 Adversarial Attack
Adversarial Attack
我们已经训练了很多 Network,但要把这些 Network 用在真正应用上,光是它们正确率高是不够的,它们需要能够应付来自人类的恶意,需要在有人试图想要欺骗它的情况下也能得到高的正确率。
举例来说,我们用 Network 来做垃圾邮件过滤,这对于垃圾邮件的发送者而言,也会想尽办法(比如更改邮件部分内容)欺骗 Network 来避免他的邮件被分为垃圾邮件。
# 1. Example of Attack
向 Network 输入一张 image,他可以告诉我们这张 image 的 class。今天我们要做的是在 image 上加入一个非常小的杂讯,最好小到人肉眼没有办法看出来,这个被加了杂讯的 image 叫做 Attacked Image,没有被加杂讯的 image 叫做 Benign Image。
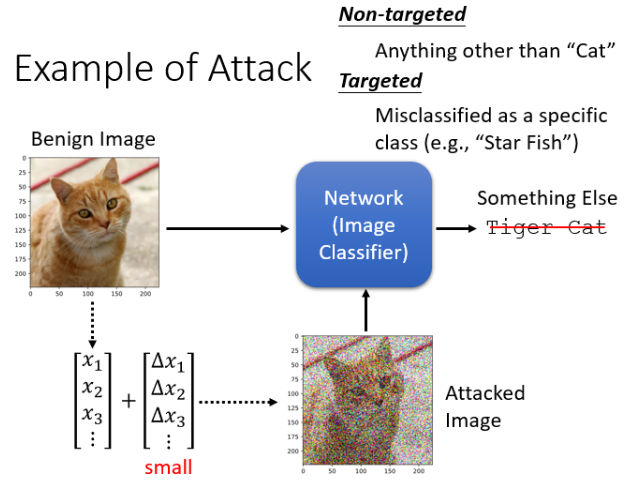
Benign Image 丢到 network 里面输出的是 cat,如果我们是攻击方,那我们会希望 Attacked Image 丢进去后输出的不可以是 cat。
攻击大致可以分成两种类型:
- Non-targeted Attack:原来的答案是 cat,只要你能够让 Network 的 output 不是 cat 就算成功了;
- Targeted Attack:我们希望 Network 的 output 不仅不是猫,还要必须是别的某个特定东西,比如必须判断为“海星”才算成功。
我们真的有可能做到,在加入一个肉眼看不到的杂讯后会改变 Network 的输出吗?这是有可能的:

- 上图左边可以识别出是 cat,但加入一个你看不到的杂讯变成右边的图片后,Network 竟然有 100% 的信心说这是一个 star fish。这说明人看不到的一个微小改变,对 ResNet 而言却有了天差地远的输出。
- 在另一个实验中,加入一个肉眼看不到的杂讯后,ResNet 也竟然有 98% 的信心说这是一个 keyboard。
那有人可能会觉着发生这种离谱的行为,会不会是因为这个 Network 太烂了?但我要告诉你,这个 Network 可是有 50 层的 ResNet,并没有很烂。而且如果你只是加入一个一般的肉眼可见的杂讯,它并不一定会犯错:

- 第二行出现犯错也是因为过于模糊导致可能与 fire screen 有点像了,这个错误是有尊严的错误。
所以加入肉眼看不到的杂讯,却产生了天差地远的结果是神奇的。
# 2. How to Attack
在讲为什么会发生这件事之前,我们先看看攻击是如何做到的:我们如何加入一个微小的杂讯,可以让 Network 产生非常错误的结果呢?
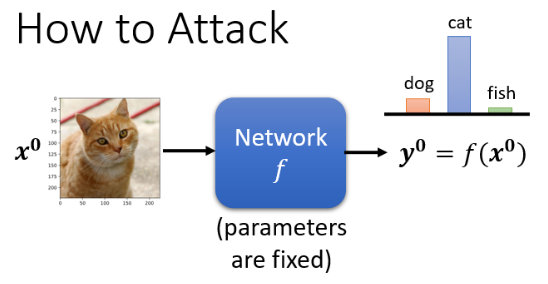
我们的 Network 输入一张 image
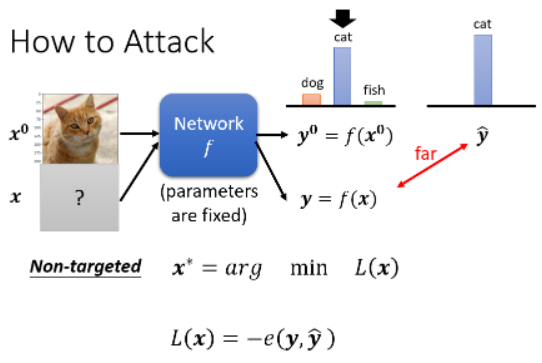
如果是 Non-Targeted Attack 的话,我们要做的就是找到一张新的 image
如果是 Targeted Attack 的话,假设我们设定的目标是
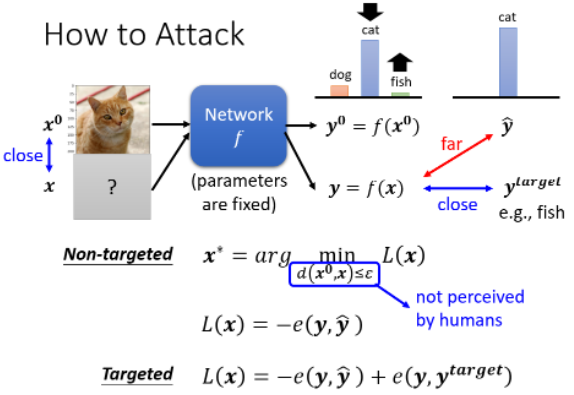
但是光是找一个
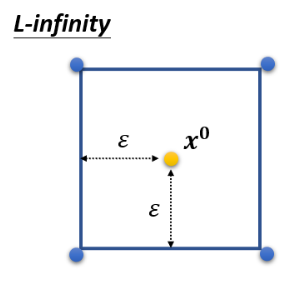
那怎么计算距离

这两种计算方法哪个好呢?我们看一个例子:
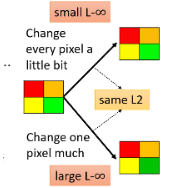
- 两种变化具有相同的 L2 值,但人类更明显会察觉出下面分支的变化,因此 L-Infinity 更接近人类的感知能力。因为上面分支的变化均匀到了每个 pixel 上,人类不易察觉出来。
所以我们也要让 L-Infinity 小才是最好的,因此常常将它当做限制来进行攻击。但具体这个差距要怎么定,还是要凭 domain knowledge。
# 3. Attack Approach
我们的 Optimization 问题要做的就是要找一个 x 去 minimize loss,而这个 x 是有限制的:
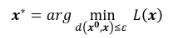
如果把对 x 的限制拿掉,那这跟我们 train 一个模型其实没有什么差别,只不过是把参数改成 Network 的 input 而已。你把 input 的那一张 image 看作 Network 参数的一部分,然后 minimize 你的 loss function 就结束了。
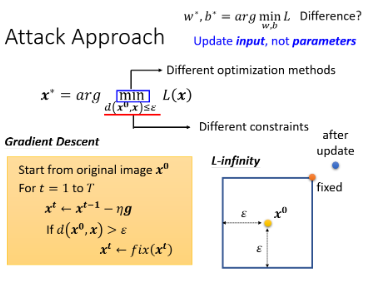
现在 Network 的参数是固定的,我们只去调 input 部分,让 input 部分去改变从而 minimize loss,这个过程的 Gradient Descent 怎么做呢?可以从

但上面的过程是没有 constraint 的前提下,现在我们把 constraint 加进去,这样可以在 Gradient Descent 里面再加一个 module,其实就是在跑这个 Gradient Descent 这个演算法时同时考虑

怎样考虑这个差距呢?方法说穿了不值钱,就是在 update 完如果发现
其实 Attack 还有非常多的变形,但精神都不脱我们今天举的这个例子。我们就介绍一个最简单的 Attack 的方法:FGSM,它是 Fast Gradient Sign Method 的缩写。它就像一拳超人那样,只用一击。本来做 Gradient Descent 时要 update 参数多次,但 FGSM 厉害在于它决定只 update 一次,试着做到一击必杀:

这里的
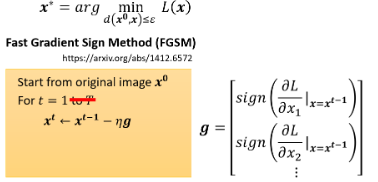
这样 vector
当然,多跑几个 iteration 的效果也往往会更好,这可以过作业的 medium baseline。