 Deployment、Daemonset、Service、Ingress
Deployment、Daemonset、Service、Ingress
参考:Kubernetes 入门实战课 | 极客时间 (opens new window) 第 18-23 讲
# 1. Deployment:让应用永不宕机
# 1.1 为什么需要 Deployment
除了离线业务,另一大类业务就是在线业务。单独的 Pod 使用 containers 可以任意编排容器,它可以保证容器正常工作,但如果 Pod 本身出错了怎么办呢?比如不小心使用 kubectl delete 误删了 Pod,或者节点发生了断电故障,那么 Pod 就会消失,对 container 的控制也就无从谈起了。另外,在线业务也远不止单纯启动一个 Pod 那么简单,还有多实例、高可用、版本更新等许多复杂操作,比如我们需要应对突发流量的压力、需要多个应用副本、需要监控应用状态。如果只是使用 Pod,那么就又走回手工管理的老路了。
Kubernetes 处理这种在线业务问题的思路是创建一个新的 API 对象:Deployment,通过对象套对象的方式,让它来管理 Pod。
# 1.2 使用 YAML 描述 Deployment
看一下 Deployment 的基本信息:
$ kubectl api-resources
NAME SHORTNAMES APIVERSION NAMESPACED KIND
deployments deploy apps/v1 true Deployment
2
3
4
可以看出,Deployment的简称是“deploy”,它的apiVersion是“apps/v1”,kind是“Deployment”。所以我们知道它的 YAML 的开头该怎么写了:
apiVersion: apps/v1
kind: Deployment
metadata:
name: xxx-dep
2
3
4
当然了,我们也可以使用如下命令来创建一个 YAML 样板:
export out="--dry-run=client -o yaml"
kubectl create deploy ngx-dep --image=nginx:alpine $out
2
得到的 Deployment YAML 大概如下所示:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: ngx-dep
name: ngx-dep
spec:
replicas: 2
selector:
matchLabels:
app: ngx-dep
template:
metadata:
labels:
app: ngx-dep
spec:
containers:
- image: nginx:alpine
name: nginx
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
对比一下 Job/CronJob 可以发现,有许多相同的地方,比如都有 spec、template 字段,template 下面也有一个 Pod,不同的地方是它的 spec 多了 replicas、selector 两个字段,而这两个字段就是 Deployment 实现多实例、高可用等功能的关键所在。
# 1.3 Deployment 的关键字段
# 1.3.1 replicas 字段
replicas 字段:Pod 实例的副本数量。
Kubernetes 会持续监控 Pod 的运行状态,万一有 Pod 发生意外而消失,他就会通过 apiserver、scheduler 等核心组件去选择新的节点,创建出新的 Pod,直到数量与“期望状态”一致。
# 1.3.2 selector 字段
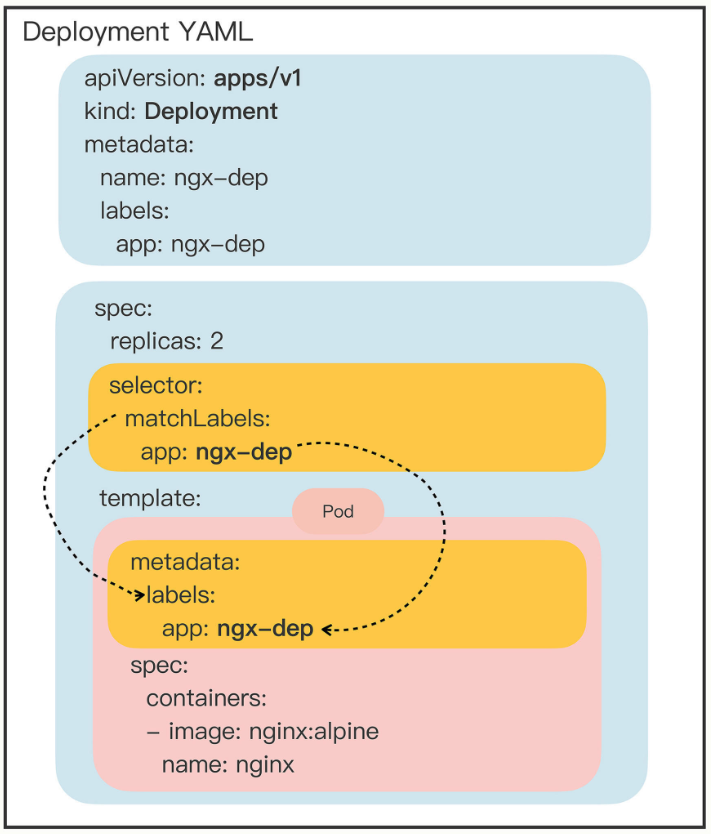
selector 字段,用于“筛选”出要被 Deployment 管理的 Pod 对象。
下属字段“matchLabels”定义了Pod对象应该携带的label,它必须和“template”里Pod定义的“labels”完全相同,否则Deployment就会找不到要控制的Pod对象,apiserver也会告诉你YAML格式校验错误无法创建。
这个 selector 字段的用法初看起来好像是有点多余,为了保证Deployment成功创建,我们必须在YAML里把label重复写两次:一次是在“ selector.matchLabels”,另一次是在“ template.matadata”。像在这里,你就要在这两个地方连续写 app: ngx-dep :
spec:
replicas: 2
selector:
matchLabels:
app: ngx-dep
template:
metadata:
labels:
app: ngx-dep
...
2
3
4
5
6
7
8
9
10
11
你也许会产生疑问:为什么要这么麻烦?为什么不能像Job对象一样,直接用“template”里定义好的Pod就行了呢?
这是因为在线业务和离线业务的应用场景差异很大。离线业务中的Pod基本上是一次性的,只与这个业务有关,紧紧地绑定在Job对象里,一般不会被其他对象所使用。而在线业务就要复杂得多了,因为Pod永远在线,除了要在Deployment里部署运行,还可能会被其他的API对象引用来管理,比如负责负载均衡的Service对象。
所以 Deployment 和 Pod 实际上是一种松散的组合关系,Deployment 实际上并不“持有” Pod 对象,它只是帮助 Pod 对象能够有足够的副本数量运行,仅此而已。如果像 Job 那样,把 Pod 在模板里“写死”,那么其他的对象再想要去管理这些 Pod 就无能为力了。
Kubernetes采用的是这种“贴标签”的方式,通过在API对象的“metadata”元信息里加各种标签(labels),我们就可以使用类似关系数据库里查询语句的方式,筛选出具有特定标识的那些对象。通过标签这种设计,Kubernetes就解除了Deployment和模板里Pod的强绑定,把组合关系变成了“弱引用”。
下图展示了 Deployment 与被他管理的 Pod 的关系:
# 1.4 用 kubectl 操作 Deployment
写好 Deployment 的 YAML 后,就可以用 kubectl apply 来创建对象了:
kubectl apply -f deploy.yml
然后使用 kubectl get deploy 来查看 Deployment 的状态:

- READY表示运行的Pod数量,前面的数字是当前数量,后面的数字是期望数量,所以“2/2”的意思就是要求有两个Pod运行,现在已经启动了两个Pod。
- UP-TO-DATE指的是当前已经更新到最新状态的Pod数量。因为如果要部署的Pod数量很多或者Pod启动比较慢,Deployment完全生效需要一个过程,UP-TO-DATE就表示现在有多少个Pod已经完成了部署,达成了模板里的“期望状态”。
- AVAILABLE要比READY、UP-TO-DATE更进一步,不仅要求已经运行,还必须是健康状态,能够正常对外提供服务,它才是我们最关心的Deployment指标。
- 最后一个AGE就简单了,表示Deployment从创建到现在所经过的时间,也就是运行的时间。
因为 Deployment 管理的是 Pod,所以也可以用 kubectl get pod 来查看 Pod 的状态,可以看到,这些被 Deployment 管理的 Pod 自动带上了名字,命名的规则是 Deployment 的名字加上两串随机数:

这时候如果我们尝试删除某个 Pod,Kubernetes 在 Deployment 的管理下又会很快创建一个新的 Pod 来保证满足期望状态。
在 Deployment 部署成功后,你还可以使用 kubectl scale 来随时调整 Pod 的数量,从而实现应用伸缩。通过指定 --replicas 参数可以指定副本的数量,比如下面的命令将 Nginx 扩容到 5 个:
kubectl scale --replicas=5 deploy ngx-dep
注意,kubectl scale 只是临时的措施。
