BERT and its family
BERT and its family
# 1. What is pre-train model?
# 1.1 Pre-train Model 的历史
以前,Pre-train Model 想要做的是:Represent each token by a embedding vector. 如下图所示:
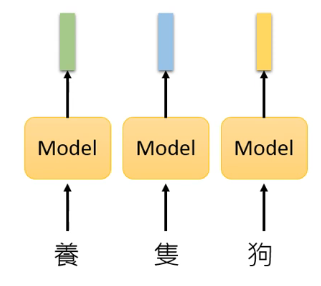
以前所做的往往是 simply a table look-up,也就是静态查表,这有一个问题:The token with the same type has the same embedding.
上面所说的技术就有知名的 Word2vec [Mikolov,er al., NIPS’13]、Glove [Pennington, et al., EMNLP’14]。
除此之外还有什么技术呢?
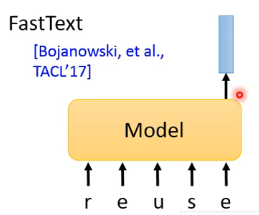
如果你考虑的是英文,如果将 English word 作为 token 的话,英文单词实在太多了,这样静态查表总会有找不到的词汇。也许我们可以把 model 改成将英文 character 作为 input,输出就是一个 vector,这就是 FastText 做的:
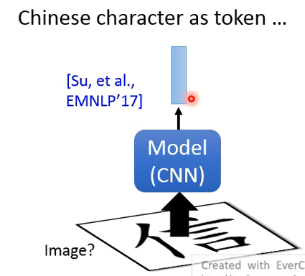
如果考虑中文,那每一个中文其实也可以看做一个 image,然后丢到 CNN 里从而输出对应的 vector,这也许也是可以的:
上面所说的技术不会考虑到 context,比如同一个“狗”出现在“圈养狗”和“单身狗”中意思不是一样的。
# 1.2 Contextualized Word Embedding
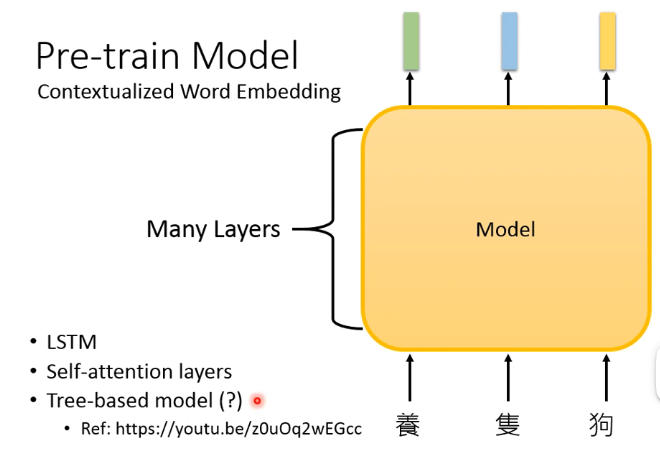
- Tree-based model 好像没有特别强,所以目前也用的不多。
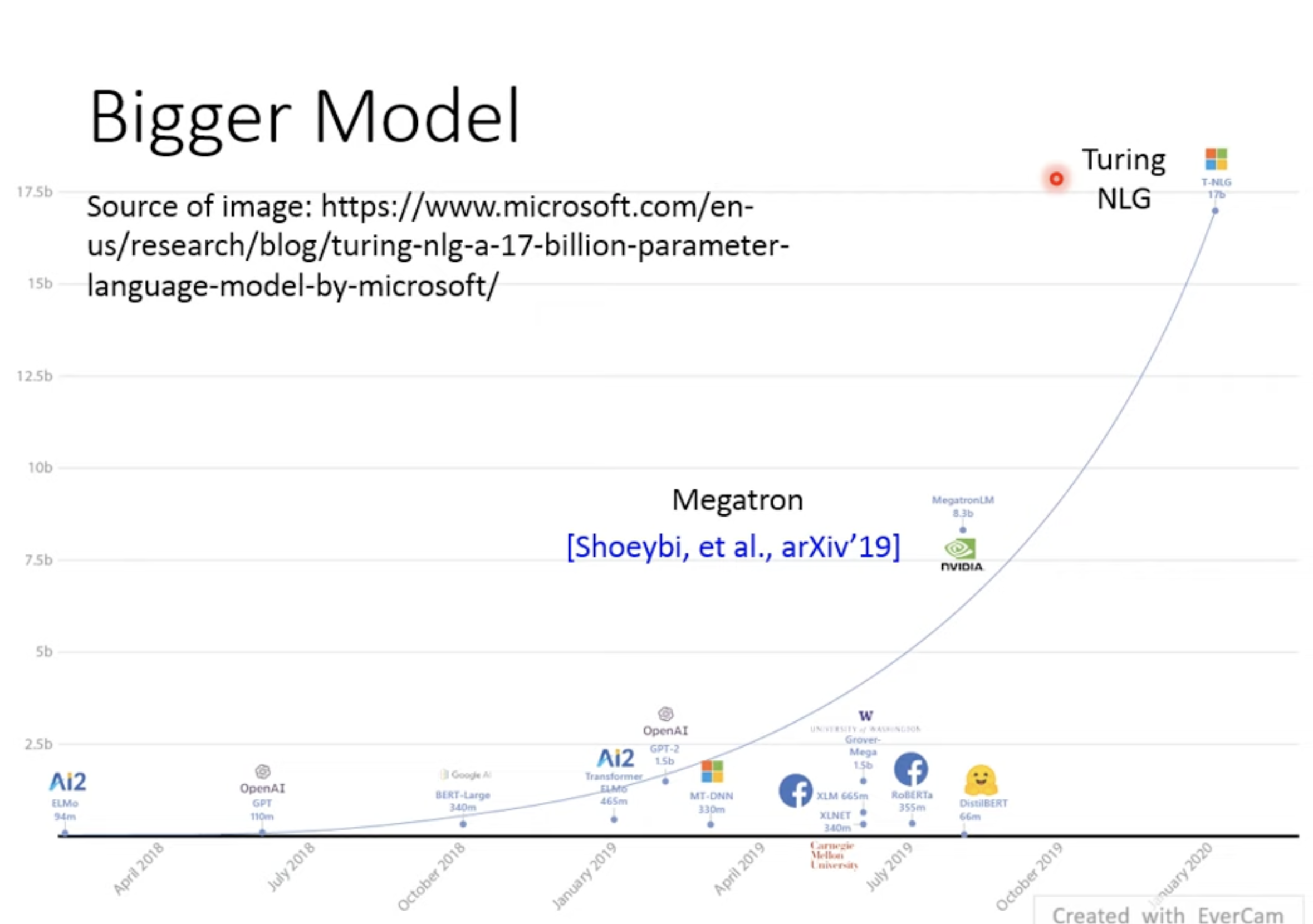
# 1.3 Bigger Model
# 1.4 Smaller Model

- 这里面很出名的是 ALBERT
这些让 BERT 变小的技术是 Network Compression。
还有一些在这些模型的 Network Architecture 上也有很多的突破:
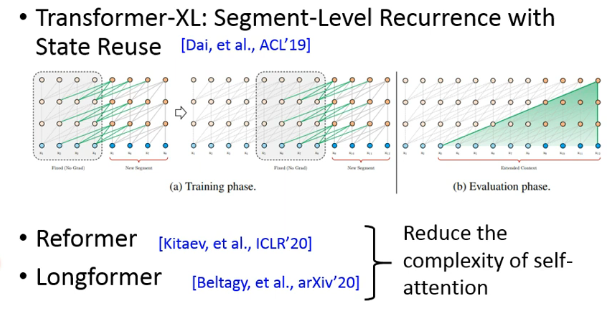
- Transformer-XL 解决了 BERT 一次只能读 512 个 token 的问题
- Reformer 和 Longformer 是为了减少 self-attention 过程中的运算复杂度
# 2. How to fine-tune?
# 2.1 NLP tasks
可以根据 input 和 output 的类型进行一个分类:
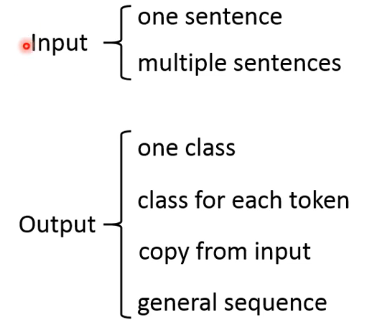
# 2.1.1 Input
对于 multiple sentences 的情况,假如有两种不同类型的 sentence,可以在两者之间加一个特殊分隔符 [SEP]:
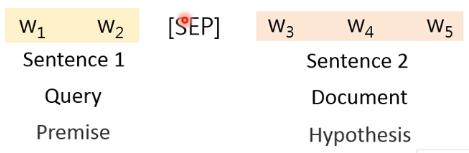
然后把它们丢到 model 里面就可以了。
# 2.1.2 Output
output 有多个类型,我们逐一看一下。
# 1)one class
一种做法如下图所示:
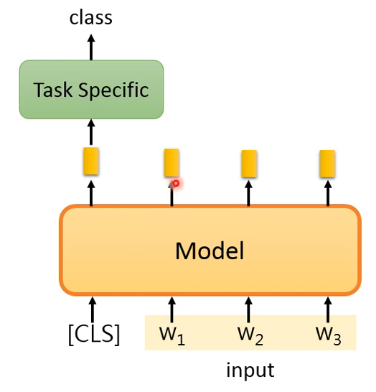
- 输入的时候加一个特别的 token:
[CLS],pretrain 的时候就要告诉 model 当看到 [CLS] 就要产生一个与整个句子有关的 Embedding - 然后把这个与整个句子有关的 Embedding 丢到一个 task specific model 中得到一个 class,这个 model 什么样要看任务有多复杂,但很多情况下直接是一个 linear transform 就可以了,或者多叠几层 linear transform。
还有另外一种做法是将整个句子的 Embedding 都进行处理得到一个 class:
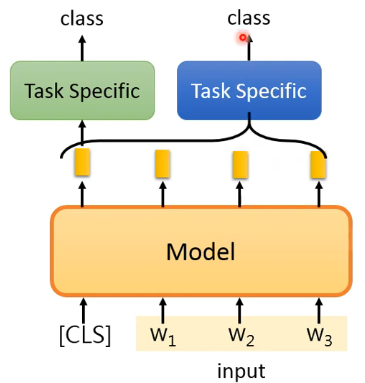
# 2)class for each token
这种就是对每个 token 都给一个 class,做法如下图:
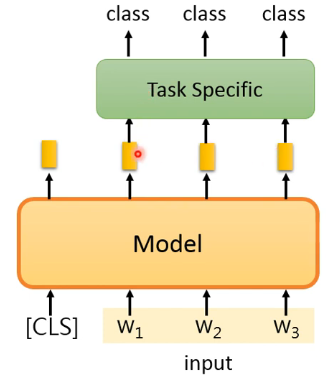
- 这里的 task specific model 可以是一个 LSTM,也可以是其他的。
# 3)copy from input
完全从 input 做 copy,这种类型的任务也没有很多,其中最经典的就是 Extraction-based QA,这个任务是:
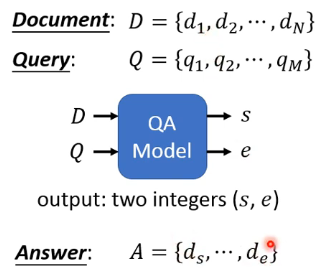
原始的 BERT 的 paper 里提供了这种任务的解决方法,可以参考论文。
# 4)general sequence
按照 seq2seq model 的设计,可以这样做:
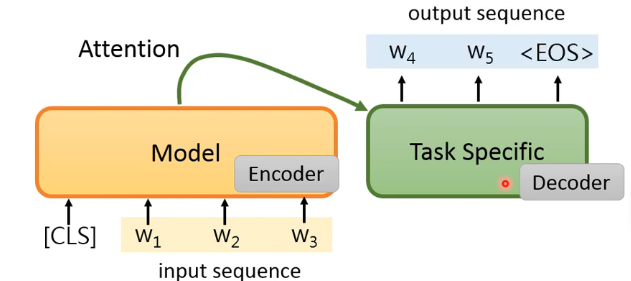
但问题是,作为 decoder 的 task specific model 是完全没有 pretrain 过的,所以这样做也许不是最好的。
来看第二种版本:
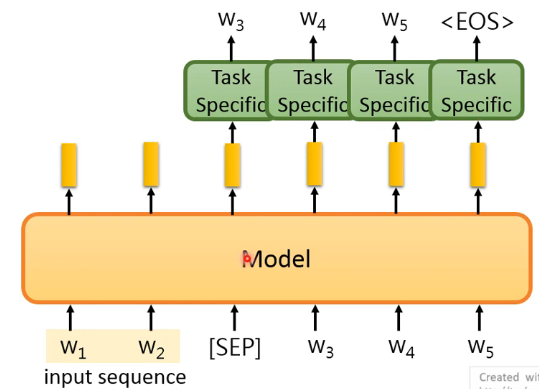
- 这种做法就是输入 input sequence 后再输入一个 [SEP],这时 Model 会输出与 [SEP] 相对应的 Embedding Vector,把这个 vector 输入到 task specific model 得到输出
<EOS>。
