 多线程
多线程
# 1. 基本概念:程序、进程、线程
- 程序(program):指一段静态的代码,是静态的。
- 进程(process):正在运行的一个程序,是一个动态的过程。进程作为资源分配的单位,系统在运行时会为每个进程分配不同的内存区域(虚拟内存)。
- 线程(thread):一个程序内部的一条执行路径。
- 若一个进程同一时间并行执行多个线程,就是支持多线程的。
- 线程作为调度和执行的单位,每个线程拥有独立的运行栈和程序计数器(pc),线程切换的开销小。
- 一个进程中的多个线程共享相同的内存地址空间 —> 它们从同一堆中分配对象,可以访问相同的变量和对象。
# 单核CPU & 多核CPU
单核 CPU 为在一个时间单元内,也只能执行一个线程的任务。如果是多核的话,才能更好的发挥多线程的效率。
一个 Java 应用程序其实至少有三个线程:main() 主线程,gc() 垃圾回收线程,异常处理线程。当然如果发生异常,会影响主线程。
# 并行 & 并发
并发(Concurrent):在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行。
并行(Parallel),当系统有一个以上CPU时,当一个CPU执行一个进程时,另一个CPU可以执行另一个进程,两个进程互不抢占CPU资源,可以同时进行,这种方式我们称之为并行。
并发是在一段时间内宏观上多个程序同时运行,并行是在某一时刻,真正有多个程序在运行。
# 2. 线程的创建和使用
# 2.1 API 中创建线程的方式
- 继承 Thread 类的方式
- 实现 Runnable 接口的方式
- 利用 Callable、FutureTask 接口来创建线程的方式。
# 2.1.1 继承 Thread 类的方式
- 定义子类继承 Thread 类,并重写 Thread 类中的 run 方法
- 实例化这个类,即创建了线程对象
- 调用线程对象的
start方法,这是会启动线程,并自动调用之前定义的run方法
示例:一个线程,计算比给定值大的素数:
class PrimeThread extends Thread {
long minPrime;
PrimeThread(long minPrime) {
this.minPrime = minPrime;
}
public void run() {
// compute primes larger than minPrime
. . .
}
}
PrimeThread p = new PrimeThread(143);
p.start();
2
3
4
5
6
7
8
9
10
11
12
13
14
区分好 start 和 run 方法
- 如果自己手动调用 run() 方法,那么就只是普通方法,没有启动多线程模式。
- run() 方法由 JVM 调用,什么时候调用,执行的过程控制都有操作系统的 CPU 调度决定。
- 想要启动多线程,必须调用 start 方法。
- 一个线程对象只能调用一次 start() 方法启动,如果重复调用了,则将抛出以下的异常
IllegalThreadStateException。
示例:多窗口买票
public class Window extends Thread {
private static int ticket = 100;
@Override
public void run() {
while(true) {
if (ticket > 0) {
System.out.println(getName() + ":卖票,票号为:" + ticket);
ticket--;
} else
break;
}
}
}
public class WindowTest {
public static void main(String[] args) {
Window t1 = new Window();
Window t2 = new Window();
Window t3 = new Window();
t1.setName("窗口1");
t2.setName("窗口2");
t3.setName("窗口3");
t1.start();
t2.start();
t3.start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
运行结果如下:
窗口3:卖票,票号为:100
窗口1:卖票,票号为:100
窗口2:卖票,票号为:100
...
2
3
4
可以看到产生了不符合预期的行为,这是因为多个线程操作共享的系统资 源可能就会带来安全的隐患。之后我们要想办法解决这个问题。
# 2.2.2 实现 Runnable 接口的方式
- 定义子类,实现 Runnable 接口,并重写 run 方法
- 通过 Thread 类含参构造器创建线程对象
- 将 Runnable 接口的子类对象作为实际参数传递给 Thread 类的构造器中
- 调用对象的 start 方法:开启线程,调用Runnable子类接口的run方法
示例:
class PrimeRun implements Runnable {
long minPrime;
PrimeRun(long minPrime) {
this.minPrime = minPrime;
}
public void run() {
// compute primes larger than minPrime
. . .
