 Search API
Search API
参考 Elasticsearch 核心技术与实战 | 极客时间 (opens new window)的 14~23 讲
# 1. Search API 概览
Elasticsearch 的 Search API 可以分成两大类:
- URI Search:在 URL 中使用查询参数
- Request Body Search:使用 ES 提供的、基于 JSON 格式的更加完备的 Query Domain Specific Language(DSL)
指定查询的 index 的方法:
| 语法 | 范围 |
|---|---|
/_search | 集群上的所有索引 |
/index1/_search | index1 |
/index1,index2/_search | index1 和 index2 |
/index*/_search | 以 index 开头的索引 |
# 1.1 URI 查询
- 使用“q”,指定查询字符串
- "query string syntax",KV 键值对

# 1.2 Request Body 查询

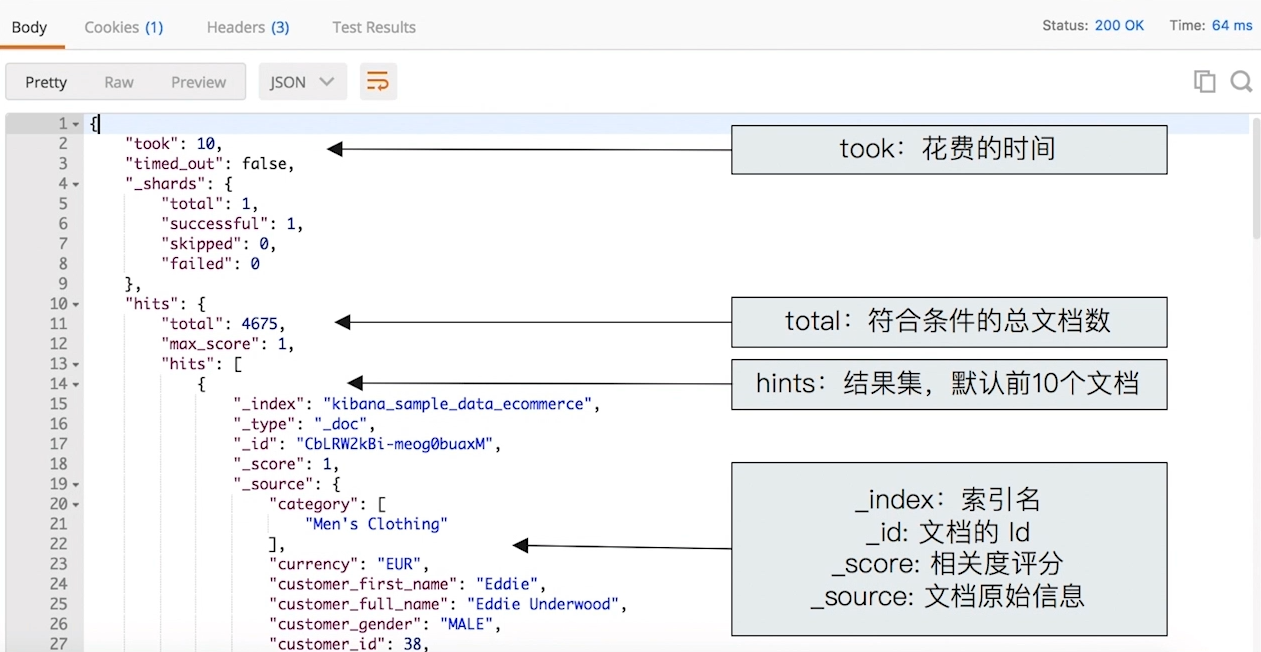
# 1.3 搜索的 Response
# 1.4 搜索的相关性(Relevance)
搜索是用户和搜索引擎的对话,用户关心的是搜索结果的相关性:
- 是否可以找到所有相关的内容
- 有多少不相关的内容被返回了
- 文档的打分是否合理
- 结合业务需求,平衡结果排名
但从搜索引擎的角度,比如百度搜索,可能还要考虑竞价排名的问题;比如电商搜索,可能还要履行提升销售业绩和去库存的职责。
计算机的一个研究方向 Information Retrieval(信息检索)对相关有一些指标进行评估:
- Precision(精准率):尽可能返回较少的无关文档
- Recall(召回率):尽量返回较多的相关文档
- Ranking:是否能够相关性进行排序?
Elasticsearch 提供了很多查询相关的参数来改善搜索的 Precision 和 Recall。
# 2. URI Search
URI Search —— 通过 URI query 实现搜索

