 知识图谱融合
知识图谱融合
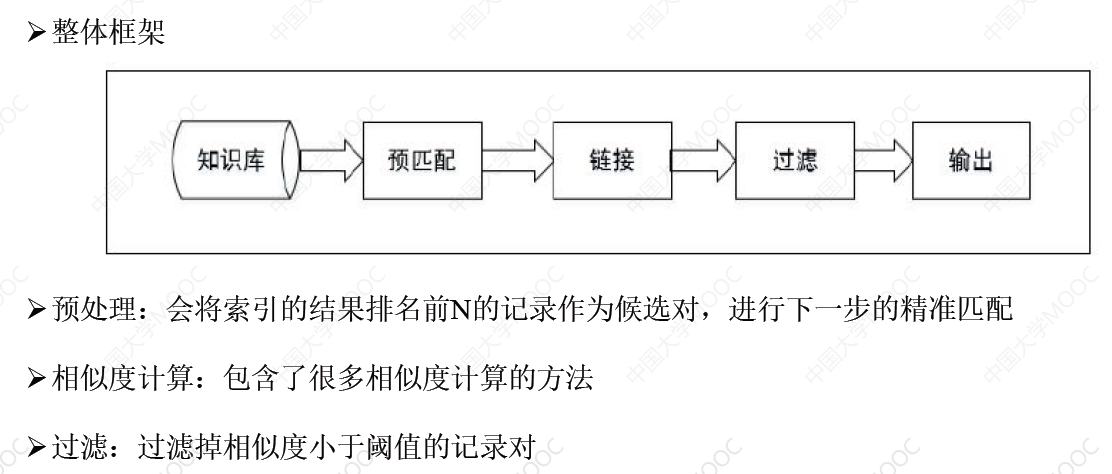
# 1. 知识图谱融合概述
# 1.1 知识图谱的异构性
从知识图谱构建的角度:
- 早期知识工程的理想是构建统一的知识库
- 人类知识体系复杂,使得难以这种统一知识库的本体难以构建出来
- 知识会随着时间演化
- 同一领域内不同组织也会构建不同的知识库
- 不同的知识库在语义和内容上有重叠和关联,但其中的表示语言和表示模型又具有差异,这便造成了本体的异构
从知识图谱应用的角度:
- 【本体层的异构问题】不同的系统采用的本体如果是异构的,那它们之间的信息交互便无法正常进行。因此解决本体异构、消除应用系统之间的互操作性障碍,是很多知识图谱面临的关键性问题之一
- 【实例层的异构问题】大量的实例也存在异构问题,比如同名实例可能指代不同的实体,而不同名的实例也可能指代相同的实体,大量的共指问题会给知识图谱的应用造成负面影响
知识融合是解决知识图谱异构问题的有效途径,它建立了异构本体和异构实例之间的联系,从而使异构知识图谱可以相互沟通,实现它们之间的互操作。知识融合的核心问题在于映射的生成。
为了解决知识融合,我们需要:
- 分析造成本体异构和实例层异构的原因,这是解决知识异构的基础
- 明确融合针对的具体对象、建立何种功能的映射,以及映射的复杂程度
以上对选择何种融合方法十分重要。
# 1.2 知识图谱异构的原因
# 1.2.1 语言异构
知识表示语言之间不匹配可能会造成的异构问题,这类语言层次上不匹配的情形分为:语法异构、逻辑异构、原语异构和表达异构四类:

# 1.2.2 模型异构
模型层面的异构与使用的知识表示语言无关,既可以发生在同一语言表达的本体之间,也可以发生在不同语言表达的本体之间。
这种异构可以分成概念化不匹配和解释不匹配:

# 1.3 知识图谱数据的特点
模型之间的异构问题的研究早在面向对象建模和数据库建模领域中就已经开展了,然而知识图谱同关系型数据库有着显著的区别:
- 优点:形式灵活,可扩展性好;包含丰富语义信息,可进行推理
- 缺点:缺乏有效的处理工具,大规模处理需要借助数据库技术;知识图谱不能代理数据库,两者各有所长
# 1.4 为什么需要知识融合
知识融合可以起到数据清洗和数据集成的作用。
- 数据清洗
- 构建的知识图谱存在异构性
- 知识融合是重要的预处理步骤之一
- 数据集成
- 不同知识图谱可能存在重叠的知识
- 融合多个不同来源的知识图谱
知识图谱可以由任意一个机构或个人自由构建,其背后的数据来源广泛,但质量参差不齐,知识融合就可以重用现有知识,并集成为一个统一、一致、简洁的形式,为使用不同形式的知识图谱的程序之间的交互建立互操作性。
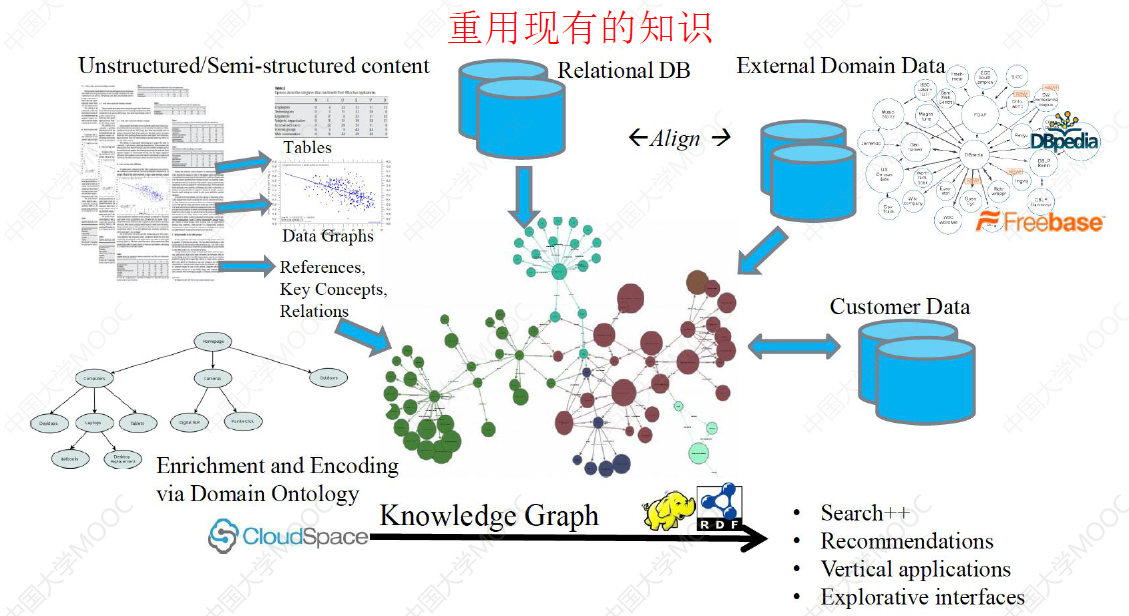
# 1.5 知识融合的目标
首要目标:合并多个知识图谱
总的来说,这些知识融合可以分成两个层次:
- 本体层匹配:等价类、子类;等价属性、子属性
- 实例层匹配:等价实例
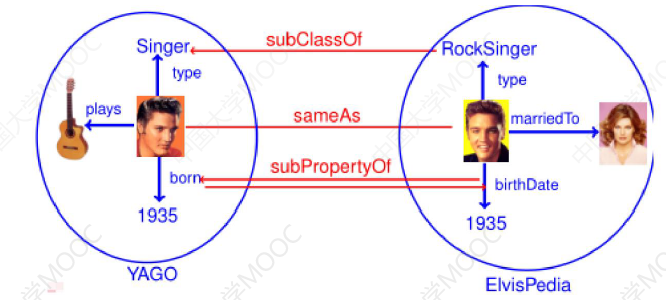
# 1.5.1 匹配异构本体
在本体层面,由于语言、数据结构等不同造成的差异,不同的知识库对相同的属性存在不同的称谓,知识融合需要寻找本体之间的映射规则,并消除本体异构,达到本体异构之间的互操作。
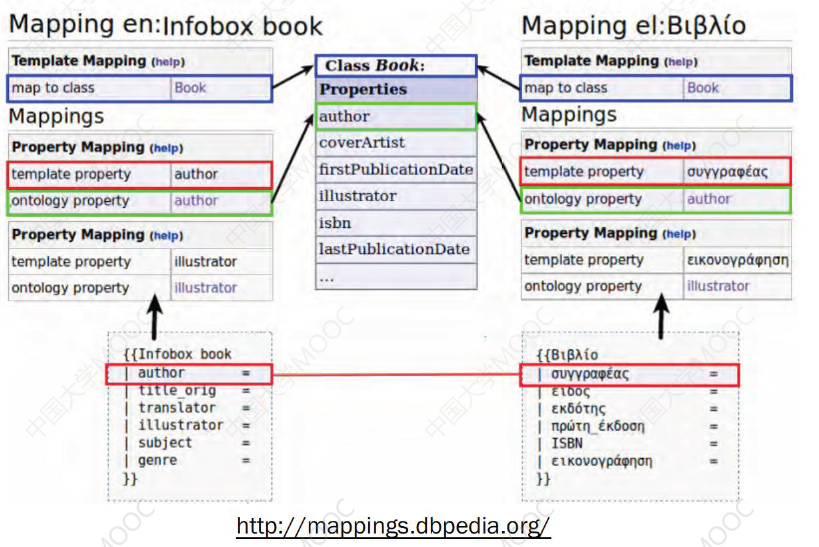
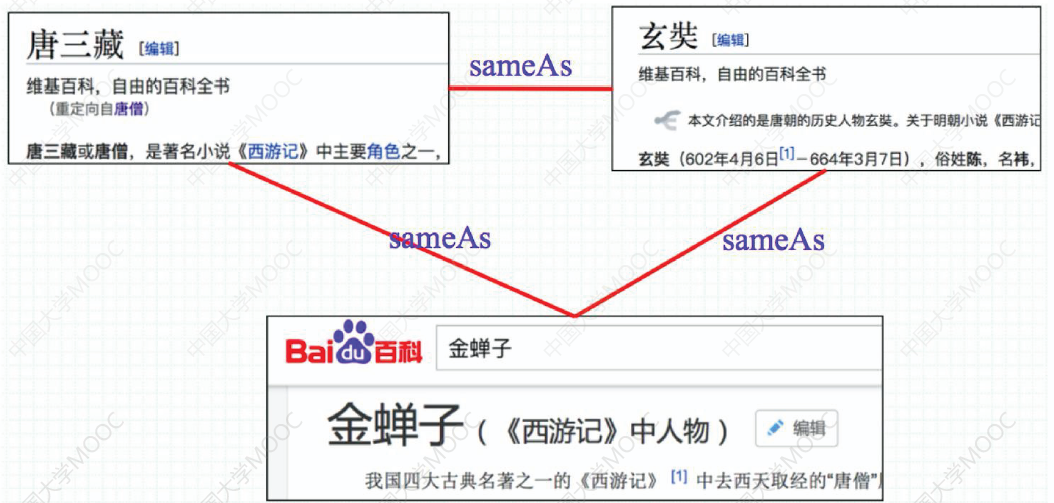
# 1.5.2 对齐异构实体
在实体层面,相同的实体可能存在别名、缩写等指代称谓,知识融合就需要对齐不同知识图谱中的相同实体:
# 1.6 知识融合方法
常见的知识融合方法有如下:
- 本体匹配(Ontology Matching):发现(模式层)等价或相似的类、属性或关系
- 又称为“本体对齐”、“本体映射”
- 实体对齐(Entity Alignment):发现指称真实世界相同对象的不同实例
- 又称“实体消解”、“实例匹配”
知识融合:即合并两个知识图谱,基本的问题都是研究怎样将来自多个来源的关于同一个实体或概念的描述信息融合起来。
小结
- 语言层面和模型层面的不匹配是导致知识图谱异构的本质原因
- 知识融合旨在将不同的知识图谱融合为统一、一致、简洁的形式,为使用不同知识图谱的应用程序之间的交互建立互操作性
# 2. 概念层融合——本体匹配
# 2.1 什么是本体
本体是领域知识规范的抽象和描述,是表达、共享、重用知识的方法,知识图谱可以看做是本体知识表示的一个大规模应用。
# 2.2 本体匹配的定义
本体匹配旨在发现源本体和目标本体之间映射单元的集合,具体而言,本体匹配发现一个三元组
- id 为映射单元的标识符,用于唯一标识该四元组
- c 和 c' 分别为 O 和 O' 中的概念
- s 表示 c 和 c' 之间的相似度,满足
根据技术的不同,本体匹配方法可以分为术语匹配方法和结构匹配方法。