}
}
PrimeRun p = new PrimeRun(143);
new Thread(p).start();
2
3
4
5
6
7
8
9
10
11
12
13
14
继承方式 VS. 实现方式
- 区别
- 继承 Thread:线程代码存放Thread子类 run 方法中
- 实现 Runnable:线程代码存在接口的子类的 run 方法
- 实现方式的好处
- 避免了单继承的局限性
- 实现方式中多个线程可以共享同一个接口实现类的对象,非常适合多个相同线程来处理同一份资源
- 相同
- 两种方式都需要重写
run(),将线程要执行的逻辑声明在 run() 中。
- 两种方式都需要重写
示例:多窗口卖票
class Ticket implements Runnable {
private int tick = 100;
public void run() {
while (true) {
if (tick > 0) {
System.out.println(Thread.currentThread().getName() + "售出车票,tick号为:" + tick--);
} else
break;
}
}
class TicketDemo {
public static void main(String[] args) {
Ticket t = new Ticket();
Thread t1 = new Thread(t);
Thread t2 = new Thread(t);
Thread t3 = new Thread(t);
t1.setName("t1窗口");
t2.setName("t2窗口");
t3.setName("t3窗口");
t1.start();
t2.start();
t3.start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
- 这里不同的线程使用了同一个 Runnable 对象。
# 2.2.3 利用 Callable、FutureTask 接口实现
前2种线程创建方式都存在一个问题:他们重写的run方法均不能直接返回结果,不适合需要返回线程执行结果的业务场景。
利用 Callable、FutureTask 接口创建线程:
- 得到任务对象
- 定义类实现 Callable 接口,重写 call 方法,封装要做的事情
- 用 FutureTask 把 Callable 对象封装成线程任务对象
- 把线程任务对象交给 Thread 处理
- 调用 Thread 的 start 方法启动线程,执行任务
- 线程执行完毕后,通过 FutureTask 的 get 方法去获取任务执行的结果
FutureTask 的 API:
| 方法名称 | 说明 |
|---|---|
public FutureTask<>(Callable call) | 把 Callable 对象封装成 FutureTask 对象。 |
public V get() throws Exception | 获取线程执行 call 方法返回的结果,它是会等线程执行完得到结果再返回的。 |
示例:
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class ThreadDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
int[] nums = {1, 2, 3};
Callable<Integer> accumulator = new Accumulator(nums);
FutureTask<Integer> futureTask = new FutureTask<>(accumulator);
Thread t = new Thread(futureTask);
t.start();
System.out.println(futureTask.get());
}
}
class Accumulator implements Callable<Integer> {
private final int[] nums;
public Accumulator(int[] nums) {
this.nums = nums;
}
@Override
public Integer call() {
int sum = 0;
for (int num: nums) {
sum += num;
}
return sum;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
优缺点:
- 优点:线程任务类只是实现接口,可以继续继承类和实现接口,扩展性强。可以在线程执行完毕后去获取线程执行的结果。
- 缺点:编码复杂一点。
# 2.2 Thread 类的常用方法
# 1)Thread 获取和设置线程名称
| 方法名称 | 说明 |
|---|---|
| String getName() | 获取当前线程的名称,默认线程名称是 “Thread-索引” |
| void setName(String name) | 将此线程的名称更改为指定的名称,通过构造器也可以设置线程名称 |
# 2)Thread 类获得当前线程的对象
| 方法名称 | 说明 |
|---|---|
| public static Thread currentThread(): | 返回对当前正在执行的线程对象的引用 |
- 此方法是 Thread 类的静态方法,可以直接使用Thread类调用。
- 这个方法是在哪个线程执行中调用的,就会得到哪个线程对象。
# 3)常用构造器
| 方法名称 | 说明 |
|---|---|
| public Thread(String name) | 可以为当前线程指定名称 |
| public Thread(Runnable target) | 封装Runnable对象成为线程对象 |
| public Thread(Runnable target ,String name ) | 封装Runnable对象成为线程对象,并指定线程名称 |
# 4)线程休眠方法
| 方法名称 | 说明 |
|---|---|
| public static void sleep(long millis) | 让当前线程休眠指定的时间后再继续执行,单位为毫秒。 |
// 项目经理要求这里运行缓慢,好让客户给钱优化
Thread.sleep(2000);
2
# 5)与调度相关的方法
| 方法名称 | 说明 |
|---|---|
| static void yield() | 线程让步。暂停当前正在执行的线程,把执行机会让给优先级相同或更高的线程,若队列中没有同优先级的线程,则忽略此方法继续执行。 |
| join() | 当某个程序执行流中调用其他线程的 join() 方法时,调用线程将被阻塞,直到 join() 方法加入的 join 线程执行完为止。比如在 A 线程中调用了 B.join(),那么 A 将被阻塞,直到 B 执行完后 A 才继续执行。 |
| 强制线程生命期结束,已过时。 |
# 6)判断当前进程是否存活
| 方法名称 | 说明 |
|---|---|
| boolean isAlive() | 判断线程是否还活着 |
# 2.3 线程的调度
# 2.3.1 调度策略
两种调度策略:
- 时间片式
- 抢占式:高优先级的线程抢占CPU
Java 的调度方法:
- 同优先级线程组成先进先出队列(先到先服务),使用时间片策略;
- 对高优先级,使用优先调度的抢占式策略
# 2.3.2 线程的优先级
优先级等级:
- MAX_PRIORITY:10
- MIN _PRIORITY:1
- NORM_PRIORITY:5
涉及的方法:
- getPriority():返回线程优先值
- setPriority(int newPriority) :改变线程的优先级
提示
- 线程创建时继承父线程的优先级
- 低优先级只是获得调度的概率低,并非一定是在高优先级线程之后才被调用
# 2.4 线程的分类
Java中的线程分为两类:一种是守护线程,一种是用户线程。
- 它们在几乎每个方面都是相同的,唯一的区别是判断 JVM 何时离开。
- 守护线程是用来服务用户线程的,通过在 start() 方法前调用。thread.setDaemon(true) 可以把一个用户线程变成一个守护线程。
- Java 垃圾回收就是一个典型的守护线程。
- 若 JVM 中都是守护线程,当前 JVM 将退出【兔死狗烹,鸟尽弓藏】。
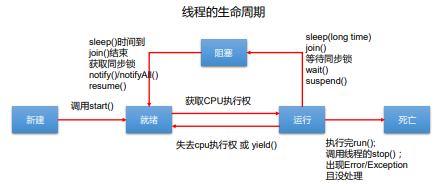
# 3. 线程的生命周期
线程在一个完整的生命周期中通常要经历如下的五种状态:
- 新建:当一个 Thread 类或其子类的对象被声明并创建时,新生的线程对象处于新建 状态
- 就绪:处于新建状态的线程被 start() 后,将进入线程队列等待 CPU 时间片,此时它已具备了运行的条件,只是没分配到 CPU 资源
- 运行:当就绪的线程被调度并获得CPU资源时,便进入运行状态,run()方法定义了线 程的操作和功能
- 阻塞:在某种特殊情况下,被人为挂起或执行输入输出操作时,让出 CPU 并临时中止自己的执行,进入阻塞状态
- 死亡(终止):线程完成了它的全部工作或线程被提前强制性地中止或出现异常导致结束
JDK 中用 Thread.State 类定义了线程的这几种状态。
# 4. 线程的同步
问题的提出:
- 多个线程执行的不确定性引起执行结果的不稳定
- 多个线程对同一数据的共享,会造成操作的不完整性,会破坏数据
以之前卖票为案例,有下面代码:
private static int ticket = 100;
@Override
public void run() {
while(true) {
if (ticket > 0) {
try{
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(getName() + ":卖票,票号为:" + ticket);
ticket--;
} else
break;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
注意 if(ticket > 0) 后面跟着一个 sleep 这个阻塞操作,于是可能出现如下的错误状态:
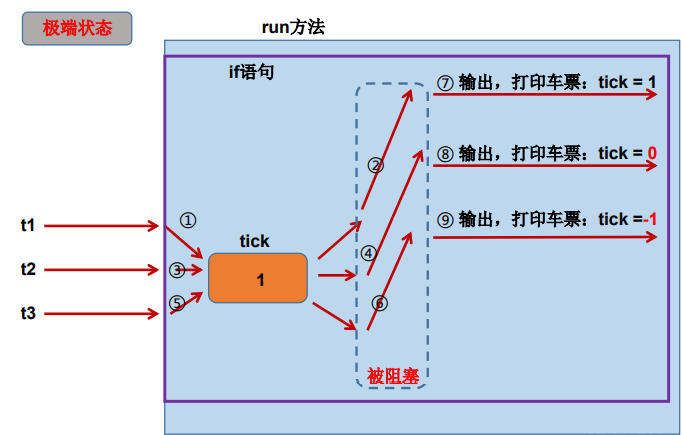
问题出现的原因:当多条语句在操作同一个线程共享数据时,一个线程对多条语句只执行了一部分,还没有执行完,另一个线程参与进来执行。导致共享数据的错误。
解决办法:对多条操作共享数据的语句,只能让一个线程都执行完,在执行过程中,其他线程不可以参与执行。
# 4.1 synchronized 的使用
在 Java 中,我们通过同步机制,来解决线程的安全问题:
- 方式一:同步代码块
- 方式二:同步方法
但也有缺点,操作同步代码时,只能有一个线程参与,其他线程等待,相当于是一个单线程的过程,效率低。
# 方式一:同步代码块
synchronized( 同步监视器 ) {
// 需要被同步的代码
...
}
2
3
4
- 操作共享数据的代码,即为需要被同步的代码
- 共享数据:多个线程共同操作的变量,比如之前例子的 ticket。
- 同步监视器:俗称锁,任何一个类的对象都可以充当锁。要求:多个线程必须要共用同一把锁。
卖票示例的改造
private static int ticket = 100;
private static Object obj = new Object();
@Override
public void run() {
while(true) {
synchronized (obj) {
if (ticket > 0) {
try{
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(getName() + ":卖票,票号为:" + ticket);
ticket--;
} else
break;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- 对随便一个对象 obj 使用上 synchronized,来同步所有对共享数据的操作,这样便可以得到正确的结果。
synchronized 包住的代码,既不能包多了,也不能包少了:
- 包少了:出现安全问题
- 包多了:既会导致性能下降,也可能出错,比如上面卖票的例子中,将 while 包在 synchronized 里面会导致所有的卖票都是一个线程在实际执行。
# 方法二:同步方法
如果操作共享数据的代码完整地声明在一个方法中,那我们不妨将此方法声明为同步的:
private synchronized void doSomething() {
....
}
2
3
于是这个方法被声明为同步的了。同步的非 static 方法会自动将 this 作为同步监视器,同步的 static 方法会自动将类 xxx.class 本身作为同步监视器。这时,
- 在继承 Thread 创建线程的方式中,由于不同线程的 this 不同,因此需要将同步方法也声明为 static 的。
- 在实现 Runnable 接口创建线程的方式中,this 指的是实现了 Runnable 的子类对象,而不是 Thread 对象,因此如果不同线程使用的同一个 Runnable 对象,那写在 Runnable 中的 this 也是相同的。
卖票示例的改造
private static int ticket = 100;
private static Object obj = new Object();
@Override
public void run() {
while(true) {
sell();
}
}
private static synchronized void sell() {
if (ticket > 0) {
try{
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + ":卖票,票号为:" + ticket);
ticket--;
} else
break;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
- 由于不同线程实例的
xxx.class是唯一的,而 this 不唯一,因此我们将同步方法声明为 static 的。
# 4.2 线程的死锁
会释放锁的操作有:
- 当前线程的同步方法、同步代码块执行结束。
- 当前线程在同步代码块、同步方法中遇到 break、return 终止了该代码块、 该方法的继续执行。
- 当前线程在同步代码块、同步方法中出现了未处理的 Error 或 Exception,导致异常结束。
- 当前线程在同步代码块、同步方法中执行了线程对象的 wait() 方法,当前线程暂停,并释放锁。
不会释放锁的操作:
- 线程执行同步代码块或同步方法时,程序调用 Thread.sleep()、 Thread.yield() 方法暂停当前线程的执行
- 线程执行同步代码块时,其他线程调用了该线程的 suspend() 方法将该线程挂起,该线程不会释放锁(同步监视器)。
- 应尽量避免使用 suspend() 和 resume() 来控制线程
死锁:不同的线程分别占用对方需要的同步资源不放弃,都在等待对方放弃自己需要的同步资源,就形成了线程的死锁。出现死锁后,不会出现异常,不会出现提示,只是所有的线程都处于阻塞状态,无法继续。
死锁的解决方法:
- 专门的算法、原则
- 尽量减少同步资源的定义
- 尽量避免嵌套同步
死锁示例:
public class DeadLockTest {
public static void main(String[] args) {
final StringBuffer s1 = new StringBuffer();
final StringBuffer s2 = new StringBuffer();
new Thread() {
public void run() {
synchronized (s1) {
s2.append("A");
synchronized (s2) {
s2.append("B");
System.out.print(s1);
System.out.print(s2);
}
}
}
}.start();
new Thread() {
public void run() {
synchronized (s2) {
s2.append("C");
synchronized (s1) {
s1.append("D");
System.out.print(s2);
System.out.print(s1);
}
}
}
}.start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
synchronized (s1)可以念成“握住 s1 这把锁”。- 这段代码就有可能陷入死锁状态。
# 4.3 同步锁 Lock
java.util.concurrent.locks.Lock 接口是控制多个线程对共享资源进行访问的工具。锁提供了对共享资源的独占访问,每次只能有一个线程对 Lock 对象加锁,线程开始访问共享资源之前应先获得Lock对象。
ReentrantLock 类实现了 Lock ,它拥有与 synchronized 相同的并发性和内存语义,在实现线程安全的控制中,比较常用的是 ReentrantLock,可以显式加锁、释放锁。
class A {
private final ReentrantLock lock = new ReenTrantLock();
public void m() {
lock.lock();
try {
// 保证线程安全的代码
}
finally {
lock.unlock();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
如果同步代码有异常,要将 unlock() 写入 finally 语句块。
面试题:synchronized 与 Lock 的异同?
相同:二者都可以解决线程安全问题
不同:
- Lock 是显式锁(需要手动开启和关闭);synchronized 是隐式锁,出了作用域自动释放
- 使用 Lock 锁,JVM 将花费较少的时间来调度线程,性能更好。并且具有更好的扩展性
优先使用顺序:Lock -> 同步代码块 -> 同步方法
面试题:如何解决线程安全问题?
Lock、synchronized 的同步代码块或同步方法。
# 5. 线程的通信 了解
线程通信就是线程间相互发送数据,线程间共享一个资源即可实现线程通信。
线程通信常见形式:通过共享一个数据的方式实现,根据共享数据的情况决定自己该怎么做,以及通知其他线程怎么做。
线程通信实际应用场景:生产者与消费者模型:生产者线程负责生产数据,消费者线程负责消费生产者产生的数据。要求:生产者线程生产完数据后唤醒消费者,然后等待自己,消费者消费完该数据后唤醒生产者,然后等待自己。
Object 类的等待和唤醒方法:
| 方法名称 | 说明 |
|---|---|
| void wait() | 让当前线程等待并释放所占锁,进入等待状态,直到另一个线程调用 notify() 方法或 notifyAll() 方法。在当前线程被notify后,会重新获得监控权,然后从断点处继续代码的执行 |
| void notify() | 唤醒正在等待的单个线程 |
| void notifyAll() | 唤醒正在等待的所有线程 |
- 上述方法应该使用当前同步锁对象进行调用。
# ▲ 经典例题:生产者/消费者问题
生产者(Producer)将产品(Product)交给店员(Clerk),而消费者(Customer)从店员处取走产品,店员一次只能持有固定数量的产品(比如:20),如果生产者试图生产更多的产品,店员会叫生产者停一下,如果店中有空位放产品了再通知生产者继续生产;如果店中没有产品了,店员会告诉消费者等一下,如果店中有产品了再通知消费者来取走产品。
分析:
- 是否是多线程问题?是,生产者线程,消费者线程
- 是否有共享数据?是,店员(或产品)
- 如何解决线程的安全问题?同步机制
- 是否涉及到线程的通信?是
# 1)售货员
/**
* 售货员
**/
class Clerk {
private int product = 0;
public synchronized void addProduct() {
if (product >= 20) {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
product++;
System.out.println("生产者生产了第" + product + "个产品");
notifyAll();
}
}
public synchronized void getProduct() {
if (this.product <= 0) {
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
System.out.println("消费者取走了第" + product + "个产品");
product--;
notifyAll();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 2)生产者
/**
* 生产者
**/
class Productor implements Runnable {
Clerk clerk;
public Productor(Clerk clerk) {
this.clerk = clerk;
}
public void run() {
System.out.println("生产者开始生产产品");
while (true) {
try {
Thread.sleep((int) Math.random() * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
clerk.addProduct();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 3)消费者
class Consumer implements Runnable { // 消费者
Clerk clerk;
public Consumer(Clerk clerk) {
this.clerk = clerk;
}
public void run() {
System.out.println("消费者开始取走产品");
while (true) {
try {
Thread.sleep((int) Math.random() * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
clerk.getProduct();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 4)测试
public class ProductTest {
public static void main(String[] args) {
Clerk clerk = new Clerk();
Thread productorThread = new Thread(new Productor(clerk));
Thread consumerThread = new Thread(new Consumer(clerk));
productorThread.start();
consumerThread.start();
}
}
2
3
4
5
6
7
8
9
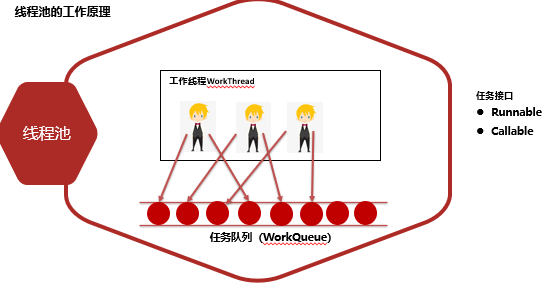
# 6. 线程池 重点
# 6.1 线程池概述
线程池就是一个可以复用线程的技术。
不使用线程池的问题
- 如果用户每发起一个请求,后台就创建一个新线程来处理,下次新任务来了又要创建新线程,而创建新线程的开销是很大的,这样会严重影响系统的性能。
# 6.2 线程池实现的 API
JDK 5.0 提供了代表线程池的接口:ExecutorService
如何得到线程池对象:
- 方式一(常用):使用 ExecutorService 的实现类 ThreadPoolExecutor 自创建一个线程池对象
- 方式二:使用 Executors(线程池的工具类)调用方法返回不同特点的线程池对象
# ThreadPoolExecutor 构造器的参数说明
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
2
3
4
5
6
7
- 参数一:指定线程池的线程数量(核心线程):
corePoolSize【不能小于0】 - 参数二:指定线程池可支持的最大线程数:
maximumPoolSize【最大数量 >= 核心线程数量】 - 参数三:指定临时线程的最大存活时间:
keepAliveTime【不能小于0】 - 参数四:指定存活时间的单位(秒、分、时、天):
unit【时间单位】 - 参数五:指定任务队列:
workQueue【不能为null】 - 参数六:指定用哪个线程工厂创建线程:
threadFactory【不能为null】 - 参数七:指定线程忙,任务满的时候,新任务来了怎么办:
handler【不能为null】
线程池常见面试题
Q:临时线程什么时候创建啊?
A:新任务提交时发现核心线程都在忙,任务队列也满了,并且还可以创建临时线程,此时才会创建临时线程。
Q:什么时候会开始拒绝任务?
A:核心线程和临时线程都在忙,任务队列也满了,新的任务过来的时候才会开始任务拒绝。
# 6.3 线程池处理任务
ThreadPoolExecutor 创建线程池对象示例:
ExecutorService pools = new ThreadPoolExecutor(
3, 5, 8,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(6),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
2
3
4
5
6
ExecutorService 的常用方法:
| 方法名称 | 说明 |
|---|---|
void execute(Runnable command) | 执行任务/命令,没有返回值,一般用来执行 Runnable 任务 |
Future<T> submit(Callable<T> task) | 执行任务,返回未来任务对象获取线程结果,一般拿来执行 Callable 任务 |
void shutdown() | 等任务执行完毕后关闭线程池 |
List<Runnable> shutdown | 立刻关闭,停止正在执行的任务,并返回队列中未执行的任务 |
- 区分好
execute和submit这两个常用的。
新任务拒绝策略:
| 策略 | 详解 |
|---|---|
| ThreadPoolExecutor.AbortPolicy | 丢弃任务并抛出 RejectedExecutionException 异常。是默认的策略 |
| ThreadPoolExecutor.DiscardPolicy: | 丢弃任务,但是不抛出异常 这是不推荐的做法 |
| ThreadPoolExecutor.DiscardOldestPolicy | 抛弃队列中等待最久的任务 然后把当前任务加入队列中 |
| ThreadPoolExecutor.CallerRunsPolicy | 由主线程负责调用任务的 run() 方法从而绕过线程池直接执行 |
示例:
Runnable target = new MyRunnable();
pools.execute(target);
int[] nums = {1, 2, 3};
Callable<Integer> accumulator = new Accumulator(nums);
Future<Integer> ft = pools.submit(accmulator);
System.out.println(ft.get());
2
3
4
5
6
7
# 6.4 Executors 工具类实现线程池
Executors:线程池的工具类通过调用方法返回不同类型的线程池对象。
| 方法名称 | 说明 |
|---|---|
| public static ExecutorService newCachedThreadPool() | 线程数量随着任务增加而增加,如果线程任务执行完毕且空闲了一段时间则会被回收掉。 |
| public static ExecutorService newFixedThreadPool(int nThreads) | 创建固定线程数量的线程池,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程替代它。 |
| public static ExecutorService newSingleThreadExecutor () | 创建只有一个线程的线程池对象,如果该线程出现异常而结束,那么线程池会补充一个新线程。 |
| public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) | 创建一个线程池,可以实现在给定的延迟后运行任务,或者定期执行任务。(可以用来做定时器) |
- 注意:Executors的底层其实也是基于线程池的实现类 ThreadPoolExecutor 创建线程池对象的。
Executors 使用可能存在的陷阱:大型并发系统环境中使用Executors如果不注意可能会出现系统风险:
newFixedThreadPool和newSingleThreadExecutor允许请求的任务队列长度是 Integer.MAX_VALUE,可能出现 OOM 错误( java.lang.OutOfMemoryError )newCachedThreadPool和newScheduledThreadPool创建的线程数量最大上限是Integer.MAX_VALUE,线程数可能会随着任务1:1增长,也可能出现OOM错误( java.lang.OutOfMemoryError )

# 7. 定时器
定时器是一种控制任务延时调用,或者周期调用的技术。作用:闹钟、定时邮件发送。
定时器的实现方式:
- 方式一:Timer
- 方式二: ScheduledExecutorService
# 7.1 Timer 定时器
| 构造器 | 说明 |
|---|---|
| public Timer() | 创建Timer定时器对象 |
| 方法 | 说明 |
|---|---|
| public void schedule(TimerTask task, long delay) | delay 后执行 TimerTask 任务,只执行一次 |
| public void schedule(TimerTask task, long delay, long period) | 开启一个定时器,按照计划处理 TimerTask 任务,执行多次 |
存在的问题:
- Timer 是单线程,处理多个任务按照顺序执行,存在延时与设置定时器的时间有出入
- 可能因为其中的某个任务的异常使 Timer 线程死掉,从而影响后续任务执行。
存在问题的示例:
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("执行 A~~" + new Date());
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, 0, 2000);
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("执行 B~~" + new Date());
}
}, 0, 2000);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
打印结果为:
执行 A~~Sun Jan 30 15:36:50 CST 2022
执行 B~~Sun Jan 30 15:36:53 CST 2022
执行 A~~Sun Jan 30 15:36:53 CST 2022
执行 A~~Sun Jan 30 15:36:56 CST 2022
执行 B~~Sun Jan 30 15:36:59 CST 2022
....
2
3
4
5
6
- 分析结果的时间就可以看出,本应计划同时进行的 A、B 两个任务,却错开了,因为本应该到了执行 B 的时间,却由于在执行 A 而导致延迟了。
# 7.2 ScheduledExecutorService 定时器
ScheduledExecutorService 是 jdk1.5中引入了并发包,目的是为了弥补 Timer 的缺陷, ScheduledExecutorService 内部为线程池。
| Executors 的方法 | 说明 |
|---|---|
| public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) | 得到线程池对象 |
| ScheduledExecutorService 的方法 | 说明 |
|---|---|
| public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit) | 周期调度方法 |
优点:基于线程池,某个任务的执行情况不会影响其他定时任务的执行。
示例:
// 1. 创建线程池作为定时器
ScheduledExecutorService pool = Executors.newScheduledThreadPool(3);
// 2. 开启定时任务
pool.scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "执行 A~~" + new Date());
}
}, 0, 2000, TimeUnit.MILLISECONDS);
pool.scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "执行 B~~" + new Date());
}
}, 0, 2000, TimeUnit.MILLISECONDS);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
结果输出:
pool-1-thread-1执行 A~~Sun Jan 30 15:50:05 CST 2022
pool-1-thread-2执行 B~~Sun Jan 30 15:50:05 CST 2022
pool-1-thread-2执行 A~~Sun Jan 30 15:50:07 CST 2022
pool-1-thread-1执行 B~~Sun Jan 30 15:50:07 CST 2022
2
3
4
- 这时便不会出现 Timer 出现过的问题了,A、B 两个任务都可以按计划执行了。