# 1.5 补充:Pod 中 labels 的用法
之前我们通过 labels 为对象“贴”了各种“标签”,在使用 kubectl get 命令的时候,加上参数 -l,使用 ==、 !=、 in、 notin 的表达式,就能够很容易地用“标签”筛选、过滤出所要查找的对象(有点类似社交媒体的 #tag 功能),效果和Deployment里的 selector 字段是一样的。
看两个例子,第一条命令找出“app”标签是 nginx 的所有Pod,第二条命令找出“app”标签是 ngx、 nginx、 ngx-dep 的所有Pod:
kubectl get pod -l app=nginx
kubectl get pod -l 'app in (ngx, nginx, ngx-dep)'
2
# 1.6 小结
这一大节学习的 Deployment 对象包装了 Pod,通过添加额外的控制功能实现了应用永不宕机。Pod 只能管理容器,不能管理自身,所以就出现了 Deployment,由它来管理 Pod。
学了Deployment这个API对象,我们今后就不应该再使用“裸Pod”了。即使我们只运行一个Pod,也要以Deployment的方式来创建它,虽然它的
replicas字段值是1,但Deployment会保证应用永远在线。
另外,作为Kubernetes里最常用的对象,Deployment的本事还不止这些,它还支持滚动更新、版本回退,自动伸缩等高级功能,这些将在后面学习。
# 2. Daemonset:忠实可靠的看门狗
Deployment 无法满足在线业务的所有场景,这一大节来看另一类代表在线业务的 API 对象:DaemonSet,它会在 Kubernetes 集群的每个节点上都运行一个 Pod,就好像是 Linux 系统里的“守护进程”(Daemon)。
# 2.1 为什么需要 DaemonSet
Deployment 可以创建任意多个 Pod 实例,但不关心这些 Pod 在哪些节点上运行,因为在它看来,Pod 的运行环境与功能是无关的。这个假设对于大多数业务是没问题的,比如 Nginx、MySQL 等。
但有一些业务比较特殊,它们不是完全独立于系统运行的,而是与主机存在“绑定”关系,必须要依附于节点才能产生价值,比如说:
- 网络应用(如kube-proxy),必须每个节点都运行一个Pod,否则节点就无法加入Kubernetes网络。
- 监控应用(如Prometheus),必须每个节点都有一个Pod用来监控节点的状态,实时上报信息。
- 日志应用(如Fluentd),必须在每个节点上运行一个Pod,才能够搜集容器运行时产生的日志数据。
- 安全应用,同样的,每个节点都要有一个Pod来执行安全审计、入侵检查、漏洞扫描等工作。
这些业务如果用Deployment来部署就不太合适了,因为Deployment所管理的Pod数量是固定的,而且可能会在集群里“漂移”,但,实际的需求却是要在集群里的每个节点上都运行Pod,也就是说Pod的数量与节点数量保持同步。
所以 Kubernetes 就定义了新的 API 对象:DaemonSet,它在形式上和 Deployment 类似,都是管理控制 Pod,但管理调度策略却不同。DaemonSet 的目标是在集群的每个节点上运行且仅运行一个 Pod,就好像是为节点配上一只“看门狗”,忠实地“守护”着节点,这就是 DaemonSet 名字的由来。
# 2.2 使用 YAML 描述 DaemonSet
DaemonSet 简称 ds,YAML 文件头信息应该是:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: xxx-ds
2
3
4
它的样板信息无法通过 kubectl create 创建出来,但可以去官网 https://kubernetes.io/zh/docs/concepts/workloads/controllers/daemonset/ (opens new window) 找一份 DaemonSet 的 YAML 示例,拷贝下来并简单修改就可以做成一份自己的文件,大概如下:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: redis-ds
labels:
app: redis-ds
spec:
selector:
matchLabels:
name: redis-ds
template:
metadata:
labels:
name: redis-ds
spec:
containers:
- image: redis:5-alpine
name: redis
ports:
- containerPort: 6379
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
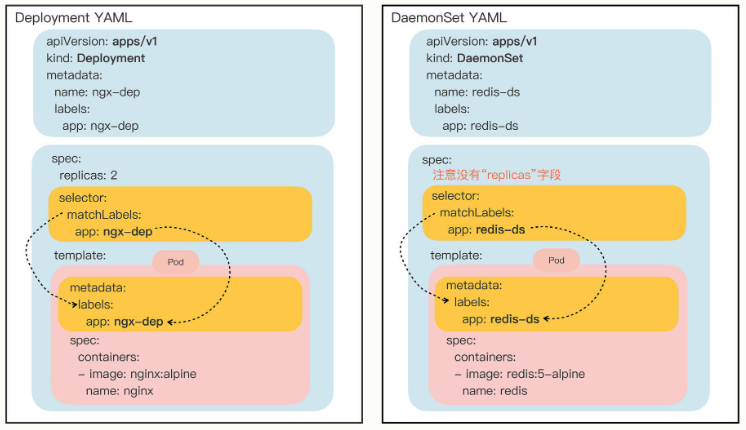
这个DaemonSet对象的名字是 redis-ds,镜像是 redis:5-alpine。把它与 Deployment 的 YAML 对比一下就可以发现,两者结构基本一样,spec 部分中都有 selector 字段和 template 字段。不同之处是 DaemonSet 在 spec 里没有 replicas 字段,因为它不会在集群里创建多个 Pod 副本,而是要在每个节点上只创建出一个 Pod 实例。
也就是说,DaemonSet 仅仅是在 Pod 的部署调度策略上和 Deployment 不同,其他的都是相同的,某种程度上我们也可以把 DaemonSet 看做是 Deployment 的一个特例。两者的 YAML 如下图:
# 2.3 在 Kubernetes 里使用 DaemonSet
可以使用 kubectl apply 将 YAML 发给 Kubernetes 并创建 DaemonSet 对象,再用 kubectl get ds 来查看状态:
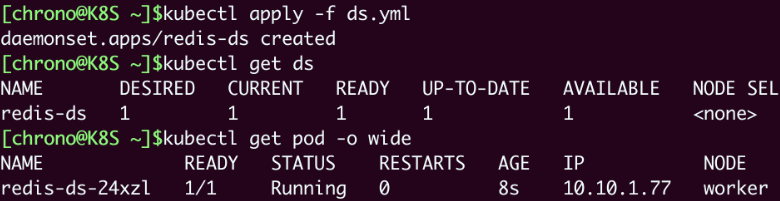
看这张截图,虽然我们没有指定DaemonSet里Pod要运行的数量,但它自己就会去查找集群里的节点,在节点里创建Pod。因为我们的实验环境里有一个Master一个Worker,而Master默认是不跑应用的,所以DaemonSet就只生成了一个Pod,运行在了“worker”节点上。
但有点不对劲。按照DaemonSet的本意,应该在每个节点上都运行一个Pod实例才对,但Master节点却被排除在外了,这就不符合我们当初的设想了。显然 DaemonSet 没有尽到“看门”的职责,它的设计与 Kubernetes 集群的工作机制发生了冲突,有没有办法解决呢?
当然,Kubernetes早就想到了这点,为了应对Pod在某些节点的“调度”和“驱逐”问题,它定义了两个新的概念:污点(taint)和容忍度(toleration)。
# 2.4 污点(taint)和容忍度(toleration)
“污点”是 Kubernetes 节点的一个属性,也有点类似于给节点贴上一些标签。“容忍度”是 Pod 的属性,表示 Pod 能否容忍一个节点上污点的存在。
我们把它俩放在一起就比较好理解了。集群里的节点各式各样,有的节点“纯洁无瑕”,没有“污点”;而有的节点因为某种原因粘上了“泥巴”,也就有了“污点”。Pod也脾气各异,有的“洁癖”很严重,不能容忍“污点”,只能挑选“干净”的节点;而有的Pod则比较“大大咧咧”,要求不那么高,可以适当地容忍一些小“污点”。
Kubernetes 在创建集群的时候会自动给节点 Node 加上一些 taint,方便 Pod 的调度和部署。这可以通过 kubectl describe node 来查看 Master 和 Worker 的状态:
$ kubectl describe node master
Name: master
Roles: control-plane,master
...
Taints: node-role.kubernetes.io/master:NoSchedule
...
$ kubectl describe node worker
Name: worker
Roles: <none>
...
Taints: <none>
...
