 The Google File System
The Google File System
参考:大数据经典论文解读 | 极客时间 (opens new window) 03-05 讲
在这篇论文发表之前,工业界的分布式系统最多也就是几十台服务器的MPI集群。而这篇GFS的论文一发表,一下子就拿出了一个运作在1000台服务器以上的分布式文件系统。并且这个文件系统,还会面临外部数百个并发访问的客户端,可以称得上是石破天惊。如今开源社区中的各种分布式系统都远比当初的 GFS 要更加复杂、强大,如今再回顾这篇论文,GFS 可以说“技术上辉煌而工程上保守”。说GFS技术上辉煌,是因为Google通过廉价的PC级别的硬件,搭建出了可以处理整个互联网网页数据的系统。而说GFS工程上保守,则是因为GFS没有“发明”什么特别的黑科技,而是在工程上做了大量的 trade-off。
在我看来吗,GFS 定了三个非常重要的设计原则,这三个原则带来了很多和传统的分布式系统研究大相径庭的设计决策。但是这三个原则又带来了大量工程上的实用性,使得GFS的设计思路后续被Hadoop这样的系统快速借鉴并予以实现。下面就介绍一下这三个原则:
# 1)以工程上“简单”作为设计原则
GFS直接使用了Linux服务上的普通文件作为基础存储层,并且选择了最简单的单Master设计。单Master让GFS的架构变得非常简单,避免了需要管理复杂的一致性问题。不过它也带来了很多限制,比如一旦Master出现故障,整个集群就无法写入数据,而恢复Master则需要运维人员手动操作,所以GFS其实算不上一个高可用的系统。
但另外一方面,GFS还是采用了Checkpoints、操作日志(Operation Logs)、影子Master(Shadow Master)等一系列的工程手段,来尽可能地保障整个系统的“可恢复(Recoverable)”,以及读层面的“可用性(Availability)”。
可以说,GFS是恪守“简单”这个原则而设计了第一版本的系统,并且在不破坏这个设计原则的情况下,通过上面一系列独立可插拔的工程策略,来进一步提高系统的可用性。
# 2)根据硬件特性来进行设计取舍
2003年,大家都还在用机械硬盘,随机读写的性能很差,所以在GFS的设计中,重视的是顺序读写的性能,对随机写入的一致性甚至没有任何保障。
而你要知道,2003年的数据中心,各台机器的网卡带宽只有100MB,网络带宽常常是系统瓶颈。所以GFS在写数据的时候,选择了流水线式的数据传输,而没有选择树形的数据传输方式。更进一步地,GFS专门设计了一个Snapshot的文件复制操作,在文件复制的时候避免了数据在网络上传输。这些设计都是为了减少数据在网络上的传输,避免我们有限的网络带宽成为瓶颈。
# 3)根据实际应用的特性,放宽了数据一致性(consistency)的选择
论文里也提到,GFS是为了在廉价硬件上进行大规模数据处理而设计的。所以GFS的一致性相当宽松。GFS本身对于随机写入的一致性没有任何保障,而是把这个任务交给了客户端。对于追加写入(Append),GFS也只是作出了“至少一次(At Least Once)”这样宽松的保障。
可以说,GFS是一个基本没有什么一致性保障的文件系统。但即使是这样,通过在客户端库里面加上校验、去重这样的处理机制,GFS在大规模数据处理上已经算是足够好用了。
看到这里,你应该可以大致理解 GFS 的设计决策,其实这三个设计原则可远没有上面说的这么简单。所以接下来,将分成三大节的内容来分别剖析这三个重要的设计选择。
# 1. Master 的三个身份
这一节来看一下 GFS 的第一个选择:“保持简单”的设计原则。
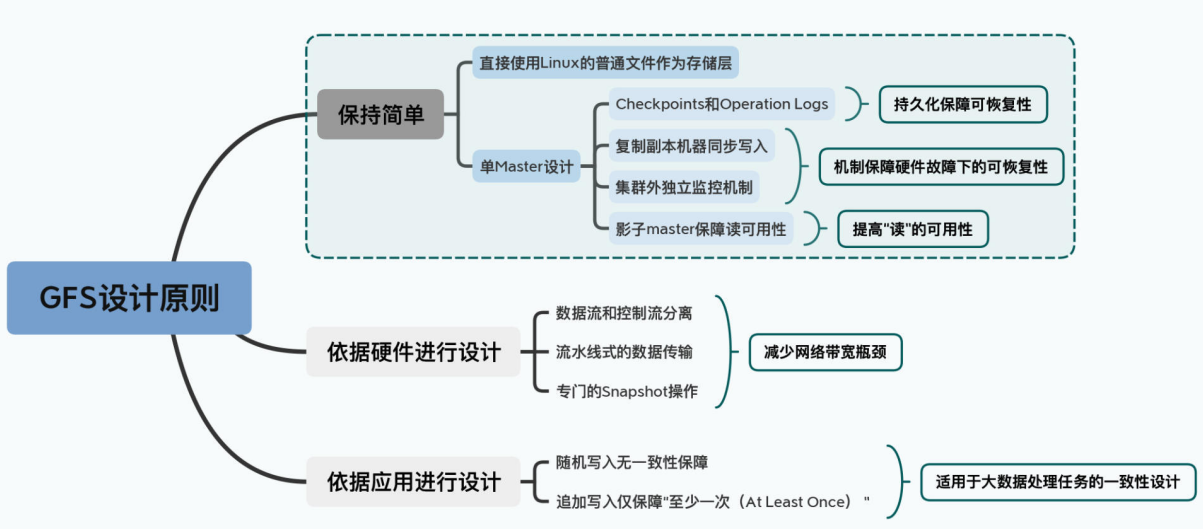
在这个设计原则下,我们会看到GFS是一个非常简单的单Master架构,但是这个Master其实有三种不同的身份,分别是:
- 相对于存储数据的Chunkserver,Master是一个目录服务;
- 相对于为了灾难恢复的Backup Master,它是一个同步复制的主从架构下的主节点;
- 相对于为了保障读数据的可用性而设立的Shadow Master,它是一个异步复制的主从架构下的主节点。
并且,这三种身份是依靠不同的独立模块完成的,互相之间并不干扰。所以,学完这一讲,你对常见的主从架构(Master-Slave)下的Master的职责,以及数据复制的模式也会有一个清晰的认识。
# 1.1 Master 的第一个身份:一个目录服务
作为一个分布式文件系统,一个有几千台服务器跑在线上的真实系统,GFS 的设计可以说是非常简单。
我们要存一个文件到 GFS 上的话,和在 Linux 系统上很像,GFS 会通过“命名空间+文件名”来定义一个文件。比如,我们可以把这一讲的录音文件存储在/data/geektime/bigdata/gfs01这样一个路径下。这样,所有GFS的客户端,都可以通过这个/data/geektime/bigdata命名空间加上gfs01这个文件名,去读或者写这个文件。
首先你要知道,在整个GFS中,有两种服务器:
- 一种是 master,也就是整个GFS中有且仅有一个的主控节点;
- 第二种是 chunkserver,也就是实际存储数据的节点。
在GFS里面,会把每一个文件按照64MB一块的大小,切分成一个个chunk。每个chunk都会有一个在GFS上的唯一的handle,这个handle其实就是一个编号,能够唯一标识出具体的chunk。然后每一个chunk,都会以一个文件的形式,放在chunkserver上。
而chunkserver,其实就是一台普通的Linux服务器,上面跑了一个用户态的GFS的chunkserver程序。这个程序,会负责和master以及GFS的客户端进行RPC通信,完成实际的数据读写操作。
当然,为了确保数据不会因为某一个chunkserver坏了就丢失了,每个chunk都会存上整整三份副本(replica)。其中一份是主数据(primary),两份是副数据(secondary),当三份数据出现不一致的时候,就以主数据为准。有了三个副本,不仅可以防止因为各种原因丢数据,还可以在有很多并发读取的时候,分摊系统读取的压力。
既然文件被拆分成一个个 chunk 存在了 chunkserver 中,那 client 是如何知道该去哪个 chunkserver 找自己要的文件呢?
答案当然是问master啦。
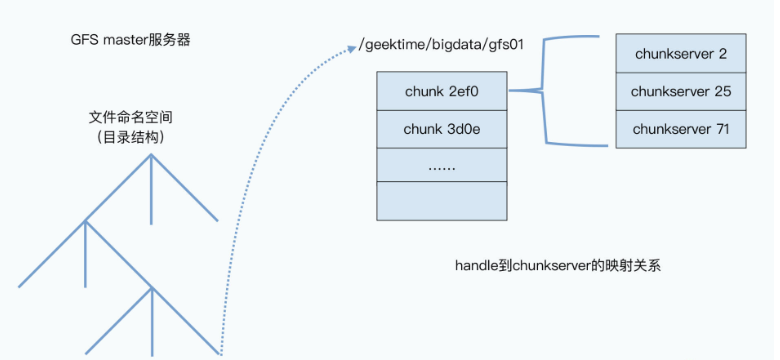
首先,master里面会存放三种主要的元数据(metadata):
- 文件和chunk的命名空间信息,也就是类似前面/data/geektime/bigdata/gfs01这样的路径和文件名;
- 这些文件被拆分成了哪几个chunk,也就是这个全路径文件名到多个chunk handle的映射关系;
- 这些chunk实际被存储在了哪些chunkserver上,也就是chunk handle到chunkserver的映射关系。
然后,当我们要通过一个客户端去读取GFS里面的数据的时候,需要怎么做呢? GFS会有以下三个步骤:
- 客户端先去问master,我们想要读取的数据在哪里。这里,客户端会发出两部分信息,一个是文件名,另一个则是要读取哪一段数据,也就是读取文件的offset及length。因为所有文件都被切成64MB大小的一个chunk了,所以根据offset和length,我们可以很容易地算出客户端要读取的数据在哪几个chunk里面。于是,客户端就会告诉master,我要哪个文件的第几个chunk。
- master拿到了这个请求之后,就会把这个chunk对应的所有副本所在的chunkserver,告诉客户端。
- 等客户端拿到chunk所在的chunkserver信息后,客户端就可以直接去找其中任意的一个chunkserver读取自己所要的数据。
这整个过程抽象一下,其实和Linux文件系统差不多。master节点和chunkserver这样两种节点的设计,其实和操作系统中的文件系统一脉相承。master就好像存储了所有inode信息的super block,而chunk就是文件系统中的一个个block。只不过chunk比block的尺寸大了一些,并且放在了很多台不同的机器上而已。我们通过master找到chunk的位置来读取数据,就好像操作系统里通过inode到block的位置,再从block里面读取数据。
所以,这个时候的master,其实就是一个“目录服务”,master本身不存储数据,而是只是存储目录这样的元数据。这个和我们的单机系统的设计思想是一样的。其实在计算机这个行业中,所有的系统都是从最简单、最底层的系统演化而来的。而这个课程中你看到的大部分的设计,其实都有这个特质。
# 1.2 Master 的快速恢复性和可用性保障
简单不是没有代价的。在这个设计下,你会发现GFS里面的master节点压力很大。在一个1000台服务器的集群里面,chunkserver有上千个,但master只有一个。几百个客户端并发读取的数据,虽然可以分摊到那1000个chunkserver的节点上,但是找到要读的文件的数据存放在哪里,都要去master节点里面去找。
所以,master节点的所有数据,都是保存在内存里的。这样,master的性能才能跟得上几百个客户端的并发访问。
但是数据放在内存里带来的问题,就是一旦master挂掉,数据就会都丢了。所以,master会通过记录操作日志和定期生成对应的Checkpoints进行持久化,也就是写到硬盘上。
这是为了确保在master里的这些数据,不会因为一次机器故障就丢失掉。当master节点重启的时候,就会先读取最新的Checkpoints,然后重放(replay)Checkpoints之后的操作日志,把master节点的状态恢复到之前最新的状态。这是最常见的存储系统会用到的可恢复机制。
当然,光有这些还不够,如果只是master节点重新启动一下,从Checkpoints和日志中恢复到最新状态自然是很快的。可要是master节点的硬件彻底故障了呢?
你要知道,去数据中心重新更换硬件可不是几分钟的事情,所以GFS还为master准备好了几个“备胎”,也就是另外几台Backup Master。所有针对master的数据操作,都需要同样写到另外准备的这几台服务器上。只有当数据在master上操作成功,对应的操作记录刷新到硬盘上,并且这几个Backup Master的数据也写入成功,并把操作记录刷新到硬盘上,整个操作才会被视为操作成功。这种方式,叫做数据的同步复制,是分布式数据系统里的一种典型模式。假如你需要一个高可用的MySQL集群,一样也可以采用同步复制的方式,在主从服务器之间同步数据。
而在同步复制这个机制之外,在集群外部还有监控master的服务在运行。如果只是master的进程挂掉了,那么这个监控程序会立刻重启master进程。而如果master所在的硬件或者硬盘出现损坏,那么这个监控程序就会在前面说的Backup Master里面找一个出来,启动对应的master进程,让它“备胎转正”,变成新的master。而这个里面的数据,和原来的master其实一模一样。不过,为了让集群中的其他chunkserver以及客户端不用感知这个变化,GFS通过一个规范名称(Canonical Name)来指定master,而不是通过IP地址或者Mac地址。这样,一旦要切换master,这个监控程序只需要修改DNS的别名,就能达到目的。有了这个机制,GFS的master就从之前的可恢复(Recoverable),进化成了能够快速恢复(Fast Recovery)。
不过,就算做到了快速恢复,我们还是不满足。毕竟,从监控程序发现master节点故障、启动备份节点上的master进程、读取Checkpoints和操作日志,仍然是一个几秒级别乃至分钟级别的过程。在这个时间段里,我们可能仍然有几百个客户端程序“嗷嗷待哺”,希望能够在GFS上读写数据。虽然作为单个master的设计,这个时候的确是没有办法去写入数据的。但是Google的工程师还是想了一个办法,让我们这个时候还能够从GFS上读取数据。这个办法就是加入一系列只读的“影子Master”,这些影子Master和前面的备胎不同,master写入数据并不需要等到影子Master也写入完成才返回成功。而是影子Master不断同步master输入的写入,尽可能保持追上master的最新状态。这种方式,叫做数据的异步复制,是分布式系统里另一种典型模式。异步复制下,影子Master并不是和master的数据完全同步的,而是可能会有一些小小的延时。
影子Master会不断同步master里的数据,不过当master出现问题的时候,客户端们就可以从这些影子Master里找到自己想要的信息。当然,因为小小的延时,客户端有很小的概率,会读到一些过时的master里面的信息,比如命名空间、文件名等这些元数据。但你也要知道,这种情况其实只会发生在以下三个条件都满足的情况下:
- 第一个,是master挂掉了;
- 第二个,是挂掉的master或者Backup Master上的Checkpoints和操作日志,还没有被影子Master同步完;
- 第三个,则是我们要读取的内容,恰恰是在没有同步完的那部分操作上;
相比于这个小小的可能性,影子Master让整个GFS在master快速恢复的过程中,虽然不能写数据,但仍然是完全可读的。至少在集群的读取操作上,GFS可以算得上是“高可用(High Availability)”的了。
# 2. 如何应对网络瓶颈?
这一节将学习 GFS 论文中的第二个重要的决策设计:根据实际的硬件情况来进行系统设计。
大数据系统本就是为“性能”而生的,因为单台服务器已经满足不了我们的性能需要。所以我们需要通过搭建成百上千台服务器,组成一个大数据集群。然而,上千台服务器的集群一样有来自各种硬件性能的限制。
在单台服务器下,我们的硬件瓶颈常常是硬盘。而到了一个分布式集群里,我们又有了一个新的瓶颈,那就是网络。
那么在这一讲里,我们就来看看网络层面的硬件瓶颈,是如何影响了GFS的设计的。在学完这一讲之后,希望你能够理解, 任何一个系统设计,都需要考虑硬件性能。并且学会在对自己的设计进行评估的时候,能够寻找到系统的硬件瓶颈在哪里。
# 2.1 GFS 的硬件配置
不知道你有没有想过,2003年的GFS是跑在什么样的硬件服务器上的呢?论文的第6部分还真的透露了一些信息给我们。Google拿来做微基准测试(Micro-Benchmark)的服务器集群的配置是这样的:
- 19台服务器、1台master、2台master的只读副本、16台chunkserver,以及另外16台GFS的客户端;
- 所有服务器的硬件配置完全相同,都是双核1.45 GHz的奔腾3处理器 + 2GB内存 + 两块80GB的5400rpm的机械硬盘 + 100 Mbps的全双工网卡。
- 然后把所有的19台GFS集群的机器放在一台交换机上,所有的16台GFS的客户端放在另外一台交换机上,两台交换机之间通过带宽是1Gbps的网线连接起来。
而Google跑在内部实际使用的真实集群,虽然论文里没有给出具体的硬件配置,但我们也可以反向推算一下。论文第6部分有一个Table 2,里面有A和B两个集群。根据表格里面的数据可以计算得出,里面的A集群平均每台chunkserver大约有200GB的硬盘,每台chunkserver需要的Metadata(元数据)大约是38MB。而里面的B集群则是800GB的硬盘,以及93MB的Metadata。这样看起来,除了可以多插几块硬盘增加一些存储空间之外,前面测试集群的硬件配置完全够用了。
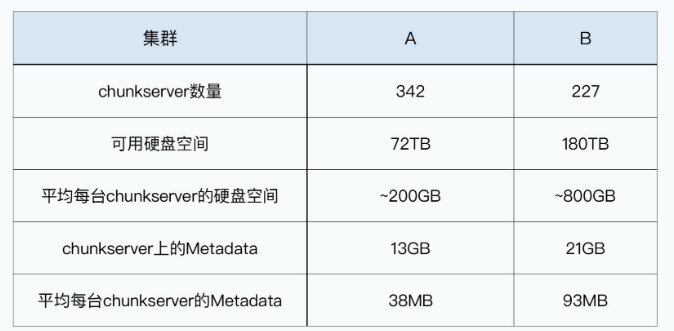
在这个硬件配置中,5400转(rpm)的硬盘,读写数据的吞吐量通常是在60MB/s~90MB/s左右。而且我们通常会插入多块硬盘,比如集群B,就需要10块80GB的硬盘,这样就意味着整体硬盘的吞吐量可以达到500MB/s以上。但是,100Mbps的网卡的极限吞吐率只有12.5MB/s,这个也就意味着,当我们从GFS读写数据的时候,瓶颈就在网络上。
那么下面,我们就来看一看针对这样的硬件瓶颈,GFS都做了哪些针对性的设计。
# 2.2 GFS 的数据写入
我们先来看看一个客户端是怎么向GFS集群里面写数据的。在上一讲里,我带你了解了一个GFS客户端怎么从集群里读取数据。相信你学完之后会觉得特别简单,感觉也就是个几千行代码的事儿。不过,写文件可就没有那么简单了。
实际上,读数据简单,是因为不管我们有多少个客户端并发去读一个文件,读到的内容都不会有区别,即使它们读同一个chunk是分布在不同chunkserver。我们不是靠在读取中做什么特殊的动作,来保障客户端读到的数据都一样。“保障读到的数据一样”这件事情,其实是在数据写入的过程中来保障的。
写入和读取不同的是,读取只需要读一个chunkserver,最坏的情况无非是读不到重试。而写入,则是同时要写三份副本,如果一个写失败,两个写成功了,数据就已经不一致了。
那么,GFS是怎么解决这样的问题的呢?下面我就带你来看一下,GFS写入数据的具体步骤:
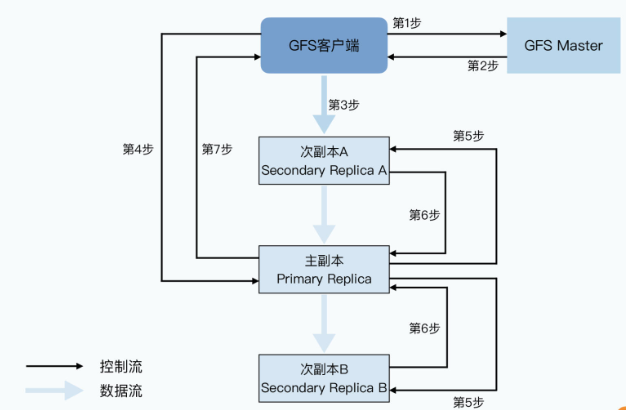
- 第一步,客户端会去问master要写入的数据,应该在哪些chunkserver上。
- 第二步,和读数据一样,master会告诉客户端所有的次副本(secondary replica)所在的chunkserver。这还不够,master还会告诉客户端哪个replica是“老大”,也就是主副本(primary replica),数据此时以它为准。
- 第三步,拿到数据应该写到哪些chunkserver里之后,客户端会把要写的数据发给所有的replica。不过此时,chunkserver拿到发过来的数据后还不会真的写下来,只会把数据 放在一个LRU的缓冲区里。
- 第四步,等到所有次副本都接收完数据后,客户端就会发送一个写请求给到主副本。我在上节课一开始就说过,GFS面对的是几百个并发的客户端,所以主副本可能会收到很多个客户端的写入请求。主副本自己会给这些请求排一个顺序,确保所有的数据写入是有一个固定顺序的。接下来,主副本就开始按照这个顺序,把刚才LRU的缓冲区里的数据写到实际的chunk里去。
- 第五步,主副本会把对应的写请求转发给所有的次副本,所有次副本会和主副本以同样的数据写入顺序,把数据写入到硬盘上。
- 第六步,次副本的数据写入完成之后,会回复主副本,我也把数据和你一样写完了。
- 第七步,主副本再去告诉客户端,这个数据写入成功了。而如果在任何一个副本写入数据的过程中出错了,这个出错都会告诉客户端,也就意味着这次写入其实失败了。
所以在GFS的数据写入过程中,可能会出现主副本写入成功,但是次副本写入出错的情况。在这种情况下,客户端会认为写入失败了。但是这个时候,同一个chunk在不同chunkserver上的数据可能会出现不一致的情况,这个问题我们会放到下一讲来深入讨论。
下图展示了这个数据写入的过程:
从这张图上你会发现,GFS的数据写入使用了两个很有意思的模式,来解决这节课一开始我提到的网络带宽的瓶颈问题。
# 2.2.1 分离控制流和数据流
第一个模式是控制流和数据流的分离。
和之前从GFS上读数据一样,GFS客户端只从master拿到了chunk data在哪个chunkserver的元数据,实际的数据读写都不再需要通过master。另外,不仅具体的数据传输不经过master,后续的数据在多个chunkserver上同时写入的协调工作,也不需要经过master。
这也就是说,控制流和数据流的分离,不仅仅是数据写入不需要通过master,更重要的是实际的数据传输过程,和提供写入指令的动作是完全分离的。
# 2.2.2 流水线式的网络数据传输
其次,是采用了流水线(pipeline) 式的网络传输。数据不一定是先给到主副本,而是看网络上离哪个chunkserver近,就给哪个chunkserver,数据会先在chunkserver的缓冲区里存起来,就是前面提到的第3步。但是写入操作的指令,也就是上面的第4~7步,则都是由客户端发送给主副本,再由主副本统一协调写入顺序、拿到操作结果,再给到客户端的。
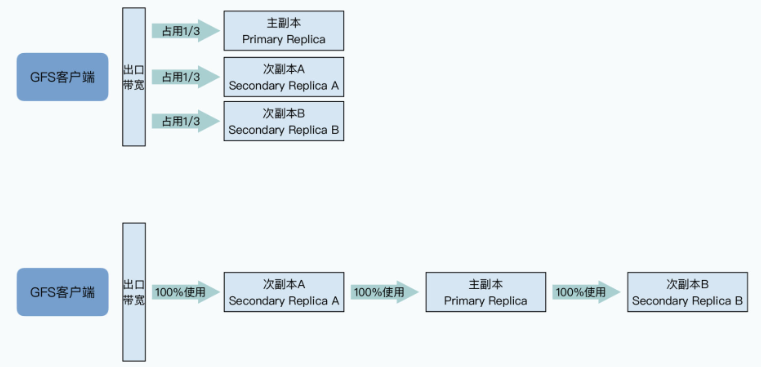
之所以要这么做,还是因为GFS最大的瓶颈就在网络。如果用一个最直观的想法来进行数据传输,我们可以把所有数据直接都从客户端发给三个chunkserver。
但是这种方法的问题在于,客户端的出口网络会立刻成为瓶颈。
比如,我们要发送1GB的数据给GFS,客户端的出口网络带宽有100MB/秒,那么我们只需要10秒就能把数据发送完。但是因为三个chunkserver的数据都要从客户端发出,所以要30s才能把所有的数据都发送完,而且这个时候,三个chunkserver的网络带宽都没有用满,各自只用了1/3,网络并没有被有效地利用起来。
而在流水线式的传输方式下,客户端可以先把所有数据,传输给到网络里离自己最近的次副本A,然后次副本A一边接收数据,一边把对应的数据传输给到离自己最近的另一个副本,也就是主副本。
同样的,主副本可以如法炮制,把数据也同时传输给次副本B。在这样的流水线式的数据传输方式下,只要网络上没有拥堵的情况,只需要10秒多一点点,就可以把所有的数据从客户端,传输到三个副本所在的chunkserver上。
两种传输方法对比如下图:
不过到这里你可能要问了:为什么客户端传输数据,是先给离自己最近的次副本A,而不是先给主副本呢?
这个问题,也和数据中心的实际网络结构有关,你可以先看看下面这张数据中心的网络拓扑图:
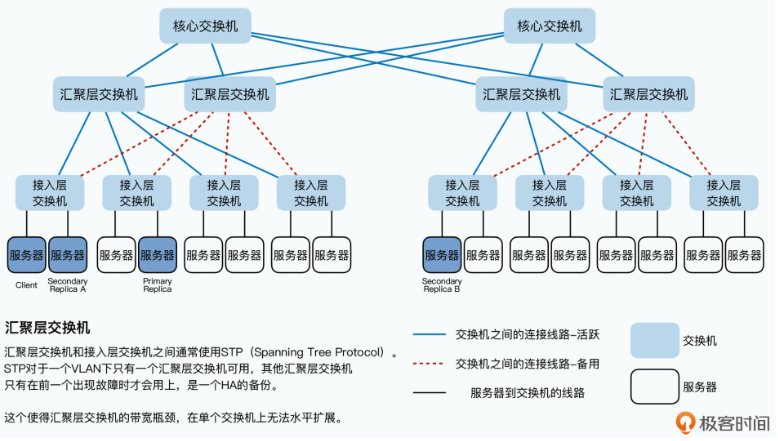
要知道,我们几百台服务器所在的数据中心,一般都是通过三层交换机连通起来的:
- 同一个机架(Rack)上的服务器,都会接入到一台接入层交换机(Access Switch)上;
- 各个机架上的接入层交换机,都会连接到某一台汇聚层交换机(Aggregation Switch)上;
- 而汇聚层交换机,再会连接到多台核心交换机(Core Switch)上。
那么根据这个网络拓扑图,你会发现,两台服务器如果在同一个机架上,它们之间的网络传输只需要通过接入层的交换机即可。在这种情况下,除了两台服务器本身的网络带宽之外,它们只会占用所在的接入层交换机的带宽。
但是,如果两台服务器不在一个机架,乃至不在一个VLAN的情况下,数据传输就要通过汇聚层交换机,甚至是核心交换机了。而如果大量的数据传输,都是在多个不同的VLAN之间进行的,那么汇聚层交换机乃至核心交换机的带宽,就会成为瓶颈。
所以我们再回到之前的链式传输的场景,GFS最大利用网络带宽,同时又减少网络瓶颈的选择就是这样的:
- 首先,客户端把数据传输给离自己“最近”的,也就是在同一个机架上的次副本A服务器;
- 然后,次副本A服务器再把数据传输给离自己“最近”的,在不同机架,但是处于同一个汇聚层交换机下的主副本服务器上;
- 最后,主副本服务器,再把数据传输给在另一个汇聚层交换机下的次副本B服务器。
这样的传输顺序,就最大化地利用了每台服务器的带宽,并且减少了交换机的带宽瓶颈。而如果我们非要先把数据从客户端传输给主副本,再从主副本传输到次副本A,那么同样的数据就需要多通过汇聚层交换机一次,从而就占用了更多的汇聚层交换机的资源。
# 2.3 独特的 Snapshot 操作
那么,在做了分离控制流和数据流,以及使用流水线式的数据传输方式之后,对于GFS的网络传输上,还有什么其他的优化空间吗?
你别说还真的有,那就是为常见的文件复制操作单独设计一个指令。
复制文件,相信这个是你用自己的电脑的时候,会常常做的事儿。在GFS上,如果我们用笨一点的办法,自然是通过客户端把文件从chunkserver读回来,再通过客户端把数据写回去。这样的话,读数据也经过一次网络传输,写回三个副本服务器,即使是流水线式的传输,也要三次传输,一共需要把数据在网络上搬运四次。
所以,GFS就专门为文件复制设计了一个 Snapshot 指令,当客户端通过这个指令进行文件复制的时候,这个指令会通过控制流,下达到主副本服务器,主副本服务器再把这个指令下达到次副本服务器。不过接下来,客户端并不需要去读取或者写入数据,而是各个chunkserver会直接在本地把对应的chunk复制一份。
这样,数据流就完全不需要通过网络传输了。
# 3. GFS 的一致性模型
这一节讨论的是 GFS 的最后一个设计特点:放宽数据一致性的要求。
分布式系统的一致性要求是一个很有挑战的话题。如果说分布式系统天生通过更多的服务器提升了性能,是一个天然的优点,那么在这些通过网络连起来的服务器之间保持数据一致,就是一个巨大的挑战。毕竟网络传输总有延时,硬件总会有故障,你的程序稍有不慎,就会遇到甲服务器觉得你的钱转账失败,而乙服务器却觉得钱已经转走了的情况。可以说,一致性是分布式系统里的一个永恒的话题。
不过2003年的GFS,对于一致性的要求,是非常宽松的。一方面,这是为了遵循第一个设计原则,就是“保持简单”,简单的设计使得做到很强的一致性变得困难。另一方面,则是要考虑“硬件特性”,GFS希望在机械硬盘上尽量有比较高的写入性能,所以它只对顺序写入考虑了一致性,这就自然带来了宽松的一致性。
# 3.1 随机写入只是“确定”的
通过上一讲的学习,我们知道了在GFS中,客户端是怎么把数据写入到文件系统里的。不过,我们并没有探讨一个非常重要的问题,就是数据写入的一致性(Consistency)问题。
我们先来看看,一致性到底指的是什么东西。在GFS里面,主要定义了对一致性的两个层级的概念:
- 第一个,就叫做“一致的(Consistent)”。这个就是指,多个客户端无论是从主副本读取数据,还是从次副本读取数据,读到的数据都是一样的。
- 第二个,叫做“确定的(Defined)”。这个要求会高一些,指的是对于客户端写入到GFS的数据,能够完整地被读到。可能看到这个定义,你还是不清楚,没关系,我下面会给你详细讲解“确定的”到底是个什么问题。
GFS 论文中给了一个表格,其中告诉了我们 GFS 对于数据写入的一致性问题:
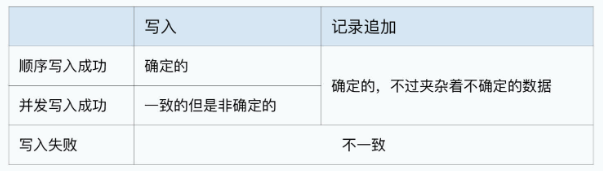
- 首先,如果数据写入失败,GFS里的数据就是不一致的。
这个很容易理解,GFS里面的数据写入,并不是一个事务。上一讲里说过,主副本会把写入指令下发到两个次副本,如果次副本写入失败了,它会告诉主副本。但是,此时主副本和另一个次副本都已经写入成功了。那么这个时候,GFS里的三个副本的数据,就是不一致的了。不同的客户端,就可能读到不同的数据。
- 其次,如果客户端的数据写入时顺序的,并且写入成功了,那么文件里面的内容就是确定的。
比如,你先往一个文件里,写入一部电影《星球大战》,这个时候,客户端无论从哪个副本读数据,读到的都是星球大战。然后再写入《星际迷航》,那么客户端再读数据,读到的也一定是《星际迷航》。
- 但是,如果由多个客户端并发写入数据,即使写入成功了,GFS里的数据也可能会进入一个一致但是非确定的状态。
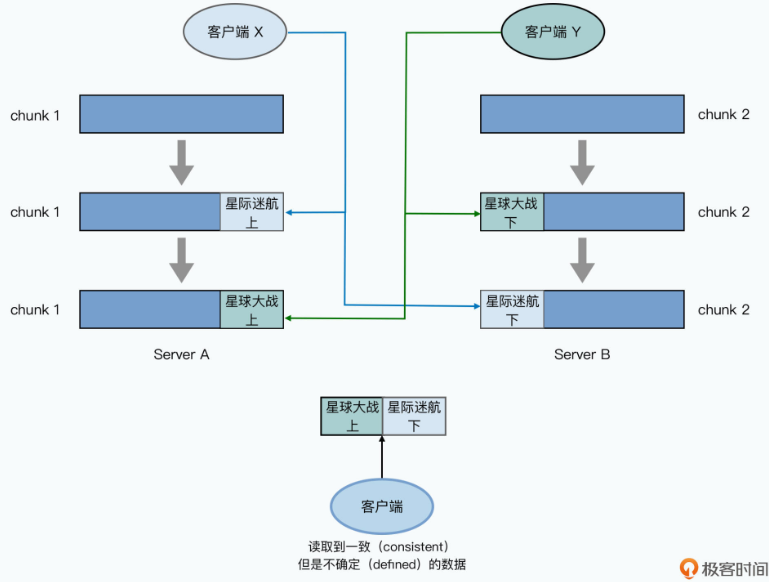
也就是说,两个客户端并发往一个文件里面写数据,一个想要写入《星球大战》,一个想要写入《星际迷航》,两个写入都成功了。这个时候,GFS里面三份副本的数据是一样的,客户端读到的数据无论是从哪个副本里读,都是一样的。但是呢,客户端可能读出来的数据里,前一小时是《星球大战》,后一小时是《星际迷航》。无论哪个时间节点去读数据,客户端都不能读到一部完整的《星球大战》,或者是《星际迷航》。
那么为什么GFS的数据写入会出现一致但是非确定的状态呢?这个来自于两个因素:
- 第一种因素是在GFS的数据读写中,为了减轻Master的负载,数据的写入顺序并不需要通过Master来进行协调,而是直接由存储了主副本的chunkserver,来管理同一个chunk下数据写入的操作顺序。
- 第二种因素是随机的数据写入极有可能要跨越多个chunk。
我们在写入《星球大战》和《星际迷航》的时候,前一个小时的电影是在chunk 1,对应的主副本在server A,后一个小时的电影是在chunk 2,对应的主副本在server B。然后写入请求到server A的时候,《星际迷航》在前,《星球大战》在后,那么《星球大战》的数据就覆盖了《星际迷航》。
而到server B的时候则是反过来,《星际迷航》又覆盖了《星球大战》。于是,就会出现客户端读数据,前半段是《星球大战》,后半段是《星际迷航》的奇怪现象了。
其实,这个一致但是非确定的状态,是因为随机的数据写入,没有原子性(Atomic)或者事务性( Transactional)。如果想要随机修改GFS上的数据,一般会建议使用方在客户端的应用层面,保障数据写入是顺序的,从而可以避免并发写入的出现。
# 3.2 追加写入的“至少一次”的保障
看到这里,你可能要纳闷了。不是说GFS支持几百个客户端并发读写吗?现在怎么又说,写入要客户端自己保障是“顺序”的呢?
实际上,这是因为随机写入并不是GFS设计的主要的数据写入模式,GFS设计了一个专门的操作,叫做记录追加(Record Appends)。这是GFS希望我们主要使用的数据写入的方式,而且它是原子性(Atomic)的,能够做到在并发写入时候是基本确定的。
不过,作为一个严谨的工程师,听到“基本”这两个字你可能心里一颤。别慌,接下来我就带你一起看一下,这个基本到底是怎么回事儿。
GFS的记录追加的写入过程,和上一讲的数据写入几乎一样。它们之间的差别主要在于,GFS并不会指定在chunk的哪个位置上写入数据,而是告诉最后一个chunk所在的主副本服务器,“我”要进行记录追加。
这个时候,主副本所在的chunkserver会做这样几件事情:
- 检查当前的chunk是不是可以写得下现在要追加的记录。如果写得下,那么就把当前的追加记录写进去,同时,这个数据写入也会发送给其他次副本,在次副本上也写一遍。
- 如果当前chunk已经放不下了,那么它先会把当前chunk填满空数据,并且让次副本也一样填满空数据。然后,主副本会告诉客户端,让它在下一个chunk上重新试验。这时候,客户端就会去一个新的chunk所在的chunkserver进行记录追加。
- 因为主副本所在的chunkserver控制了数据写入的操作顺序,并且数据只会往后追加,所以即使在有并发写入的情况下,请求也都会到主副本所在的同一个chunkserver上排队,也就不会有数据写入到同一块区域,覆盖掉已经被追加写入的数据的情况了。
- 而为了保障chunk里能存的下需要追加的数据,GFS限制了一次记录追加的数据量是16MB,而chunkserver里的一个chunk的大小是64MB。所以,在记录追加需要在chunk里填空数据的时候,最多也就是填入16MB,也就是chunkserver的存储空间最多会浪费1/4。
那么到了这里,你可能要问了:如果在主副本上写入成功了,但是在次副本上写入失败了怎么办呢?这样不是还会出现数据不一致的情况吗?
其实在这个时候,主副本会告诉客户端数据写入失败,然后让客户端重试。不过客户端发起的重试,并不是在原来的位置去写入数据,而是发起一个新的记录追加操作。这个时候,可能已经有其他的并发追加写入请求成功了,那么这次重试会写入到更后面。
我们可以一起来看这样一个例子:有三个客户端X、Y、Z并发向同一个文件进行记录追加,写入数据A、B、C,对应的三个副本的chunkserver分别是Q、P、R。主副本先收到数据A的记录追加,在主副本和次副本上进行数据写入。在A写入的同时,B,C的记录追加请求也来了,这个时候写入会并行进行,追加在A的后面。这个时候,A的写入在某个次副本R上失败了,于是主副本告诉客户端去重试;同时,客户端再次发起记录追加的重试,这次的数据写入,不在A原来的位置,而会是在C后面。
重试是对所有副本都再来一次追加。
如此一来,在B和C的写入,以及A的重试完成之后,我们可以看到:
- 在Q和P上,chunkserver里面的数据顺序是 A-B-C-A;
- 但是在R上,chunkserver里面的数据顺序是 N/A-B-C-A;
也就是Q和P上,A的数据被写入了两次,而在R上,数据里面有一段是有不可用的脏数据。如下图所示:
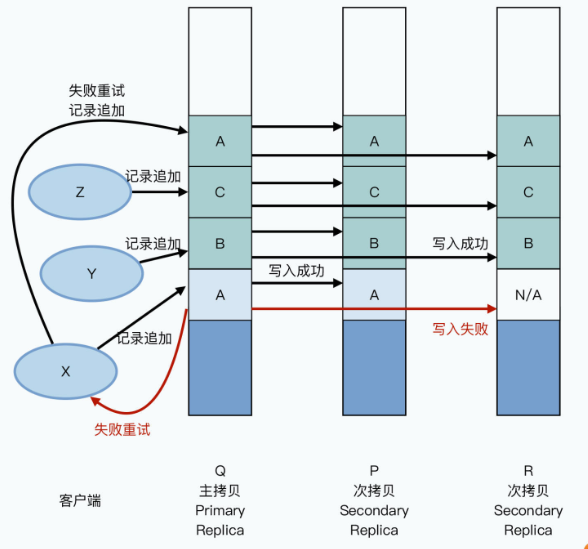
