 基本概念与操作
基本概念与操作
参考 Elasticsearch 核心技术与实战 | 极客时间 (opens new window)的 01~13 讲
# 1. Elasticsearch 的安装
# 1.1 安装 Java
运行 ES,需要安装并配置 JDK,即设置 $JAVA_HOME。
各版本对 Java 的依赖:
- ES 5 需要 Java 8 以上的版本
- ES 6.5 开始支持 Java 11
- 7.0 开始,内置了 Java 环境
# 1.2 获取 Elasticsearch 安装包
# 1.3 Elasticsearch 的文件目录结构
| 目录 | 配置文件 | 描述 |
|---|---|---|
| bin | 脚本文件,包括启动 ES,安装插件,运行统计数据等 | |
| config | elasticsearch | 集群配置文件,user、role based 相关配置 |
| JDK | Java 运行环境 | |
| data | path.data | 数据文件 |
| lib | Java 类库 | |
| logs | path.log | 日志文件 |
| modules | 包含所有 ES 模块 | |
| plugins | 包含所有已安装插件 |
# 1.4 JVM 配置
- 修改 JVM - config/jvm.options
- 7.1 下载的默认设置是 1 GB
- 生产配置的建议
- Xmx 和 Xms 设置成一样
- Xmx 不要超过机器内存的 50%
- 内存总量不要超过 30GB
# 1.5 安装与查看插件
$ bin/elasticsearch-plugin install analysis-icu
-> Downloading analysis-icu from elastic
[===============================================]100%
-> Installed analysis-icu
$ bin/elasticsearch-plugin list
analysis-icu
2
3
4
5
6
7
或者访问 localhost:9200/_cat/plugins?v
Elasticsearch 提供插件的机制对系统进行扩展:
- Discovery Plugin
- Analysis Plugin
- Security Plugin
- Management Plugin
- Ingest Plugin
- Mapper Plugin
- Backup Plugin
# 1.6 如何在开发机上运行多个 Elasticsearch 实例
- bin/elasticsearch -E node.name=node1 -E cluster.name=geektime -E path.data=node1_data -d