2
3
4
5
6
7
8
9
10
11
12
13
可以看到,Master节点默认有一个 taint,名字是 node-role.kubernetes.io/master,它的效果是 NoSchedule,也就是说这个污点会拒绝Pod调度到本节点上运行,而Worker节点的 taint 字段则是空的。
这正是Master和Worker在Pod调度策略上的区别所在,通常来说Pod都不能容忍任何“污点”,所以加上了 taint 属性的Master节点也就会无缘Pod了。
明白了“污点”和“容忍度”的概念,你就知道该怎么让 DaemonSet 在 Master 节点(或者任意其他节点)上运行了,方法有两种。
# 1)方法一:去掉 Master 上的 taint
去掉 Master 上的 taint,让它变得像 worker 一样纯洁无瑕,DaemonSet 自然就不需要再区分 Master/Worker。
给 Master 去掉 taint 的方法
操作Node上的“污点”属性需要使用命令 kubectl taint,然后指定节点名、污点名和污点的效果,去掉污点要额外加上一个 -。
比如要去掉Master节点的“NoSchedule”效果,就要用这条命令:
kubectl taint node master node-role.kubernetes.io/master:NoSchedule-
命令执行后,原本因为这个 taint 而不在这里运行的 Pod 就会立刻在上面创建并运行起来了。
但是,这种方法修改的是 Node 的状态,影响面会比较大,可能会导致很多 Pod 都跑到这个节点上运行,所以我们可以保留 Node 的“污点”,为需要的 Pod 添加“容忍度”,只让某些 Pod 运行在个别节点上,实现“精细化”调度。
# 2)方法二:为 Pod 增加容忍度(toleration)
为Pod添加字段 tolerations,让它能够“容忍”某些“污点”,就可以在任意的节点上运行了。
tolerations 是一个数组,里面可以列出多个被“容忍”的“污点”,需要写清楚“污点”的名字、效果。比较特别是要用 operator 字段指定如何匹配“污点”,一般我们都使用 Exists,也就是说存在这个名字和效果的“污点”。
如果我们想让DaemonSet里的Pod能够在Master节点上运行,就要写出这样的一个 tolerations,容忍节点的 node-role.kubernetes.io/master:NoSchedule 这个污点:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
operator: Exists
2
3
4
重新 kubectl apply 之后,效果就起作用了。
需要特别说明一下,容忍度并不是DaemonSet独有的概念,而是从属于Pod,所以理解了“污点”和“容忍度”之后,你可以在Job/CronJob、Deployment里为它们管理的Pod也加上 tolerations,从而能够更灵活地调度应用。
官方文档 https://kubernetes.io/zh/docs/concepts/scheduling-eviction/taint-and-toleration/ (opens new window) 罗列了各污点的效果,可以参考。
# 2.5 静态 Pod
DaemonSet 是在 Kubernetes 里运行节点专属 Pod 最常用的方式,但它不是唯一的方式,Kubernetes 还支持另外一种叫静态 Pod 的应用部署手段。
“静态Pod”非常特殊,它不受Kubernetes系统的管控,不与apiserver、scheduler发生关系,所以是“静态”的。
但既然它是Pod,也必然会“跑”在容器运行时上,也会有YAML文件来描述它,而唯一能够管理它的Kubernetes组件也就只有在每个节点上运行的kubelet了。
“静态Pod”的YAML文件默认都存放在节点的 /etc/kubernetes/manifests 目录下,它是Kubernetes的专用目录。下图展示了 Master 节点的目录情况:
你可以看到,Kubernetes 的 4 个核心组件 apiserver、etcd、scheduler、controller-manager 原来都以静态 Pod 的形式存在的,这也是为什么它们能够先于 Kubernetes 集群启动的原因。
如果你有一些 DaemonSet 无法满足的特殊的需求,可以考虑使用静态 Pod,编写一个 YAML 文件放到这个目录里,节点的 kubelet 会定期检查目录里的文件,发现变化就会调用容器运行时创建或者删除静态 Pod。
# 2.6 小结
- DaemonSet的目标是为集群里的每个节点部署唯一的Pod,常用于监控、日志等业务。
- DaemonSet的YAML描述与Deployment非常接近,只是没有
replicas字段。 - “污点”和“容忍度”是与DaemonSet相关的两个重要概念,分别从属于Node和Pod,共同决定了Pod的调度策略。
- 静态Pod也可以实现和DaemonSet同样的效果,但它不受Kubernetes控制,必须在节点上纯手动部署,应当慎用。
课外小贴士:
- Linux 系统里最出名的守护进程应该就是 systemd 了它是系统里的 1号进程,管理其他所有的进程。
- 网络插件 Fannel 就是一个 DaemonSet,它位于名字空间“kube-system”,可以用“kubectl get ds -n kube-system”看到。
- 虽然静态 Pod 在 Kubernetes 里已经存在了很长时间但 Kubernetes 官网对它的态度却是 “ 模棱两可”,毕竟它游离在系统之外,不好管理,所以将来有被废弃的可能。
- 与污点、容忍度相关的另一个概念是“节点亲和性”(nodeAfnity),作用是更“偏好”选择哪种节点但用法略复杂一些
- 在 Kubernetes v1.24 中,master 节点将不再使用污点
node-role.kubernetes.io/master,而是改成node-role.kubernetes.io/control-plane
# 3. Service:微服务架构的应对之道
为了更好地支持微服务以及服务网格这样的应用架构,Kubernetes 又专门定义了一个新的对象:Service,它是集群内部的负载均衡机制,用来解决服务发现的关键问题。
# 3.1 为什么要有 Service
借助 Kubernetes 强大的自动化运维能力,我们可以把应用的更新上线频率由以前的月、周级别提升到天、小时级别,让服务质量更上一层楼。不过,在应用程序快速版本迭代的同时,另一个问题也逐渐显现出来了,就是服务发现。
Deployment 和 DaemonSet 管理下的 Pod 经常处于动态的变化之中,所以这些 IP 地址也是经常变来变去。业内的解决方案就是负载均衡,典型的应用有LVS、Nginx等等。它们在前端与后端之间加入了一个“中间层”,屏蔽后端的变化,为前端提供一个稳定的服务。但LVS、Nginx毕竟不是云原生技术,所以Kubernetes就按照这个思路,定义了新的API对象:Service。
Service 的工作原理就与 Nginx 差不多,Kubernetes 会给它分配一个静态 IP 地址,然后它再去自动管理、维护后面动态变化的 Pod 集合,当客户端访问 Service,它就根据某种策略,把流量转发给后面的某个 Pod。下图清楚地展示了 Service 的工作原理:
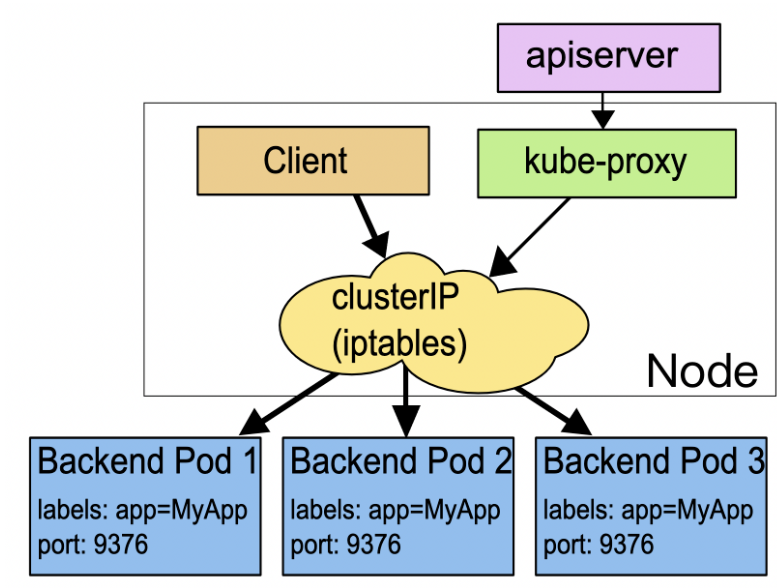
你可以看到,这里Service使用了iptables技术,每个节点上的kube-proxy组件自动维护iptables规则,客户不再关心Pod的具体地址,只要访问Service的固定IP地址,Service就会根据iptables规则转发请求给它管理的多个Pod,是典型的负载均衡架构。