# 2.2 How to fine-tune
假设你有一些 task specific data,该怎样去 fine-tune 呢?这里有两种做法。
第一种做法,固定住 pre-trained model 从而变成一个 feature extractor,然后我们只 fine-tune 那些 task specific 的部分:
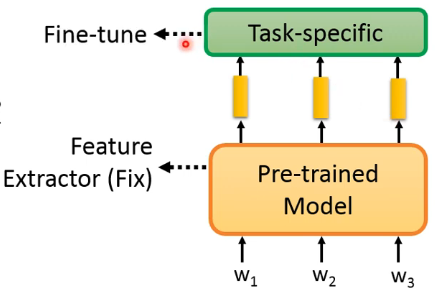
第二种做法,把 pre-trained model 和 task-specific model 合在一起 fine-tune,当成一个巨大的 model 来解这个 down-stream task:
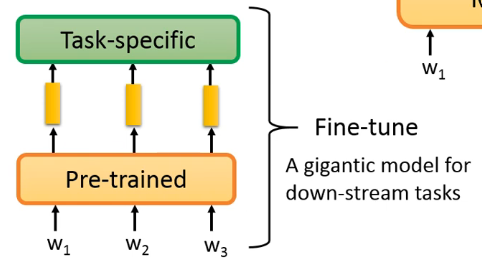
在以前,巨大 model 在 train 时很容易 overfitting,但第二种做法由于只有 task-specific 的 param 是随机初始化的,pre-trained model 的 param 并不是随机初始化的,所以也许这种方式并没有那么容易 overfitting。在一些文献中指出,第二种做法的 performance 往往比第一种要好一些。
# 2.3 Adaptor
刚刚讲的第二种 fine-tune 方法有一个问题,对每一个 task specific 进行 fine-tune 后,pretrained model 会变得不一样:
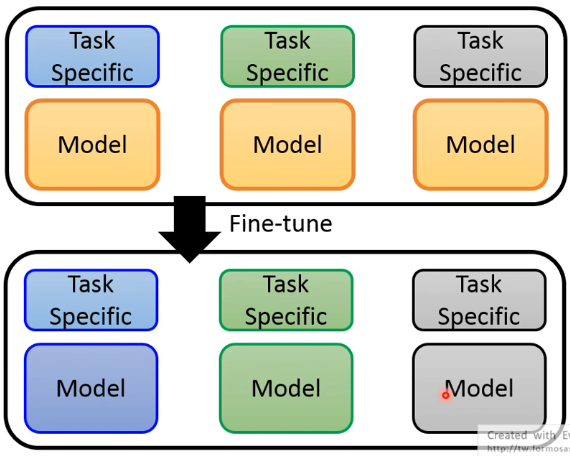
这样每个任务都需要存一个新的 model,而这些 model 往往非常巨大,所以这可能行不通的,因此有了 Adaptor 的概念。也就是说,我们能不能只能调 pretrained model 的一部分就好了,于是我们在 pretrained model 里面加了一个很小的 layer,这些 layer 就叫做 Adaptor,下图用 Apt 来简称。这样 fine-tune 时只调整 Pretrained Model 的 Adaptor 部分,这样存储时就只需要存一份 pretrained model 的主体部分,从而减小存储压力:
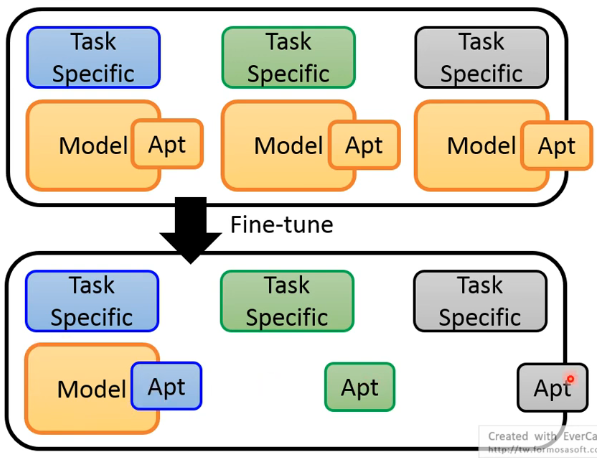
这边举一个使用 Adaptor 的例子,当然还有很多其他做法:
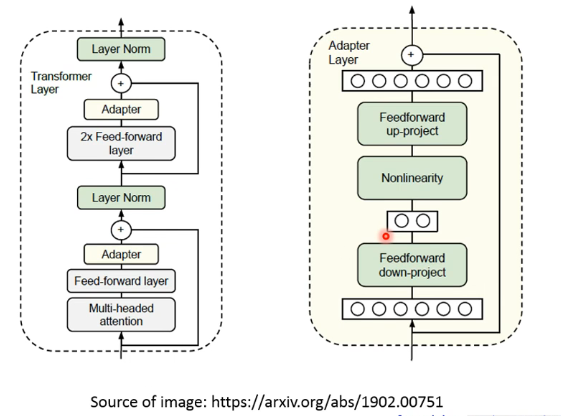
- pretrain 的时候是没有 Adaptor 的,而是在准备 fine-tune 时才加入并只调整 Adaptor 的参数。
这个例子的表现结果如下:

- Accuracy delta 中的 0 代表当我们 fine-tune 整个 model 时的 performance
- 蓝色这条线表示越往右边微调参数越多
# 2.4 Weighted Features
我们之前是把 input sequence 后扔进整个 model 后,拿到最后的 Embedding 输给 down-stream task layer 中。但还有一种做法,因为每一层他所抽取的资讯是不一样的,所以一种做法是把不同层的 feature 给 weighted sum 起来得到一个新的 embedding,这个 embedding vector 同时综合了多层抽取的资讯,然后再把它丢到 down-stream 中:
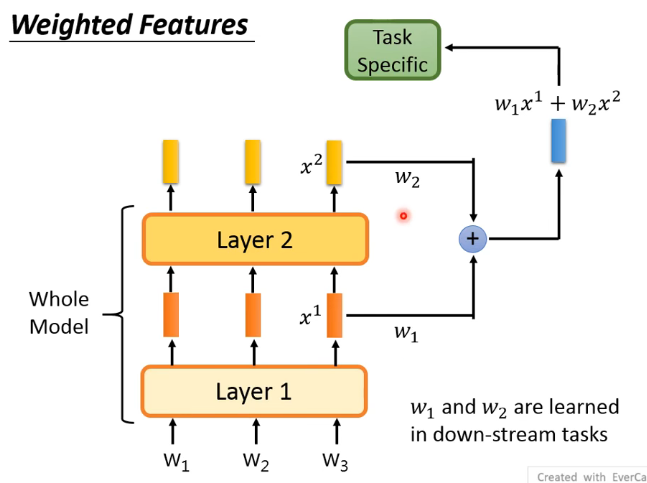
这里的
# 3. Why Pre-train Models?
GLUE 是检测一个模型了解人类语言的能力:
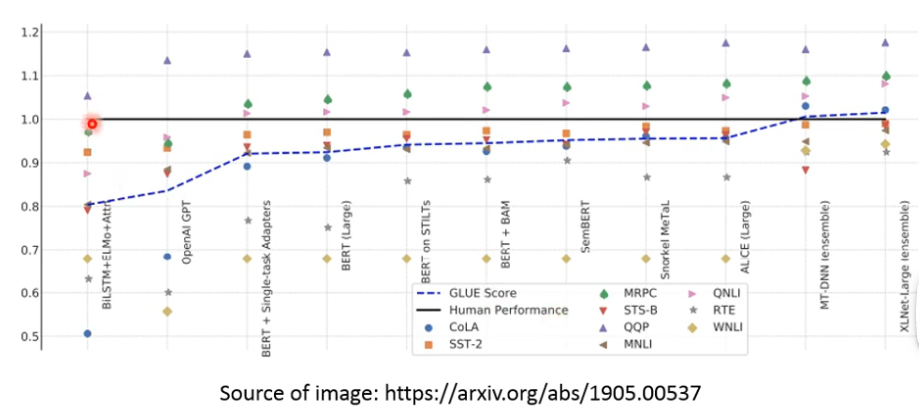
- 黑色的这条线表示人类理解这个数据集的能力,可以看到后面提出的 pretrain model 都至少可以在这个 corpus 上超越人类的 performance 了。
有很多 paper 讨论了为什么 pretrain model 是有效的,这里选其中一篇来讲解。这里选了 arxiv 上 1908.05620 这一篇,分析其中的两个结果
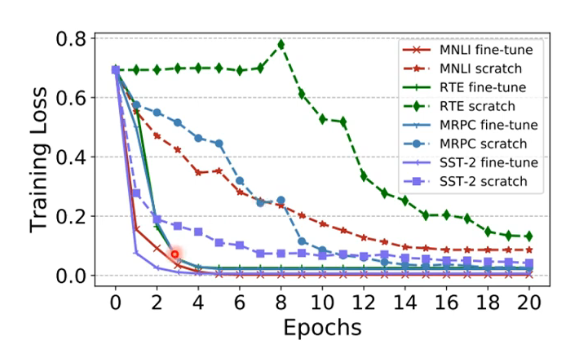
- 虚线代表没有 pretrain 的 model,实线代表有 pretrain 的 model,它们的 model 大小是一样的。
- 可以看到,有 pretrain 的 model 在 training 时 training loss 下降的非常快。
那只看 training loss 是不是有可能是因为 pretrain model 会 overfitting 呢?它在面对新的数据时 generalize 的能力如何呢?我们来看下图:
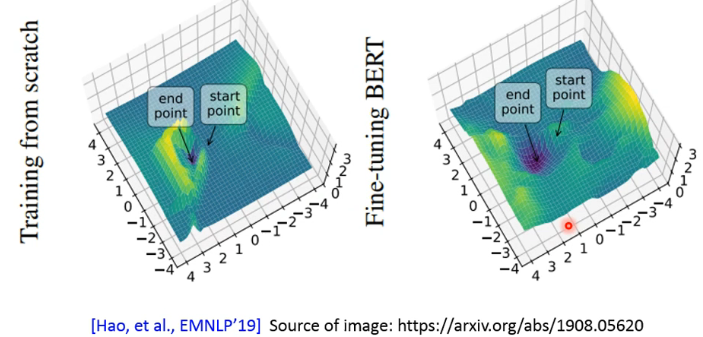
- 可以看到,fine-tuning BERT 所处在的 local minima 是一个盆地,而左图是一个峡谷。一般来说,local minima 处在盆地时的泛化能力是要比处在峡谷时要强的。
# 4. How to Pre-train?
这章讲如何得到 pre-train 的模型。
我们希望什么样的 pre-train 的 model 呢?我们希望它能把 token sequence 吃进去,然后把每个 token 变成一个 embedding vector,而且希望这些 embedding vector 是 contextulize 的,即考虑上下文的。
# 4.1 Pre-training by Translation
像这种抽取 contextulize 的 embedding 的方法最早是 CoVe 这篇 paper,它是通过 translation 而不是现在常用的 unsupervised learning 的方法得到的这个 model:
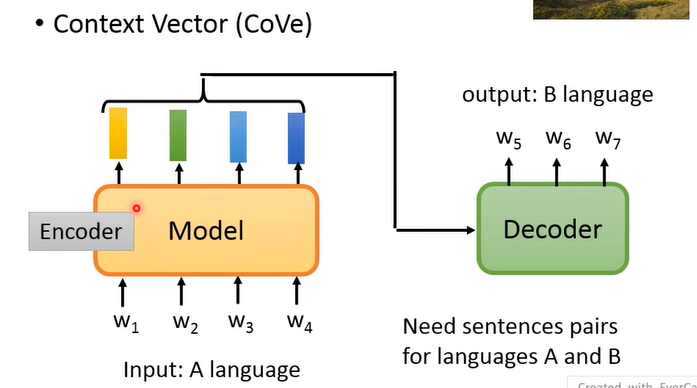
- 把这个 model 当作是 translation 的 Encoder,最终训练好 Encoder 和 Decoder,这里的 Encoder 就是我们 pretrain 好的 contextulize word embedding 的 model。
这篇 paper 选择 translation 也是有合理性的,因为他会把input sequence 里面的资讯都如实呈现到输出里面,而像 summarize 之类的任务就不行。但这种方式的问题是收集大量的 pair data 作为 training data 是很困难的,于是就有了之后的 unsupervised 的方法,现在也常称为 self-supervised 方法。
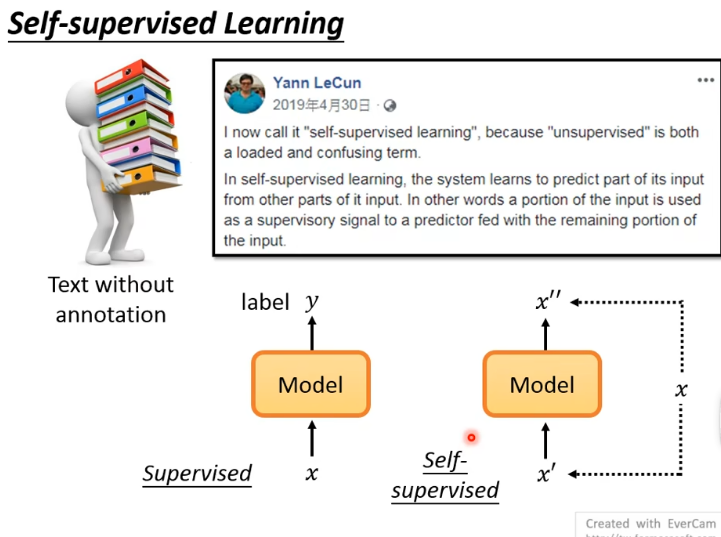