# 2.3 基于字符串的术语匹配方法
术语匹配方法,从本体的术语出发,比较与本体成分相关的名称、标签或注释,寻找异构本体之间的相似性。术语匹配方法又可以分为基于字符串的方法和基于语言的方法。这一节介绍基于字符串的术语匹配方法。
基于字符串的方法:直接比较表示本体成分的术语的字符串结构
在进行严格的字符串比较之前,需要对字符串进行规范化,这或许能够提高字符串比较的结果。规范化的主要操作包括:
- 大小写:统一为大写字母或小写字母
- 消除变音符:Montréal -> Montreal
- 空白正规化:所有的空白字符(如空格、制表符和回车等)转换为单个的空格符
- 连接符正规化:正规化单词的换行连接符等
- 消除标点:在不考虑句子的情况下要去除标点符号
- 消除无用词:如 “to” 和 “a”
规范化字符串之后,需要对不同的字符串进行相似度度量:
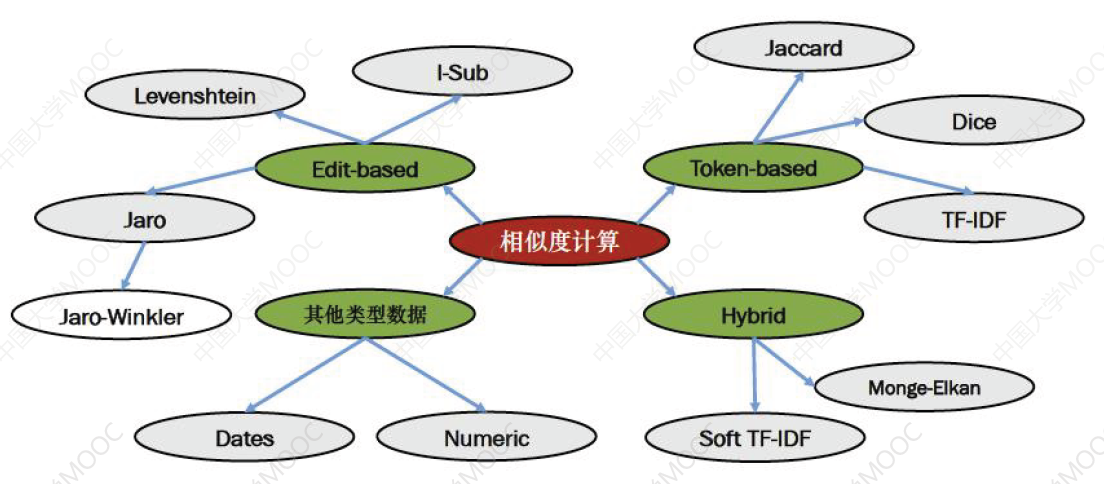
下面介绍一些字符串相似度计算方法。
🌠 Levenshtein 距离,即最小编辑距离,目的是用最少的编辑操作将一个字符串转换成另一个。举例如下:

- 上图中,将 Lvensshtain 转换为 Levenshtein 总共需要操作 3 次,编辑距离也就是 3
计算 Levenshtein Distance 是一个典型的动态规划问题。
🌠 汉明距离:它计算两个字符串中字符出现位置的不同。
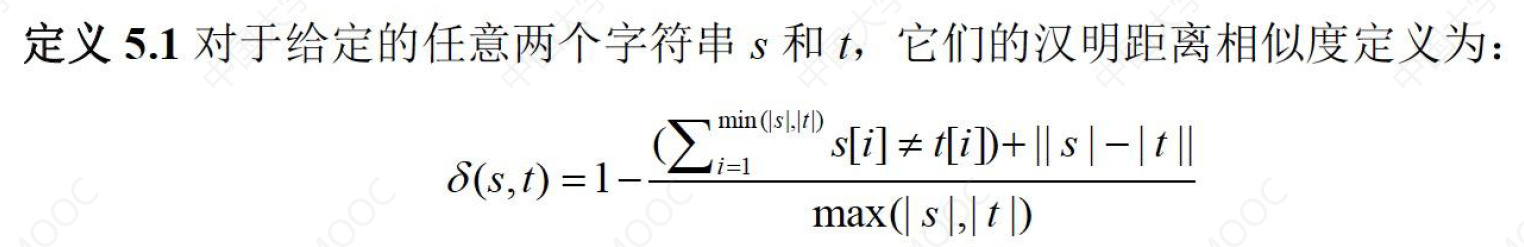
🌠 子串相似度:进一步精确度量两个字符串包含共同部分的比例
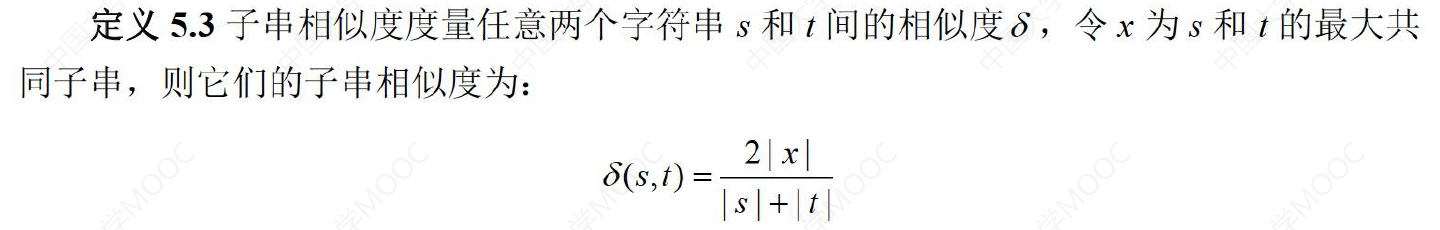
🌠 Dice 系数:用于度量两个集合的相似性,因为可以把字符串理解为一种集合,因此 Dice 距离也会用于度量字符串的相似性,Dice 系数定义如下:
- 以 Lvensshtain 和 Levenshtein 为例,两者的相似度为 2 * 9 / (11+11) = 0.82
🌠 Jaccard 系数:适合处理短文本的相似度,定义如下:
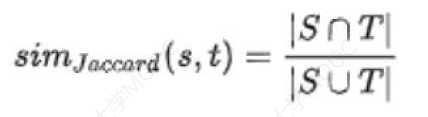
可以看出与 Dice 系数的定义比较相似。两种方法都将文本转换为集合,除了可以用符号分割单词外,还可以考虑用 n-gram 分割单词,用 n-gram 分割句子等来构建集合,计算相似度。
🌠 TF-IDF:主要用来评估某个字或者用某个词对一个文档的重要程度。具体计算方式可以参考 TF-IDF。
# 2.4 基于语言的术语匹配方法
基于语言的方法:依靠 NLP 技术寻找概念或关系之间的联系。
- 内部方法:使用语言的内部属性,如形态和语法特点, 寻找同一字符串的不同语言形态,如 Apple 与 Apples
- 外部方法:利用外部的资源,如词典等。 使用 WordNet 能判断两个术语是否有同义或上下义关系
# 2.5 术语匹配的原理
核心思想:将匹配的目标变为向量的形式,通过向量相似度实现匹配
- 本体中的概念和属性往往含有大量的文本信息
- 将待匹配的对象的相关文本组成成文档的形式,再转换为文档向量
# 2.6 基于虚拟文档的术语匹配方法
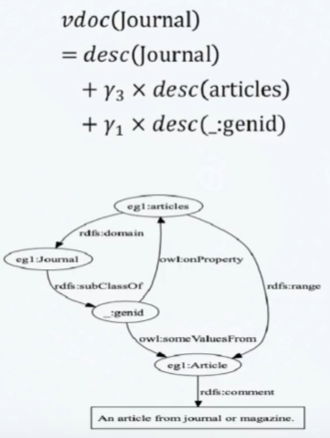
构建的虚拟文档包含如下部分:
- 概念的语言学描述:本地名、标签、注释
- 匿名结点的语言学描述:前向邻居的语言学描述
- 概念的邻居:主语邻居、谓语邻居、宾语邻居
- 概念的虚拟文档:自身 + 邻居结点
构建虚拟文档后,便可以通过计算语义描述文档相似度来寻找异构本体元素间的映射,两文档的语义文档描述相似度越高,它们相匹配的可能性越大。
Constructing virtual documents for ontology matching. (WWW2006)
# 2.7 结构匹配的原理
在寻找映射的过程中,同时考虑本体和结构,能够弥补只进行术语匹配的不足,提高映射结果的精度。
核心思想:利用本体的结构信息来弥补文本信息量不足的情况
- 本体中的概念和属性往往有大量相关的其他概念和属性,组成了一种图结构
- 结构匹配器往往不采用图匹配技术,后者代价高昂且效果不理想
结构匹配器可以分成如下两种:
- 间接的结构匹配器:在术语匹配器中考虑结构信息,如邻居、上下文、属性等
- 直接的结构匹配器:直接采用图匹配算法
- 图匹配复杂度高,无法直接使用
- 一般基于相似度传播模型的变体很有效
# 2.8 经典的结构匹配算法:Anchor-PROMPT
The PROMPT plug-in allows you to compare, map, move, merge and extract multiple ontologies in Protege.
Anchor-PROMPT 的目标就是在术语比较的基础上,利用本体结构进一步判断和发现可能相似的本体成分。它的输入是一个相关术语的集合,其中每对术语分别来自两个不同本体,这样的“术语对”称为 anchor,术语对可以利用 Anchor-PROMPT 中的术语比较算法自动生成,也可以由用户提供。Anchor-PROMPT 的目标是根据所提供的初始术语对的集合,进一步分析异构本体的结构,产生新的语义相关的术语对。
Anchor-PROMPT 将每个本体 O 视为一个带边的有向图 G,O 中的每个概念 c 表示图 G 中的节点,每个关系 s 是连接相关概念 A 和 B 之间的边,图中通过边来连接两个相关节点,成为相邻节点。如果从节点 A 出发,经过一系列的边都能到达节点 B,那么 A 和 B 之间就存在一条路径,路径的长度就是边的数目。
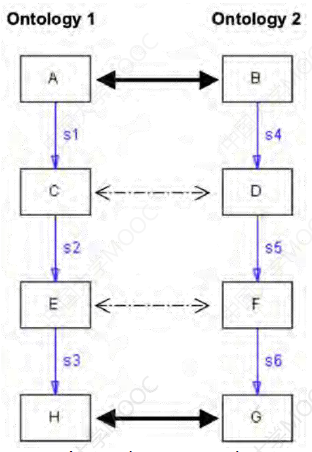
Anchor-PROMPT 基于这样的一个直觉:如果两对术语相似且有连接它们的路径,那么路径中的元素也通常相似:
- 生成一组长度小于 L 的路径来连接两个本体中的 anchor
- 生成一组长度相等的路径对
- 对于路径对中相同位置的节点,增加它们的相似度得分
因此通过最初给定的相关术语的小集合,Anchor-PROMPT 能够产生本体间大量的可能语义相似的术语对。
Anchor-PROMPT: Using non-local context for semantic matching. (IJCAI 2001)
# 2.9 大型本体匹配
传统的匹配方法往往仅适用于小型本体,复杂度为
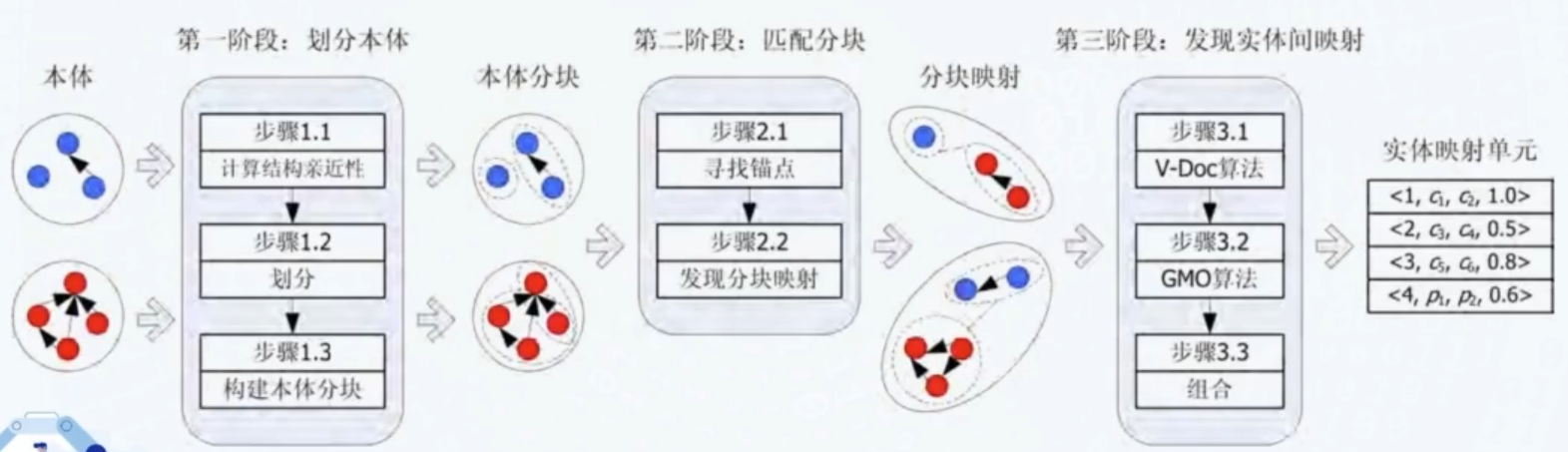
Matching large ontologies: A divide-and-conquer approach. (DKE2008)
为什么要分块:
- 记录进行一一链接的时间复杂度为
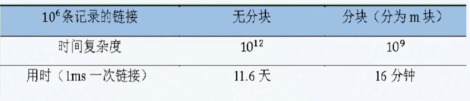
可以看出,分块能够显著提高效率。
分块的方法有如下:
- 基于 Hash 函数:对于记录 x 有
- 临近分块:排序邻居法、Canopy 聚类、红黑集覆盖法
小结
- 本体匹配侧重发现模式层等价或相似的类、属性和关系,目前已有基于术语匹配和结构匹配等方法
- 大规模本体匹配通常采用先分块后匹配的方式
# 3. 实例层的融合 —— 实体对齐
实体对齐(Entity Alignment,EA)侧重发现指称真实世界相同对象的不同实例。
在实际应用中,由于知识图谱的实体规模通常较大,因此针对实例层的匹配成为近年来知识融合所面临的主要任务。
实体对齐的方法可以分成如下两大类:
- 传统方法:等价关系推理、相似度计算
- 基于表示学习的方法:Embedding-based
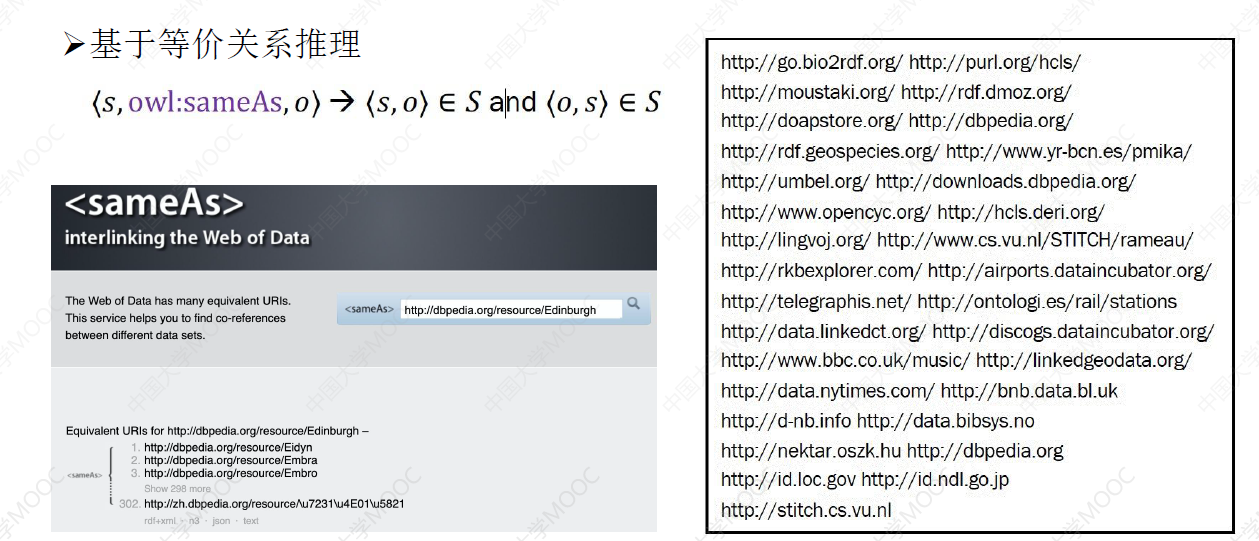
# 3.1 EA 方法:等价关系推理
等价关系声明了概念之间或关系之间的对应。等价成分可以在互操作过程中相互替代
# 3.2 EA 方法:相似度计算
计算特征:
- 实体标签信息,如实体名、昵称、别名等(效果不理想,因为可能跨语言)
- 人工定义特征:公共邻居、词向量、类别等
得到实体特征后,可以计算向量相似度:编辑距离、汉明距离等
# 3.3 EA 方法:Embedding-based
核心思想:基于表示学习技术,将 KG 中的 entity 和 relation 都映射到 low-dimensional vector space,然后直接用数学表达式计算实体间相似度。

- 在上图这个例子中,我们就可以发现,“义勇军进行曲”和“中国国歌”的 embedding 很相近,因此可以将他们称之为等价实体,从而进行实体对齐。
下面介绍两种 Embedding-based 的方法。
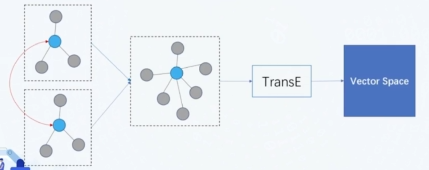
# 3.3.1 合并成一个 KG 并进行 KRL
合并预先匹配好的实体,将两个 KG 合并成一个 KG,用单一 KG 来做 KRL:
一种做法是在 TransE 基础上增加了一个实体对齐损失,并采用线性转换矩阵的方式来实现实体对齐:
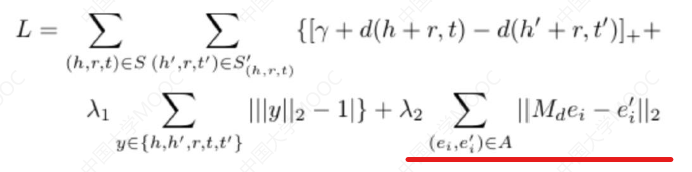
A Joint Embedding Method for Entity Alignment of Knowledge Bases
# 3.3.2 两个 KG 分别进行 KRL
两个 KG 先分别进行 KRL,得到两个 vector space,然后用一些预先匹配好的实体训练一个线性变换对齐两个向量空间:
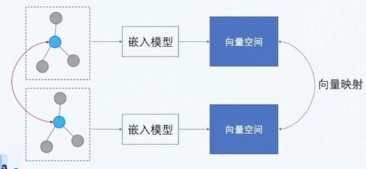
这一思路的典型方法是 MTransE,它也使用 TransE 进行表示学习,并通过线性变化对齐 vector space。
Multilingual Knowledge Graph Embeddings for Cross-lingual Knowledge Alignment. (IJCAI2017)