不过 Service 并不是只能使用 iptables 来实现负载均衡,它还有另外两种实现技术:性能更差的 userspace 和性能更好的 ipvs,但这些都属于底层细节,我们不需要刻意关注。
# 3.2 使用 YAML 描述 Service
Service 的简称是 svc,apiVersion 是 v1。注意,这说明它与 Pod 一样,属于 Kubernetes 的核心对象,不关联业务应用,与 Job、Deployment 是不同的。
一个 Service 的 YAML 开头如下所示:
apiVersion: v1
kind: Service
metadata:
name: xxx-svc
2
3
4
Kubernetes 可以使用 kubectl expose 来创建样板 YAML。因为在Kubernetes里提供服务的是Pod,而Pod又可以用Deployment/DaemonSet对象来部署,所以 kubectl expose 支持从多种对象创建服务,Pod、Deployment、DaemonSet都可以。
使用 kubectl expose 指令时还需要用参数 --port 和 --target-port 分别指定映射端口和容器端口,而Service自己的IP地址和后端Pod的IP地址可以自动生成,用法上和Docker的命令行参数 -p 很类似,只是略微麻烦一点。比如如果想为我们之前创建的 ngx-dep 这个 Deployment 对象生成 Service,命令就要这么写:
export out="--dry-run=client -o yaml"
kubectl expose deploy ngx-dep --port=80 --target-port=80 $out
2
生成的 Service YAML 如下:
apiVersion: v1
kind: Service
metadata:
name: ngx-svc
spec:
selector:
app: ngx-dep
ports:
- port: 80
targetPort: 80
protocol: TCP
2
3
4
5
6
7
8
9
10
11
12
13
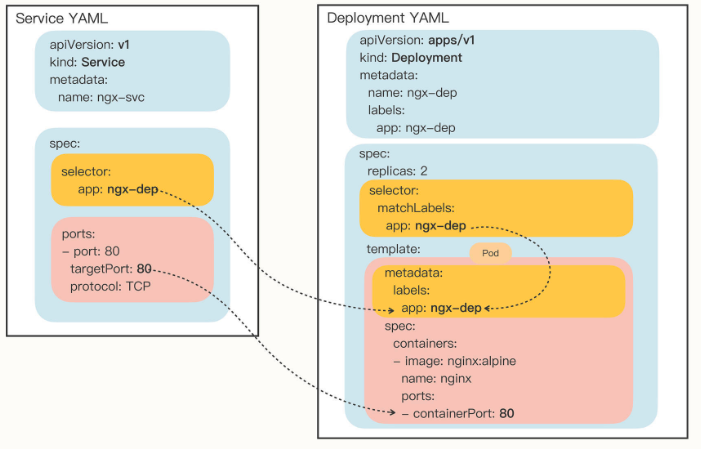
你会发现,Service 的定义非常简单,在“spec”里只有两个关键字段,selector 和 ports:
selector:和 Deployment/DaemonSet 里的作用是一样的,用来过滤出要代理的那些 Pod。因为我们指定要代理Deployment,所以Kubernetes就为我们自动填上了ngx-dep的标签,会选择这个Deployment对象部署的所有Pod。ports:里面的三个字段分别表示外部端口、内部端口和使用的协议,在这里就是内外部都使用80端口,协议是TCP。
为了让你看清楚Service与它引用的Pod的关系,我把这两个YAML对象画在了下面的这张图里,需要重点关注的是 selector、 targetPort 与Pod的关联:
# 3.3 在 Kubernetes 里使用 Service
在创建 Service 对象之前,我们先对之前的 Deployment 做一点改造,方便观察 Service 的效果。
首先,我们创建一个ConfigMap,定义一个Nginx的配置片段,它会输出服务器的地址、主机名、请求的URI等基本信息:
apiVersion: v1
kind: ConfigMap
metadata:
name: ngx-conf
data:
default.conf: |
server {
listen 80;
location / {
default_type text/plain;
return 200
'srv : $server_addr:$server_port\nhost: $hostname\nuri : $request_method $host $request_uri\ndate: $time_iso8601\n';
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
然后我们在 Deployment 的“template.volumes”里定义存储卷,再用“volumeMounts”把配置文件加载进 Nginx 容器里:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ngx-dep
spec:
replicas: 2
selector:
matchLabels:
app: ngx-dep
template:
metadata:
labels:
app: ngx-dep
spec:
volumes:
- name: ngx-conf-vol
configMap:
name: ngx-conf
containers:
- image: nginx:alpine
name: nginx
ports:
- containerPort: 80
volumeMounts:
- mountPath: /etc/nginx/conf.d
name: ngx-conf-vol
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
部署这个Deployment之后,我们就可以创建Service对象了,用的还是 kubectl apply:
kubectl apply -f svc.yml
创建之后,用命令 kubectl get 就可以看到它的状态:

你可以看到,Kubernetes 为 Service 对象自动分配了一个 IP 地址“10.96.240.115”,这个地址段是独立于 Pod 地址段的。而且 Service 对象的 IP 地址还有一个特点,它是一个“虚地址”,不存在实体,只能用来转发流量。
想要看Service代理了哪些后端的Pod,你可以用 kubectl describe 命令:
kubectl describe svc ngx-svc
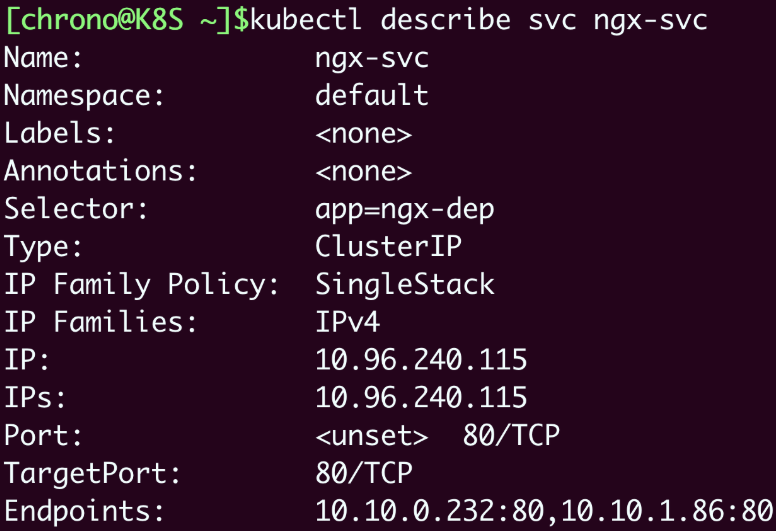
截图里显示Service对象管理了两个endpoint,分别是“10.10.0.232:80”和“10.10.1.86:80”,初步判断与Service、Deployment的定义相符,那么这两个IP地址是不是Nginx Pod的实际地址呢?
我们还是用 kubectl get pod 来看一下,加上参数 -o wide:

把Pod的地址与Service的信息做个对比,我们就能够验证Service确实用一个静态IP地址代理了两个Pod的动态IP地址。
那怎么测试 Service 的负载均衡效果呢?因为Service、 Pod的IP地址都是Kubernetes集群的内部网段,所以我们需要用 kubectl exec 进入到Pod内部(或者ssh登录集群节点),再用curl等工具来访问Service:
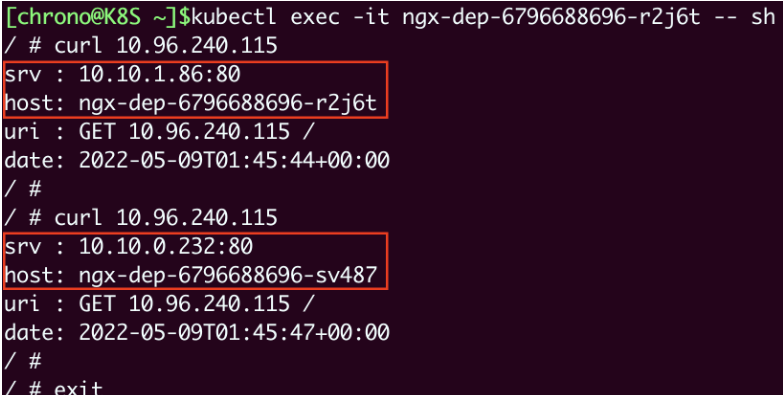
- 我们 curl 的是 Service 的固定 IP 地址,然后可以看到它把请求转发给了后端的某个 Pod,输出信息显示了是哪个 Pod 响应了这个请求,就表名 Service 确实完成了对 Pod 的负载均衡任务。
我们再试着删除一个 Pod,在看看 Service 是否会更新它的后端的 Pod,从而实现自动化的服务发现:
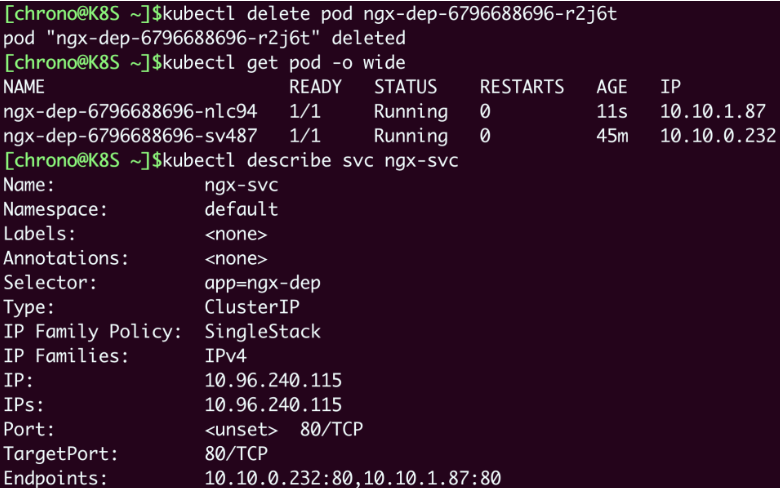
- 可以看到,Service 可以通过 controller-manager 来实时监控 Pod 的变化情况,所以就会立即更新它的代理的 IP 地址,从上图可以看到,Endpoints 的 IP 列表随着 Pod 的变化也发生了改变。
# 3.4 以域名的方式使用 Service
Service 对象的 IP 地址是静态的,保持了稳定,这在微服务里确实很重要,不过以数字形式的 IP 地址用起来还是不太方便。这个时候 Kubernetes 的 DNS 插件就派上了用处,它可以为 Service 创建容易记忆的域名,让 Service 更容易使用。
在这之前,我们先介绍一个概念:名字空间(namespace)。Kubernetes 使用 namespace 用来在集群中实现对 API 对象的隔离和分组。
这里所说的 namespace 与 Linux 的 namespace 技术不一样。
namespace 简写为 ns,可以使用 kubectl get ns 来查看当前集群里都有哪些 namespace,也就是说 API 对象有哪些分组:
$ kubectl get ns
NAME STATUS AGE
default Active 4d1h
kube-node-lease Active 4d1h
kube-public Active 4d1h
kube-system Active 4d1h
kubernetes-dashboard Active 3d23h
2
3
4
5
6
7
Kubernetes 有一个默认的 namespace:default,如果不显式指定,API 对象都会在这个 default namespace 中,而其他的 namespace 都有各自的用途,比如 kube-system 就包含了 apiserver、etcd 等核心组件的 Pod。
因为 DNS 是一种层次结构,为了避免太多的域名导致冲突,Kubernetes 就把 namespace 作为域名的一部分,减少了重名的可能性。
Service 对象的域名完全形式是:对象.名字空间.svc.cluster.local,但很多时候也可以省略后面的部分,直接写“对象.名字空间”,甚至“对象名”就足够了,默认会使用 default namespace。
现在我们来试验一下 DNS 域名的用法,还是先 kubectl exec 进入 Pod,然后用 curl 访问 ngx-svc、 ngx-svc.default 等域名:
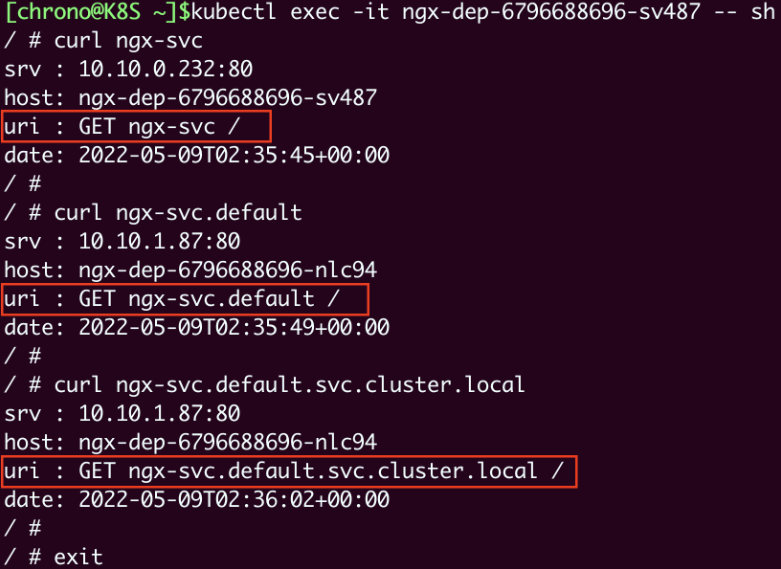
可以看到,现在我们就不再关心 Service 对象的IP地址,只需要知道它的名字,就可以用 DNS 的方式去访问后端服务。
比起 Docker,这无疑是一个巨大的进步,而且对比其他微服务框架(如 Dubbo、Spring Cloud),由于服务发现机制被集成在了基础设施里,也会让应用的开发更加便捷。
顺便说一下,Kubernetes也为每个Pod分配了域名,形式是“ IP地址.名字空间.pod.cluster.local”,但需要把IP地址里的
.改成-。比如地址10.10.1.87,它对应的域名就是10-10-1-87.default.pod。
# 3.5 如何让 Service 对外暴露服务
由于 Service 是一种负载均衡技术,所以它不仅能够管理 Kubernetes 集群内部的服务,还能够担当向集群外部暴露服务的重任。
Service对象有一个关键字段“type”,表示 Service 是哪种类型的负载均衡。前面我们看到的用法都是对集群内部 Pod 的负载均衡,所以这个字段的值就是默认的“ClusterIP”,Service 的静态 IP 地址只能在集群内访问。
除了“ClusterIP”,Service 还支持其他三种类型,分别是“ExternalName”“LoadBalancer”“NodePort”。不过前两种类型一般由云服务商提供,我们的实验环境用不到,所以接下来就重点看“NodePort”这个类型。
当在 YAML 里添加字段 type: NodePort 的话,那么 Service 除了会对后端的 Pod 做负载均衡之外,还会在集群里的每个节点上创建一个独立的端口,用这个端口对外提供服务,这也正是“NodePort”这个名字的由来。
让我们修改一下 Service 的 YAML 文件,加上字段“type”:
apiVersion: v1
...
spec:
...
type: NodePort
2
3
4
5
然后创建对象,再用 kubectl get svc 查看它的状态:

就会看到“TYPE”变成了“NodePort”,而在“PORT”列里的端口信息也不一样,除了集群内部使用的“80”端口,还多出了一个“30651”端口,这就是Kubernetes在节点上为Service创建的专用映射端口。
因为这个端口号属于节点,外部能够直接访问,所以现在我们就可以不用登录集群节点或者进入Pod内部,直接在集群外使用任意一个节点的IP地址,就能够访问Service和它代理的后端服务了。
比如我现在所在的服务器是“192.168.10.208”,在这台主机上用curl访问Kubernetes集群的两个节点“192.168.10.210”“192.168.10.220”,就可以得到Nginx Pod的响应数据:
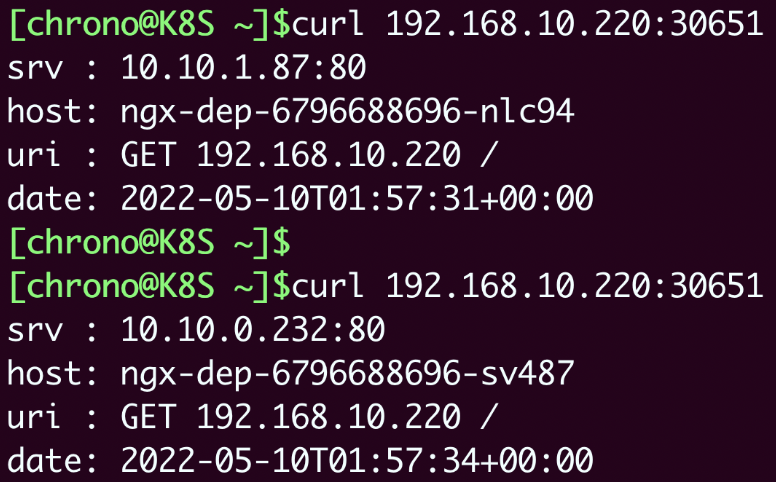
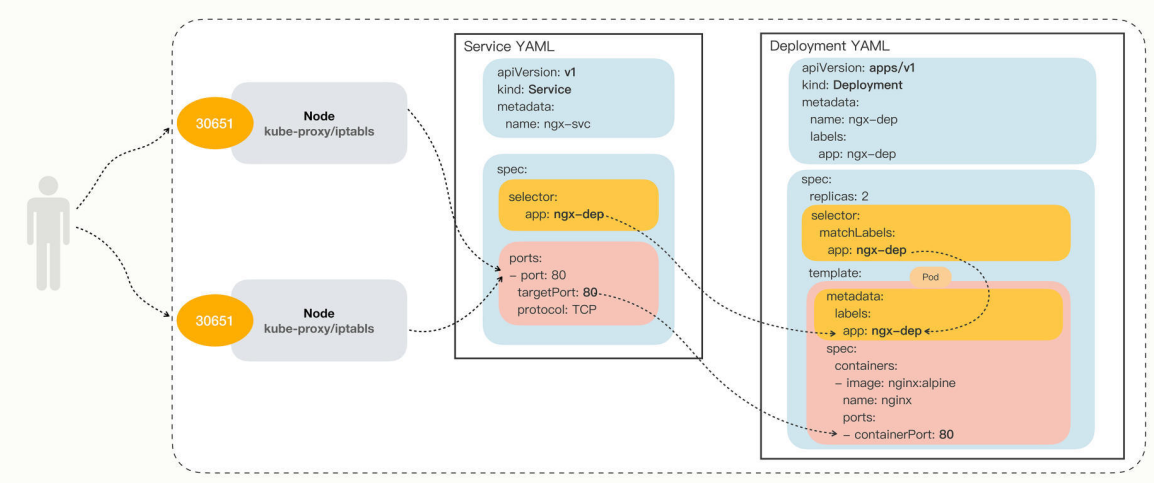
我把NodePort与Service、Deployment的对应关系画成了图,你看了应该就能更好地明白它的工作原理:
学到这里,你是不是觉得 NodePort 类型的 Service 很方便呢。不过它也有一些缺点:
- 第一个缺点是它的端口数量很有限。Kubernetes为了避免端口冲突,默认只在“30000~32767”这个范围内随机分配,只有2000多个,而且都不是标准端口号,这对于具有大量业务应用的系统来说根本不够用。
- 第二个缺点是它会在每个节点上都开端口,然后使用kube-proxy路由到真正的后端Service,这对于有很多计算节点的大集群来说就带来了一些网络通信成本,不是特别经济。
- 第三个缺点,它要求向外界暴露节点的IP地址,这在很多时候是不可行的,为了安全还需要在集群外再搭一个反向代理,增加了方案的复杂度。
虽然有这些缺点,但NodePort仍然是Kubernetes对外提供服务的一种简单易行的方式,在其他更好的方式出现之前,我们也只能使用它。
# 3.6 小结
这一大节学习的 Service 对象实现了负载均衡和服务发现技术,是 Kubernetes 应对微服务、服务网格等现代流行应用架构的解决方案。
- Pod的生命周期很短暂,会不停地创建销毁,所以就需要用Service来实现负载均衡,它由Kubernetes分配固定的IP地址,能够屏蔽后端的Pod变化。
- Service对象使用与Deployment、DaemonSet相同的“selector”字段,选择要代理的后端Pod,是松耦合关系。
- 基于DNS插件,我们能够以域名的方式访问Service,比静态IP地址更方便。
- 名字空间是Kubernetes用来隔离对象的一种方式,实现了逻辑上的对象分组,Service的域名里就包含了名字空间限定。
- Service的默认类型是“ClusterIP”,只能在集群内部访问,如果改成“NodePort”,就会在节点上开启一个随机端口号,让外界也能够访问内部的服务。
课外小贴士:
- iptables 基于 Linux 内核里的 netflter 模块,用来处理网络数据包,实现修改、过滤、地址转换等功能。
- 实际上 Service 并不直接管理 Pod,而是使用代表 IP 地址的 Endpoint 对象,但我们一般不会直接使用 Endpoint,除非是检查错误。
# 4. Ingress:集群进出流量的总管
Service 是 Kubernetes 内置的负载均衡机制,支持域名访问和服务发现,是微服务架构必需的基础设施,但也只能说是“基础设施”,它对网络流量的管理方案还是太简单,所以 Kubernetes 又在 Service 之上提出了新的概念:Ingress。相比 Service,Ingress 更接近实际业务,对它的开发、应用和讨论也是社区里最火爆的。
