 机器学习的可解释性
机器学习的可解释性
之前训练的模型可以根据我们的 input 得到 output,但我们不满足于此,我们想要机器给出它得到答案的理由,这就是 Explainable 的 Machine Learning。
# 1. Why we need Explainable ML?
Correct answers ≠ Intelligent,就算今天机器可以得到正确的答案,也不代表它一定非常聪明。举一个例子,过去有一个神马汉斯,据说可以算数学题,你问它根号 9 等于多少,它会敲三下就停下来,旁边的人就会欢呼。后来有人发现说,它其实是通过侦测到周围人微妙的情感变化来决定什么时候停下跺马蹄,而并不是真的会解数学问题。今天我们看到的种种 AI 的应用,有没有就可能跟神马汉斯一样呢?
在今天很多真实应用中,可解释性的 model 往往是必须的:
- loan issuers are required by law to explain their models.
- Medical diagnosis model is responsible for human life. Can it be a black box?
- If a model is used at the court, we must make sure the model behaves in a nondiscriminatory manner.
- If a self-driving car suddenly acts abnormally, we need to explain why.
更进一步说,如果 model 具有解释力的话,那未来我们可以凭借着解释的结果,再去修正我们的模型。现在的 DL 在改进模型时需要调一些 hyperparameter,但我们期待未来,在 DL 犯错的时候,我们可以知道它错在什么地方,为什么犯错,这样也许就有更好的办法来 improve 我们的 model。
# 2. Interpretable v.s. Powerful
有人觉得 Deep Learning Network 本身就是一个黑箱,那改用其他容易解释的模型也许就不需要研究 Explainable ML 了。假设都采用 Linear Model,Linear Model 的可解释能力是比较强的,我们可以从它的每一个 feature 的 weight 得到 Linear Model 在做什么事。但问题是它没有非常 powerful。
真实的 powerful model 也许根本就在路灯之外,而我们要做的事情就是改变路灯的范围,看能不能让 powerful model 也可以被置于路灯之下。
Interpretable 和 Explainable
Interpretable 和 Explainable 虽然在文献上常常被互相使用,但其实还是有一点点差别的:
- Explainable 是说一个东西本来是个黑箱,我们想办法赋予它解释的能力;
- Interpretable 通常说一个东西它本来就不是黑箱,我们本来就可以知道它的内容。
不过这两个术语常常在文献中混用。
另外有人会说 Decision Tree,它相较于 Linear model 更加强大,相较于 Deep Learning 更加 Interpretable:

但实际上在真正应用时,用到的技术是 Random Forest,其实是好多棵 Decision Tree 共同决定的结果。一棵 Decision Tree 也许容易解释,但当有一片森林,面对 500 棵 decision tree 时,也很难说它们合起来是怎么做出判断的。
# 3. Goal of Explainable ML
Explainable Machine Learning 的目标是什么?以下是我(李宏毅)个人的看法。
很多人对於 Explainable Machine Learning 会有一个误解,觉得一个好的 Explanation 就是要告诉我们整个模型在做什么事,我们要完全了解它是怎么做出一个决断的。但你想想看这件事情真的是有必要的吗?其实世界上有很多很多的黑盒子在你身边,人脑不是也是黑盒子吗,我们其实也并不完全知道人脑的运作原理,但是我们往往可以相信另外一个人做出的决断,那为什么对 Deep Network 做出的决断那么恐惧呢?那我觉得其实对人而言,也许一个东西能不能让我们放心和接受,理由是非常重要的,
有一个心理学实验,哈佛大学在排队打印时,如果一个人跟前面的人说能不能先让自己打印,自己就只印 5 页而已,这时有 60% 的人同意。之后再把理由改成因为我赶时间,这时接受程度会变成 94%。神奇的是就算把理由改成“我需要先印”,光是这样,接受程度也有 93%。所以,人就需要一个理由,你为什么先印,你只要讲出一个理由。
那么什么是好的 Explaination?好的 Explanation 就是人能接受的 Explanation,人就是需要一个理由来让我们感到高兴。到底让谁高兴呢,也许是你的客户,也许是哪些觉得 Deep Learning 是一个黑盒子而不爽的人,也许你需要说服的就是你自己,今天给你了一个做出决断的理由,你就高兴了。
# 4. Local Explaination
Explainable 的 Machine Learning 又分成两大类:Local Explanation 和 Global Explanation。
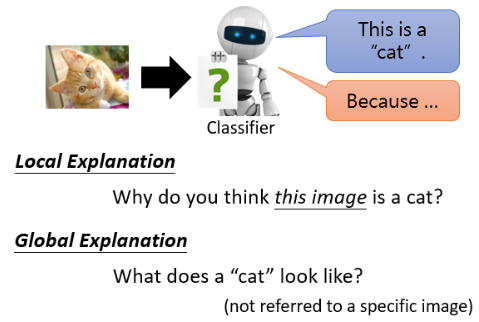
- Local Explanation 是要回答为什么它聚德这张图片是一只猫;
- Global Explanation 并不是针对任何一张特定的图片来进行分析,而是说当我们有一个 model,里面有一堆 parameters,对 model 而言,什么样的东西叫作一只猫。
