 BigTable
BigTable
参考:大数据经典论文解读 | 极客时间 (opens new window) 08-10 讲
GFS和MapReduce通过非常简单的设计,帮助我们解决了海量数据的存储、顺序写入,以及分布式批量处理的问题。但他们的局限性也很大,无法实现一个可以高并发、保障一致性,并且支持随机读写数据的系统。这个系统就是接下来要讲解的 BigTable。下面主要讲解三个问题:
- Bigtable想要解决什么问题?我们不能用MySQL这样的关系型数据库,搭建一个集群来解决吗?
- Bigtable的架构是怎么样的?它是怎么来解决可用性、一致性以及容易运维这三个目标的?
- Bigtable的底层数据结构是怎么样的?它是通过什么样的方式在机械硬盘上做到高并发地随机读写呢?
当你理解了这三个问题,相信你对分布式数据库的设计可以算是正式入门了,而且你对于计算机底层数据结构、硬件原理和大型系统设计之间的联系也建立起来了。这样,无论你后续是想专门从事分布式数据库的开发,还是成为一个熟知各类系统原理的架构师,都会有很大帮助。
# 1. Bigtable 要解决什么问题?
# 1.1 Friendster 面临的问题
以往有一个Friendster 的社交网站,它早于 Facebook,但却因为种种原因而销声匿迹了。其中一个很重要的问题就是在技术上没有解决好 scalability 的问题。从 2003 年开始,Friendster 就一直遇到严重的性能瓶颈,并且因为性能问题限制了很多功能的实现。
Friendster在成立一年之后的2003年,就已经有7500万用户了,所以服务器压力的确很大。那么根据上面MIT学生的描述,我们可以想象一个简单的社交网络的功能,以及对应需要的读写请求数量:用户去看自己的时间线的时候,需要看到自己150个好友发的帖子。这里有两种解决办法。
一种是用户发帖子的时候,系统往所有好友的时间线里写一条数据,那么写入就会放大150倍。假设每天有20%的用户发3条帖子,那么写入的数据量就是:
7500万 x 20% x 150 x 3 = 67.5亿
67.5亿条随机数据写入,如果均匀分配到10个小时,每秒的随机写入量大概是:
67.5亿 / (3600秒 * 10) = 18.75万次/秒
还有一种是每个用户看自己时间线的时候,系统会查询150个好友各自发表的内容,然后做合并。那么对应的就是22.5亿次的随机数据读取,也就是每秒6.25万次的随机读取。
如果你读过我的《深入浅出计算机组成原理》中关于 机械硬盘 (opens new window) 的那一讲,你就知道一块7200转的机械硬盘,只能支撑100的IOPS,也就是100次随机读写。那按照上面的数据来看,我们至少需要600块硬盘,才能支撑简单地读取自己的时间线信息。事实上,600块硬盘远远不够的,无论是读写什么数据,都不太可能只写入1条数据,更不可能只有1次随机读写,而我们的硬盘,也不可能刚好跑满IOPS。
所以一方面,我们可能需要数千块硬盘,对应的,也就需要上千台服务器。另一方面,这个集群需要能够支持海量的随机读写,至少需要支持到每秒百万次级别的随机读写,而Bigtable就是这样一个系统。
# 1.2 “小数据”的 MySQL 集群
Bigtable的论文发表于2006年,而基于论文实现的开源系统HBase,要到2008年才第一次正式发布(0.18.0版本)。所以,Friendster并没有Bigtable可以用,在2003年,一家互联网公司面对“伸缩性”这个问题,最好的选择是使用一个MySQL集群。
维护一个几十乃至上百台服务器的MySQL集群是可行的,但是,如果要像GFS一样到一千乃至数千台服务器,还有可行性吗?下面我们就一起来看一下。
分库分表的扩容方式:
一致性的随机读写,在单个服务器上似乎并不是什么问题。如果你是做后端应用开发的,肯定用过MySQL这样的数据库,你可以很容易地通过简单的SQL,完成增删改查这样的随机数据读写。如果要把单机的MySQL扩展成分布式,好像也不是什么难题,只要做个分库分表就好了,这些套路你应该会非常熟悉。
一般来说,我们会先做垂直分库,在电商的系统里,我们把用户、商品、订单的表拆分到不同服务器的数据库上。如果发现这样还不行,我们就再进行水平分库,把订单号Hash一下,然后取“模”(mod)个4,拆分到4台不同的服务器的数据库里。
这样,每台机器只需要承接1/4的负担,看起来这种方式也能解决问题。当然,在分库分表的过程中,我们已经放弃了MySQL这样的关系型数据库的很多特性,比如外键关联这样的约束,以及单个数据库里面的跨行跨表的事务。
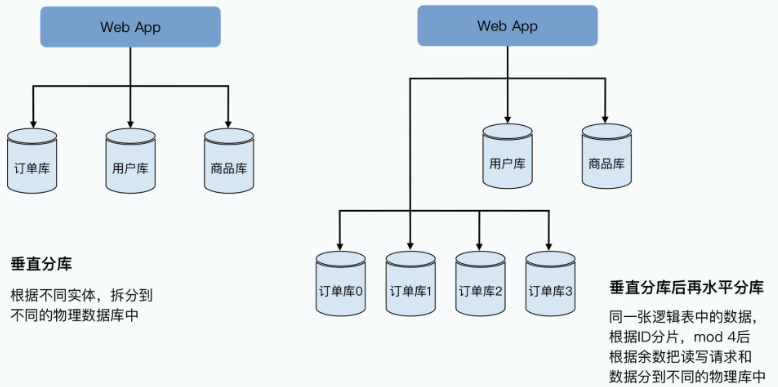
那么,为什么谷歌还需要发明一个Bigtable呢?这是因为分库分表,并不是一个很好的实现“可伸缩性”和“可运维性”的方案。基于分库分表的方案,运维起来会很费劲,主要体现在以下三点:
# 1)不得不进行的“翻倍扩容”
首先,是资源使用很浪费。当服务器性能出现瓶颈需要扩容的时候,我们常常只能采取“翻倍”分库增加服务器的方案。就以前面举的订单表为例,我们通过把订单号“模”上个4,拆分到4个不同的服务器的数据库里。
而随着我们承接的订单越来越多,每天SQL查询的请求越来越多,服务器的峰值CPU可能超过了60%。为了安全起见,我们希望对服务器进行扩容,让峰值CPU控制在40%以下。但是这个时候,我们没办法只是增加4 * 0.6 / 0.4 - 4 = 2台服务器,而是不得不“翻倍”增加4台服务器。
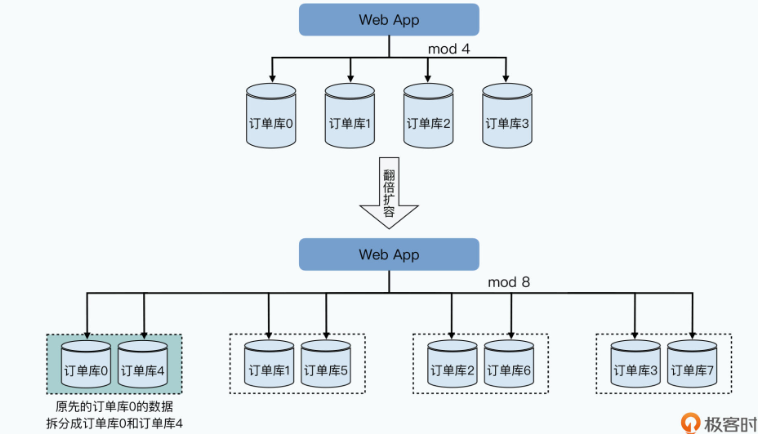
为什么呢?因为如果我们只增加2台服务器,把各个服务器的分片,从模上4变成模上6,我们就需要在增加服务器之后,搬运大量的数据。并且这个数据搬运,不只是搬到新增加的服务器上,而是有些数据还要在原有的4台服务器上互相搬运。
这个搬运过程需要占用大量的网络带宽和硬盘读写,所以很有可能要让数据库暂停服务。而如果不暂停服务的话,我们就要面对在数据搬运的过程中,到底应该从哪个服务器读和写数据的问题,问题一下子就变得极其复杂了。
而翻倍扩容服务器,我们可以只需要简单复制50%的数据,并且在数据完成复制之后自动切换分片就可以了。但是翻倍扩容的方案,自然就带来了很多浪费,明明我们只需要加两台服务器,但是现在要加上四台。更浪费的是,我们增加的服务器,也许只是为了应对双十一促销这样的一小段时间,等到促销完成,我们又不再需要这些服务器了。
可这个时候,如果我们需要缩减服务器,也会非常麻烦,我们需要再把两台服务器的数据复制到一台服务器上,才能完成缩容。可以看到,这个集群虽然可以“伸缩”,但是伸缩起来非常不容易。
而我们希望的伸缩性是什么样的呢?自然是需要的时候,加1台服务器也加得,加10台服务器也加得。而用不上的时候,减少个8台10台服务器也没有问题,并且这些动作都不需要停机。这个,也是Bigtable的设计目标。
# 2)“我怎么早没想到”的数据分区
其次,是底层的数据分区策略对于应用不透明。如何分库和分表都需要开发人员来设计,撰写代码的时候,也常常要考虑底层分库分表的设计。用着用着你会发现,使用 MySQL 集群,需要你在一开始就对如何切分数据做好精心设计。一旦稍有不慎,设计上出现了数据倾斜,就很容易造成服务器忙得忙死,闲得闲死的现象。并且即使你已经考虑得非常仔细了,随着业务本身的变化,比如要搞个双十一,也会把你一朝打回原形。
那么,我们希望的分布式数据库是什么样的呢?自然是数据的分片是自适应的。比如2019年只有100万订单,那就分片到一个服务器节点上;2020年有了1000万订单,自动给你分了10个节点;当2021年有1亿订单的时候,就给你分配上100个节点。而这一点,也同样是Bigtable的设计目标。
# 3)天天跑机房的人肉运维
最后,是故障恢复需要人工介入。在MySQL集群里,我们可以对每个服务器都准备一个高可用的备份,避免一出现故障整个集群就没法用了。但是此时,我们的运维人员仍然需要立刻介入,因为这个时候系统是**多了一个“单点”**的,我们需要手工添加一台新的服务器进入集群,同步到最新的数据。
我们可以一起来算一算,如果有一个1000台服务器的MySQL集群,每台服务器上都给插上12块硬盘,一共有1万2千块硬盘。这么多硬盘,我们到底要面临多少故障呢?
2003年,谷歌的论文用的还是传统的机械硬盘,那个时候机械硬盘的可靠性数据我已经找不到了。不过我们可以看一下2021年的数据:Backblaze这个公司从2012年开始就会发布硬盘的可靠性数据,从2021年Q2季度来看,他们数据中心里将近18万块的硬盘,在90天里一共坏了439块,差不多每天要坏上将近5块硬盘。
我们的1万2千块硬盘,是他们的7%不到,基本上3天也要坏上一块硬盘。要知道,这个还是只考虑了硬盘的硬件损坏,还没有算上CPU、内存、交换机、网络等等各种各样的问题。
那么,如果让我们的运维工程师,每个礼拜都有两天跑去数据中心换硬盘、运维系统,恐怕他别的事情也都干不了了。
而我们希望的可运维性是怎么样的呢?最好是1000台节点的服务器,坏个10台8台没事儿,系统能够自动把这10台8台服务器下线,用剩下的990台继续完成服务。我们的运维人员只要1个月跑一趟机房批量换些机器就好,而不用996甚至007地担心硬件故障带来的不可用问题。
# 1.3 BigTable 的设计目标
看到这里,相信你对Bigtable的设计目标应该更清楚了。最基础的目标自然是应对业务需求的,能够支撑百万级别随机读写IOPS,并且伸缩到上千台服务器的一个数据库。但是光能撑起IOPS还不够。在这个数据量下,整个系统的“可伸缩性”和“可运维性”就变得非常重要。
这里的伸缩性,包括两点:
- 第一个,是可以随时加减服务器,并且对添加减少服务器数量的限制要小,能够做到忙的时候加几台服务器,过几个小时峰值过去了,就可以把服务器降下来。
- 第二个,是数据的分片会自动根据负载调整。某一个分片写入的数据多了,能够自动拆成多个分片来平衡负载。而如果负载大了,添加了服务器之后,也能很快平衡数据,让各个节点均匀承担压力。
而可运维性,则除了上面的两点之外,小部分节点的故障,不应该影响整个集群的运行,我们的运维人员也不用急匆匆地立刻去恢复。集群自身也要有很强的容错能力,能够把对应的请求和服务,调度到其他节点去。
那么,当我们回头看这个设计目标之后,会发现Bigtable的设计思路和GFS以及MapReduce一脉相承。
这三个系统的核心设计思路,就是把一个集群当成一台计算机。对于使用者来说,完全不用在意后面的分布式的存在。这样的设计思路,使得所有的工程师,并不需要学习什么新知识,只要熟悉这些分布式系统给到的接口,就能上手写大型系统。而这一点就让谷歌在很长一段时间都拥有极强的工程优势。
在GFS+MapReduce+Bigtable发布的前后几年里,谷歌发布了很多优秀的产品,比如Gmail、Google Maps、Google Analytics等,而这些产品的底层,就是优秀的分布式架构系统给谷歌带来的竞争优势。
当然,除了这些目标之外,Bigtable也放弃了很多目标,其中有两个非常重要:
- 第一个是放弃了关系模型,也不支持SQL语言;
- 第二个,则是放弃了跨行事务,Bigtable只支持单行的事务模型。
而这两个问题,一直要到10年后的Spanner里,才被真正解决好。在后续的课程里,你也会看到Spanner是怎么一步步从Bigtable进化而来的。到时候,你也可以对照着Spanner的论文来回头看看Bigtable,看看这些逐步迭代的设计是否和你自己的思考和猜想一致。
BigTable 解决以上提出问题的答案主要就是三点:
- 第一点,是将整个系统的存储层,搭建在GFS上。然后通过单Master调度多Tablets的方式,使得整个集群非常容易伸缩和维护。
- 第二点,是通过MemTable+SSTable这样一个底层文件格式,解决高速随机读写数据的问题。
- 最后一点,则是通过Chubby这个高可用的分布式锁服务解决一致性的挑战。
接下来我们会继续解读 BigTable 的实现,并在之后专门讲解这个 Chubby 分布式锁的论文。
扩展阅读
今天我们聊了很多MySQL集群这样的关系型数据库集群在可伸缩性上会遇到的挑战。那是不是MySQL集群真的就只能搞个三五台服务器呢?倒也不是,战胜了Friendster的Facebook里,就有MySQL集群,有上千台服务器。 事实上,他们的工程师还在2015年的SRECon里面分享过这个主题“MySQL Automation at Facebook Scale”,我把 链接 (opens new window) 放在了这里,你可以去看一看。不过看完你会发现,为了去运维这么大的MySQL集群,需要做的开发工作其实和实现一个Bigtable也差不多了。分布式锁、自动分片、自动故障隔离和恢复一个都少不了。
# 2. Bigtable 的架构是怎么样的?
这一章一起来看一下 Bigtable 的整体架构,并以此可以掌握三个重要知识点:
- 第一个,Bigtable是如何进行数据分区,使得整个集群灵活可扩展的;
- 第二个,Bigtable是如何设计,使得Master不会成为单点故障,乃至单点性能的瓶颈;
- 最后,自然是整个Bigtable的整体架构和组件由哪些东西组成。
相信在学完这一讲后,你也能自己设计一个分布式数据库的基本架构。并且,你也会对分布式数据库设计的分区和复制机制、系统整体架构设计,以及如何分析和优化整个架构的瓶颈所在,有一个清晰的了解。
# 2.1 理解 Bigtable 的基本数据模型
当我们一旦开始分库分表,就很难使用关系数据库的一系列特性了,比如 SQL 里面的 join 功能,或者是跨行的事务。因为这些功能在分库分表的场景下,都要涉及到多台服务器,不是说做不到,但是问题一下子就复杂了。
所以,Bigtable在一开始,也不准备先考虑事务、Join等高级的功能,而是把核心放在了“可伸缩性”上。因此,Bigtable自己的数据模型也特别简单,是一个很宽的稀疏表。
- 每一张Bigtable的表都特别简单,每一行就是一条数据:
- 每一行里的数据呢,你需要指定一些列族(Column Family),每个列族下,你不需要指定列(Column)。每一条数据都可以有属于自己的列,每一行数据的列也可以完全不一样,因为列不是固定的。这个所谓不是固定的,其实就是列下面没有值。因为Bigtable在底层存储数据的时候,每一条记录都要把列和值存下来,没有值,意味着对应的这一行就没有这个列。这也是为什么说Bigtable是一个“稀疏”的表。
- 列下面如果有值的话,可以存储多个版本,不同版本都会存上对应版本的时间戳(Timestamp),你可以指定保留最近的N个版本(比如N=3,就是保留时间戳最近的三个版本),也可以指定保留某一个时间点之后的版本。
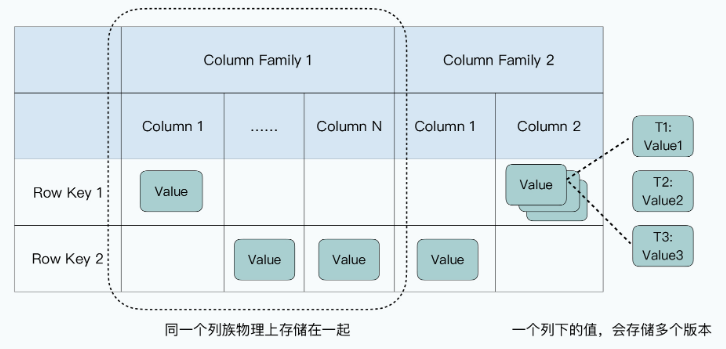
原论文对 Bigtable 的数据模型的定义
A Bigtable is a sparse, distributed, persistent multi-dimensional sorted map.
其实,这里的有些命名容易让人误解,比如列族,这个名字很容易让人误解Bigtable是一个基于列存储的数据库。但事实完全不是这样,我觉得对于列族,更合理的解读是,它是一张“物理表”,同一个列族下的数据会在物理上存储在一起。而整个表,是一张“逻辑表”。
在现实当中,Bigtable的开源实现HBase,就是把每一个列族的数据存储在同一个HFile文件里。而在Bigtable的论文中,Google定义了一个叫做本地组(Locality Group)的概念,我们可以把多个列族放在同一个本地组中,而同一个本地组的所有列的数据,都会存储在同一个SSTable文件里。
这个设计,就使得我们不需要针对字段多的数据表,像MySQL那样,进行纵向拆表了。
Bigtable的这个数据模型,使得我们能很容易地去增加列,而且增加列并不算是修改Bigtable里一张表的Schema,而是在某些这个列需要有值的行里面,直接写入数据就好了。这里的列和值,其实是直接以key-value键值对的形式直接存储下来的。
这个灵活、稀疏而又宽的表,特别适合早期的互联网业务。虽然数据量很大,但是数据本身的Schema我们可能没有想清楚,加减字段都不需要停机或者锁表。要知道,MySQL直到5.5版本,用ALTER命令修改表结构仍然需要将整张表锁住。并且在锁住这张表的时候,我们是不能往表里写数据的。对于一张数据量很大的表来说,这会让整张表有很长一段时间不能写入数据。
而Bigtable这个稀疏列的设计,就为我们带来了很大的灵活性,如同《架构整洁之道》的作者 Uncle Bob (opens new window) 说的那样:“架构师的工作不是作出决策,而是尽可能久地推迟决策,在现在不作出重大决策的情况下构建程序,以便以后有足够信息时再作出决策。”
# 2.1.1 Rows
Bigtable 保证了每一次对 row 的读写都是原子性的(不管设计多少 column)。
Bigtable 按照 row key 的 order 进行分区,每个 row 的分区被称为一个 tablet。
# 2.1.2 Column Families
Column keys are grouped into sets called column families, which form the basic unit of access control.All data stored in a column family is usually of the same type.
A column key is named using the following syntax:
区分 column family 和 column:
- column family 必须先创建,才能创建基于它的 column
- column family 的数量少且一般固定不变动,而 column 的数量多且容易变动
# 2.1.3 Timestamps
Each cell in a Bigtable can contain multiple versions of the same data; these versions are indexed by timestamp.
越新的时间戳就代表了越新的数据,最新版的数据总是被优先读到,而老版本的数据可以通过垃圾回收机制来回收掉。
# 2.2 数据分区,可伸缩的第一步
搞清楚了Bigtable的数据模型,我们再来一起看一看,Bigtable是怎么解决上一讲MySQL集群解决不好的水平分库问题的。
把一个数据表,根据主键的不同,拆分到多个不同的服务器上,在分布式数据库里被称之为数据分区( Paritioning)。分区之后的每一片数据,在不同的分布式系统里有不同的名字,在MySQL里呢,我们一般叫做Shard,Bigtable里则叫做Tablet。
上一讲里,MySQL集群的分区之所以遇到种种困难,是因为我们通过取模函数来进行分区,也就是所谓的哈希分区。我们会拿一个字段哈希取模,然后划分到预先定好N个分片里面。这里最大的问题,在于分区需要在一开始就设计好,而不是自动随我们的数据变化动态调整的。
但是往往计划不如变化快,当我们的业务变化和计划稍有不同,就会遇到需要搬运数据或者各个分片负载不均衡的情况。
所以,在Bigtable里,我们就采用了另外一种分区方式,也就是动态区间分区。我们不再是一开始就定义好需要多少个机器,应该怎么分区,而是采用了一种自动去“分裂”(split)的方式来动态地进行分区。
我们的整个数据表,会按照行键排好序,然后按照连续的行键一段段地分区。如果某一段行键的区间里,写的数据越来越多,占用的存储空间越来越大,那么整个系统会自动地将这个分区一分为二,变成两个分区。而如果某一个区间段的数据被删掉了很多,占用的空间越来越小了,那么我们就会自动把这个分区和它旁边的分区合并到一起。
这个分区的过程,就好像你按照A~Z的字母顺序去管理你的书的过程。一开始,你只有一个空箱子放在地上,然后你把你的书按照书名的拼音,从上到下放在箱子里。当有一本新书需要放进来的时候,你就按照字母顺序插在某两本书中间。而当箱子放不下的时候,你就再拿一个空箱子,放在放不下的箱子下面,然后把之前的箱子里的图书从中间一分,把下面的一半放到新箱子里。
而我们删除数据的时候,就要把书从箱子里面拿走。当两个相邻的箱子里都很空的时候,我们就可以把两个箱子里面的书放到一个箱子里面,然后把腾出来的空箱子挪走。这里的一个个“箱子”就是我们的分片,这里面的一本本书,就是我们的一行数据,而书名的拼音,就是我们的行键。可能以A、B、C开头的书多一些,那么它们占用的分区就会多一些,以U、V、W开头的书少一些,可能这些书就都在一个分区里面。
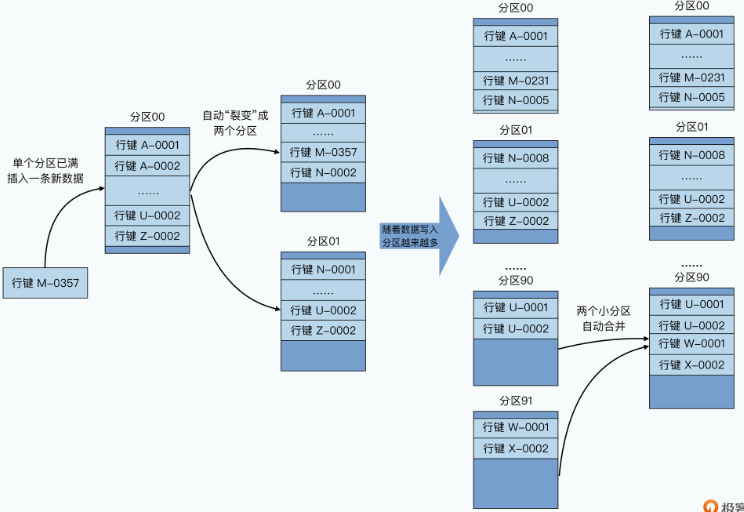
采用这样的方式,你会发现,你可以动态地调整数据是如何分区的,并且每个分区在数据量上,都会相对比较均匀。而且,在分区发生变化的时候,你需要调整的只有一个分区,再没有需要大量搬运数据的压力了。
# 2.3 通过 Master + Chubby 进行分区管理
那么看到这儿,你可能要问了:要是上一讲的MySQL集群也用这样的分区方式,问题是不是就解决了?
答案当然是办不到了。因为我们还需要有一套存储、管理分区信息的机制,这在哈希分片的MySQL集群里是没有的。在Bigtable里,我们是通过 Master 和 Chubby 这两个组件来完成这个任务的。这两个组件,加上每个分片提供服务的 Tablet Server,以及实际存储数据的 GFS,共同组成了整个Bigtable集群。
# 2.3.1 Master、Chubby 和 Tablet Server 的用途
Tablet Server 的角色最明确,就是用来实际提供数据读写服务的。一个Tablet Server上会分配到10到1000个Tablets,Tablet Server就去负责这些Tablets的读写请求,并且在单个Tablet太大的时候,对它们进行分裂。
而哪些Tablets分配给哪个Tablet Server,自然是由Master负责的,而且Master可以根据每个Tablet Server的负载进行动态的调度,也就是Master还能起到负载均衡(load balance)的作用。而这一点,也是MySQL集群很难做到的。
这是因为,Bigtable的Tablet Server只负责在线服务,不负责数据存储。实际的存储,是通过一种叫做SSTable的数据格式写入到GFS上的。也就是 Bigtable 里,数据存储和在线服务的职责是完全分离的。我们调度Tablet的时候,只是调度在线服务的负载,并不需要把数据也一并搬运走。
而在上一讲里的 MySQL 集群,服务职责和数据存储是在同一个节点上的。我们要想把负载大的节点调度到其他地方去,就意味着数据也要一并迁移走,而复制和迁移数据又会进一步加大节点的负载,很有可能造成雪崩效应。
这就体现了存储与控制分离的好处。
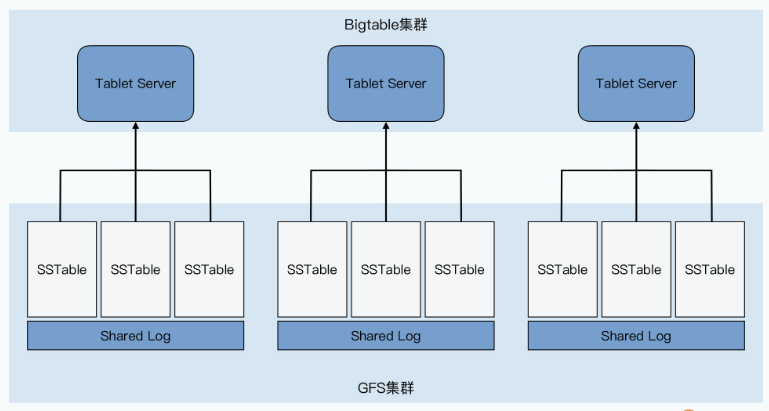
事实上,Master一共会负责5项工作:
- 分配Tablets给Tablet Server;
- 检测Tablet Server的新增和过期;
- 平衡Tablet Server的负载;
- 对于GFS上的数据进行垃圾回收(GC);
- 管理表(Table)和列族的Schema变更,比如表和列族的创建与删除。
那看到这里你可能要问了,好像Master加上Tablet Server就足以组成Bigtable了,为什么还有一个Chubby这个组件呢? 别着急,你接着往下看。
Bigtable需要Chubby来搞定这么几件事儿:
- 确保我们只有一个Master;
- 存储Bigtable数据的引导位置(Bootstrap Location);
- 发现Tablet Servers以及在它们终止之后完成清理工作;
- 存储Bigtable的Schema信息;
- 存储ACL,也就是Bigtable的访问权限。
这里面的最后两项只是简单的数据存储功能,我们就不多讲了,我们重点来看看前三项。
如果没有Chubby的话,我能想到最直接的集群管理方案,就是让所有的Tablet Server直接和Master通信,把分区信息以及Tablets分配到哪些Tablet Server,也直接放在Master的内存里面。这个办法,就和我们之前在GFS里的办法一样。但是这个方案,也就使得Master变成了一个单点故障点(SPOF-Single Point of Failure)。当然,我们可以通过Backup Master以及Shadow Master等方式,来尽可能提升可用性。
可是这样第一个问题就来了,我们在GFS的论文里面说过,我们可以通过一个外部服务去监控Master的存活,等它挂了之后,自动切换到Backup Master。但是,我们怎么知道Master是真的挂了,还是只是“外部服务”和Master之间的网络出现故障了呢?
如果是后者的话,我们很有可能会遇到一个很糟糕的情况,就是系统里面出现了两个Master。这个时候,可能两个客户端分别认为这两个Master是真的,当它们分头在两边写入数据的时候,我们就会遇到数据不一致的问题。
那么Chubby,就是这里的这个外部服务,不过Chubby不是1台服务器,而是5台服务器组成的一个集群,它会通过Paxos这样的共识算法,来确保不会出现误判。而且因为它有5台服务器,所以也一并解决了高可用的问题,就算挂个1~2台,也并不会丢数据。关于具体Chubby的原理和使用,我们会在后面讲解Chubby论文的时候专门介绍,今天就先不展开了。
# 2.3.2 为什么数据读写不需要 Master?
Chubby帮我们保障了只有一个Master,那么我们再来看看分区和Tablets的分配信息,这些信息也没有放在Master。Bigtable在这里用了一个很巧妙的方法,就是直接把这个信息,存成了Bigtable的一张 METADATA 表,而这张表在哪里呢,它是直接存放在Bigtable集群里面的,其实METADATA表自己就是一张Bigtable的数据表。
这其实有点像MySQL里面的information_schema表,也就是数据库定义了一张特殊的表,用来存放自己的元数据。不过,Bigtable是一个分布式数据库,所以我们还要知道,这个元数据究竟存放在哪个Tablet Server里,这个就需要通过Chubby来告诉我们了。
- Bigtable在Chubby里的一个指定的文件里,存放了一个叫做 Root Tablet 的分区所在的位置。
- 然后,这个Root Tablet的分区,是METADATA表的第一个分区,这个分区永远不会分裂。它里面存的,是METADATA里其他Tablets所在的位置。
- 而METADATA剩下的这些Tablets,每一个Tablet中,都存放了用户创建的那些数据表,所包含的Tablets所在的位置,也就是所谓的User Tablets的位置。
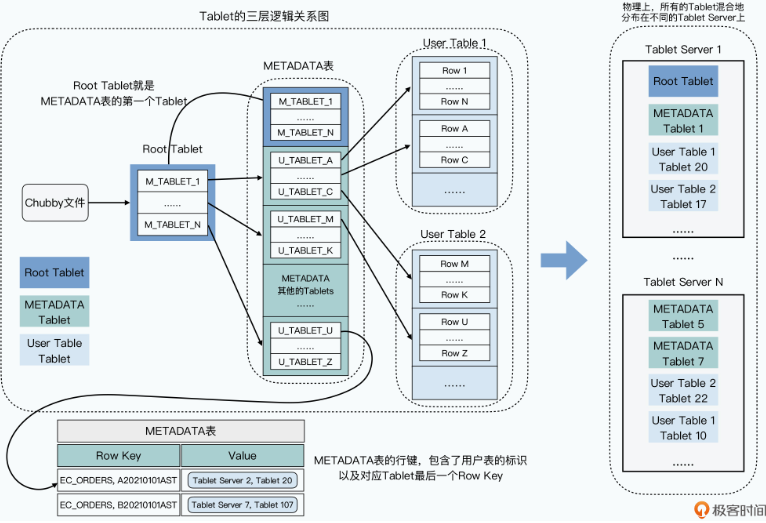
这里我们来看一个具体的Bigtable数据读写的例子,来帮助你理解这样一个三层结构。比如,客户端想要根据订单号,查找我们的订单信息,订单都存在Bigtable的ECOMMERCE_ORDERS表里,这张要查的订单号,就是A20210101RST。
那么,我们的客户端具体是怎么查询的呢?
- 客户端先去发起请求,查询Chubby,看我们的Root Tablet在哪里。
- Chubby会告诉客户端,Root Tablet在5号Tablet Server,这里我们简写成TS5。
- 客户端呢,会再向TS5发起请求,说我要查Root Tablet,告诉我哪一个METADATA Tablet里,存放了ECOMMERCE_ORDERS业务表,行键为A20210101RST的记录的位置。
- TS5会从Root Tablet里面查询,然后告诉客户端,说这个记录的位置啊,你可以从TS8上面的METADATA的tablet 107,找到这个信息。
- 然后,客户端再发起请求到TS8,说我要在tablet 107里面,找ECOMMERCE_ORDERS表,行键为A20210101RST具体在哪里。
- TS8告诉客户端,这个数据在TS20的tablet 253里面。
- 客户端发起最后一次请求,去问TS20的tablet 253,问ECOMMERCE_ORDERS表,行键为A20210101RST的具体数据。
- TS20最终会把数据返回给客户端。
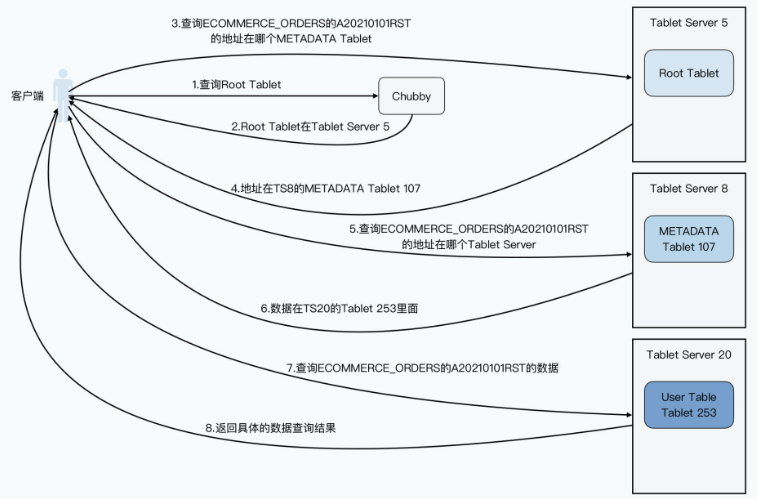
可以看到,在这个过程里,我们用了三次网络查询,找到了想要查询的数据的具体位置,然后再发起一次请求拿到最终的实际数据。一般我们会把前三次查询位置结果缓存起来,以减少往返的网络查询次数。而对于整个METADATA表来说,我们都会把它们保留在内存里,这样每个Bigtable请求都要读写的数据,就不需要通过访问GFS来读取到了。
这个Tablet分区信息,其实是一个三层Tablet信息存储的架构,而三层结构让Bigtable可以“伸缩”到足够大。METADATA的一条记录,大约是1KB,而METADATA的Tablet如果限制在128MB,三层记录可以存下大约 (128*1000)**2=2**34 个Tablet的位置,也就是大约160亿个Tablet,肯定是够用了。
这个设计带来了一个很大的好处,就是查询Tablets在哪里这件事情,尽可能地被分摊到了Bigtable的整个集群,而不是集中在某一个Master节点上。而唯一所有人都需要查询的Root Tablet的位置和里面的数据,考虑到Root Tablet不会分裂,并且客户端可以有缓存,Chubby和Root Tablet所在的Tablet服务器也不会有太大压力。
另外你还会发现,在整个数据读写的过程中,客户端是不需要经过Master的。即使Master节点已经挂掉了,也不会影响数据的正常读写。客户端不需要认识Master这个“主人”,也不依赖Master这个“主人”为我们提供服务。这个设计,让Bigtable更加“高可用”了。
而如果我们回顾前面整个查询过程,其实就很容易理解,为什么Chubby里面存的叫做Bigtable的引导位置,因为这个过程和操作系统启动的过程很类似,都是要从一个固定的位置读取信息,来获得后面的动态的信息。在操作系统里,这个是读取硬盘的第一个扇区,而在Bigtable里,则是Chubby里存放Root Tablet位置的固定文件。
# 2.3.3 Master 的调度者角色
的确,在单纯的数据读写的过程中不需要Master。Master只负责Tablets的调度而已,而且这个调度功能,也对Chubby有所依赖。我们来看一看这个过程是怎么样的:
- 所有的Tablet Server,一旦上线,就会在Chubby下的一个指定目录,获得一个和自己名字相同的 独占锁(exclusive lock)。你可以看作是,Tablet Server把自己注册到集群上了。
- Master会一直监听这个目录,当发现一个Tablet Server注册了,它就知道有一个新的Tablet Server可以用了,也就是可以分配Tablets。
- 分配Tablets的情况很多,可能是因为其他的Tablet Server挂了,导致部分Tablets没有分配出去,或者因为别的Tablet Server的负载太大,这些情况都可以让Master去重新分配Tablet。具体的分配策略论文里并没有说,你可以根据自己的需要实现对应的分配策略。
- Tablet Server本身,是根据是否还独占着Chubby上对应的锁,以及锁文件是否还在,来确定自己是否还为自己分配到的Tablets服务。比如Tablet Server到Chubby的网络中断了,那么Tablet Server就会失去这个独占锁,也就不再为原先分配到的Tablets提供服务了。
- 而如果我们把Tablet Server从集群中挪走,那么Tablet Server会主动释放锁,当然它也不再服务那些Tablets了,这些Tablets都需要重新分配。
- 无论是前面的第4、5点这样异常或者正常的情况,都是由Master来检测Tablet Server是不是正常工作的。检测的方法也不复杂,其实就是通过 心跳。Master会定期问Tablets,你是不是还占着独占锁呀?无论是Tablet Server说它不再占有锁了,还是Master连不上Tablet Server了,Master都会做一个小小的测试,就是自己去获取这个锁。如果Master能够拿到这个锁,说明Chubby还活得好好的,那么一定是Tablet Server那边出了问题,Master就会删除这个锁,确保Tablet Server不会再为Tablets提供服务。而原先Tablet Server上的Tablets就会变回一个未分配的状态,需要回到上面的第3点重新分配。
- 而Master自己,一旦和Chubby之间的网络连接出现问题,也就是它和Chubby之间的会话过期了,它就会选择“自杀”,这个是为了避免出现两个Master而不自知的情况。反正,Master的存活与否,不影响已经存在的Tablets分配关系,也不会影响到整个Bigtable数据读写的过程。
# 2.4 小结
好了,到了这里,相信你对整个Bigtable的系统架构就有一个清晰的了解了,现在我们就一起来回顾一下。
整个Bigtable是由4个组件组成的,分别是:
- 负责存储数据的GFS;
- 负责作为分布式锁和目录服务的Chubby;
- 负责实际提供在线服务的Tablet Server;
- 负责调度Tablet和调整负载的Master。
而通过 动态区域分区 的方式,Bigtable的分区策略需要的数据搬运工作量会很小。在Bigtable里,Master并不负责保存分区信息,也不负责为分区信息提供查询服务。
Bigtable是通过把分区信息直接做成了 三层树状结构的Bigtable表,来让查询分区位置的请求分散到了整个Bigtable集群里,并且通过 把查询的引导位置放在Chubby中,解决了和操作系统类似的“如何启动”问题。而整个系统的 分区分配工作,由Master完成。通过对于Chubby锁的使用,就解决了Master、Tablet Server进出整个集群的问题。
到这里,Bigtable的基础架构就介绍完了。不过我们还有两个非常重要的知识点需要深入探讨,一个是单个Tablet的底层存储和读写,具体是如何实现来做到高性能的,另一个是今天出现的神奇的Chubby到底是什么。接下来会逐渐找到答案。
# 3. SSTable 存储引擎详解
我们已经知道 Bigtable 的整体架构,这一章主要详细深入到 Bigtable 的数据部分,去看看它是怎么回事儿。这一部分将超越 Bigtable 的论文,深入到MemTable和SSTable的具体实现。通过这一章,我们希望搞懂两个知识点:
- 首先,自然是Bigtable本身的单个Tablet是如何提供服务的。
- 其次,是我们如何利用好硬件特性,以及合理的算法和数据结构,让单个Tablet提供足够强劲的性能。
当你把这两个知识点掌握清楚了,你就能很容易学会怎么实现一个单机存储引擎,并且能够对硬件性能、算法与数据结构的实际应用有一些心得。
# 3.1 Bigtable 的读写操作
在讲解Bigtable底层是怎么读写数据之前,我们先来看一看,Bigtable读写数据的API长什么样子。下面是论文里面提供的两段代码。
// Open the table
Table *T = OpenOrDie("/Bigtable/web/webtable");
// Write a new anchor and delete and old anchor
RowMutation r1(T, "com.cnn.www");
r1.Set("anchor:www.c-span.org", "CNN")
r1.Delete("anchor:www.abc.com");
Operation op;
Apply(&op, &r1);
2
3
4
5
6
7
8
9
Scanner scanner(T);
ScanStream *stream;
stream = scanner.FetchColumnFamily("anchor");
stream->SetReturnAllVersions();
scanner.Lookup("com.cnn.www");
for (; !stream->Done(); stream->Next()) {
printf("%s %s %lld %s\n",
scanner.RowName(),
stream->ColumnName(),
stream->MicroTimestamp(),
stream->Value());
}
2
3
4
5
6
7
8
9
10
11
12
这两段代码非常简单:
- 第一段,就是在一张叫做webtable的数据表上,对行键为com.cnn.www的数据进行操作。这个操作在这个anchor列族里修改了两个列,分别是将www.c-span.org列的值设置为CNN,以及将www.abc.com这个列删除掉了。因为Bigtable支持单行事务,所以这两个修改,要么都完成了,要么都没有完成,不会存在一个成功,一个失败的情况。
- 第二段,则是读取同样一张表里行键相同的数据,并且遍历里面所有的列,取出对应所有版本的时间戳和值,然后打印出来。其实就是一个从Bigtable里根据行键,随机读取一条数据的操作。
这两个操作,也就是Bigtable最常用的数据读写的场景,就是根据某一个行键去随机读写对应的列和列里面的值。那我们今天的主要任务,也是看一看Bigtable具体是如何高性能地实现这两个操作的。
# 3.2 如何提供高性能的随机数据写入?
在前面解读GFS的课程里,我们看到GFS这个文件系统本身,对随机读写是没有任何一致性保障的。而在上一讲里,我们又了解到Bigtable是一个支持随机读写的KV数据库,而且它实际的数据存储是放在GFS上的。这两点,听起来似乎是自相矛盾的,为什么一个对随机读写没有一致性保障的文件系统,可以拿来作为主要用途是随机读写的数据库的存储系统呢?
当时的传统机械硬盘并不喜欢随机写:
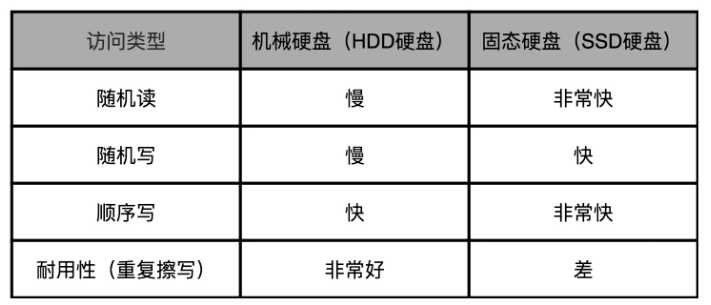
所以,Bigtable为了做到高性能的随机读写,采用了下面这一套组合拳,来解决这个问题:
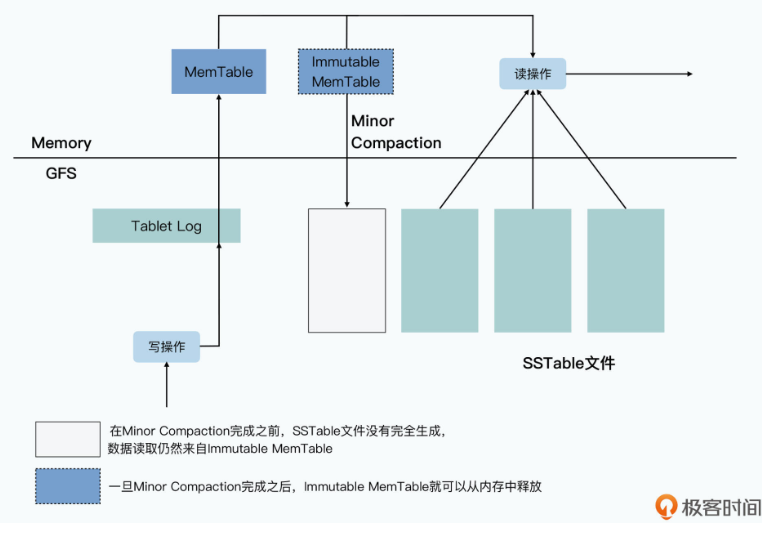
- 首先是将硬盘随机写,转化成了顺序写,也就是把Bigtable里面的提交日志(Commit Log)以及将内存表(MemTable)输出到磁盘的Minor Compaction机制。
- 其次是利用“局部性原理”,最近写入的数据,会保留在内存表里。最近被读取到的数据,会存放到缓存(Cache)里,而不存在的行键,也会以一个在内存里的布隆过滤器(BloomFilter)进行快速过滤,尽一切可能减少真正需要随机访问硬盘的次数。
Bigtable 实际写入数据的过程是这样的:
- 当一个写请求过来的时候,Tablet Server先会做基础的数据验证,包括数据格式是否合法,以及发起请求的客户端是否有权限进行对应的操作。这个权限设置,是Tablet Server从Chubby中获取到,并且缓存在本地的。
- 如果写入的请求是合法的,对应的数据写入请求会以追加写的形式,写入到GFS上的提交日志文件中,这个写入对于GFS上的硬盘来说是一个顺序写。这个时候,我们就认为整个数据写入就已经成功了。
- 在提交日志写入成功之后,Tablet Server会再把数据写入到一张内存表中,也就是我们常说的MemTable。
- 而当我们写入的数据越来越多,要超出我们设置的阈值的时候,Tablet Server会把当前内存里的整个MemTable冻结,然后创建一个新的MemTable。被冻结的这个MemTable,一般被叫做Immutable MemTable,它会被转化成一个叫做SSTable的文件,写入到GFS上,然后再从内存里面释放掉。这个写入过程,是完整写一个新文件,所以自然也是顺序写。
如果在上面的第2步,也就是提交日志写入完成之后,Tablet Server因为各种原因崩溃了,我们会通过重放(replay)所有在最后一个SSTable写入到GFS之后的提交日志,重新构造起来MemTable,提供对外服务。
在整个数据写入的过程中,你会发现只有顺序写,没有随机写。那你可能会有一些疑惑了,如果只是插入新数据,追加写当然就可以了。但是在前面的代码示例里面,是去更新数据和删除数据呀,为什么这样顺序写可以删除和修改数据呢?
