强化学习
强化学习
之前所讲的技术基本上都是基于 Supervised Learning,它们的数据都有一个 label,但在 RL 里面就是要面对另一个问题:机器当给我们一个 input 的时候,我们不知道最佳的 output 应该是什么。比如下围棋,面对一个盘势,怎样的下一步是最好的答案是不知道的(尽管一些棋谱中能给出较好的答案),在这个你不知道正确答案是什么的情况下,往往就是 RL 可以派上用场的时候。
但是 RL 在学习时,机器也不是一无所知的,我们虽然不知道正确的答案是什么,但机器会知道什么是好,什么是不好,机器会与环境互动,得到一个叫做 reward 的东西。藉由知道什么样的输出是好的,什么是不好的,机器还是可以学出一个模型。
本章的 Outline:
我们想说的是 RL 也跟 Machine Learning 一样也是三个步骤,具有相同的框架,不要觉得难学。
# 1. What is RL?
# 1.1 相关概念
我们已经说了 Machine Learning 就是找一个 function,RL 同样也是如此。
在 RL 里面,会有一个 Actor,还有一个 Environment,这个 Actor 与 Environment 会进行互动:
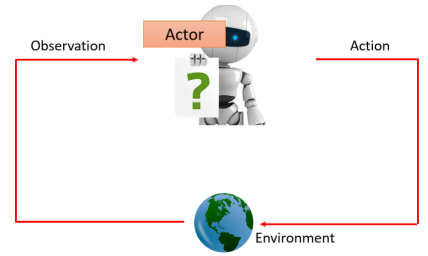
- Environment 会给 Actor 一个 Observation 作为输入;
- Actor 看到 Observation 后会有一个输出 Action,这个 Action 会去影响 Environment;
- Actor 采取 Action 后,Environment 会给予一个新的 Observation;
这里的 Actor 本身就是一个 function,是我们所要找的 function,其输入是 Environment 给它的 Observation,输出是这个 Actor 要采取的 Action,在这个互动过程中,Environment 会不断地给 Actor 一些 Reward,来告诉它说这个 Action 是好的还是不好的。要找的 Actor 这个 function 就是最大化最终得到的 Reward 的总和。
# 1.2 Example: Playing Video Game
拿 Space Invader 这个简单的小游戏来作为例子。最早的几篇 RL 的论文都是让机器去玩 Space Invader 这个游戏。
Space Invader:
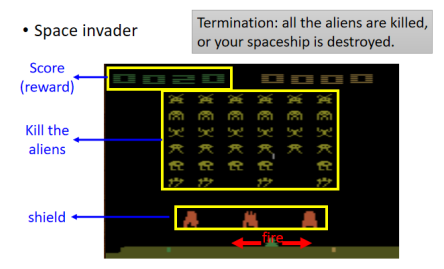
- 要操控的是下面的绿色太空梭,可以采取的 Action 有三个:左移、右移和开火,要做的就是杀掉画面上的外星人。
- 开火几种黄色的外星人的话,外星人就死掉了。
- 你前面橙色的东西是防护罩,你不小心打到它也会使它减小,也可以躲在它后面抵挡外星人的攻击。
- 杀死外星人或者打掉最上面的补给包会奖励 score,这个 score 就是 Environment 给我们的 Reward。
- 游戏的终止条件:外星人都被杀光或者你的母舰被外星人击中。
如果要用 Actor 去玩 Space Invader:
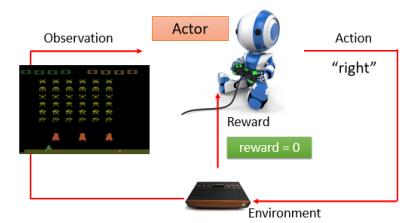
Actor 坐在一个人的角度去操控摇杆,Environment 就是游戏的主机,Observation 是游戏的画面,Action 是向左、向右和开火三种可能的行为之一,得到的 score 就是 Reward。游戏画面改变的时候,就代表有了新的 Observation 进来,此时你的 Actor 就会决定采取新的 Action。
我们的目标就是 learn 出一个 Actor,它可以在玩这个游戏时得到的 Reward 总和是最大的。