除了直接对齐 vector 之外,也有学者提出基于迭代训练的实体对齐方法:YTransE。它在两个异质知识图谱之间,根据少量种子对齐实体,然后通过不断迭代的方法实现大量实体对齐。这种方法分别学习两个 KG 的表示,建立两者的映射关系,并合并等价实体。
Iterative entity alignment via joint knowledge embeddings. (IJCAI2017)
# 4. 知识融合工具
# 4.1 Silk
Silk (opens new window) 是一个基于 Python 开发的集成异构数据源的开源框架。其框架如下:
# 4.2 OpenEA
OpenEA (opens new window) 是一个开源的基于 TensorFlow 的实体对齐框架,包含了各种主流的前沿算法。
# 4.3 EAKit
EAKit (opens new window) 是一个轻量级基于 PyTorch 的实体对齐框架。用户可以方便地基于 EAKit 实现自定义的模块开发。
小结
- 知识融合历经了蓬勃发展,如何将表示学习技术运用于实体对齐过程成为新的热点。
- 目前缺乏专门针对实体对齐的表示学习模型,导致现有基于表示学习的实体对齐方法精度不高。
- 人机协作可以有效提高实体对齐的效果,目前已经得到较多关注。
# 5. 知识融合的前沿技术
# 5.1 无监督对齐
对齐问题的设定是有一些预先匹配好的实体,但是这种设定有时无法满足,因此有不少研究者在探索如何无监督地进行实体对齐。
Entity Alignment between Knowledge Graphs Using Attribute Embeddings. (AAAI 2019)
- 谓词对齐:使用统一的命名方案重新命名两个 KG 的谓词(如 bornIn 和 wasBornIn),为关系嵌入提供统一的向量空间,从而合并两个 KG。
- 嵌入学习:
- 结构嵌入:通过关系三元组学习得到
- 属性字符嵌入:通过属性三元组学习得到
- 结构嵌入和属性特征嵌入的联合学习
- 实体对齐:对 embedding 计算相似度,超过一定阈值的为对齐实体。
# 5.2 多视图对齐
Multi-view Knowledge Graph Embedding for Entity Alignment. (IJCAI2019)
KG 中的实体具有各种特性,但是当前 embedding-based 的方法只利用了其中一种或两种特性。由于对齐问题的复杂性,单一模型的嵌入能力往往不足以对齐两个网络,因此从多视角来对齐效果会更好。
