 Anomaly Detection
Anomaly Detection
# 1. Background
# 1.1 Problem Formulation
- Given a set of training data
- 用上标来表示一个完整的 data point,用下标来表示一个完整东西的其中一部分
- We want to find a function detecting input
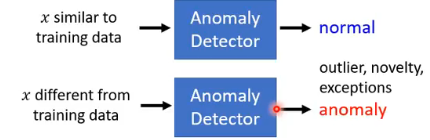
Different approaches use different ways to determine the similarity. 我们这里的 anomaly 不一定就说是坏的,它可能是 outlier、novelty 等。
# 1.2 What is Anomaly?

# 1.3 Applications

# 1.4 Binary Classification?
一个很直觉的方法就是用 Binary Classification 来做:
- Given normal data
- Given anomaly
- Then training a binary classifier ….
但这样做的问题是,如下图,Pokemon 的资料是差不多的,但是 NOT Pokemon 的东西太多了,你根部无法得知 Class 2 的 distribution 长什么样子。

还有一个原因是,其实你不太容易收集到 anomal examples,比如欺诈检测,银行收集到的大部分资料都是正常的交易。
# 1.5 Categories
根据所拥有的资料的样子,可以做如下分类:
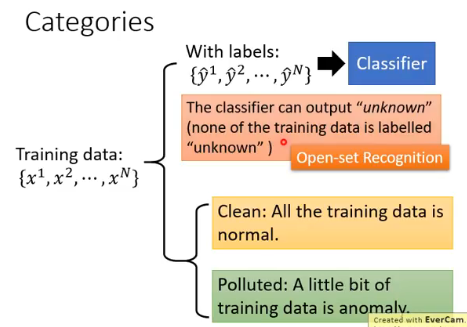
- 如果你希望你的模型在看到不知道的数据类别时,能够 output 一个 “unknown”,那么这种问题也称为 Open-set Recognition。
# 2. Case 1:With Classifier
# 2.1 Example Application
任务:From The Simpsons or not

我们收集的资料每个 Simpsons 家族人物的 image 都还有一个 label:
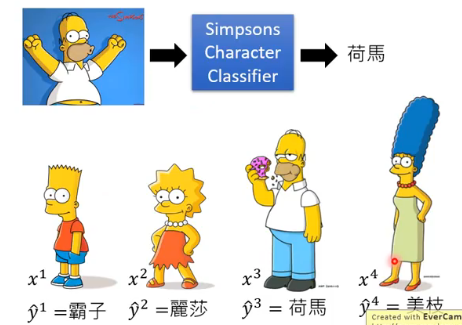
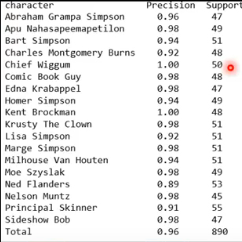
有一个人就是这么干的,收集了一大堆 Simpsons 家族人物的训练资料来训练一个 classifier,结果如下(还不错):
# 2.2 How to use the Classifier?
我们想要做的事情就是根据这个 classifier 来帮我们判断一个 image 是否来自于 Simpsons 家族人物:
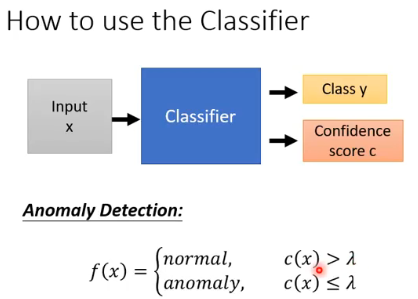
- 我们不仅让这个 classifier 告诉我们它属于 Simpsons 家族的哪个人物,还要它告诉我们这次判断的 confidence score
- 这里的 threshold
# 2.3 How to estimate Confidence?
我们知道 classifier 输出的其实是一个 distribution,然后机器的 confidence 就是 the maximum scores:

当然还有其他的计算 confidence 的方法,比如计算 negative entropy。
做了一些实验,实验结果如下,效果还行:

当然也有是一些识别错误的。
尽管这看着很简单,但其实往往 performance 还不错,这也不是一个很弱的方法,很多情况下值得一试。
# 2.4 Summary
刚刚这个过程可以总结如下:

# 2.5 Outlook:Network for Confidence Estimation
除了上面的方法之外,还有一种更好的方法是:直接让 Neural Network 生成一个 confidence score:

具体可以参考相关资料。
# 2.5 如何计算一个异常检测系统的效能好坏?
一个 development set 的计算结果如下图,蓝色是 Simpsons 家族的 image 输入进去后得到的 confidence score,红色的是其他的 image 输入进去以后得到的 confidence score:
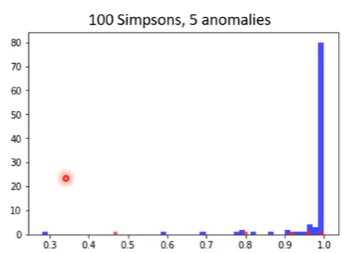
可以看到,也有一些红色的点是具有挺高的 confidence score 的,也有一个蓝色的点具有挺低的 confidence score,但是大多数 Simpsons 家族的 image 能够大于 0.998,因此效果其实还不错。
那怎么计算这个异常检测系统的 performance 的好坏呢?
在 anomaly dection 中,accuracy is not a good measurement! 因为异常资料和正常资料的分布是很悬殊的,所以 A system can have high accuracy, but do nothing.
我们看看把 threshold
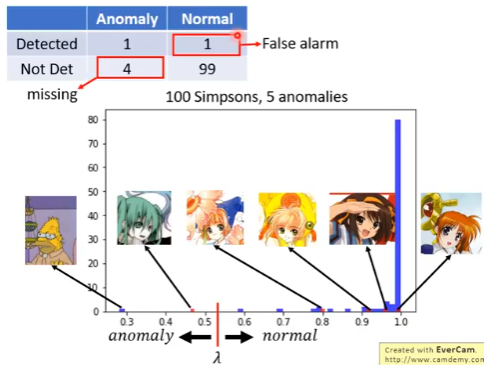
- 正常但是被认为异常的叫做 False alarm
- 异常但是没有检测出来的叫做 missing
再改一下 threshold 的位置,这样得到的统计结果在上面的右表中:

其实一个系统的好坏,取决于你认为 False alarm 比较严重还是 missing 比较严重。因此根据你的实际情况可以设计一个 cost table,从不同的 cost table 可以计算得到不同的 cost:
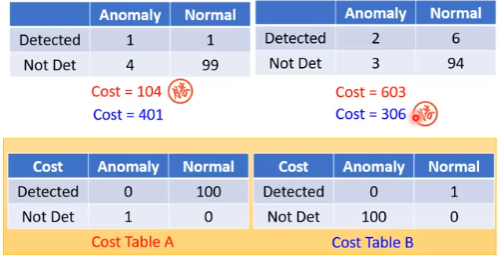
所以 cost table 怎么设计,取决于你要用它做什么事情。
在文献中,还有很多其他的 metrics,比如:
- Some evaluation metrics consider the ranking. For example, Area under ROC curve.
这一节其实想说,一个异常检测系统没有办法用一个传统的方法来判断一个系统的好坏。
# 2.6 Possible Issue
用一个 Classifier 来做 anomaly detection 的话,比如 classify 猫和狗,这时就能得到下面的分类结果:

如果这时 classifier 看到“羊驼”等这种异常动物时,可能就倾向于将他们放到 boundary 上,得到一个比较低的 confidence score,从而判断出这是一个“异常”。但是问题是,有些动物可能比猫更像猫,比狗更像狗… 如下图:

也就是说,对于机器来说,有一些东西虽然在训练期间没有看过这些标为异常的资料,但是这些东西可能有非常强的 feature 给你的 classifier 很大的信心说它看到了某一种 class。
拿刚才那个例子,由于 Simpsons 家族的人物往往都是黄脸,那 classifier 很可能就是利用了这个 feature,那我们做一下实验,果然 ….:

怎么解决这个问题呢?这里列举了一些相关资料:

如下图,你可以在训练 classifier 的时候,不仅让他学会 classify,还要教他当看到异常图片时,要学会给出一个很低的 confidence score。
# 3. Case 2:Without Labels
这种情况下收集到的资料是没有 label 的。
# 3.1 问题背景
有一个游戏:Twitch Plays Pokemon,它是由全世界所有人一起参与这个游戏,共同操作才完成这个游戏,同一时刻玩家所有玩家输入指令,系统会随机 pick 出一个来执行。但为什么这个游戏很难的?也许是有很多人是“Troll(网络小白)”,什么是 Troll 呢:
- Players that are not familar with the game.
- Just for fun…
- Malicious players…
总之,有很多 Troll(网络小白)不想完成这场游戏。现在我们假设大多数玩家是想要完成这场游戏的,他们就是 normal data for training,那我们使用 anomaly detection 技术能否识别出 Troll(anomaly)呢?
# 3.2 Problem Formulation
- Given a set of training data
- We want to find a function detecting input
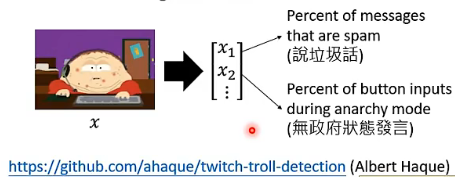
一个 x 的 feature 就像上面那个样子。
现在的问题是,x 是没有 label 的,那 model 要怎样识别呢?Generated from
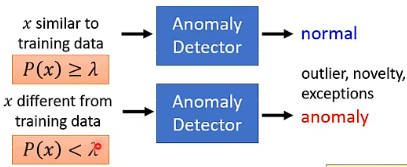
这里的 threshold
假设这里的 x 的 feature 只有两个,也就是 x 是二维的,那解决问题的思路差不多是这样:
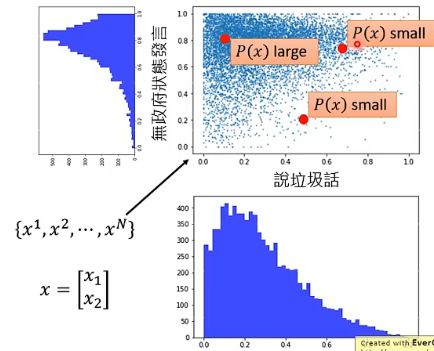
# 3.3 Maximum Likelihood
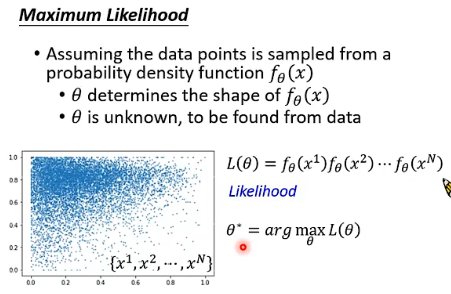
这件事怎么做呢?我们可以认为所有看到的 data points 都是由一个 probability density function
我们要计算一个 likelihood
现在我们要做的就是找出能够最大化
一个常用的 probability density function 是多维的 Gaussian Distribution,具体的做法如下图:
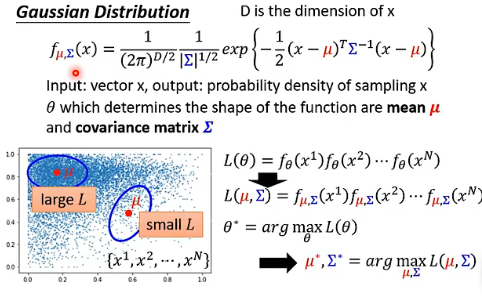
为什么一定要用 Gaussian 呢?一个简单的回答就是,如果用其他的 distribution 也会问同样的问题。而且 Gaussian 真的很常用,尽管有时候你的 data distribution 没有那么像 Gaussian,它也是效果不错的。或者也可以给数据加 log、加根号来让他变得像 Gaussian。
但其实预先假设了 Gaussian 还是一个非常强的假设,因为 data 的分布根本就不是 Gaussian。所以,How about
那这里的参数
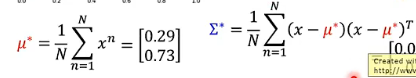
所以给了我们资料以后,我们就可以按照上面公式来计算出极大化似然函数的参数
inference 阶段还怎么做呢?把 data point 代入到
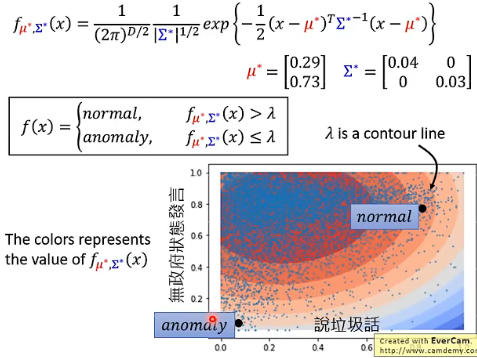
# 3.4 Outlook
还有其他的方法,比如 deep learning based 的方法:Auto-Encoder

更多的方法:
