 Data Efficient & Parameter-Efficient Tuning
Data Efficient & Parameter-Efficient Tuning
# 1. Background: Pre-trained Language Models
# 1.1 什么是 Language Model?
Neural Language Models: A neural network that defines the probability over sequences of words.
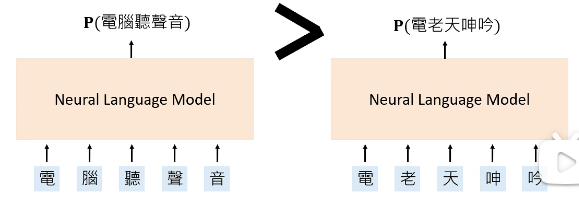
# 1.2 怎样训练的这些 model?
Given an incomplete sentence, predict the rest of the sentence.
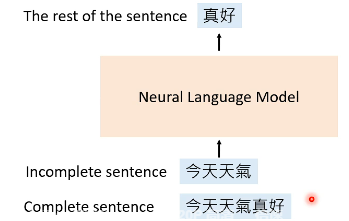
不完整的句子怎么构造呢?根据不完整的句子的构造方式,可以将 Language Model 的训练分成两种:
- Autoregressive Language Model(ALMs): Complete the sentence given its prefix.
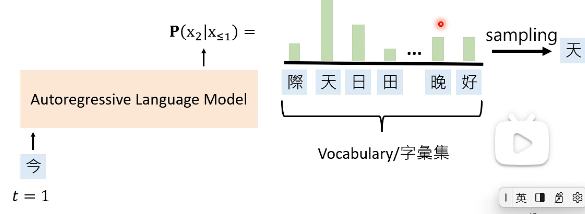
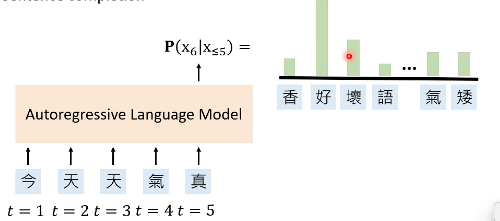
我们看一下 Transformer-based PLM 长什么样子:
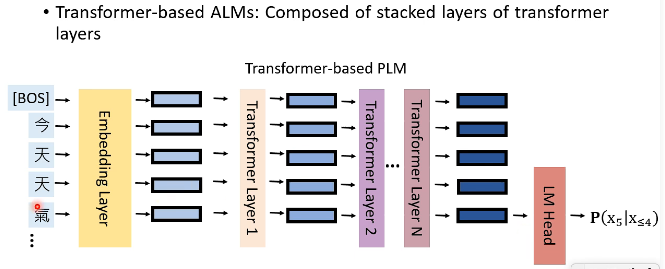
上图中,“气”这个字经过一系列 layer,得到了它的 embedding,然后把这个 embedding 输入到一个 LM Head 中,可以得到预测下一个 token 的概率。
训练一个 Language Model 的方式就是 self-supervised learning,但它没有一个明确的定义,这里我们说:
Self-supervised learning: Predicting any part of the input from any other part.
还存在另外一种 Language Model,即 Masked Language Models(MLMs):
Masked Language Models(MLMs): Use the unmarked words to predict the masked word.
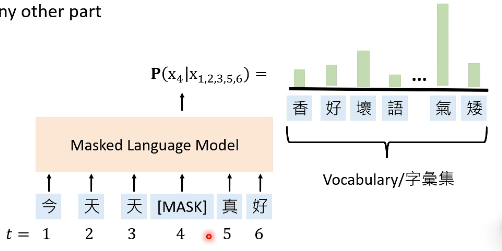
# 1.3 Pre-trained Language Models(PLMs)
Pre-training: Using a large corpora to train a neural language model.
- Autoregressive pre-trained: GPT 系列(GPT, GPT-2, GPT-3)
- MLM-based pre-trained: BERT 系列(BERT, RoBERTa, ALBERT)
为什么要这样做呢?We believe that after pre-training, the PLM learns some knowledge, encoded in its hidden representations, that can transfer to downstream tasks.

fine-tuning: Using the pre-trained weights of the PLM to initialize a model for a downstream task.
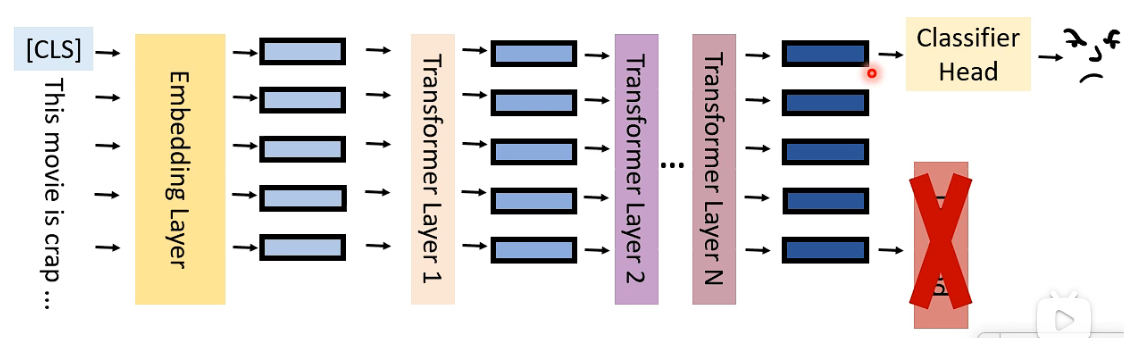
PLMs has shown great success on a variety of benchmark datasets in NLP. The next goal is to make PLMs fit in real-life use case. 但我们将 PLMs 用到现实情况时,却会遇到各种问题。
# 2. The problem of PLMs
# 2.1 Problem 1: Data scarcity in downstream tasks
A large amount of labeled data is not easy to obtain for each downstream task. 下面是一个训练 BERT 所用的 dataset:
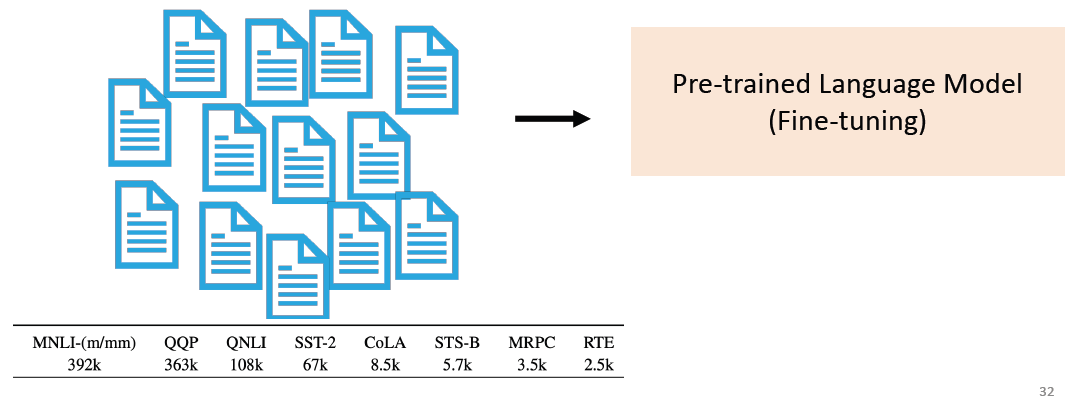
这里面的数据集最少都是几千级的,但在现实中想要弄到这么多的数据还是非常困难的。
# 2.2 Problem 2: The PLM is too big
The PLM is too big, and they are still getting bigger:
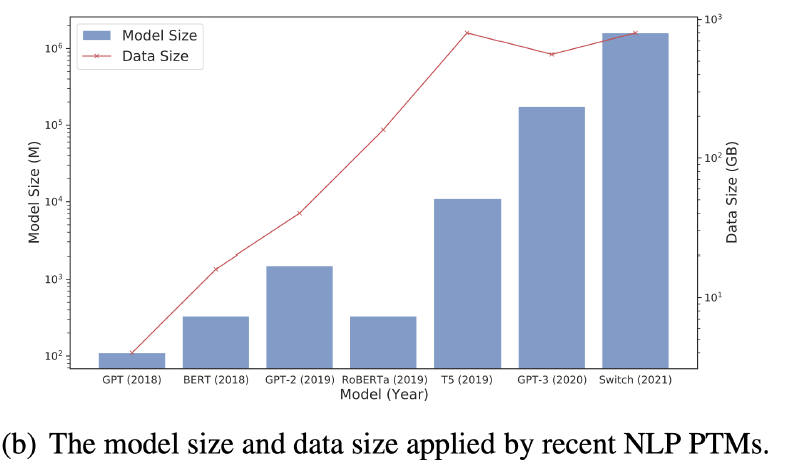
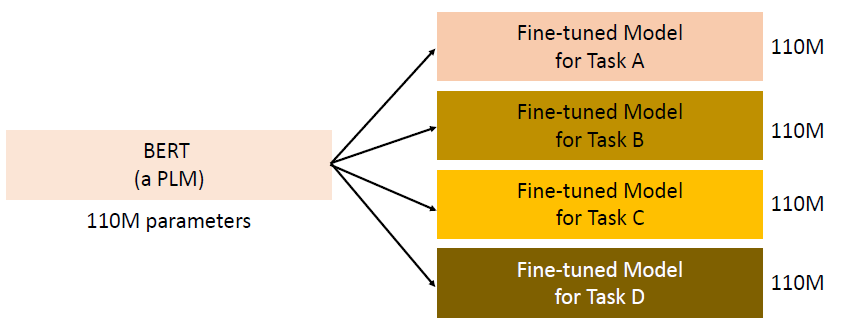
在实际应用时,这么大的模型,我们需要为每个 downstream 都弄一份 copy,这会特别占据空间:
而且这么多层的模型,计算一次 inference 都需要花费特别多的时间。
因此,模型越来越大的问题可以总结为两个:
- Inference takes too long.