我们先看 Local Explaination,也就是为什么你觉得一张图片是一只猫。
# 4.1 Which component is critical?
Local Explaination 问的再具体一点,就是到底是图片里的什么东西让 model 觉得这是一只猫?假设把 model 的输入叫做 x,这个 x 可以拆成多个 component
对 image,component 可以是 pixel;对文字,component 可以是 token。
那怎么知道一个 component 的重要性呢?可以对某一个 component 做改造或删除,如果 Network 的 output 有了巨大变化,那这个 component 就是很重的。对于 image 来说,在 image 不同位置放上灰色方块,再输入 Network 看看结果:
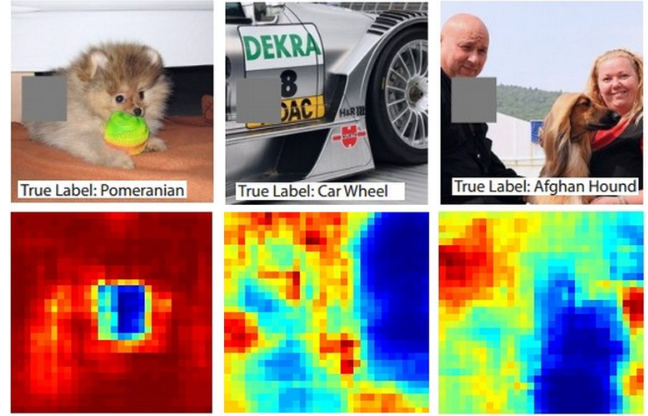
- 蓝色代表博美狗的机率是低的,红色代表博美狗的机率是高的。把狗头盖住后几率变低,说明机器觉得狗头比较重要。
# 4.2 Saliency Map
接下来还有一个进阶的方法:计算 gradient。
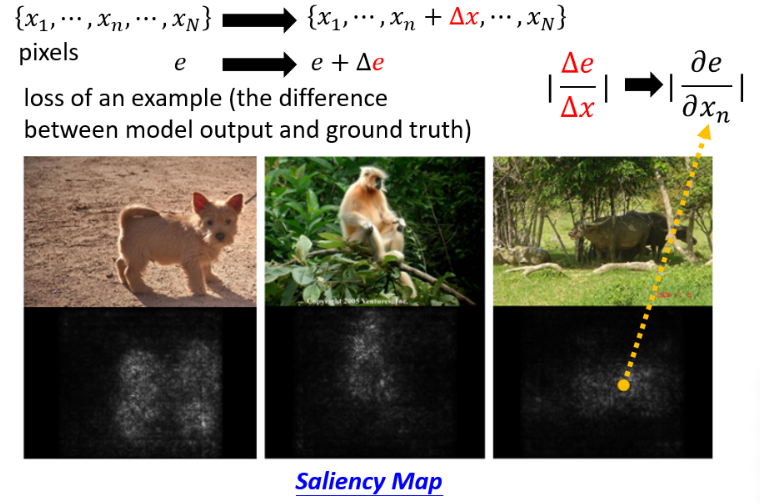
- 如果今天把某个
因此
有什么办法能把 Saliency Map 画得更好呢?一种方法是 Smooth Grad。比如说下面这张图片:

- 用 Smooth Grad 可以让画出的 Saliency Map 把主要的精力集中到瞪羚身上。
Smooth Grad 就是你在图片上加上各种不同的杂讯,加不同的杂讯后就是不同的图片了,再对每一张计算 Saliency Map,将得到的每一张 Saliency Map 计算平均,就得到 Smooth Grad 的结果。其实这样做的目的也只是让人看了爽。
其实,光看 Gradient 并不完全能够反映一个 Component 的重要性,比如下面例子:
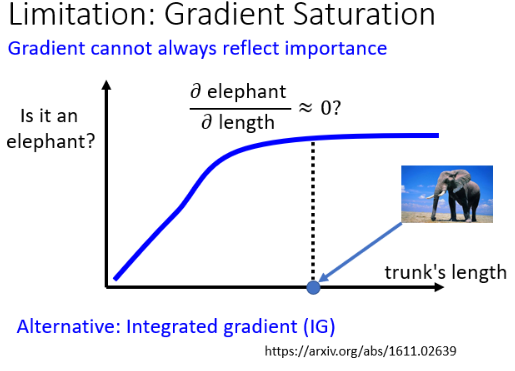
- 横轴代表的是生物的鼻子,纵轴代表说这个生物是大象的可能性
在鼻子长度比较短时,随着长度越来越长,这个生物是大象的可能性越来越大,但是当鼻子的长度长到一个程度以后,就算是更长,也不会变得更像大象。这时去计算鼻子长度对大象可能性的微分的话,结果可能趋近于 0,这时只看 Gradient 可能得出“鼻子长度对是不是大象不重要”的错误结论。
