 ELMo
ELMo
# 1. Contextualized Word Embedding
很多词存在一词多义的情况,为了应对这种情况,出现了 Contextualized Word Embedding,它期待说:
- Each word token has its own embedding (even though it has the same word type)
- The embeddings of word tokens also depend on its context.
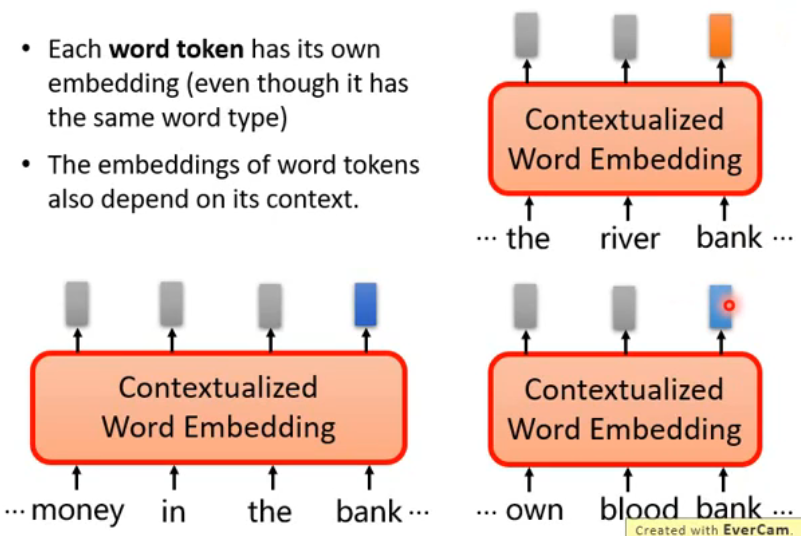
- 比如说,下面两个句子中的 bank 的含义可能比较相近,他们的 Embedding 也会很相近;但是右边上下的两个句子的 bank 的含义可能就不太一样了,这时他们的 Embedding 也会差距很大。
# 2. ELMo
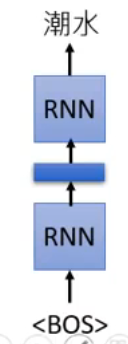
ELMo 是一个 RNN-based 的 Language Model。什么是 RNN-based language model:它是从大量 sentences 中训练出来的。比如你有一句话“潮水 退了 就 知道 谁 没穿 裤子”,那么就要教给它如果看到一个 begin token <BOS>,那就要输出“潮水”:
接下来再输入“潮水”这个 token,你就要输出“退了”这个 token:
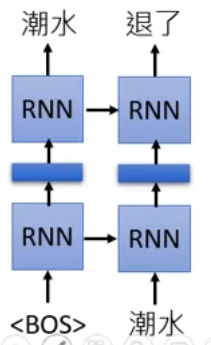
看到“潮水”和“退了”这两个 token,就要输出“就”….. 然后一直重复下去:
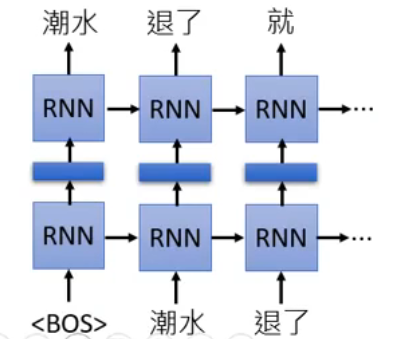
这样用很多 sentences 学完之后,你就有 Contextualized Word Embedding 了!你可以直接把 RNN 的 hidden layer 拿出来,说它就是当前输入的那个 token 的 Contextualized Word Embedding,比如下图输入“退了”之后,标红的那一部分:
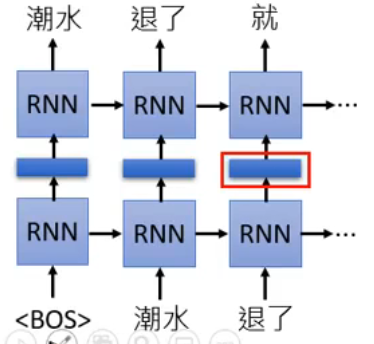
为什么说它是 Contextualized 呢?因为如果你给它不同的 context 的句子,那它输出的 embedding 是不同的。
以上就是 ELMo 的基本概念。但上面这种方式只考虑了每个 token 的前文,没有考虑到后文,这时只需要再训练一个反向的 RNN 就好了:
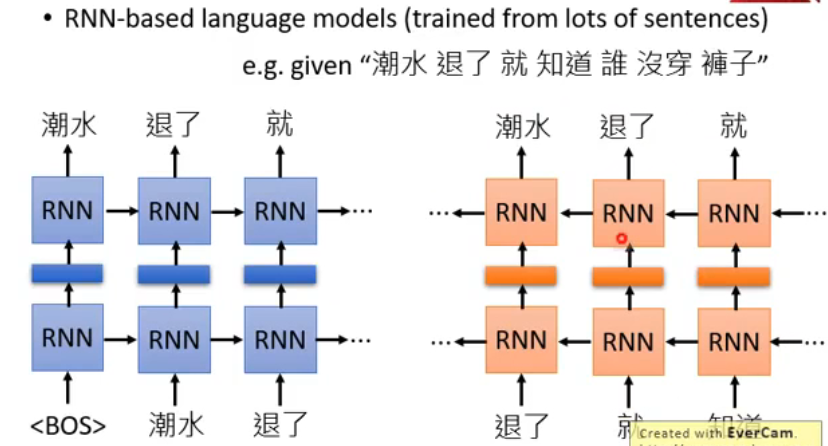
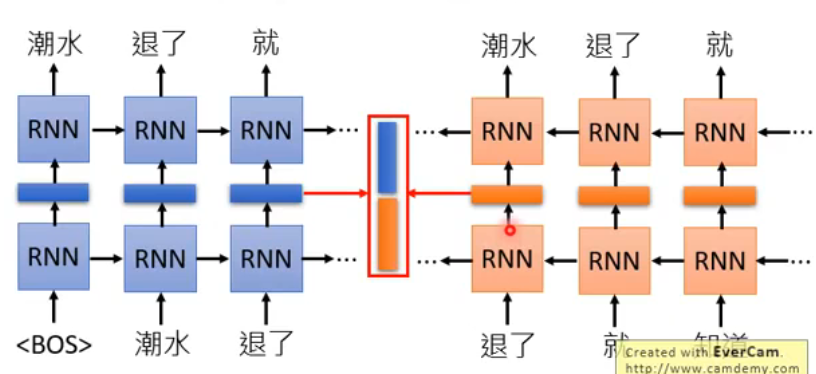
现在我们为了得到“退了”这个 token 的 embedding,就要把两个方向的 RNN 的 hidden layer 都拿出来:
现在很多模型都是 Deep 的,ELMo 也是 deep 的,它有很多层的 RNN:
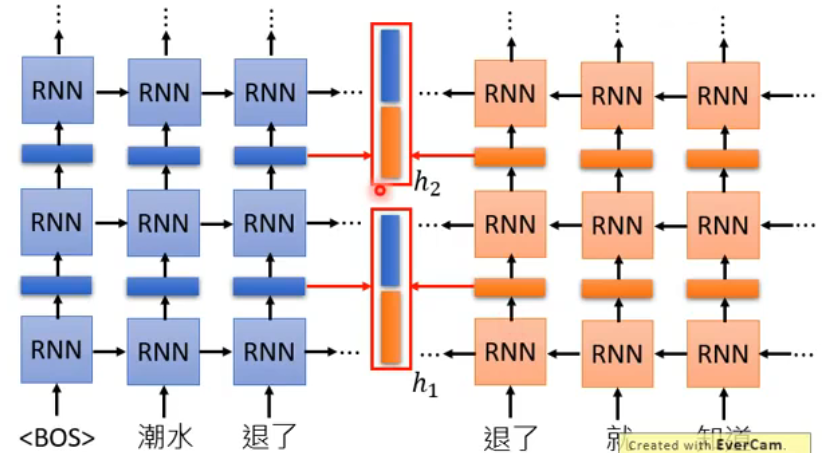
但现在遇到的问题是,它有这么多层 RNN,每一层都有一个 embedding,那到底应该用哪一层的呢?ELMo 给出的 solution 就是:“我全都要!”
每次给 ELMo 一个 token,它会得到好多个 contextualized word embedding(每一层 RNN 都会得到),这时怎么办呢?就可以把每一个 embedding 统统加起来一起用,ELMo 具体的做法是 weighted sum:
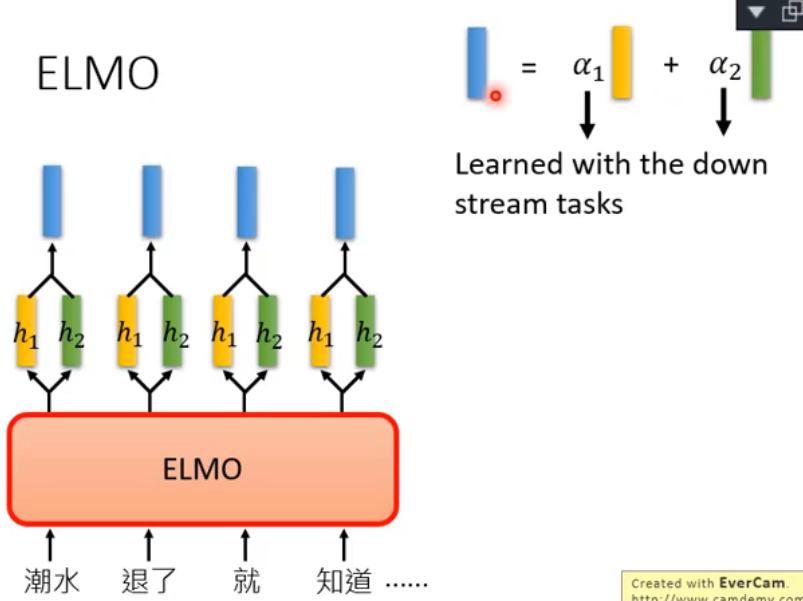
- 黄色和绿色代表同一个 token 的不同 contextualized word embedding,ELMo 通过
- 这里的 weights
所以这里不同的 downstream tasks 用到的 weights
原论文展示了一下训练结果:
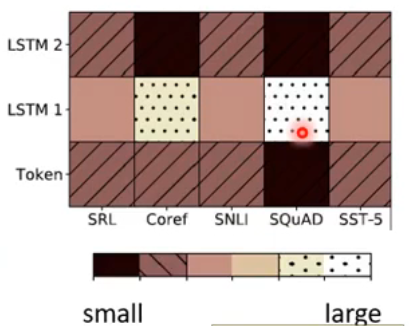
- 横轴代表不同的 task,纵轴是不同层的