 网络编程
网络编程
# 1. 非阻塞 vs 阻塞
# 1.1 阻塞
- 阻塞模式下,相关方法都会导致线程暂停
- ServerSocketChannel.accept 会在没有连接建立时让线程暂停
- SocketChannel.read 会在没有数据可读时让线程暂停
- 阻塞的表现其实就是线程暂停了,暂停期间不会占用 cpu,但线程相当于闲置
- 单线程下,阻塞方法之间相互影响,几乎不能正常工作,需要多线程支持
- 但多线程下,有新的问题,体现在以下方面
- 32 位 jvm 一个线程 320k,64 位 jvm 一个线程 1024k,如果连接数过多,必然导致 OOM,并且线程太多,反而会因为频繁上下文切换导致性能降低
- 可以采用线程池技术来减少线程数和线程上下文切换,但治标不治本,如果有很多连接建立,但长时间 inactive,会阻塞线程池中所有线程,因此不适合长连接,只适合短连接
- 但多线程下,有新的问题,体现在以下方面
# 1.1.1 Server 端代码
// 使用 nio 来理解阻塞模式, 单线程
// 0. ByteBuffer
ByteBuffer buffer = ByteBuffer.allocate(16);
// 1. 创建了服务器
ServerSocketChannel ssc = ServerSocketChannel.open();
// 2. 绑定监听端口
ssc.bind(new InetSocketAddress(8080));
// 3. 连接集合
List<SocketChannel> channels = new ArrayList<>();
while (true) {
// 4. accept 建立与客户端连接, SocketChannel 用来与客户端之间通信
log.debug("connecting...");
SocketChannel sc = ssc.accept(); // 阻塞方法,线程停止运行
log.debug("connected... {}", sc);
channels.add(sc);
for (SocketChannel channel : channels) {
// 5. 接收客户端发送的数据
log.debug("before read... {}", channel);
channel.read(buffer); // 阻塞方法,线程停止运行
buffer.flip();
debugRead(buffer);
buffer.clear();
log.debug("after read...{}", channel);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 1.1.2 客户端代码
SocketChannel sc = SocketChannel.open();
sc.connect(new InetSocketAddress("localhost", 8080));
System.out.println("waiting...");
2
3
# 1.2 非阻塞模式
- 非阻塞模式下,相关方法都会不会让线程暂停
- 在 ServerSocketChannel.accept 在没有连接建立时,会返回 null,继续运行
- SocketChannel.read 在没有数据可读时,会返回 0,但线程不必阻塞,可以去执行其它 SocketChannel 的 read 或是去执行 ServerSocketChannel.accept
- 写数据时,线程只是等待数据写入 Channel 即可,无需等 Channel 通过网络把数据发送出去
- 但非阻塞模式下,即使没有连接建立,和可读数据,线程仍然在不断运行,白白浪费了 cpu
- 数据复制过程中,线程实际还是阻塞的(AIO 改进的地方)
代码方面,客户端代码不需要改动,需要对服务端进行改动,使其单线程可以处理多个客户端的连接:
// 使用 nio 来理解非阻塞模式, 单线程
// 0. ByteBuffer
ByteBuffer buffer = ByteBuffer.allocate(16);
// 1. 创建了服务器
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false); // 非阻塞模式
// 2. 绑定监听端口
ssc.bind(new InetSocketAddress(8080));
// 3. 连接集合
List<SocketChannel> channels = new ArrayList<>();
while (true) {
// 4. accept 建立与客户端连接, SocketChannel 用来与客户端之间通信
SocketChannel sc = ssc.accept(); // 非阻塞,线程还会继续运行,如果没有连接建立,但sc是null
if (sc != null) {
log.debug("connected... {}", sc);
sc.configureBlocking(false); // 非阻塞模式
channels.add(sc);
}
for (SocketChannel channel : channels) {
// 5. 接收客户端发送的数据
int read = channel.read(buffer);// 非阻塞,线程仍然会继续运行,如果没有读到数据,read 返回 0
if (read > 0) {
buffer.flip();
debugRead(buffer);
buffer.clear();
log.debug("after read...{}", channel);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
这种方式会让程序一直消耗 CPU 来跑,这会让 CPU 累死的,所以实际中并不会这样用,而是会采用 selector 模式。
# 1.3 selector 多路复用
单线程可以配合 Selector 完成对多个 Channel 可读写事件的监控,这称之为多路复用。
- 多路复用仅针对网络 IO、普通文件 IO 没法利用多路复用
- 如果不用 Selector 的非阻塞模式,线程大部分时间都在做无用功,而 Selector 能够保证