所以光看 Gradient 或 Saliency Map 可能没有办法完全告诉我们一个 Component 的重要性,这里还有其他的一种方法:nterated 的 Gradient(IG)。这里不再展开讲述 IG。
# 4.3 How a network processes the input data?
之前我们是看一个 input 的哪些部分比较重要,接下来再看一个 Network 怎么去处理一个 input 并得到最终的答案的。
我们研究用人眼来看 Network 里面发生了什么事。100 dim 的 tensor 不容易观察,这时可以把它降到二维(怎么做的不再展开),看看一个语音识别的例子:
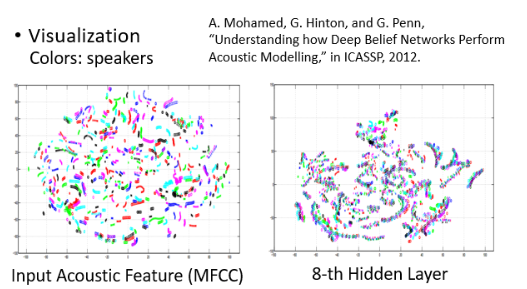
- 每一个点代表一小段声音讯号,每一个顏色代表了某一个 Speaker
- 可以看到 input 中同一个人他说的话就是比较相近,但说相同的内容,其 tensor 也差距很大。但神奇的是,通过了 8 层 Network 后,机器知道说这些话是同样的内容,不同人讲的相同内容竟然被 align 在了一起。
除了用人眼观察以外,还有另外一个技术叫做 Probing,就是用探针去插入这个 Network,然后看看说发生了什么事。举例来说,假设你想要知道 BERT 的某一个 Layer 到底学了什么东西,那你可以训练一个探针,你的探针其实就是分类器:
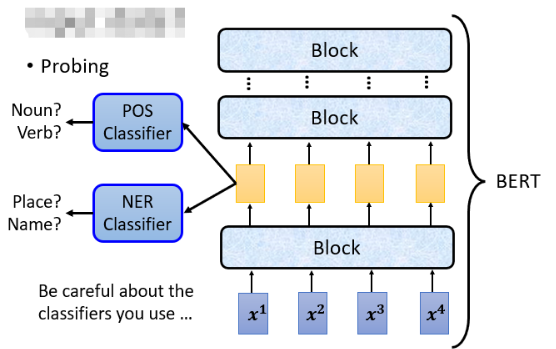
但是用这个技术时,要小心你使用的 Classifier 它的强度。当你的 classifier 的正确率很低时,不一定是因为这些 feature 里没有我们需要的资讯,可能就是你的 hyperparameters 没有调好。
Probing 也不一定要是 Classifier,它可以是其他东西,比如在语音辨识中可以在中间加一个探针,来还原声音来查看效果。
# 5. Global Explaination
Local Explaination 是给机器一张 image,它告诉我们说它为什么觉得这里面有一只猫,而 Global Explaination 并不针对某一张 image 来分析,而是把整个 model 拿出来,分析对这个 network 而言,它心里想象的猫长什么样子。
