 YAML、Pod、Job、CronJob、ConfigMap、Secret
YAML、Pod、Job、CronJob、ConfigMap、Secret
参考:Kubernetes 入门实战课 | 极客时间 (opens new window) 第 11-16 讲
# 1. YAML:Kubernetes 世界里的通用语
# 1.1 声明式与命令式
Dockerfile 属于命令式(imperative),告诉了计算机每步怎么做,而 Kubernetes 的 YAML 属于声明式(declarative),它告诉了计算机一个目标状态,并让计算机想办法去完成任务。
# 1.2 什么是 YAML
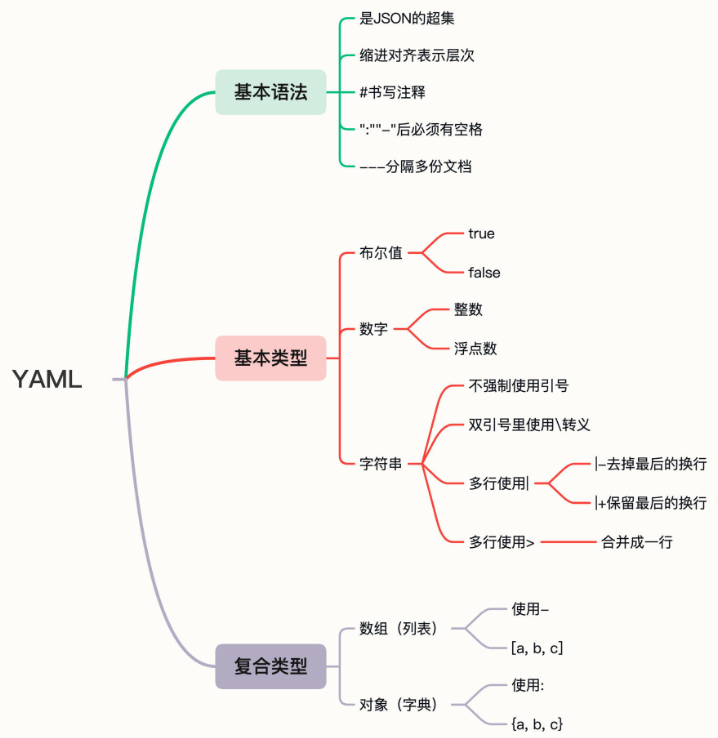
YAML 是 JSON 的超集,即任何合法的 JSON 文档也都是 YAML 文档。但 YAML 语法更简单紧凑:
- 使用空白与缩进表示层次(有点类似Python),可以不使用花括号和方括号。
- 可以使用
#书写注释,比起JSON是很大的改进。 - 对象(字典)的格式与JSON基本相同,但Key不需要使用双引号。
- 数组(列表)是使用
-开头的清单形式(有点类似MarkDown)。 - 表示对象的
:和表示数组的-后面都必须要有空格。 - 可以使用
---在一个文件里分隔多个YAML对象。
关于 YAML 的知识整理如下图:
# 1.3 什么是 API 对象
我们需要在 YAML 中声明哪些东西呢?Kubernetes 在理论层面抽象出了很多个概念用来描述系统的管理运维工作,这些概念就叫做 API 对象,之前提到的组件 apiserver 的名字也是来源于它。
因为apiserver是Kubernetes系统的唯一入口,外部用户和内部组件都必须和它通信,而它采用了HTTP协议的URL资源理念,API风格也用RESTful的GET/POST/DELETE等等,所以,这些概念很自然地就被称为是“API对象”了。
有哪些 API 对象呢?可以使用命令 kubectl api-resources 查看当前 k8s 支持的所有对象:
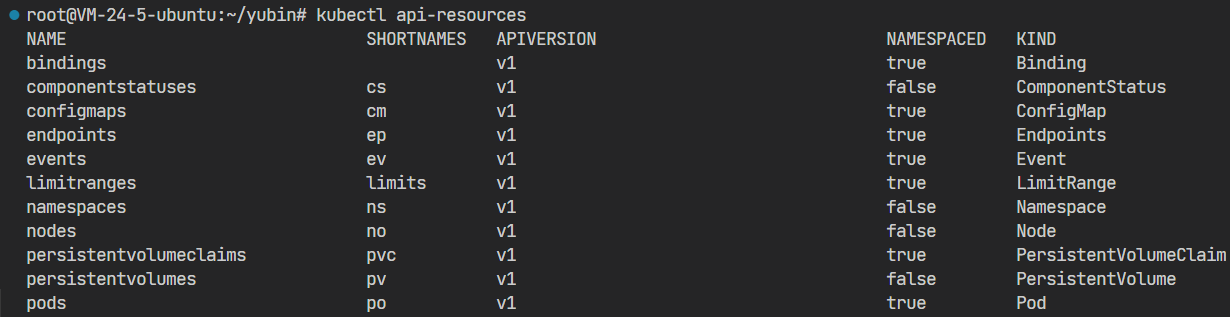
在输出的“NAME”一栏,就是对象的名字,比如ConfigMap、Pod、Service等等,第二栏“SHORTNAMES”则是这种资源的简写,在我们使用kubectl命令的时候很有用,可以少敲几次键盘,比如Pod可以简写成po,Service可以简写成svc。
在使用kubectl命令的时候,你还可以加上一个参数 --v=9,它会显示出详细的命令执行过程,清楚地看到发出的HTTP请求,比如:
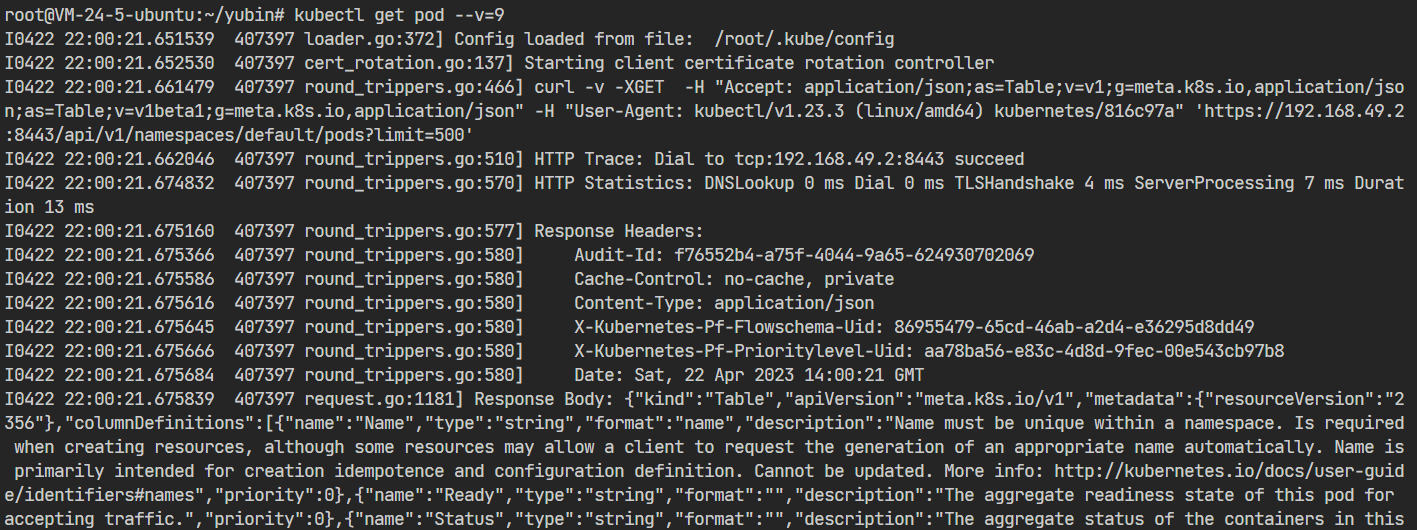
从截图里可以看到,kubectl 客户端等价于调用了 curl,向 8443 端口发送了 HTTP GET 请求,URL 是 /api/v1/namespaces/default/pods。
目前的Kubernetes 1.23版本有50多种API对象,全面地描述了集群的节点、应用、配置、服务、账号等等信息,apiserver会把它们都存储在数据库etcd里,然后kubelet、scheduler、controller-manager等组件通过apiserver来操作它们,就在API对象这个抽象层次实现了对整个集群的管理。
# 1.4 如何描述 API 对象
之前我们使用 kubectl 运行 nginx 的命令用的是命令式的 kubectl run:
kubectl run ngx --image=nginx:alpine