- bin/elasticsearch -E node.name=node2 -E cluster.name=geektime -E path.data=node2_data -d
- bin/elasticsearch -E node.name=node3 -E cluster.name=geektime -E path.data=node3_data -d
删除进程:ps | grep elasticsearch,kill pid。
然后通过访问 localhost:9200/_cat/nodes 来得到结果。
# 1.7 kibana 的安装与界面浏览
下载后,/bin/kibana 即可启动。
# 1.8 Logstash 的安装
# 2. 基本概念
# 2.1 文档(Document)
Elasticsearch 是面向文档的,文档是所有可搜索数据的最小单位。比如:
- 日志文件中的日志项
- 一本电影的具体信息 / 一张唱片的详细信息
- MP3 播放器里的一首歌/一篇 PDF 文档中的具体内容
文档会被序列化成 JSON 格式,保存在 Elasticsearch 中:
- JSON 对象由字段组成
- 每个字段都有对应的字段类型(字符串/数值/布尔/日期/二进制/范围类型)
每个文档都有一个 Unique ID,你可以自己指定这个 ID,也可以通过 Elasticsearch 自动生成。
# 2.1.1 JSON 文档
- 一篇文档包含了一系列的字段。类似数据库表中一条记录。
- JSON 文档,格式灵活,不需要预先定义格式:
- 字段的类型可以指定或者通过 Elasticsearch 自动推算
- 支持数组 / 支持嵌套
# 2.1.2 文档的元数据
元数据,用于标注文档的相关信息
_index:文档所属的索引名_type:文档所属的类型名_id:文档唯一 ID_source:文档的原始 JSON 数据_all:整合所有字段内容到该字段,已被废除_version:文档的版本信息_score:相关性打分(做全文检索是很重要)

# 2.2 索引(Index)
索引(Index)是文档的容器,是一类文档的结合:
- Index 体现了逻辑空间的概念: 每个索引都有自己的 Mapping 定义,用于定义包含的文档的字段名和字段类型。
- Shard 体现了物理空间的概念: 索引中的数据分散在 Shard 上
索引的 Mapping 与 Settings:
- Mapping 定义文档字段的类型
- Setting 定义不同的数据分布
索引的不同语意
- 名词:一个 Elasticsearch 集群中,可以创建很多个不同的索引
- 动词:保存一个文档到 Elasticsearch 的过程也叫索引(indexing)