# 1.3 Example: Learning to play Go
实如果把 RL 拿来玩围棋,那你的 Actor 就是就是 AlphaGo,Environment 就是 AlphaGo 的人类对手。
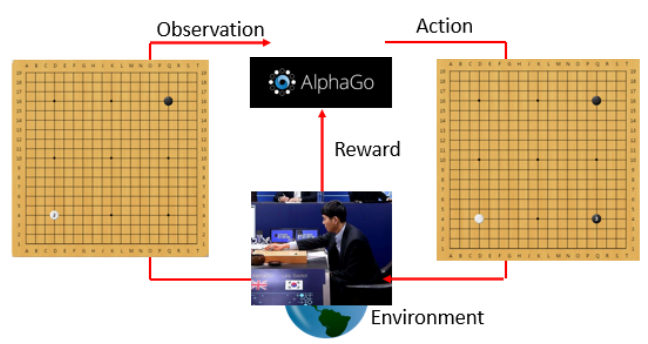
在下围棋里面,Actor 所采取的行为几乎没有办法得到任何 Reward,而是定义说如果赢了就得到 1 分,输了就得到 -1 分。
# 1.4 RL 的三个步骤
课程一开始就说了 Machine Learning 就是三个步骤:
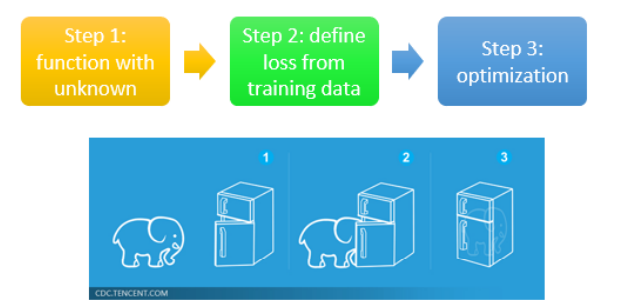
- 有一个 function,里面有一些未知的 params,这些未知数是要被找出来的;
- 定一个 loss function
- Optimization:想办法找出未知 params 去最小化 loss
其实 RL 也是一样的三个步骤,分别来看一下。
# 👣 Step 1:Function with Unknown
这里有未知数的 function 就是 Actor,这个 Actor 就是一个 Network,现在通常叫它 Policy Network。
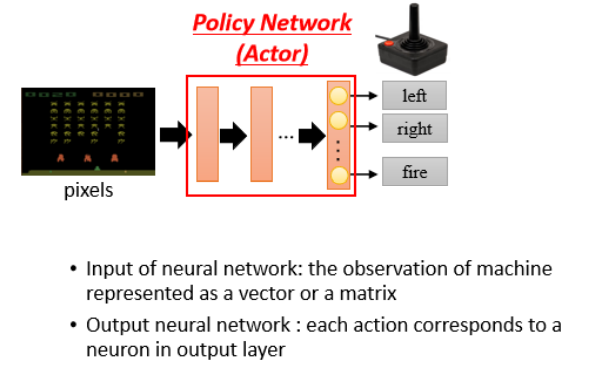
这个 Network 会给每个可能的 Action 输出一个得分,且这些得分总和为 1:
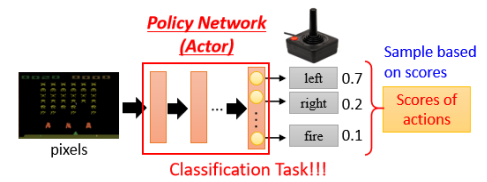
至于这个 Network 的架构,可以你自己去设计,它可以是 CNN,也可以是 RNN 甚至是 Transformer 等。
在最后机器在决定采取哪一个 Action 时取决于输出的每一个 Action 的分数。常见的做法是把这个分数当做一个概率,然后按照这个概率去 Sample,从而随机决定要采取哪一个 Action。比如上图中,“向左”得到 0.7 分,那就有 70% 的几率采取这个 Action。采取 Sample 这种思路的好处是机器的每一次所采取的行为会略有不同,不至于太死板。比如你剪刀石头布时,总出石头也会被打爆。
# 👣 Step 2:Define “Loss”
在 RL 里面,loss 长什么样呢?我们先看一下互动的过程。
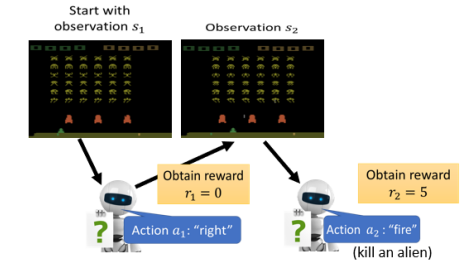
- 初始游戏画面 Observation
不断刚刚的过程直到机器采取某个 Action 后游戏结束了,那从游戏开始到结束的这整个过程称为一个 Episode。整个游戏过程所有得到的 Reward 累加称为 Total Reward,也称为 Return。
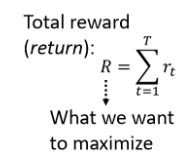
这里目标是 Total Reward 越大越好,但 loss 是越小越好,所以在 RL 的情景下,我们可以把 Total Reward 取负号当做我们的 loss。
# 👣 Step 3:Optimization
Actor 与 Environment 互动的过程再用图表示一次如下:
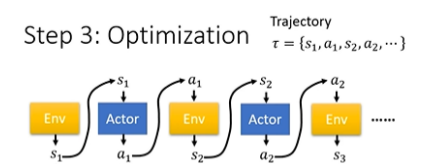
Reward
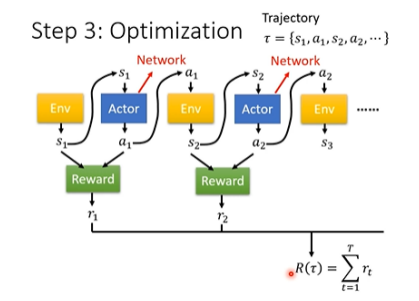
整个 Optimization 的过程就是找一个 Network 的参数,让产生出来的 Return
- 第一个问题是,Actor 的 output 具有随机性。因为其输出的 Action 是 sample 产生的,如果把整个 Environment、Actor 和 Reward 合起来当成一个巨大的 network 来看待,那这个 network 可不一般,它里面的某一层 layer 每次产生的结果是不一样的。
- 另一个更大的问题是,你的 Environment 和 Reward 根本就是 network,他们只是一个黑盒子而已,你根本不知道里面发生了什么事。刚刚所说的 Reward 是明确的一条规则,但更麻烦的是在一些 RL 问题中,Reward 与 Env 都是具有随机性的。比如在电玩的应用中,同样的 Action,游戏机到底给你怎样的回应是有乱数的。
目前一般的 gradient descent 还无法训练这个 network 来找出 Actor 来最大化 Return。所以 RL 真正难点在于怎么解这个 Optimization 问题。这就是 RL 跟一般的 ML 不一样的地方。
但我们还是可以把 RL 看成三个阶段,只是 maximize reward 时跟以前的方法有点不一样。
# 2. Policy Gradient
RL 中用来解 Optimization 的一个常用演算法是 Policy Gradient。
# 2.1 How to control your actor
在讲 Policy Gradient 之前,我们先来看看怎样操控一个 Actor 的输出,即怎样让一个 Actor 在看到某一个特定 Observation 时采取一个特定的 Action。
这其实可以想成一个分类的问题,比如让 Actor 输入 s,输出是
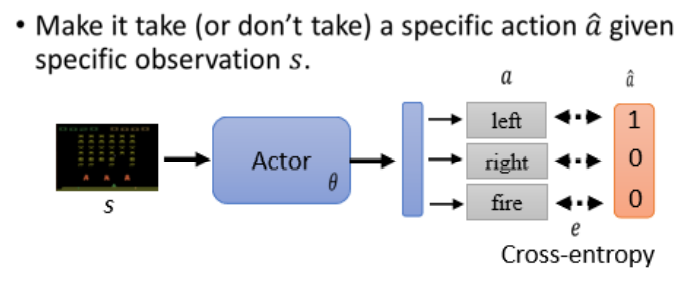
假设你希望 Actor 采取
但假设你还想让你的 Actor 不要采取某个行为,比如输入
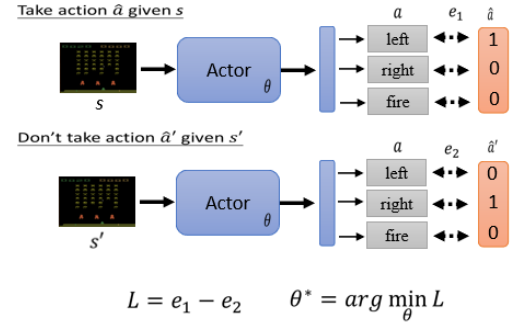
这个过程就像在 train 一个 classifier 一样,用于去控制 Actor 的行为,而且这一部分的过程就是 Supervised Learning,等下会看到它与一般的 Supervised Learning 有啥区别。
所以我们要 train 一个 Actor,其实就是需要收集一些训练资料,这个训练资料说希望在

甚至还可以更进一步,可以说每一个行为并不是只有好或者不好,而是有程度区别的,有非常好的,有 nice to have 的,有 a little bad 的,有非常差的。所以我们现在给每一个
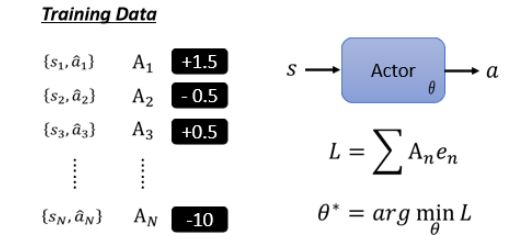
- 比如说看到
- 比如说看到
所以我们透过
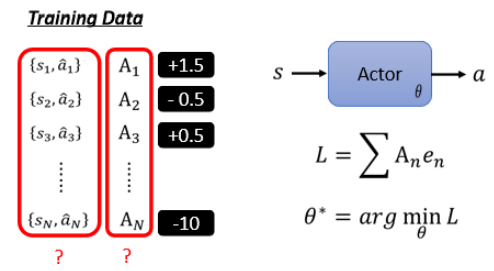
接下来的难点就是怎样定出
# 2.2 不同 version 的 idea
之前所看到流程与 Supervised Learning 没什么不同,接下来的重点是怎么定义 A。
# 2.2.1 Version 0
先说一个最简单的版本,其实也是不怎么正确的版本。助教的 sample code 就是这个版本。
首先还是需要收集一些训练资料,就是需要收集 s 和 a 的 pair。怎么收集呢?你需要先有一个 Actor 与 Env 互动,就可以收集到 s 与 a 的 pair。
一开始 Actor 是随机的东西,然后把它每一个 s 执行的行为 a 记录下来,这个过程通常要让 Actor 与 Env 做多个 Episode,然后就可以收集到足够的资料。比如助教的 sample code 就是跑了 5 个 Episode。
接下来我们需要去评价每一个 action 到底是好还是不好,评价完后既可以拿这个评价结果来训练我们的 Actor。怎样评价呢?之前说过我们用
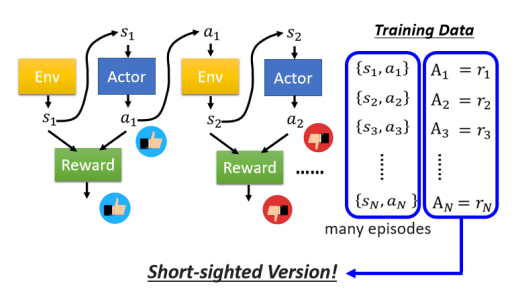
之所以说这是一个不好的版本,是因为这样得到的 Network 是一个短视近利的 Actor,它只知道会一时爽,完全没有长程规划的概念。比如在 Space Invader 游戏中,只有 “fire” 才会得到 reward,那训练的 Actor 将会倾向于一直开火。
我们知道说说每一个行为其实都会影响互动接下来的发展,所以说每一个行为并不是独立的,每一个行 为都会影响到接下来发生的事情。我们今天在与 Env 互动时,有一个问题是 Reward Delay,就是有时候你需要牺牲短期的利益以换取更长程的目标。
接下来我们正式进入 RL 的领域,来看看真正的 Policy Gradient 是怎么做的。
# 2.2.2 Version 1
在 Version 1 里,
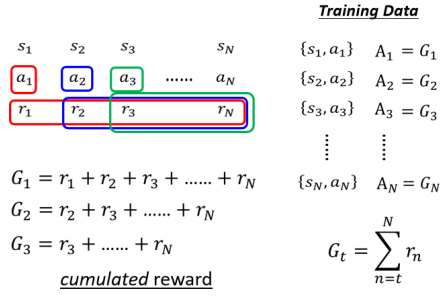
这里的
但仔细想想会发现,这个 version 也有问题。假设这个游戏非常长,你把
# 2.2.3 Version 2
Version 2 的 Cumulated Reward 用
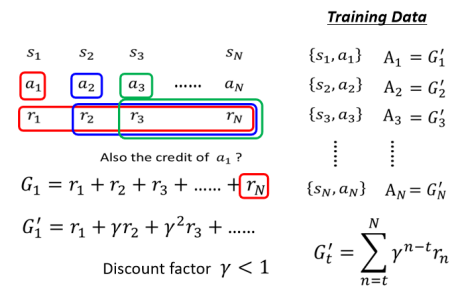
这个方法把距离
像围棋这种游戏结尾才有分数的游戏,可以这样做:采取一连串 action,只要最后赢了,这一串的 action 都是好的,如果输了,这一连串的 action,通通都算是不好的。你也能感觉出来这很难 train,确实很难 train,最早版本的 AlphaGo 就是这样 train 的。
# 2.2.4 Version 3
好和坏是相对的,比如你一门课考了 60,这好不好呢,需要看别人都得了多少分,如果别人都是三四十分,那你就是最好,如果别人都是八九十分,那你就很不厉害,所以 reward 这个东西是相对的。
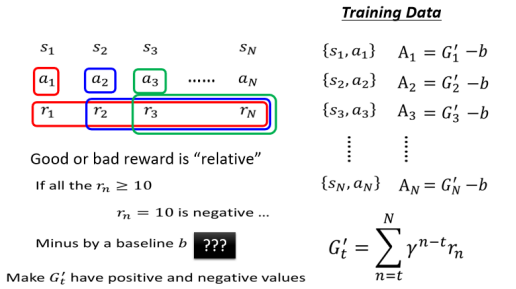
如果我们只是单纯地算
# 2.3 Policy Gradient 怎么操作?

首先给你的 Actor 一个 random params
这里有一个很神奇的地方,一般的 training 的 data collection 是 for 循环外,比如说我有一堆资料,然后用他们来做 training,来做 update model,最后得到一个收敛的参数,然后拿这个参数来做 testing。但在 RL 里不是这样,你 data collection 的过程是在 for 循环里面的:

这样假设你打算跑 for 循环 400 次,那你就得收集资料 400 次,一旦更新完一次参数以后,接下来你就要重新去收集资料了。用图形化的方式表示如下图:
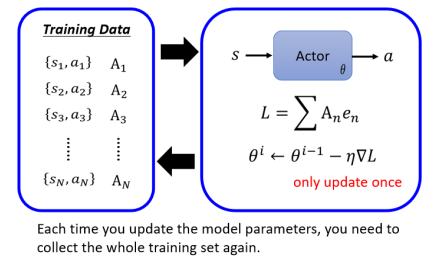
为什么不能事先收集资料,而是每次 update network 后就要重新再收集资料呢?这边一个比较简单的比喻是”一个人的食物,可能是另外一个人的毒药“,由
# 2.4 On-policy v.s. Off-policy
刚刚我们说的这个训练的 Actor 跟要拿来跟环境互动的 Actor 是同一个,这种情况叫做 On-policy Learning。刚刚所示范的 Policy Gradient 的 algorithm 就是 On-policy 的 learning。还存在另外一种状况叫做 Off-policy Learning。
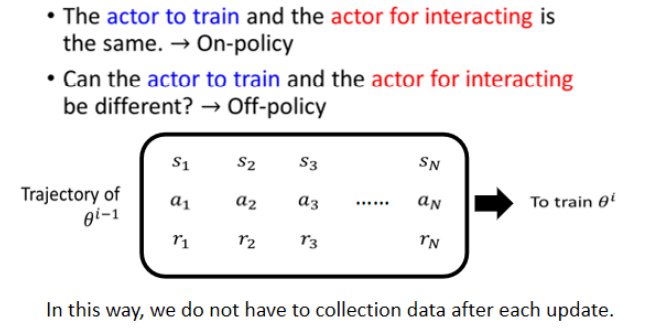
这里不再细讲 Off-policy 的 learning,Off-policy 的 Learning 期待能够做到的事情是让要训练的 Actor 与跟环境互动的 Actor 是分开的两个 Actor,也就是解决让训练的 Actor 能不能根据其他 Actor 跟环境互动的经验来进行学习的问题。
Off-policy 有一个非常显而易见的好处是你就不用一直收集资料了,它可以做到收集一次资料就 update 参数很多次。毕竟每轮 iteration 都重新收集资料是导致训练时间慢的一个重要原因。
