 Linux 命名空间和 Cgroups:容器是由什么构成的?
Linux 命名空间和 Cgroups:容器是由什么构成的?
参考如下文章:
- https://medium.com/faun/kubernetes-story-linux-namespaces-and-cgroups-what-are-containers-made-from-d544ac9bd622
- https://zhuanlan.zhihu.com/p/585921599
- https://zhuanlan.zhihu.com/p/159362517
- https://time.geekbang.org/column/intro/100015201
如果我们做 DevOps,我们可能熟悉 Kubernetes、Docker 和容器。但是我们有没有想过docker到底是个什么东西?什么是容器?Docker是容器吗?Docker 不是容器,我将在这篇文章中解释它是什么。
这是深入容器系列的第一部分:
- Linux 命名空间和 Cgroup:容器是由什么制成的?
- 深入容器运行时
- Kubernetes 如何与容器运行时一起工作?
- 深入容器——使用 Golang 构建你自己的容器
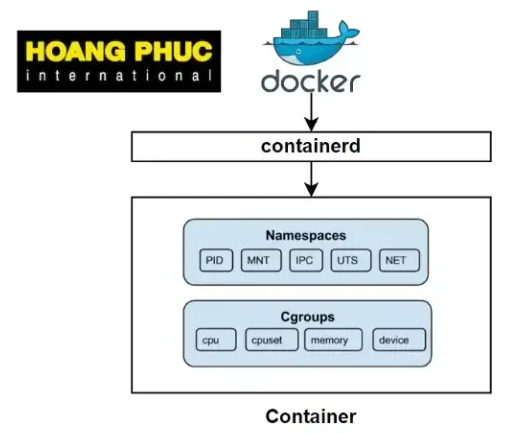
# 1. 容器
容器是一种技术,它允许我们在独立的环境中运行进程,并在同一台计算机上运行其他进程。那么容器是如何做到的呢?
为此,容器是根据 Linux 内核的一些新特性构建的,其中两个主要特性是“namespace”和“cgroups”。
# 2. Linux 命名空间
这是 Linux 的一个特性,可以让我们创建类似虚拟机的东西,与虚拟机工具的功能非常相似。这个主要特征使我们的流程完全独立于其他流程。
Linux 命名空间有很多不同的种类:
- PID 命名空间允许我们创建单独的进程。
- 网络命名空间允许我们在任何端口上运行程序,而不会与同一台计算机上运行的其他进程发生冲突。
- Mount 命名空间允许您在不影响主机文件系统的情况下挂载和卸载文件系统。
# 2.1 使用 unshare 创建一个 PID Namespace
创建一个 Linux 命名空间非常简单,我们使用一个名为 unshare 创建单独进程的包:
sudo unshare --fork --pid --mount-proc bash
它将创建一个单独的进程并将 bash shell 分配给它:
root@VM-24-5-ubuntu:~#
尝试运行 ps aux 命令:
root@VM-24-5-ubuntu:~# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 7236 4000 pts/1 S 14:47 0:00 bash
root 9 0.0 0.1 8876 3344 pts/1 R+ 14:48 0:00 ps aux
2
3
4
可以看到,在这里面执行的只由最开始的 bash 进程以及刚刚执行的 ps,而 bash 是第 1 号进程(PID=1)。
如果你在另一个终端上连接这个服务器并输入命令 ps aux:
root@VM-24-5-ubuntu:~# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
...
root 1990031 0.0 0.0 5480 592 pts/1 S 14:47 0:00 unshare --fork --pid --mount-proc bash
...
2
3
4
5
你会看到unshare进程正在运行,你可以认为它类似于运行docker ps命令时列出的容器。
这是怎么做到的呢?本来我们在宿主机中运行一个 bash 程序,操作系统会给它分配一个 PID,比如 PID=100。而现在 Linux Namespace 机制给这个进程施加了一个“障眼法”,让他永远看不到前面的 PID 为 1~99 的进程,这样,它就会误以为自己是这个系统的第一个进程了。
这种机制其实就是对被隔离应用的进程空间动了手脚,使得这些进程只能“看到”重新计算过得 PID,比如 PID=1。可实际上,在宿主机的操作系统里,它还是原来的第 100 号进程。这种技术就是 Linux 中的 Namespace 机制。
要退出 namespace,请键入exit:
root@VM-24-5-ubuntu:~# exit
现在当你在服务器上再次运行 ps aux 命令时,我们会看到之前的unshare进程已经消失了。
# 2.2 使用 clone() 创建 PID Namespace
Namespace 的使用方式也非常有意思:它其实只是 Linux 创建新进程中的一个可选参数。我们知道,在 Linux 系统中创建线程的系统调用是 clone(),比如:
int pid = clone(main_function, stack_size, SIGCHLD, NULL);
这个系统调用就会为我们创建一个新的进程,并返回它的 PID。而当我们用 clone() 创建新进程时,就可以在参数中指定 CLONE_NEWPID 参数从而创建新的进程空间,比如:
int pid = clone(main_function, stack_size, SIGCHLD | CLONE_NEWPID, NULL);
这时,新创建的这个进程将会“看到”一个全新的进程空间,在这个进程空间中,它的 PID 是 1。多次执行上面的 clone 调用就会创建多个 PID Namespace。
关于 PID Namespace 更多的系统调用
- setns:让进程加入已存在的 namespace
int setns(int fd, int nstype);
- 调用这个函数的进程会被加入到 fd 所代表的 namespace 中;
- fd:表示要加入 namespace 的文件描述符。它是一个指向 /proc/[pid]/ns 目录中文件的文件描述符,可以通过直接打开该目录下的链接文件或者打开一个挂载了该目录下链接文件的文件得到。
- nstype:参数 nstype 让调用者可以检查 fd 指向的 namespace 类型是否符合实际要求。若把该参数设置为 0 表示不检查。
在 docker 中,使用 docker exec 命令在已经运行着的容器中执行新的命令就需要用到 setns() 函数。
- clone:创建新的进程,并设置它的 namespace
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg);
- C 语言的 clone() 是一个系统调用的 wrapper,它负责建立新进程的堆栈并且调用对编程者隐藏的 clone() 系统调用。
- clone() 其实是 linux 系统调用 fork() 的一种更通用的实现方式,它可以通过 flags 来控制使用多少功能,一共有 20 多种 CLONE_ 开头的 flag 参数用来控制 clone 进程的方方面面(比如是否与父进程共享虚拟内存等)。
- fn:指定一个由新进程执行的函数。当这个函数返回时,子进程终止。该函数返回一个整数,表示子进程的退出代码。
- child_stack:传入子进程使用的栈空间,也就是把用户态堆栈指针赋给子进程的 esp 寄存器。调用进程(指调用
clone()的进程)应该总是为子进程分配新的堆栈。 - flags:表示使用哪些 CLONE_ 开头的标志位,与 namespace 相关的有 CLONE_NEWIPC、CLONE_NEWNET、CLONE_NEWNS、CLONE_NEWPID、CLONE_NEWUSER、CLONE_NEWUTS 和 CLONE_NEWCGROUP。
- arg:指向传递给 fn() 函数的参数。
- unshare:把当前进程移动到新的 namespace 中
int unshare(int flags);
- C 语言库中的 unshare() 函数也是对 unshare() 系统调用的封装。调用 unshare() 的主要作用就是不启动新的进程就可以起到资源隔离的效果。它会创建一个新的 namespace 并把当前进程加入进去。
- 系统还默认提供了一个叫 unshare 的命令,其实就是在调用 unshare() 系统调用。
- 参数的 flags 与 clone 的 flags 相同。
# 2.3 更多种类的 Namespace
除了上面刚刚用的 PID Namespace,Linux 系统还提供了 Mount、UTS、IPC、Network 和 User 这些 Namespace,用来对进程上下文施加各种“障眼法”。

这就是 Linux 容器的最基本的实现原理。所以,Docker 容器这个听起来玄而又玄的概念,实际上是在创建容器进程时,指定了该进程所需要启动的一组 Namespace 参数,这样,容器就只能“看到”当前 Namespace 所限定的资源、文件、设备、状态或者配置。
可见,容器其实就是一种特殊的进程而已。
# 3. Cgroups
我们可以创建一个独立于其他具有 Linux 名称空间的进程的进程。但是如果我们创建多个命名空间,那么如何限制每个命名空间的资源,使其不占用另一个命名空间的资源呢?
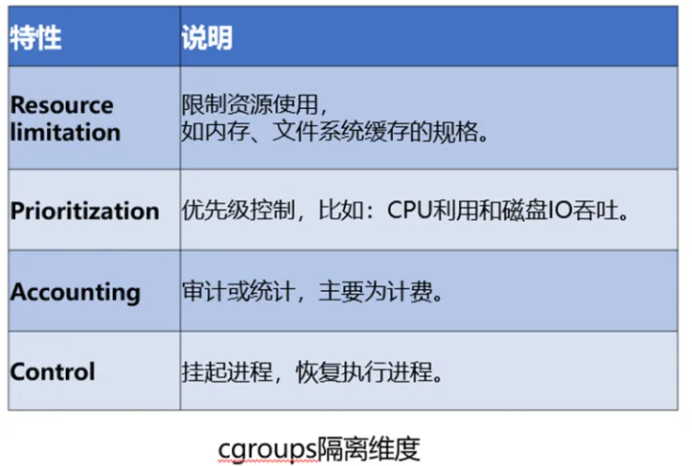
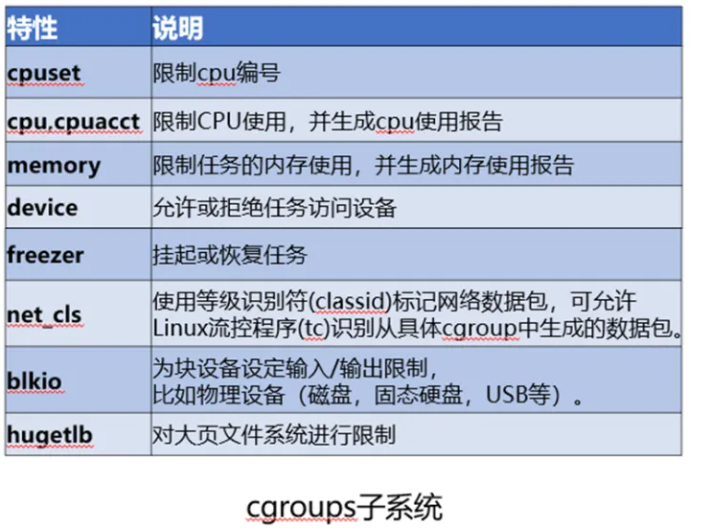
幸运的是,在 2007 年,一些人专门为我们开发了 Cgroups(Linux Control Group)。这是一项 Linux 功能,允许您限制进程的资源。Cgroups 将确定进程可以使用的 CPU 和内存的限制。
要创建 Cgroup,我们将使用 cgcreate。在使用之前cgcreate,我们需要安装 cgroup-tools:
# Ubuntu / Debian
sudo apt-get install cgroup-tools
# CentOS
sudo yum install libcgroup
2
3
4
然后我们用下面的命令创建 Cgroups:
sudo cgcreate -g memory:my-process
这会在 /sys/fs/cgroup/memory 路径下创建一个 my-process 的文件夹,里面的文件如下:
$ ls /sys/fs/cgroup/memory/my-process
cgroup.clone_children memory.memsw.failcnt
cgroup.event_control memory.memsw.limit_in_bytes
cgroup.procs memory.memsw.max_usage_in_bytes
memory.failcnt memory.memsw.usage_in_bytes
memory.force_empty memory.move_charge_at_immigrate
memory.kmem.failcnt memory.oom_control
memory.kmem.limit_in_bytes memory.pressure_level
memory.kmem.max_usage_in_bytes memory.soft_limit_in_bytes
memory.kmem.tcp.failcnt memory.stat
memory.kmem.tcp.limit_in_bytes memory.swappiness
memory.kmem.tcp.max_usage_in_bytes memory.usage_in_bytes
memory.kmem.tcp.usage_in_bytes memory.use_hierarchy
memory.kmem.usage_in_bytes notify_on_release
memory.limit_in_bytes tasks
memory.max_usage_in_bytes
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
我们会看到很多文件,这些是定义进程限制的文件,我们现在感兴趣的文件是 memory.kmem.limit_in_bytes,它会定义一个进程的内存限制,数值以字节为单位。例如,我们将创建一个内存限制为 50Mi 的进程:
sudo echo 50000000 > /sys/fs/cgroup/memory/my-process/memory.limit_in_bytes
然后运行下面的命令使用 Cgroup:
yubin@VM-24-5-ubuntu:~$ sudo cgexec -g memory:my-process bash
[sudo] password for yubin:
root@VM-24-5-ubuntu:/home/yubin#
2
3
现在 Cgroup 创建的进程内存将会被限制为 50Mi。
# 4. 带命名空间的 Cgroups
现在,我们可以使用带有命名空间的 Cgroups 来创建一个独立的进程并限制它可以使用的资源。
例如:
sudo cgexec -g memory:my-process unshare --fork --pid --mount-proc bash
运行结果:
yubin@VM-24-5-ubuntu:~$ sudo cgexec -g memory:my-process unshare --fork --pid --mount-proc bash
root@VM-24-5-ubuntu:/home/yubin# echo "Hello from in a container"
Hello from in a container
2
3
所以,容器是 cgroups 和 namespace 这两个特性的组合,虽然实际上它可能还有一些其他的东西,但基本上 cgroups 和 namespace 是两个主要的特性。
# 5. Union File System
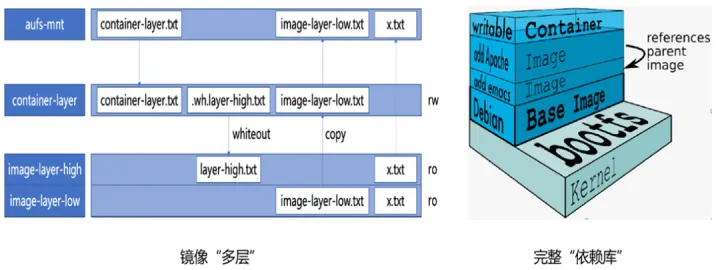
Union File System, 联合文件系统:将多个不同位置的目录联合挂载(union mount)到同一个目录下。
- Docker 利用联合挂载能力,将容器镜像里的多层内容呈现为统一的 Rootfs(根文件系统)。
- Rootfs 打包整个操作系统的文件和目录,是应用运行所需要的最完整的“依赖库”。
# 6. 什么是 Docker
那么什么是docker?Docker 只是一个帮助我们与底层容器技术交互的工具。更准确的说,Docker帮助我们轻松创建容器,而不需要我们做很多事情。Docker 项目最核心的原理实际上就是为待创建的用户进程做以下工作:
- 启动 Linux Namespace 配置;
- 设置指定的 Cgroups 参数;
- 在 mount namespace 下切换进程的根目录(change root);
这样,一个完整的容器就诞生了。不过 Docker 项目在最后一步的切换上会优先使用 pivot_root 系统调用,如果系统不支持才会使用 chroot。虽然这两个系统调用功能类似,但也有细微区别。
为了与容器交互,Docker 使用容器运行时(container runtime)。我们将在下一篇文章中讨论它。