# 5.1 What does a filter detect?
有一个 CNN,里面有一堆 filter,输入一个 image X,每一个 convolutional Layer 输出一个 feature map,每一个 filter 给我们一个 metric。
如果今天输入 image X 后,在 filter 1 输出的 feature map 里很多位置有比较大的 value,那可能意味着这个 image X 里有很多 filter 1 负责侦测的那个特征,当 filter 1 看到这些 pattern 后,就会在它的 feature map 上呈现较大的 value。
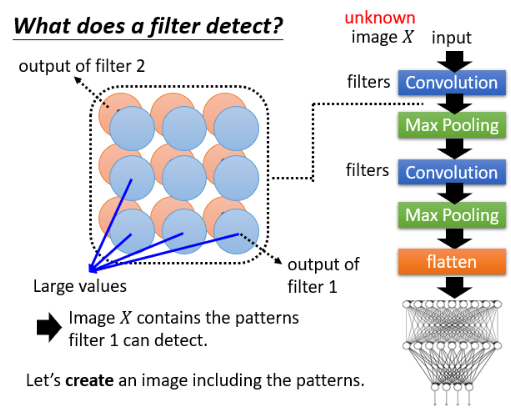
现在我们想看对于 filter 1 而言,它想要看的 pattern 到底长什么样子,那怎么做呢?那我们就去制造一张 image,让机器创造出一张 image,并让这张 image 包含有 filter 1 要 detect 的 pattern,那我们就可以从这张 image 中看到 filter 1 负责 detect 什么样的东西了。怎样寻找这张 image 呢?假设 feature map 每一个 element 用
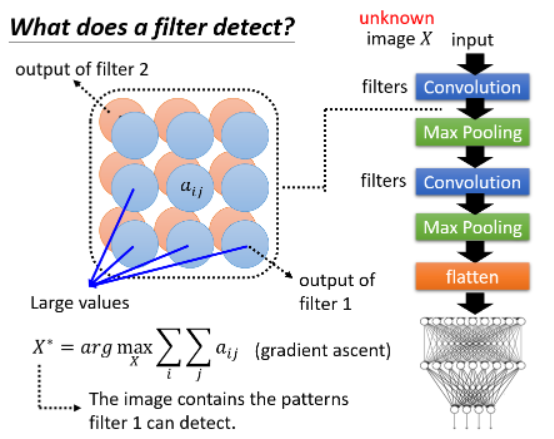
- 解这个问题的过程中要 maximize 某个东西,因此需要 Gradient ascent,找出的
我们用 mnist dataset 去 train 一个 classifier,并查看第二层的 Conv Layer 里的 filter 对应的