有一个经典的 Off-policy 的方法 —— Proximal Policy Optimization,缩写是 PPO,这也是蛮强的一个方法。Off-policy 的重点就是:你在训练的那个 Network 要知道自己跟别人之间的差距,它要有意识的知道说它跟环境互动的那个 Actor 是不一样的。比如美国队长克里斯伊凡追女孩的方法只需要一个表白,而你就不一样了。具体的细节做法可以参考过去上课的录影。
# 2.5 Collection Training Data: Exploration
还有一个重要的概念叫做 Exploration,指的是今天这个 Actor 在采取行为时是有一些随机性的。而这个随机性其实非常地重要,很多时候你随机性不够,你会 train 不起来。举一个最简单的例子,假设你一开始初始的 Actor 永远都只会向右移动,如果它从来没有采取开火这个行为,它就永远不知道开火这件事情到底是好还是不好,它只有做了这件事,我们才能评估这个 action 好还是不好。
所以你今天在训练的过程中,这个拿去跟环境的互动的这个 Actor 本身的随机性是非常重要的。你其实会期待说跟环境互动的这个 Actor 随机性可以大一点,这样我们才能够收集到比较丰富的资料,防止出现有一些状况的 reward 是从来不知道的。为了要让这个 Actor 的随机性大一点,甚至你在 training 的时候,你会刻意加大它的随机性。
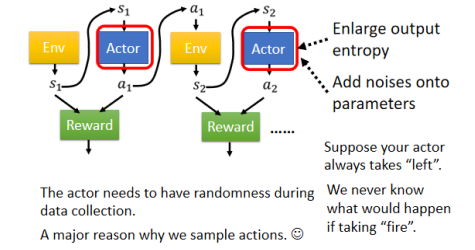
比如说 Actor 的 output 本来是一个 distribution,有人会刻意加大这个 distribution 的 entropy,让它在训练时比较容易 sample 到那些几率比较低的 action。或者有人在 Actor 的 parameters 上加 noise,让它每一次采取的 action 都不一样。这个过程就是 Exploration,它是 RL training 中一个非常重要的技巧。
# 3. Actor-Critic
# 3.1 What is Critic
上一部分我们讲的是 learn 一个 Actor,这一部分我们要 learn 的是一个 Critic。我们会解释这个 Critic 是什么以及对 learn Actor 有什么帮助。
Critic 的工作就是用来评估一个 Actor 的好坏。比如说你有了一个参数为
Critic 有多种变形,有的只看游戏画面来判断,有的时看到一个游戏画面和 Actor 所要采取的一个 action 来估计接下来会得到多少 Reward。
一种具体的 Critic 叫做 Value Function,记作
- Critic: Given actor
- Value function
要得到 discounted cumulated reward,你可以直接透过把游戏玩到底,看看最后它到底会得到的
有多少。但这个 Value Function 的能力就是它要未卜先知,未看先猜,游戏还没玩完,只光看到 s 就要预测这个 Actor 可以得到什么样的表现。
举个例子,你给 Value Function 下面的游戏画面,由于里面还有很多 aliens,如果是一个好的 Actor,那接下来应该能得到很多的 reward:
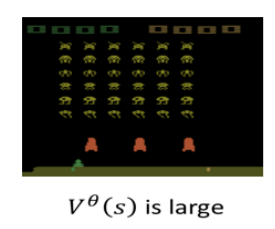
如果看到下面这个游戏中盘的画面,这时 aliens 没多少了,那得到的 reward 应该也较少:
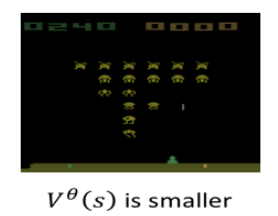
Value Function
# 3.2 How to estimate
在讲 Cirtic 怎样被使用之前,我们先讲一下 Critic 怎样被训练出来的。有两种常用的训练的方法,一种是 Monte Carlo Based 的方法,一种是 Temporal-Difference 的方法。
# 3.2.1 💡 Monte-Carlo(MC) based approach
如果是用 MC 的方法的话,你就把 Actor 拿去跟环境互动,从而得到一些游戏记录,这就是一笔 Value Function 的训练资料,这笔资料告诉它说,如果你看到
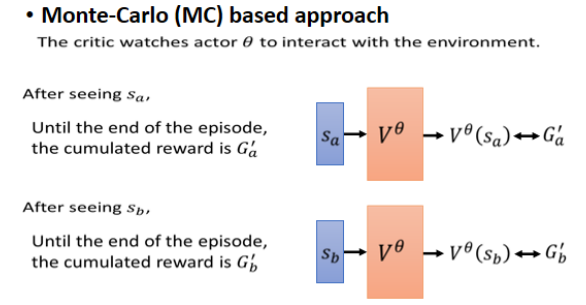
这个方法很符合直觉,你就去观察 Actor,会得到的 cumulated reward,那观察完你就有训练资料,直接拿这些训练资料来训练 Value Function。这就是 MC 的方法。
# 3.2.2 💡 Temporal-difference(TD) approach
Temporal-Difference 的方法缩写是 TD,它希望做的事情是不用玩完整场游戏才能得到训练 Value Function 的资料。在 MC 方法中需要玩完整场游戏才能得到一笔训练资料,但有的游戏很长甚至根本不会结束,这时就适合用 TD 的方法。
先看一下
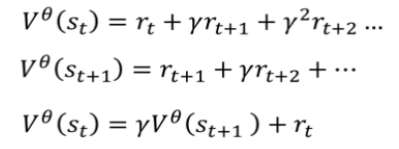
可以看到对于 function
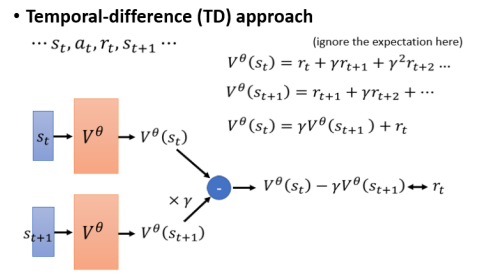
上图什么意思呢?假设我们有一笔资料,我们把
# 3.2.3 MC v.s. TD
对同样的训练资料、同样的 Actor

- 我们知道
- 但计算
两种计算方法都没有错,只是看待的角度不同。
# 3.3 Version 3.5
Critic 怎样用于训练 Actor 呢?我们在讲训练 Actor 时说让它跟 Env 互动得到一堆
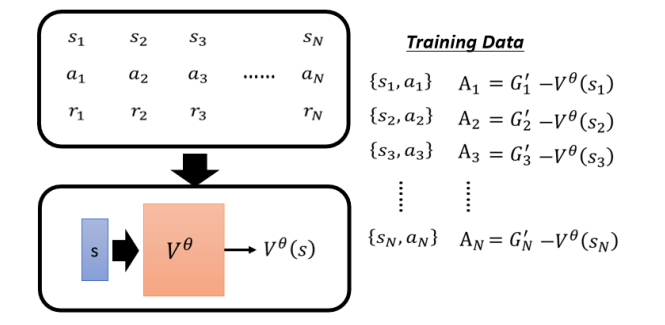
为什么减掉 V 是一个合理的选择呢?我们已经知道
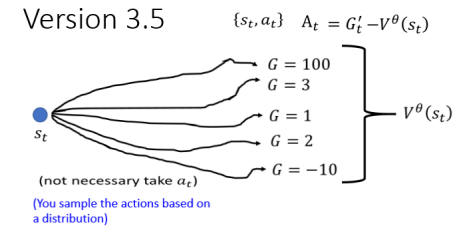
- 如果
- 如果
所以这就是为什么应该把
# 3.4 Version 4
所要讲的最后一个版本就是拿平均去减掉平均。
在执行完
- 如果
- 如果
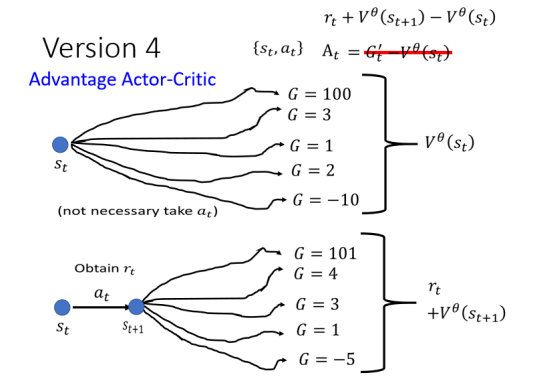
这个方法就是大名鼎鼎的一个常用方法,叫做 Advantage Actor-Critic,在这里面,
# 3.5 Tip of Actor-Critic
讲一个训练 Actor-Critic 的小技巧,这可以用到作业里面。
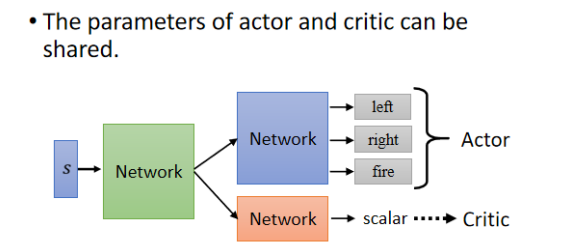
Actor 和 Critic 都是 network,它们都把 Observation 当作 input,Actor 的 output 是每一个 action 的分数,Critic 的 output 是一个数值,代表估计的接下来会得到的 cumulated reward。可以发现,这两个 network 的 input 是一样的东西,它们应该有部分参数可以共用,比如当 input 是一个 image 时,那前面几层应该都需要 CNN 来提取这个游戏画面的信息吧。
所以 Actor 与 Critic 可以共用前面几个 layer,后面的才不一样了。这是一个训练 Actor-Critic 的小技巧。
# 3.6 Outlook: Deep Q Network(DQN)
其实在 RL 里还有一种犀利的做法:直接采取 Critic 就可以决定用什么样的 Action。其中最知名的就是 Deep Q Network (DQN),这里不再展开,可以参考过去上课录影。
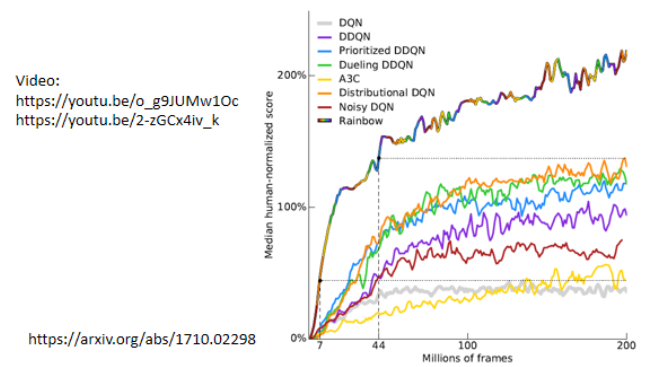
曾经有一篇很知名的 paper,叫 Rainbow,它尝试了七种 DQN 的变形,然后把它们集合起来,对比起来就像一个 rainbow:
# 4. Reward Shaping
# 4.1 What is Reward Shaping?
当我们让 Actor 与 Env 做互动时,会整理所得到的 reward 并计算出
If
这种问题的解决方法是:The developers define extra rewards to guide agents. 也就是我们在额外定义一些 reward 来帮助我们的 Actor 去学习,这就是 Reward Shaping。比如让你读博士,博士毕业才得到 reward 的话,那这段路会好长好长,但如果再定义一些额外的 reward,比如修完一门课得到一些 reward,做完一个专题得到一些 reward,发一篇 paper 得到一些 reward,那一步一步地你也就博士毕业了。
# 4.2 Example: VizDoom
有一个游戏叫做 VizDoom,规则是你被击中就掉分,击中别人就得分,现在我们做 reward shaping:

- 比如看第二行,当健康值下降时,将 reward 定义为负值;第四行,当拾到补给包时就给一些 reward。如果你的 agent 待在原地一动不动,就要扣 reward 从而驱使它运动。
这个过程是需要一些 domain knowledge 的,需要根据专业知识来定义这些 reward。
# 4.3 Curiosity Based 的 Reward Shaping
Curiosity Based 的 Reward Shaping 就是给机器加上好奇心,所谓好奇心就是要去探索新的事物。做法是除了原本的 reward,我们再加入一种新的 reward: Obtaining extra reward when the agent sees something new (but meaningful)。
具体可参见 https://arxiv.org/abs/1705.05363
但注意是看到有意义的新东西,而不是一直去看杂讯。
# 5. No Reward: Learning from Demonstration
在游戏中 reward 很容易定义出来,但在很多实际场景中 reward 是很难定义的。比如在自动驾驶中,很难说闯红灯应该给多少 reward、礼让行人应该给多少 reward。甚至 hand-crafted rewards can lead to uncontrolled behavior,比如你可能让机器人不允许伤害人类,但机器人可能最终做出囚禁人类的行为。
在没有 reward 的情况下让 Actor 与 Env 互动的一种方法叫做 Imitation Learning(模仿学习)。在 Imitation Learning 中,我们假设 Actor 仍然能够与 Env 互动,但不会从中得到 reward。没有了 reward,但我们有了另外一种东西:Demonstration of the expert。
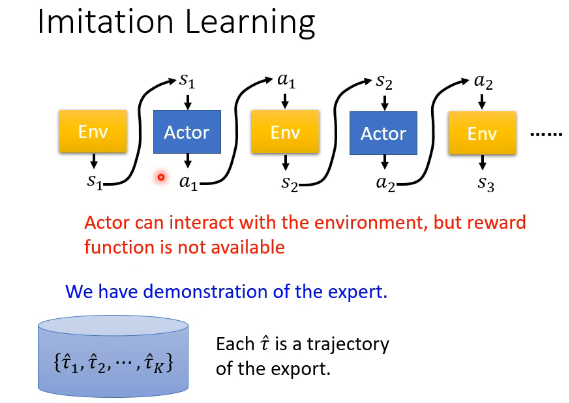
每一个来自 expert 的互动得到的 sequence 记作
Imitation Learning 主要有两种方式:行为克隆(Behavior Cloning)和逆向强化学习(Inverse Reinforcement Learning),下面逐一介绍。
# 5.1 Behavior Cloning
行为克隆是一种十分简单,十分直接的想法。假设我们有许多专家的示例数据:
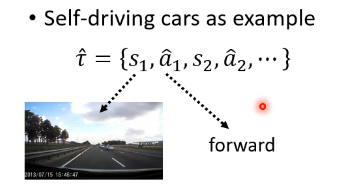