# 4.2 Self-supervised Learning
Self-supervised Learning 是 Yann LeCun 在 Twitter 上提出的,其基本概念如下:
# 4.3 Predict Next Token
给这个 model 一个
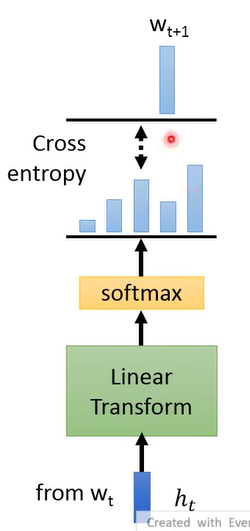
这样就用从
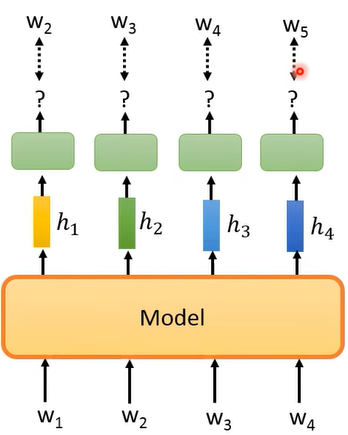
注意,在训练时不可以让 model 一次把
以上所讲的 Predict Next Token 任务是最早的 unsupervised pretrain 技术,这样得到的 model 就是一个 language model(LM)。
这个 model 可以使用 LSTM,也可以使用 Self-attention。使用 LSTM 的 language model 有 ELMo、ULMFiT 等,使用 Self-attention 的有 GPT、Megatron、Turing NLG 等。
使用 Self-Attention 作为 model 来做 predict next token 时,注意要给 self-attention 加一个 constraint,不能让它看到后面的,比如
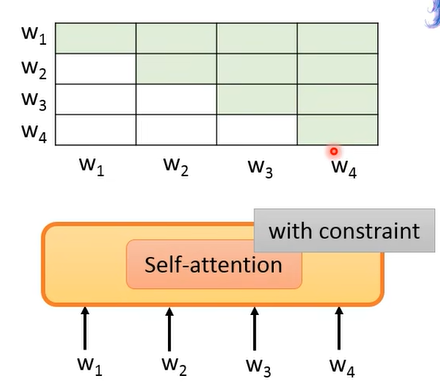
# 4.4 Predict Next Token - Bidirectional
刚刚讲的最终得到的 contextualize representation 只考通过 predict next token 得到的,而且是只考虑了 left context,并没有考虑 right context。
ELMo 就是同时考虑了 left context 和 right context 用来得到一个 token 的 contextualize representation:
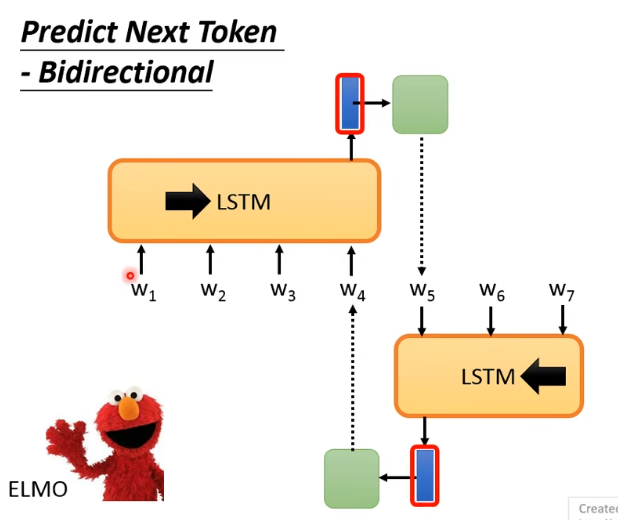
- 它有一个由左向右的 LSTM,看
- 然后 ELMo 把正向的 LSTM 和逆向的 LSTM 输出的 vector 给 concatenate 起来,当作代表
所以说 ELMo 通过两个方向的 LSTM 来考虑了一个 token 的 left context 和 right context。但这样还不够,因为 machine 在看 left context 进行 encoding 时没有看到 right context,即两次 encoding 的过程都只是看到句子的一半而非全部,两个 LSTM 得到的 vector 是没有交互的。
# 4.5 Masking Input
BERT 弥补了刚刚讲的 ELMo 的 encoding 过程没有左右 context 交互的问题,而且 BERT 做的也不再是 predict next token,而是 masking input:
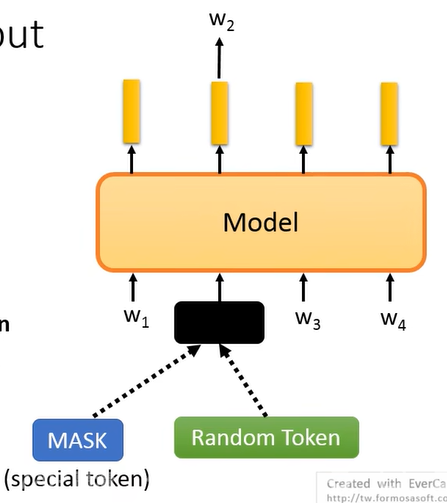
- BERT 对 input sequence 的一些 token 给 masking 掉,对 masking 的部分有随机两种做法:一种是替换成一个 special token [MASK],一种是随机 sample 一个 token 替换到这里。
- 然后用所 masking 掉的部分输出的 vector 来预测 masking 掉的是哪个 token。
