # 默认使用桥接模式
docker run -d --rm redis # 默认使用桥接模式
2
然后我们还是在本机和容器里执行 ip addr 命令(Redis容器里没有ip命令,所以只能在Nginx容器里执行):
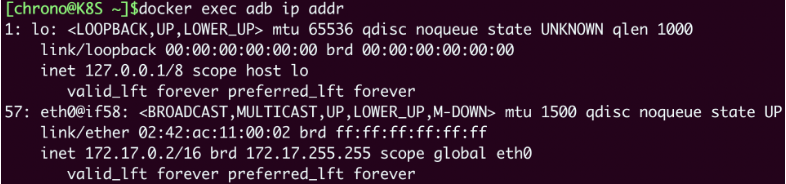
对比一下刚才host模式的输出,就可以发现容器里的网卡设置与宿主机完全不同,eth0是一个虚拟网卡,IP地址是B类私有地址“172.17.0.2”。
我们还可以用 docker inspect 直接查看容器的 ip 地址:
docker inspect xxx |grep IPAddress
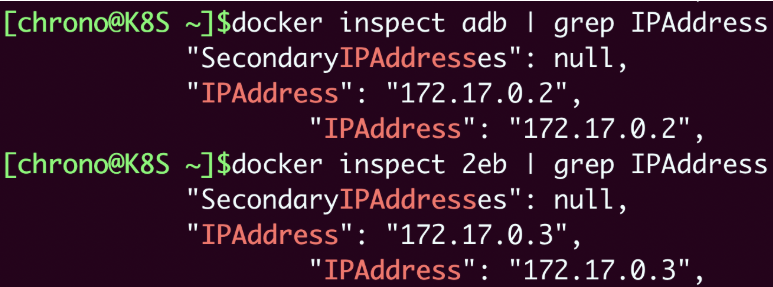
这显示出两个容器的IP地址分别是“172.17.0.2”和“172.17.0.3”,而宿主机的IP地址则是“172.17.0.1”,所以它们都在“172.17.0.0/16”这个Docker的默认网段,彼此之间就能够使用IP地址来实现网络通信了。
# 5.4 如何分配服务端口号
在编写 Dockerfile 时,可以用 EXPOSE 指令声明容器对外的端口号,在 docker run 时也可以使用 -p 参数来实现端口映射。
# 5.5 课外小贴士
- Docker 还可以使用“volume”命令创建独立挂载的数据卷”,但它的用法与 Kubernetes 差距较大,为了避免混淆这里就不介绍了。
- Docker 官方推荐使用来代替“-v”,但--mount--mount”用法很繁琐,而“-v”已经有了很长的应用历史了,所以我还是建议用较为方便的“-v”。
-v挂载目录时如果发现源路径不存在会自动创建这有时候会是一个“坑”,当主机目录被意外删除时会导致容器里出现空目录,让应用无法按预想的流程工作。-v挂载目录默认是可读可写的,但也可以加上:ro变成只读,可以防止容器意外修改文件,例如-v /tmp:/tmp:ro- IPv4 地址是 32 位,分为 5 类 (ABCDE),ABC 类地址中各有一部分网段可以私用,“172.16.0.0/16~172.31.0.0/16”就都属于 B 类私有地址。