 内存结构
内存结构
# 1. 程序计数器
Program Counter Register 程序计数器
- 作用:记住下一条 JVM 指令的执行地址
- 在物理上,是通过寄存器来实现的
- 特点:
- 是线程私有的:每个线程都有自己的程序计数器,因为每个线程都有自己的一套字节码,不同线程会通过时间片来交替运行,交替过程中需要使用程序计数器来记录下当前程序运行到哪了。
- 不会存在内存溢出:像其他的堆、栈等都可能出现内存溢出
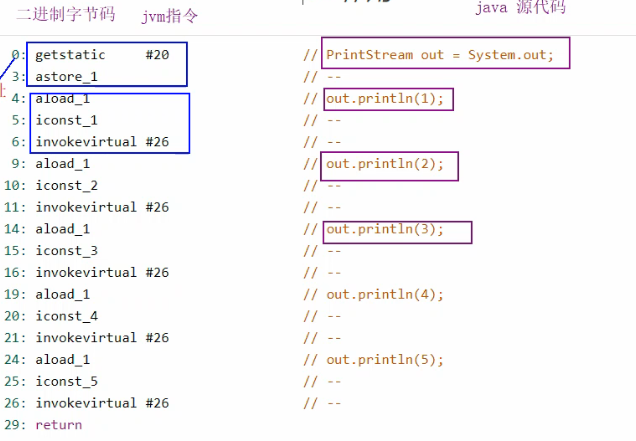
字节码和 JVM 指令如下图所示:
# 2. 虚拟机栈
# 2.1 定义
栈 —— 线程运行需要的内存空间。由多个栈帧组成,栈帧是每个方法运行时需要的内存。如下图所示:
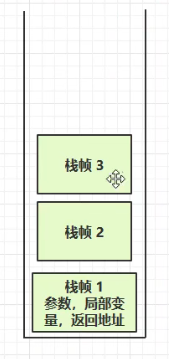
每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法。
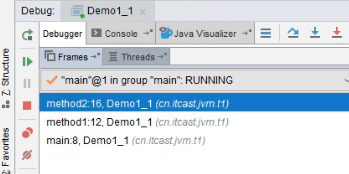
当你在 IDEA 中调试 debug Java 程序时,就会看到多个 frames,他们就是这里的栈帧:
问题辨析
- 垃圾回收是否涉及栈内存?
不。垃圾回收只会回收堆中的内存。
- 栈内存分配越大越好吗?
Java 启动时可以通过 -Xss 来设置栈内存。由于物理内存是一定的,当把栈内存分配太大时,会让线程数变少。
- 方法内的局部变量是否线程安全?
局部变量是存在于栈帧中,每个线程会有一个栈,因此这个局部变量也是线程私有的,不同线程之间不会互相干扰。但 static 是多个线程共享的,多线程下必须对其进行保护:

判断一个变量是否线程安全,不仅要看这个变量是否为局部变量,还看这个变量是否逃离了方法的作用范围。比如你 return 一个局部变量创建的对象后,那这个对象就有可能被别的线程在调用方法后拿到。
因此可以总结:
- 如果方法内局部变量没有逃离方法的作用访问,它是线程安全的。
- 如果是局部变量引用了对象,并逃离方法的作用范围,需要考虑线程安全
# 2.2 栈内存溢出
往往是两个原因:
- 栈帧过多导致栈内存溢出
- 栈帧过大导致栈内存溢出
从而出现 StackOverflowError 的异常。
# 2.3 线程运行诊断
# 2.3.1 案例一:CPU 占用过多
定位过程:
- 用 top 命令定位哪个进程对 CPU 的占用过高
ps H -eo pid,tid,%cpu | grep 进程id(用 ps 命令进一步定位是哪个线程引起的 cpu 占用过高)- 使用
jstack 进程id可以根据线程 id(nid)找到有问题的线程id,进一步定位到问题代码的源码行号
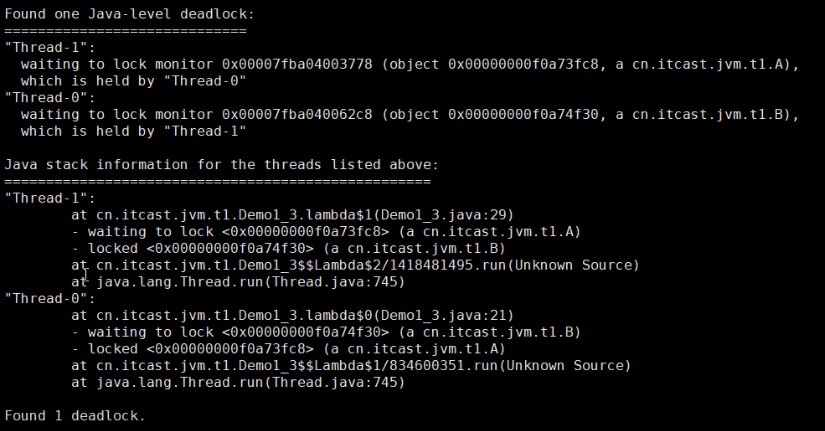
# 2.3.1 案例二:程序运行很长时间没有结果
使用 jstack 可以检测到死锁现象:
# 3. 本地方法栈
Native Method 是指不使用 Java 而编写的代码,比如有时为了与底层 OS 打交道,而需要调用 C 的代码等。这些 native method 运行时所使用的内存就是本地方法栈。
Java 标准库中 Object.hashCode、Object.clone 等方法都是用 C/C++ 编写的,而 Java 是通过本地方法接口来调用这些方法。
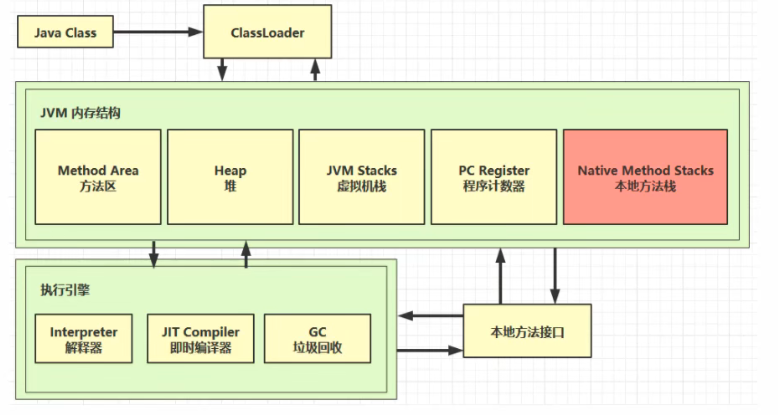
# 4. 堆
刚刚讲的部分都是线程私有的,而现在要讲的堆和后面要讲的方法区都是线程共享的。
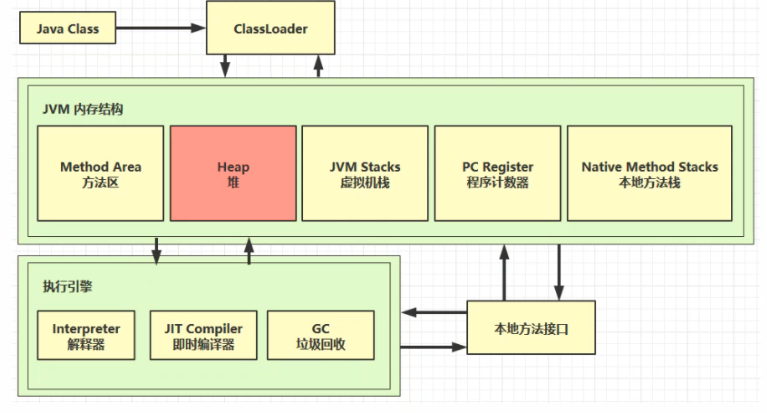
# 4.1 定义
Heap:通过 new 关键字,创建对象都会使用堆内存
特点:
- 它是线程共享的,堆中对象都需要考虑线程安全的问题
- 有垃圾回收机制
# 4.2 堆内存溢出
如果不断创建大量对象,而且这些对象还被使用,那就可能产生堆内存溢出错误:OutOfMemoryError。
JVM 参数 -Xmx 可以控制最多可以使用的堆空间。
# 4.3 堆内存诊断
# 4.3.1 jps 工具
查看当前系统中有哪些 java 进程
# 4.3.2 jmap 工具
查看堆内存占用情况:jmap -heap 进程id
# 4.3.3 jconsole 工具
图形界面的,多功能的监测工具,可以连续监测。这个工具很直观。
# 4.3.4 jvirsualvm 工具 ⭐️
监视更加直观。
- 其中“堆 dump”(堆转储)工具可以抓取堆内存的快照,并对其中的对象进行分析
# 5. 方法区
# 5.1 定义
Oracle 中 JVM 规范对方法区的定义如下:
The Java Virtual Machine has a method area that is shared among all Java Virtual Machine threads. The method area is analogous to the storage area for compiled code of a conventional language or analogous to the "text" segment in an operating system process. It stores per-class structures such as the run-time constant pool, field and method data, and the code for methods and constructors, including the special methods (§2.9 (opens new window)) used in class and instance initialization and interface initialization.
The method area is created on virtual machine start-up. Although the method area is logically part of the heap, simple implementations may choose not to either garbage collect or compact it. This specification does not mandate the location of the method area or the policies used to manage compiled code. The method area may be of a fixed size or may be expanded as required by the computation and may be contracted if a larger method area becomes unnecessary. The memory for the method area does not need to be contiguous.
A Java Virtual Machine implementation may provide the programmer or the user control over the initial size of the method area, as well as, in the case of a varying-size method area, control over the maximum and minimum method area size.
The following exceptional condition is associated with the method area:
- If memory in the method area cannot be made available to satisfy an allocation request, the Java Virtual Machine throws an
OutOfMemoryError.
# 5.2 组成
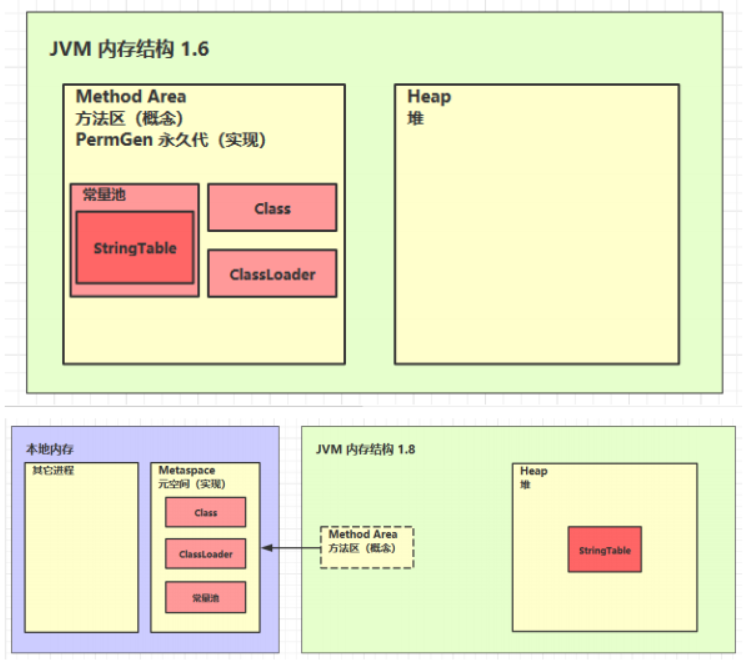
Method Area 只是一个概念,具体实现是取决于 JVM,在 1.6 中,PermGen(永久代)是 Method Area 的实现。
在 JVM 1.8 中,永久代被废弃,Method Area 被使用 Metaspace 来实现。Metaspace 不再占用堆内存,不再由 JVM 管理内存,而是被移到本地内存中了。
# 5.3 内存溢出
- 1.8 以前会导致永久代内存溢出(OutOfMemoryError)
- JVM 参数
-XX:MaxPermSize可设置
- JVM 参数
- 1.8 之后会导致元空间内存溢出(OutOfMemoryError)
- 由于 metaspace 放在了本地内存中,因此一般不会溢出
- JVM 参数
-XX:MaxMetaspaceSize可设置
# 5.4 运行时常量池
常量池 就是一个符号表,为字节码提供常量符号(类名、方法名、字面量等),字节码只需提供一个符号表的编号(比如 #1),解析时可以通过查表来得到常量符号。
运行时常量池:常量池是 *.class 文件中的,当该类被加载,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址。
# 5.5 StringTable
# 5.5.1 一道面试题
String s1 = "a";
String s2 = "b";
String s3 = "a" + "b";
String s4 = s1 + s2;
String s5 = "ab";
String s6 = s4.intern();
// 问
System.out.println(s3 == s4); // false
System.out.println(s3 == s5); // true
System.out.println(s3 == s6); // true
String x2 = new String("c") + new String("d");
String x1 = "cd";
x2.intern();
// 问,如果调换了【最后两行代码】的位置呢,如果是jdk1.6呢
System.out.println(x1 == x2); // false
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 5.5.2 StringTable
StringTable 也称为串池。看下面例子:
public static void main(String[] args){
String s1 = "a";
String s2 = "b";
String s3 = "ab";
}
2
3
4
5
对于变量 s1,s2,s3,我们都知道它们被存在了栈中。可是后面的字符串呢?它被存储在哪个地方呢?经过反编译,我们得到如下 JVM 指令:
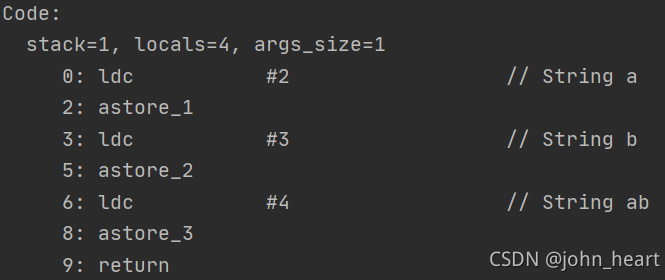
这里的#2就是“a”,当类加载的时候,常量池中的信息会加载到运行时常量池中,此时的a,b,ab都还是符号,没有变成java对象。当运行此方法,执行到对应的代码时,才会将符号a变成“a”字符串对象,并将对象放入 StringTable 中。 需要注意的是,普通的 java 对象在类加载的时候就会生成并放入堆中,而这种方式生成的 String 不同,只有当执行到新建String的代码时才会在 StringTable 中生成字符串对象。
StringTable 是一个哈希表,这些 String 的字面量存在其中。在上例中,“a”就是哈希表的key。一开始的时候,会根据“a”到串池中找其对象,一开始是没有的,所以就会创建一个并放入串池中。串池为 [“a”]。
执行到指令ldc #3时,会和上面一样,生成一个“b”对象并放入串池中,串池变为[“a”, “b”]。同样地,后面会生成“ab”对象并放入串池中。串池变为[“a”, “b”, “ab”]。
小结一下:字面量创建字符串对象是懒惰的,即只有执行到相应代码才会创建相应对象(和一般的类不同)并放入串池中。如果串池中已经有了,就直接使用串池中的对象(让引用变量指向已有的对象)。串池中的对象只会存在一份,也就是只会有一个“a”对象。
# 5.5.3 String 变量的拼接
观察下面的代码,请问输出结果是什么?
String s1 = "a";
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;
System.out.println(s3 == s4); // false
2
3
4
5
6
其实通过反编译 JVM 1.8 的指令可以看到,两个 String 变量的拼接是通过 StringBuilder 来实现的,并最终通过调用 toString 方法来生成新的字符串对象,即便 StringTable 中存在相同值的字符串,这时不会在复用 StringTable 中的 String,而是一个新对象。
在上面的例子中,s3 指向串池中的 “ab” 对象,s4 指向堆中的 “ab” 对象,因此这是两个不同的对象。
# 5.5.4 编译期优化
像下面这行代码(注意与 5.5.3 节的区别,上一节是两个变量拼接,这里是两个字面量拼接):
String s5 = "a" + "b";
这会在编译期间进行优化,使得结果已经在编译器确定为 “ab” 并存入 StringTable 中。因此下面的判等是 true:
String s3 = "ab";
String s5 = "a" + "b";
System.out.println(s3 == s5); // True
2
3
# 5.5.5 intern
String s = new String("a") + new String("b");
String s2 = s.intern();
System.out.println(s1 == "ab"); // true
System.out.println(s == "ab"); // false
2
3
4
5
s.intern() 方法会尝试将字符串对象放入串池中,如果有则不会放入,如果没有则放入,且会返回串池中的对象,同时 s 调用 intern 方法后依旧指向堆中的对象。
# 5.5.6 StringTable 特性小结
常量池中的字符串仅是符号,第一次用到时才变为对象
利用串池的机制,来避免重复创建字符串对象
字符串变量拼接的原理是 StringBuilder
字符串常量拼接的原理是编译期优化
可以使用 intern 方法,主动将串池中还没有的字符串对象放入串池
# 5.6 StringTable 性能调优
- StringTable 是一个哈希表,所以它的性能就和它的大小密切相关,所以 StringTable 调优其实就是调桶的个数。桶的数量越大,就越不容易产生哈希碰撞,效率就越好。可以通过
-XX:StringTableSize= …进行设置。 - 考虑将字符串对象是否入池。如果要存的字符串过多并且很多重复,可以通过 intern 方法,把字符串从堆中入池,就可以减少字符串对象的个数,节约堆内存。
# 6. 直接内存
# 6.1 定义
Direct Memory:
- 常见于 NIO 操作时,用于数据缓冲区
- 分配回收成本较高,但读写性能高
- 不受 JVM 内存回收管理
Direct Memory 也存在 OutOfMemoryError 的可能。
# 6.2 使用
Java 本身并不具备磁盘读写的能力,而是必须调用 OS 的函数来完成,这样 CPU 和内存的状态变化为:
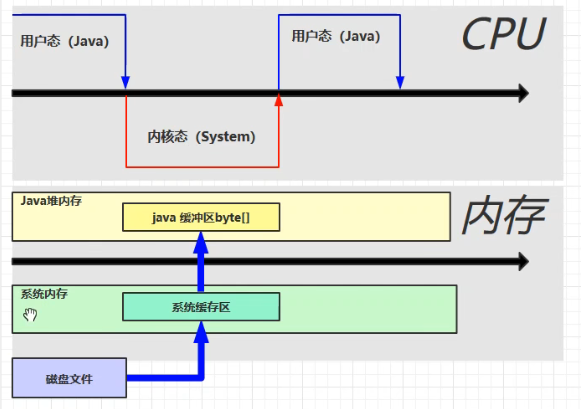
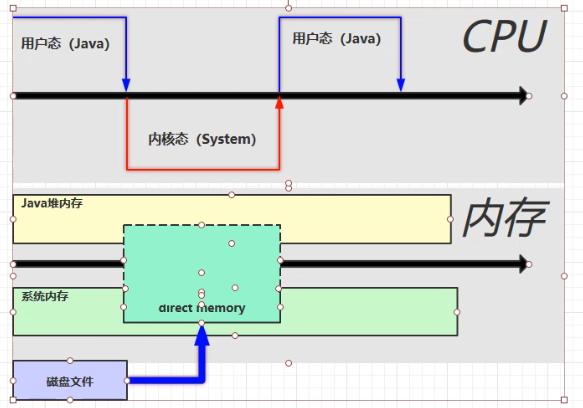
上图中,由于 Java 不能运行系统缓冲区,只能将里面的内容拷贝到一个 Java 缓冲区中。这里的问题就是有两份缓冲区,造成了不必要的浪费。因此可以使用 Direct Memory,它是在系统缓冲区中划出的一块内存,但是 Java 也可以直接访问,从而相比之前减少了一次数据拷贝操作。如下图所示:
public class Demo1_26 {
static int _1Gb = 1024 * 1024 * 1024;
public static void main(String[] args) throws IOException {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1Gb);
System.out.println("分配完毕");
System.in.read();
System.out.println("开始释放");
byteBuffer = null;
System.gc(); // 显式的垃圾回收,Full GC
System.in.read();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 6.3 释放原理
上面在 allocateDirect() 的实现方式是:
- 通过
unsafe对象在DirectByteBuffer这个类对象的构造阶段分配出内存; - 然后在这个对象的析构阶段将调用
freeMemory将内存释放掉。
ByteBuffer 的实现类内部,使用了 Cleaner (虚引用)来监测 ByteBuffer 对象,一旦 ByteBuffer 对象被垃圾回收,那么就会由 ReferenceHandler 线程通过 Cleaner 的 clean 方法调用 freeMemory 来释放直接内存。
因此我们通过 allocateDirect() 申请的内存资源,会在垃圾回收的时候被释放掉。
# 6.4 禁用显式回收对直接内存的影响
由于 System.gc() 会触发 Full GC,对性能影响比较大,因此 JVM 参数 -XX:+DisableExplicitGC 可以让手动调用的 System.gc() 无效。
如果加上这个参数,那么即使我们手动调用了 System.gc(),也不会直接释放掉 DirectMemory,而是要等到 DirectByteBuffer 被垃圾回收的事后才被释放。
当我们使用 direct memory 比较多的时候,可以直接使用
unsafe的allocateMemory()和freeMemory()方法来手动管理直接内存。