所以在这个记录追加的场景下,GFS承诺的一致性,叫做“至少一次(At Least Once)”。也就是写入一份数据A,在重试的情况下,至少会完整地在三个副本的同一个位置写入一次。但是也可能会因为失败,在某些副本里面写入多次。那么,在不断追加数据的情况下,你会看到大部分数据都是一致的,并且是确定的,但是整个文件中,会夹杂着少数不一致也不确定的数据。
# 3.3 解决一致性的机制
看到这里可以发现,GFS的写入数据的一致性保障是相当低的。它只是保障了所有数据追加至少被写入一次,并且还保障不了数据追加的顺序。这使得客户端读取到的副本中,可能也会存在重复的数据或者空的填充数据,这样的文件系统实在不咋样。
不过,这个“至少一次”的机制,其实很适合Google的应用场景。你想像一下,如果你是一个搜索引擎,不断抓取网页然后存到GFS上。其实你并不会太在意这个网页信息是不是被重复存了两次,你也不太会在意不同的两个网页存储的顺序。而且即使你在意这两点,比如你存的不是网页,而是用户的搜索日志或广告展示和点击的日志数据。或者你担心数据写入失败,带来的是部分不完整的数据,也有很多简单的解决办法。
事实上,GFS的客户端里面自带了对写入的数据去添加校验和(checksum),并在读取的时候计算来验证数据完整性的功能。而对于数据可能重复写入多次的问题,你也可以对每一条要写入的数据生成一个唯一的ID,并且在里面带上当时的时间戳。这样,即使这些日志顺序不对、有重复,你也可以很容易地在你后续的数据处理程序中,通过这个ID进行排序和去重。
而这个“至少一次”的写入模型也带来了两个巨大的好处:
- 高并发和高性能。这个设计使得我们可以有很多个客户端并发向同一个 GFS 上的文件进行追加写入,而高性能本身也是我们需要分布式系统的起点。
- 简单。GFS采用了一个非常简单的单 master server,多个 chunkserver 架构,所有的协调动作都由 master 来做,而不需要复杂的一致性模型。毕竟,2003 年我们只有极其难以读懂的 Paxos 论文,Raft 这样的分布式共识算法要在10年之后的2013年才会诞生。而简单的架构设计,使得系统不容易出 Bug,出了各种 Bug 也更容易维护。
而即使GFS里的数据随机写入能够保障确定性,在那个年代的实用价值也不高。因为那个时候,大家用的还都是5400转,或者7200转的机械硬盘,这样几百个客户端要是并发写入一个位置,硬盘是根本扛不住的。
对于随机数据写入的一致性,我会在后面 Bigtable 的论文里,再带你看看 Google 是如何在这个不可靠的 GFS 上,架起一个高可用性、可以随机读写的 KV 数据库。
# 4. 小结
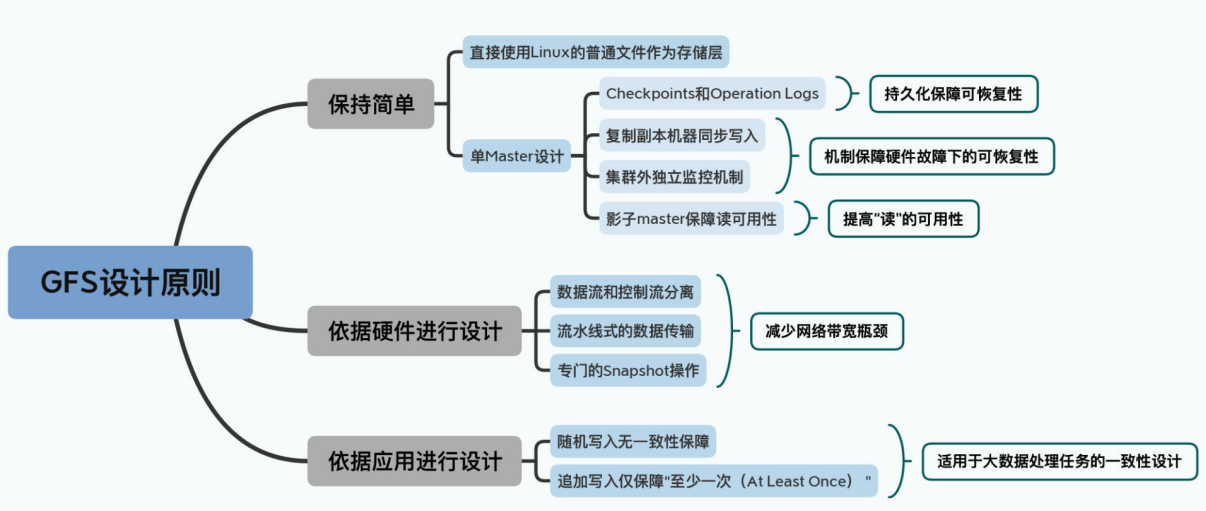
回顾过去三讲,我们可以看到GFS的设计原则,就是简单、围绕硬件性能设计,以及在这两个前提下对于一致性的宽松要求。可以说,GFS不是一个“黑科技”系统,而是一个非常优秀的工程化系统。在后面的MapReduce以及Bigtable的论文中,我们还会反复看到类似的设计选择。
今天我们所讲的,其实是在大数据及分布式领域中一个非常重要的主题,那就是CAP问题。在之后的很多论文里,你也可以看到不同系统是如何处理CAP问题带来的挑战的。在学完今天这节课之后,我比较推荐你去读一读2012年,在CAP理论发表12年后,作者埃里克·布鲁尔(Eric Brewer)对CAP问题的回顾文章 《CAP理论十二年回顾:“规则”变了》 (opens new window)。