BERT 用的 Model 是 Transformer Encoder 堆叠起来的。
其实考古一下的话,Word2Vec 的 CBOW 模型的 training 过程就与 BERT 很像,只不过 BERT 内部结构更加复杂,所考虑的东西也更多了。
原始 BERT 中要 masking 掉哪些位置是随机决定的,但这不一定很好。具体改进的做法有:

- 上面的 WWM 是 masking 掉一整词,防止出现要预测“黑 [MASK] 江”这种简单的任务;
- 下面是指讲 entity 先识别出来,然后 masking 掉 entity,这么做的就是 ERNIE。
还有一种 masking 的方法叫做 SpanBert,它就是一次 masking 掉很长的一个范围,原来的 BERT 只是每次随机选一个 token 来 masking 掉。SpanBert 每次盖住多长是有一个几率分布:

这篇 paper 也对比多不同类型的 masking 方法的效果:
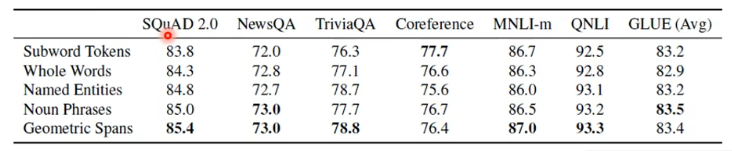
- Geometric Spans 就是 SpanBert 提出的 masking 方法。
# 4.6 Span Boundary Objective(SBO)
SpanBert 同时提出了一个新的预训练方法:Span Boundary Objective(SBO)。做法如下:
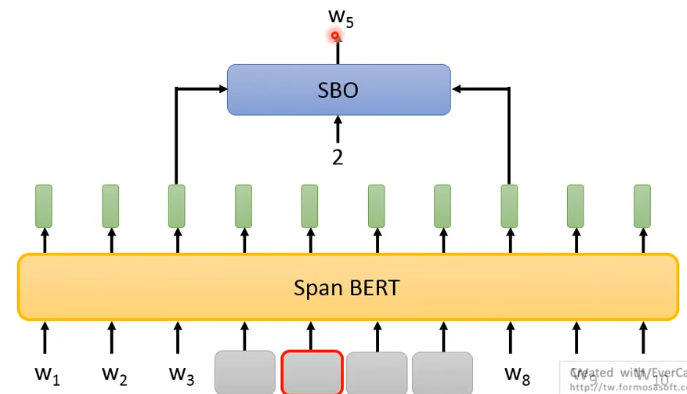
- 先 masking 一个范围,同时有一个 SBO 的 model,它把这个所 masking 部分的左右两边的 token 吃进去,同时给 SBO model 一个数字 2,这个数字表示要预测所 masking 掉 span 里的第 2 个 token
这个训练方法也许看上去匪夷所思,其实这种设计所期待的是:一个 span 的左右两边的 token 可以包含它内部整个 span 的资讯。为什么这样呢?以后讲到 coreference 时会有用处。
# 4.7 XLNet
“XL” 指的是 Transformer-XL,具体是什么可以参考 paper。
以往的 predict next token 是根据 left context 去 predict 下一个 token,而 XLNet 是把 input sequence 里面的 token 给随机打乱,比如下图中的下面部分:
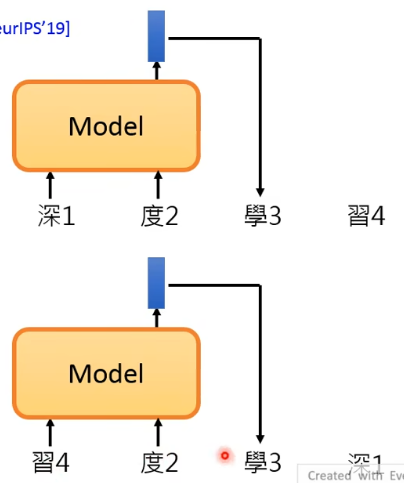
- 下面就是把“深度学习”打乱成“习度学深”,然后让 model 根据“习度”去预测“学”。
另外,原始 BERT 是根据整个句子的资讯加上 mask 掉的 [MASK] 本身去预测 mask 掉的 token,如下图的上面部分所示。而 XLNet 是只根据 sentence 的一部分而非全部来预测,而且到底是根据哪些部分是随机决定的,还有一个特别的是它不会给 model 看到 mask 的部分(但也会给它 positional information),如下图的下面部分所示:
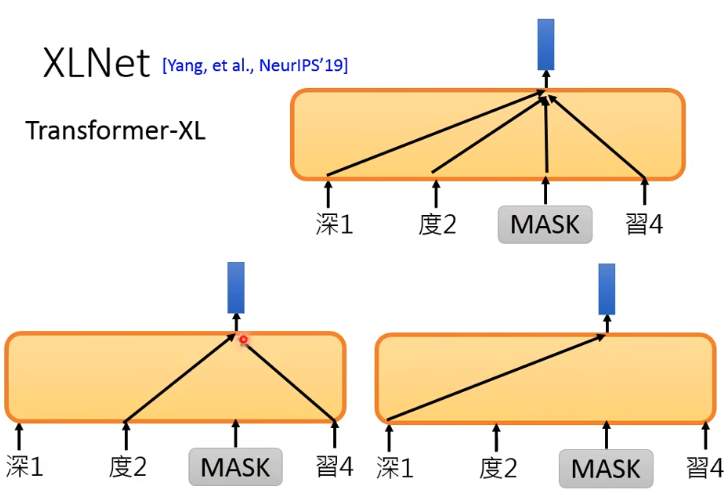
其实 XLNet 为了实现上面所说的,在架构上也做了很多改变,具体可参考原 paper。