下面看一下如何以 YAML 语言来声明式地在 k8s 中描述并创建 API 对象。在 YAML 中,我们需要说清楚我们的目标状态,让 Kubernetes 自己去决定如何拉取镜像并运行:
apiVersion: v1
kind: Pod
metadata:
name: ngx-pod
labels:
env: demo
owner: chrono
spec:
containers:
- image: nginx:alpine
name: ngx
ports:
- containerPort: 80
2
3
4
5
6
7
8
9
10
11
12
13
14
可以看出,这里是创建一个 pod,要使用 nginx:alpine 的 image 来创建一个 container,并开放 80 端口,而其他部分就是 k8s 对 API 对象强制的格式要求了。
因为API对象采用标准的 HTTP 协议,为了方便理解,我们可以借鉴一下 HTTP 的报文格式,把 API 对象的描述分成“header”和“body”两部分。
header 包含的是 API 对象的基本信息,有三个字段:
- apiVersion:表示操作这种资源的 API 版本号,由于 Kubernetes 的迭代速度很快,不同的版本创建的对象会有差异,为了区分这些版本就需要使用 apiVersion 这个字段,比如 v1、v1alpha1、v1beta1 等等。
- kind:表示资源对象的类型,比如 Pod、Node、Job、Service 等。
- metadata:表示的是资源的一些元信息,也就是用来标记对象,方便 Kubernetes 管理的一些信息。在上面的示例中有两个元信息:
- name:给 pod 起了个名字
- labels:给 pod 贴上一些便于查找的标签,分别是
env和owner。
以上信息都被 kubectl 用于生成 HTTP 请求发给 apiserver,你可以用 --v=9 参数在请求的 URL 里看到它们,比如:
https://192.168.49.2:8443/api/v1/namespaces/default/pods/ngx-pod
header 中的 apiVersion、kind、metadata 这三个字段都是任何对象都必须有的,而 body 部分则会与对象特定相关,每种对象会有不同的规格定义,在 YAML 里就表现为 spec 字段(即 specification),表示我们对对象的“期望状态”(desired status)。
还是来看这个 Pod,它的 spec 里就是一个 containers 数组,里面的每个元素又是一个对象,指定了名字、镜像、端口等信息:
spec:
containers:
- image: nginx:alpine
name: ngx
ports:
- containerPort: 80
2
3
4
5
6
现在把这些字段综合起来,我们就能够看出,这份 YAML 文档完整地描述了一个类型是 Pod 的 API 对象,要求使用 v1 版本的 API 接口去管理,其他更具体的名称、标签、状态等细节都记录在了 metadata 和 spec 字段等里。
使用 kubectl apply、 kubectl delete,再加上参数 -f,你就可以使用这个 YAML 文件,创建或者删除对象了:
kubectl apply -f ngx-pod.yml # 创建 API 对象
kubectl delete -f ngx-pod.yml # 删除 API 对象
2
Kubernetes 收到这份“声明式”的数据,再根据 HTTP 请求里的 POST/DELETE 等方法,就会自动操作这个资源对象,至于对象在哪个节点上、怎么创建、怎么删除完全不用我们操心。
# 1.5 如何编写 YAML
这么多字段,我们怎样才能编写正确的 YAML 呢?
这个问题的最权威的答案自然是 k8s 的官方文档 (opens new window),API 对象的所有字段都可以在里面找到。但这内容太多,下面介绍一些实用的小技巧。
第一个技巧其实前面已经说过了,就是 kubectl api-resources 命令,它会显示出资源对象相应的API版本和类型,比如Pod的版本是“v1”,Ingress的版本是“networking.k8s.io/v1”,照着它写绝对不会错。
第二个技巧,是命令 kubectl explain,它相当于是Kubernetes自带的API文档,会给出对象字段的详细说明,这样我们就不必去网上查找了。比如想要看Pod里的字段该怎么写,就可以这样:
kubectl explain pod
kubectl explain pod.metadata
kubectl explain pod.spec
kubectl explain pod.spec.containers
2
3
4
使用前两个技巧编写 YAML 就基本上没有难度了。
⭐️ 第三个技巧就是kubectl的两个特殊参数 --dry-run=client 和 -o yaml,前者是空运行,后者是生成YAML格式,结合起来使用就会让 kubectl 不会有实际的创建动作,而只生成 YAML 文件。例如,想要生成一个Pod的YAML样板示例,可以在 kubectl run 后面加上这两个参数:
kubectl run ngx --image=nginx:alpine --dry-run=client -o yaml
就会生成一个绝对正确的 YAML 文件:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: ngx
name: ngx
spec:
containers:
- image: nginx:alpine
name: ngx
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
接下来你要做的,就是查阅对象的说明文档,添加或者删除字段来定制这个 YAML 了。
这个小技巧还可以再进化一下,把这段参数定义成Shell变量(名字任意,比如$do/$go,这里用的是 $out),用起来会更省事,比如:
export out="--dry-run=client -o yaml"
kubectl run ngx --image=nginx:alpine $out
2
今后除了一些特殊情况,我们都不会再使用 kubectl run 这样的命令去直接创建 Pod,而是会编写 YAML,用“声明式”来描述对象,再用 kubectl apply 去发布 YAML 来创建对象。
# 1.6 课外小贴士
- Kubernetes 的 AP 版本命名有明确规范,正式版本(GA,Generally available) 是 v1 这样的纯数字,试验性质、不稳定的是 alpha,比较稳定、即将发布的是 beta。
- 因为 Kubernetes 的开发语言是 Go,所以 API 对象字段用的都是 Go 语法规范,例如字段命名遵循“Camel Case”,类型是 boolean、string、[]Object 等。
# 2. Pod:Kubernetes 里最核心的概念
为什么 Kubernetes 不直接使用 container,而是还是再抽象出一个 Pod 对象?
# 2.1 为什么要有 Pod?
Pod 原意是“豌豆荚”,看一下下面这个图片,每一颗豌豆就像一个容器,Pod 就是包含了很多成员的一种结构:

容器让进程运行在一个沙盒环境里,但当进入生产环境时,这种隔离性带来了不少麻烦,因为大多数任务都是需要多个进程相互协作来完成。而容器的理念又希望每个 container 里只运行一个进程。为了解决这样多应用联合运行的问题,同时还要不破坏容器的隔离,就需要在容器外面再建立一个“收纳舱”,这就是 Pod 概念的提出。容器正是“豆荚”里那些小小的“豌豆”,你可以在Pod的YAML里看到,“spec.containers”字段其实是一个数组,里面允许定义多个容器。
# 2.2 为什么 Pod 是 Kubernetes 的核心对象
Pod 是对容器的打包,里面的容器是一个整体,总是能够一起调度、一起运行,绝不会出现分离的情况。Kubernetes 让 Pod 去编排处理容器,并把 Pod 作为应用调度部署的最小单位,因此它也成了 Kubernetes 世界里的“原子”,基于 Pod 就可以构建出更多更复杂的业务形态了。
下面的这张图显示了从 Pod 开始,扩展出了Kubernetes里的一些重要API对象,比如配置信息ConfigMap、离线作业Job、多实例部署Deployment等等,它们都分别对应到现实中的各种实际运维需求:
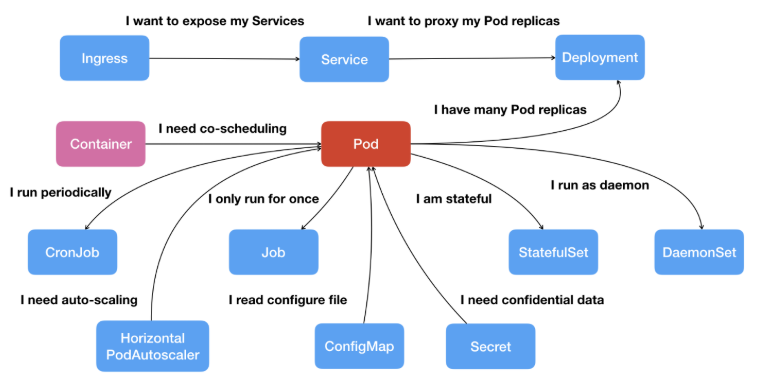
尽管这张图很经典,但随着 Kubernetes 的多年发展,它已经不能全面描述 Kubernetes 的资源对象了。
基于此,我(专栏作者)又重画了一份以 Pod 为中心的 Kubernetes 资源对象关系图,下面的介绍将基于此图来探索各项功能。
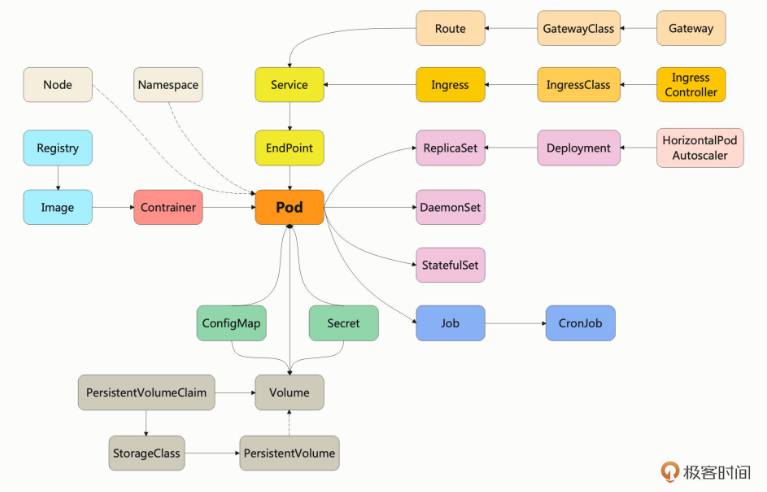
由此可以看出,Kubernetes 的资源都直接或间接地依附在 Pod 之上,所有的 Kubernetes 功能都必须通过 Pod 来实现,所以 Pod 理所当然地成为了 Kubernetes 的核心对象。
# 2.3 如何使用 YAML 描述 Pod?
这里只介绍一些 YAML 中的常用字段,详细说明可以通过 kubectl explain 来查看。
因为 Pod 也是 API 对象,所以也必然具有 apiVersion、kind、metadata 和 spec 四个基本组成部分:
- apiVersion:固定
v1 - kind:固定
Pod - metadata:一般由 name 和 labels 两个字段
- name:给 Pod 起一个名字(必须),本课程为了与其他资源区分,Pod 的名字均加了一个 -pod 后缀。
- labels:可以添加任意数量的 key-value,给 Pod 贴上归类的标签,结合 name 就更方便识别和管理了。
在 labels 中,我们可以根据运行环境,使用 label
env=dev/test/prod,根据所在的数据中心,使用 labelregion=north/south,根据应用在系统中的层次,使用tier=front/middle/back等待。
下面这段 YAML 就描述了一个简单的 Pod:
apiVersion: v1
kind: Pod
metadata:
name: busy-pod
labels:
owner: chrono
env: demo
region: north
tier: back
2
3
4
5
6
7
8
9
spec 字段由于需要管理、维护 Pod 这 Kubernetes 的基本调度单元,里面有非常多的关键信息,今天只介绍最重要的 containers 字段部分,其余的 hostname、restartPolicy 等字段可以查阅相关文档。
“containers”是一个数组,里面的每一个元素又是一个 container 对象,也就是容器。
一个 container 对象必须也要有个 name 表示名字,有个 image 表示使用的镜像,这两个是必须要有的,其余的字段与 docker 的差不多了:
- ports:列出容器对外暴露的端口,和Docker的
-p参数有点像。 - imagePullPolicy:指定镜像的拉取策略,可以是Always/Never/IfNotPresent,一般默认是IfNotPresent,也就是说只有本地不存在才会远程拉取镜像,可以减少网络消耗。
- env:定义Pod的环境变量,和Dockerfile里的
ENV指令有点类似,但它是运行时指定的,更加灵活可配置。 - command:定义容器启动时要执行的命令,相当于Dockerfile里的
ENTRYPOINT指令。 - args:它是command运行时的参数,相当于Dockerfile里的
CMD指令,这两个命令和Docker的含义不同,要特别注意。
下面是 busy-pod 的 spec 部分:
spec:
containers:
- image: busybox:latest
name: busy
imagePullPolicy: IfNotPresent
env:
- name: os
value: "ubuntu"
- name: debug
value: "on"
command:
- /bin/echo
args:
- "$(os), $(debug)"
2
3
4
5
6
7
8
9
10
11
12
13
14
这里我为Pod指定使用镜像busybox:latest,拉取策略是 IfNotPresent ,然后定义了 os 和 debug 两个环境变量,启动命令是 /bin/echo,参数里输出刚才定义的环境变量。
可以看到这份 YAML 文件把容器的运行状态描述地很清晰,比 docker run 的命令行要清晰地多。
# 2.4 如何使用 kubectl 来操作 Pod
- 指定 YAML 文件来创建 Pod:
kubectl apply -f busy-pod.yml - 指定 YAML 文件来删除 Pod:
kubectl delete -f busy-pod.yml - 根据 Pod 的 name 来删除:
kubectl delete pod busy-pod
由于 Kubernetes 的 Pod 不会在前台运行,只能后台运行,如果想看日志,可以使用命令 kubectl logs <pod-name>。
- 查看 Pod 列表和运行状态:
kubectl get pod - 查看某个 Pod 的详细状态(用于调试排错):
kubectl describe pod busy-pod
在使用 kubectl describe 时,通常只需要关注末尾的 “Events” 部分,它显示的是Pod运行过程中的一些关键节点事件:

kubectl 也提供了类似 docker 的 cp 与 exec 命令:
kubectl cp:把本地文件拷贝进 Podkubectl exec:进入 Pod 内部执行 shell 命令,用法也差不多
cp 与 exec 的使用示例
比如我有一个“a.txt”文件,那么就可以使用 kubectl cp 拷贝进Pod的“/tmp”目录里:
echo 'aaa' > a.txt
kubectl cp a.txt ngx-pod:/tmp
2
不过 kubectl exec 的命令格式与Docker有一点小差异,需要在Pod后面加上 --,把kubectl的命令与Shell命令分隔开,你在用的时候需要小心一些:
kubectl exec -it ngx-pod -- sh
准确地说,kubectl cp 和 kubectl exec 操作的应该是 Pod 里的容器,需要用“-c”参数指定容器名,不过因为大多数 Pod 里只有一个容器,所以就省略了。
# 2.5 小结
相比于 container 的“细粒度”,VM 的”粗粒度“,Pod 可以说是”中粒度“,灵活又轻便,非常适合在云计算领域作为应用调度的基本单元。
虽然 Pod 是 Kubernetes 的核心概念,非常重要,但事实上在 Kubernetes 里通常并不会直接创建 Pod,因为它只是对容器做了简单的包装,比较脆弱,离复杂的业务需求还有些距离,需要 Job、CronJob、Deployment 等其他对象增添更多的功能才能投入生产使用。
课外小贴士:
- Pod 内部有一个名为 infra 的容器,它实际上代表了Pod,维护着 Pod 内多容器共享的主机名、网络和存储。infra 容器的镜像叫“pause”,非常小,只有不到 500KB。
- 对于确实不需要重启的 Pod,可以配置字段 “re-startPolicy: Never“
- 准确地说,“kubectl cp”“kubectl exec”操作的应该是 Pod 里的容器,需要用“-c”参数指定容器名,不过因为大多数 Pod 里只有一个容器,所以就省略了。
# 3. Job/CronJob:为什么不直接用 Pod 来处理业务?
# 3.1 为什么不直接使用 Pod
现在你应该知道,Kubernetes 使用的是 RESTful API,把集群中的各种业务都抽象为 HTTP 资源对象,那么在这个层次之上,我们就可以使用面向对象的方式来考虑问题。
虽然面向对象的设计思想多用于软件开发,但它放到Kubernetes里却意外地合适。因为Kubernetes使用YAML来描述资源,把业务简化成了一个个的对象,内部有属性,外部有联系,也需要互相协作,只不过我们不需要编程,完全由Kubernetes自动处理。
面向对象的设计有许多基本原则,其中有两条我认为比较恰当地描述了Kubernetes对象设计思路,一个是单一职责,另一个是组合优于继承:
- 单一职责:对象应该只专注于做好一件事情,不要贪大求全,保持足够小的粒度才更方便复用和管理。
- 组合优于继承:尽量让对象在运行时产生联系,保持松耦合,而不要用硬编码的方式固定对象的关系。
应用这两条原则,我们再来看Kubernetes的资源对象就会很清晰了。因为Pod已经是一个相对完善的对象,专门负责管理容器,那么我们就不应该再“画蛇添足”地盲目为它扩充功能,而是要保持它的独立性,容器之外的功能就需要定义其他的对象,把Pod作为它的一个成员“组合”进去。
这样每种Kubernetes对象就可以只关注自己的业务领域,只做自己最擅长的事情,其他的工作交给其他对象来处理,既不“缺位”也不“越位”,既有分工又有协作,从而以最小成本实现最大收益。
# 3.2 为什么要有 Job/CronJob
现在学习两个新对象:Job 和 CronJob,他们组合了 Pod,实现了对离线业务的处理。
Kubernetes 里有两大类业务:
- 在线业务:像 Nginx、MySQL 一样,一旦运行基本不会停止
- 离线业务:比如日志分析、视频转码等任务,虽然具有一些计算量,但也只会运行一段时间,必定会退出。所以它的调度策略也就与“在线业务”存在很大的不同,需要考虑运行超时、状态检查、失败重试、获取计算结果等管理事项。
离线业务也可以分为两种,一种是临时任务,跑完就完事了;一种是定时任务,可以按时按点周期运行,不需要过多干预。
在 Kubernetes 中,临时任务就是 API 对象 Job,定时任务就是 API 对象 CronJob,使用这两个对象你就能够在 Kubernetes 里调度管理任意的离线业务了。
# 3.3 Job
# 3.3.1 如何使用 YAML 描述 Job?
Job 的 YAML 开头部分还是那几个必备字段:
- apiVersion不是
v1,而是batch/v1。 - kind是
Job,这个和对象的名字是一致的。 - metadata里仍然要有
name标记名字,也可以用labels添加任意的标签。
注意如果想生成 YAML 模板,就不能使用 kubectl run 了,因为它只能创建 Pod,想要创建 Pod 以外的其他对象的话,可以使用命令
kubectl create <对象名>
比如用 busybox 创建一个“echo-job”,命令就是这样的:
export out="--dry-run=client -o yaml" # 定义Shell变量
kubectl create job echo-job --image=busybox $out
2
会生成一个基本的YAML文件,保存之后做点修改,就有了一个Job对象:
apiVersion: batch/v1
kind: Job
metadata:
name: echo-job
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- image: busybox
name: echo-job
imagePullPolicy: IfNotPresent
command: ["/bin/echo"]
args: ["hello", "world"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
你会注意到Job的描述与Pod很像,但又有些不一样,主要的区别就在“spec”字段里,多了一个 template 字段,然后又是一个“spec”,显得有点怪。
如果你理解了刚才说的面向对象设计思想,就会明白这种做法的道理。它其实就是在Job对象里应用了组合模式, template 字段定义了一个“ 应用模板”,里面嵌入了一个Pod,这样Job就可以从这个模板来创建出Pod。
而这个Pod因为受Job的管理控制,不直接和apiserver打交道,也就没必要重复apiVersion等“头字段”,只需要定义好关键的 spec,描述清楚容器相关的信息就可以了,可以说是一个“无头”的Pod对象。
为了辅助你理解,我把 Job 对象重新组织了一下,用不同的颜色来区分字段,这样你就能够很容易看出来,其实这个“echo-job”里并没有太多额外的功能,只是把 Pod 做了个简单的包装:

因为 Job 业务的特殊性,所以我们还要在 spec 里多加一个字段 restartPolicy,确定 Pod 运行失败时的策略, OnFailure 是失败原地重启容器,而 Never 则是不重启容器,让 Job 去重新调度生成一个新的 Pod。
# 3.3.2 如何在 Kubernetes 里操作 Job?
运行这个离线作业的命令还是 kubectl apply:
kubectl apply -f job.yml
创建之后 Kubernetes 就会从 YAML 的模板定义中提取 Pod,在 Job 的控制下运行 Pod,你可以用 kubectl get job、 kubectl get pod 来分别查看 Job 和 Pod 的状态:
$ kubectl get job
NAME COMPLETIONS DURATION AGE
echo-job 1/1 18s 33s
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
echo-job-bz69d 0/1 Completed 0 59s
2
3
4
5
6
7
可以看到,因为Pod被Job管理,它就不会反复重启报错了,而是会显示为 Completed 表示任务完成,而Job里也会列出运行成功的作业数量,这里只有一个作业,所以就是 1/1。
你还可以看到,Pod 被自动关联了一个名字,用的是Job的名字(echo-job)再加上一个随机字符串(pb5gh),这当然也是Job管理的“功劳”,免去了我们手工定义的麻烦,这样我们就可以使用命令 kubectl logs 来获取Pod的运行结果:
$ kubectl logs echo-job-bz69d
hello world
2
Kubernetes 支持在 Job 级别上添加更多字段来控制离线作业,其他更详细的可以参考 Job 文档:
- activeDeadlineSeconds,设置Pod运行的超时时间。
- backoffLimit,设置Pod的失败重试次数。
- completions,Job完成需要运行多少个Pod,默认是1个。
- parallelism,它与completions相关,表示允许并发运行的Pod数量,避免过多占用资源。
要注意这4个字段并不在 template 字段下,而是在 spec 字段下,所以它们是属于 Job 级别的,用来控制模板里的 Pod 对象。
下面我再创建一个Job对象,名字叫“sleep-job”,它随机睡眠一段时间再退出,模拟运行时间较长的作业(比如MapReduce)。Job的参数设置成15秒超时,最多重试2次,总共需要运行完4个Pod,但同一时刻最多并发2个Pod:
apiVersion: batch/v1
kind: Job
metadata:
name: sleep-job
spec:
activeDeadlineSeconds: 15
backoffLimit: 2
completions: 4
parallelism: 2
template:
spec:
restartPolicy: OnFailure
containers:
- image: busybox
name: echo-job
imagePullPolicy: IfNotPresent
command:
- sh
- -c
- sleep $(($RANDOM % 10 + 1)) && echo done
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
使用 kubectl apply 创建Job之后,我们可以用 kubectl get pod -w 来实时观察 Pod 的状态,看到 Pod 不断被排队、创建、运行的过程。等运行完在 kubectl get 来看一下:
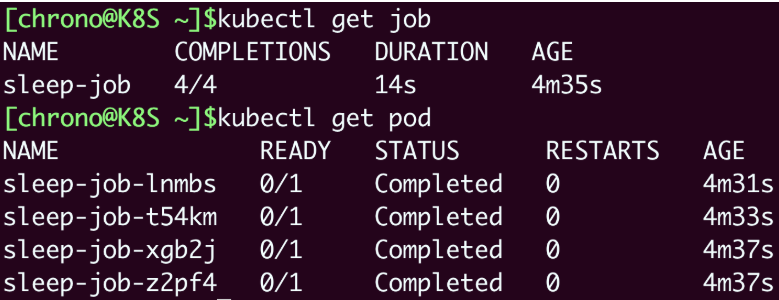
就会看到Job的完成数量如同我们预期的是4,而4个Pod也都是完成状态。
显然,“声明式”的Job对象让离线业务的描述变得非常直观,简单的几个字段就可以很好地控制作业的并行度和完成数量,不需要我们去人工监控干预,Kubernetes把这些都自动化实现了。
# 3.4 CronJob
我们可以直接使用 kubectl create 来创建 CronJob 的样板:
要注意两点:
- 因为 CronJob 的名字有点长,所以 Kubernetes 提供了简写
cj,这个简写也可以使用命令kubectl api-resources看到。- CronJob 需要定时运行,所以我们在命令行里还需要指定参数
--schedule。
export out="--dry-run=client -o yaml" # 定义Shell变量
kubectl create cj echo-cj --image=busybox --schedule="" $out
2
然后我们编辑这个 YAML 样板,生成 CronJob 对象:
apiVersion: batch/v1
kind: CronJob
metadata:
name: echo-cj
spec:
schedule: '*/1 * * * *'
jobTemplate:
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- image: busybox
name: echo-cj
imagePullPolicy: IfNotPresent
command: ["/bin/echo"]
args: ["hello", "world"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
我们还是重点关注它的 spec 字段,你会发现它居然连续有三个 spec 嵌套层次:
- 第一个
spec是CronJob自己的对象规格声明 - 第二个
spec从属于“jobTemplate”,它定义了一个Job对象。 - 第三个
spec从属于“template”,它定义了Job里运行的Pod。
所以,CronJob其实是又组合了Job而生成的新对象,我还是画了一张图,方便你理解它的“套娃”结构:
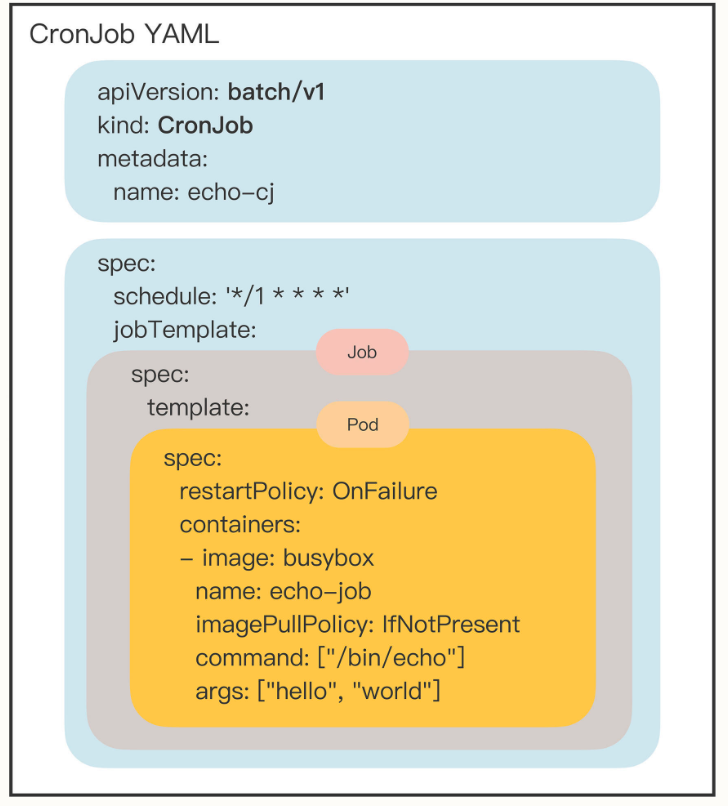
除了定义 Job 对象的“jobTemplate”字段之外,CronJob 还有一个新字段就是“schedule”,用来定义任务周期运行的规则。它使用的是标准的 Cron 语法。
除了名字不同,CronJob和Job的用法几乎是一样的,使用 kubectl apply 创建CronJob,使用 kubectl get cj、 kubectl get pod 来查看状态:
kubectl apply -f cronjob.yml
kubectl get cj
kubectl get pod
2
3
# 3.5 小结
这一节以面向对象的思想分析了 Kubernetes 里资源对象的设计,它强调“职责单一”和“对象组合”,简单来说就是“对象套对象”。
通过这种嵌套方式,Kubernetes里的这些API对象就形成了一个“控制链”:CronJob使用定时规则控制Job,Job使用并发数量控制Pod,Pod再定义参数控制容器,容器再隔离控制进程,进程最终实现业务功能,层层递进的形式有点像设计模式里的Decorator(装饰模式),链条里的每个环节都各司其职,在Kubernetes的统一指挥下完成任务。
今天学习了 Job 和 CronJob 两种对象:
- Job 的关键字段是
spec.template,里面定义了用来运行业务的Pod模板,其他的重要字段有completions、parallelism等。 - CronJob 的关键字段是
spec.jobTemplate和spec.schedule,分别定义了 Job 模板和定时运行的规则。
课外小贴士:
- Job/CronJob 的“apiVersion”字段是“batch/v1”表示它们不属于核心对象组 (core group),而是批处理对象组 (batch group)。
- 出于节约资源的考虑,CronJob 不会无限地保留已经运行的 Job,它默认只保留 3 个最近的执行结果,但可以用字段“successfulJobsHistoryLimit”改变。
- 网站 crontab.guru (opens new window) 很好地解释了 cron 表达式的含义。
# 4. ConfigMap/Secret:怎样配置、定制我的应用
想让业务更顺利地运行,有一个问题不容忽视,那就是应用的配置管理。比如 Nginx 的 nginx.conf、Redis 的 redis.conf 等。之前我们说管理配置文件的方式可以使用 COPY 命令打包到镜像中,或者通过 docker cp 拷贝进去。但这两种方式不太灵活,对于这个问题,Kubernetes 有自己的解决方案,就是使用 YAML 语言来定义 API 对象,再组合起来实现动态配置。
今天讲解的专门用来管理配置信息的两种对象 ConfigMap 和 Secret 就可以实现灵活地配置我们的应用。
应用程序中配置信息有两类:
- 明文配置:也就是不保密,比如 port、运行参数等
- 机密配置:设计敏感信息,不能随意查看,比如 password、certificate 等
ConfigMap 用来保存明文配置,Secret 用来保存机密配置。
# 4.1 ConfigMap
ConfigMap 简写名字是 cm。
与之前的 Pod 之类的相比,ConfigMap 的 YAML 没有 spec 字段,因为 ConfigMap 存的是静态的字符串,并不是容器,也就不需要 spec 来说明运行时的规格,而是哦需要一个含义更明确的字段:data 字段。
如下命令创建 YAML 样本文件:
export out="--dry-run=client -o yaml" # 定义Shell变量
kubectl create cm info --from-literal=k=v $out
2
--from-literal表示从字面值生成一些数据,而由于 ConfigMap 里的数据都是 KV 形式的,所以它的参数需要使用k=v的形式。
得到样板文件后在修改一下:
apiVersion: v1
kind: ConfigMap
metadata:
name: info
data:
count: '10'
debug: 'on'
path: '/etc/systemd'
greeting: |
say hello to kubernetes.