我们得到了这一串专家动作之后,直接丢到一个 Actor 中进行训练,
这种有了 expert 的 demonstration 然后让机器去模仿人类的行为,被叫做 Behavior Cloning。
但这有一个问题:The experts only sample limited observation。比如人类开车转弯几乎不会出现碰撞墙壁等情况,而让机器从这些 behavior 中学习后,它将没有见过这些特殊情况导致其不会去应对。
更严重的问题是,The agent will copy every behavior, even irrelevant actions. 如果机器的学习能力有限时,这会更糟糕,比如一个大佬具有创新性强、不修边幅等特点,而你想去模仿时由于学习能力有限而只学到了不修边幅,那可就糟糕了。
总的来说,Behavior Cloning 本质上是一种 Supervised Learning,在现实应用中,很不靠谱。
# 5.2 Inverse Reinforcement Learning
之前我们说了 reward 很难定义,而本节的 Inverse Reinforcement Learning 就是让机器自己学习出来 reward 的定义。
以往的 RL 是这样做的:
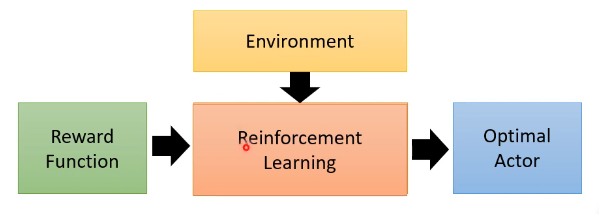
而 Inverse Reinforcement Learning (逆强化学习,IRL) 则是从 expert 的 demonstration 和 Environment 来反推 reward function 应该长什么样子,即 reward function 是 learn 出来的,在有了 reward function 后,就可以用它按照一般的 RL 来 train 我们的 Actor。如下图所示:
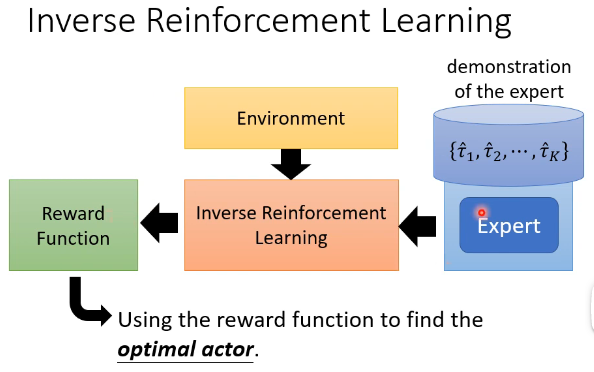
有人可能觉得这个学习出来的 reward function 可能会比较简单,但通过简单的 reward function 而找的 Actor 就一定简单吗?现实中单纯是“活下去”这个 reward function 就能学出千变万化的复杂的 Actor。其实,简单的 reward function 并不代表通过它找到的 Actor 是简单的,甚至是很复杂的。
IRL 的一个基本原则是:The teacher is always the best. 这里的 the best 并不代表说你要去模仿老师的行为,而是说老师的行为一定会取得最高的 reward。基本的思想是:

用图示的方式来展示上面的过程就是:
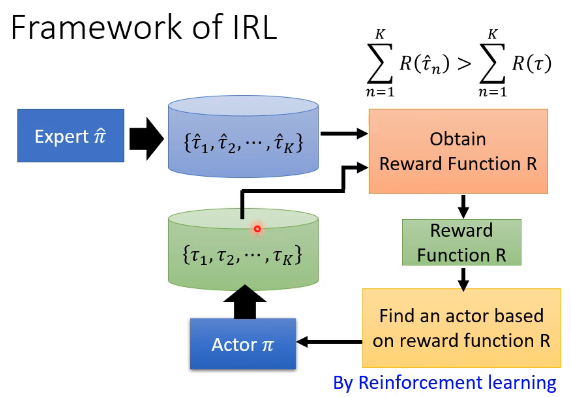
这个过程有没有很熟悉呢?它其实和 GAN 很像,我们可以把 Actor 想象成 GAN 里面的 Generator,把 Reward Function 想象成 Discriminator,两者对比如下:
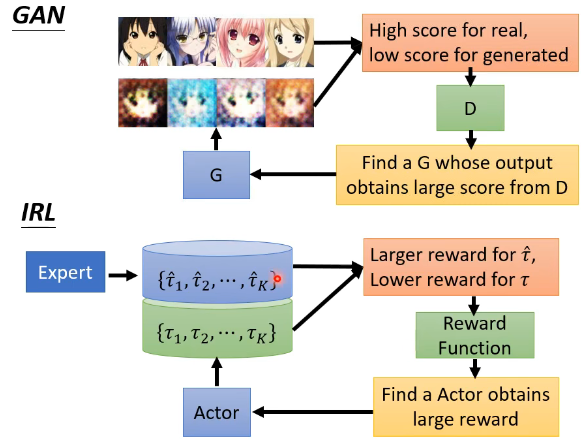
两者对比一下会发现,Generator 尽可能去寻找奖励最大的行为,而 Discriminator 则不断优化奖励函数,让专家的行为和模型的行为区分开来。
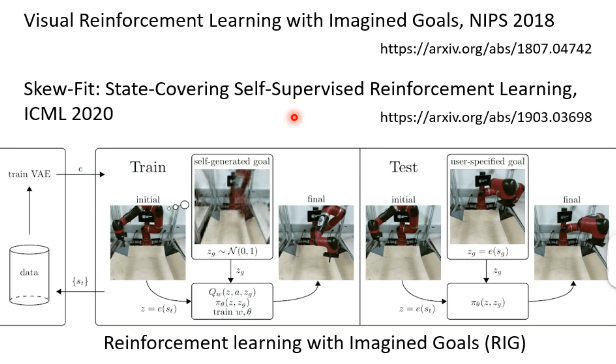
现在还有一个更潮的做法叫做 Reinforcement learning with Imagined Goals (RIG),它是直接给机器一个画面,让机器做出画面中的行为,这里不再细讲了,如下图所示: