 Dremel
Dremel
在解读 Hive 时,我们看到了 Hive 通过分区(Partition)和分桶(Bucket)的方式减少了 MapReduce 要扫描的数据,但这还远远不够。
要知道,Hive 表通常采用的都是“宽表”,也就是我们会把上百个字段都直接放在一张表里面,但是实际我们在分析这些日志的时候,往往又只需要用到其中的几个字段。
比如,我们之前的日志,有超过100个字段,但是如果我们想要通过IP段和IP地址,查看是否有人刻意刷单刷流量的话,我们可能只需要IP地址等有限的4~5个字段。而如果这些字段在Hive里并不是一个分区或者分桶的话,MapReduce程序就需要扫描所有的数据。这个比起我们实际需要访问的数据,多了数十倍。
但是,我们又不可能对太多字段进行分区和分桶,因为那样会导致文件数量呈几何级数地上升。就以上节课的例子来说,如果我们要在国家之后再加上“州”这个维度,并进行分区,那么目录的数量会增长50倍(以美国为例有 50 个州)。而如果我们再在时间维度上加上一个“小时”的数据维度,那么目录的数量还要再增长24倍。这么一算,我们只是加入了两个维度进行分区,目录数就已经变成了原来的 1200 倍,这会使得我们在 HDFS 上的文件数量大增,而每个文件都变得很小。而在这种大量、小文件的场景下,是发挥不出 MapReduce 进行顺序文件读写的吞吐量的优势的。
所以,即使已经进行了分区,我们的很多数据分析任务,仍然浪费了大量的性能在访问不需要的数据上。
此外,MapReduce 还有一个很明显的缺陷是:每个任务都有比较大的额外开销。在Hive里每执行一个HQL,都需要经过把程序复制到各个节点、启动Master和Worker,然后进行整个MapReduce的过程。可能我们只是访问1GB的数据,即使按照单机读写硬盘的吞吐量来计算,也就是一两分钟的事情。但是整个MapReduce运行的过程却很难少于3分钟,其中可能有一半时间,都花在了MapReduce这个程序运行机制带来的额外开销上了。
总而言之,MapReduce 乃至已经针对 MapReduce 作出了一定优化的 Hive,虽然可伸缩性很强,但是在整体的运行过程中其实非常浪费。
那么,想要解决这个问题,就请你和我一起来学习这篇《Dremel: Interactive Analysis of Web-Scale Datasets》论文。我们会通过两章的时间来解读这篇论文,第一章我们会主要关注 Dremel 里的数据是如何存储的,第二章我们会来了解 Dremel 的数据是如何计算的。
# 1. 深入剖析列式存储
通过这一讲的学习,你会搞清楚列式存储是怎么一回事儿,你也会知道,如果要在列式存储中支持复杂的嵌套结构类型,应该怎么做。并且,通过学习Dremel的论文,你也就搞清楚了Parquet这个开源的列式存储结构是怎么一回事儿了。
# 1.1 从行存储到列存储
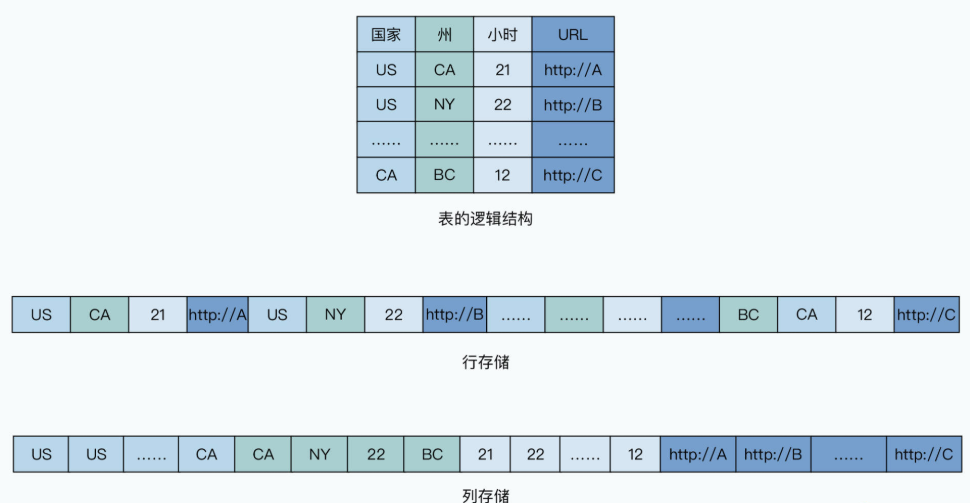
之前讨论的最初版本的 Hive 以及 Thrift 的存储数据方式都是行存储,也就是一行数据是存在一块的。这对于我们写程序去解析数据来说非常方便,我们只需要顺序读取数据,然后反序列化出来一个个对象,遍历去顺序处理就好了。
但是,当一行数据有100个字段,而我们的分析程序只需要其中5个字段的时候,就很尴尬了。因为如果我们顺序解析读取数据,我们就要白白多读20倍的数据。而如果跳着读取数据,这种随机读取会让读取性能大打折扣。所以一个新的想法出现了:我们能不能不要一行一行存储数据,而是一列一列存储数据?这样,当分析程序只需要几列数据的时候,就顺序地读取连续的、存放在一起的那几列数据就好了。
不过,这样存储之后,数据写入就变得有些麻烦了。原先只需要顺序写入,现在却需要向多个地方追加写入。解决办法也很简单,使用类似于 Bigtable 的 WAL+MemTable+SSTable 组合的解决方案。对于追加写入的数据,我们可以先写 WAL 日志,然后再把数据更新到内存中,接着再从内存里面,定期导出按列存储的文件到硬盘上。这样,我们所有的数据写入,也一样都是顺序写入的。
当然,在 Hadoop 这样的大数据环境中,甚至这样的追加写入操作都不需要。我们可以直接通过一个 MapReduce 程序,把原来的按行存储的数据做一个格式转换就好了,在这个 MapReduce 的过程中,数据的读写都是顺序的,我们的分析程序也只需要读取这个数据转换的结果就好了。
事实上,在一个分布式的环境里,我们的数据其实并不能称之为 100% 的列存储。因为我们在分析数据的时候,可能需要多个列的组合筛选条件。比如,我们可能同时需要采用用户所在的州和小时作为筛选条件。如果这两列的数据在不同的服务器上,那么我们就需要通过网络传输这些数据。我们在 GFS 的论文里也看到了,网络往往是大数据系统的第一瓶颈。

所以,更合理的解决方案是行列混合存储。因为,我们需要把一批行相同的数据,放在同一个服务器上,也就是说:在单个服务器上,数据是列存储的,但是在全局,数据又根据行进行分区,分配到了不同的服务器节点上。
而这个解决方案我们之前也已经用过了,那就是像 Bigtable 一样对数据进行分区。只要行键在同一区间的列存储的数据,存储在相同服务器的硬盘上,我们也就不需要通过网络传输,来把基于列存储的数据,组装成一行行的数据了。而这种存储方式,正好和我们前面通过 MapReduce 进行数据格式转换对上了。我们可以让所有的Map函数都读取分配给它的数据,然后转换成列存储,存储到自己所在的节点的硬盘上。这整个过程中,完全不需要网络传输。
# 1.2 解决嵌套结构问题
列存储并不是什么新鲜玩意儿,传统的OLAP数据库里,其实早就用上了。那么,为什么 Dremel 值得单独发上一篇论文呢?原因就在于,在大数据领域,这些数据对象支持复杂的嵌套结构。
如下是论文给的一个嵌套结构记录的示例:

即使你没有接触过 Protobuf,通过这个例子相信也不难看懂。这里定义了一个 Document 的结构体,它通过唯一的一个ID标识了出来。其中,Links 里面可以存放正向链接(也就是对应链接指向的文档)的 Document ID,以及反向链接(也就是是链接指向当前的网页)的 Document ID。
不过这里有一点需要注意,那就是一个 Document 里,可以有很多个正向链接,也可以有很多个反向链接。也就是说,Document 的结构里面被申明为 repeated 的 Backward 和 Foward 字段,都是一个 List,它们可以有很多个值。
我们再往下看,其中的Name group和Name group里的Language也是一样的,都被申明为了repeated,也就是一个网页可以有多个Name,每个Name里又会有多个Language。也就是我们可以在 List 里面,再套一层 List。
这样一来,问题一下子就变得麻烦了。原先我们的列存储,每个列有多少行数据是固定的。我们要组装数据也很容易,只要每个列的第1条数据和另一个列的第1条数据,合并在一起就好了。
但是在现在这个,一行数据的一个列,可能有多条数据。如果我们把每个字段的数据都按列存储,那么不同列的数据行数就不一样多了。比如,我把论文里图2的r1和r2两条数据,都按列存放下来,那么你能看得出来,Links.Backward的第三个值到底应该是在哪条记录里吗?
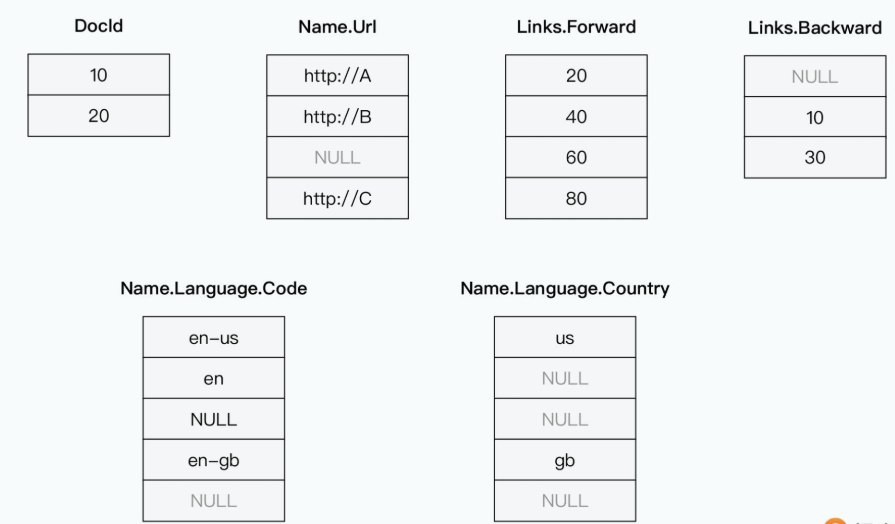
你可能会想,那我记录一下每行数据里,有多少个值不就好了?不过问题可没有那么简单,因为这里存在List套List的情况,甚至还可以有List套List再套List的情况。所以即使我们知道,前面的示意图里,Name.Language.Code的连续三个值都属于记录 r1,但是我们没法儿知道,它是属于里面的Name这个List里的第一个Name,还是第二个Name。其他多层嵌套的字段也有类似的问题。而且更进一步的,Dremel支持Optional的字段,也就是说,Name下面可能有Language字段,也可能没有。
这样,我们就没有办法把已经转化成列存储的数据,简单地重新组装回原始对象了。
而 Dremel 的论文,就对重复嵌套字段和可选字段这两个问题提供了一个解决方案,那就是除了在列里存储每一个值之外,它还额外存储了两个字段。有了这两个字段,我们就能反向组装出原来的一行行数据:
- 第一个字段叫做 Repetition Level,用来告诉我们,当前这个值相对于上一次出现,是由第几层嵌套结构引起的。
- 第二个字段叫做 Definition Level,用来告诉我们,当一个字段是 Optional,也就是可选的时候,它现在没有填充值,是因为多层嵌套的哪一层的字段为空。
# 1.2.1 Repetition Level
我们先来看看 Repetition Level 是怎么一回事。为了方便理解,我们下面把每个字段的 Reptition level 的值,简称为 r。
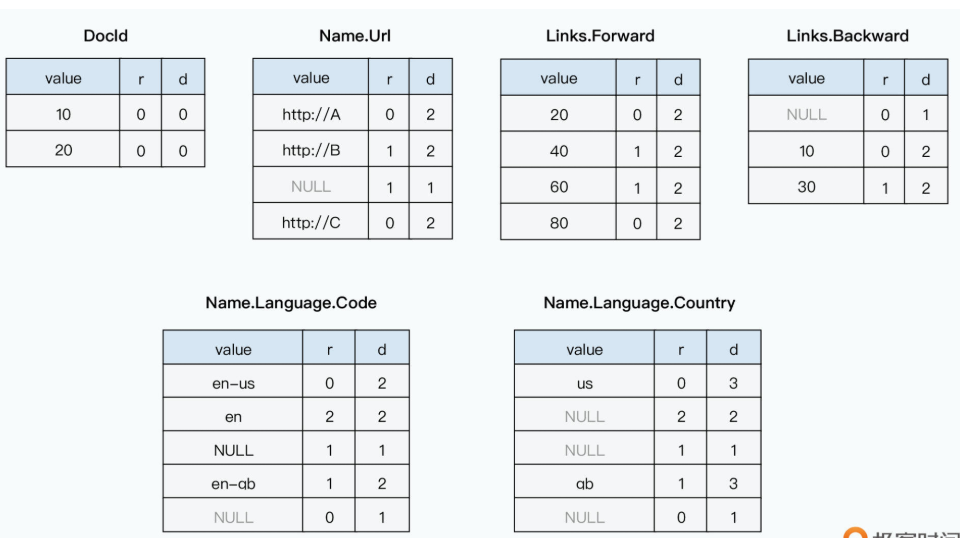
以 Name.Language.Code 这个字段为例,这个嵌套结构有三层,第 1 层是 Name,第 2 层是 Language,第 3 层则是 Code。其中,只有 Name 和 Language 是 repeated,也就是会重复出现的,第三层 Code 只是一个简单的值。比如下面这个示例数据:
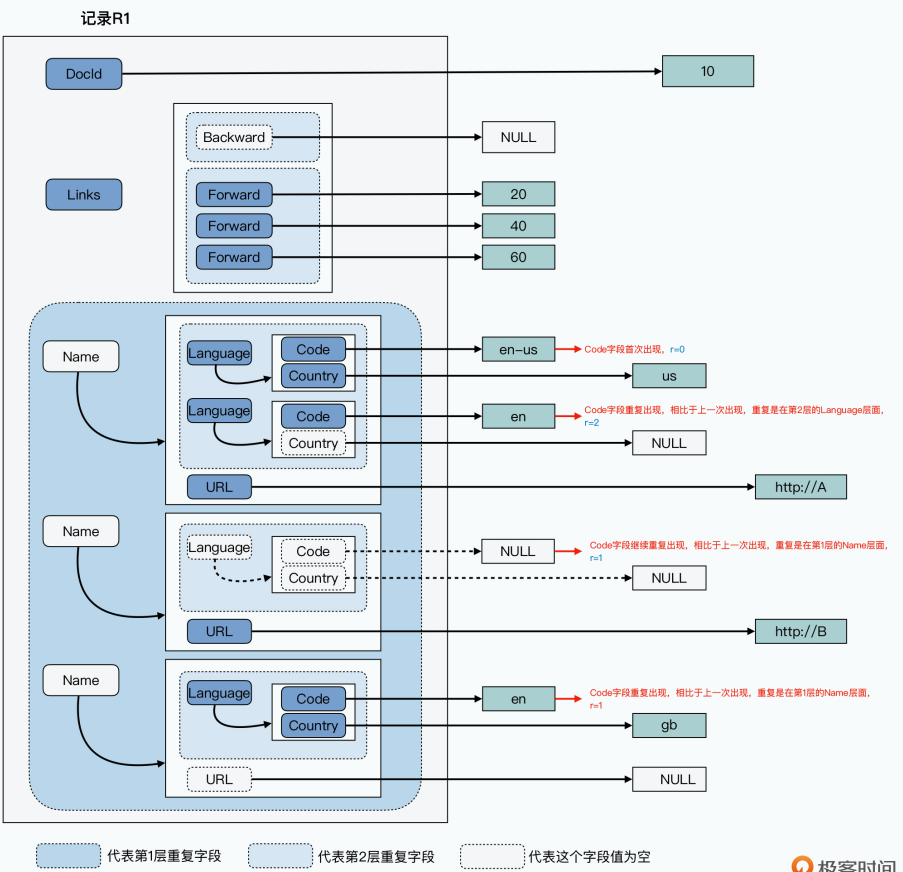
// 论文中图2的示例数据 r1
DocId: 10
Links
Forward: 20
Forward: 40
Forward: 60
Name
Language
Code: 'en-us'
Country: 'us'
Language
Code: 'en'
Name
Url: 'http://A'
Name
Language
Code: 'en-gb'
Country: 'gb'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- 对于r1这条记录,存放的第一个值
'en-us',因为它是第一个出现的,之前没有重复出现过,所以它的r是0。你可以认为,每当遇到一个r=0,意味着它已经到了一条新的Document记录中了。 - 存放的第二个值
'en',它的r=2,也就是说,这是一条重复出现的记录,并且,它是在第2层重复出现的。所以你可以看到,这个'en'在原来的结构当中,是新出现了同一个Name下的Lanuage,而不是新出现了一个第1层的Name。 - 存放的第三个值null,说明这个Name.Language.Code的值为空,而r=1,说明它也还是重复出现的一条记录,不过这次它是在第1层重复出现的了。也就是一个新的Name,这就对应着r1里面,URL为
'http://A'的那个Name,里面的确也没有Code,并且连Language也没有。 - 存放的第四个值
'en-gb'的r=1,则是说明重复在第1层,也就是又需要一个新的Name - 存放的第五个值null的r=0,则是说明这个值不来自于之前重复的列表,也就是一条新的Document记录,其实也就是进入论文图2里面的r2这条记录了。
这个 Repetition 其实指向的就是 Protobuf 中的 repeated 的关键字。我们通过这个 Repetition Level,就能够区分清楚,这个值存储的是哪一层的 repeated 的值。
# 1.2.2 Definition Level
那么到这里,你可能会觉得:这样看来问题就解决了呀,我们为什么还需要一个Definition Level呢?
这是因为,对于很多取值为NULL的字段来说,我们并不知道它为空,是因为自己作为一个Optional字段,所以没有值,还是由于上一层的Optional字段的整个对象为空。
而这个Definition Level,是要告诉我们,对于取值为NULL的对象,具体到哪一层 Optional 的对象的值变成了 NULL。知道了这个信息,我们通过列数据反向组装成行对象的时候,就能够100%还原了,不会出现不知道哪一层结构应该设置为空的情况。
在下面的讲解中,我们把这个Definition Level就记录为d,我们还是来看看Name.Language.Code这个字段。
可以看到,在Protobuf的定义中,对于Code字段来说,Name字段本身是必然需要的。只有1层Language字段是可要可不要的。那么,当Code字段为Null的时候,只有一种可能性,也就是第1层的Language是空,这个时候,d=1。因为只要Code出现,Name字段本身必然出现:
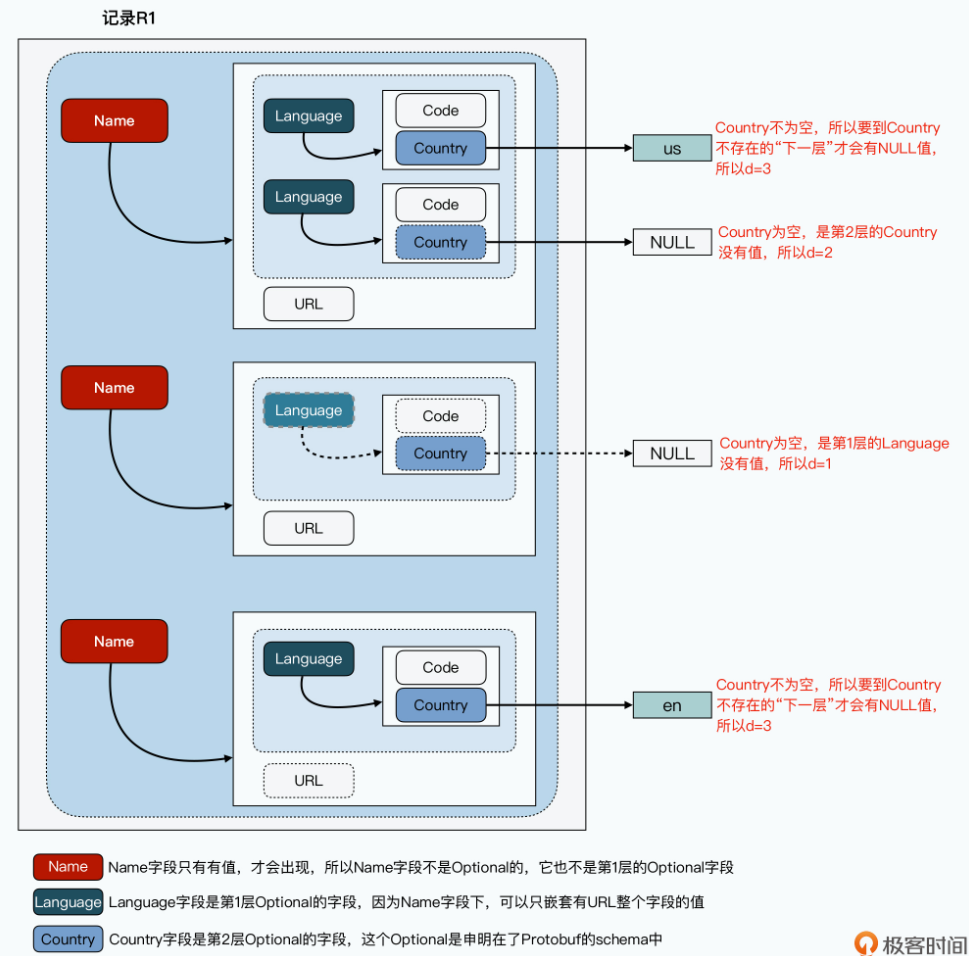
在前面的数据示例里,我们把这个Definition Level,记录为了d。可以看到,只要取值不是Null的情况,这个d其实就是当前字段作为Optional字段,定义的层数加1。
如果你去看Name.Language.Country这个列的数据,可以更清楚地做一个对比。
首先和前面一样,Name字段本身不能为NULL。而Language、Country字段都是Optional的,那么Country没有值,可能是因为第1层的Language就已经是Null了,也可能是因为第2层的Country字段本身是NULL。
这里你可以看到,第一个Country的值是 'us',那么它的d就是Country本身,作为Optional字段嵌套的层数加1,也就是d=3;第二和第三个值为null,但是它们的Definition Level并不一样,分别是2和1。
- 通过对比原始的数据,可以看到,第一个Country没有值,但是第1层Optional的Language不是空的,里面还有一个Code取值是
'en',因为它是到Country这个第2层的时候,才是NULL的,所以d=2。 - 而第二个Country没有值,它的第1层的Language也不存在,所以d=1。
就这样,Dremel通过Repetition Level和Definition Level这两个字段,就巧妙地在把数据拆分成列之后,能够重新把它们组装起来,100%还原了原先一行行的数据。 而这样拆分成按列存储,在大部分的数据分析情况下,都会大大减少我们需要扫描的数据,提升我们进行数据分析的效率。
Dremel的论文发表之后,的确也有很多工程师表示,论文里对于列存储的解决方法写得不够清楚。Twitter的工程团队,在2013年发表了开源项目Parquet,并专门在他们的官方博客上,详细解释了Parquet的数据存储格式,是如何通过Dremel论文里面的原理实现的。我在这里放上对应的 链接 (opens new window),你可以去读一下。
# 2. 他山之石的 MPP 数据库
以往 MapReduce 分析数据往往需要几十分钟来完成,而我们自然希望 SQL 在大数据集上能在几十秒甚至十几秒内就得到结果。所以 Google 并没有在列存储上止步,而是借鉴了多种不同的数据系统,搭建起了整个 Dremel 系统,真的把在百亿行的数据表上,常见 OLAP 分析所需要的时间,缩短到了 10 秒这个数量级上。那么,这节课我们就来看看Dremel是通过什么样的系统架构,做到这一点的。
和所有工程上的进展一样,Dremel 也是从很多过去的系统中汲取了养分:
- 第一,它从传统的 MPP 数据库,学到了数据分区和行列混合存储,并且把计算节点和存储节点放在同一台服务器上。
- 第二,它从搜索引擎的分布式索引,学会了如何通过一个树形架构,进行快速检索然后层层归并返回最终结果。
- 第三,它从 MapReduce 中借鉴了推测执行(Speculative Execution),来解决了少部分节点大大拖慢了整个系统的整体运行时间的问题。
而这三个的组合,就使得 Dremel 最终将百亿行数据表的分析工作缩短到了 1 分钟以内。
通过这节课的学习,我希望你不仅能够学到 Dremel 的具体架构的设计,更能够学会在未来的架构设计工作中,博采众长,做出让人拍案叫好的系统设计。
# 2.1 瓶颈并不出现在硬件
Dremel采用的列存储,已经极大地减少了我们扫描数据的浪费。在论文里,Google给出了这样一组数据:在3000个节点上,查询一个87TB、一共有240亿条数据的数据集,查询的内容是一个简单的Word Count程序。如果采用MapReduce去读取行存储的数据,那么需要读取87TB的数据。而如果采用列存储的话,因为只需要读取一列数据,所以只扫描了0.5TB的数据,整个MapReduce程序执行的时间,也缩短了整整一个数量级。
这也是为什么,在Dremel论文发表之后,开源社区很快跟进了这个支持嵌套的列存储的存储格式,也就催生了 Parquet 这个开源项目。
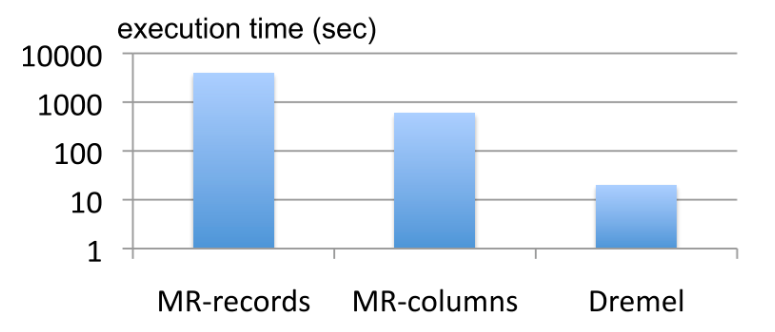
不过,如果你去看论文中的图10,你会发现,使用 Dremel 比传统的 MapReduce 读取列存储的数据还要再快一个数量级。那这又是怎么做到的呢?请你和我接着一起往下看。
我们之前提过很多次,MapReduce虽然伸缩性非常好,非常适合进行大规模的数据批处理,但是它也有一些明显的缺陷,其中很重要的一个问题,就是每个任务都有相对比较大的额外开销(overhead)。
所以即使有了 Hive,可以让分析师不用写程序,可以直接写 SQL,另外列存储也让我们需要扫描的数据大大减少了,但是 MapReduce 这个额外开销,始终还是会让我们的分析程序的运行时间在分钟级别。而前面的图里我们可以看到,Dremel则可以让我们这样的SQL跑在10秒级别。说实话,刚看到这个数据的时候,我是有点难以置信的。事实上,不只是我这样的工程师这么想,著名的 Wired (opens new window) 在 Dremel 发表之后就报道过,像 Berkeley 的教授阿曼多·福克斯(Armando Fox)就说,“如果你事先告诉我Dremel可以做什么,那么我不相信你可以把它做出来”。
不过,回过头来,从硬件的性能来说,这看起来又是完全做得到的。论文里给出的实验数据里,是用 3000 个节点,去分析 0.5TB 的数据,这意味着每个节点只需要分析 167MB 的数据。即使是传统的 5400 转的机械硬盘,顺序读写的确也只需要数秒钟,再加上网络传输和 CPU 的计算时间,的确也就是个 10 秒钟上下的时间。因此,计算时间的瓶颈并没有出现在硬件上。
# 2.2 Dremel 的系统架构
Dremel之所以这么快,是因为它的底层计算引擎并不是MapReduce。Dremel一方面继承了很多GFS/MapReduce的思路,另一方面也从传统的MPP(Massively Parallel Processing)数据库和搜索引擎的分布式检索模块,借鉴了设计思路。其实它的核心思路就是这四条:
- 让计算节点和存储节点放在同一台服务器上。MPP数据库和搜索引擎的分布式索引的架构也是这样的。
- 进程常驻,做好缓存,确保不需要大量的时间去做冷启动。这一点,也跟MPP数据库和分布式索引采用的架构和优化手段类似。
- 树状架构,多层聚合,这样可以让单个节点的响应时间和计算量都比较小,能够快速拿到返回结果。这个架构,和搜索引擎的分布式索引架构是完全相同的。
- 最后一点则仍然来自于GFS/MapReduce,一方面是即使不使用GFS,数据也会复制三份存放到不同的节点。然后在计算过程中,Dremel会监测各个叶子服务器的执行进度,对于“落后”的计算节点,会调度到其他计算节点,这个方式和MapReduce的思路是一样的。更进一步的,Dremel还会只扫描98%乃至99%的数据,就返回一个近似结果。对于Top K,求唯一数,Dremel也会采用一些近似算法来加快执行速度。这个方法,也是我们在MapReduce中经常用到的。
那么下面,我们就对着论文中Dremel的系统架构图,一起来看一下它是如何组合 GFS/MapReduce、MPP 数据库,以及搜索引擎的系统架构,来实现一个能够在数十秒内返回分析结果的 OLAP 系统的。
Dremel采用了一个多层服务树的架构,整个服务树里面有三种类型的节点:
- 首先是根服务器(root server),用来接收所有外部的查询请求,并且读取Dremel里各个表的METADATA,然后把对应的查询请求,路由到下一级的服务树(serving tree)中。
- 然后是一系列的中间服务器(intermediate servers),中间服务器可以有很多层。比如第一层有5个服务器,那么每个服务器可以往下再分发下一层的5个服务器,它是一个树状结构,这也是服务树的这个名字的由来。我们所有查询Dremel系统的原始SQL,每往下分发一层,就会重写(rewrite)一下,然后把结果在当前节点做聚合,再返回给上一层。
- 最下面是一层叶子服务器(leaf servers),叶子服务器是最终实际完成数据查询的节点,也算是我们实际存储数据的节点。
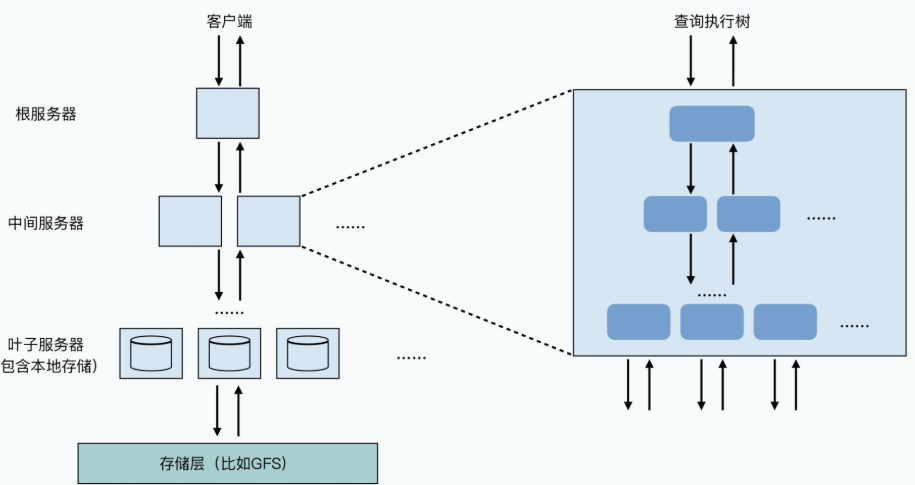
光这样讲系统的架构实在还是太抽象,我们还是来看看论文里给到的 SQL 的例子:
SELECT A, COUNT(B) FROM T GROUP BY A
这是一个我们在日常数据分析中很常见的 SQL,它是从某一个表里 T,按照某一个维度 A(比如国家、时间),看某一个统计指标 B(比如页面访问量、唯一用户数)这样的数据。这个 SQL 在 Dremel 上执行的过程是这样的。
首先,SQL 会发送到根服务器,根服务器会把整个 SQL 重写成下面这样的形式。
SELECT A, SUM(c) FROM (
UNION ALL … ) GROUP BY A
其中的每一个
= SELECT A, COUNT(B) AS c FROM GROUP BY A
这个解决办法其实一看就能看懂。因为原始的SQL是进行统计计数,那么我们只需要让中间服务器,分别去统计一部分分区数据的统计计数,再把它们累加到一起,就可以拿到最终想要的结果1。这里的
事实上,这里面的
# 2.3 行列混合存储的 MPP 架构
上节课我们学习过列存储的内容,我们知道Dremel的列存储本质上是行列混合存储的。所以每一个节点所存储的数据,是一个特定的分区(Partition),但是里面包含了这个分区所有行的数据。这样当数据到达叶子节点的时候,叶子节点需要执行的 SQL 只需要访问一台物理服务器。在这种情况下,我们可能有两种方案:
- 一种是对应的数据,就直接存放在叶子节点的服务器的本地硬盘上。这种方式,也是传统的MPP数据库采用的方式,也是 Dremel 系统在2006年,在 Google 内部开始使用的时候采用的方式,直到论文发表的 2009 年,这还是 Dremel 系统主要采用的方案。
- 另一种方式,则是叶子节点本身不负责存储,而是采用一个共享的存储层,比如 GFS。Dremel 从 2009 年开始,就逐步把存储层全部迁移到了 GFS 上。
把数据存储和计算放在同一个节点,以及将用户 SQL 查询重写,并行分发到多个节点并且汇总所有节点的查询结果,是MPP数据库的常见方案。这也是为什么 Dremel 论文里说,它从 MPP 数据库里借鉴了很多解决问题的思路。
# 2.4 树形分发的搜索引擎架构
而这个一层层服务树分发的机制,则是借鉴了搜索引擎的分布式检索机制。数据分区到不同的叶子节点上,就是相当于我们把不同的文档分片到不同的索引分片服务器上。
每一个索引分片服务器,会完成自己分片数据上的检索工作,然后把结果返回给上一层的中间服务器。中间服务器也会在自己这一层,把检索结果再进行合并处理,再往上一层层返回,直到根服务器。
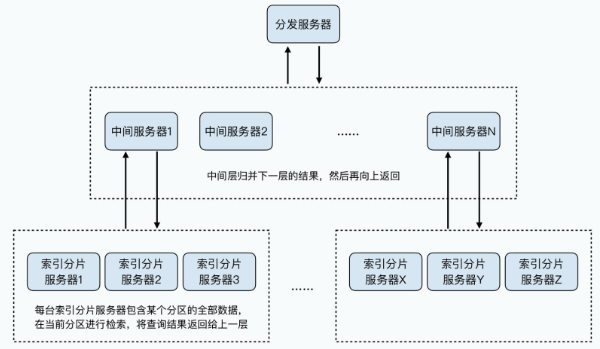
我们可以拿一个例子来看看,Dremel 和搜索引擎的分布式索引有哪些相像之处。最合适的一个例子,就是求一个数据集中排序的 Top K,也就是前 K 项的返回结果,它对应的 SQL 就是这样的:
SELECT A, B, C FROM T ORDER BY D LIMIT K
然后这个查询,在根服务器就会被重写成这样:
SELECT A, B, C FROM (
UNION ALL … ) ORDER BY D LIMIT K
里面的每一个
= SELECT A, B, C AS c FROM ORER BY D LIMIT K
然后每一个
这个和搜索引擎的分布式索引的架构是完全一样的,唯一的差别是,搜索引擎计算TOP K的方式更加复杂一些,需要利用倒排索引,以及根据搜索的关键词,计算文档的一个“分数”来进行排名而已。
这个架构中最核心的价值,在于可以通过中间服务器来进行“垂直”扩张。并且通过“垂直”扩张,可以在计算量基本不变的情况下,通过服务器的并行,来缩短整个SQL所花费的时间。也就是通过增加更多的服务器, 让系统的吞吐量(Throughoutput)不变,延时(Latency)变小。这个“垂直”扩张,并不是所谓的对硬件升级进行Scale-Up,而是增加中间层服务器,增加归并聚合计算的并行度。
因为实际扫描数据,是在最终的叶子节点进行的,所以这一层花费的时间和性能是固定的。如果我们没有中间服务器,而是所有的叶子节点数据都直接归并到根服务器,那么性能瓶颈就会在根服务器上。
根服务器需要和3000个节点传输数据,并在根节点进行聚合。而这个聚合又在一个节点上,只能顺序进行,即使每一个叶子节点返回的数据,在根节点进行数据聚合只需要20毫秒,那么我们也需要1分钟才能完成3000个节点的数据聚合。
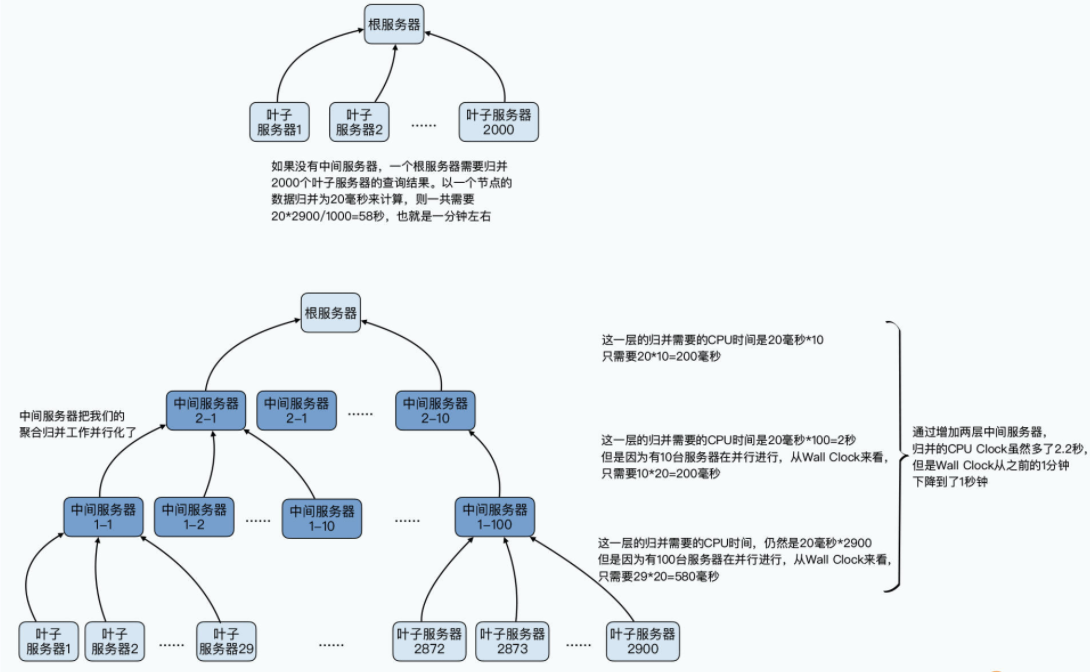
而如果我们在中间加入中间层的服务器,比如,我们有100个中间层的服务器,每个服务器下面聚合30个叶子服务器。那么中间层服务器就只需要600毫秒完成中间层的聚合,中间层的结果到根服务器也只需要2秒,我们可以在3秒内完成两层的聚合工作。
当然,在实际的 SQL 执行过程中,我们还有叶子节点扫描数据,以及数据在叶子节点和中间层,还有中间层和根服务器之间的网络传输开销,实际花费的时间会比这个多一些。但是中间层,帮助我们把数据归并的工作并行化了。我们归并工作需要的 CPU 时间越多,这个并行化就更容易缩短整个查询的响应时间。
我们的叶子节点越多,叶子节点返回的数据记录越多,增加中间层就越划算。论文里的实验部分针对不同的SQL和不同层数的中间服务器做了各种实验,你可以去仔细看一看。
这里,我们可以来对照着看看实验部分里,两个SQL中的Q2和Q3:
Q2:SELECT country, SUM(item.amount) FROM T2 GROUP BY country
Q3:SELECT domain, SUM(item.amount) FROM T2 WHERE domain CONTAINS ’.net’ GROUP BY domain
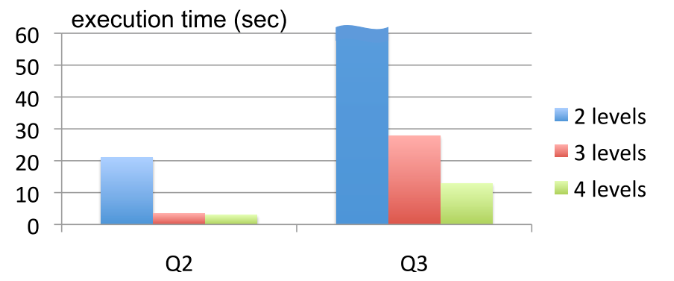
其中,Q2是按照国家进行数据聚合,因为国家的数量很少,所以每一个叶子节点返回的数据量也很小。但是即使这样,在没有中间节点的情况下,因为根服务器要和3000个叶子服务器一一通信、聚合数据,花费的时间也要20秒。而我们只要加上一个中间层,所花费的时间立刻缩短到了3秒,但是要注意,这个时候即使我们再增加中间层,时间也无法缩短了。
而里面的Q3,是按照域名进行数据聚合。我们知道互联网上的域名数量特别多,在这个SQL中,最终一共会有110万个域名。没有中间层的时候,执行时间需要超过一分钟。增加了100个节点的中间层之后,时间就缩短了一半以上,而当我们在中间层再加一层,把整个服务器的树形结构变成 1:10:100:2900 的时候,执行时间能够再缩短一半,到15秒之内。
其实,这个树形垂直扩展的架构,也是搜索引擎能从无穷无尽的网页中,快速在几百毫秒之内给到你结果的核心所在。