- 有可连接事件时才去连接
- 有可读事件才去读取
- 有可写事件才去写入
- 限于网络传输能力,Channel 未必时时可写,一旦 Channel 可写,会触发 Selector 的可写事件
# 2. selector
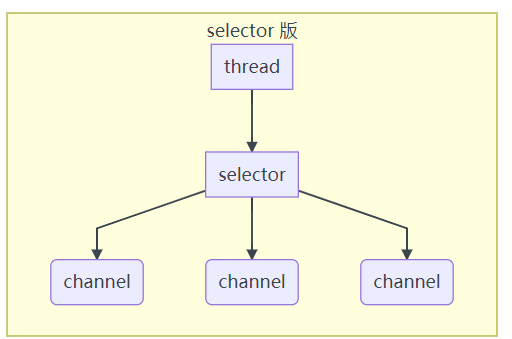
好处:
- 一个线程配合 selector 就可以监控多个 channel 的事件,事件发生线程才去处理。避免非阻塞模式下所做无用功
- 让这个线程能够被充分利用
- 节约了线程的数量
- 减少了线程上下文切换
# 2.1 创建 selector
创建 selector,可以管理多个 channel
Selector selector = Selector.open();
# 2.2 绑定 channel 事件
也称之为注册事件,绑定的事件 selector 才会关心:
SelectKey 就是将来事件发生后,通过它可以知道事件和哪个 channel 的事件。
channel.configureBlocking(false);
SelectionKey key = channel.register(selector, 绑定事件);
2
SelectKey就是将来事件发生后,通过它可以知道事件和哪个 channel 的事件。- channel 必须工作在非阻塞模式
- FileChannel 没有非阻塞模式,因此不能配合 selector 一起使用
- 绑定的事件类型可以有
- connect - 客户端连接成功时触发
- accept - 服务器端成功接受连接时触发
- read - 数据可读入时触发,有因为接收能力弱,数据暂不能读入的情况
- write - 数据可写出时触发,有因为发送能力弱,数据暂不能写出的情况(后面会讲)
# 2.3 监听 channel 事件
select() 方法:若没有事件发生,则线程阻塞;如果有事件,则线程会恢复运行
可以通过下面三种方法来监听是否有事件发生,方法的返回值代表有多少 channel 发生了事件:
# 2.3.1 方式 1:阻塞直到绑定事件发生
int count = selector.select();
# 2.3.2 方式 2:阻塞直到绑定事件发生,或是超时(时间单位为 ms)
int count = selector.select(long timeout);
# 2.3.3 方式 3:不会阻塞,也就是不管有没有事件,立刻返回,自己根据返回值检查是否有事件
int count = selector.selectNow();
select 何时不阻塞
- 事件发生时
- 客户端发起连接请求,会触发 accept 事件
- 客户端发送数据过来,客户端正常、异常关闭时,都会触发 read 事件,另外如果发送的数据大于 buffer 缓冲区,会触发多次读取事件
- channel 可写,会触发 write 事件
- 在 linux 下 nio bug 发生时
- 调用 selector.wakeup()
- 调用 selector.close()
- selector 所在线程 interrupt
# 3. 处理 accept 事件
# 3.1 客户端代码
public class Client {
public static void main(String[] args) {
try (Socket socket = new Socket("localhost", 8080)) {
System.out.println(socket);
socket.getOutputStream().write("world".getBytes());
System.in.read();
} catch (IOException e) {
e.printStackTrace();
}
}
}
2
3
4
5
6
7
8
9
10
11
# 3.2 服务端代码
@Slf4j
public class ChannelDemo6 {
public static void main(String[] args) {
try (ServerSocketChannel channel = ServerSocketChannel.open()) {
channel.bind(new InetSocketAddress(8080));
System.out.println(channel);
Selector selector = Selector.open();
channel.configureBlocking(false);
channel.register(selector, SelectionKey.OP_ACCEPT); // 只关心 accept 事件
while (true) {
int count = selector.select();
// int count = selector.selectNow();
log.debug("select count: {}", count);
// if(count <= 0) {
// continue;
// }
// 获取所有事件(如果有两个 client 来建立连接,则会有会有两个 accept 事件)
Set<SelectionKey> keys = selector.selectedKeys();
// 遍历所有事件,逐一处理
Iterator<SelectionKey> iter = keys.iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
// 判断事件类型
if (key.isAcceptable()) {
ServerSocketChannel c = (ServerSocketChannel) key.channel(); // 表示是哪个 channel 触发的事件
// 必须处理
SocketChannel sc = c.accept();
log.debug("{}", sc);
}
// 处理完毕,必须将事件移除
iter.remove();
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
事件发生后能否不处理?
事件发生后,要么处理,要么取消(cancel),不能什么都不做,否则下次该事件仍会触发,这是因为 NIO 底层使用的是水平触发。
可以通过调用 SelectionKey 的 cancel 来进行取消。
# 4. 处理 read 事件
@Slf4j
public class ChannelDemo6 {
public static void main(String[] args) {
try (ServerSocketChannel channel = ServerSocketChannel.open()) {
channel.bind(new InetSocketAddress(8080));
System.out.println(channel);
Selector selector = Selector.open();
channel.configureBlocking(false);
channel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
int count = selector.select();
// int count = selector.selectNow();
log.debug("select count: {}", count);
// if(count <= 0) {
// continue;
// }
// 获取所有事件
Set<SelectionKey> keys = selector.selectedKeys();
// 遍历所有事件,逐一处理
Iterator<SelectionKey> iter = keys.iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
// 判断事件类型
if (key.isAcceptable()) { // 处理 accept 事件
ServerSocketChannel c = (ServerSocketChannel) key.channel();
// 必须处理
SocketChannel sc = c.accept();
sc.configureBlocking(false);
sc.register(selector, SelectionKey.OP_READ);
log.debug("连接已建立: {}", sc);
} else if (key.isReadable()) { // 处理 read 事件
try {
SocketChannel sc = (SocketChannel) key.channel();
ByteBuffer buffer = ByteBuffer.allocate(128);
int read = sc.read(buffer);
if(read == -1) { // client 正常断开
key.cancel();
sc.close();
} else {
buffer.flip();
debug(buffer);
}
} catch (IOException e) { // client 异常断开
e.printStackTrace();
key.cancel();
}
}
// 处理完毕,必须将事件移除
iter.remove();
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
# 4.1 为何要 iter.remove()
因为 selector 在事件发生后,就会将对应的 key 放入 selectedKeys 集合,但不会在处理完后从 selectedKeys 集合中移除,需要我们自己编码删除。例如
- 第一次触发了 ssckey 上的 accept 事件,没有移除 ssckey
- 第二次触发了 sckey 上的 read 事件,但这时 selectedKeys 中还有上次的 ssckey ,这会让程序认为需要进行 accept 的逻辑,但在处理时因为没有真正的 serverSocket 连上了,就会导致空指针异常
所以当我们处理完一个 key 后,需要我们自己去把它移除掉。
# 4.2 cancel 的作用:处理 client 断开
cancel 会取消注册在 selector 上的 channel,并从 keys 集合中删除 key 后续不会再监听事件。
比如当 client 断开后,服务器这边会产生一个 IOException 的异常并生成一个 read 类型的 key,服务器端需要捕获这个异常并将这个 key 给 cancel 掉。
如果 client 是正常断开,也会产生一个 read 类型的 key,当 channel.read(buf) 返回 -1 时表示 client 正常断开,需要判断并对 key 进行 cancel。
这里的逻辑可以参考上面的代码,以及如何进行的
key.cancel()
# 4.3 处理消息的边界
不处理边界的问题:
当我们分配了 4 byte 的 buffer 来从 channel 进行 read 时,可能发生这样一种情况:client 发送 "中国",但这两个汉字是 6 个 byte 编码而成的,这导致 server 端接收的结果会把"国"这个字给拆开接收,这样在 server 的打印就会出现问题:

这就是不处理 message 的边界的问题。网络编程中发生的”半包“问题都属于此类。
如何处理消息的边界呢?ByteBuffer 和 message 大致有如下关系:
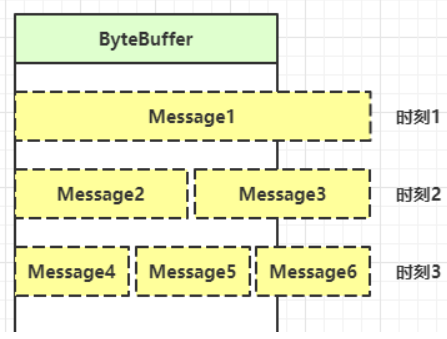
有三种处理思路:
- 一种思路是固定消息长度,数据包大小一样,服务器按预定长度读取,缺点是浪费带宽
- 另一种思路是按分隔符拆分,缺点是效率低
- 常用的思路是,先获取总内容有多少 bytes,用来表示后续还有多少 bytes,然后再分配合适的 buffer 来接收这些 bytes。缺点是 buffer 需要提前分配,如果内容过大,则影响 server 吞吐量。
TLV 和 LTV
Type 类型、Length 长度、Value 数据。
- HTTP 1.1 是 TLV 格式(先收到 Content-Type,然后收到总长度,然后才是真正的 Value)
- HTTP 2.0 是 LTV 格式
这里以第二种思路来进行示例展示,即以分隔符 \n 的方式。
服务器端代码 ⭐️:
private static void split(ByteBuffer source) {
source.flip();
for (int i = 0; i < source.limit(); i++) {
// 找到一条完整消息
if (source.get(i) == '\n') {
int length = i + 1 - source.position();
// 把这条完整消息存入新的 ByteBuffer
ByteBuffer target = ByteBuffer.allocate(length);
// 从 source 读,向 target 写
for (int j = 0; j < length; j++) {
target.put(source.get());
}
debugAll(target);
}
}
source.compact(); // 0123456789abcdef position 16 limit 16
}
public static void main(String[] args) throws IOException {
// 1. 创建 selector, 管理多个 channel
Selector selector = Selector.open();
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);
// 2. 建立 selector 和 channel 的联系(注册)
// SelectionKey 就是将来事件发生后,通过它可以知道事件和哪个channel的事件
SelectionKey sscKey = ssc.register(selector, 0, null);
// key 只关注 accept 事件
sscKey.interestOps(SelectionKey.OP_ACCEPT);
log.debug("sscKey:{}", sscKey);
ssc.bind(new InetSocketAddress(8080));
while (true) {
// 3. select 方法, 没有事件发生,线程阻塞,有事件,线程才会恢复运行
// select 在事件未处理时,它不会阻塞, 事件发生后要么处理,要么取消,不能置之不理
selector.select();
// 4. 处理事件, selectedKeys 内部包含了所有发生的事件
Iterator<SelectionKey> iter = selector.selectedKeys().iterator(); // accept, read
while (iter.hasNext()) {
SelectionKey key = iter.next();
// 处理key 时,要从 selectedKeys 集合中删除,否则下次处理就会有问题
iter.remove();
log.debug("key: {}", key);
// 5. 区分事件类型
if (key.isAcceptable()) { // 如果是 accept
ServerSocketChannel channel = (ServerSocketChannel) key.channel();
SocketChannel sc = channel.accept();
sc.configureBlocking(false);
ByteBuffer buffer = ByteBuffer.allocate(16); // attachment
// 将一个 byteBuffer 作为附件关联到 selectionKey 上
SelectionKey scKey = sc.register(selector, 0, buffer);
scKey.interestOps(SelectionKey.OP_READ);
log.debug("{}", sc);
log.debug("scKey:{}", scKey);
} else if (key.isReadable()) { // 如果是 read
try {
SocketChannel channel = (SocketChannel) key.channel(); // 拿到触发事件的channel
// 获取 selectionKey 上关联的附件
ByteBuffer buffer = (ByteBuffer) key.attachment();
int read = channel.read(buffer); // 如果是正常断开,read 的方法的返回值是 -1
if(read == -1) {
key.cancel();
} else {
split(buffer);
// 需要扩容
if (buffer.position() == buffer.limit()) {
ByteBuffer newBuffer = ByteBuffer.allocate(buffer.capacity() * 2);
buffer.flip();
newBuffer.put(buffer); // 0123456789abcdef3333\n
key.attach(newBuffer); // 把新的 buffer 给 attach 上
}
}
} catch (IOException e) {
e.printStackTrace();
key.cancel(); // 因为客户端断开了,因此需要将 key 取消(从 selector 的 keys 集合中真正删除 key)
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
- 每个 channel 都有自己的 buffer,防止多个 channel 之间读取的数据混乱了,因此需要用到 selectionKey 的附件机制
- 当一条 message 很长时,buffer 应当动态扩容,也就是当 buffer 的 position 已经到达了 limit 且还没有分隔符来 split,说明 buffer 满了,需要扩容
客户端:
SocketChannel sc = SocketChannel.open();
sc.connect(new InetSocketAddress("localhost", 8080));
SocketAddress address = sc.getLocalAddress();
// sc.write(Charset.defaultCharset().encode("hello\nworld\n"));
sc.write(Charset.defaultCharset().encode("0123\n456789abcdef"));
sc.write(Charset.defaultCharset().encode("0123456789abcdef3333\n"));
System.in.read();
2
3
4
5
6
7
# 4.4 ByteBuffer 大小分配
- 每个 channel 都需要记录可能被切分的消息,因为 ByteBuffer 不能被多个 channel 共同使用,因此需要为每个 channel 维护一个独立的 ByteBuffer
- ByteBuffer 不能太大,比如一个 ByteBuffer 1Mb 的话,要支持百万连接就要 1Tb 内存,因此需要设计大小可变的 ByteBuffer
- 一种思路是首先分配一个较小的 buffer,例如 4k,如果发现数据不够,再分配 8k 的 buffer,将 4k buffer 内容拷贝至 8k buffer,优点是消息连续容易处理,缺点是数据拷贝耗费性能,参考实现 http://tutorials.jenkov.com/java-performance/resizable-array.html (opens new window)
- 另一种思路是用多个数组组成 buffer,一个数组不够,把多出来的内容写入新的数组,与前面的区别是消息存储不连续解析复杂,优点是避免了拷贝引起的性能损耗
# 5. 处理 write 事件
# 5.1 一次无法写完的例子
- 非阻塞模式下,无法保证把 buffer 中所有数据都写入 channel,因此需要追踪 write 方法的返回值(代表实际写入字节数)
int write = sc.write(buffer); - 用 selector 监听所有 channel 的可写事件,每个 channel 都需要一个 key 来跟踪 buffer,但这样又会导致占用内存过多,就有两阶段策略
- 当消息处理器第一次写入消息时,才将 channel 注册到 selector 上
- selector 检查 channel 上的可写事件,如果所有的数据写完了,就取消 channel 的注册
- 如果不取消,会每次可写均会触发 write 事件
public class WriteServer {
public static void main(String[] args) throws IOException {
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);
ssc.bind(new InetSocketAddress(8080));
Selector selector = Selector.open();
ssc.register(selector, SelectionKey.OP_ACCEPT);
while(true) {
selector.select();
Iterator<SelectionKey> iter = selector.selectedKeys().iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
iter.remove();
if (key.isAcceptable()) {
SocketChannel sc = ssc.accept();
sc.configureBlocking(false);
SelectionKey sckey = sc.register(selector, SelectionKey.OP_READ);
// 1. 向客户端发送内容
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 30000000; i++) {
sb.append("a");
}
ByteBuffer buffer = Charset.defaultCharset().encode(sb.toString());
int write = sc.write(buffer);
// 3. write 表示实际写了多少字节
System.out.println("实际写入字节:" + write);
// 4. 如果有剩余未读字节,才需要关注写事件
if (buffer.hasRemaining()) {
// read 1 write 4
// 在原有关注事件的基础上,多关注 写事件
sckey.interestOps(sckey.interestOps() + SelectionKey.OP_WRITE);
// 把 buffer 作为附件加入 sckey
sckey.attach(buffer);
}
} else if (key.isWritable()) {
ByteBuffer buffer = (ByteBuffer) key.attachment();
SocketChannel sc = (SocketChannel) key.channel();
int write = sc.write(buffer);
System.out.println("实际写入字节:" + write);
if (!buffer.hasRemaining()) { // 写完了
key.interestOps(key.interestOps() - SelectionKey.OP_WRITE);
key.attach(null);
}
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
以上在 if (key.isAcceptable()) 下面想要发送 buffer 数据时,可能存在一次发不完的情况,而如果循环判断 buffer.hasRemaining() 并继续写入 channel 的话,channel 还处于满的状态时也会尝试写入,导致很多无用操作,因此在 buffer.hasRemaining() 后面,应该是将“可写事件(OP_WRITE)”加入到关注的事件中。
# 5.2 write 事件为何要取消
只要向 channel 发送数据时,socket 缓冲可写,这个事件会频繁触发,因此应当只在 socket 缓冲区写不下时再关注可写事件,数据写完之后再取消关注
# 6. 多线程的优化
现在都是多核 cpu,设计时要充分考虑别让 cpu 的力量被白白浪费。前面的代码只有一个选择器,没有充分利用多核 cpu,如何改进呢?
分两组选择器:
- 单线程配一个选择器(Boss Selector),专门处理 accept 事件
- 创建 cpu 核心数的线程,每个线程配一个选择器(Worker Selector),轮流处理 read 事件
如下图所示:

- 左边黄色方框代表想要与服务器建立连接的 client
如何拿到 cpu 个数?
- Runtime.getRuntime().availableProcessors() 如果工作在 docker 容器下,因为容器不是物理隔离的,会拿到物理 cpu 个数,而不是容器申请时的个数
- 这个问题直到 jdk 10 才修复,使用 jvm 参数 UseContainerSupport 配置, 默认开启
# 7. UDP
- UDP 是无连接的,client 发送数据不会管 server 是否开启
- server 这边的 receive 方法会将接收到的数据存入 byte buffer,但如果数据报文超过 buffer 大小,多出来的数据会被默默抛弃
首先启动服务器端:
public class UdpServer {
public static void main(String[] args) {
try (DatagramChannel channel = DatagramChannel.open()) {
channel.socket().bind(new InetSocketAddress(9999));
System.out.println("waiting...");
ByteBuffer buffer = ByteBuffer.allocate(32);
channel.receive(buffer);
buffer.flip();
debug(buffer);
} catch (IOException e) {
e.printStackTrace();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
输出:
waiting...
运行客户端:
public class UdpServer {
public static void main(String[] args) {
try (DatagramChannel channel = DatagramChannel.open()) {
channel.socket().bind(new InetSocketAddress(9999));
System.out.println("waiting...");
ByteBuffer buffer = ByteBuffer.allocate(32);
channel.receive(buffer);
buffer.flip();
debug(buffer);
} catch (IOException e) {
e.printStackTrace();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 8. NIO vs BIO
# 5.1 stream vs channel
- stream 不会自动缓冲数据,channel 会利用系统提供的发送缓冲区、接收缓冲区(更为底层)
- stream 仅支持阻塞 API,channel 同时支持阻塞、非阻塞 API,网络 channel 可配合 selector 实现多路复用
- 二者均为全双工,即读写可以同时进行
# 5.2 网络 IO 模型
同步阻塞、同步非阻塞、同步多路复用、异步阻塞(没有此情况)、异步非阻塞
- 同步:线程自己去获取结果(一个线程)
- 异步:线程自己不去获取结果,而是由其它线程送结果(至少两个线程)
当调用一次 channel.read 或 stream.read 后,会切换至操作系统内核态来完成真正数据读取,而读取又分为两个阶段,分别为:
- 等待数据阶段
- 复制数据截断
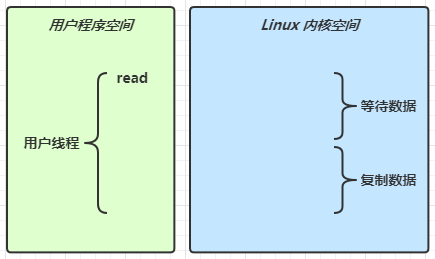
# 5.2.1 阻塞 IO
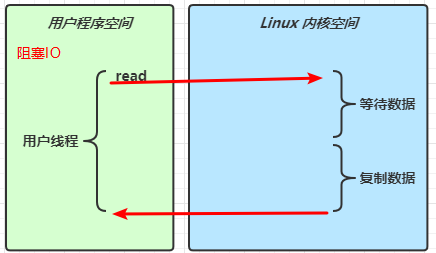
在等待数据到来的时间内,用户程序啥也干不了
# 5.2.2 非阻塞 IO
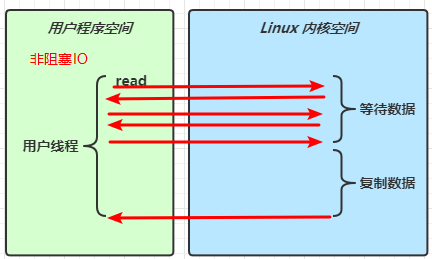
当用户程序调用
read时,如果内核空间没有收到数据,会立刻返回一个 0 表示没有数据,而不是阻塞等待,这样用户程序可以在过一会之后再次read这种方式会产生频繁的用户态与内核态的切换,造成无谓开销
# 5.2.3 多路复用
这种方式的关键是:首次不是调用 read,而是调用一次 select
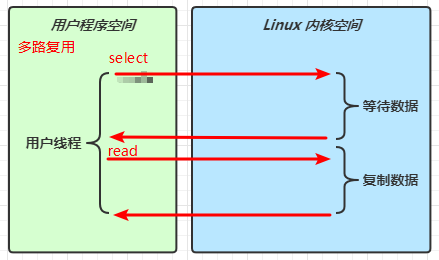
一个 selector 可以监测多个 channel 上的事件。
# 5.2.4 异步 IO

# 5.3 零拷贝
# 5.3.1 传统 IO 的问题
传统的 IO 将一个文件通过 socket 写出:
File f = new File("helloword/data.txt");
RandomAccessFile file = new RandomAccessFile(file, "r");
byte[] buf = new byte[(int)f.length()];
file.read(buf);
Socket socket = ...;
socket.getOutputStream().write(buf);
2
3
4
5
6
7
8
内部工作流程是这样的:
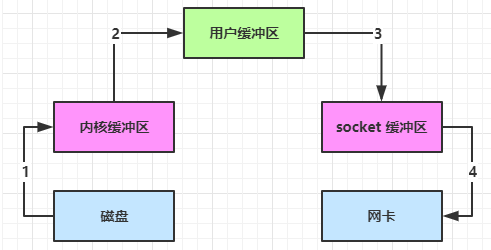
- Java 本身并不具备 IO 读写能力,因此 read 方法调用后,要从 java 程序的用户态切换至内核态,去调用操作系统(Kernel)的读能力,将数据读入内核缓冲区。这期间用户线程阻塞,操作系统使用 DMA(Direct Memory Access)来实现文件读,其间也不会使用 cpu
- 从内核态切换回用户态,将数据从内核缓冲区读入用户缓冲区(即 byte[] buf),这期间 cpu 会参与拷贝,无法利用 DMA
- 调用 write 方法,这时将数据从用户缓冲区(byte[] buf)写入 socket 缓冲区,cpu 会参与拷贝
- 接下来要向网卡写数据,这项能力 Java 又不具备,因此又得从用户态切换至内核态,调用操作系统的写能力,使用 DMA 将 socket 缓冲区的数据写入网卡,不会使用 cpu
可以看到中间环节较多,java 的 IO 实际不是物理设备级别的读写,而是缓存的复制,底层的真正读写是操作系统来完成的:
- 用户态与内核态的切换发生了 3 次,这个操作比较重量级
- 数据拷贝了共 4 次
# 5.3.2 NIO 优化
优化方法:通过 DirectByteBuf
ByteBuffer.allocate(10)-> HeapByteBuffer,使用的还是 java 内存ByteBuffer.allocateDirect(10)-> DirectByteBuffer,使用的是操作系统内存
大部分步骤与优化前相同,不再赘述。唯有一点:Java 可以使用 DirectByteBuf 将堆外内存映射到 jvm 内存中来直接访问使用
- 这块内存不受 jvm 垃圾回收的影响,因此内存地址固定,有助于 IO 读写
- java 中的 DirectByteBuf 对象仅维护了此内存的虚引用,内存回收分成两步
- DirectByteBuf 对象被垃圾回收,将虚引用加入引用队列
- 通过专门线程访问引用队列,根据虚引用释放堆外内存
- 减少了一次数据拷贝,用户态与内核态的切换次数没有减少
进一步优化(底层采用了 linux 2.1 后提供的 sendFile 方法),java 中对应着两个 channel 调用 transferTo/transferFrom 方法拷贝数据:
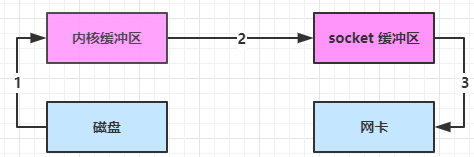
- java 调用 transferTo 方法后,要从 java 程序的用户态切换至内核态,使用 DMA 将数据读入内核缓冲区,不会使用 cpu
- 数据从内核缓冲区传输到 socket 缓冲区,cpu 会参与拷贝
- 最后使用 DMA 将 socket 缓冲区的数据写入网卡,不会使用 cpu
可以看到
- 只发生了一次用户态与内核态的切换
- 数据拷贝了 3 次(图中的数字标明拷贝发生的顺序)
进一步优化(linux 2.4)

- java 调用 transferTo 方法后,要从 java 程序的用户态切换至内核态,使用 DMA 将数据读入内核缓冲区,不会使用 cpu
- 只会将一些 offset 和 length 信息拷入 socket 缓冲区,几乎无消耗
- 使用 DMA 将 内核缓冲区的数据写入网卡,不会使用 cpu
整个过程仅只发生了一次用户态与内核态的切换,数据拷贝了 2 次(磁盘 -> 内核 buffer -> 网卡)。所谓的【零拷贝】,并不是真正无拷贝,而是在不会拷贝重复数据到 JVM 内存中,零拷贝的优点有
- 更少的用户态与内核态的切换
- 不利用 cpu 计算(拷贝过程都是用 DMA),减少 cpu 缓存伪共享
- 零拷贝适合小文件传输(大文件会大量占用内核缓冲区,影响其他程序的文件读写)
# 5.4 AIO
AIO 用来解决数据复制阶段的阻塞问题:
- 同步意味着,在进行读写操作时,线程需要等待结果,还是相当于闲置
- 异步意味着,在进行读写操作时,线程不必等待结果,而是将来由操作系统来通过回调方式由另外的线程来获得结果
异步模型需要底层操作系统(Kernel)提供支持
Windows 系统通过 IOCP 实现了真正的异步 IO Linux 系统异步 IO 在 2.6 版本引入,但其底层实现还是用多路复用模拟了异步 IO,性能没有优势 Netty 也尝试实现过异步 IO,但提升并不多且增加了编码的复杂度,后来就放弃了
# 5.4.1 文件 AIO
来看看 AsynchronousFileChannel:
@Slf4j
public class AioDemo1 {
public static void main(String[] args) throws IOException {
try{
AsynchronousFileChannel s =
AsynchronousFileChannel.open(
Paths.get("1.txt"), StandardOpenOption.READ);
ByteBuffer buffer = ByteBuffer.allocate(2);
log.debug("begin...");
s.read(buffer, 0, null, new CompletionHandler<Integer, ByteBuffer>() {
@Override
public void completed(Integer result, ByteBuffer attachment) {
log.debug("read completed...{}", result);
buffer.flip();
debug(buffer);
}
@Override
public void failed(Throwable exc, ByteBuffer attachment) {
log.debug("read failed...");
}
});
} catch (IOException e) {
e.printStackTrace();
}
log.debug("do other things...");
System.in.read();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
输出:
13:44:56 [DEBUG] [main] c.i.aio.AioDemo1 - begin...
13:44:56 [DEBUG] [main] c.i.aio.AioDemo1 - do other things...
13:44:56 [DEBUG] [Thread-5] c.i.aio.AioDemo1 - read completed...2
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 61 0d |a. |
+--------+-------------------------------------------------+----------------+
2
3
4
5
6
7
8
可以看到
- 响应文件读取成功的是另一个线程 Thread-5
- 主线程并没有 IO 操作阻塞
默认文件 AIO 使用的线程都是守护线程,所以最后要执行 System.in.read() 以避免守护线程意外结束。