 知识图谱概述
知识图谱概述
# 1.1 语言与知识
首先我将从“语言与知识”两个视角出发引出我们这门课的主角——知识图谱。
早期的人工智能有两个主要流派:
- 一个流派称为连接主义,主张智能的实现应该模拟人脑的生理结构,即用计算机模拟人脑的神经网络连接结构,这个流派发展至今,即所谓大红大紫的深度学习;
- 另外一个流派称为符号主义,主张智能的实现应该模拟人类的心智,即用计算机符号记录人脑的记忆,表示人脑中的知识等,即所谓知识工程与专家系统等。
知识图谱可以归属于符号主义的流派。深度学习首先在视觉、听觉等感知任务中获得成功,本质上解决的是识别和判断问题。事实上,这两种AI对于实现真正的人工智能都很重要,缺一不可。
认知智能有两个核心的研究命题,一个是语言理解,另外一个就是知识表示。人类通过认识世界来积累关于世界的知识,通过学习到的知识来解决碰到的问题,而语言则是知识最直接的载体,同时反过来,正确理解语言又需要知识的帮助。
提示
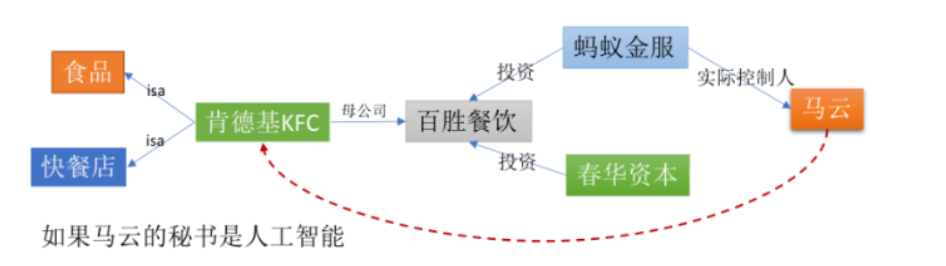
这里有个有趣的段子,G20期间,马云对秘书说,中午帮我买肯德基,30分钟后,秘书回来说,买好了,一共4.6亿美元。这当然是个玩笑,但马云的蚂蚁金服的确投资了肯德基的母公司百胜餐饮集团。当然我们这里关注的是背景知识对于理解语言的重要性。
比如假如马云的秘书是一个人工智能,它在第一个语境中,应该把肯德基识别为一种食品,而在第二个语境中应该把肯德基识别为一家公司,而且它还需要知道肯德基的母公司是百胜,蚂蚁投资了百胜,而马云是蚂蚁的实际控制人,才能正确地判断马云和肯德基的关系,这就是知识图谱。
人工智能领域有一个经典研究方向叫知识工程和专家系统。基本思想是建立一个系统能够从专家大脑里获取知识,这类知识可以是框架系统、语义网络或产生式规则,这个从人脑获取知识的过程叫作知识工程。再通过一个推理引擎来为非专家用户提供服务,比如辅助诊断、判案等等。
当前,通过机器来理解文本中的知识有两大主要技术路线,第一种是抽取技术,例如从文本中识别实体、关系、逻辑结构等等;第二种是文本预训练,即:通过大量的文本预料来训练一个神经网络大模型,文本中的知识被隐含在参数化的向量模型中,而向量化的表示和神经网络是对机器友好的。
简单的说,知识图谱旨在利用图结构建模、识别和推断事物之间的复杂关联关系和沉淀领域知识,已经被广泛应用于搜索引擎、智能问答、语言语义理解、大数据决策分析、智能物联等众多领域。对于机器而言,图结构比文本更加友好。深度学习,或者更为准确的说是表示学习的兴起,表明参数化的向量和神经网络是适于完成快速计算的信息载体。我们在自然语言中,可以为每个词学一个向量表示,我们也可以为视觉场景中的每一个对象学习一个向量表示,为知识图谱中的每一个实体学习一个向量表示。我们通常把这些对象的向量化表示称为Embedding或“Distributed Vector Representation”
因此,我们通过将词语、实体、对象、关系等都投影到向量空间,就可以更加方便的在向量空间对这些语言、视觉和知识对象进行操作,甚至可以利用神经网络来实现逻辑推理。
知识图谱同时拥抱机器的符号表示和向量表示,并能将两者有机的结合起来解决搜索、问答、推理、分析等多个方面的问题。
小结
- 人的大脑依靠所学的知识进行思考和推理,具有表示、学习和处理知识的能力是人类心智区别于其他物种最根本的区别。
- 语言是知识的最主要表示载体,语言与知识是实现认知智能最重要的两个方面。
- 知识图谱是一种结构化的知识表示方法,相比于文本更易于被机器查询和处理。
- 语言与知识的向量化表示,以及利用神经网络实现语言理解与知识处理是目前最重要的技术发展趋势之一。
# 1.2 知识图谱的起源
1989年,作为欧洲高能物理研究中心的计算机工程师,Tim提出了一种基于超文本技术的信息管理系统。他利用超文本链接技术实现科技文献之间的相互关联,并实现了世界上第一个能处理这种超链接文本的Web服务器和浏览器。1994年,Web 已经在全世界范围内快速发展起来,成为互联网上的最大应用。但 Tim 指出,这种以文本链接为主的Web并非他设想中的Final Web的样子。他认为那个Final Web应该是Web of Everything。