多视图对齐模型的基本思想是将知识图谱中的不同特性划分为不同的子集,也称为视图,之后从特定的视图学习实体嵌入,用联合优化提高对齐性能。
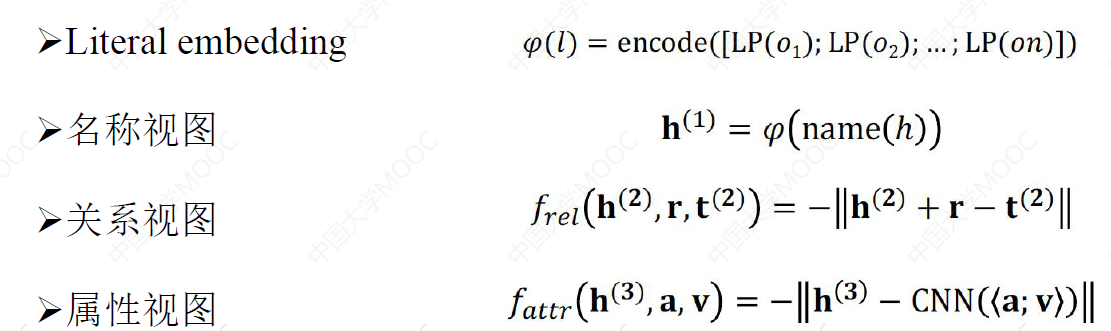
为了实现多视图实体对齐,多视图对齐模型可以采用平均不同视图嵌入的方式,导出一个从每个视图嵌入空间到共享空间的正交映射矩阵,参与多视图嵌入的联合训练,从而使多视图彼此受益。
多视图对齐本质是一种重复利用数据的方式,表示学习并没有发生本质改变。
# 5.3 嵌入表示增强
Semi-Supervised Entity Alignment via Knowledge Graph Embedding with Awareness of Degree Difference. (WWW268019)
这类模型改进了现有的嵌入表示模型,并将改进后的用于实体对齐。
现有的嵌入模型会让度(节点的邻居个数)相似的节点更接近,但这对对齐任务来说并不是一件好的事情,因此有学者提出用对抗训练的方式来解决这一问题:
- 判别器的目标是预测节点的度,生成器的目标是让判别器无法预测节点的度。这样,最后的嵌入表示会削弱度的影响。
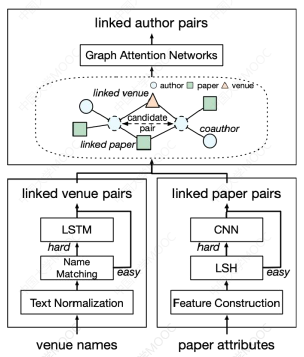
# 5.4 超大规模实体对齐
OAG: Toward Linking Large-scale Heterogeneous Entity Graphs. (KDD2019)
大多数现有的实体对齐工作都是在几十万个实体,至多几百万个实体的数据集上进行测试,然而在上亿网络的节点对齐时,无论从计算的复杂度,还是对齐的效果上,都会有一些新的问题产生:实体异构、实体歧义、大规模匹配。
学者们设计了一个统一的框架来解决以上挑战:OAG。它包括三个不同的匹配模块来匹配不同类型的实体:出版地点、论文和作者。在每种模块中,针对每种类型的实体的匹配难点,设计了不同的算法:
- 出版地点匹配:LSTM
- 论文匹配:局部敏感哈希、CNN
- 作者匹配:异构图注意力网络
小结
知识融合的未来展望:
- 多模态知识融合:不同模态的数据如图片、视频也存在大量的结构化知识,多模态知识融合是可以进一步赋能更多的应用。
- 公平高效的知识表示:实体对齐不同于知识图谱补全任务,亟需从本质上设计其特有的知识表示学习模型。
- 大规模知识融合:真实世界的知识图谱存在数十百亿乃至千亿实体,亟需高效的大规模知识融合算法。