 TF-IDF
TF-IDF
在寻找一个文章中哪些词比较重要时,最简单的方法可以对这个文档进行词频(Term Frequency,TF)的统计,词频指的是在一个文档中某个词汇出现的频率或次数。但是这种方法存在明显的缺点,当对一个文档进行分析时,像“我们”、“的”这种词语往往都会有很高的词频,但由于这类词语在大多数文档中都具有较高的词频,因此这种词语的高词频往往无法体现出该文档的特征,相反,某些词语如“篮球”、“卧推”等虽然词频并没有很高,但却集中出现在了某些文档当中,这类词语就可以很明显地体现出这些文档的特点。
为了解决上面所说的问题,人们又引入了逆文档频率(Inverse Document Frequency,IDF)这个概念,将词频与逆文档频率进行结合共同组成了 TF-IDF 这个指标,一个词语的 TF-IDF 计算方式为:
其中,词频(TF)的计算方式如下图:
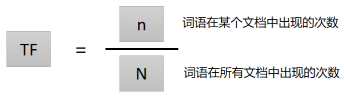
逆文档频率(IDF)的计算方式如下图:
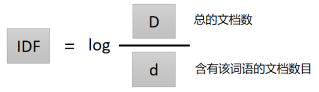
可以看出,对于给定分析的语料库,总文档数 D 是一个固定值,因此一个词语的 IDF 值取决于含有该词语的文档数目 d,所以包含这个词语的文档越多,这个词语的 IDF 值将越小。
综合来看 TF 与 IDF 两个指标,当一个词语在一个文档中出现次数越多时,它的 TF 值将越大,但随着它在更多文档中出现,它的 IDF 值将变小。将 TF 与 IDF 进行结合起来的 TF-IDF 指标就由此实现了突出重要词语,而抑制次要词语的效果。
当然,TF-IDF 也有一些缺点。比如一些语境下可能并不符合 TF-IDF 指标所做的假设,这时计算得到的 TF-IDF 指标可能对词语重要性的衡量出现误差。同时 TF-IDF 没有考虑文档的上下文语境,无法区分一词多义等情况。
以上所介绍的 TF-IDF 指标计算方式是一种经典的计算方式,在具体实现中可能会在归一化、平滑处理等方面存在稍许计算上的差异,但这些计算方式的所蕴含的本质思想都是共通的。