 知识图谱的存储与查询
知识图谱的存储与查询
# 1. 基于关系型数据库的知识图谱存储
# 1.1 知识图谱的各种存储方式
知识图谱的存储需要综合考虑知识结构、图的特点、索引和查询优化等问题。
典型的知识图谱存储引擎分为基于关系数据库的存储和基于原生图的存储。
知识图谱并非一定要用图数据库存储,例如 Wikidata 项目后端是 MySQL 实现的。
# 1.2 图结构模型
属性图和 RDF 图模型都是有向标记图。基于知识图谱的特点,我们需要考虑三个方面的问题:
- 存储的物理结构
- 存储的性能问题
- 图的查询问题
# 图的查询语言:SPARQL
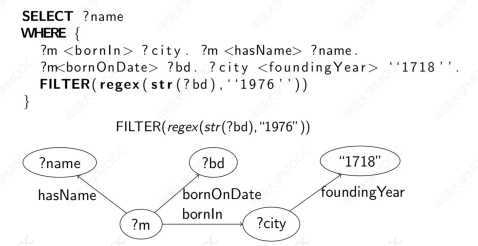
- 查询计算的问题便转换成了一个子图匹配的问题
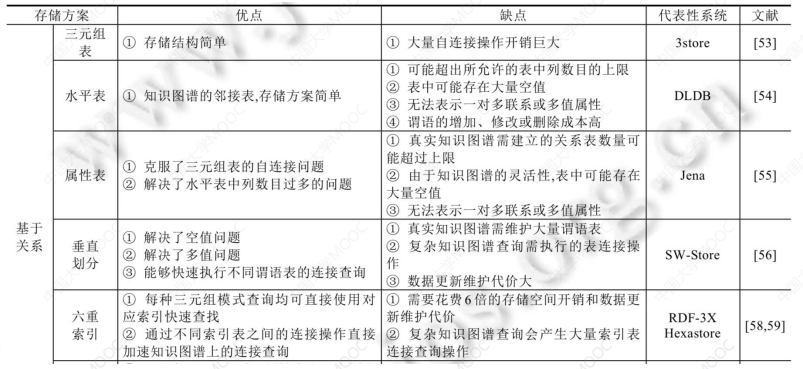
# 1.3 最简单的存储:Triple Store
我们可以利用关系型数据库直接存三元组,建立一张包含 subject、property 和 object 的表,但这样最大的问题是查询的效率很低:

- SPARQL 转换成 SQL 后会包含非常多的 self-join 查询,效率十分低下。
# 1.4 属性表存储(Property Tables)
属性表存储仍然基于传统关系数据库实现,典型的如 Jena、FlexTable、DB2-RDF 等实现。
基本思想是以实体类型为中心,把属于同一个实体类型的属性组织为一个表,即属性表,进行存储:
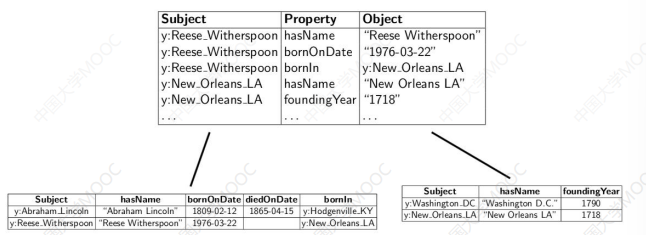
- 优点:Join 减少了,本质上接近于关系数据库,可重用 RDBMS功能
- 缺点:
- 产生大量空值
- 其实现高度依赖基于 subject 的合理聚类,但对 subject 聚类的计算比较复杂,并对具有多值属性的聚类计算更加复杂
# 1.5 二元表(Binary Tables)
二元表也称为垂直划分表,也是基于关系数据库实现的三元组存储方式。
基本思想是对三元组按属性分组,为每个属性在关系数据库中建立一个包含(Subject、Object)两列的表:
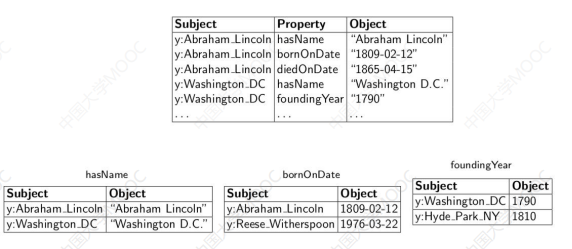
由于一个知识图谱中属性数量是有限的,因此表的总体数量是可控的。
- 优点:没有空值;避免了大规模的聚类计算;对于 Subject-Subject-Join 操作性能好
- 缺点:insert 性能损耗高(因为对于同一个 subject,要同时对多个表进行 insert 操作);并且 Subject-Object Join 性能差(而且这种方式比较普遍)
# 1.6 全索引结构(Exhaustive Indexing)
性能最好的存储方式是基于全索引结构的存储,典型的实现包括 RDF-3X,Hexastore 等。
这种方法也仅维护一张包含 (Subject, Predicate, Object) 的三列表,但增加了多个方面的优化手段:
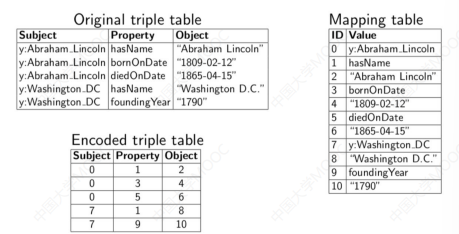
- 第一个优化手段是建立 Mapping Tab,即将所有的字符串首先映射到唯一的数字 ID,这一将大大压缩存储空间。
- 进一步建立六种索引: SPO, SOP, PSO, POS, OPS, OSP,即分别建立 Subject-Predicate-Object 等六个方面的全索引,显然多种形式的索引覆盖了多个维度的图查询需求。
- 同时三元组基于字符串排序,并利用 clustered B+ tree 树来组织索引以进一步优化索引检索的效率。

查询示例:以最初给的 SPARQL 为例(即下图)
在检索 ?m <bornIn> ?city 时,会利用 PSO 索引查询 <bornIn> ?m ?city 进行一轮匹配,并依次完成所有候选条件的处理和候选三元组的过滤,最后筛选得到所需要的结果。
小结
# 2. 基于原生图数据库的知识图谱存储
# 2.1 关系型数据库的局限性
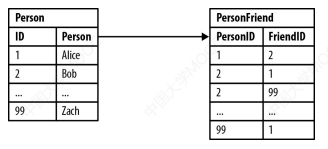
关系型数据库虽然被命名为“关系”,但却十分不善于处理关系
- 关系模型将语义关联关系隐藏在外键结构中,无显示表达,并带来关联查询与计算的复杂性。
- 数据来源多样性带来大量离群数据(Outlier Data),导致数据集的宏观结构愈发复杂和不规整,对于包含大量离群数据的场景,关系模型将造成大量表连接、稀疏行和非空处理。
- 互联网的开放世界假设要求数据模型满足高动态和去中心化的扩增数据的能力,关系模型对表结构的范式要求限制了 Schema 层的动态性。
从根本上而言,关系模型背离了用接近自然语言的方式来描述客观世界的原则,这使得概念化、高度关联的世界模型与数据的物理存储之间出现了失配。
下面举个例子来说明这种局限性:
- 问 “who are Bob's friends?” 很容易回答
- 但处理具有对称关系的查询时,比如 "Who is friends with Bob",由于 friends 具有对称关系,即 A 是 B 的朋友,那 B 也是 A 的朋友,这时如果用关系型数据库,受限于建表索引的范式约束,查 A 的朋友是谁很高效,但查询谁与 A 是朋友则需要遍历整个 friend 表并逐一比对,这显然很低效。但从图的角度,只需要声明 friend 关系是自反关系即可支持反向查询。
- 更为困难的是执行多跳查询,这会带来更加复杂的 Join 计算,并会随着跳数的增加呈指数级增长
而且知识图谱需要更加丰富的关系语义表达与关联推理能力,如对称关系、传递关系等。
除了关联查询能力,深层次的关系建模还将提供关联推理的能力,属性图数据库如 Neo4J 提供了关系模型的关联查询能力,AllegroGraph 等 RDF 图数据库提供了更多的关联推理能力。
NoSQL 也不善于处理关联关系,关系在 NoSQL 数据库中也不是 First-Class Citizen,在处理数据关联也需要使用类似于外键的 Foreign Aggregates。
- Foreign Aggregates 不能处理自反关系,例如查询 “who is friends with Bob?” 时,需要暴力计算,即扫描所有实体数据集。
- Foreign Aggregates 也不负责维护 Link 的有效性,在处理多跳关系时效率也很低下。
# 2.2 原生图数据库
图数据库:Relations are first-class citizens,这是不同于关系型数据库的准则。
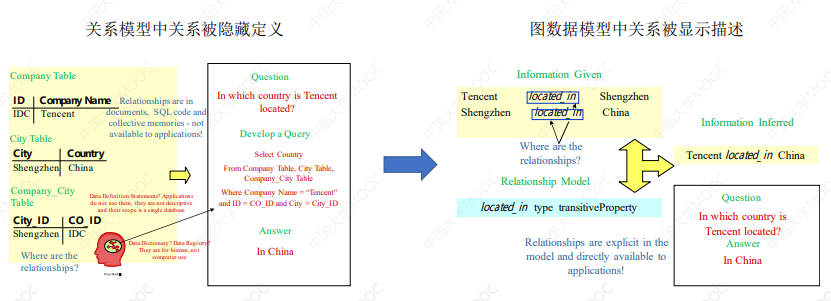
原生图数据库还可以利用图的结构特征建索引:
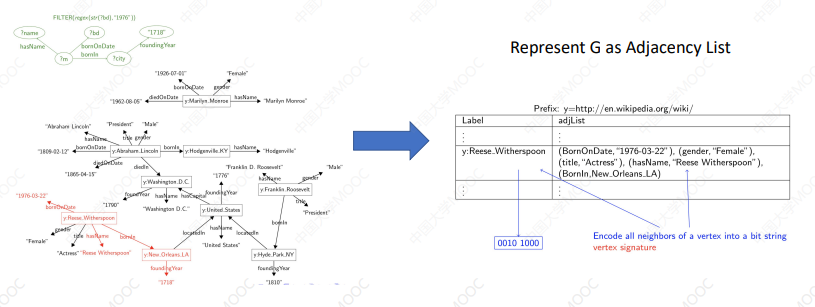
- 将图表示为一个邻接列表
图数据建模的好处:
- 自然表达:图是十分自然的描述事物关系的方式,更加接近于人脑对客观事物的记忆方式
- 易于扩展:例如在图中,临时希望获取历史订单,只需新增边即可
- 复杂关联表达:图模型易于表达复杂关联逻辑的查询,例如在推荐系统中,希望表达复杂的推荐逻辑,例如:"all the flavors of ice cream liked by people who enjoy espresso but dislike Brussels sprouts, and who live in a particular neighborhood."
- 多跳优化:在处理多跳查询上,图模型有性能优势
常见的图数据库列表:
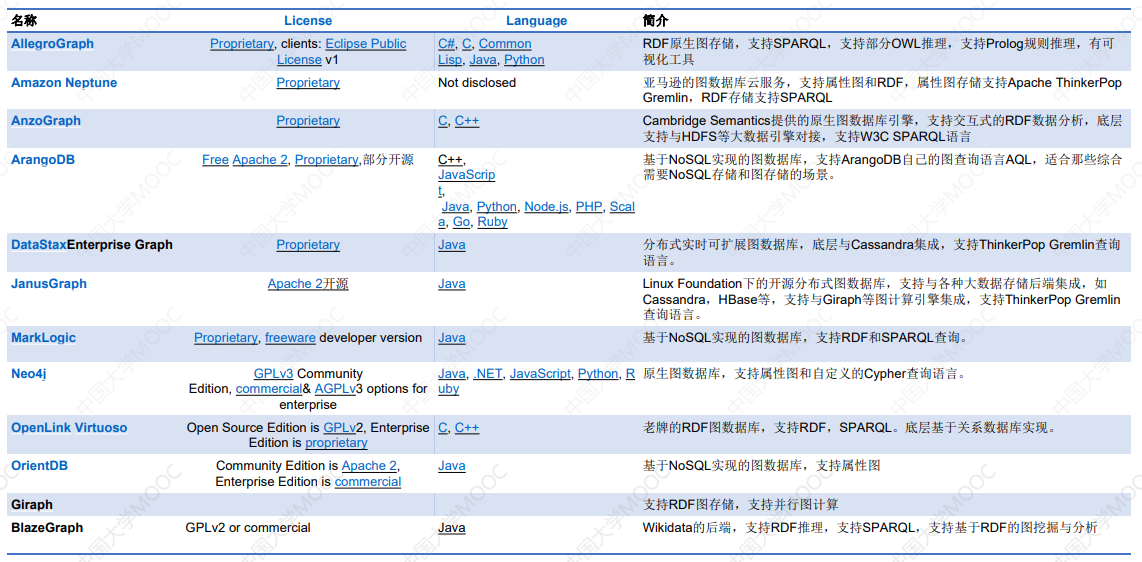
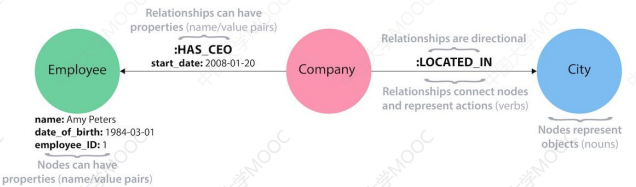
# 2.3 图数据库举例:Neo4J
属性图是图数据库 Neo4J 实现的图结构表示模型,在工业界有广泛应用。属性图由顶点(Vertex),边(Edge),标签(Label),关系类型和属性(Property)组成的有向图。
在属性图中,节点和关系是最重要的实体。节点上包含属性,属性可以以任何键值形式存在。
# 2.4 图查询语言:Cypher
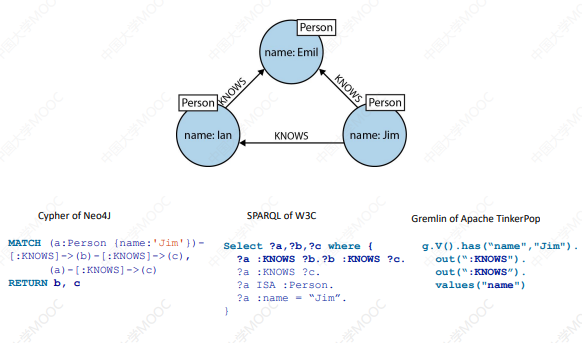
Cypher、SPARQL、Gremlin 是常用的图查询语言,这里不再介绍他们的细节。
小结:什么时候使用图数据库
- 高性能关系查询:需要快速遍历许多复杂关系的任何用例。这实际上包括欺诈检测、社交网络分析、网络和数据库基础设施等
- 模型的灵活性:任何依赖于添加新数据而不会中断现有查询池的用例。模型灵活性包括链接元数据、版本控制数据和不断添加新关系
- 快速和复杂的分析规则:当必须执行需要复杂的规则时,例如子图的比较。这包括推荐、相似度计算和主数据管理
# 3. 原生图数据库实现原理浅析
# 3.1 实现原理:免索引邻接
原生图是指采用免索引邻接(Index-free adjacency)构建的图数据库引擎,如 AllegroGraph, Neo4J 等。
采用免索引邻接的数据库为每一个节点维护了一组指向其相邻节点的引用,这组引用本质上可以看做是相邻节点的微索引(micro index)。这种微索引比起全局索引在处理图遍历查询时非常廉价,其查询复杂度与数据集整体大小无关,仅正比于相邻子图的大小。
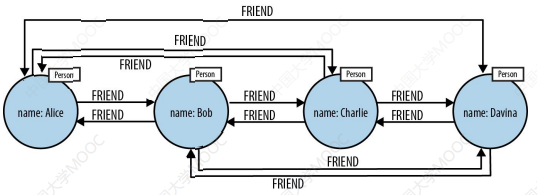
# 3.1.1 关系型数据库中的 Table Join 的计算复杂度
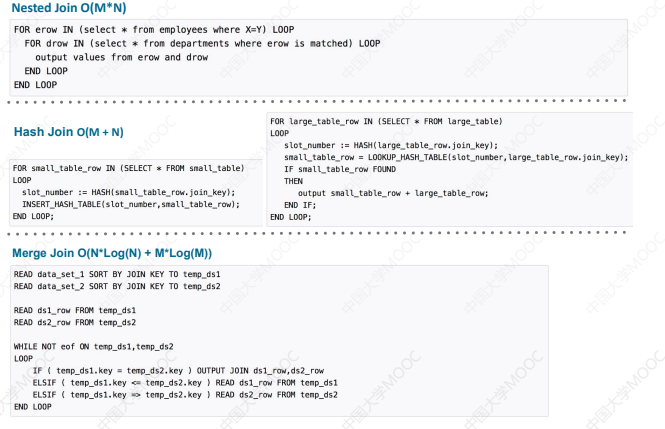
- 可以看到这些 Join 的计算复杂度大小都与表的大小或数据集的大小有关
# 3.1.2 Index-free adjacency 的计算复杂度
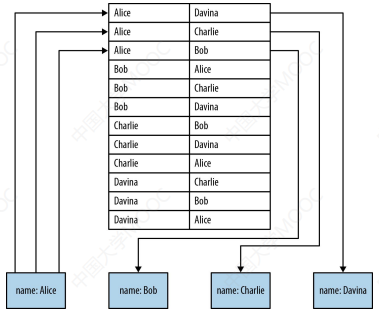
对于 Index-free adjancy,关系是直接基于某个节点的相邻节点获取的(tail to head 或 head to tail)。例如,为了查询 "who is friends with Alice",我们只需要检索 Alice 的所有 incoming FRIEND 关系即可,这个复杂度仅与节点的邻居个数有关,而与整个数据集的大小是无关的。
# 3.2 原生图数据库的物理存储实现
这里我们依然以 Neo4J 为例来介绍:
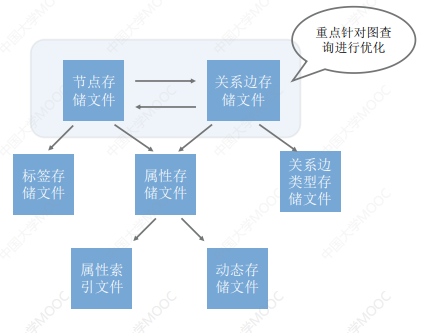
- 最核心的实现是两个文件:节点存储文件和关系边存储文件。neo4j 重点通过这两个文件的物理结构设计,来对整个图的查询进行全方位的优化
# 3.2.1 节点存储文件

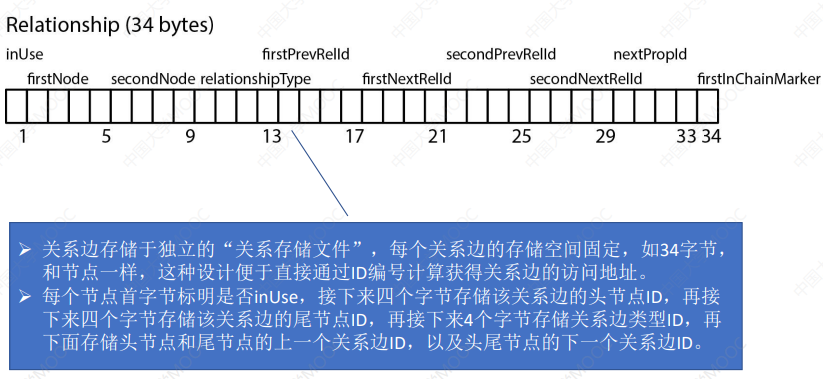
# 3.2.2 关系存储文件
# 3.3 图遍历查询的物理实现
这是一个图谱实际物理实现设计:
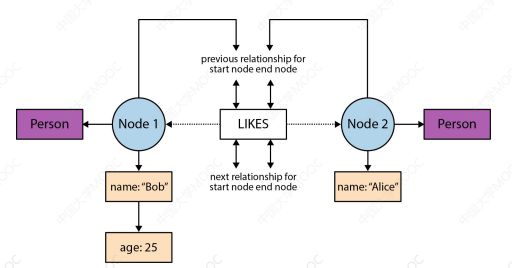
主要优化的点:
- 节点的查找,关系的查找
- 从节点到关系,从关系到节点
- 从关系到关系
- 从节点到属性,从关系到属性
- 从关系到关系类型
# 3.4 属性数据的存储处理:内联与动态存储
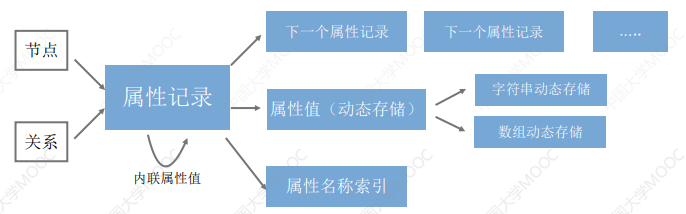
- 图数据库中存在大量属性,这些属性的检索与图遍历的计算是分开的,这是为了让节点之间的图遍历能不受大量属性数据的影响。
- 节点和关系的存储记录都包含指向它们的第一个属性 ID 的指针,属性记录也是固定大小,便于之间通过ID计算获得存储位置
- 每个属性记录包含多个属性块,以及属性链中下一个属性的 ID
- 每个属性记录包含属性类型以及属性索引文件,属性索引文件存储属性名称
- 对于每一个属性值,记录包含一个指向动态存储记录的指针(大属性值)或内联值(小属性值)
# 4. 各种选型的比较
# 4.1 RDF 图模型和属性图模型的比较

属性图模型是 Neo4J 所引导的一种数据模型,因其性能较好而得到业界的大量使用。
RDF 图模型因为来源于人工智能领域有关知识表示方面的研究,因而具有比较好的知识表示的理论与基础。
一般而言,
- 如果应用场景重图结构和查询分析,那属性图会更合适一些
- 如果应用场景重知识的建模,特别要求描述和表示复杂的关联关系,且有知识推理的要求,那 RDF 图模型会更合适一些
# 4.2 知识图谱查询语言的比较
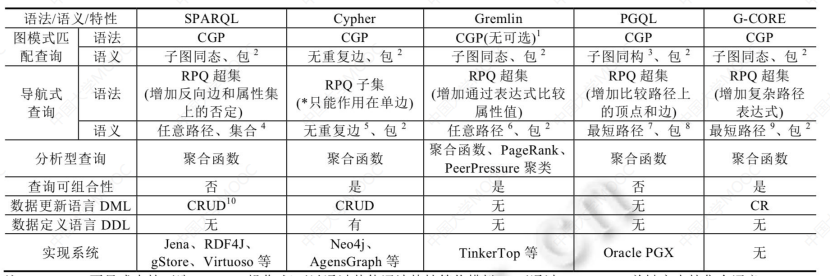
- SPARQL 因与 RDF 对应,也具有较好的理论模型基础,同时对于更加复杂的知识表示的查询,其支持度也会比较好
- 其他的几种查询语言主要是针对图的结构设计的语言,一般对于比较强调图结构的应用会更加适用
# 4.3 常见知识图谱数据库管理系统比较
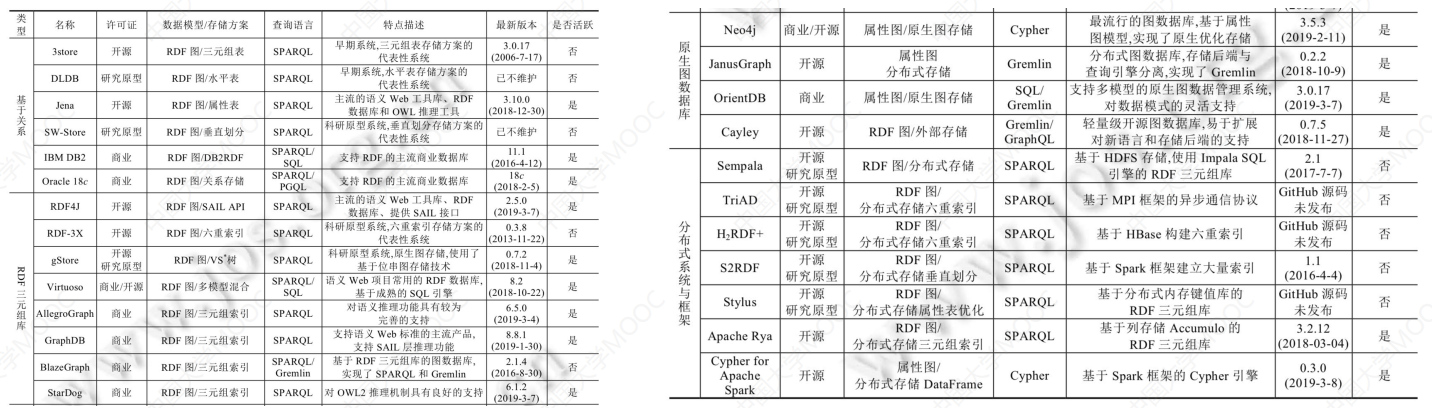
不再详细介绍。
总结:知识图谱存储的选择
- 知识图谱存储方式的选择需要综合考虑性能、动态扩展、实施成本等多方面综合因素
- 区分原生图存储和非原生图存储:原生图存储在复杂关联查询和图计算方面有性能优势,非原生图存储兼容已有工具集通常学习和协调成本会低。
- 区分 RDF 图存储和属性图存储:RDF 存储一般支持推理,属性图存储通常具有更好的图分析性能优势
- 在大规模处理情况下,需要考虑与底层大数据存储引擎和上层图计算引擎集成需求
总结:关于图模型与图数据库
- 图模型是更加接近于人脑认知和自然语言的数据模型,图数据库是处理复杂的、半结构化、多维度的、紧密关联数据的最好技术。我们鼓励在知识图谱项目中采用和实践图数据库
- 图数据库有它弱处,假如你的应用场景不包含大量的关联查询,对于简单查询,传统关系模型和 NoSQL 数据库目前在性能方面更加有优势
- RDF 作为一种知识图谱表示框架的参考标准,向上对接 OWL 等更丰富的语义表示和推理能力,向下对接简化后的属性图模型以及图计算引擎,是最值得重视的知识图谱表示框架