2
3
4
5
6
7
8
9
10
11
现在可以使用 kubectl apply 来创建 ConfigMap 对象了,然后用 kubectl get、 kubectl describe 来查看状态:
$ kubectl apply -f cm.yml
configmap/info created
$ kubectl get cm
NAME DATA AGE
info 4 54s
kube-root-ca.crt 1 26h
$ kubectl describe cm info
Name: info
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
debug:
----
on
greeting:
----
say hello to kubernetes.
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
你可以看到,现在 ConfigMap 的 Key-Value 信息就已经存入了 etcd 数据库,后续就可以被其他 API 对象使用。
# 4.2 Secret
它与 ConfigMap 很类似,不过 Secret 对象又细分出很多类,比如
- 访问私有镜像仓库的认证信息
- 身份识别的凭证信息
- HTTPS通信的证书和私钥
- 一般的机密信息(格式由用户自行解释)
这里只解释最后一种,先创建出 YAML 样板:
kubectl create secret generic user --from-literal=name=root $out
得到的Secret对象大概是这个样子:
apiVersion: v1
kind: Secret
metadata:
name: user
data:
name: cm9vdA== # root
pwd: MTIzNDU2 # 123456
db: bXlzcWw= # mysql
2
3
4
5
6
7
8
9
Secret 的 YAML 中保存的不再是明文,比如 data 字段下面的 name 值就是一串乱码。这串“乱码”就是Secret与ConfigMap的不同之处,不让用户直接看到原始数据,起到一定的保密作用。不过它的手法非常简单,只是做了Base64编码,根本算不上真正的加密,所以我们完全可以绕开kubectl,自己用Linux小工具“base64”来对数据编码,然后写入YAML文件,比如:
$ echo -n "123456" | base64
MTIzNDU2
2
- 要注意这条命令里的
echo,必须要加参数-n去掉字符串里隐含的换行符,否则Base64编码出来的字符串就是错误的。
接下来的创建和查看对象操作和 ConfigMap 是一样的:
$ kubectl apply -f secret.yml
secret/user created
$ kubectl get secret
NAME TYPE DATA AGE
default-token-pvqwj kubernetes.io/service-account-token 3 26h
user Opaque 3 24s
$ kubectl describe secret user
Name: user
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
db: 5 bytes
name: 4 bytes
pwd: 6 bytes
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
这样一个存储敏感信息的 Secret 对象也就创建好了,而且因为它是保密的,使用 kubectl describe 不能直接看到内容,只能看到数据的大小。
# 4.3 使用 ConfigMap/Secret
因为 ConfigMap 和 Secret 只是一些存储在etcd里的字符串,所以如果想要在运行时产生效果,就必须要以某种方式“注入”到Pod里,让应用去读取。在这方面的处理上 Kubernetes 和 Docker 是一样的,也是两种途径:环境变量和加载文件。
# 4.3.1 以环境变量的方式使用 ConfigMap/Secret
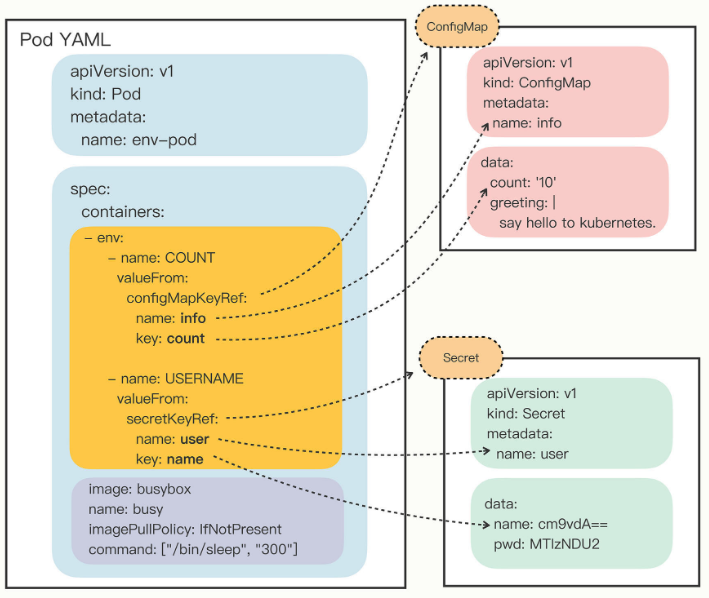
在 Pod 的 YAML 中 containers 有一个 env,它定义了 Pod 里容器能够看到的环境变量。当时我们只是简单实用了 value 来写死,实际上它可以使用 valueFrom 字段来从 ConfigMap 或 Secret 对象里获取值,从而把配置信息以环境变量的形式注入进 Pod,也就是配置与应用的解耦。
如下示例所示:
apiVersion: v1
kind: Pod
metadata:
name: env-pod
spec:
containers:
- env:
- name: COUNT
valueFrom:
configMapKeyRef:
name: info
key: count
- name: USERNAME
valueFrom:
secretKeyRef:
name: user
key: name
image: busybox
name: busy