可以看到,它想要做的事情确实是去侦测一些基本的 pattern,比如左下角的是侦测竖线,右下角是侦测斜直线等等。
# 5.2 What does a digit look like for CNN?
假如我们不是看某一个 filter,而是看最终的这个 image classifier 的 output,我们想办法去找一个 image X 能够让某一个类别的分数越高越好。比如我们选数字 1 出来,找到的

- 会发现其实就是一堆杂讯,根本没有办法看到数字。
为什么会这样?如果学了 Adversarial Attack 的话,会知道在 image 上加一些人眼根本看不到的奇奇怪怪的杂讯,就可以让机器看到各式各样的物件。这边也是一样,对机器来说,它不需要看到真的很像 0 那个数字的图片时它才说它看到数字 0,在你给它一些乱七八糟的杂讯,它也会说看到数字 0,并且信心分数非常高。
假设我们希望我们今天看到的是比较像是人想像的数字,那应该怎么办?可以在解这个 Optimization 问题时加一些限制:

- 加一个限制,使其同时让
- 新加的 R(X) 用来衡量这个 X 有多像一个数字,因为数字图片中有颜色的地方是很少的,所以 R(X) 可以那样设计
- 这样的结果在数字 “6” 和 “8” 上已经有点感觉了
有论文可以展示出好的结果,但这个过程也要经历非常多的 Constraint 来解这个 Optimization Problem,而不是可以轻轻松松得到的:
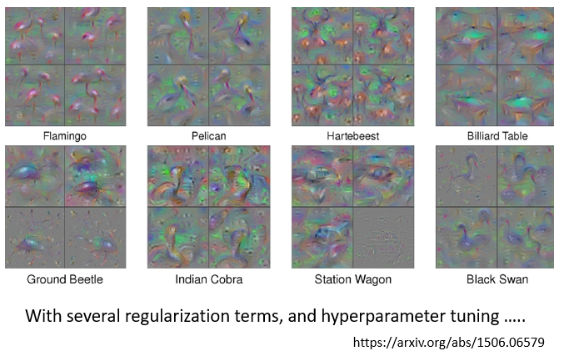
# 5.3 Constraint from Generator
在 Global Explanation 如果真的很想看到非常清晰的图片的话,还有一个招数是使用 Generator:
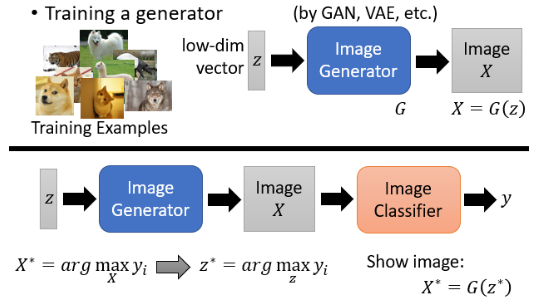
- 先训练一个 Image Generator,利用这个 Image Generator 来帮我们反推对于 image classifier 而言,它所想象的某一个类别长什么样。
好,我们看看这样找出来的

- 效果确实不错。
但讲到这里,你可能会觉得整个想法有点是强要这样,就是今天你找出来的图片如果跟你想像的东西不一样,比如今天找出来的火山跟你想像不一样,你就说这个 Explanation 的方法不好,然后你硬是要弄一些方法去找出来那个图片跟人想像的是一样的,你才会说这个 Explanation 的方法是好的。那也许今天对机器来说,它看到的图片就是像是一些杂讯一样,也许它心里想象的某个数字就是像是那些杂讯一样,但我们却不愿意认同这个事实,而是硬要想一些方法让机器產生出看起来比较像样的图片。其实今天的 Explainable AI 的技术往往就是有这个特性。我们其实没有那么在乎机器真正想的是什么,其实我们也不知道机器真正想的是什么,我们是希望有些方法解读出来的东西能让人看起来觉得很开心,然后你就说,机器想的应该就是这个样子,然后你的老板、你的客户听了很开心。今天的 Explainable AI 往往会有这样的倾向。
# 6. Concluding Remarks
我们介绍了 Explainable AI 的两个主流的技术:Local Explanation 和 Global Explanation:

其实 Explainable 的 Machine Learning 还有很多技术,这边再举一个例子,比如你可以用一个比较简单的模型想办法去模仿复杂的模型的行為,然后就可以通过分析简单地模型来了解复杂模型中在做什么:
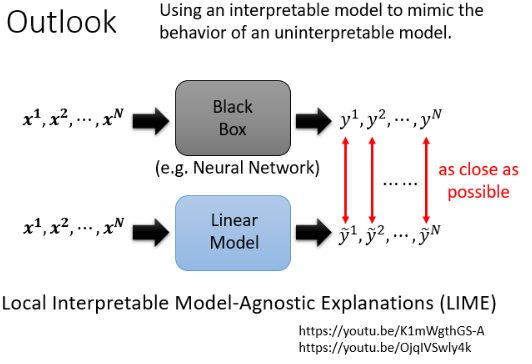
可能你怀疑一个 Linear Model 有办法去模仿一个黑盒子的行為吗?确实不一定能做到,这一系列 work 里有个特别知名的叫做 Local Interpretable Model-Agnostic Explanations(LIME),它也没有说要用 Linear Model 去模仿黑盒子全部的行為,它直接说它是 Local Interpretable,也就是只让 Linear Model 去模仿 black box 的一小个区域的行为,然后解读那一个小区域里发生的事情,这是一个非常经典的方法,就叫做 LIME。