# 2.5 来自 MapReduce 的容错方案
除了 MPP 数据库和搜索引擎之外,Dremel 也没有忘了向自家的前辈 MapReduce 借鉴经验。我们刚才看到,Dremel 的整个服务器集群也不小,实验里就动用了 3000 台服务器。那么一旦遇到这种情况,我们一样要面临容错的问题。
而 Dremel 和 MapReduce 一样,会遇到网络问题、硬件故障。乃至于个别叶子节点因为硬盘可能将坏未坏,虽然仍然能够读取数据,但是就是特别慢,这些它会遇到的问题,其实 MapReduce 里都遇到过。所以 Dremel 自然也就大大方方地借鉴了 MapReduce 和 GFS 里,已经用过的几个办法:
- 首先是虽然数据存储到了本地硬盘,也会有 3 份副本。这样,当我们有个别节点出现故障的时候,就可以把计算请求调度到另外一套有副本数据的节点上。
- 其次,是借鉴了 MapReduce 的 推测执行功能,Dremel 也会监测叶子节点运行任务的进度。在 3000 个节点里,我们总会遇到一些节点跑起来特别慢,拖慢了整个系统返回一个查询结果的时间。往往 99% 的节点都算完了,大家等这几个节点要等上个三五分钟。这些节点无论是在 MapReduce 还是 Dremel 中都会存在,我们一般称它们为“掉队者”(Stragglers)。
而 Dremel 和 MapReduce 一样,一旦监测到掉队者的出现,它就会把任务再发给另外一个节点,避免因为单个节点的问题,导致整个任务的延时特别长。
另外,在 MapReduce 里,我们最终还是要等待所有的 Map 和 Reduce 函数执行完才给出结果。而在 Dremel 里,我们可以设置扫描了 98% 或者 99% 的数据就返回一个近似的结果。
一方面,从 Dremel 的实验数据来看,通常 99% 的到叶子节点处理的数据是低于 5 秒的,但是另外的少部分数据往往花费了非常长的时间,甚至会到几分钟。另一方面,Dremel 是一个交互式的分析系统,更多是给分析师分析数据给出结论,而不是生成一个用来财务记账的报表,数据差上个 1%~2% 并不重要。
# 小结
好了,到这里,Dremel 的架构我们就学习完了,那我们就一起来总结一下吧。
可以看到,Dremel 对于大数据集下的 OLAP 系统的设计,并没有止步于我们上节课所说的列存储。
通过借鉴 MPP 数据库,把计算和存储节点放在一起,以及通过行列混合的方式,Dremel 完成了数据的并行运算,而且缩减了需要扫描的数据。通过借鉴搜索引擎的分布式索引系统,Dremel 搭建了一个树形多层的服务器架构,通过中间层服务器进行数据聚合,减少了整个系统计算和返回结果的延时。
而通过借鉴 MapReduce 的容错机制,Dremel会把太慢的任务调度到其他拥有数据副本的节点里去,并且更激进地抛弃那些“掉队者”节点的数据,在只扫描了 98%~99% 的数据的时候,就返回结果,尽可能让每个 SQL 都能快速看到结果。
其实,从硬件层面的参数来看,Dremel 能够在几秒乃至几十秒内,扫描 240 亿条数据中的几列数据进行分析,的确是做得到的。Dremel本身也没有发明什么新算法、新架构,而是通过借鉴现有各类成熟的并行数据库、搜索引擎、MapReduce搭建起了一个漂亮的框架,把大部分人眼里的不可能变成了可能。相信这一点,对于所有想要做架构设计的同学来说,都会有所启发。
# 推荐阅读
过去的那么多节课里,我们读的都是至少十年前的“老”论文了。其实所有的这些系统都在不停地进化。Dremel论文的几位作者,在2020年的VLDB里,就发表了一篇新论文叫做 《Dremel: A Decade of Interactive SQL Analysis at Web Scale》 (opens new window)。这篇论文讲述了Dremel系统后续的迭代更新,其中包括数据存储如何迁移到共享的GFS上、如何通过内存Shuffle架构提升Dremel的性能等等,很值得一读。从十年之后回顾看一个老系统,我们会看到技术架构是如何在不断的权衡、优化中进步的。