实际上,这是因为我们并不会在写入的时候,去修改之前写入的数据。我们在插入数据和更新数据的时候,其实只是在追加一个新版本的数据。我们在删除数据的时候,也只是写入一个墓碑标记,本质上也是写入一个特殊的新版本数据。
而对于数据的“修改”和“删除”,其实是在两个地方发生的。
第一个地方,是一个叫做Major Compaction 的机制。按照前面的数据写入机制,随着数据的写入,我们会有越来越多的SSTable文件。这样我们就需要通过一个后台进程,来不断地对这些SSTable文件进行合并,以缩小占用的GFS硬盘空间。
第二个地方,是在我们读取数据的时候。在读取数据的时候,我们其实是读取MemTable加上多个SSTable文件合并在一起的一个视图。也就是说,我们从MemTable和所有的SSTable中,拿到了对应的行键的数据之后,会在内存中合并数据,并根据时间戳或者墓碑标记,来对数据进行“修改”和“删除”,并将数据返回给到客户端。
相信到这里,你应该就明白了,为什么在整个Bigtable的数据写入过程中,是没有任何到GFS的随机写入的。GFS硬盘上的SSTable的整个文件,一旦写入完成,就是不可变(Immutable)的,所有的数据写入,包括删除,都是写入一个数据的新版本。而后台,会有一个程序会定期地进行类似于“垃圾回收”的操作,通过合并SSTable,清理掉过期版本和被标记为删除的数据。
这也是为什么在Bigtable的数据模型里面,很自然地对于一个列下的值,根据时间戳可以有多个版本:
# 3.3 如何提供高性能的随机数据读取?
随机写入被转化成了顺序写,但是随机读我们还是避免不了的。而且按照前面的流程,你会发现,随机读的代价可不小。一次数据的随机查询,我们可能要多次访问GFS上的硬盘,读取多个SSTable。
接下来我们就一起来看一看,Bigtable是怎么在尽可能减少随机读取的情况下,来访问数据的。
我们先来看一下MemTable和SSTable的数据结构和文件格式。
MemTable的数据结构通常是通过一个AVL红黑树,或者是一个跳表(Skip List)来实现的。而BigTable的Memtable和SSTable的源码,一般被认为就是由Google开源的LevelDB来实现的。在实际的LevelDB源码中,MemTable是选择使用跳表来作为自己的数据结构。之所以采用这个数据结构,原因也很简单,主要是因为MemTable只有三种操作:
- 第一种是根据行键的随机数据插入,这个在数据写入的时候需要用到;
- 第二种是根据行键的随机数据读取,这个在数据读取的时候需要用到;
- 最后一种是根据行键有序遍历,这个在我们把MemTable转化成SSTable的时候会被用到。
而AVL红黑树和跳表在这三种操作上,性能都很好,随机插入和读取的时间复杂度都是O(logN),而有序遍历的时间复杂度,则是O(N)。
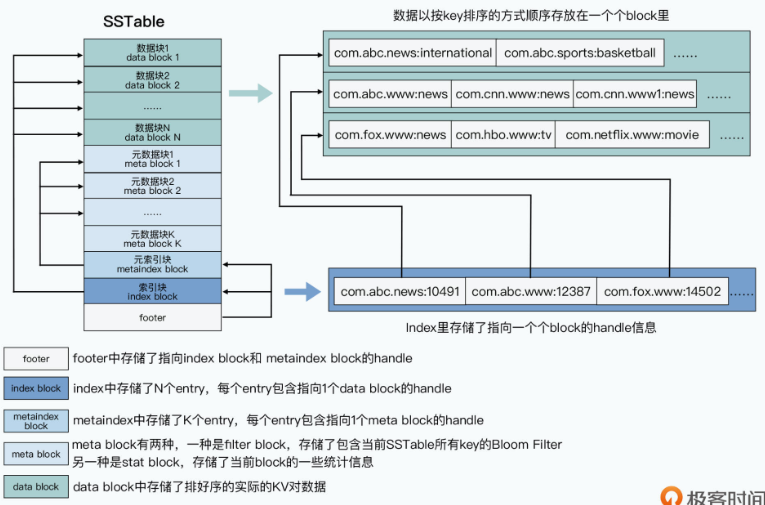
当MemTable的大小超出阈值之后,我们会遍历MemTable,把它变成一个叫做SSTable的文件。SSTable的文件格式其实很简单,本质上就是由两部分组成:
- 第一部分,就是实际要存储的行键、列、值以及时间戳,这些数据会按照行键排序分成一个个固定大小的块(block)来进行存储。这部分数据,在SSTable中一般被称之为数据块(data block)。
- 第二部分,则是一系列的元数据和索引信息,这其中包括用来快速过滤当前SSTable中不存在的行键的布隆过滤器,以及整个数据块的一些统计指标,这些数据我们称之为元数据块(meta block)。另外还有针对数据块和元数据块的索引(index),这些索引内容,则分别是元数据索引块(metaindex block)和数据索引块(index block)。
因为SSTable里面的数据块是顺序存储的,所以要做Major Compaction的算法也很简单,就是做一个有序链表的多路归并 就好了。并且在这个过程中,无论是读输入的SSTable,还是写输出的SSTable,都是顺序读写,而不是不断地去随机访问GFS上的硬盘。Major Compaction会减少同一个Tablet下的SSTable文件数量,也就是会减少每次随机读的请求需要访问的硬盘次数。
而当我们要在SSTable里查询数据的时候,我们先会去读取索引数据,找到要查询的数据在哪一个数据块里。然后再把整个数据块返回给到Tablet Server,Tablet Server再从这个数据块里,提取出对应的KV数据返回给Bigtable的客户端。
那么在这个过程中,Bigtable又利用了压缩和缓存机制做了更多的优化,下面我就来给你介绍下这些优化步骤:
首先,是通过压缩算法对每个块进行压缩。这个本质上是以时间换空间,通过消耗CPU的计算资源,来减少存储需要的空间,以及后续的缓存需要的空间。
其次,是把每个SSTable的布隆过滤器直接缓存在Tablet Server里。布隆过滤器本质是一个二进制向量,它可以通过一小块内存空间和几个哈希函数,快速检测一个元素是否在一个特定的集合里。在SSTable的这个场景下,就是可以帮助我们快速判断,用户想要随机读的行键是否在这个SSTable文件里。
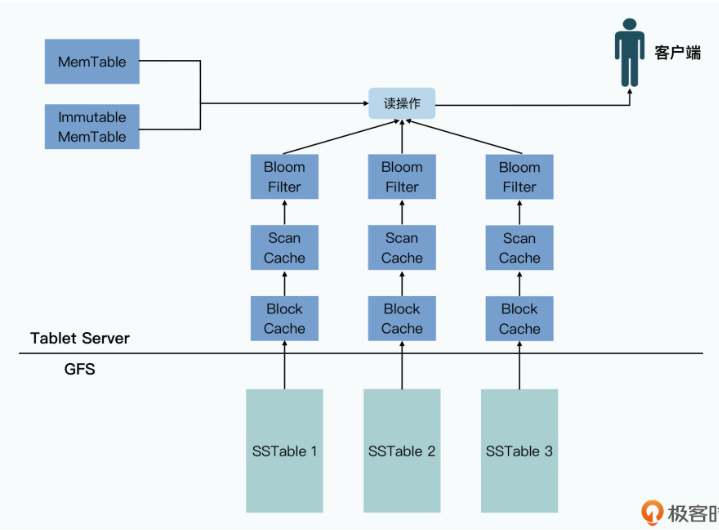
最后,Bigtable还提供了两级的缓存机制。
- 高层的缓存,是对查询结果进行缓存,我们称之为 Scan Cache。比如前面的示例代码中,我们要查询com.cnn.www这个行键的数据,那么第一次查询到了这个数据之后,我们会把对应的数据,放在Tablet Server的一个缓存空间里。这样,下一次我们查询同样的数据,就不需要再访问GFS上的硬盘了。
- 低层的缓存,是对查询所获取到的整个数据块进行缓存,我们称之为 Block Cache。还以com.cnn.www这个行键为例,我们会把它所在的整个块数据都缓存在Tablet Server里。因为一个块里存储的数据都是排好序的,所以当下一次用户想要查询com.cnn.www1这样的行键的时候,就可以直接从Block Cache中获取到,而不需要再次访问GFS上的SSTable文件。
