 持有对象(集合)
持有对象(集合)
Java 提供了一套容器类用来“保存对象”,并将其划分为两个不同的概念:
- Collection:一个独立元素的序列,包括 List、Set 和 Queue
- Map:一组“键值对”的映射表
这些类型统称为集合类,但由于 Collection 又是其中一个特定子集的术语,所以往往也使用更宽泛的术语“容器”。
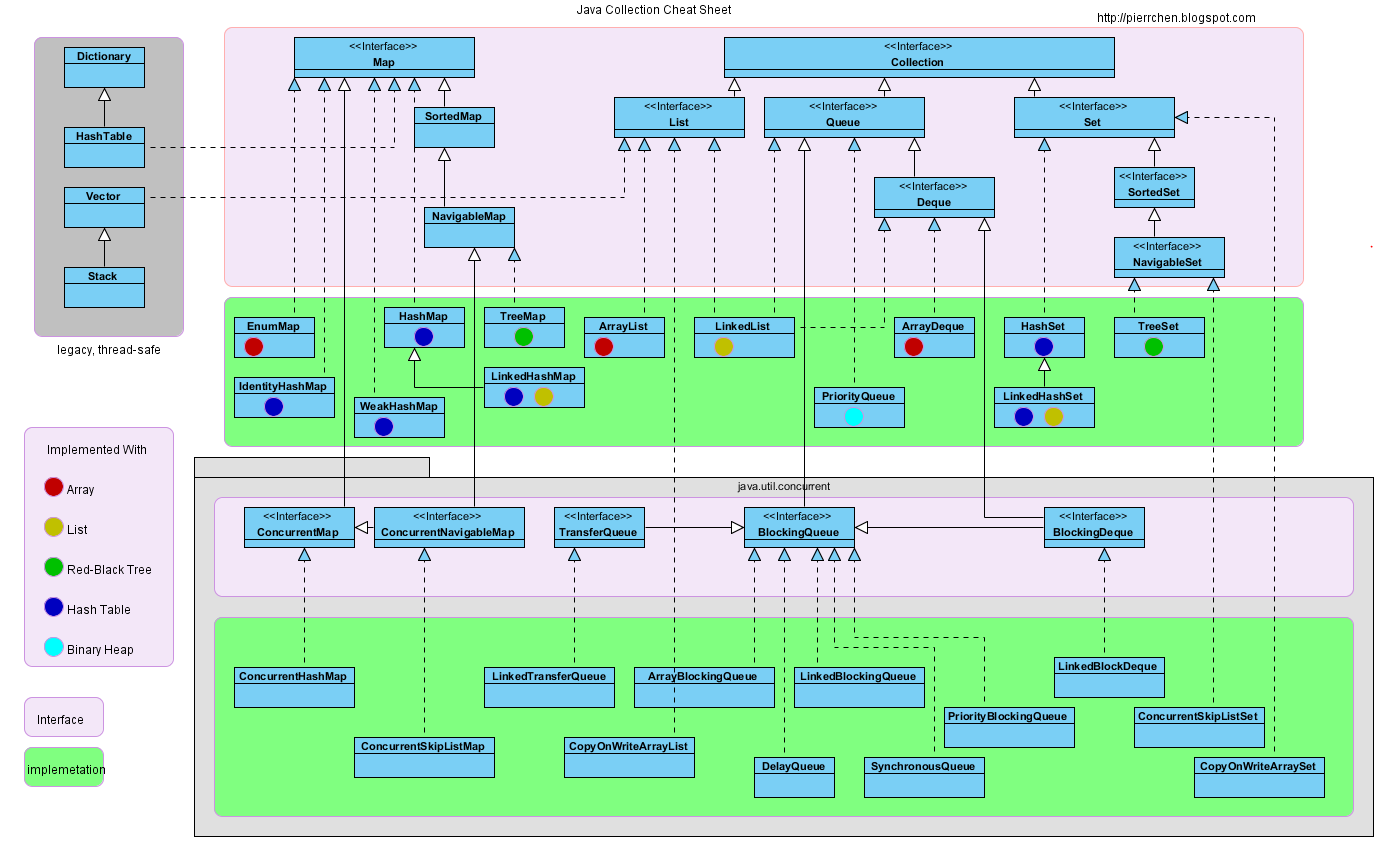
# 1. Collection 集合体系
Collection 是单列集合的祖宗接口,它的功能是全部单列集合都可以继承使用的。
# 1.1 Collection 常用 API
| 方法名称 | 说明 |
|---|---|
| public boolean add(E e) | 把给定的对象添加到当前集合中 |
| public void clear() | 清空集合中所有的元素 |
| public boolean remove(E e) | 把给定的对象在当前集合中删除 |
| public boolean contains(Object obj) | 判断当前集合中是否包含给定的对象 |
| public boolean isEmpty() | 判断当前集合是否为空 |
| public int size() | 返回集合中元素的个数。 |
| public Object[] toArray() | 把集合中的元素,存储到数组中 |
# 1.2 Collection 的遍历方式
# 1)方式一:迭代器
Collection 集合获取迭代器:
| 方法名称 | 说明 |
|---|---|
Iterator<E> iterator() | 返回集合中的迭代器对象,该迭代器对象默认指向当前集合的 0 索引 |
Iterator 中的常用方法:
| 方法名称 | 说明 |
|---|---|
| boolean hasNext() | 询问当前位置是否有元素存在,存在返回true ,不存在返回false |
| E next() | 获取当前位置的元素,并同时将迭代器对象移向下一个位置,注意防止取出越界。 |
- 迭代器取元素时越界会出现 NoSuchElementException 异常。
Iterator<String> it = lists.iterator();
while(it.hasNext()){
String ele = it.next();
System.out.println(ele);
}
2
3
4
5
# 2)方式二:foreach
for(Type varName : 数组或者Collection集合) {
// ...
}
2
3
- 既可以遍历集合也可以遍历数组。
# 3)方式三:lambda 表达式
JDK 8 的新技术 Lambda 表达式,提供了一种更简单、更直接的遍历集合的方式。
Collection 结合 Lambda 遍历的 API:
| 方法名称 | 说明 |
|---|---|
default void forEach(Consumer<? super T> action) | 结合 lambda 遍历集合 |
lists.forEach(s -> {
System.out.println(s);
});
2
3
# 2. List 系列集合
特点:有序、可重复、有索引。
# 2.1 List 特有方法
List 集合因为支持索引,所以多了很多索引操作的独特 API,其他 Collection 的功能List也都继承了。
| 方法名称 | 说明 |
|---|---|
| void add(int index,E element) | 在此集合中的指定位置插入指定的元素 |
| E remove(int index) | 删除指定索引处的元素,返回被删除的元素 |
| E set(int index, E element) | 修改指定索引处的元素,返回被修改的元素 |
| E get(int index) | 返回指定索引处的元素 |
- ArrayList 底层是基于数组实现的,根据查询元素快,增删相对慢(但在实际上也非常快)。
- LinkedList 底层基于双链表实现的,查询元素慢,增删首尾元素是非常快的(多了很多增删首尾的 API)。
# 2.2 List 的遍历
① 迭代器 ② foreach ③ Lambda ④ 普通 for 循环(因为 List 支持索引)
# 3. 泛型深入
# 3.1 泛型概述
泛型是 JDK5 中引入的特性,可以在编译阶段约束操作的数据类型,并进行检查。
格式:<Type>,只支持引用数据类型。
泛型好处:
- 统一数据类型
- 把运行时期的问题提前到了编译期间,避免了强制类型转换可能出现的异常,因为编译阶段类型就能确定下来
泛型可以在很多地方使用:泛型类、泛型方法、泛型接口。
# 3.2 自定义泛型类
格式示例:public class MyArrayList<T> {}
- 泛型变量常用的标识是:T、E、K、V 等
核心思想:把出现泛型变量的地方全部替换成传输的真实数据类型
类似地可定义泛型方法和泛型接口。
# 3.3 泛型通配符、上下限
通配符:?