- Consume too much space.
# 3. Labeled Data Scarcity -> Data-Efficient Fine-tuning
# 3.1 Prompt Tuning
# 3.1.1 什么是 Prompt Tuning?
以往在做 natural language inference 时,我们往往会这么做:

但如果 training data 较少的话,这往往是难以做出来的:

此时一种方法是,都加上一句 “Is is true that” 来表示询问后面这个句子与前面句子的关系,如下图所示:

这个东西就是 Prompt Tuning 的核心概念,也就是设置一些东西告诉 model 我们在做什么。所以说,By converting the data points in the dataset into natural language prompts, the model may be easier to know what it should do.
什么是 Prompt Tuning 呢?Format the downstream task as a language modelling task with predefined templates into natural language prompts.
# 3.1.2 Prompt Tuning 需要什么
What you need in prompt tuning:
- A prompt template
- A PLM
- A verbalizer
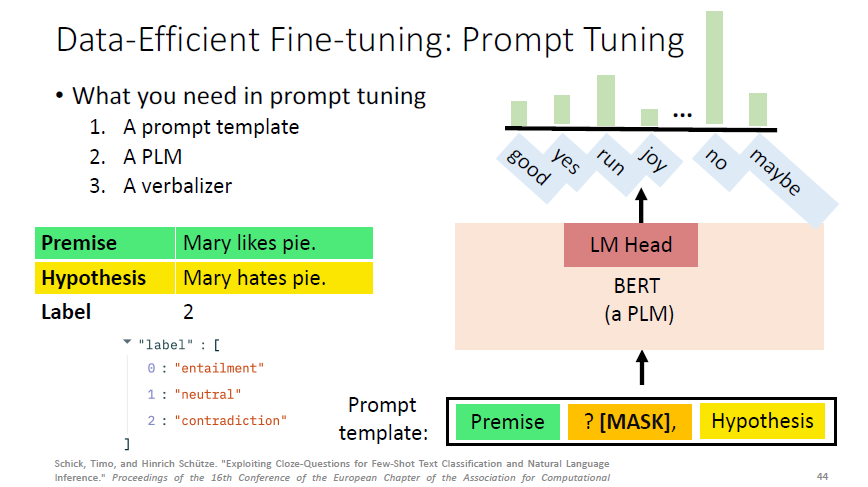
# 1)A prompt template
A prompt template: convert data points into a natural language prompt.
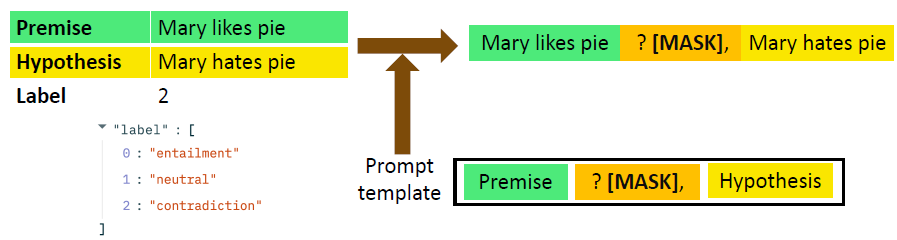
在得到 natural language prompt 后,就可以将它输入到 PLM 中,来预测 [MASK] 的部分是什么。
# 2)A PLM
A PLM: perform language modeling.
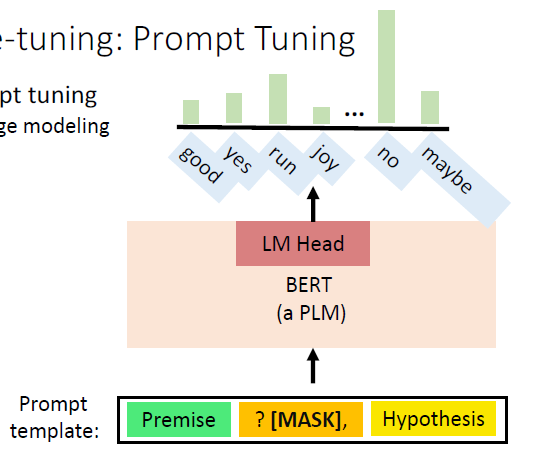
# 3)A verbalizer
A verbalizer: A mapping between the label and the vocabulary. For example, which vocabulary should represents the class “entailment”:

然后在神经网络中,我们就可以这么干了:
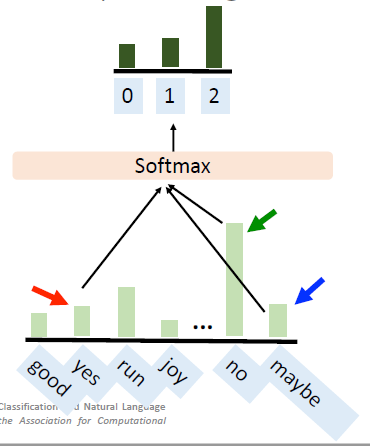
# 3.1.3 Prompt tuning v.s. Standard fine-tuning
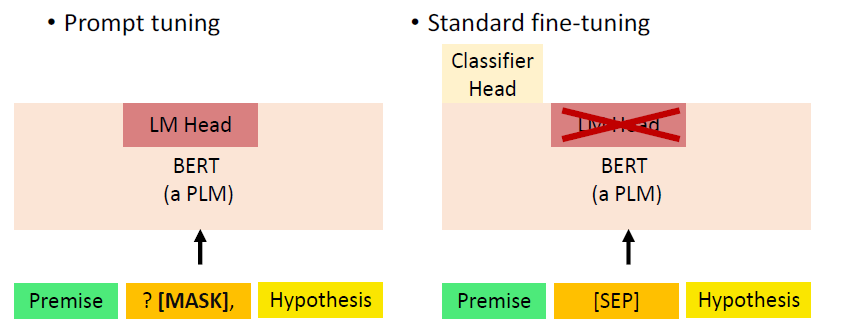
- 在 standard fine-tuning 中,我们会丢掉 LM Head 并重新 initialize 一个 Classifier Head;
- 而在 prompt tuning 中,我们就是要利用 language model 的能力,因此不会丢弃这个 language model 的 head。
Prompt tuning has better performance under data scarcity because:
- It incorporates human knowledge(因为 prompt template 的设计本身就融入了 human knowledge)
- It introduces no new parameters
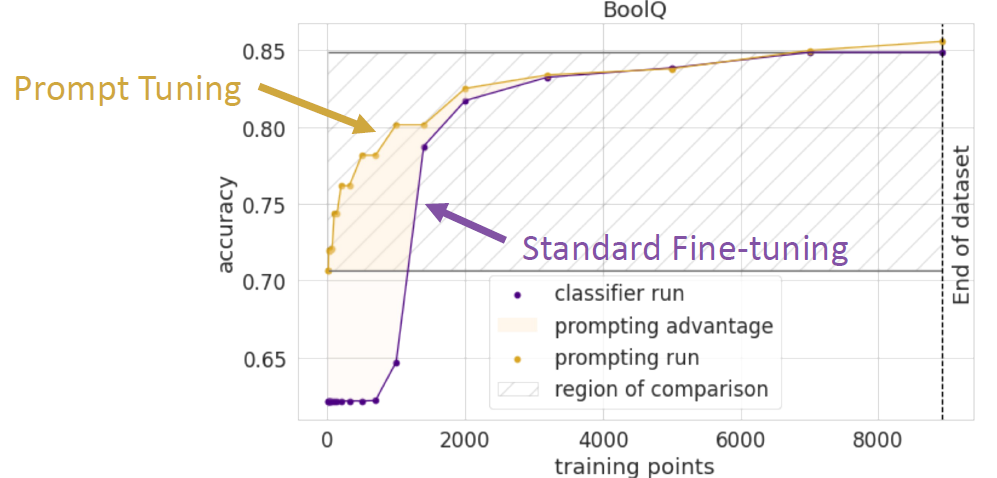
下面,Lets see how prompts can help us under different level of data scarcity.
# 3.2 Few-shot Learning
Few-shot Learning: We have some labeled training data.
但 Few-shot Learning 也是一个没有明确定义的词,具体多少是 few-shot,并没有具体的范围,在这里假设 few-shot 是指的 “Some ≈ 10GB training data”。
Good News 是 GPT-3 可以被用于做 few-shot learning,但 bad news 是:GPT-3 is not freely available and contains 175B parameters.
Can we use smaller PLMs and make them to perform well in few-shot learning?
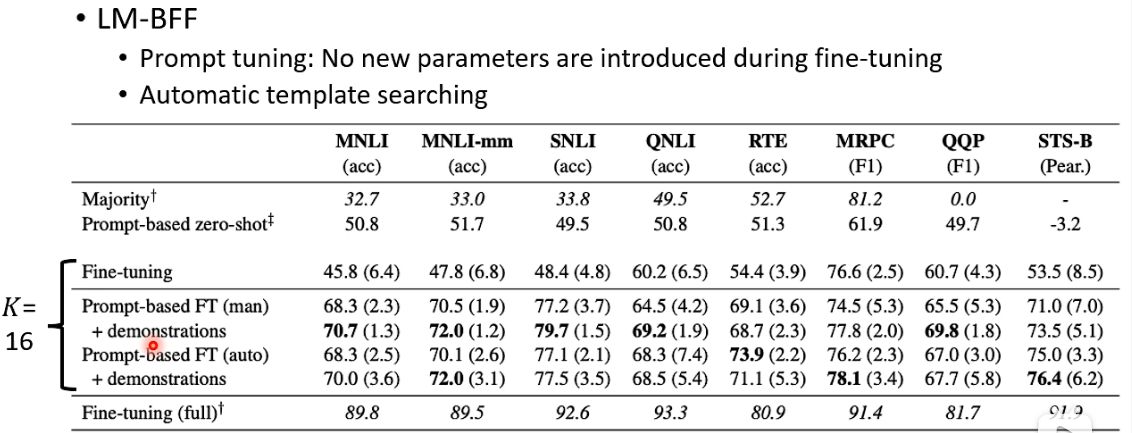
LM-BFF: better few-shot fine-tuning of language models. 它的核心概念:prompt + demonstration。
prompt 是指下面这个样子:
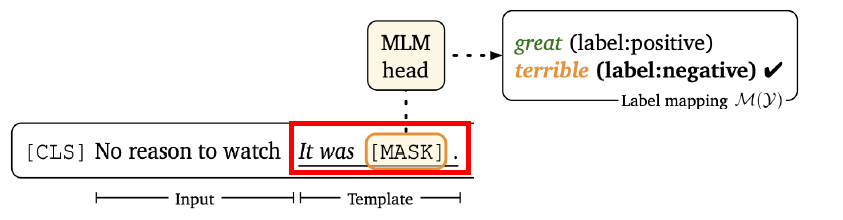
而 demonstration 是说,我要让 model 知道,当它看到这样的 prompt 之后,它该去怎么做。所以 demonstration 的做法就是,在 prompt 的部分后面加了两个 demonstration 的句子:

给他一个正面的 review,当 model 看到正面的 review 之后,它应该知道后面 “It was ___” 这里应该填 “great”,类似的,当他看到负面的 review 之后,它应该知道后面的 “It was ___” 这里应该填 “terrible”。 这样的形式就可以更加帮助 language model 在 few-shot learning 上面的表现。
其 performance 如下:
# 3.3 Semi-supervised Learning
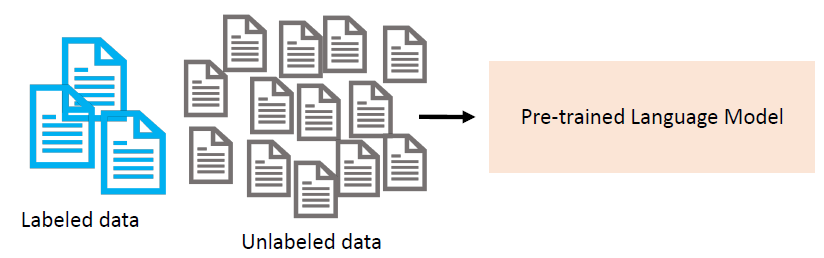
Semi-supervised Learning: We have some labeled training data and a large amount of unlabeled data.
这里主要看一下:It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners (opens new window),因为 GPT-3 的论文就是 Language Models are Few-Shot Learners (opens new window),所以前者就像有点在打脸 GPT-3 的样子。
它提出的方法叫做 Pattern-Exploiting Training (PET),具体分成了三个步骤:
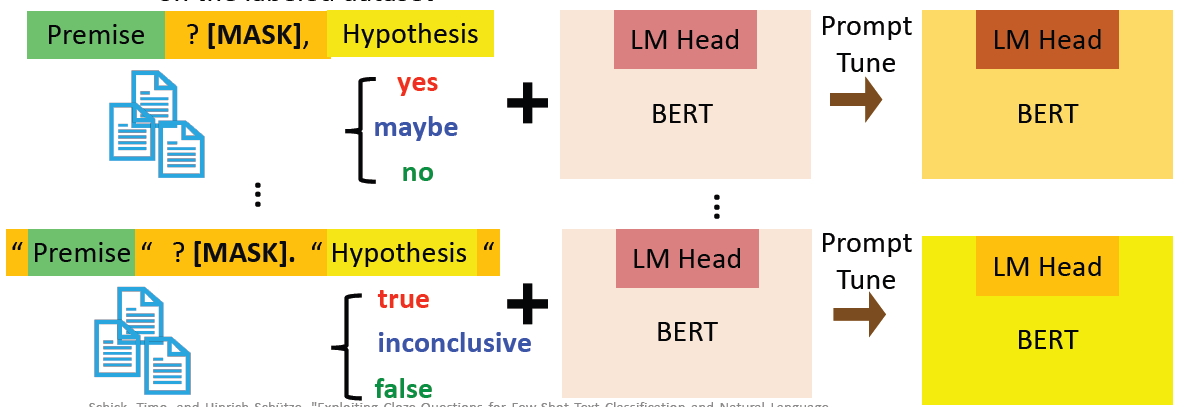
- Step 1: Use different prompts and verbalizer to prompt-tune different PLMs on the labeled dataset.
- Step 2: Predict the unlabeled dataset and combine the predictions from different models.
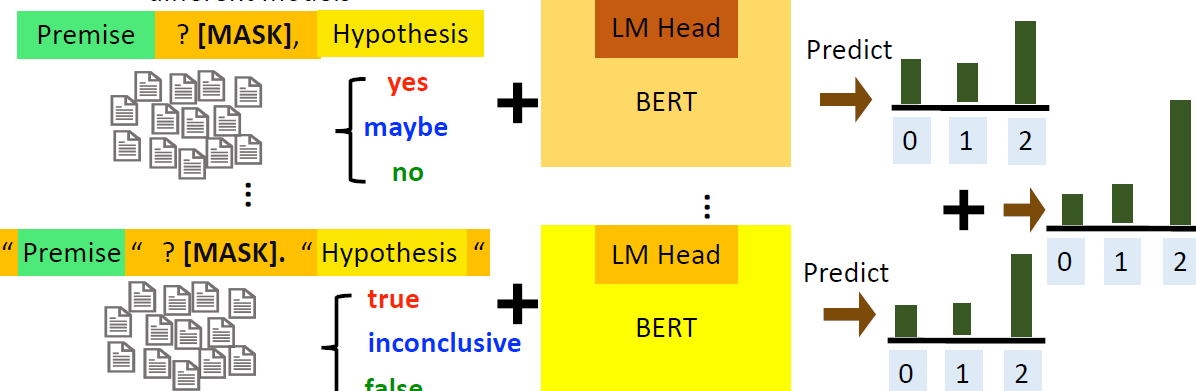
对同一笔数据,不同 prompt-tune 得到的 model 给出的 prediction 也许是不一样的,我们拿到这些 prediction 后再将他们 combine 到一起,在这里可以只是简单地相加。
- Step 3: Use a PLM with classifier head to train on the soft-labeled data set.
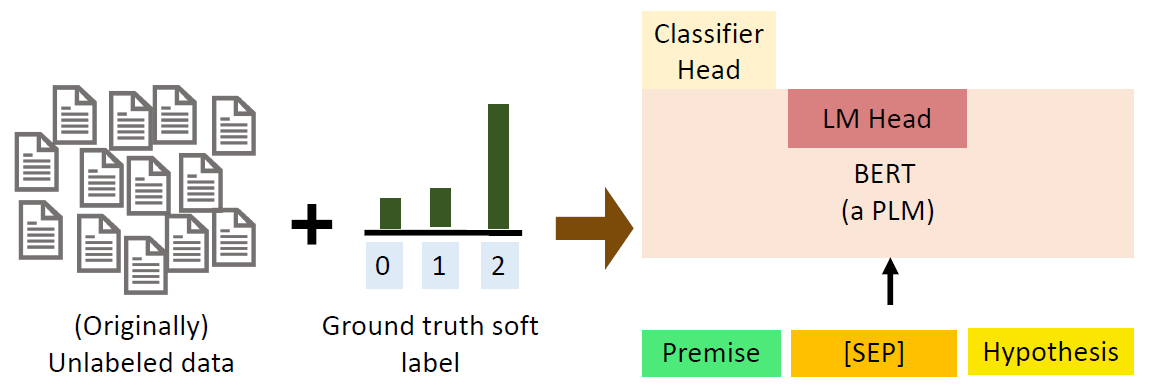
这一步是在所有的 dataset 进行 fine-tuning,对于 labeled data 则是用的原 label,而对于 unlabeled data,则用的是 soft label,即我们在 step 2 中得到的 label,然后进行 standard fine-tuning,也就是拿掉 LM Head 再加一个 Classifier Head 进行 fine-tuning。
# 3.4 Zero-shot Learning
# 3.4.1 什么是 zero-shot?
Zero-shot inference: inference on the downstream task without any training data. If you don’t have training data, then we need a model that can zero-shot inference on downstream tasks.
什么样的 model 可以做 zero-shot inference 呢?GPT-3 可以!GPT-3 的可以告诉了我们一件事情:Only if your model is large enough.
Zero-shot: The model predicts the answer given only a natural language description of the task. No gradient updates are performed. 比如如下面所示,你告诉要做的 task description,然后再给一个 prompt:
它的 performance 如下图,可以看到随着参数量越来越多,performance 会越老越好,但 zero-shot 其实也没有特别好,还是有很多的提升空间:
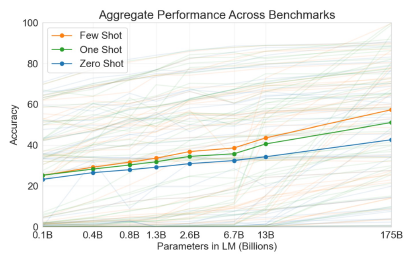
# 3.4.2 Where does this zero-shot ability spring from?
💡 Hypothesis: during pre-training, the training datasets implicitly contains a mixture of different tasks.
为什么 GPT-3 可以做到 zero-shot inference 呢?一个假说认为,我们 pre-training 的过程就很像是一个 multi-task learning 的环境,pre-training data 里面有各种各样的 task,因此能让他学到 multi-task learning 的能力。
比如说它可能会看到 QA 的文本,如下所示,一个 Q 开头,一个 A 开头,这其中就暗示了 QA task 了:

又比如下面这个例子,当他看到 one-sentence summary 时,他就知道上面的 abstract 的那一大段话用一句话来表述的话,就是后面这句话的样子,因此这也暗示了 summarization 的 task:

所以说,during pre-training, the training datasets implicitly contains a mixture of different tasks.
到了这里,有人就想到说,与其让他 implicitly 学习这种能力,不如让他 explicitly 学习这种能力。
💡 Hypothesis: multi-task training enables zero-shot generalization.
有人就对 T5 模型用 multi-task learning 的方式进行 fine-tuning,然后测试看在 fine-tuning 之后,这个 model 有没有能力做 zero-shot learning:
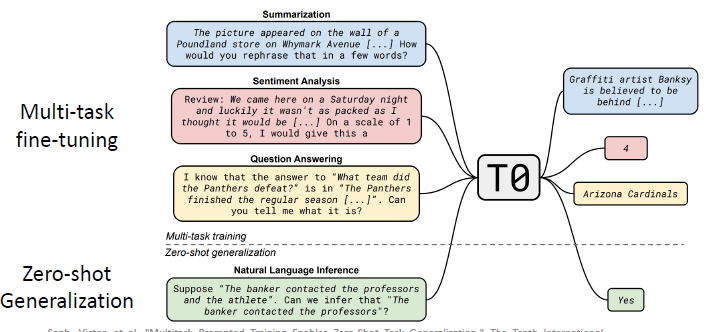
具体的做法与之前是一样的,就是将非常多的 dataset 转换成多种类型的 prompts 的形式,然后给他看很多的 prompt。比如下面这个例子就是在做 Natural Language Inference (NLI) 时,将 NLI dataset 转换成 Natural language prompt 的示例:

我们要 train 的 task 有很多不同种类,我们将这些 tasks 分成两类,如下图所示,黄色的一类 tasks 会用于 fine-tuning 过程,然后剩下的绿色的一类 tasks 会用于 zero-shot inference 的测试。
上面所讲的这种做法,sometimes achieves performance better than GPT-3 (175B parameters) with only 11B parameters. 效果还是很不错的。
# 3.5 Summary
我们总结一下做了什么,在 dataset 比较少的时候,我们可以 use natural language prompts and add scenario-specific designs:

# 4. PLMs Are Gigantic -> Reducing the Number of Parameters
这一章就是讲当 PLM 太大的时候,应该怎么样让他小一点。
最直接的想法就是让 PLM 更加小一点,但是这其实是有问题的,因为直接对小的 PLM 进行 pre-training 后,其实你还是用的同样的 corpus、同样的时间来预训练,最终结果的 performance 相比于大的 model 相差了很大一截,所以直接用小的 PLM 来做 pre-training 是不太可行的。
比较可行的一个方法是减少我们在 fine-tuning 时所需要用到的参数的量。这其实就有很多不同的方式了。
# 4.1 Pre-train a large model, but use a smaller model for the downstream tasks.
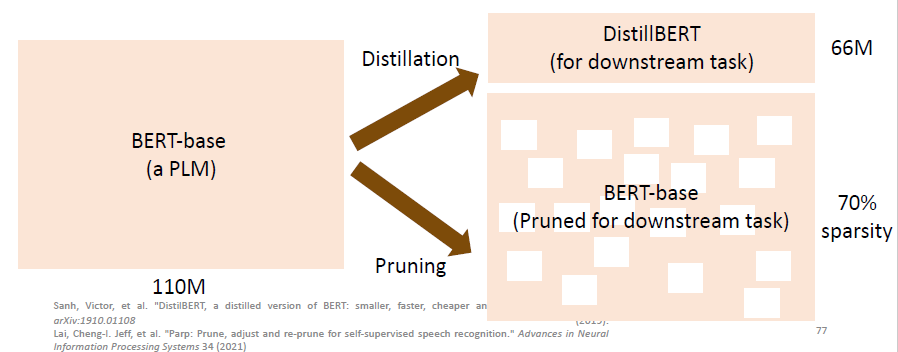
下面这个 pruning 的做法得到的 BERT-base 虽然结构还是比较大,但是由于它的 sparsity 比较高,因此占用的空间就小了很多了。
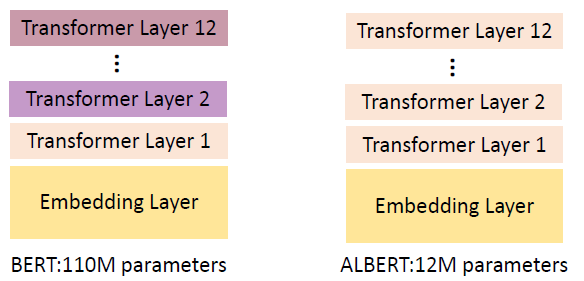
# 4.2 Share the parameters among the transformer layers: ALBERT
以往的不同 Transformer Layer 的参数是不一样的,但在 ALBERT 中,每一层的参数都是一样的:
# 4.3 Parameter-Efficient Fine-tuning
这种方法就是希望在 fine-tuning 的时候,怎样用少一点的 parameters。一种方法是下面这种:
🚀 Use a small amount of parameters for each downstream task
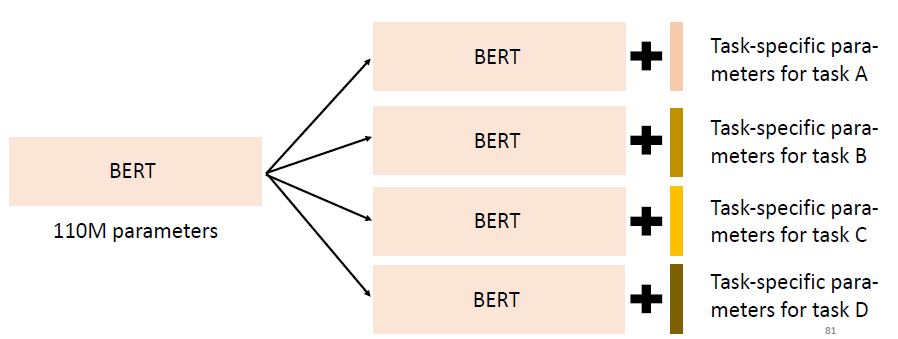
这样我们就只需要一个 BERT 的参数,再加上对每个 task 有一个专属的 parameters,从而大大降低我们所需要的空间。
这件事情怎么做呢?
要做这件事情之前,我们先看一下 standard fine-tuning 真正做了什么。standard fine-tuning 真正做的事情是:Modify the hidden representation (
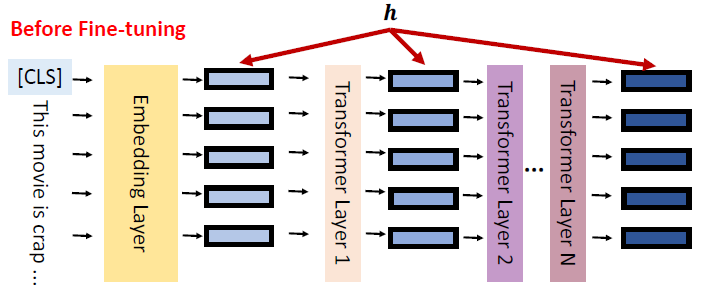
经过了微调之后,PLM 内部的
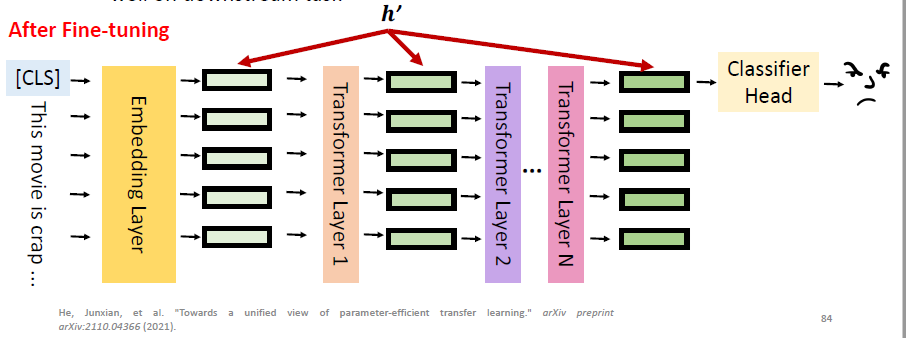
这个微调后的 hidden representation 能够被 classifier head 很好地利用。以上就是 standard fine-tuning 所做的事情。
所以说,standard fine-tuning = modifying the hidden representation based on PLM. 也就是将 hidden representation 从
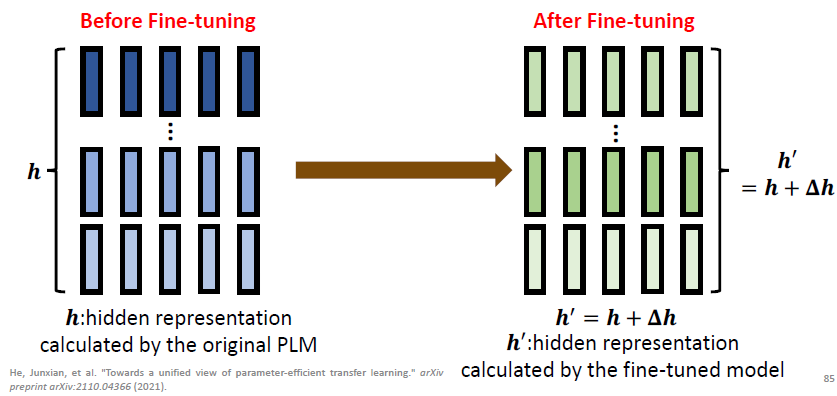
但现在我们想问的是,我们有没有办法不要调整整个 model 的参数,而是只要改变少部分的参数就可以达到改变 hidden representation 的目标呢?这里 parameter-efficient fine-tuning 所要做的就是这件事情。下面就看一下不同的 parameter-efficient fine-tuning 是怎么做的。
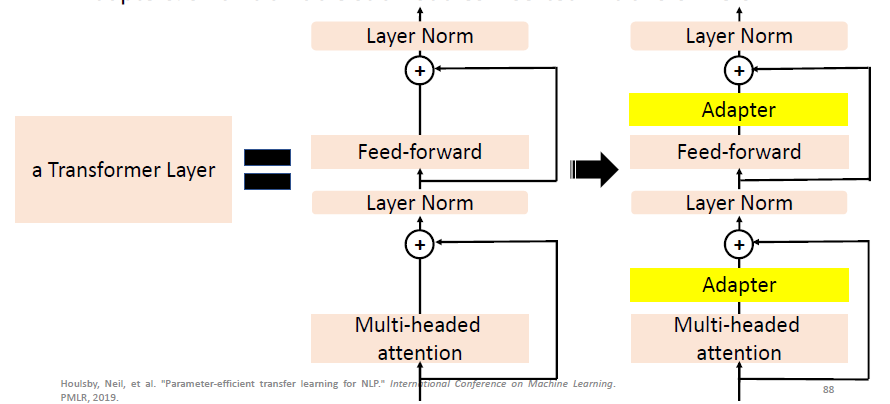
# 4.4 Parameter-Efficient Fine-tuning: Adapter
Adapter 就是 use special submodules to modify hidden representations:
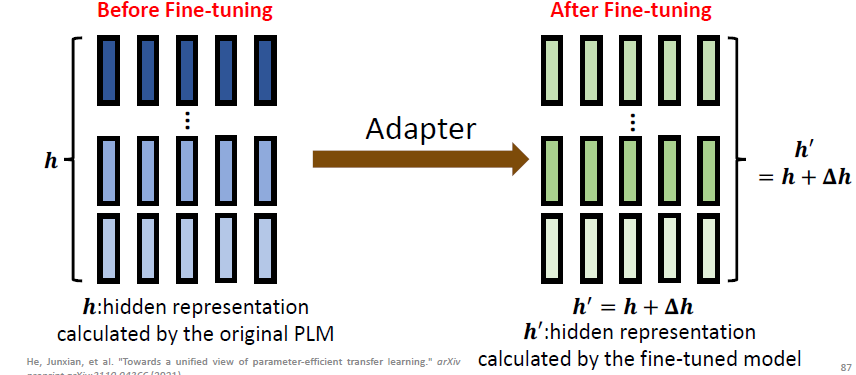
Adapters: small trainable submodules inserted in transformers.
这里的 Adapter 长什么样呢?如下图所示,hidden representation
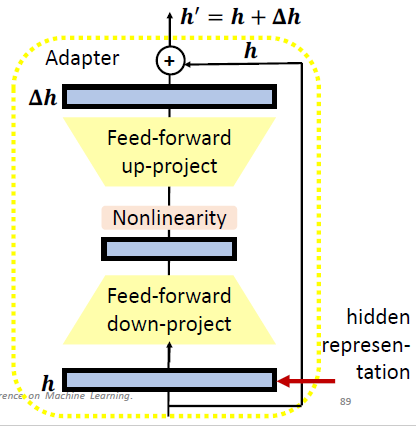
所以在这个技术中,我们 fine-tuning 的只需要去 update 我们的 adapters 和 classifier head 就可以了。
# 4.5 Parameter-Efficient Fine-tuning: LoRA
从整体上看,LoRA 所要做的事情与刚刚是一样的:
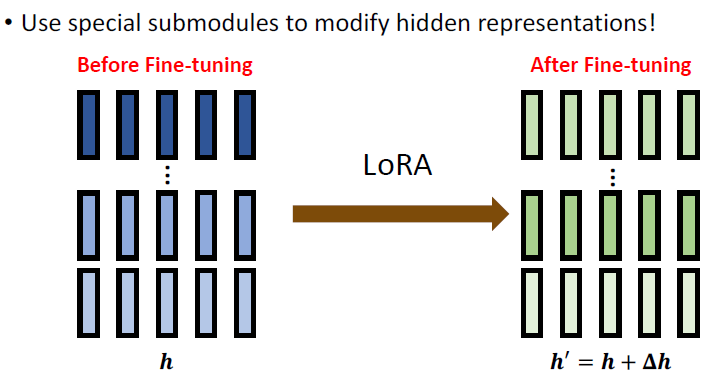
LoRA: Low-Rank Adaptation of Large Language Models. 如下图所示,它所做的就是在 Feed-forward 部分上平行地加上了一个 submodule:

Feed-forward 部分原来就是一个两层的 MLP,现在加上 LoRA 后,结构如下图:
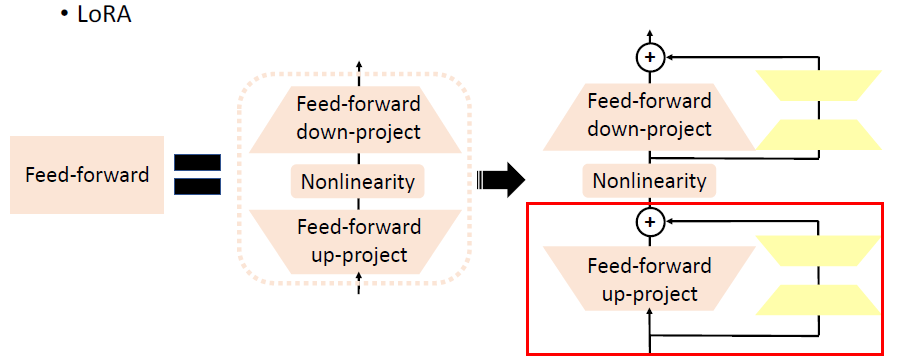
LoRA 的 submodule 会加上原来的 MLP 的输出,从而共同构成输出。如果我们放大红色方框的部分,可以看到具体做法如下:
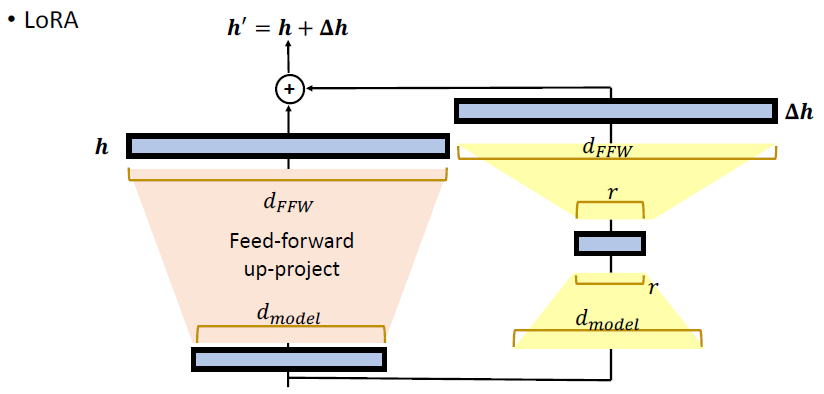
原来的
这样的话,所有的 downstream tasks 共享一个 PLM,然后每一层的 LoRA submodule 和 classifier head 才是 task-specific modules。
LoRA 的卖点之一是,它的 submodule 是平行地插在 feed-forward 部分上,这样不会增加 inference 的时间,而 Adapter 技术则是加深了网络的深度,这导致了 inference 时间的增加。
# 4.6 Parameter-Efficient Fine-tuning: Prefix Tuning
Prefix Tuning 所做的事情也是一样:
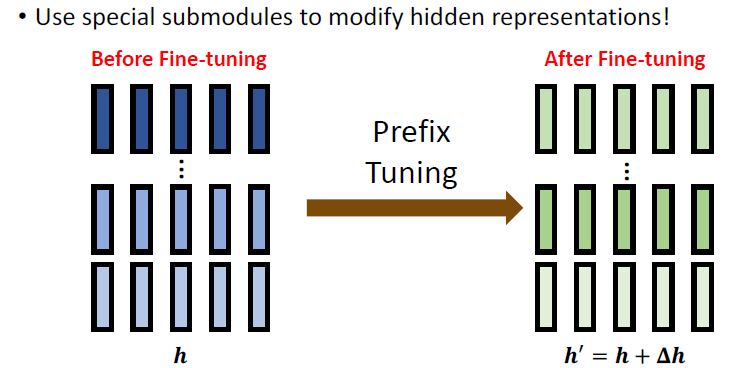
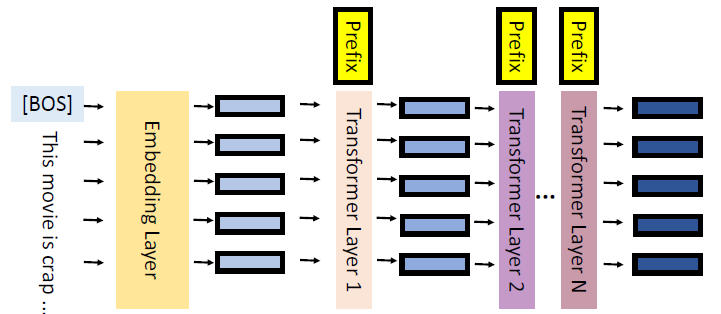
Prefix Tuning: Insert trainable prefix in each layer.
为了讲 prefix tuning,我们先回顾一下 standard self-attention 的操作,如下图所示,为了计算
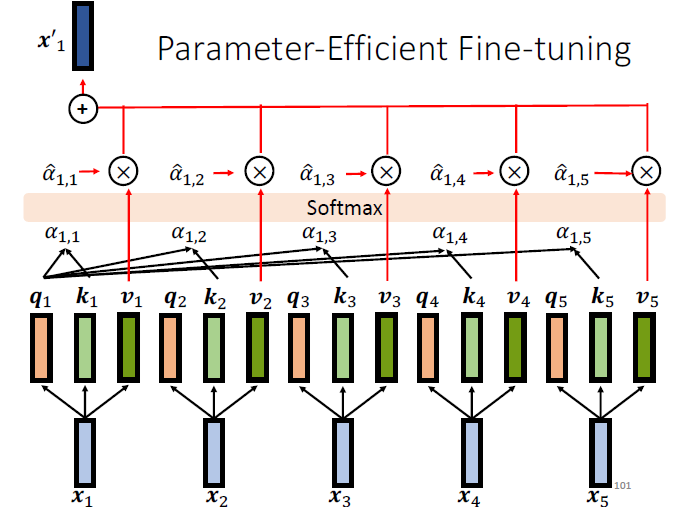
而 prefix tuning 则是在 standard self-attention 的基础上加了一些东西,如下图所示,所增加 prefix
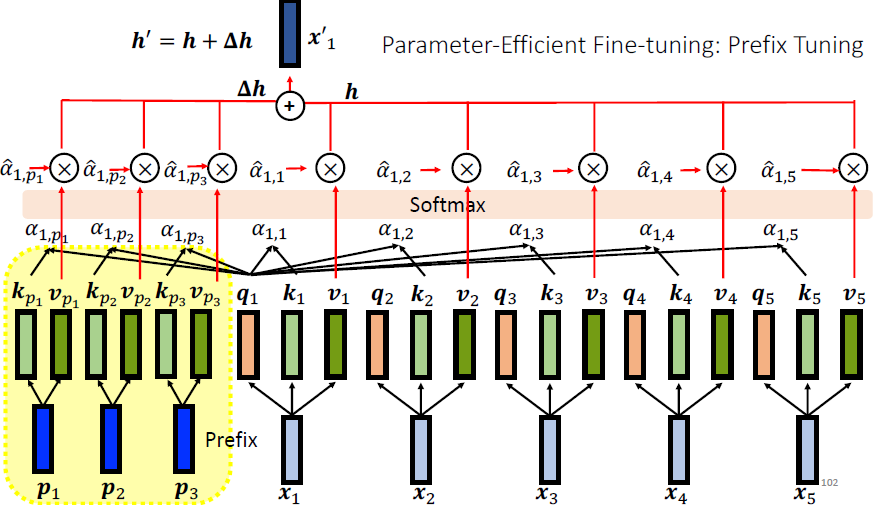
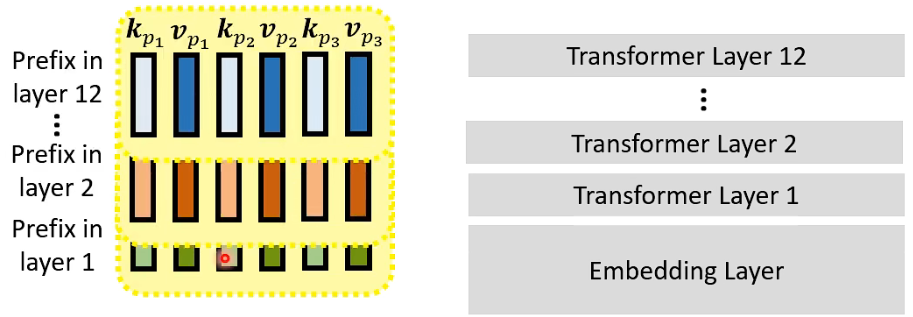
在 prefix tuning 中,Only the prefix (key and value) are updated during fine-tuning. 在最后,我们只需要保留 k v 就好,可以把 prefix
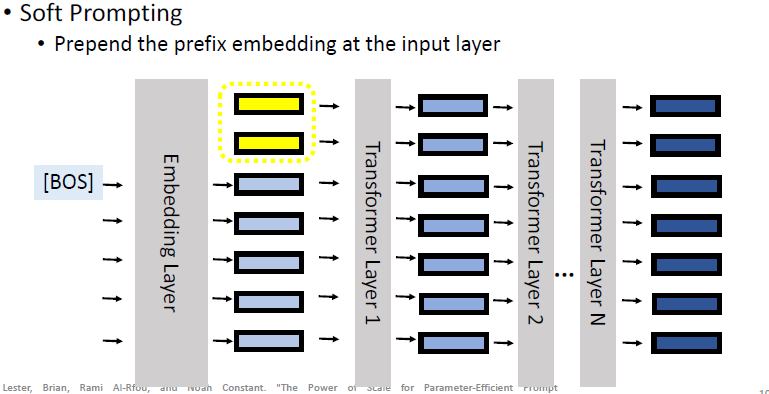
# 4.7 Parameter-Efficient Fine-tuning: Soft Prompting
这个 Soft Prompting 可以看成是一个 prefix tuning 的一个简化版,它就是只在 input layer 上插入了几个 prefix embedding:
为什么这叫做 soft prompt 呢?之前的 prompt 方式是 Hard Prompting:add words in the input sentence (fine-tune the model while fixing the prompts):
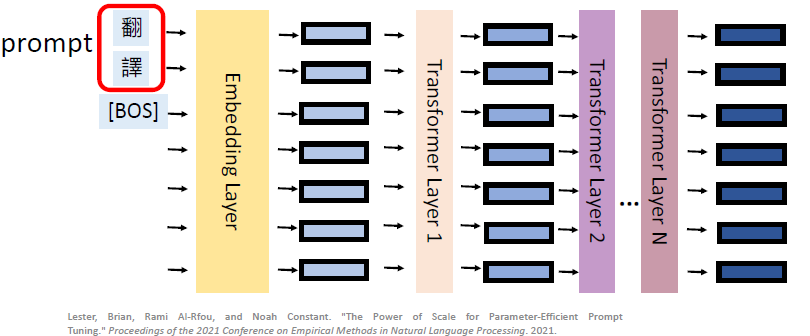
在这种 hard prompting 中,你是没有办法直接调这个 prompt 的字,因为它们又不是可以微分的,因此比较 hard。而 soft prompting can be considered as the soften version of prompting.
Soft Prompt v.s. Hard Prompt

# 4.8 总结 Parameter-Efficient Fine-tuning
- 🍨 Benefit 1:Drastically decreases the task-specific parameters.
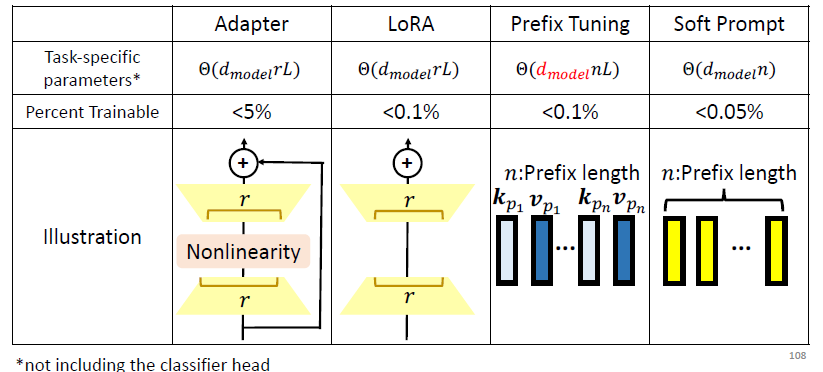
Adapter 和 LoRA 的 percent trainable 差距很大的原因在于
Soft Prompt 往往需要在 model 很大的时候,效果才会比较好,而其余的则没有要求 model 很大。
- 🍨 Benefit 2: Less easier to overfit on training data; better out-of-domain performance.
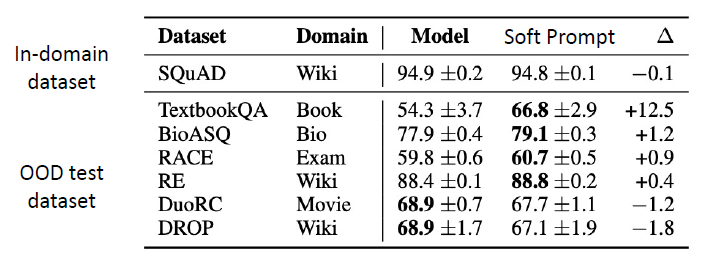
可以看到,soft prompt 虽然参数比较少,但是效果还是很好的,尽管在后面两个 dataset 上 performance 略有降低,但也没有降低很多了。
- 🍨 Benefit 3: Fewer parameters to fine-tune; a good candidate when training with small dataset.

可以看到,在 low-resource 的情况下可以表现更好,而在 high-resource 的情况下,即使用了较少的参数,但 performance 也没有掉太多。
# 4.9 Early Exit
这个主题的目的也是想要减少 downstream task 的 parameters 数量,不过它是动态减少的。
传统的 PLM 是用最后一层的 hidden representation 来训练一个 classifier,而问题是使用整个模型来做 inference 太花时间了,于是有人提出 Simpler data may require less effort to obtain the answer. 于是有了这么一个想法:Reduce the number of layers used during inference。
这样的做法就是在每一层上加一个 classifier:
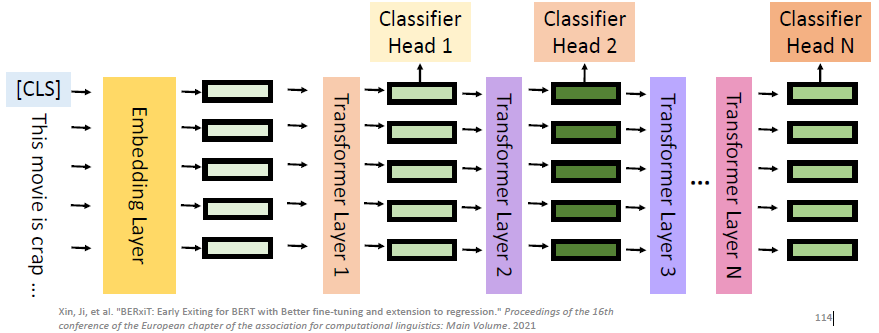
但这样的话,现在的问题就是:How do we know which classifier to use? 这其实有很多不同的做法,这里讲一个最新的做法:
我们额外又训练一个叫做 Confidence predictor 的 submodule,这个 predictor 会根据 classifier 和 hidden representation 来 predict 说这个 classifier 的结果够不够有信心:
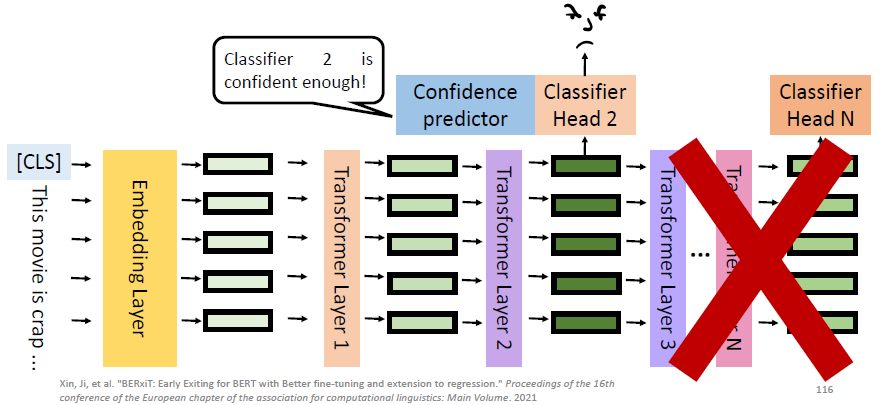 ****
****
比如上图中,在第一层的 classifier 被认为是不够有信心的,于是会来到 classifier 2,这时 predictor 认为有足够信心了,于是就可以直接拿这个 classifier 的 output 当做最终的 output,而不需要再去看后面的部分了。
所以 Early exit reduces the inference time while keeping the performance。
# 4.10 Summary
- Parameter-efficient fine-tuning: Reduce the task-specific parameters in downstream task.
- Early exit: Reduce the models that are involved during inference.
# 5. Closing Remarks
What we address in this lecture:
- Making PLM smaller, faster, and more parameter-efficient
- Deploying PLMs when the labeled data in the downstream task is scarce
The problems we discuss are just a small part of problems of PLMs, and the problems are not completely solved yet:
- Why does self-supervised pre-training work
- Interpretability of the model's prediction
- Domain adaptation
- Continual learning/lifelong learning
- Security and privacy