 Megastore
Megastore
随着时间推移,工程师们越来越多地让大数据库系统支持上了 SQL 的特性,对于 OLAP 系统来说,支持 Schema 定义、支持字段类型、支持直接用类 SQL 的语言进行数据分析,很快就成为了新一代大数据分析系统的标准。
所以,Google 也想在 Bigtable 这样的 OLTP 数据库上支持 SQL,让我们看看《Megastore: Providing scalable, highly available storage for interactive services》这篇论文为我们带来了什么。
Megastore 是一个雄心勃勃的系统,支持SQL这样的接口只是它想要做到的所有事情中的一小项。如果列出 Megastore 支持的所有特性,相信也是一个让人两眼放光的系统,好像是分布式数据库的终极答案:
- 跨数据中心的多副本同步数据复制;
- 支持为数据表的字段建立 Schema,并且可以通过 SQL 接口来访问;
- 支持数据库的二级索引;
- 支持数据库的事务。
不过,Megastore 最终只是 Google 迈向 Spanner 中的一个里程碑。Megastore 的大部分高级特性,都基于实际的应用场景做了取舍和妥协。相比于略显高深的 Spanner,Megastore 的设计对大部分工程师和架构师来说更有实践意义。我会通过接下来的三讲,带你解读 Megastore 的论文:
- 第一讲,主要讲解论文中的第二部分,也就是Megastore的整体系统架构,以及这个架构是怎么从我们的应用场景需求妥协而来的。
- 第二讲,我们会来看一看Megastore的API设计、数据模型以及事务和并发控制是怎么做的,看看Megastore是怎么利用好Bigtable的特性来实现一个更高级的数据库。这个也是论文中的第三部分。
- 第三讲,我们会深入论文的第四部分,研究Megastore的数据复制机制,一起来看看,一个为跨数据中心复制而优化的Paxos算法实现,是怎么样的。
# 1. Megastore:全国各地都能写入的数据库
通过第一讲的学习,相信对你根据业务实践来设计系统,以及如何在各种工程实践上进行取舍的能力有所裨益。
# 1.1 互联网时代的数据库
在我们前面介绍过的那些论文里,会发现工程师们对于可用性问题的考虑,往往是局限在一个数据中心里。GFS里我们会对数据做三份备份,但是这三份数据还是在同一个数据中心的三台服务器里;针对 Chubby 这样的服务,我们用了五个节点,放到不同的交换机下,但这仍然是在一个数据中心里。
可是,如果我们的分布式数据库只能在一个数据中心里,那无论是在“可用性”上,还是在“性能”上,在互联网时代都有点不够看。
- 在可用性这个角度,尽管我们在数据中心内部可以有非常完善的分布式、多路供电以及柴油发电机等方案,但是一旦遇上像水灾、地震这样的自然灾害,这些手段都无济于事。而往往在这个时候,让每个人能够访问到网络、发送消息又是特别重要的。前一阵我们遇到的郑州水灾就是一个很典型的例子。
- 在性能这个角度,如果我们的数据中心设在旧金山,那么一个上海用户的一个请求,在最理想的情况下,也至少需要100毫秒以上才能够完成一个网络请求的往返。在真实的网络环境里,其实100毫秒是远不够的,往往要到150乃至200毫秒。而这个访问速度,显然会让很多用户觉得网络慢,体验不好,容易流失用户。
那么,解决这两个问题最好的办法,就是我们有多个数据中心。每个用户的请求都可以访问到就近的本地数据中心,对应的数据也直接就近写入本地数据中心里的数据库,也都从本地数据中心的数据库里读。而各个数据中心的数据库之间,会进行数据复制,确保你在旧金山写入的数据,我在上海一样可以读到。如下图所示:

而且既然是一个互联网层面的数据库,也就是用户量可能像 Facebook 或 Google 这样,达到几十亿,那这个数据库也需要有非常强的水平扩展能力,通过简单地增加服务器就能够服务更多的用户。
这些需求点,也就是 Google 需要 Megastore 这样一个系统的起因。而论文在第二部分的一开始,就写明了 Megastore 的解决方案:
- 对于可用性问题,通过实现一个为远距离链接优化过的同步的、容错的日志复制器
- 对于伸缩性问题,通过把数据分区成大量的“小数据库”,每一个都有独立进行同步复制的数据库日志,存放在每个副本的 NoSQL 的数据存储里
那么接下来,我们就一起看看这个方案具体是怎么样的。
# 1.2 复制、分区和数据本地化
和 Hive 没有重写计算引擎而是直接用了 MapReduce 一样,Megastore 也没有重写数据存储层,而是直接使用了 Bigtable。那么,Megastore 想要解决的第一个问题,就是如何在多个数据中心的 Bigtable 之间复制数据。
我们常见的数据复制的方案,其实无非就是三种:
- 异步主从复制,这个我们之前在讲解 Chubby 的时候就讨论过。异步主从复制有两个核心问题,第一个是如果 Master 节点挂了,Slave 如果还没有及时同步数据的话,我们可能会丢数据。第二个是如果写数据在数据中心 A,读数据在数据中心 B,那么刚写入的数据我们会读不到,也就是无法满足整个系统是“可线性化”的。
- 同步主从复制,这也是大部分系统的解决方案。
- 乐观复制,这种方案是 AP(Availability + Partition Tolerance)系统中常常用到的方案。也就是数据可以在任何一个副本中写入,然后这个改动会异步地同步到其他副本中。因为可以在任何一个副本就近写入,所以系统的可用性很好,延时也很低。但是,什么时候会同步完成我们并不知道,所以系统只能是最终一致的。而且,这个系统基本无法实现事务,因为两个并发写入究竟谁先谁后很难判定,所以隔离性就无从谈起了,而“可线性化”自然也就没法做到了。
Megastore 在这件事情上的选择非常简单明确,那就是直接使用 Paxos 算法来进行多个数据中心内的数据库的同步。要注意,Megastore 并不是像我们之前讲解 Bigtable+Chubby 那样,只是采用 Paxos 来确保只有一个 Master。Megastore 是直接在多个数据中心里,采用 Paxos 同步写入数据,是一个同步复制所有的数据库日志,但是没有主从区分的系统。
不过,Megastore 选择直接使用 Paxos,最大的一个问题就是性能。
- 一方面,我们的数据传输无法突破物理学的限制,跨数据中心的延时是省不掉的。所以Megastore对于Paxos算法的实现,专门做了优化。这个优化,我们会在下一讲里专门讲解。
- 另一方面,即使把Paxos算法优化到极限,我们也避免不了,Paxos算法的每一次“共识”都需要超过半数节点的确认。如果是通过Paxos来保障一个数据库日志的同步复制,那么写入数据的性能就受限于单台服务器了,这也是为什么在Bigtable里,我们只是使用Chubby来管理粗粒度的锁,而不是直接用Paxos来进行同步复制。
那么在 Megastore 里,我们该怎么解决这个 Paxos 的性能瓶颈呢?
# 1.3 从业务需求到架构设计
我们先来回想一下分布式系统,需要做到“可线性化”的原因是什么。
以最常见的电商为例子,我下订单的数据库操作完成了之后,我再去查询这张订单是否完成,应该要能看到刚刚下的这一张订单。要不然的话,我一定会觉得很奇怪也非常担心,觉得钱付出去了,但是东西可能拿不到。但是,几乎在我下单之前,另一位在海南的朋友也下单了。那么,他下的这张订单是否在我下单之前可以读取到,我却并不在意。一方面,自然我也没有权限看到他的订单,另一方面,在业务上我们也并不需要分辨,几乎在同一时间下单的人谁先谁后。
根据这个例子我们可以看到,从业务上来说,我们不一定需要全局的可线性化,而只要一些业务上有关联的数据之间,能够保障可线性化就好了。不仅从“可线性化”的角度是这样的,其实数据库事务隔离性的“可串行化”也是这样的。
我的订单,如果从业务上就不会和我在海南的朋友之间有冲突,不会去读写相同的数据。那么我们在下单过程中,互相之间的“可串行化”的隔离性,“有”和“没有”是没有区别的。也就是我们的“可串行化”的要求,也不是全局的。
而这个现实业务中,对于数据库事务的“可串行化”,以及分布式系统的“可线性化”不需要是全局的,就给 Megastore 带来了解决问题的思路。
Megastore 是这么做的。
首先,它引入了一个叫做实体组(Entity Group)的概念。Megastore 里的数据分区,也是按照实体组进行数据分区的。
然后,一个分区的实体组,会在多个数据中心之间通过 Paxos 进行数据同步读写。本质上,Megastore 其实是把一个大数据表,拆分成了很多个独立的小数据表。每一个小数据表,在多个数据中心之间是通过Paxos算法进行同步复制的,你可以在任何一个数据中心写入数据。但是各个小数据表之间,并没有“可线性化”和“可串行化”的保障。

你可以看一看论文里的图 1,整个 Megastore 的架构,就好像是一个二维矩阵。横向按行,是按照数据分区进行了切分,纵向按列,是一个个独立的数据中心。
每一个分区的数据,可以在任意一个数据中心写入,同步复制到其他数据中心去。不过,不同分区的实体组之间的数据,其实就可以看作是两个独立的数据库的写操作,互相之间没有先后顺序和隔离性的关系了。
那么实体组到底是什么呢?你可以把实体组,当成是一个实体,以及挂载在这个实体下的一系列实体。
比如在前面电商的例子里,每一个用户是一个实体,这个用户的所有订单,可以以一个List的形式挂载在这个用户下,这个用户的所有和商家的消息,也可以挂载在这个用户下。这些东西打包在一起,就是一个实体组。一个实体组下的数据,往往我们经常会一起操作。比如,我们会去查看自己最近下的订单,意味着一个用户下的所有订单会在一起读取。
Megastore 在每一个实体组内,支持一阶段的数据库事务。但是,如果你有跨实体组的操作需求,你该怎么办呢?你有两个选择,第一个,是使用两阶段事务,当然它的代价非常高昂,是一个阻塞的、有单点的解决方案。而第二个,则是抛弃事务性,转而采用 Megastore 提供的异步消息机制。因为一旦跨实体组,我们就不能保障数据操作是在同一个服务器上进行的了,就需要跨服务器的操作需求。
两阶段事务相信你已经非常熟悉了,我们来看看这个消息传递机制是怎么样的。当我们需要同时操作两个实体组A和B的时候,我们可以对第一个实体组,通过一阶段事务完成写入。然后,通过Megastore提供的一个队列(queue),向实体组B发起一个消息。实体组B接收到这个消息之后,可以原子地执行这个消息所做的改动。
所以,A 和 B 两边的改动,在这个消息机制下,都是事务性的。但是两边的操作并没有共同组成同一个分布式事务。所以,如果在跨实体组的操作中采用了消息机制,Megastore 本质上没有实现数据库事务,它实现的仍然是数据库的最终一致性。

如果我们拿一个具体的应用案例,可以更容易看清楚 Megastore 的这个设计。我们就以即时聊天,比如微信这个场景作为例子好了。
- 我们可以把每个微信账号,当成是一个实体组。
- 账号里面的每一条收和发的消息,也挂载在这个实体组里。
- 当你要发一条消息出去的时候,其实会影响到两个实体组,一个是你的微信账号,因为你的聊天记录里会多一条发出的消息。另一个是收件人的微信账号,他的聊天记录里也会多一条消息。
- 但是我们并不需要保证,你这里看到发出消息和他看到收到消息同时发生。那么我们就可以采用Megastore的异步消息机制。
- 我们先用一个一阶段事务,在你的微信账号的实体组里写入这条消息。然后再通过 Megastore 的异步消息机制,往收件人的微信账号里发送一条“写入消息”的请求。而他的实体组在收到这个“写入消息”的请求之后,把整个消息事务性地写入自己的实体组就可以了。
而之所以这个消息机制是有效可行的,其实还是回到我们开头说的,在实际应用层面,我们对于“可串行化”以及“可线性化”的需求并不是全局的,而是可以分区的。我们只需要保障自己发出的消息,在自己的微信界面上,看起来是按照顺序出现的就可以了。而并不要求收件人的微信和发件人的微信之间,也是“可线性化”的。
# 1.4 对 Megastore 设计的讨论
我们可以看到 Megastore 提出了一系列雄心勃勃的目标,而且它的实现也没有从头开始,而是基于 Bigtable 和 Paxos 算法来实现这些目标。
但天才工程师也摆脱不了自然限制,由于 Paxos 算法本身的性能局限,Metgastore 采取了分区的做法。 本质上,Megastore不是一个“可线性化”的分布式数据库,而是很多个分布式数据库的一个合集。而在事务性上,Megastore 也作出了种种限制,Megastore只支持一个实体组下的一阶段事务
可以看到,Megastore 虽然提出了雄心勃勃的目标,但在最终实现上,还是做出了种种的妥协和限制。Megastore 并不是一个“透明”的分布式数据库,而是要你在充分了解它的特性之后,对于你自己的数据库表进行对应的适配性设计,才能发挥出它的这些有意思的特性。
相比开创时代的Bigtable,和成为最终答案的Spanner,Megastore在网络上的资料相对少一些。实体组的概念,也和大部分你熟悉的关系型数据库和KV数据库都有些区别。不过,你可以直接去用一下 Google Cloud 里的 Datastore (opens new window) 这个产品,它其实就是进化多年之后的Megastore。当然,我也推荐你反复读一下 Megastore 的 论文原文 (opens new window),这是一个每一个优秀工程师都能通过自己的思考和分析找出的解决方案。
# 2. 把 Bigtable 玩出花来
Megastore 虽然定了一个雄心勃勃的设计目标,但是当我们深入它的整体架构的时候,发现它还是根据实际的应用场景做了种种的妥协。所以,Megastore 虽然支持了 SQL 形式的接口,但是实际在应用中,仍然需要我们针对自己的数据模型进行精心的设计。
那么,这一讲,我们就看看 Megastore 的数据模型是怎么样的,它在底层又是如何使用 Bigtable 来存储数据的,它实现的实体组层面的事务又是怎么一回事儿。
事实上,与其说 Megastore 是一个独立的分布式数据库方案,不如说它更像一个 Bigtable 上的应用层的封装。那么在深入了解了 Megastore 的数据模型之后,相信你能够学会善用现有的系统,利用好现有系统的各种特性,就能有效组合出各类原先觉得难以做到的数据库高级特性。
# 2.1 实体组到底是什么
实体组这个名字,我们在上一讲里,就已经反复提过很多次了。我们给出了一个抽象的概念,说它是一系列会经常共同访问的数据,也给出了一些像是用户和他的订单这样的例子。那么这一讲,我们就深入来看看,实体组到底是个什么东西。
这里拿论文图 3 展示的一个最简单的示例 Schema 作为例子,它是一个片分享服务的示例 Schema:
CREATE SCHEMA PhotoApp
CREATE TABLE User {
required int64 user_id;
required string name;
} PRIMARY KEY(user_id), ENTITY GROUP ROOT;
CREATE TABLE Photo {
required int64 user_id;
required int32 photo_id;
required int64 time;
required string full_url;
optional string thumbnail_url;
repeated string tag;
} PRIMARY KEY(user_id, photo_id),
IN TABLE user,
ENTITY GROUP KEY(user_id) REFERENCES User;
CREATE LOCAL INDEX PhotosByTime
ON Photo(user_id, time);
CREATE GLOBAL INDEX PhotosByTag
ON Photo(tag) STORING (thumbnail_url);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
首先是定义了一个叫做 PhotoApp 的 Schema,你可以认为是定义了数据库里的一个库(database)。
然后定义了一张叫做User的表,并且定义其中的 user_id 是主键,并且定义了这个表是实体组(Entity Group)的一个 Root。一条 User 表的记录,就代表了一个用户。
接着,定义了一张叫做 Photo 的表,其中的主键是 user_id和 photo_id 两个字段的组合。并且,这张表是关联到前面的 User 表这个根上的。这个挂载,是通过 user_id 这个字段关联起来的。这个关联关系,就是我们上一讲所说的“挂载”。
实际上,我们可以有多个表,都关联到 User 表这个根上。而所谓的实体组,在逻辑上就是一张根表A,并且其他表可以通过外键,关联到根表 A 的主键上。并且,这个关联是可以层层深入的。比如我们还可以再定义一个表,叫做 PhotoMeta,里面可以再通过 user_id 和 photo_id,再关联到 Photo 表上。
最后,Schema 里分别建立了两个索引:
- 一个是叫做 PhotosByTime 的本地索引(Local Index),索引的是Photo表里 user_id 和 time 字段的组合;
- 另一个,是叫做 PhotosByTag 的 全局索引(Global Index),索引的是Photo表里的Tag这个字段,并且它专门设置了一个特定的STORING参数,指向了Photo表里的thumbnaill这个字段。
如果你仔细看一下这个Schema,你会发现其实这个Schema的定义,更像是我们前面见过的Thrift或者Protobuf的定义文件。每个字段不仅有类型,还有是否是required以及optional,并且我们可以定义repeated的字段,也就是有某一个字段在某一条记录里面是List。
这个其实是我们在大数据系统中常见的一种技术方案。为了减少数据需要跨越特定的服务器进行 Join,不如直接支持嵌套的 List 类型的字段。而 Megastore 也直接使用了 Protobuf 的 Schema,使得跨语言跨团队使用 Megastore 变得更加容易了。
# 2.2 实体组的数据布局
抛开这些题外话,我们一起看看为什么在一个实体组内,我们可以让数据经常共同访问,而跨越实体组就不合适呢?
其实只要观察一下上面的这个示例Schema,在Bigtable内是如何存储的,你自己就能得出答案。
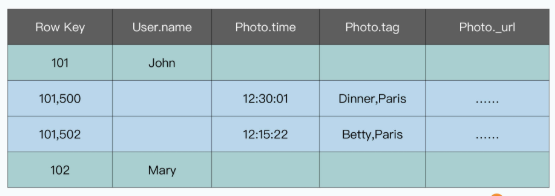
我把论文里面的图5,也就是前面的PhotoApp表在Bigtable里是怎么存储的放在了这里,并把示例数据分别标成了绿色和蓝色。对于PhotoApp里的User和Photo这两张表,是存放在同一张Bigtable的表里的,其中,绿色部分的数据是来自User表的,而蓝色部分的数据来自Photo表。
可以看到,我们是直接拿User表的主键 user_id,作为了Bigtable里的行键。而对于Photo表,我们是拿 user_id 和 photo_id 组合作为行键,存放在同一张表里。因为Bigtable里面的数据,是按照行键连续排列的。所以,同一个User下的Photo的数据记录,会连续存储在对应的User记录后面。
我们之前讲过 Bigtable 里面的数据是按照行键分区的,实际的数据存储,也是按照行键连续存储的。并且,当我们用一个行键去 Bigtable 里面查询数据的话,Bigtable 会有 Block Cache,也就是把底层的 SSTable 的整个 Block 都获取回来。而这个里面,其实就会包含当前行键前后连续行键所包含的数据。
所以,当我们去查询某一条User记录的时候,会有非常高的概率,直接把User记录下的Photo记录一并获取到,而不需要再次访问对应的硬盘。自然读写的性能,就会比随机布局的数据要好上很多。在 Megastore 的论文里,这样的数据布局是被称之为对 Key 进行预 Join(Pre-Joining with Keys)。
除此之外,为了避免热点问题,Megastore支持你对数据表添加一个SCATTER参数,添加了这个参数之后,所有的行键都会带上Root实体记录的Key的哈希值。这样,虽然同一个实体组里的数据还是连续排列的,但是同一张表的两个连续实体组的Root记录的Key,就不一定存储在一个服务器上了。
而数据库里的每一个列也非常简单,我们就直接使用Bigtable的Column就好了。而且Megastore这样混合一个实体组里的多个表的结构,其实是非常适合Bigtable的。因为Bigtable的列是稀疏的,对于不存在的列,并不需要存储,当然也不会占用存储空间。这样,虽然一个Bigtable里的表,实际存放了一套实体组的Schema下的很多张表,但是并不会存在存储上浪费的情况。