例如,一个教授的个人主页实际上描述的是他的各种属性语义信息,如果他的主页上有一个超链接指向浙江大学的官方主页,这个超链接实际上指的是这名教授和浙江大学是雇佣关系,但这个超链接没有这方面的语义描述,搜索引擎也无法识别和处理这种语义关系。
他于1998年正式提出了 Semantic Web 的概念。与经典Web一样,Semantic Web也是以图和链接为中心的信息管理系统,但不同之处是,这个图中的节点可以是粒度更细的事物,如:一本书、个人、机构、概念等等,图中的链接也标明这些事物之间的语义关系,如雇佣、朋友、作者等等。对Semantic Web理念的另外一种解读叫 Linked Data,这是大数据的视角,指的是通过规范化的语义表达框架,比如Schema或Ontology将碎片化的数据关联和融合形成高度关联的大数据。所以本质上,Semantic Web也可以看作是一种数据关联网络,告诉我们可以通过规范化的语义来加强数据之间的逻辑关联性,从而帮助发现和释放数据的内在价值。
# 语义网项目介绍
# 谷歌知识图谱
谷歌于2010年收购了开发Freebase的MetaWeb公司,并于2012年发布了首个基于知识图谱实现的搜索引擎。对于搜索引擎,知识图谱解决了一个简单的痛点问题,即:精确的对象级搜索。谷歌通过构建庞大的知识图谱,以结构化而非纯文本的方式描述事物的属性以及事物之间的关联关系,就可以实现这种对象级的精准搜索。
# Freebase
Freebase是早期的语义网项目,主要通过开放社区协作方式构建,在经过近八年的开发和数据积累后,其母公司MetaWeb 于2010年被谷歌收购。谷歌随后在Freebase基础之上发布了其面向搜索的知识图谱。
# WikiData
WikiData一定程度上可以看作是Freebase的后续发展。它由维基基金会支持,同样也是依靠开放社区来众包构建。它的目标是要成为世界上最大的免费知识库,并采用了CC0完全自由的开放许可协议。
# Schema.org
Schema.org是谷歌等搜索引擎公司共同推动的Web数据Schema标准。Schema.org本质是一种轻量级的Ontology,定义了有关人物、机构、地点等最常用的一千多个类和关系。任何人都可以利用这个Schema描述自己的数据,并以RDFa、Mcirodata等格式插入到网页、邮件中。
这使得每个人或机构都可以定制自己的知识图谱信息,并被搜索引擎快速的抓取和更新到后台数据库中。全球约有1.2亿的网站,超过30%的网页已经嵌入有Schema.org的语义数据。
# DBPedia
DBPedia也是早期的语义网项目,DBPedia意指数据库版本的Wikipedia,是从Wikipedia抽取出来的链接数据集。DBPedia采用了一个较为严格的本体,包含人、地点、音乐、电影、组织机构、物种、疾病等类定义。
# YAGO
YAGO是由德国马普研究所研制的链接数据库。YAGO主要集成了Wikipedia、WordNet和GeoNames三个来源的数据。其主要特点是考虑了时间和空间维度的知识表示,YAGO是IBM Watson的后端知识库之一。
# WordNet
WordNet是最著名的词典知识库,主要用于词义消歧等自然语言处理任务。由普林斯顿大学认识科学实验室从1985年开始开发,与谷歌知识图谱以实体关系为主不同,WordNet主要定义词与词之间的语义关系。
# ConceptNet
ConceptNet最早源于MIT的OpenMind Common Sense 项目,由著名人工智能专家Marvin Minsky于1999年建议创立。与谷歌知识图谱相比,ConceptNet侧重于词与词之间的关系。更加接近于WordNet,但比WordNet包含的关系类型多。
# BabelNet
BabelNet是多语言词典知识库。它集成了WordNet在词语关系上的优势和Wikipedia在多语言方面的优势。通过机器翻译技术自动化的构建成功了目前最大规模的多语言词典知识库,目前包含了271种语言,1400万同义词组。
# 中文开放知识图谱:OpenKG
在中文领域,中国中文信息学会语言与知识计算专业委员会于2015年启动了 OpenKG 中文开放知识图谱项目的建设,系统收集和整理了中文领域的众多开放知识图谱。
# 1.3 知识图谱的价值
知识图谱有什么用处呢?