# 4.1 为什么要有 Ingress
Service 存在的问题:
上一节我们了解到,Service 的功能本质上就是一个由 kube-proxy 控制的四层均衡负载,在 TCP/IP 协议栈上转发流量:
但在四层上的负载均衡功能还是太有限了,只能够依据IP地址和端口号做一些简单的判断和组合,而我们现在的绝大多数应用都是跑在七层的HTTP/HTTPS协议上的,有更多的高级路由条件,比如主机名、URI、请求头、证书等等,而这些在TCP/IP网络栈里是根本看不见的。
Service 还有一个缺点,它比较适合代理集群内部的服务。如果想要把服务暴露到集群外部,就只能使用NodePort或者LoadBalancer这两种方式,而它们都缺乏足够的灵活性,难以管控,这就导致了一种很无奈的局面:我们的服务空有一身本领,却没有合适的机会走出去大展拳脚。
该怎么解决这个问题呢?
既然 Service 是四层的负载均衡,那 Kubernetes 再引入一个新的 API 对象,在七层上做负载均衡不是就可以了吗?
不过除了七层负载均衡,Ingress 还应该承担更多的职责,也就是作为流量的总入口,统管集群的进出口数据。Ingress 扇入、扇出流量,让外部用户能够安全、顺畅、便捷地访问内部服务:
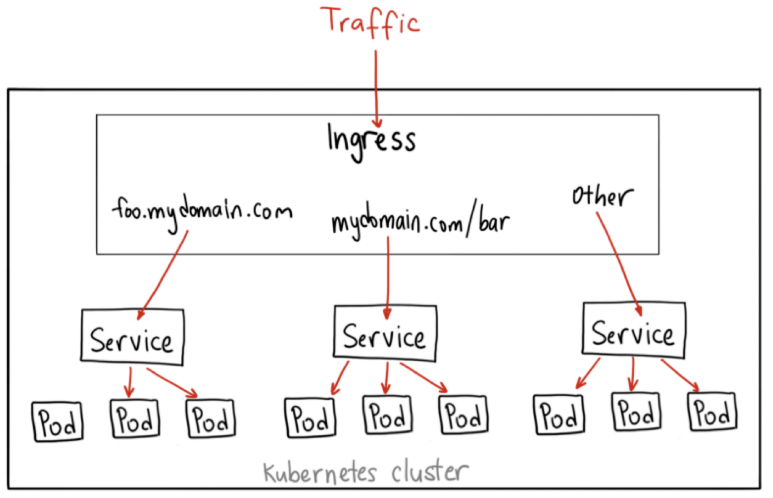
这个 API 对象被命名为 Ingress,意思就是集群内外边界上的入口。
# 4.2 为何要有 Ingress Controller
Ingress 可以说是在七层上另一种形式的 Service,它同样会代理一些后端的 Pod,也有一些路由规则来定义流量应该如何分配、转发,只不过这些规则都使用的是 HTTP/HTTPS 协议。
你应该知道,Service 本身是没有服务能力的,它只是一些 iptables 规则,真正配置、应用这些规则的实际上是节点里的kube-proxy组件。如果没有 kube-proxy,Service 定义得再完善也没有用。
同样的,Ingress 也只是一些 HTTP 路由规则的集合,相当于一份静态的描述文件,真正要把这些规则在集群里实施运行,还需要有另外一个东西,这就是 Ingress Controller,它的作用就相当于 Service 的 kube-proxy,能够读取、应用 Ingress 规则,处理、调度流量。
按理来说,Kubernetes 应该把 Ingress Controller 内置实现,作为基础设施的一部分,就像 kube-proxy 一样。不过 Ingress Controller 要做的事情太多,与上层业务联系太密切,所以 Kubernetes 把 Ingress Controller 的实现交给了社区,任何人都可以开发 Ingress Controller,只要遵守 Ingress 规则就好。这就造成了Ingress Controller“百花齐放”的盛况。
这些实现中最著名的,就是老牌的反向代理和负载均衡软件Nginx了。从Ingress Controller的描述上我们也可以看到,HTTP层面的流量管理、安全控制等功能其实就是经典的反向代理,而Nginx则是其中稳定性最好、性能最高的产品,所以它也理所当然成为了Kubernetes里应用得最广泛的Ingress Controller。不过,因为Nginx是开源的,谁都可以基于源码做二次开发,所以它又有很多的变种,比如社区的Kubernetes Ingress Controller( https://github.com/kubernetes/ingress-nginx (opens new window))、Nginx公司自己的Nginx Ingress Controller( https://github.com/nginxinc/kubernetes-ingress (opens new window))、还有基于OpenResty的Kong Ingress Controller( https://github.com/Kong/kubernetes-ingress-controller (opens new window))等等。
根据 DockerHub 上的统计,Nginx公司的开发实现是下载量最多的 Ingress Controller,所以下面将以它为例,讲解 Ingress 和 Ingress Controller 的用法。
下面这张图展示了 Ingress Controller 在 Kubernetes 集群里的地位:
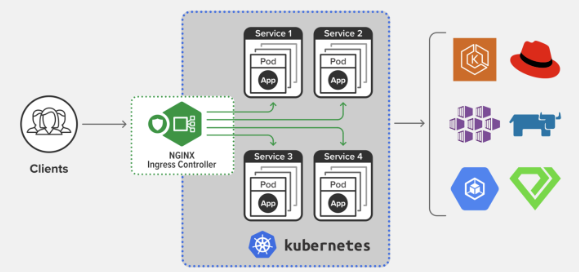
# 4.3 为何要有 Ingress Class
到现在,有了Ingress和Ingress Controller,我们是不是就可以完美地管理集群的进出流量了呢?最初Kubernetes也是这么想的,一个集群里有一个Ingress Controller,再给它配上许多不同的Ingress规则,应该就可以解决请求的路由和分发问题了。
但随着 Ingress 在实践中的大量应用,很多用户发现这种用法会带来一些问题,比如:
- 由于某些原因,项目组需要引入不同的Ingress Controller,但Kubernetes不允许这样做;
- Ingress规则太多,都交给一个Ingress Controller处理会让它不堪重负;
- 多个Ingress对象没有很好的逻辑分组方式,管理和维护成本很高;
- 集群里有不同的租户,他们对Ingress的需求差异很大甚至有冲突,无法部署在同一个Ingress Controller上。
所以,Kubernetes 就又提出了一个 Ingress Class 的概念,让它插在 Ingress 和 Ingress Controller 中间,作为流量规则和控制器的协调人,解除了 Ingress 和 Ingress Controller 的强绑定关系。
现在,Kubernetes 用户可以转向管理 Ingress Class,用它来定义不同的业务逻辑分组,简化 Ingress 规则的复杂度。比如说,我们可以用 Class A 处理博客流量、Class B 处理短视频流量、Class C 处理购物流量。
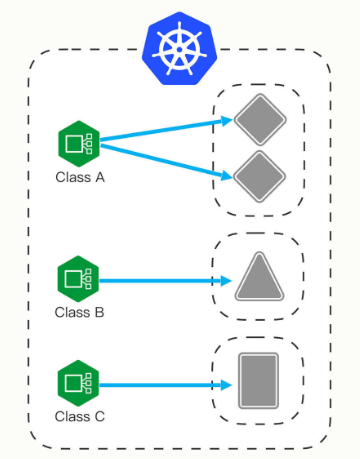
这些 Ingress 和 Ingress Controller 彼此独立,不会发生冲突,所以上面的那些问题也就随着 Ingress Class 的引入迎刃而解了。
# 4.4 用 YAML 描述 Ingress/Ingress Class
Ingress、 Ingress Controller、Ingress Class 这三个对象是社区经过长期讨论后达成的一致结论,是我们目前能获得的最佳解决方案。
现在来看一下如何编写他们的 YAML 描述文件。
使用 kubectl api-resources 可以查看他们的基本信息:
$ kubectl api-resources
NAME SHORTNAMES APIVERSION NAMESPACED KIND
ingresses ing networking.k8s.io/v1 true Ingress
ingressclasses networking.k8s.io/v1 false IngressClass
2
3
4
你可以看到,Ingress和Ingress Class的apiVersion都是“networking.k8s.io/v1”,而且Ingress有一个简写“ing”,但Ingress Controller怎么找不到呢?
这是因为Ingress Controller和其他两个对象不太一样,它不只是描述文件,是一个要实际干活、处理流量的应用程序,而应用程序在Kubernetes里早就有对象来管理了,那就是Deployment和DaemonSet,所以我们只需要再学习Ingress和Ingress Class的的用法就可以了。
# 4.4.1 Ingress
Ingress也是可以使用 kubectl create 来创建样板文件的,和Service类似,它也需要用两个附加参数:
--class,指定Ingress从属的Ingress Class对象。--rule,指定路由规则,基本形式是“URI=Service”,也就是说是访问HTTP路径就转发到对应的Service对象,再由Service对象转发给后端的Pod。
好,现在我们就执行命令,看看Ingress到底长什么样:
export out="--dry-run=client -o yaml"
kubectl create ing ngx-ing --rule="ngx.test/=ngx-svc:80" --class=ngx-ink $out
2
生成的 YAML 如下:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ngx-ing
spec:
ingressClassName: ngx-ink
rules:
- host: ngx.test
http:
paths:
- path: /
pathType: Exact
backend:
service:
name: ngx-svc
port:
number: 80
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
这里有两个关键字段:ingressClassName 和 rules,分别对应了命令行参数,含义还是比较好理解的。
只是“rules”的格式比较复杂,嵌套层次很深。不过仔细点看就会发现它是把路由规则拆散了,有host和http path,在path里又指定了路径的匹配方式,可以是精确匹配(Exact)或者是前缀匹配(Prefix),再用backend来指定转发的目标Service对象。个人觉得(作者觉得),Ingress YAML 里的描述还不如 kubectl create 命令行里的 --rule 参数来得直观易懂,而且 YAML 里的字段太多也很容易弄错,建议你还是让 kubectl 来自动生成规则,然后再略作修改比较好。
# 4.4.2 Ingress Class
有了 Ingress 对象,那么与它关联的 Ingress Class 是什么样的呢?
其实Ingress Class本身并没有什么实际的功能,只是起到联系Ingress和Ingress Controller的作用,所以它的定义非常简单,在“spec”里只有一个必需的字段“ controller”,表示要使用哪个Ingress Controller,具体的名字就要看实现文档了。
比如,如果我要用 Nginx 开发的 Ingress Controller,那么就要用名字“nginx.org/ingress-controller”:
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: ngx-ink
spec:
controller: nginx.org/ingress-controller
2
3
4
5
6
7
Ingress 和Service、Ingress Class 的关系画成一张图,如下:
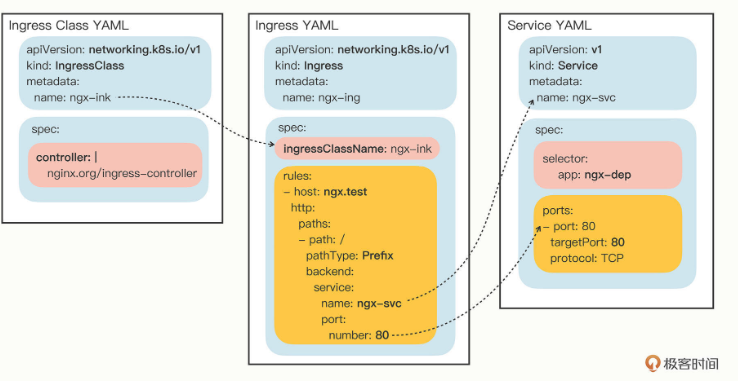
# 4.5 在 Kubernetes 里使用 Ingress/Ingress Class
因为 Ingress Class 很小,所以我把它与 Ingress 合成了一个 YAML 文件,让我们用 kubectl apply 创建这两个对象:
kubectl apply -f ingress.yml
然后我们用 kubectl get 来查看对象的状态:
kubectl get ingressclass
kubectl get ing
2

命令 kubectl describe 可以看到更详细的 Ingress 信息:
kubectl describe ing ngx-ing
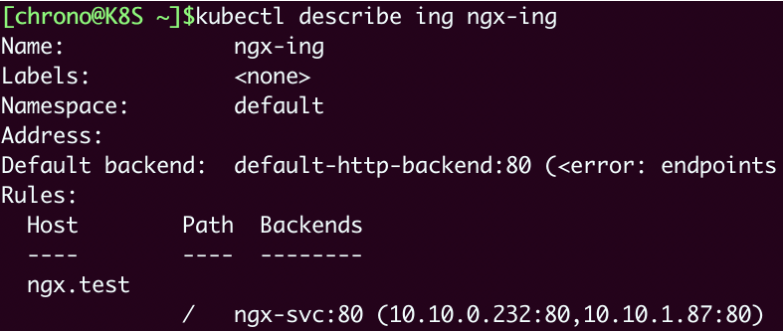
可以看到,Ingress 对象的路由规则 Host/Path 就是在 YAML 里设置的域名“ngx.test/”,而且已经关联了之前创建的 Service 对象,还有 Service 后面的两个 Pod。
另外,不要对Ingress里“Default backend”的错误提示感到惊讶,在找不到路由的时候,它被设计用来提供一个默认的后端服务,但不设置也不会有什么问题,所以大多数时候我们都忽略它。
# 4.6 在 Kubernetes 里使用 Ingress Controller
准备好了 Ingress 和 Ingress Class,接下来我们就需要部署真正处理路由规则的 Ingress Controller。
你可以在GitHub上找到Nginx Ingress Controller的项目( https://github.com/nginxinc/kubernetes-ingress (opens new window)),因为它以Pod的形式运行在Kubernetes里,所以同时支持Deployment和DaemonSet两种部署方式。这里我选择的是Deployment,相关的YAML也都在我们课程的项目( https://github.com/chronolaw/k8s_study/tree/master/ingress (opens new window))里复制了一份。
Nginx Ingress Controller的安装略微麻烦一些,有很多个YAML需要执行,但如果只是做简单的试验,就只需要用到4个YAML:
kubectl apply -f common/ns-and-sa.yaml
kubectl apply -f rbac/rbac.yaml
kubectl apply -f common/nginx-config.yaml
kubectl apply -f common/default-server-secret.yaml
2
3
4
前两条命令为Ingress Controller创建了一个独立的名字空间“nginx-ingress”,还有相应的账号和权限,这是为了访问apiserver获取Service、Endpoint信息用的;后两条则是创建了一个ConfigMap和Secret,用来配置HTTP/HTTPS服务。
部署Ingress Controller不需要我们自己从头编写Deployment,Nginx已经为我们提供了示例YAML,但创建之前为了适配我们自己的应用还必须要做几处小改动:
- metadata里的name要改成自己的名字,比如
ngx-kic-dep。 - spec.selector和template.metadata.labels也要修改成自己的名字,比如还是用
ngx-kic-dep。 - containers.image可以改用apline版本,加快下载速度,比如
nginx/nginx-ingress:2.2-alpine。 - 最下面的args要加上
-ingress-class=ngx-ink,也就是前面创建的Ingress Class的名字,这是让Ingress Controller管理Ingress的关键。
修改完之后,Ingress Controller的YAML大概是这个样子:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ngx-kic-dep
namespace: nginx-ingress
spec:
replicas: 1
selector:
matchLabels:
app: ngx-kic-dep
template:
metadata:
labels:
app: ngx-kic-dep
...
spec:
containers:
- image: nginx/nginx-ingress:2.2-alpine
...
args:
- -ingress-class=ngx-ink
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
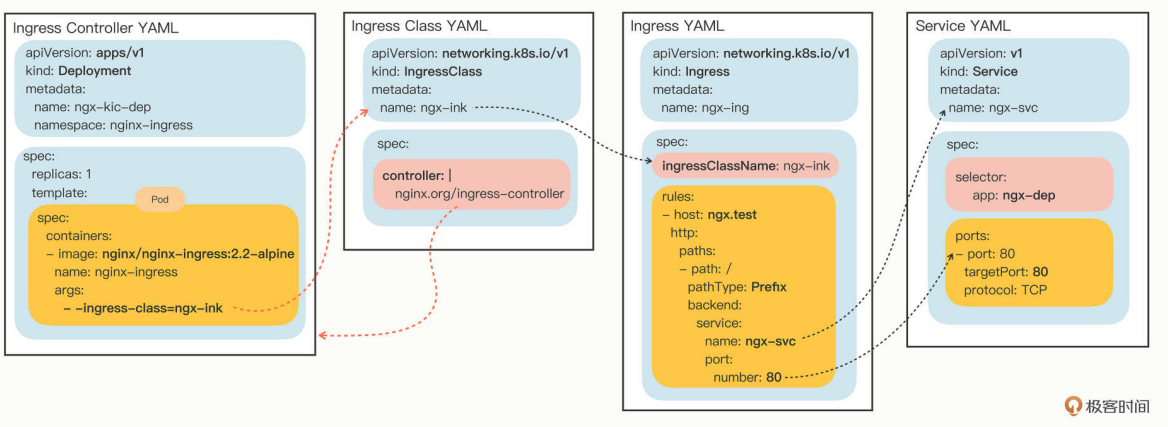
有了Ingress Controller,这些API对象的关联就更复杂了,你可以用下面的这张图来看出它们是如何使用对象名字联系起来的:
确认Ingress Controller 的YAML修改完毕之后,就可以用 kubectl apply 创建对象:
kubectl apply -f kic.yml
注意Ingress Controller位于名字空间“nginx-ingress”,所以查看状态需要用“-n”参数显式指定,否则我们只能看到“default”名字空间里的Pod:
kubectl get deploy -n nginx-ingress
kubectl get pod -n nginx-ingress
2
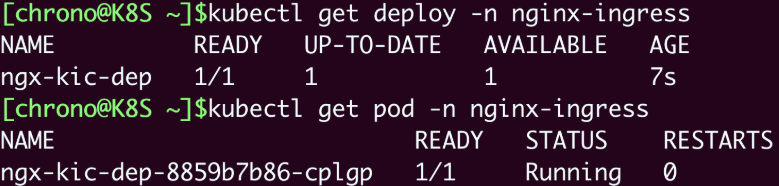
现在Ingress Controller就算是运行起来了。
不过还有最后一道工序,因为Ingress Controller本身也是一个Pod,想要向外提供服务还是要依赖于Service对象。所以你至少还要再为它定义一个Service,使用NodePort或者LoadBalancer暴露端口,才能真正把集群的内外流量打通。这个工作就交给你课下自己去完成了。
这里使用 kubectl port-forward 来把本地的端口映射到Kubernetes集群的某个Pod里,在测试验证的时候非常方便。
下面这条命令就把本地的8080端口映射到了Ingress Controller Pod的80端口:
kubectl port-forward -n nginx-ingress ngx-kic-dep-8859b7b86-cplgp 8080:80 &

我们在curl发测试请求的时候需要注意,因为Ingress的路由规则是HTTP协议,所以就不能用IP地址的方式访问,必须要用域名、URI。
你可以修改 /etc/hosts 来手工添加域名解析,也可以使用 --resolve 参数,指定域名的解析规则,比如在这里我就把“ngx.test”强制解析到“127.0.0.1”,也就是被 kubectl port-forward 转发的本地地址:
curl --resolve ngx.test:8080:127.0.0.1 http://ngx.test:8080
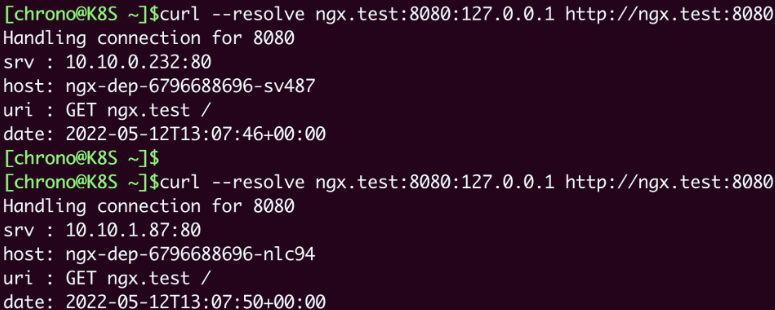
把这个访问结果和上一节课里的Service对比一下,你会发现最终效果是一样的,都是把请求转发到了集群内部的Pod,但Ingress的路由规则不再是IP地址,而是HTTP协议里的域名、URI等要素。
# 4.7 小结
这一大节学习了Kubernetes里七层的反向代理和负载均衡对象,包括Ingress、Ingress Controller、Ingress Class,它们联合起来管理了集群的进出流量,是集群入口的总管。
- Service是四层负载均衡,能力有限,所以就出现了Ingress,它基于HTTP/HTTPS协议定义路由规则。
- Ingress只是规则的集合,自身不具备流量管理能力,需要Ingress Controller应用Ingress规则才能真正发挥作用。
- Ingress Class解耦了Ingress和Ingress Controller,我们应当使用Ingress Class来管理Ingress资源。
- 最流行的Ingress Controller是Nginx Ingress Controller,它基于经典反向代理软件Nginx。
再补充一点,目前的Kubernetes流量管理功能主要集中在Ingress Controller上,已经远不止于管理“入口流量”了,它还能管理“出口流量”,也就是 egress,甚至还可以管理集群内部服务之间的“东西向流量”。
此外,Ingress Controller通常还有很多的其他功能,比如TLS终止、网络应用防火墙、限流限速、流量拆分、身份认证、访问控制等等,完全可以认为它是一个全功能的反向代理或者网关,感兴趣的话你可以找找这方面的资料。
课外小贴士:
- 所谓的“四层”、“七层”指的是 OSI 网络参考模型里的层次,简单来说,四层就是 TCP/IP 协议,七层就是 HTTP/HTTPS 等应用协议。
- 因为 Ingress Controller 的名字比较长,所以有的时候会缩写成 IC 或者 KIC。
- 为了提升路由效率,降低网络成本,IngressController 通常不会走 Service 流量转发,而是访问 apiserver 直接获得 Service 代理的 Pod 地址,从而绕过了 Service 的 iptables 规则。
- Ingress 的能力较弱,路由规则不灵活,所以 IngressController 基本上都有各自的功能扩展,比如 Nginx 就增加了自定义资源对象 VirtualServer、Transport-Server 等。