 预训练语言模型简介
预训练语言模型简介
# 1. 自然语言处理研究进展
NLP 领域任务繁多,每一类任务所使用的训练数据和模型不尽相同,绝大多数的 NLP 任务都可以分为如下五类:
| 任务名 | 描述 | 模型 | 应用 |
|---|---|---|---|
| 分类 | 给 seq 添加类标 | 文本分类,情感分析 | |
| 匹配 | 匹配两个 seq | 搜索、问答、单轮对话(基于检索) | |
| 翻译 | seq2seq | 机器翻译、自动语音识别、单轮对话(基于生成) | |
| 结构化预测 | 将 seq 映射到特定结构 | 命名实体识别、分词、词性标注、一寸分析、语义分析 | |
| 序列决策处理 | 在动态变化的环境中采取状态操作 | 多轮对话 |
NLP 的数据通常很难标注,因此缺乏大规模标注数据一直是困扰 NLP 领域的一大难题。虽然如此,但研究人员可以从人类浩如烟海的文本中轻易获取大规模的无标注文本数据。如果能够有效利用这些数据,就能大幅提升 NLP 任务的效果。
预训练语言模型(Pre-trained Language Model)就是通过对这些无标签的数据进行“预训练”,获得一个比较好的语言表示,再将其应用到特定的自然语言处理下游任务种。
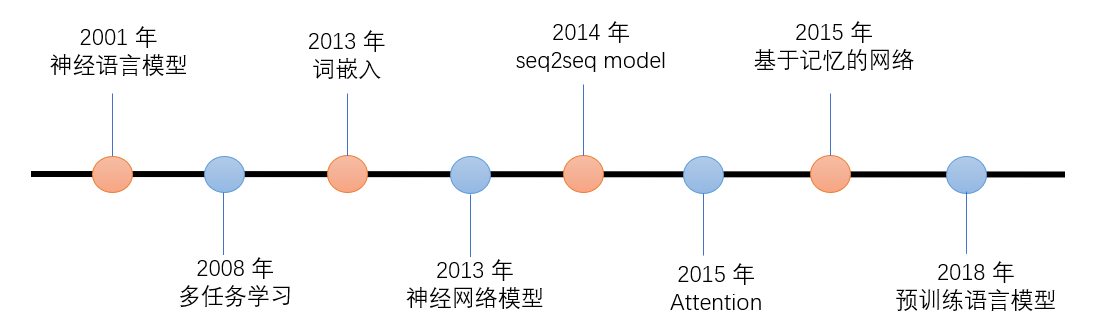
NLP 领域里程碑式的进展如下图所示:
# 2. 为什么要预训练
# 2.1 预训练
预训练属于迁移学习的范畴。预训练的思想是:模型参数不再是随机初始化的,而是通过一些任务进行预先训练,得到一套模型参数,然后用这套参数对模型进行初始化,再进行训练。
比如在 CV 领域,多个 CNN 构成的 model 在训练后,越浅的层学到的特征越通用。因此,在大规模图片数据上预先获取的“通用特征”,会对下游任务有非常大的帮助。
# 2.2 自然语言表示
自然语言的表示学习,就是将人类的语言表示成更易于计算机理解的方式。下图是自然语言表示学习的发展路径:
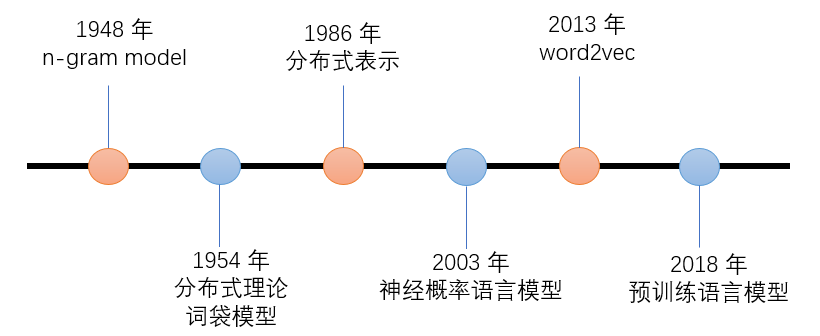
- 早期的 n-gram 模型,是基于统计的语言模型,通过前 n 个词来预测第 n+1 个词。
- 分布式理论的核心思想是:上下文相似的词,其语义也相似,是一种统计意义上的分布;
- 分布式表示:与分布式理论不同,它并没有统计意义上的分布,它是指文本的一种表示方式,相比与 one-hot 表示,分布式表示将文本在更低的维度进行表示。
- word2vec 中每一个 word 都有了一个固定的词向量表示,语义相近的词,其向量也是相似的。但这种词向量不能很好地解决一词多义问题,因为以 word2vec 为代表的第一代预训练语言模型中,一个 word 的词向量是固定不变的。
- EMLo 考虑了上下文的词向量表示方法,以 BiLSTM 作为特征提取器,同时考虑了上下文的信息,从而较好的解决了多义词的表示问题。ELMo 开启了第二代预训练语言模型的时代,即“预训练 + 微调”的范式。EMLo 之后的 Transformer 作为更强大的特征提取器,被应用到后续的各种模型中,不断刷新 NLP 的 SOTA 表现。
# 2.3 预训练语言模型的发展史及分类
预训练语言模型的发展史:
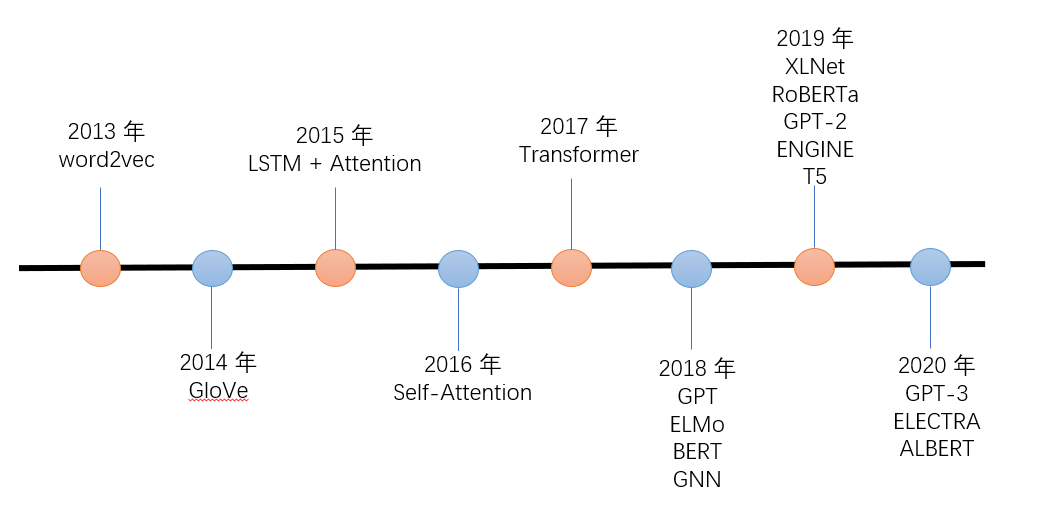
我们简单区分一下自回归(Autoregressive)和自编码(Autoencoder)两种不同的模型:
- 自回归(Autoregressive)模型:根据句子中前面的单词,预测下一个单词;
- 自编码(Autoencoder)模型:通过覆盖句子中的单词,或者对句子做结构调整,让模型附院单词或次序,从而调节网络参数。

- 自编码模型中,(a) 图所示的单词级别是只有一个单词被覆盖;(b) 图所示的句子级别的例子不仅有单词的覆盖,还有词序的改变。
ELMo、GPT 系列和 XLNet 属于自回归模型,而 BERT、EGINE、RoBERTa 等属于自编码模型。
目前,预训练语言模型的通用范式是:
- 基于大规模文本,预训练得出通用的语言表示;
- 通过微调的方式,将学习到的知识传递到不同的下游任务中。
由于不同的预训练语言模型的结构不同、优势不同,在实际应用中,需要根据具体的任务选择不同的模型。例如,BERT 系列模型更适合于理解任务,而 GPT 系列模型更适用于生成任务。
预训练语言模型的发展可以参考邱锡鹏教授的 Pre-trained Models for Natural Language Processing: A Survey (opens new window)。