- 互联网搜索引擎:Web的理想是链接万物,搜索引擎最终的理想是让我们能直接搜索万事万物,知识图谱支持的事物级别而非文本级别的搜索,大幅度提升了用户的搜索体验,因此,当前所有的搜索引擎公司都把知识图谱作为基础数据,并成立独立部门来持续建设。
- 智能问答:比如天猫精灵、小米小爱、百度度秘等背后都有知识图谱数据和技术的支持。智能问答本质就是一种对话式的搜索,相比起普通的搜索引擎,智能问答更加需要事物级的精确搜索和直接回答。智能厨房、智能驾驶、智能家居等都需要实现这种对话式的信息获取。
智能问答的实现形式
当前实现智能问答功能主要有三种形式:
- 第一种是问答对,这种实现简单的建立问句和答句之间的匹配关系,优点是易于管理,缺点是无法支持精确回答。
- 第二种形式类似于Stanford的Squad竞赛这种形式,要求能够从大段文本中准确定位答案,这当然是我们终极期望的形式,但源于语言理解本身的困难比较难于完全实用。例如小米小爱的后台实现中,这种形式的问答仅仅能支持个位数百分比的问句。
- 第三种就是知识图谱,相对于纯文本,从结构化的知识图谱中定位答案要容易得多,同时比起问答对形式,因为答案是以关联图的形式组织,不仅仅能提供精准答案,还能通过答案关联非常便利的扩展相关答案。
- 推荐系统:例如,在电商的推荐计算场景中,我们可以分别构建 UserKG 和 ItemKG。知识图谱的引入丰富了User和Item的语义属性和语义关系等信息,这将大大增强User和Item的特征表示,从而有利于挖掘更深层次的用户兴趣,关系的多样性也有利于实现更加个性化的推荐,丰富的语义描述还可以增强推荐结果的可解释性,让推荐结果更加可靠可信。
- 大数据分析:很多领域的大数据分析问题并不需要构建很复杂的算法模型,如果能根据分析的需要构建一个知识图谱,大部分大数据分析问题都可以转化为一个知识图谱上面的查询问题。当然有了图结构的数据,我们也可以更加容易的在知识图谱上叠加各种图算法,例如图嵌入算法、图神经网络等等。这些算法利用知识图谱中存在的关系进一步挖掘和推理未知的关系,从而大幅提升数据分析的深度和广度。
- 理解语言:当一个人听到或看到一句话的时候,他使用自己所有的知识和智能去理解。这不仅包括语法,也包括他的词汇知识、上下文知识,更重要的,是对相关事物的理解。知识图谱对于那些凡是涉及语义理解的任务都有作用。除了文本语义的理解,在图像、视频等视觉理解任务中,知识图谱也能发挥作用。比如图中这个例子,我们看到一只海鸟,图片本身所包含的信息显然是有限的。如果我们能引入知识图谱中关于海鸟的语义描述、关联的其它鸟等,就能大幅增强图片处理的深度和广度。比如,我们可以利用外源知识库中相关的鸟类信息来提升相似图片的检索效果。
- 物联网:OneM2M是物联网领域的一个国际联盟,它有一个独立的工作组,专门为物联网设备数据定义 Ontology,这些物联网本体被用来对设备数据进行语义封装,从而提升物联设备之间的语义互操作能力。例如,一个温度可能是人的体温、也可能是一个设备的温度,进一步理解这个温度数据还需要知道是在什么时间、什么位置等等,丰富的语义描述将大大提升物联设备数据的利用效率,终极的万物互联是设备通过规范化的语义进行数据层面的互联。
# 一些应用举例
- 新零售知识图谱:我们综合运用多项技术深度融合来自于天猫、淘宝、盒马等线上数据,来自于银泰百货、LAZADA等线下数据,以及舆情、百科、国家行业标准、竞品平台等外部数据,构建了百亿级实体数、千亿级关系边的商品知识图谱,并形成了一整套从建模、抽取、补全、融合、推理、推荐、问答、分析在内的算法和工具集,我们取了一个名字叫藏经阁知识引擎,用经书来比喻图谱,用藏经阁来比喻处理图谱数据的知识引擎。例如,在商家发品应用中,我们利用图谱数据和算法为新发商品自动预测品类、补全缺失属性、推荐能引导销售的商品关键属性,并利用知识图谱辅助自动生成商品广告,为卖家大幅节省维护商品信息的时间,覆盖淘宝天猫盒马等4.2亿+新发商品,商品发布时长平均降低25秒。
- 中医药知识图谱:基本的想法是希望通过构建一个中间本体,把中医和西医的概念和数据关联起来,然后在此基础之上实现语义搜索、跨库检索、知识问答、文本纠错和集成挖掘分析等功能。
- 大规模故障诊断知识图谱:自动驾驶网络ADN是相对于软件定义网络SDN提出来的概念,是华为倡导的利用人工智能技术进一步提升通信网络自动化、智能化的新一代网络基础设施管理解决方案。我们提出利用图数据融合集成包括业务投诉、故障现象、设备告警、系统日志、专家经验、外部环境等多种来源数据,构建自动驾驶网络知识图谱,并利用这个知识图谱关联网络故障诊断相关的文档、图片、案例等多模态数据,为运维专家提供更高效的故障信息检索和专家问答服务等功能,同时通过再叠加符号规则推理、图表示学习和图神经网络等技术方法,实现故障的根因分析、用户意图的翻译执行、自动运维规划等多种人工智能能力。