imagePullPolicy: IfNotPresent
command: ["/bin/sleep", "300"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
如上所示,valueFrom 字段指定了 env 的来源,他可以是 configMapKeyRef 或 secretKeyRef,然后进一步指定所使用的 ConfigMap/Secret 对象的 name 和里面的 key。
关系如下图所示:
# 4.3.2 以 Volume 的方式使用 ConfigMap/Secret
我们可以为 Pod “挂载(mount)”多个Volume,里面存放供 Pod 访问的数据,这种方式有点类似 docker run -v。
在 Pod 里挂载 Volume 很容易,只需要在“spec”里增加一个“volumes”字段,然后再定义卷的名字和引用的 ConfigMap/Secret 就可以了。要注意的是 Volume 属于 Pod,不属于容器,所以它和字段“containers”是同级的,都属于“spec”:
spec:
volumes:
- name: cm-vol
configMap:
name: info
- name: sec-vol
secret:
secretName: user
2
3
4
5
6
7
8
上面定义的两个 volume 分别引用了 ConfigMap 对象和 Secret 对象。
有了 Volume 的定义之后,就可以在容器里挂载了,这要用到“volumeMounts”字段,正如它的字面含义,可以把定义好的 Volume 挂载到容器里的某个路径下,所以需要在里面用 mountPath、name 明确地指定挂载路径和 Volume 的名字:
containers:
- volumeMounts:
- mountPath: /tmp/cm-items
name: cm-vol
- mountPath: /tmp/sec-items
name: sec-vol
2
3
4
5
6
以上写好后,配置信息就可以加载成文件了。这里先花了个图来表示他们的引用关系:
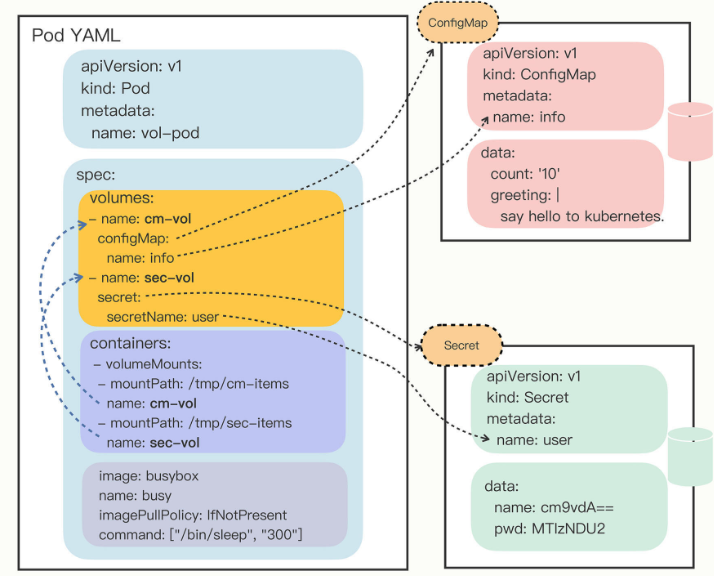
你可以看到,挂载 Volume 的方式和环境变量又不太相同:
- 环境变量是直接引用了ConfigMap/Secret
- 而Volume又多加了一个环节,需要先用Volume引用ConfigMap/Secret,然后在容器里挂载Volume,有点“兜圈子”“弯弯绕”。
这种方式的好处在于:以 Volume 的概念统一抽象了所有的存储,不仅现在支持ConfigMap/Secret,以后还能够支持临时卷、持久卷、动态卷、快照卷等许多形式的存储,扩展性非常好。
现在我把Pod的完整YAML描述列出来,然后使用 kubectl apply 创建它:
apiVersion: v1
kind: Pod
metadata:
name: vol-pod
spec:
volumes:
- name: cm-vol
configMap:
name: info
- name: sec-vol
secret:
secretName: user
containers:
- volumeMounts:
- mountPath: /tmp/cm-items
name: cm-vol
- mountPath: /tmp/sec-items
name: sec-vol
image: busybox
name: busy
imagePullPolicy: IfNotPresent
command: ["/bin/sleep", "300"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
创建之后,我们还是用 kubectl exec 进入Pod,看看配置信息被加载成了什么形式:
kubectl apply -f vol-pod.yml
kubectl get pod
kubectl exec -it vol-pod -- sh
2
3
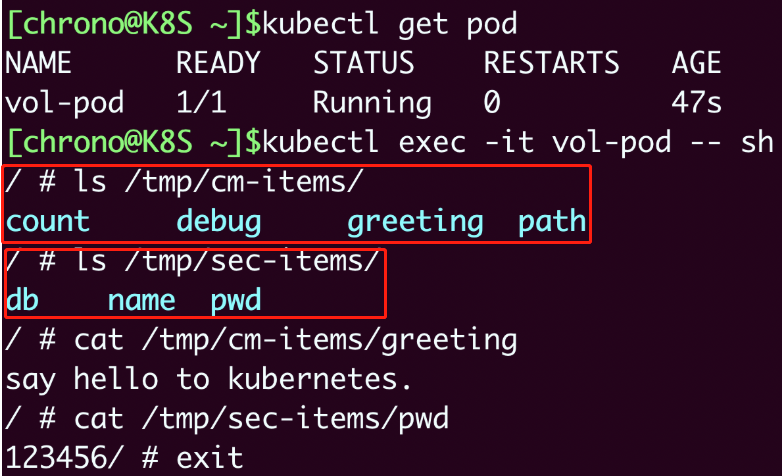
你会看到,ConfigMap 和 Secret 都变成了目录的形式,而它们里面的 Key-Value 变成了一个个的文件,而文件名就是 Key。
因为这种形式上的差异,以Volume的方式来使用ConfigMap/Secret,就和环境变量不太一样。环境变量用法简单,更适合存放简短的字符串,而Volume更适合存放大数据量的配置文件,在Pod里加载成文件后让应用直接读取使用。
# 4.4 小结
课外小贴士:
- 如果已经存在了一些配置文件,我们可以使用参数--from-fle”从文件自动创建出 ConfgMap 或Secret。
- Secret 对象默认只会以 Base64 编码的形式存储在etcd 里,而 Base64 不是加密算法,所以它通常并不是secret”,不过你可以为 Kubernetes 启用加密功能实现真正的安全。
- Linux 里对环境变量的命名有限制,不能使用
-、.等特殊字符,所以在创建 ConfgMap/Secret 的时候要留意一下,否则会无法以环境变量的形式注入 Pod。