- ? 可以在“使用泛型”的时候代表一切类型
- E T K V 是在定义泛型的时候使用的
案例导学:
- 开发一个极品飞车的游戏,所有的汽车都能一起参与比赛
class Car {
...
}
/** 宝马 */
class BMW extends Car {
...
}
/** 奔驰 */
class BENZ extends Car {
...
}
2
3
4
5
6
7
8
9
10
11
12
13
注意:🔺 虽然 BMW 和 BENZ 都继承了 Car 但是 ArrayList<BMW> 和 ArrayList<BENZ> 与 ArrayList<Car> 没有关系的!!
泛型的上下限:
? extends Car:其中的?必须是 Car 或者其子类,泛型上限? super Car:其中的?必须是 Car 或者其父类,泛型下限
助记
extends —— 子类
super —— 父类
# 4. Set 系列集合
- HashSet : 无序、不重复、无索引。
- LinkedHashSet:有序、不重复、无索引。
- TreeSet:排序、不重复、无索引。
Set 集合的功能上基本上与 Collection 的 API 一致。
# 4.1 HashSet
HashSet 集合底层采取哈希表存储的数据,哈希表的组成:
- JDK8 之前的,底层使用数组+链表(拉链法)组成
- JDK8 开始后,底层采用数组+链表+红黑树组成
- 当一条拉链上数据过多时(长度超过 8),这条链表会自动转换成红黑树
Object 类的 API public int hashCode() 会返回对象的哈希值。
提示
如果希望 Set 集合认为两个内容相同的对象是重复的应该怎么办?
- 重写对象的
hashCode和equals方法。
# 4.2 LinkedHashSet
有序、不重复、无索引。底层数据结构依然是哈希表,只是每个元素又额外地多了一个双链表的机制来记录存储顺序。
# 4.3 TreeSet
不重复、无索引、可排序。
- 可排序:按照元素的大小默认升序排序。注意:TreeSet 是一定要排序的,可以将元素按照指定的规则进行排序。
TreeSet 底层是基于红黑树实现排序的,增删查改的性能都较好。
# 4.3.1 为 TreeSet 自定义排序规则
🖊方式一:让自定义的类(如 Student 类)实现 Comparable 接口重写里面的 compareTo 方法来定制比较规则。
🖊方式二:TreeSet 有参构造器,可以设置 Comparator 接口对应的比较器对象,来定制比较规则。
关于比较的返回值规则:第一个元素大于第二个元素则返回正整数,小于则返回负整数,相等则返回 0。
# 5. Java 可变参数
可变参数用在形参中可以接收多个数据。格式:Type... argName,例如:
public static void sum(int...nums) {
int result = 0;
for (int i = 0; i < nums.length; ++i) {
result += nums[i];
}
return result;
}
2
3
4
5
6
7
调用时可以传递 0~N 个参数,也可以传输一个数组。可变参数在方法内部本质上就是一个数组。
注意事项:
- 一个形参列表中可变参数至多有一个
- 可变参数必须放在形参列表的最后
# 6. 集合工具类 Collections
Collections 是用来操作集合的工具类。
# 6.1 常用 API
| 方法名称 | 说明 |
|---|---|
public static <T> boolean addAll(Collection<? super T> c, T... elements) | 给集合对象批量添加元素 |
public static void shuffle(List<?> list) | 打乱 List 集合元素的顺序 |
# 6.2 排序 API
只能对于 List 集合的排序。
| 方法名称 | 说明 |
|---|---|
public static <T> void sort(List<T> list) | 将集合中元素按默认规则排序 |
public static <T> void sort(List<T> list,Comparator<? super T> c) | 将集合中元素按指定规则排序 |
# 7. Map 集合体系
// TODO