- 金融知识图谱:例如,我们通过构建上市公司知识图谱分析企业与企业、人、行业、舆情事件、宏观要素之间的关联关系,研究重大新闻事件对关联企业的影响力传播。利用知识抽取技术实现金融新闻、研报公报的自动结构化;利用图谱数据和推荐算法,实现信息咨询服务的精准推送和智能问答服务;在信贷领域,通过知识图谱提供数千万企业的行为数据关联建模、提高风险感知能力、风险传导识别,利用图谱数据和规则自动检测法律文本的合规性,从而减少信贷违约风险。

知识图谱当然还有更多的垂直领域应用。由于每个行业的知识体系和知识特点不一样,因此每个领域不仅要建自己的领域知识图谱,同时不同领域的建设方式和所用到的技术也有所不同。
小结
- 知识图谱技术源于互联网,最早落地应用的也是搜索引擎、智能问答和推荐计算等技术领域。
- 知识图谱支持通过规范化语义集成和融合多来源数据,并能通过图谱推理能力支持复杂关联大数据的挖掘分析,因此在大数据分析领域也有广泛应用。
- 不论是语言理解和视觉理解,外源知识库的引入都可以有力的提升语义理解的深度和广度。
- 知识图谱在医疗、金融、电商、通信等多个垂直领域都有着广泛的应用,并且每个领域都有其独特的实现和实践方式。
# 1.4 知识图谱的技术内涵
在这小节中,我们为大家系统性梳理知识图谱涉及的主要技术要素,帮助大家了解和掌握知识图谱的核心技术内涵。
我们首先要强调的是知识图谱是典型的交叉技术领域。从人工智能的视角,传统符号知识表示是知识图谱的重要基础技术,同时深度学习、表示学习等领域与知识图谱的交叉产生了知识图谱嵌入、可微知识图谱推理等交叉领域。
知识图谱始终有两个比较核心的技术基因:
- 第一个是从知识即 Knowledge 的视角。这来源于传统AI的知识表示与推理领域,我们关心怎么表示概念和实体,怎样刻画它们之间的关系,怎样进一步表示Axiom、Rules等更加复杂的知识,随着深度学习的兴起,怎样利用向量来表示实体和关系产生了KG Embedding的技术领域,怎样利用神经网络来实现逻辑推理产生了Neural Symbolic Reasoning等新技术领域。
- 第二个视角是从图的视角。这来源于知识图谱的互联网基因,我们关心图中的节点、边、路径、子图结构,怎样存储大规模的图数据,怎样利用图的结构对图数据进行推理、挖掘与分析等等。Knowledge Graph一方面比Pure Graph表达能力更强,因而能建模和解决更加复杂的问题,另外一方面又比传统知识表示所采用的formal logic要简单,同时容忍知识中存在噪音,构建过程更加容易扩展,因此得到了更为广泛的认可和应用。
更加细分的知识图谱技术要素:
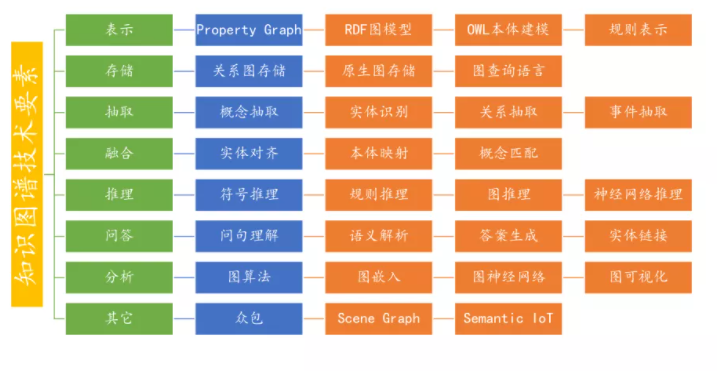
# 各技术维度的概览
# 1)基于图的知识表示
最常用的知识图谱表示方法有属性图和 RDF 图两种。这两种表示方法都基于一个共同的图模型——即有向标记图,知识图谱就是基于有向标记图的知识表示方法。我们以RDF图模型为例来具体介绍。
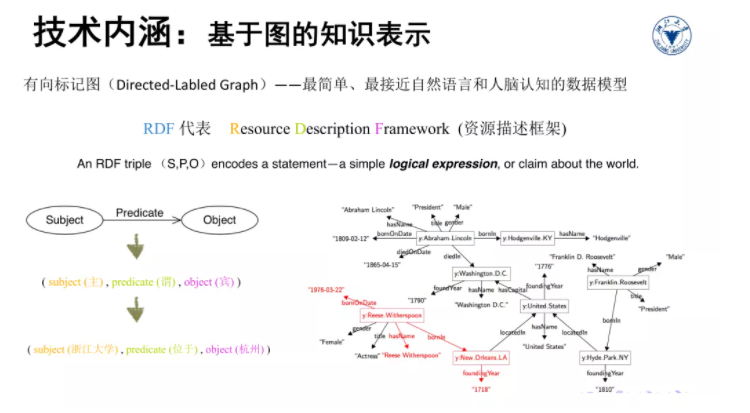
知识图谱的最基本组成单元是三元组,一个三元组包含(Subject,Predicate,Object)三个部分,即主语、谓语、宾语。例如,浙江大学 位于杭州就可以简单的用一个三元组来表示。一条三元组代表了对客观世界某个逻辑事实的陈述。这些三元组头尾相互连接就形成了一张描述万物关系的图谱。
从这个角度来看,三元组实际上是最简单,而且最接近于人的自然语言的数据模型,而图的信息组织方式又更加接近于人脑的记忆存储方式。当然,三元组的表达能力也是有限的,在后面的章节中我们还会介绍更加复杂的知识,比如本体公理、规则逻辑等应该怎么建模和表示。
# 2)图的数据存储与查询
图数据库充分利用图的结构建立微索引,这种微索引比起关系数据库的全局索引在处理图遍历查询时更加廉价,其查询复杂度与数据集整体大小无关,仅正比于相邻子图的大小。
因此在很多涉及复杂关联和多跳的场景中得到广泛应用。这里需要说明的是,图数据库并非知识图谱存储的必选方案,在后面的章节中,我们会介绍常见的知识图谱存储的各种解决方案。
# 3)知识的抽取
知识图谱的构建一般多依赖已有的结构化数据,通过映射到预先定义的Schema来快速的冷启动。然后利用自动化抽取技术从半结构化和文本中提取结构化信息来补全知识图谱。这里涉及到D2R映射,表格及列表数据抽取,从文本中识别实体、关系、事件等等。这里需要特别说明的是,完全自动化的抽取高质量的知识目前仍然是无法做到的,机器抽取 + 人工众包仍然是当前知识图谱构建的主流技术路线。
# 4)知识图谱的融合
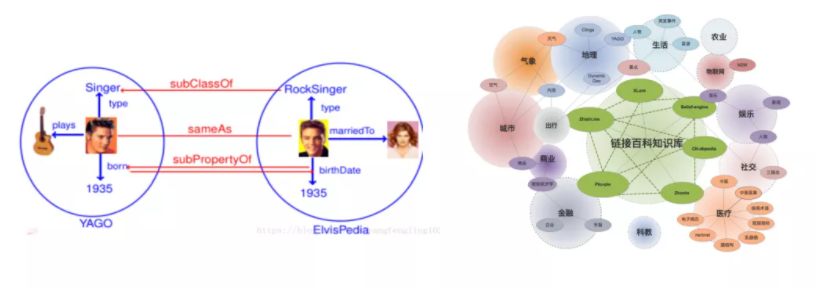
在知识图谱的构建过程中,很多时候都需要使用数据融合技术将多个来源数据中的实体或概念映射到统一的命名空间中。这主要包含两个层面的融合,一个是在本体概念层面,例如两个不同的知识图谱用到的概念,其中一个定义的 RockSinger 是另外一个定义的Singer类的子类。另外一个是在实体层面,例如同一个人在不同的数据集中用的名字是不一样的。基于表示学习的方法是当前实现知识图谱异构融合的主流技术。
# 5)知识图谱推理
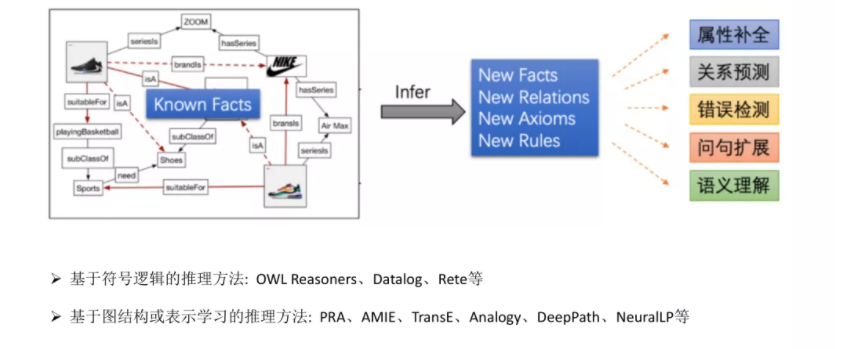
推理是知识图谱的核心技术和任务。简而言之,知识图谱推理的目标是利用图谱中已经存在的关联关系或事实来推断未知的关系或事实,在知识图谱的各项应用任务中发挥着重要作用。
如图所示,推理可以用来实现链接预测、补全缺失属性、检测错误描述和识别语义冲突,以提升图谱质量等;在查询和问答中,推理可以用来拓展问句语义和提高查询召回;在推荐计算中,推理可用来提升推荐的精准性和可解释性。此外,推理在深度语言语义理解和视觉问答中也扮演必不可少的角色。
凡是包含深度语义理解的任务都会涉及推理的过程。当前在知识图谱上实现推理大致可以分为基于符号逻辑的方法和基于表示学习的方法两类。传统基于符号逻辑的方法主要优点是具备可解释性,主要缺点是不易于处理隐含和不确定的知识;基于表示学习的方法主要优点是推理效率高且能表征隐含知识,主要缺点是丢失可解释性。在推理的章节中,我们将展开具体的介绍。
# 6)KBQA
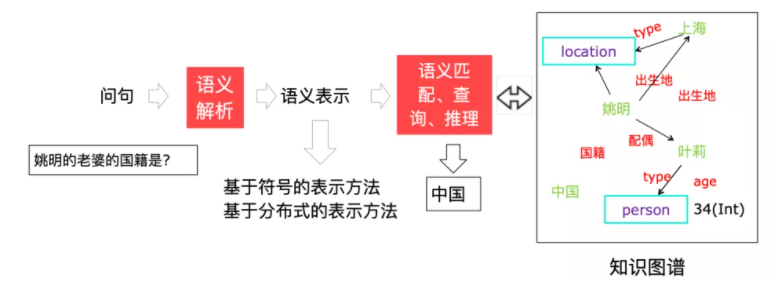
问答是利用知识图谱数据的主要形式之一。一个典型的问答处理流程,涉及对问句的语义解析,即把自然语言问句解析为更易于被机器处理的逻辑表示或分布式表示形式,再将问句的语义表示与知识图谱中的节点进行匹配和查询,这个过程中可能还需要叠加推理,对结果进行放大,最后再对候选的匹配结果进行排序并生成对用户友好的答案形式。知识图谱问答有很多种不同的实现形式,我们也会在知识图谱问答章节对相关基本技术进行介绍。
# 7)图算法和图神经网络
知识图谱作为一种基于图结构的数据,可以充分利用各种图挖掘与分析算法对知识图谱进行深度的挖掘和分析。这包括常见的基于图论的一系列算法,如最短路径搜索、子图识别、中心度分析等等,也包括图嵌入、图神经网络等图表示学习方法。我们将在图算法章节具体展开介绍。
# 总结
我们需要特别强调的是,知识图谱不是单一的技术,做知识图谱一定要有系统工程的思维。很多人在理解知识图谱时通常仅从自己比较熟悉的角度去把握。很多时候有点类似于盲人摸象,仅仅把握其中某一个方面的技术对于做好知识图谱是很不够的。
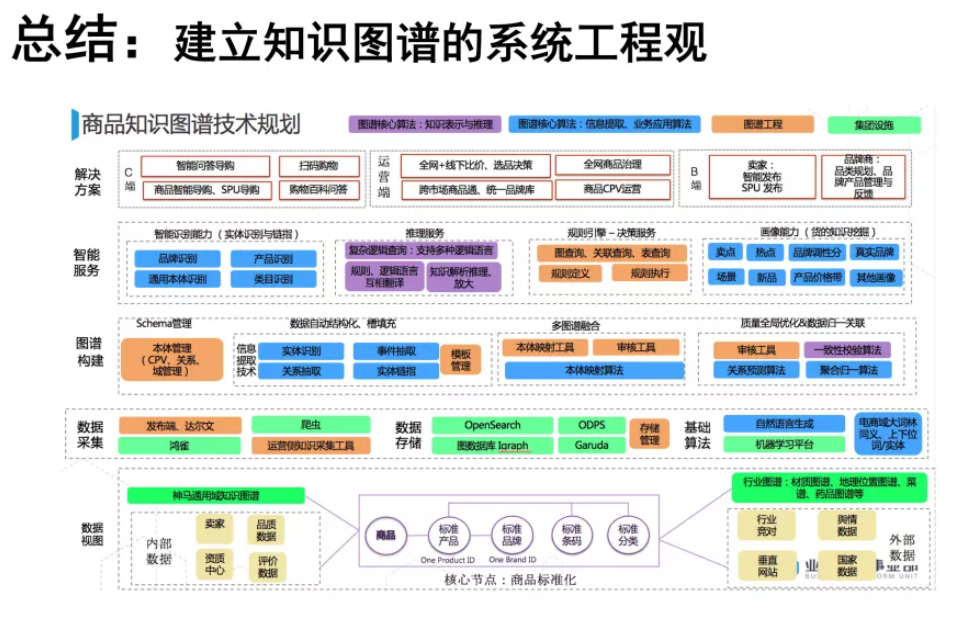
知识图谱技术涉及数据、算法、工具和系统四个维度。知识图谱首先是一种高质量的数据,其次,我们通常需要围绕知识图谱数据形成一整套算法、工具和应用系统。针对大家所在的领域选择必要的技术要素、设计系统性的技术架构,更多地采用系统工程的思路来实践知识图谱是非常重要的实践思路。