# 2.1 Query String Syntax
# 2.1.1 指定字段 v.s. 泛查询
q=title:2012/q=2012
指定字段的查询:
GET /movies/_search?q=2012&df=title
{
"profile": "true"
}
// 或者
GET /movies/_search?q=title:2012
{
"profile": "true"
}
2
3
4
5
6
7
8
9
10
11
- 表示查询
title为 2012 的
泛查询:
GET /movies/_search?q=2012
{
"profile": "true"
}
2
3
4
# 2.1.2 Term v.s. Phrase
Term Query:Beautiful Mind 等效于 Beautiful OR Mind。如下例:
GET /movies/_search?q=title:Beautiful Mind
{
"profile": "true"
}
2
3
4
使用引号,作为 Phrase Query:"Beautiful Mind" 等效于 Beautiful AND Mind,而且要求前后顺序保持一致。如下例:
GET /movies/_search?q=title:"Beautiful Mind"
{
"profile": "true"
}
2
3
4
# 2.1.3 分组与引号
title:(Beautiful AND Mind):加上一个括号把查询条件括起来,变成了一个分组。因此做 Term Query 时最好加一个括号括起来,能够更明显。title="Beautiful Mind":加引号变成了 Phrase Query。
# 2.1.4 Boolean Query
前面看到了,当两个 term 在一起的时候,默认的是 OR 的关系。其他的关系也可以指定:
AND/OR/NOT或者&&/||/!- 必须大写
- 例如:
title:(matrix NOT reloaded)
# 2.1.5 加号和减号
在一个分组中,
+表示 must-表示 must_not
比如:title:(+matrix -reloaded)
在 URI Query 中,URL 中的
%2B就代表加号
# 2.1.6 范围查询
区间表示:[] 闭区间,{} 开区间。示例:
year:{2019 TO 2018]year:[* TO 2018]
# 2.1.7 算术符号
year:>2010year:(>2010 && <=2018)year:(+>2010 +<=2018)
# 2.1.8 通配符查询
通配符查询效率低,占用内存大,不建议使用。
? 代表 1 个字符,* 代表 0 或多个字符。示例:
title:mi?dtitle:be*
# 2.1.9 正则表达
- title:[bt]oy
# 2.1.10 模糊匹配与近似查询
- title:befutifi~1
- title:”lord rings”~2
# 3. Request Body 与 Query DSL 简介
Request Body Search 是指将查询语句以 Query DSL 的写法通过 HTTP Request Body 发送给 Elasticsearch。
# 3.1 分页
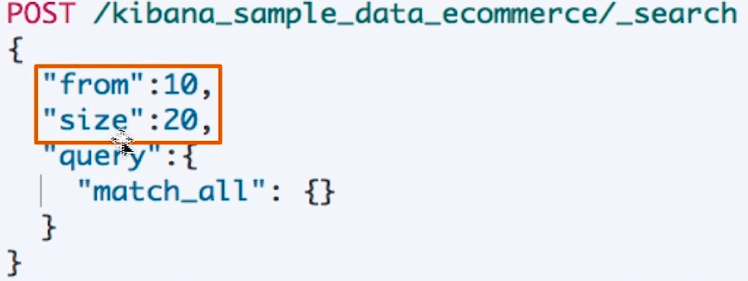
- From 从 0 开始,默认返回 10 个结果
- 获取靠后的翻页成本较高
# 3.2 排序
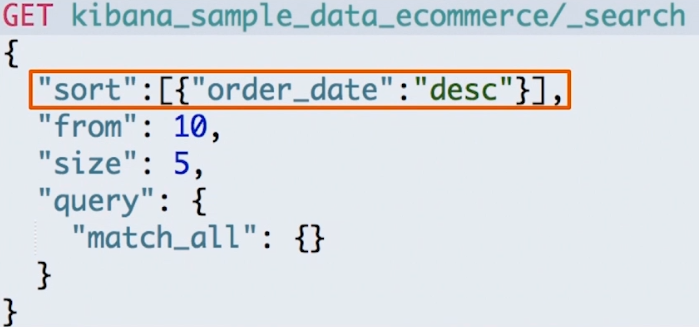
- 最好在“数字型”与“日期型”字段上排序。因为对于多值类型或分析过的字段排序,系统会选一个值,无法得知该值。
# 3.3 _source filtering
当我们只关心 doc 的某一些字段时,可以在 _source 中指定:
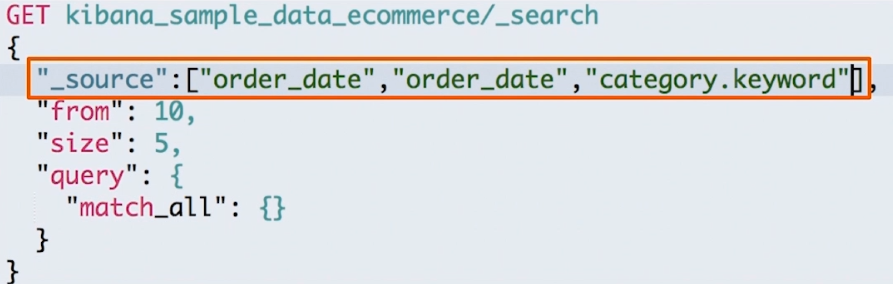
- 如果
_source中没有存储,那么就只返回匹配的文档的元数据 _source支持使用通配符,示例:"_source": ["name*", "desc*"]
# 3.4 脚本字段
可以在 Request Body 中加入 painless 来写一个脚本,从而得到脚本字段,可以在查询中计算一些值。
# 3.5 使用查询表达式 —— Match 与 Match Phrase
# 3.6 Query String 与 Simple Query String
# 3.6.1 Query String
类似 URI Query:

# 3.6.2 Simple Query String

- 类似 Query String,但是会忽略错误的语法同时只支持部分
- 查询语法不支持 AND OR NOT,会当作字符串处理
- Term 之间默认的关系是 OR,可以指定 Operator
- 支持 部分逻辑
+替代 AND|替代 OR-替代 NOT
# 4. Mapping
# 4.1 Dynamic Mapping 与常见字段类型
# 4.1.1 什么是 Mapping
- Mapping 类似数据库中的 schema 的定义,作用如下:
- 定义索引中的字段的名称
- 定义字段的数据类型,例如字符串,数字,布尔......
- 字段,倒排索引的相关配置,(Analyzed or Not Analyzed. Analyzer)
- Mapping 会把 JSON 文档映射成 Lucene 所需要的扁平格式
- 一个 Mapping 属于一个索引的 Type
- 每个文档都属于一个 Type
- 一个 Type 有一个 Mapping 定义
- 7.0 开始,不需要在 Mapping 定义中指定 type 信息
# 4.1.2 字段的数据类型
- 简单类型
- Text / Keyword
- Date
- Integer / Floating
- Boolean
- IPv4 & IPv6
- 复杂类型-对象和嵌套对象
- 对象类型/嵌套类型
- 特殊类型
- geo_point & geo_shape / percolator
# 4.1.3 什么是 Dynamic Mapping
- 在写入文档时候,如果索引不存在会自动创建索引
- Dynamic Mapping 的机制,使得我们无需手动定义Mappings。Elasticsearch 会自动根据文档信息,推算出字段的类型
- 但是有时候会推算的不对,例如地理位置信息
- 当类型如果设置不对时,会导致一些功能无法正常运行,例如 Range 查询
可以通过 GET <index-name>/_mappings 来查看某个 index 的 Mapping。
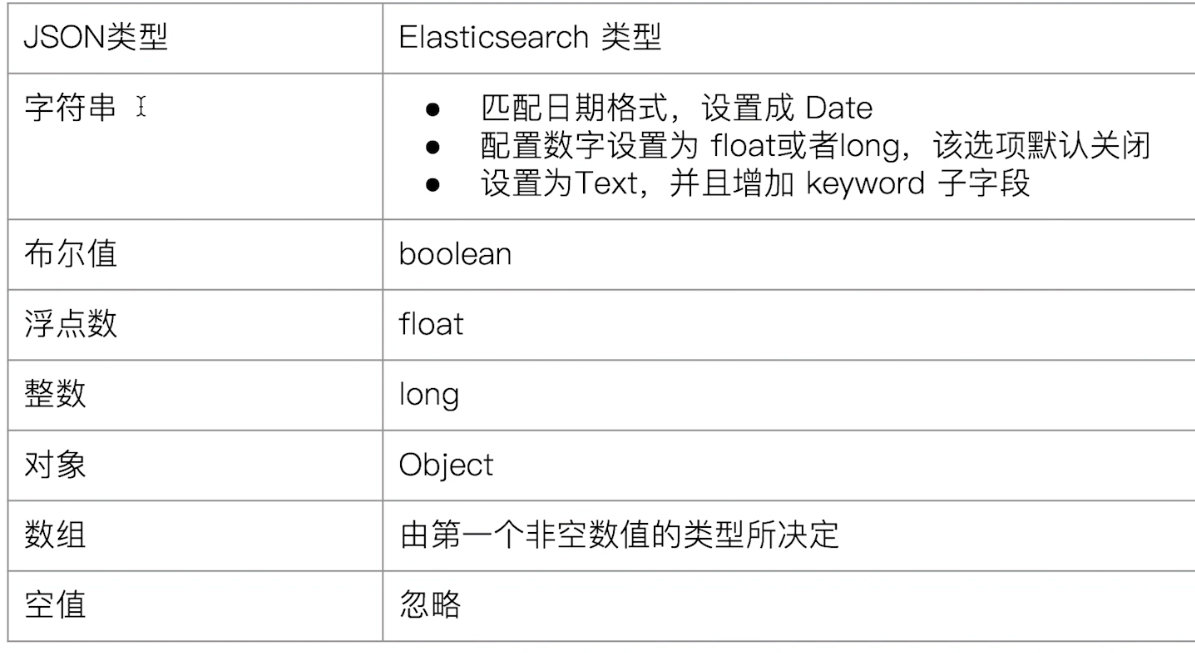
# 4.1.4 类型的自动识别
# 4.1.5 能够更改 Mapping 的字段类型
两种情况:
- 新增加字段
- Dynamic 设为 true 时,一旦有新增字段的文档写入,Mapping 也同时被更新
- Dynamic 设为 false,Mapping 不会被更新,新增字段的数据无法被索引但是信息会出现在
_source中 - Dynamic 设置成 Strict,文档写入失败
- 对已有字段,一旦已经有数据写入,就不再支持修改字段定义
- Lucene 实现的倒排索引,一旦生成后,就不允许修改如果希望改变字段类型,必须 Reindex API,重建索引
原因:如果修改了字段的数据类型,会导致已被索引的属于无法被搜索。但是如果是增加新的字段,就不会有这样的影响。
# 4.1.6 控制 Dynamic Mappings
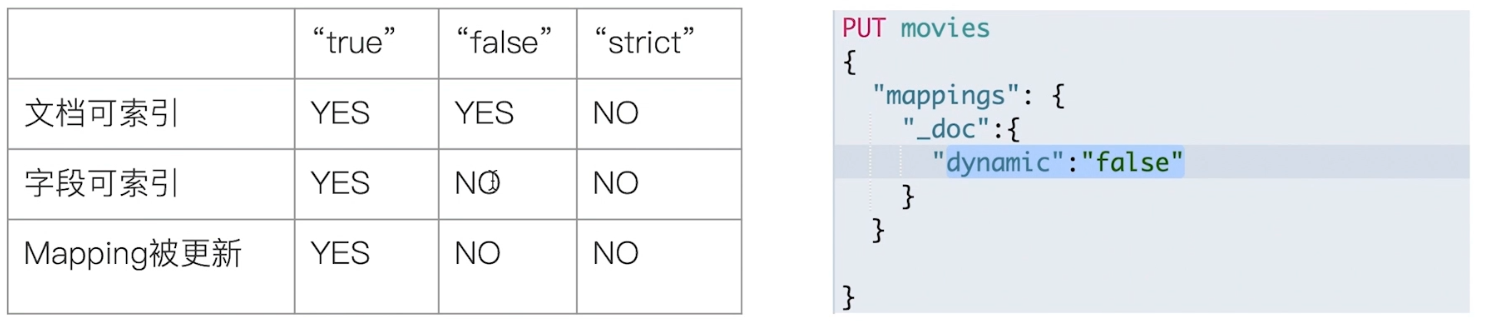
- 当 dynamic 被设置成 false 时候,存在新增字段的数据写入,该数据可以被索引,但是新增字段被丢弃
- 当设置成 Strict 模式时候,数据写入直接出错
# 4.2 显式 Mapping 设置
# 4.2.1 如何显式定义一个 Mapping

mappings 处定义的 Mapping 是一个 JSON 的格式。
# 4.2.2 自定义 Mapping 的一些建议
- 可以参考 API 手册,纯手写
- 为了减少输入的工作量,减少出错率,也可以依照以下步骤来完成:
- 创建一个临时的 index,写入一些样本数据
- 通过访问 Mapping API 获得该临时文件的 Dynamic Mapping 的定义
- 修改后用,使用该配置创建的索引
- 删除临时索引
# 4.2.3 控制当前字段是否被索引
参数 index:控制当前字段是否被索引。默认为 true。如果设置成 false,该字段不可被搜索。
示例:

# 4.2.4 Index Options
Elasticsearch 为索引设置了四种不同级别的设置,可以控制倒排索引记录的内容:
- docs - 记录 doc id
- freqs - 记录 doc id 和 term frequencies
- positions - 记录 doc id /term frequencies /term position
- offsets - doc id / term frequencies / term posistion / character offects
Text 类型默认记录 postions,其他默认为 docs。记录内容越多,占用存储空间越大。
# 4.2.5 null_value
用于实现我们支持对 NULL 值实现搜索。只有 Keyword 类型才支持设定 null_value。
比如我们要搜索:GET users/_search?q=mobile:NULL。其 Mapping 需要是:

# 4.2.6 copy_to
_all在 ES 7 中已经被 copy_to 所替代
它用于满足一些特定的搜搜需求,copy_to 将字段的数值拷贝到目标字段,且目标字段不出现在 _source 中。
示例:

- 上例中,查询是用的 fullName,但结果的
_source中却没有 fullName:
"hits" : [
{
"_index" : "users",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.5753642,
"_source" : {
"firstName" : "Ruan",
"lastName" : "Yiming"
}
}
]
2
3
4
5
6
7
8
9
10
11
12
# 4.2.7 数组类型
Elasticsearch 中不提供专门的数组类型。但是任何字段,都可以包含多个相同类型的数值。
Demo:
#数组类型
PUT users/_doc/1
{
"name":"onebird",
"interests":"reading"
}
PUT users/_doc/1
{
"name":"twobirds",
"interests":["reading","music"]
}
POST users/_search
{
"query": {
"match_all": {}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
搜索结果:

查看 Mapping(可以看到 interests 依然是一个 text 类型,而不是数组类型):

# 4.3 多字段特性
# 4.3.1 多字段特性
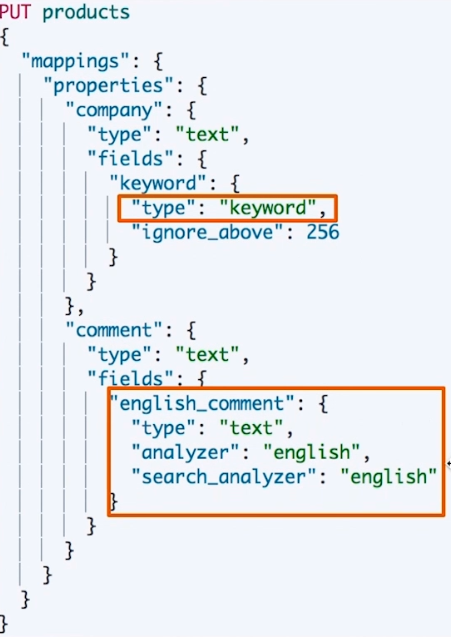
上例中,多字段特性的用处:
company字段实现精确匹配:增加一个 keyword 字段- 使用不同的 Analyzer,可以:
- 不同语言
- pinyin 字段的搜索
- 还支持为搜索和索引指定不同的 analyzer
# 4.3.2 Exact Values v.s. Full Text
- Excat Values:包括数字 / 日期 / 具体一个字符串(例如 “Apple Store”),这种不需要进一步分词
- Elasticsearch 中的 keyword
- Full Text:非结构化的文本数据
- Elasticsearch 中的 text
举例:
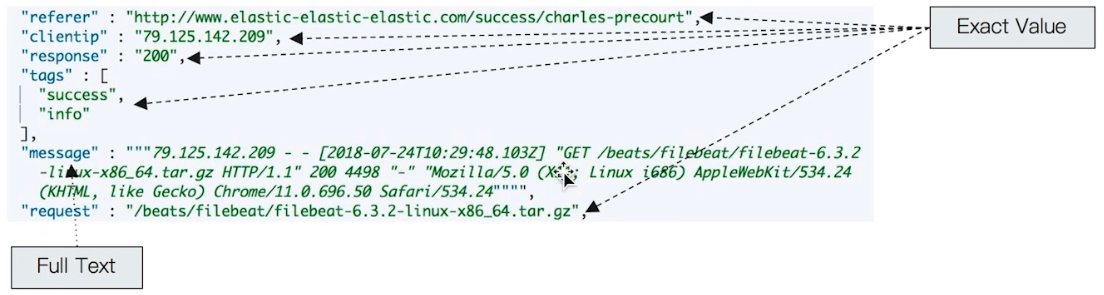
Elasticsearch 在做 Exact Value 的索引时,不需要做特殊的分词处理。
# 4.4 Mapping 中自定义 Analyzer
当 Elasticsearch 自带的分词器无法满足时,可以自定义分词器。通过自组合不同的组件实现自定义的分析器。
- Character Filter
- Tokenizer
- Token Filter
你可以通过在一个适合你的特定数据的设置之中组合字符过滤器、分词器、词汇单元过滤器来创建自定义的分析器。按这三种照顺序执行。
# 4.4.1 Character Filter
在 Tokenizer 之前对文本进行处理,例如增加删除及替换字符。可以配置多个 Character Filters。会影响 Tokenizer 的 position 和 offset 信息一些自带的 Character Filters。
一些自带的 Character Filters:
- HTML strip - 去除 html 标签
- Mapping - 字符串替换
- Pattern replace - 正则匹配替换
# 4.4.2 Tokenizer
将原始的文本按照一定的规则,切分为词(term or token)。
Elasticsearch 内置的 Tokenizers:whitespace | standard | uax_url_email | pattern | keyword | path hierarchy
也可以用 Java 开发插件,实现自己的 Tokenizer。
# 4.4.3 Token Filter
将 Tokenizer 输出的单词,进行增加、修改、删除。
自带的 Token Filters:
- Lowercase |stop| synonym(添加近义词)
# 4.4.4 示例
- 去掉 HTML:
POST _analyze
{
"tokenizer": "keyword", // 表示不做任何分词
"char_filter": ["html_strip"],
"text": "<b>hello world</b>"
}
2
3
4
5
6
运行的结果如下:

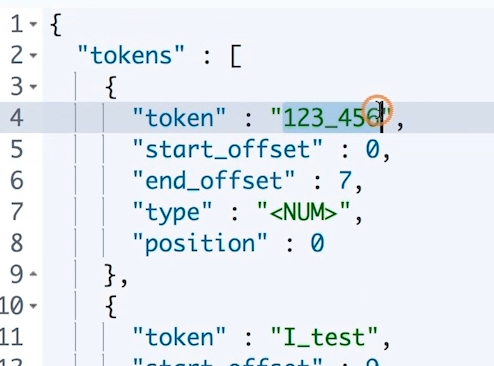
- 使用 char filter 实现将
-替换为_:

运行结果如下,可以看到,完成了替换:
# 4.5 Index Template 与 Dynamic Template
它们可以用于管理多个索引。集群上的索引会越来越多,例如,你会为日志每天创建个索引使用多个索引可以让你的更好的管理的你数据,提高性能。
# 4.5.1 Index Template
Index Templates:帮助你设定 Mappings 和 Settings,并按照一定的规则,自动匹配到新创建的索引之上。
- 模板仅在一个索引被新创建时,才会产生作用。修改模板不会影响已创建的索引。
- 可以设定多个索引模板,这些设置会被 merge 在一起。
- 可以指定 order 的数值,控制 merging 的过程
两个 Index Template 示例:

- 右边的mapping设置日期探测关闭,数字探测打开。
Index Template 的工作方式:
- 当一个索引被新创建时:
- 应用 Elasticsearch 默认的 settings 和 mappings
- 应用 order 数值低的 Index Template 中的设定
- 应用 order 高的 Index Template 中的设定,之前的设定会被覆盖
- 应用创建索引时,用户所指定的 Settings 和 Mappings,并覆盖之前模板中的设定
ES 中相关的 API:
// 查看 template 信息
GET /_template/template_default
GET /_template/temp*
2
3
# 4.5.2 Dynamic Template
Dynamic Template:根据 Elasticsearch 识别的数据类型,结合字段名称,来动态设定字段类型。
- 所有的字符串类型都设定成 Keyword,或者关闭 keyword 字段
- is 开头的字段都设置成 boolean
- long_ 开头的都设置成 long 类型
一个 Dynamic Template 长下面这个样子:

- Dynamic Template 是定义在某个索引的 Mapping 中
- Template 有个名字(比如上例的
full_name) - 匹配规则是个一个数组
- 为匹配到字段设置 Mapping
# 5. ES 的聚合分析简介
# 5.1 什么是聚合(Aggregation)
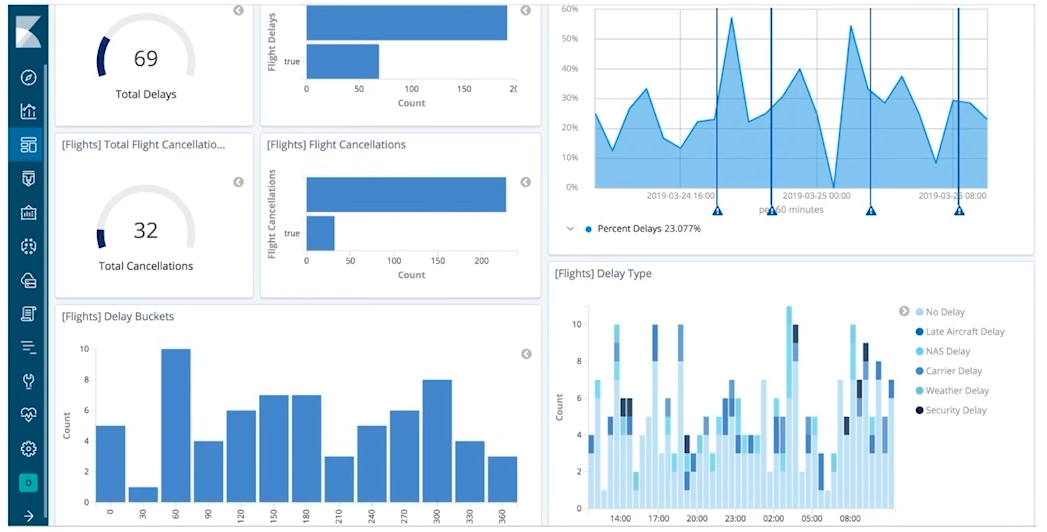
- Elasticsearch 除了搜索以外,还提供了针对 ES 数据进行统计分析的功能,而且实时性高。
- 通过聚合,我们会得到一个数据的概览,是分析和总结全套的数据
- 高性能,只需要一句话,就可以从 Elasticsearch 得到分析结果
Kibana 中的可视化报表就是通过 ES 的聚合分析来实现的:
# 5.2 聚合的分类
- Bucket Aggregation - 一些列满足特定条件的文档的集合
- Metric Aggregation - 一些数学运算,可以对文档字段进行统计分析
- Pipeline Aggregation - 对其他的聚合结果进行二次聚合
- Matrix Aggregation - 支持对多个字段的操作并提供一个结果矩阵
之后的课程还会继续深入分析。
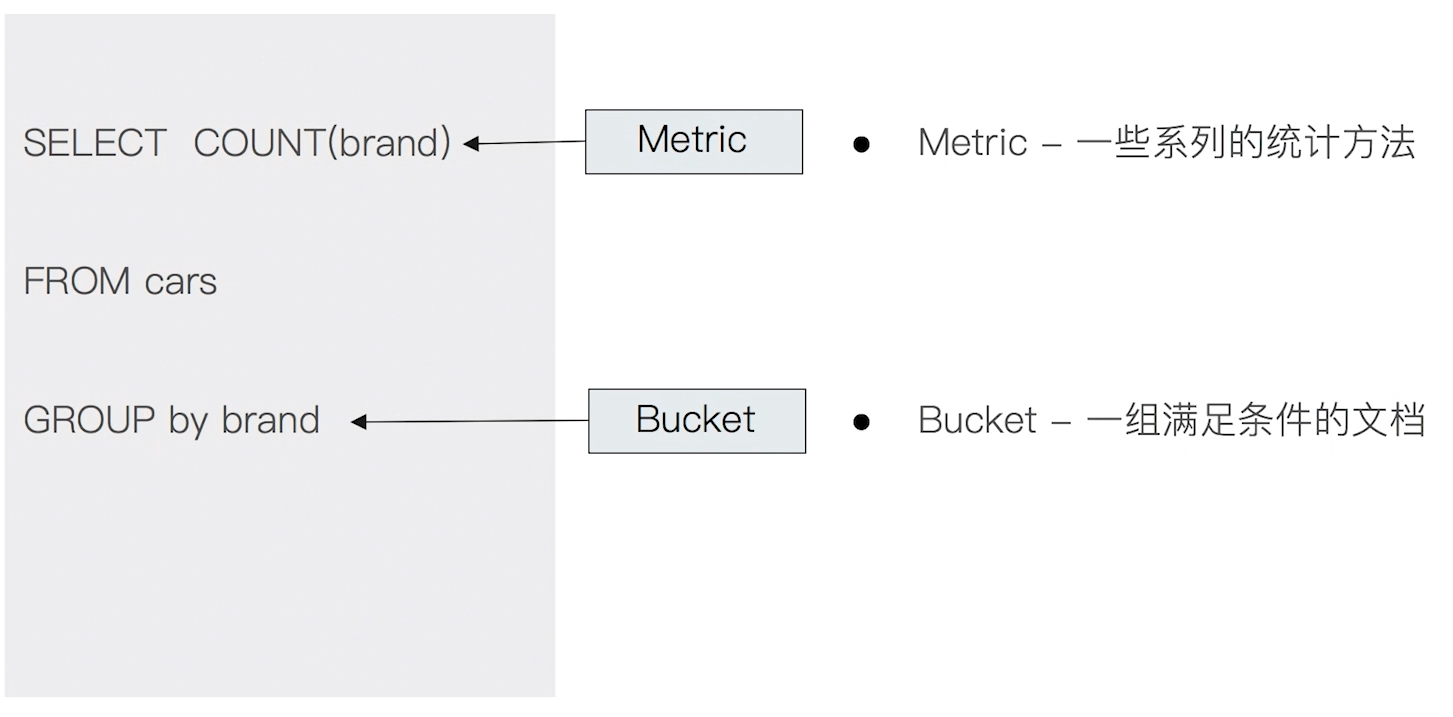
# 5.3 Bucket & Metric
- Metric:一些系统的统计方法(类似 count)
- Bucket:一组满足条件的文档(group by)
# 5.3.1 Bucket
Elasticsearch 提供了很多类型的 Bucket,用来帮助你用多种方式来划分文档,比如 Term & Range(时间 / 年龄区间 / 地理位置)。
下图是将一对文档划分成多个 Bucket 的示例:
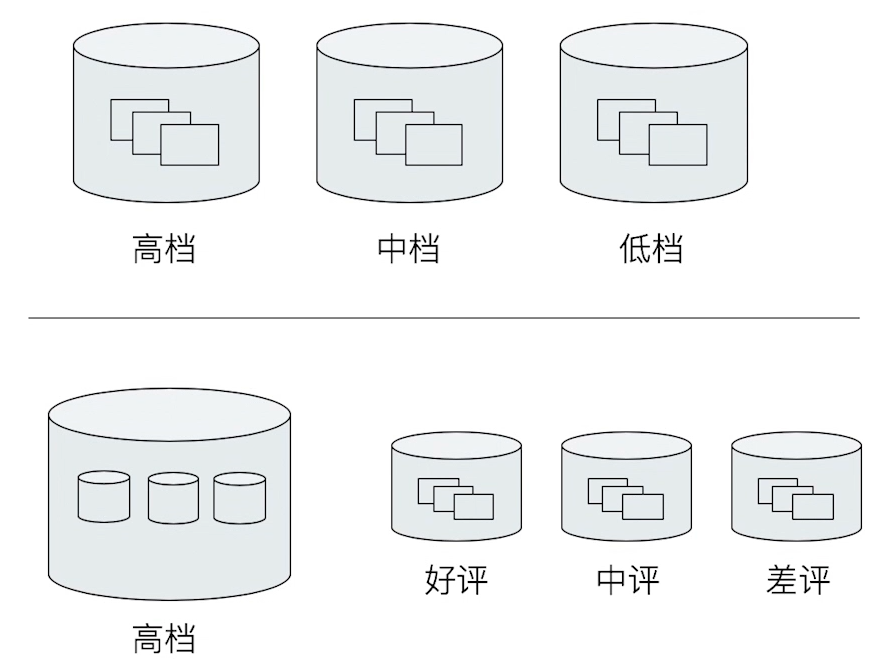
一个 Bucket 的例子:

# 5.3.2 Metric
Metric 会基于数据集计算结果,除了支持在字段上进行计算,同样也支持在脚本(painless script)产生的结果之上进行计算。
- 大多数 Metric 是数学计算,仅输出一个值
- min / max / sum / avg /cardinality
- 部分 metric 支持输出多个数值
- stats / percentiles / percentile_ranks
一个 Metric 的例子:
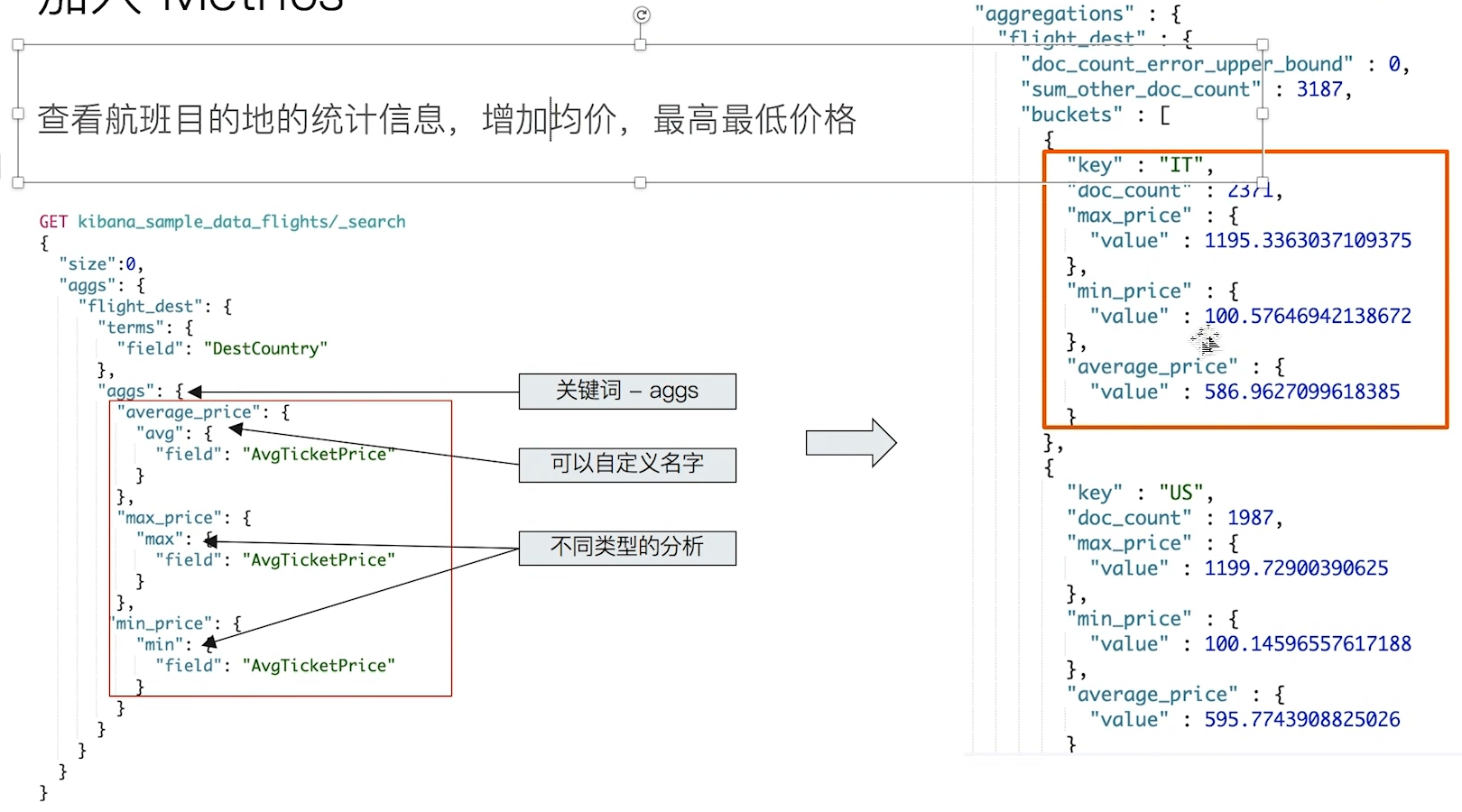
这种查询可以嵌套。