需要注意的是,这两层缓存都是针对单个SSTable上的,而不是在单个Tablet上。而因为SSTable是一个不可变的数据,所以只要不出现Major Compaction,或者整个SSTable文件因为过期可以清理的情况,这些缓存都不会因为Tablet里写入新的数据而需要主动失效。新写入的数据更新都体现在MemTable中,不会影响到我们的SSTable。
这样,在有了后面两个优化步骤之后,我们就会发现 访问硬盘的次数大大减少 了。一方面,当读请求里的行键不存在的时候,我们有90%+乃至99%+的概率可以通过BloomFilter过滤掉。而当读请求的行键存在的时候,我们访问硬盘的次数也很少。而且对于一个Tablet下的多个SSTable文件来说,BloomFilter已经可以快速帮我们排除掉那些,不包含我们要查询的行键的SSTable的文件了。
然后是Block Cache,因为元数据和索引也是一个Block,所以只要一个SSTable常常被访问,这些数据就会被缓存在Tablet Server的内存里,所以查询索引的过程,也往往在内存里面发生。
而对于索引进行的实际数据查询,只要我们的查询有“时间局部性”,比如查询的通常是最近查询过的数据,或者有“空间局部性”,也就是连续查询的数据的行键是相邻的,我们就可以通过Scan Cache或者Block Cache给到答案,而不需要去访问GFS的文件系统。
只有完全没有规律的随机查询,才会使得我们的查询最终不得不大量进行随机的GFS文件访问,也就是变成随机的硬盘访问。而且更糟糕的是,我们还需要在网络上传输大量用不到的整个block的数据。在这种情况下,Bigtable的性能并不好。
在论文第7部分的性能评估里,你也可以看到,对于Bigtable来说,数据存储在GFS上,而不是放在内存里的随机读的性能是最差的,在500个Tablet Server的环境下,单个节点数据读取的吞吐量,只有随机写入的1/8左右。
不过,好在真实世界里,数据访问往往是满足局部性原理的,而且在Bigtable论文发表17年后的今天,我们大都用上了SSD硬盘,可以在很大程度上缓解这个问题。
# 3.4 小结
据随机写入,我们采用了三个简单的步骤来实现高性能:
- 首先是将随机写变为顺序写,将数据写入变成追加一条提交日志;
- 然后是将数据写入到内存而非硬盘上,也就是插入记录到通过跳表实现的MemTable里。
- 最后是定期将太大的MemTable冻结起来,变成一个根据行键排好序的SSTable文件。
事实上,这种随机写入数据的方式是在各类数据系统中,最常见的一个套路。如果你回头去看GFS的Master里对于元数据修改的实现,你会发现整个流程其实是非常相似的。只不过,在那里有些操作的名字不太一样而已。GFS里,对于Master里存放的元数据的操作步骤是这样的:
- 将操作日志(Operation Log)写入到本地和远端硬盘;
- 在master里修改实际的数据结构;
- 每当日志增长到一定程度,master会创建对应的检查点(checkpoint)。
GFS这里的操作日志和Bigtable的提交日志、检查点和定期输出的SSTable,其实都是起到了相同的作用。 在数据库系统中,一般称之为预写日志(WAL,Write-Ahead-Log),一旦写入,数据就持久化下来了。中间,我们总是把最新的数据更新在内存里更新一次,使得后续的数据查询可以从内存里面获取到。最后一步,不管是叫做checkpoint、Snapshot还是其他什么名字,都能够使得数据恢复只需要重放一小段时间的日志,使得故障恢复的时间尽可能短。
Bigtable的数据,是由内存里的MemTable和GFS上的SSTable共同组成的。在MemTable里,它是通过跳表实现了O(logN)时间复杂度的单条数据随机读写,以及O(N)时间复杂度的数据顺序遍历。而SSTable里,则是把数据按照行键进行排序,并分成一个个固定大小的block存储。而对应指向block的索引等元数据,也一样存成了一个个block。
另外,对于数据的读取,Bigtable也采用了三个办法来实现高性能:
- 首先是定期在后台合并SSTable,以减少读请求需要访问的SSTable的数量;
- 其次是通过在内存里缓存BloomFilter,使得对于不存在于SSTable中的行键,可以直接过滤掉,无需访问SSTable文件才能知道它并不存在;
- 最后是通过Scan Cache和Block Cache这两层缓存,利用局部性原理,使得查询结果可以在缓存中找到,而无需访问GFS上的硬盘。
回顾这整个存储引擎的实现方式,我们会发现,我们看到的Bigtable的数据模型,其实是一系列的内存+数据文件+日志文件组合下封装出来的一个逻辑视图。
数据库的存储引擎并不是用了什么高深的算法、特别的硬件,而是在充分考虑了硬件特性、算法和数据结构,乃至数据访问的局部性,综合到一起设计出来的一个系统。每一个环节都是教科书上可以找到的基础知识,但是组合在一起就实现了一个分布式数据库。而这个数据库暴露给用户的,也是一个非常简单的、类似于Map的根据键-值读写的接口。
Bigtable的论文,我们就先解读到这里了。不过,其实我们还有一个重要的话题没有聊,那就是关于Bigtable乃至所有数据库的“事务性”,放心,我并没有忘了这个重要的主题。关于Bigtable所支持的单行事务,以及数据库的事务性的原理,我们会在后面解读Megastore论文的时候,来进行更详细的分说。
推荐阅读
这一讲的主要内容,都是围绕着Bigtable里,单个Tablet的存储引擎的实现。实际的LevelDB或者其他的MemTable+SSTable的实现,都做了大量优化,以加快检索速度,或者减少存储的空间。如果你想深入了解MemTable和SSTable文件格式和内部实现的各种细节,一个很好的材料是 leveldb handbook (opens new window)。