- ES 中,创建一个倒排索引的过程
- 名词:一个 B 树索引,一个倒排索引
# 2.3 Type
在 7.0 之前,一个Index 可以设置多个 Types。从 6.0 开始,Type 已经被 Deprecated。7.0 开始,一个索引只能创建一个 _doc 的 Type。
传统关系型数据库与 Elasticsearch 的一个不太恰当的类比:
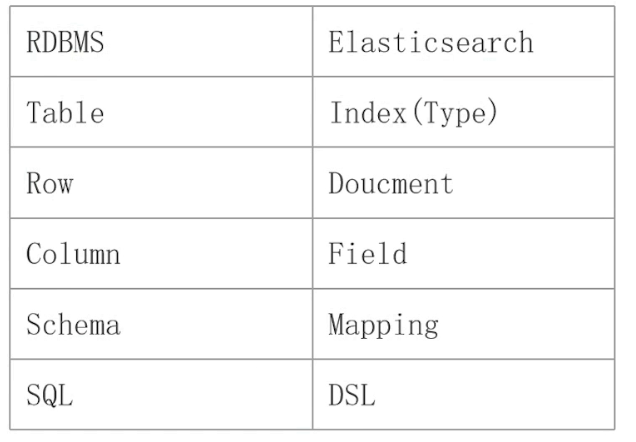
- Elasticsearch:Schemaless / 相关性 / 高性能全文检索
- RDMS:事务性 / Join
# 2.4 节点
# 2.4.1 ES 的分布式
分布式系统的可用性和扩展性:
- 高可用性:
- 服务可用性:允许有节点停止服务
- 数据可用性:部分节点丢失,不会丢失数据
- 可扩展性:
- 请求量提升/数据的不断增长 (将数据分布到所有节点上)
Elasticsearch 的分布式架构的好处
- 存储的水平扩容
- 提高系统的可用性,部分节点停止服务,整个集群的服务不受影响
Elasticsearch 的分布式架构:
- 不同的集群通过不同的名字来区分,默认名字“elasticsearch“
- 通过配置文件修改,或者在命令行中
-E cluster.name=geektime进行设定 - 一个集群可以有一个或者多个节点
# 2.4.2 节点的概念
节点是一个 Elasticsearch 的实例,本质上就是一个 Java 进程,生产环境一般建议一台机器只运行一个 Elasticsearch 实例。
- 每一个节点都有名字,通过配置文件配置,或者启动时候使用命令行
-E node.name=node1指定 - 每一个节点在启动之后,会分配一个 UID,保存在 data 目录下
# 2.4.3 Master eligible nodes 与 Master Node
每个节点启动后,默认就是一个 Master eligible 节点,它可以参加选主流程,进而成为 Master 节点。
- 可以设置 node.master: false 禁止一个节点成为 Master eligible 节点。
- 当第一个节点启动时候,它会将自己选举成 Master 节点。
- 每个节点上都保存了集群的状态,只有 Master 节点才能修改集群的状态信息,否则会导致数据的不一致。
集群状态(Cluster State)是指维护了一个集群中的必要信息,比如:
- 所有的节点信息
- 所有的索引和其相关的 Mapping 与 Setting 信息
- 分片的路由信息
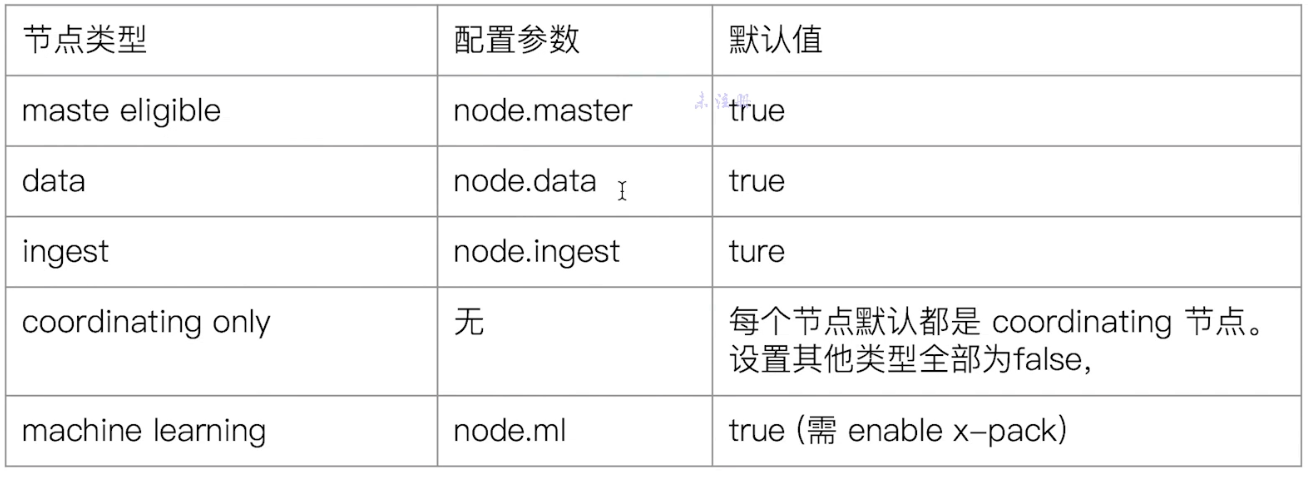
# 2.4.4 不同类型的节点
- Data Node:可以保存数据的节点。它负责保存分片数据,在数据扩展上起到了至关重要的作用。
当集群已经无法再保存现有数据时,就可以通过增加一个 Data Node 的实例来扩展。
Coordinating Data:负责接受 Client 的请求,将请求分发到合适的节点,最终把结果汇集到一起。
- 每个节点默认都起到了 Coordinating Node 的职责。
Hot & Warm Node
- Hot Node 是那些配置较高的节点
- Warm Node 是那些配置较低的节点,往往存储一些较旧的数据
- 通过不同硬件配置的 Data node,用来实现 Hot & Warm 架构,可以降低集群部署的成本。
Machine Learning Node
- 负责跑机器学习的 Job,用来做异常检测
Tribe Node
- Tribe Node 连接到不同的 Elasticsearch 集群并且支持将这些集群当成一个单独的集群处理
- 面临淘汰,5.3 后开始使用 Cross Cluster Serarch
# 2.4.5 配置节点类型
- 开放环境中一个节点可以承担多种角色
- 生产环境中,应该设置单一的角色的节点(dedicated node)
# 2.5 分片
# 2.5.1 分片的概念
存在 Primary Shard 和 Replica Shard,实现了一个主从架构。
Primary Shard(主分片),用以解决数据水平扩展的问题。通过主分片,可以将数据分布到集群内的所有节点之上。
- 一个分片是一个运行的 Lucene 的实例
- 主分片数在索引创建时指定,后续不允许修改,除非 Reindex
Replica Shard(副本),用以解决数据高可用的问题。分片是主分片的拷贝。
- 副本分片数,可以动态调整
- 增加副本数,还可以在一定程度上提高服务的可用性(读取的吞吐)
这里就是数据复制和数据分区同时使用了。
下面看一个三节点的集群中,blogs 索引的分片分布情况:
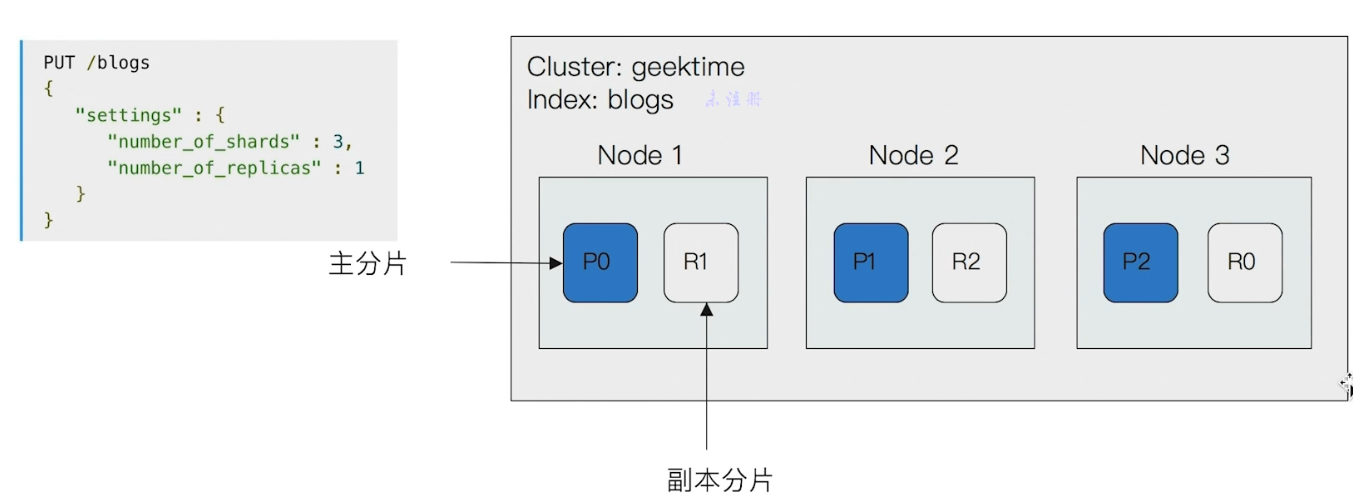
看 Settings 就知道:
number_of_shards:表示由 3 个主分片number_of_replicas:表示每个主分片有 1 个副本
# 2.5.2 分片的设定
对于生产环境中分片的设定,需要提前做好容量规划:
- 如果分片数设置过小:
- 导致后续无法增加节点实现水品扩展;
- 单个分片的数据量太大,导致数据重新分配耗时;
- 如果分片数设置过大:
- 影响搜索结果的相关性打分,影响统计结果的准确性;
- 单个节点上过多的分片,会导致资源浪费,同时也会影响性能;
7.0 开始,默认主分片从 5 改成 1,解决了 over-sharding 的问题。
# 2.5.3 分片的健康状况
- Green:主分片与副本都正常分配
- Yellow:主分片全部正常分配,有副本分片未能正常分配
- Red:有主分片未能分配

相关 API
GET _cluster/health:查看集群的健康状况GET _cat/nodes:查看集群 nodes 的信息GET _cat/shards:查看集群的分片信息
# 3. 文档的基本 CRUD 和批量操作
# 3.1 基本 CRUD

# 3.1.1 Create 一个文档
- 支持自动生成文档 ID 和指定文档 ID 两种方式:
- 调用
POST users/_doc会自动生成文档 ID - 调用
PUT user/_create/1则指定文档 ID 为 1,如果该 ID 的文档已存在,则操作失败。
- 调用

# 3.1.2 Get 一个文档
- 找到文档,返回 HTTP 200
- 其中文档元信息部分,
_version的值代表经过了多少次改动,因为同一 ID 的文档,即使被删除,version 号也会不断增加。 _source中默认包含了文档的所有原始信息。
- 其中文档元信息部分,
- 找不到文档,返回 HTTP 404

# 3.1.3 Index 文档
Index 和 Create 不一样的地方: 如果文档不存在,就索引新的文档。否则现有文档会被删除,新的文档被索引。_version 会加 1。
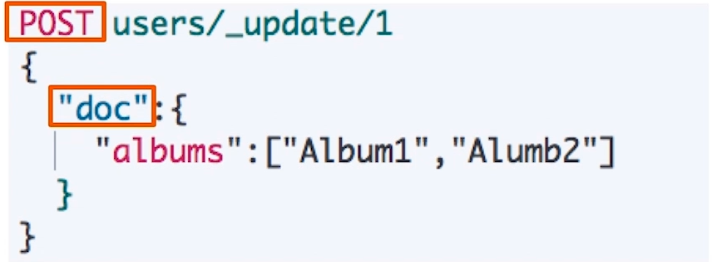
# 3.1.4 Update 文档
Update 方法不会删除原来的文档,而是实现真正的数据更新。
它的 POST 方法的 payload 需要包含在 “doc” 中:
# 3.2 Bulk API
批量操作,可以减少网络连接所产生的开销,提高性能。
# 3.2.1 bulk 操作
支持四种类型操作:Index、Create、Update、Delete
- 可以再 URL 中指定 index,也可以在请求的 Payload 中进行。
- 操作中单条操作失败,并不会影响其他操作。
- 返回结果包括了每一条操作执行的结果。

但一次也别发送过多的数据。
# 3.2.2 批量读取:mget
GET _mget
{
"docs": [
{
"_index": "user",
"_id": 1
},
{
"_index": "comment",
"_id": 1
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
# 3.2.3 批量查询:msearch
POST /users/_msearch
{}
{"query": {"match_all": {}}, "from": 0, "size": 10}
{}
{"query": {"match_all": {}}}
{"index": "twitter2"}
{"query": {"match_all": {}}}
2
3
4
5
6
7
8
# 3.3 常见返回错误
| 问题 | 原因 |
|---|---|
| 无法连接 | 网络故障或集群挂了 |
| 连接无法关闭 | 网络故障或节点出错 |
| 429 | 集群过于繁忙 |
| 4xx | 请求体格式有错 |
| 500 | 集群内部错误 |
# 4. 倒排索引
# 4.1 什么是倒排索引
- 正排索引:doc ID -> doc
- 倒排索引:term -> doc ID
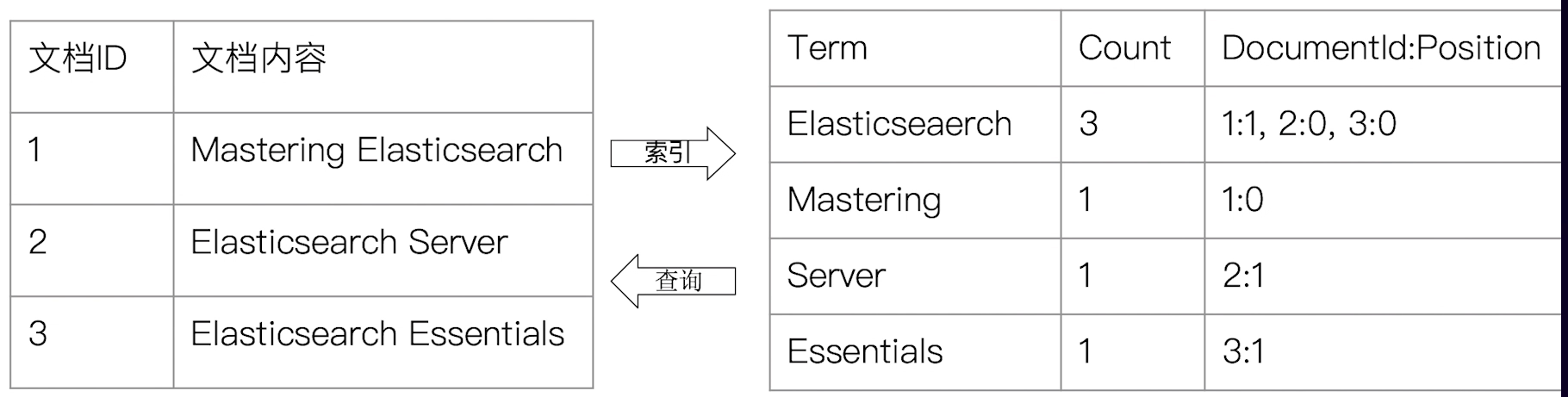
# 4.2 倒排索引的核心组成
倒排索引包含两个部分:
- 单词词典(Term Dictionary),记录所有文档的单词,记录单词到倒排列表的关联关系
- 单词词典一般比较大,可以通过 B+ 树或哈希拉链法实现,以满足高性能的插入与查询
- 倒排列表(Posting List),记录了单词对应的文档组合,由倒排索引项组成
- 倒排索引项(Posting)
- 文档 ID
- 词频 TF - 该单词在文档中出现的次数,用于相关性评分
- 位置(Position) - 单词在文档中分词的位置。用于语句搜索(phrase query)
- 偏移(Offset) - 记录单词的开始结束位置,实现高亮显示
- 倒排索引项(Posting)
示例:以 term Elasticsearch 为例来展示:
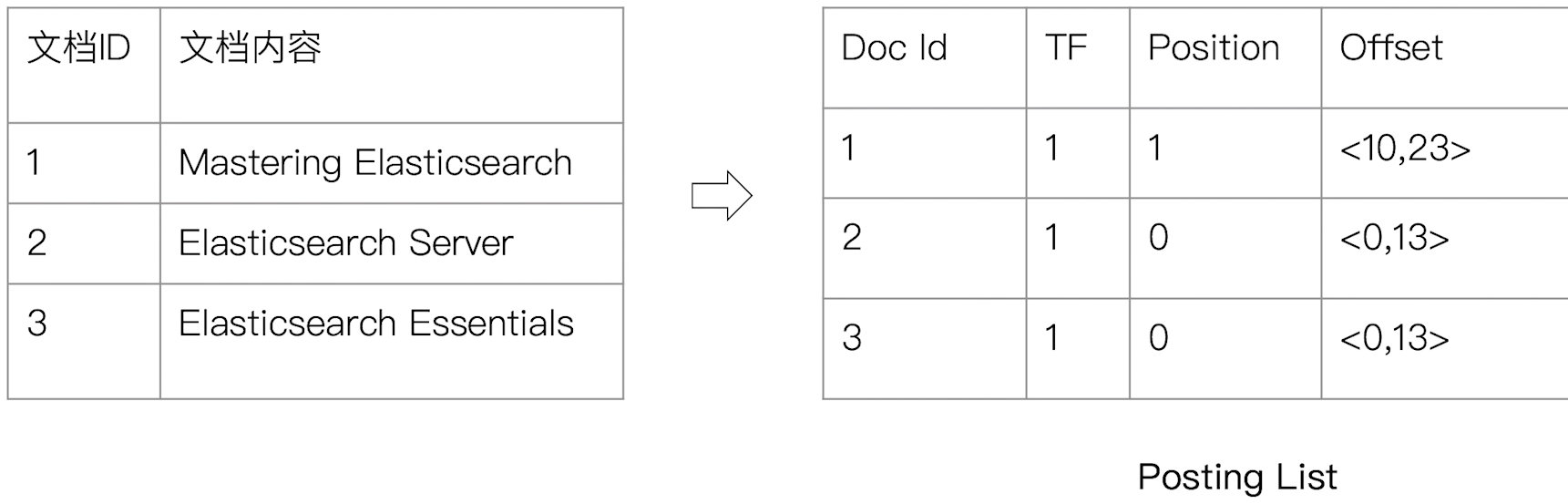
Elasticsearch 对 doc 的每个字段,都有自己的倒排索引。
你可以指定对某些字段不做索引
- 优点:节省存储空间
- 缺点:字段无法被搜索
# 5. 通过 Analyzer 进行分词
# 5.1 Analysis
Analysis:文本分析是把全文本转换一系列单词 (term / token) 的过程,也叫分词。
Analysis 是通过 Analyzer(分词器)来实现的,可以使用 Elasticsearch 内置的分析器,或者按需定制化分析器。
除了在数据写入时转换词条,匹配 Query 语句时候也需要用相同的分析器对查询语句进行分析。
下图是一个分词的示例:

- 可以看到,分词器将
Elasticsearch Server分成了elasticsearch和server,不仅分成了两个单词,还都变成了小写。
# 5.2 Analyzer 的组成
Analyzer(分词器)是专门处理分词的组件,由三部分组成:
- Character Filters:针对原始文本处理,例如去除 html
- Tokenizer:按照规则切分为单词
- Token Filter:将切分的的单词进行加工:小写,删除 stopwords,增加同义词等
如下图所示:
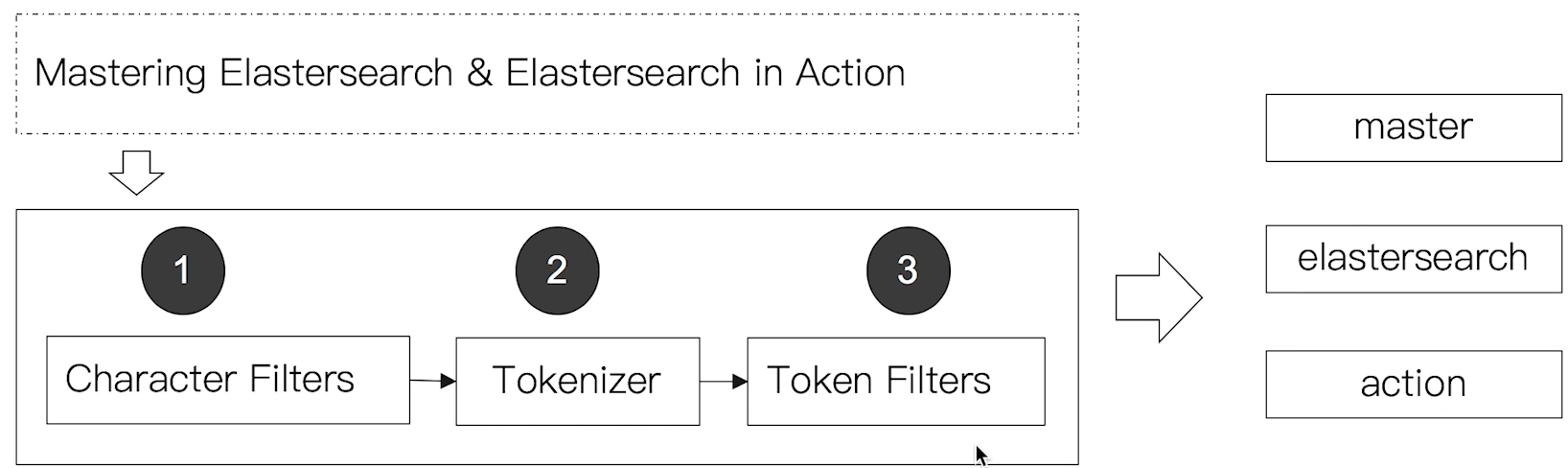
# 5.3 _analyzer API
使用 _analyzer API 可以用三种方式来查看 Analyzer 是如何工作的。
# 1)直接指定 Analyzer 进行测试

# 2)指定索引的字段进行测试

# 3)自定义分词器进行测试

# 5.4 ES 内置的分词器
Elasticsearch 内置的分词器有如下:
- Standard Analyzer:默认分词器,按词切分,小写处理
- Simple Analyzer:按照非字母切分 (符号被过滤),小写处理
- Stop Analyzer:小写处理,停用词过滤 (the,a,is)
- Whitespace Analyzer:按照空格切分,不转小写
- Keyword Analyzer:不分词,直接将输入当作输出
- Patter Analyzer:正则表达式,默认
\W+(非字符分隔) - Language:提供了 30 多种常见语言的分词器
- Customer Analyzer:自定义分词器
下面依次看一下。
# 1)Standard Analyzer
它是默认的分词器:按词切分,小写处理。
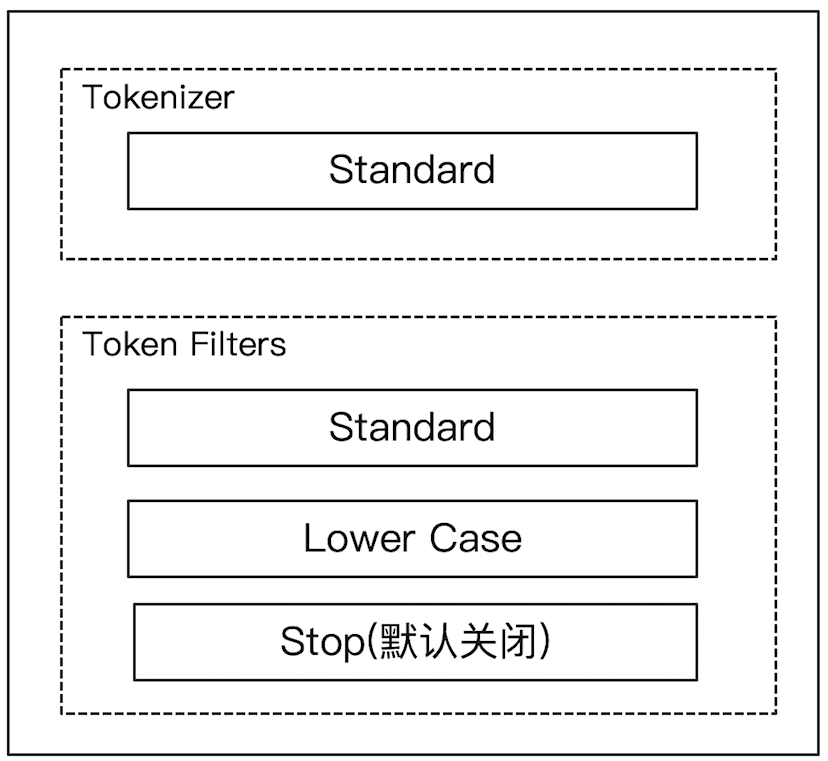
可以在 Kibana 的 dev tools 中进行如下尝试:
GET _analyze
{
"analyzer": "standard",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
2
3
4
5
# 2)Simple Analyzer
按照非字母切分,非字母的都被去除,并小写处理。
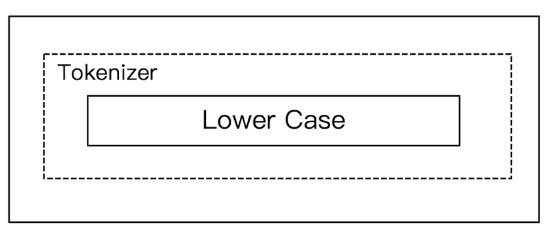
GET _analyze
{
"analyzer": "simple",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
2
3
4
5
# 3)Whitespace Analyzer
按照空格切分。

GET _analyze
{
"analyzer": "whitespace",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
2
3
4
5
# 4)Stop Analyzer
相比 Simple Analyzer,多了 stop filter,这会把 the、a、is 等修饰性词语去除掉。
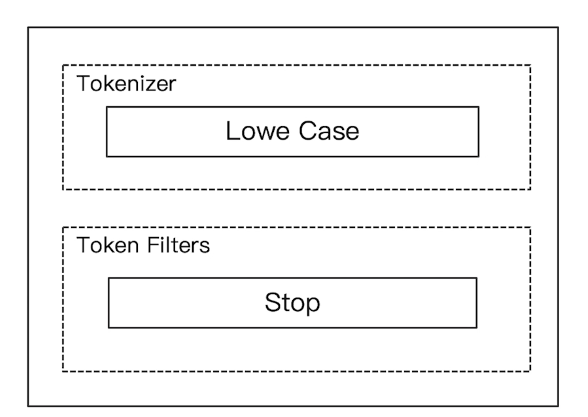
GET _analyze
{
"analyzer": "stop",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
2
3
4
5
# 5)Keyword Analyzer
不分词,直接将输入当一个 term 输出。
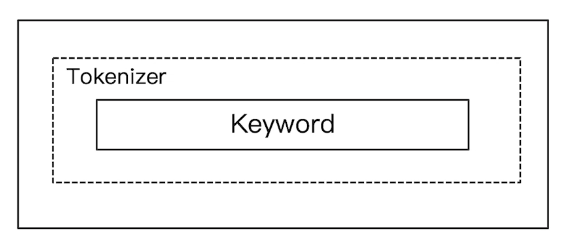
GET _analyze
{
"analyzer": "keyword",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
2
3
4
5
# 6)Pattern Analyzer
通过正则表达式进行分词,默认是 \W+,即按照非字符的符号进行分割。
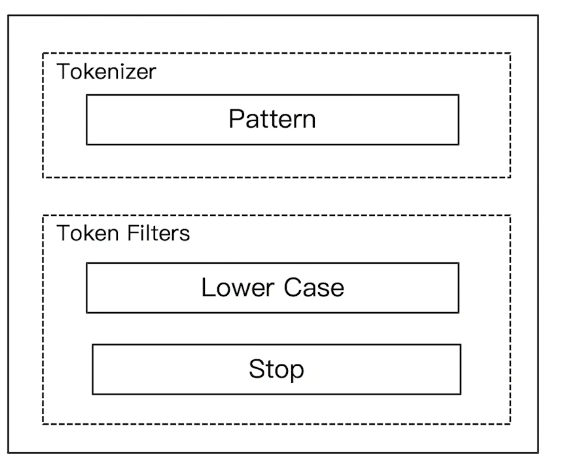
GET _analyze
{
"analyzer": "pattern",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
2
3
4
5
# 7)Language Analyzer

GET _analyze
{
"analyzer": "english",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
2
3
4
5
- 可以看到,经过这里的分词,
running被变成了run,foxes被变成了fox等,以及也停用了 in 等 term。
# 5.5 中文分词
中文分词也就是将中文句子切分成一个个的 term,而不是一个个字,但根据不同的上下文语境,一句中文的不同切分方法会有不同的理解。
这里需要用到 ICU Analyzer:
- 需要安装:
elasticsearch-plugin install analysis-icu - 它提供了 Unicode 的支持,更好的支持亚洲语言
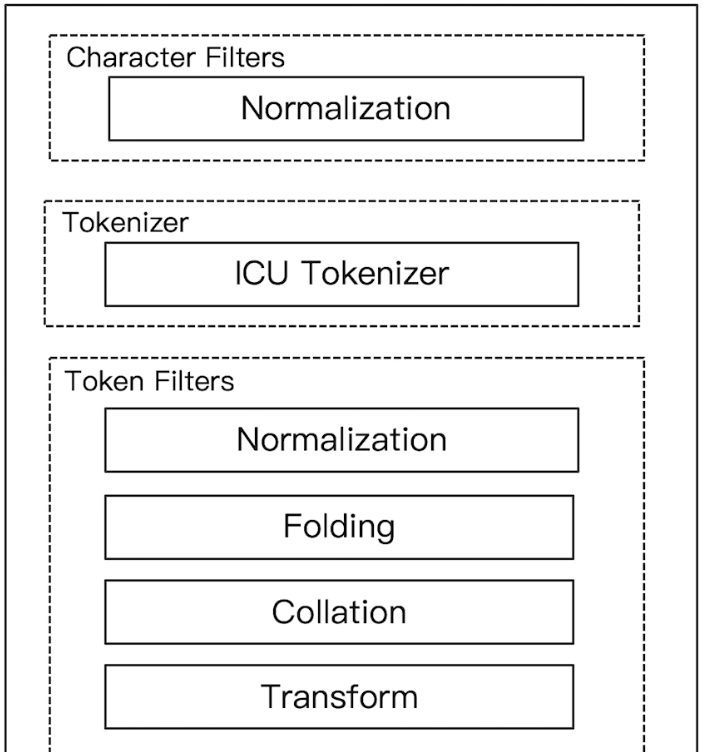
对比一下 ICU Analyzer 和 Standard Analyzer,standard 的会将中文切分成一个字一个字,但 icu_analyzer 则会有更好的表现:
GET _analyze
{
"analyzer": "standard",
"text": "他说的的确在理"
}
GET _analyze
{
"analyzer": "icu_analyzer",
"text": "他说的的确在理"
}
2
3
4
5
6
7
8
9
10
11
尽管如此,icu_analyzer 表现仍然不是很让人满意,社区中还有更多的中文分词器,他们的表现会更好:
- IK
- 支持自定义词库,支持热更新分词字典
- IK Github (opens new window)
- THULAC
- THU LexucalAnalyzer for Chinese,清华大学自然语言处理和社会人文计算实验室的一套中文分词器
- THULAC Github (opens new window)