# 4.8 MASS / BART
其实 BERT 本身有点不善言辞,也就是说它不太适合 generation 的任务。而我们想把它用于 sequence-to-sequence,就要让它具有产生句子的能力,也就是”Given paritial sequence, predict the next token“。但 BERT 的训练任务却是从来没有只看 partial sequence 来 predict。
下面我们的讨论只局限于 autoregressive model 的情况下,即根据前面的 sequence 来产生下一个 token,由左向右地产生,而不讨论 non-autoregressive 的情况。
BERT 本质是一个 encoder,不太适合 seq2seq 的任务,所以我们可以直接 pretain 一个 seq2seq 的 model:
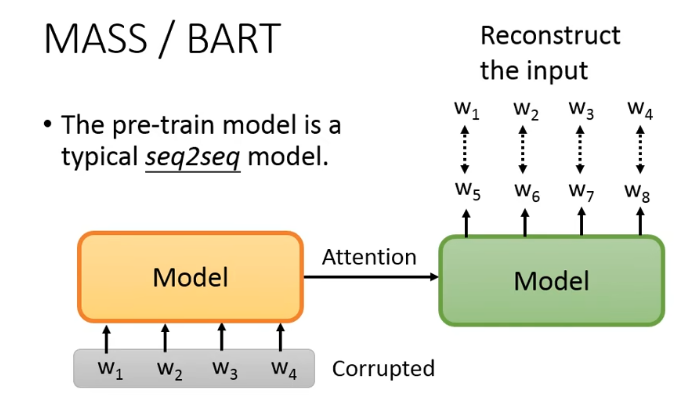
但要注意,我们要对 input 的做某种程度的破坏,否则这个 seq2seq model 学不到什么东西。怎么来对 input 进行破坏呢,这里有两篇 paper 来探讨这个事情:
- MAsked Sequence to Sequence pre-training (MASS)
- Bidirectional and Auto-Regressive Transformers (BART)
那么他俩做的是什么事呢?MASS 的想法与 BERT 很像,就是随机把一些地方 mask 掉,实际上原始 MASS 的 paper 只要求能 reconstruct 一开始 mask 掉的部分就可以了:
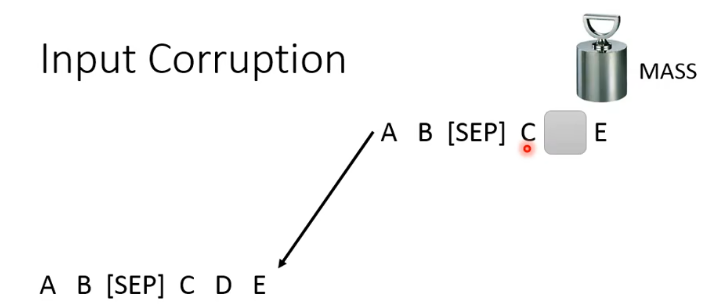
在 BART 里面还提出了各式各样的方法,比如 delete 掉一个 token、做 permutation、做 rotation(即改变起始位置)、做 Text Infilling(随机插一个 [MASK] 来误导 model):
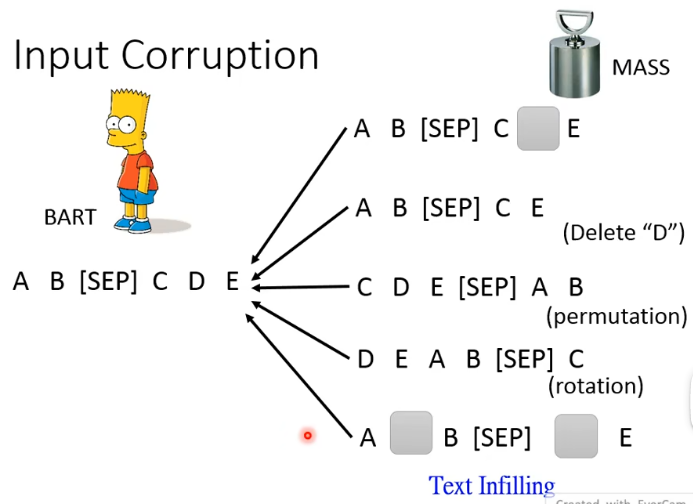
BART 做了这么方法,结果表明:
- Permutation / Rotation do not perform well.
- Text Infilling is consistenly good.
# 4.9 UniLM
UniLM 同时是 Encoder 和 Decoder,同时还是一个 seq2seq 的 model:
UniLM 不像之前 encoder 和 decoder 拆开,而是只有一个 model 来做三种类型 pretrain:
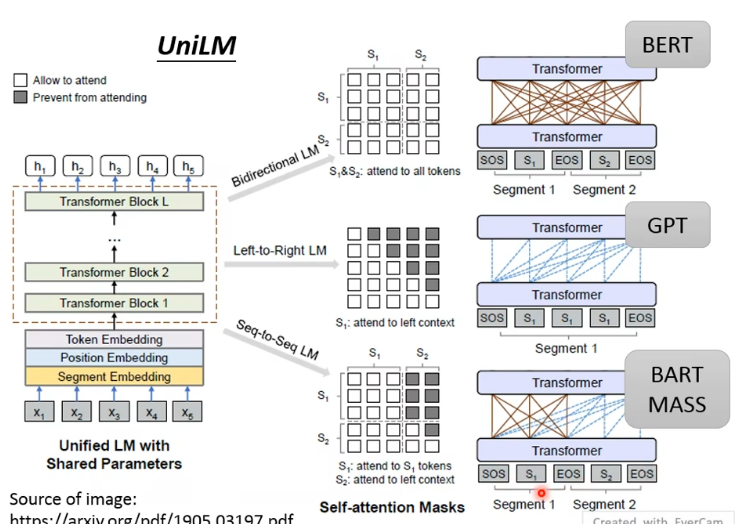
- 既当作 BERT 一样训练,又当作 GPT 来训练,还当成一个 seq2seq 来训练。
# 4.10 ELECTRA
ELECTRA 做的是先将一个 sentence 中的某个 token 给 replace 掉,然后让 model 来判断每个输入的 token 是否有被 replace,比如我们将“the chef cooked the meal”中的 “cooked” 给 replace 成 “ate”:
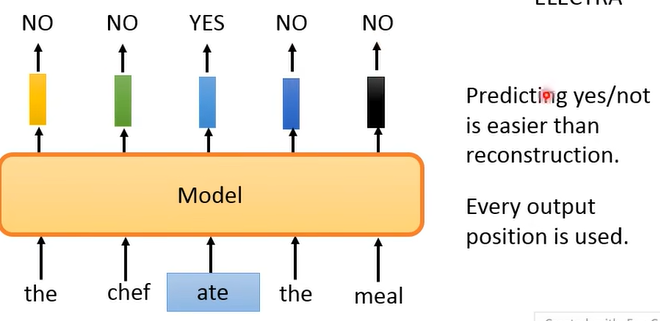
但问题来了,怎么把一个词 replace 后可以语法上没有错但语义会怪怪的呢?因为太离谱的 replace 很容易就会被发现从而使 model 学不到什么东西。做法就是加一个 small BERT 来产生用来 replace 的 token:
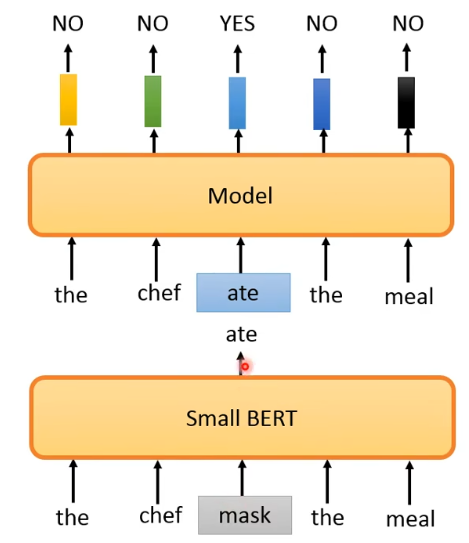
注意,因为下面的这个 small BERT 不是要效果很好,希望它预测后有点错误。而且这不是一个 GAN。
神奇的是,ELECTRA 训练的效果还很好:
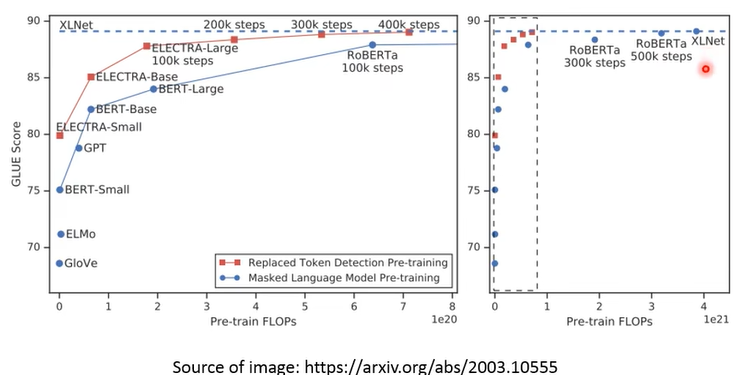
- 横轴是所需的计算量,纵轴是在 GLUE 上的得分
# 4.11 Sentence Level
有时候我们希望的不是给一个 token 一个 embedding,而是给一个 sentence 一个 embedding,也就是用一个 global embedding 来表示整个 input 的 token sequence。
基于“You shall know a sentence by the conpany it keeps” 的想法,有一个叫做 Skip Thought 的想法:有一个 seq2seq 的 model,encoder 读入一个 sentence 变成一个 vector,然后 decoder 用这个 vector 来预测输入 sentence 的下一个 sentence:
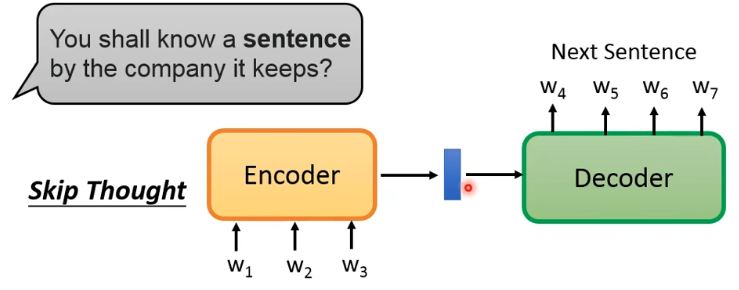
这样如果两个句子所接的下一句很像,那这两个 sentence 的 embedding 也应该很相近。
但我们说过,如果让 model 去生成东西的话,运算量就往往比较大,于是有了一个进阶版:Quick Thought:
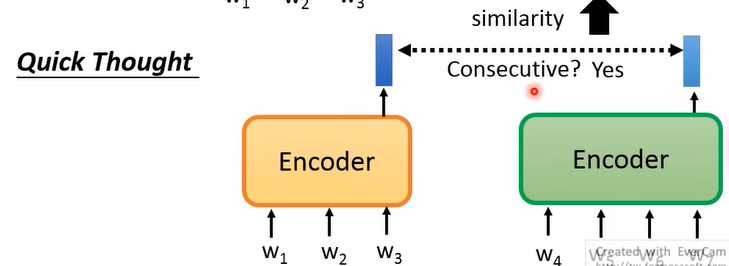
这个方法是说,有两个 encoder,吃进去两个 sentence,得到两个 vector,如果两个 sentence 是相邻的话,那得到的两个 vector 越相近越好,反之则越远越好。从而避开了做”生成“这个事情。
# 4.12 NSP -> SOP
原始 BERT 的 pretrain 中有一个任务是 NSP,指的是给 BERT 随便两个 sentence,通过 [CLS] 的输出来让 BERT 告诉我们这两句是否具有上下句关系:

后来 RoBERTa 等模型发现说 NSP 没什么用,于是墙倒众人推,很多人都说 NSP 没什么用。于是有了 SOP(Sentence order prediction)任务,就是对给的两个相邻但可能颠倒前后顺序的 sentence,model 要告诉我们给的第一句是否是给的第二句的在语义上的前一句,是就回答 Yes,不是就回答 None。这个方法用在了 ALBERT 上。
之所以 SOP 比 NSP 有用,也许是因为 NSP 这个任务本身很简单,而 SOP 相比较来说更难一些。
# 4.13 T5
讲了这么多 pretrain 的方法,哪种最好呢?Google 就展现了自己雄厚的财力,把当时几乎所有 pretrain 的方法都做了一遍,发表了 T5 这篇 paper,它长达五十几页。
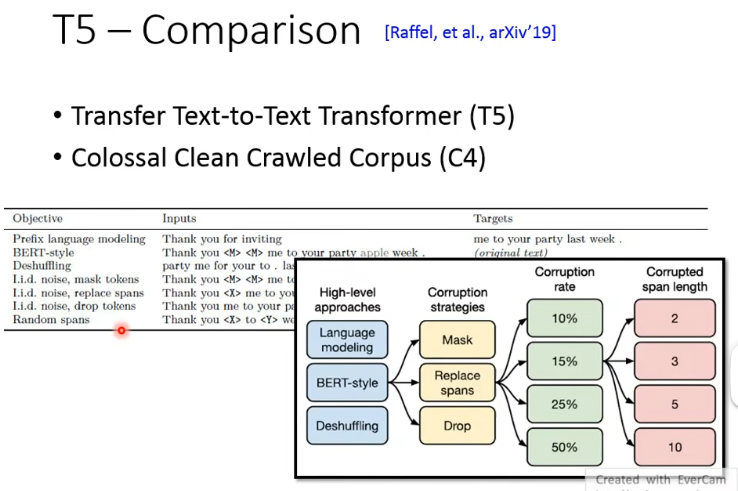
- paper 叫做 T5,用的训练数据集叫做 C4。命名大师!
# 4.14 Others
除了刚刚提到的 ERNIE,还有另外一个同名的 ERNIE:
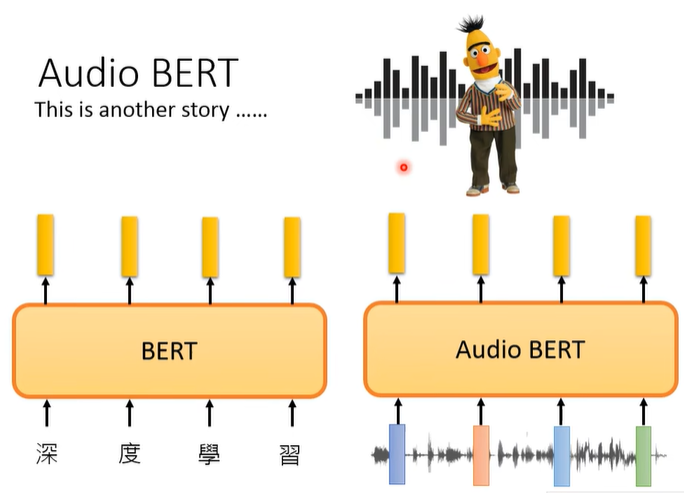
另外,还有一种语音版的 BERT,即 Audio BERT: