 生成对抗网络 GAN
生成对抗网络 GAN
# 1. Generation
# 1.1 Network as Generator
今天要讲的主题是 Generation 这件事情。
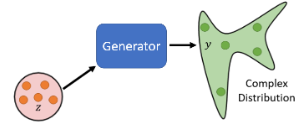
之前学的 Network 都是一个 function,给一个 input x 得到一个 output y。而所要学的新的主题是把 network 当做一个 generator 来使用。特别之处在于现在 network 的输入会加上一个 random 的 variable,即加一个
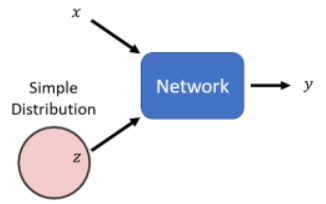
这个 network 怎样同时看 x 和 z 呢?可以直接拼接起来,也可以相加作为 input …
每次一个 x 进来时,都从 distribution 中 sample 一个 z,来得到 y,这样随着 sample 的 z 不同,y 也就不同。也就是说,同样的 x 作为输入,随着 sample 到的 z 不同,经过一个复杂的 network 转换后就变成了一个复杂的 distribution。图示:
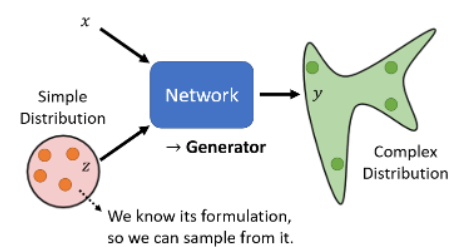
这种可以输出一个 distribution 的 network,我们就叫它 generator。
# 1.2 Why distribution?
为什么我们需要 generator 的输出是一个 distribution?比如在 video prediction 中,给你的 network 过去的游戏画面,然后它的输出是新的游戏画面。这时候,在训练资料里面,同样的输入再面对转角时,有时候小精灵往左转,有时候往右转,这两种可能性同时存在于训练资料里面,Network 要两面讨好,处理这个问题的一种可能性就是让机器的输出是有几率的:
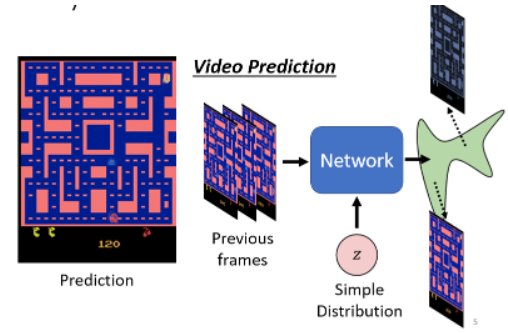
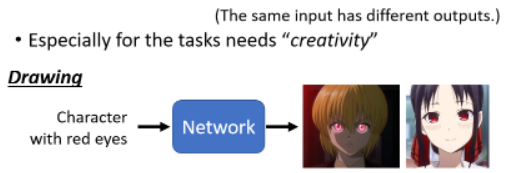
当我们的任务需要一点创造力的时候,更具体说就是我们想要找一个 function,同样的输入有多种输出,而且这些不同的输出都是对的,就需要 generator 的 model。
比如画图这件事就需要一点创造力:
还比如对话这种事:
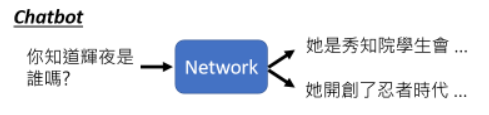
- 我们问机器说辉夜是谁,其实每个人可能都有不同的答案,这时候就需要 generative 的 model。
# 2. GAN
generative 的 model 中,有一个非常知名,它就是 Generative Adversarial Network(GAN),我们主要就是介绍它,发音就是 gàn。
它有很多很多的变形,在 GitHub 上可以找到一个 GAN 的 zoo:
# 2.1 Example:Anime Face Generation
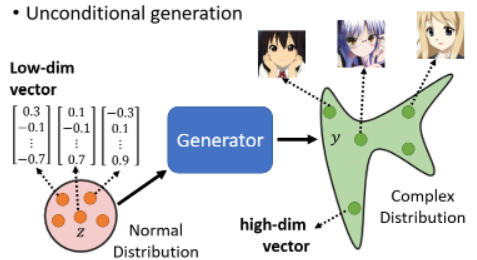
我们举一个让机器生成二次元人物的脸的例子,它是一个 unconditional generation,就是我们这边先把 x 拿掉:
之后讲到 conditional generation 的时候会再把 x 加回来。拿掉 x 后,generator 的输入就是 z 了。之后我们都假设 z 是一个从 normal distribution 中 sample 出来的一个 vector,这个 vector 通常是一个 low-dimensional 的 vector,它的维度是你自己决定的。
一张图片就是一个非常高维的向量,所以 generator 实际上做的事情就是產生一个非常高维的向量,比如 64 × 64 × 3 的 tensor 表示 image。
当从 distribution 中 sample 出不同的 z,输出的 y 都不一样。那我们希望不管这边 sample 到怎样的 z,输出都是动画人物的脸:
为什么是 normal distribution 呢?也可以是别的,但经验是不同的 distribution 之间的差异,可能并没有真的非常大。只要是一个够简单的 distribution 就可以了,network 会对应到一个复杂的 distribution 中。
# 2.2 Discriminator
在 GAN 中,一个特别的地方是,除了 generator 外,我们还要训练另外一个东西,叫做 discriminator。它的作用是,它会拿一张图片作为 input,其 output 是一个数值,这个 discriminator 本身也是一个 neural network,是一个 function:
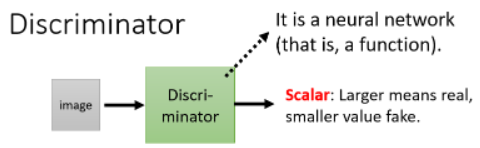
它输出的 scalar 越大,表示输入的 image 越像真的二次元人物的图像。举例来说:
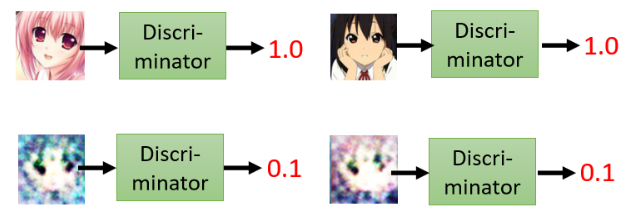
至于 generator 和 discriminator 的架构长什么样子,你完全可以自己设计,只要有你要的输入输出就可以了。
# 2.3 Basic idea of GAN
为什么要多一个 disciminator,这要讲一个故事:
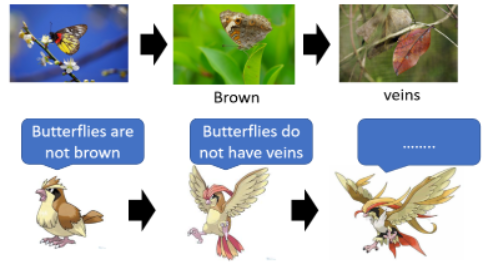
- 物竞天择之下,蝴蝶越来越像树叶,以免别天敌吃掉。而比比鸟为了吃掉蝴蝶,也逐渐进化越来越不容易被骗过。最终完成了从蝴蝶到枯叶蝶的进化。
- 在这个过程中,蝴蝶就是 generator,比比鸟就是 discriminator。
现在回到 generator 要画出二次元的人物,disciriminator 就是要去分辨出 generator 的输出和真正的图片:

- 一开始 generator 会乱画,这时 discriminator 很容易地根据是否有两个黑眼睛就能分别出真假;之后 generator 调整参数进化了,它为了骗过 discriminator 就画出了眼睛,而后 discriminator 也会进化,开始从嘴巴进行分辨 ……
generator 与 discriminator 之间有一个对抗的关系,就用了 adversarial 这个字眼,这只是一个拟人化的说法而已。
# 2.4 Algorithm
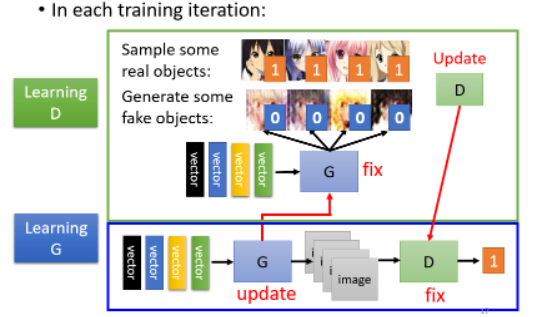
下面正式讲一下这个演算法长什么样子。network 训练之前,要先初始化 generator 和 discriminator 的参数。
# step 1:Fix generator G, and update discriminator D
初始化完参数以后,接下来训练的第一步是定住你的 generator,只 train 你的 discriminator。

- discriminator 训练的目标是要分辨真正的二次元人物和 generator 產生出来的二次元人物
这种分辨可能是把真正的人物标 1,generator 产生的人物标 2,这就成了一个分类或者 regression 的问题了。具体怎么做,看你喽。
# step 2:Fix discriminator D, and update generator G
我们训练完 discriminator 以后,接下来定住 discriminator 改成训练 generator。如何训练呢?拟人化的讲法就是让 generator 想办法去骗过 discriminator。
实际上的操作方法是:从 distribution 中 sample 出一个 vector 输给 generator,产生一个图片,把它丢给 discriminator,discriminator 会给这个图片一个分数,而 generator 的训练目标就是让这个 discriminator 输出高分,这就意味着 generator 骗过了 discriminator。图示如下:
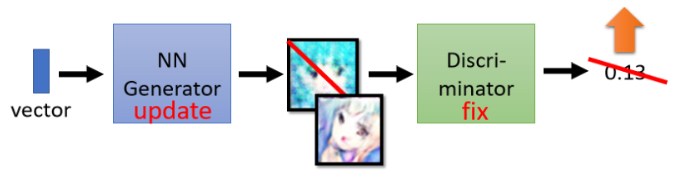
更具体一点,我们可以将 generator 和 discriminator 两个 network 直接接起来当成一个大的 network 来看待,其中某一层的输出代表一张图片:
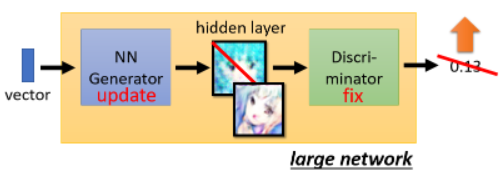
至于怎么调 network 的参数,这根训练一般的 network 没什么不同。所以现在讲了两个步骤:
- step 1:Fix generator G, and update discriminator D
- step 2:Fix discriminator D, and update generator G
接下来就是反复地训练两个 network:
# 2.5 示例 Anime Face Generation 的结果
生成二次元人脸的任务,到底可以做到什么样的程度呢?
2000 次的结果如下:

五万次的结果如下:

使用 StyleGAN 可以做到下面这个样子:
除此之外还有一个 progressive GAN 可以产生真是人脸:

在两个向量之间做内插 interpolation,可以看到这两个向量对应的图片中间的逐渐变化过程:

用 BigGAN 甚至可以做到产生下面的图片:

还产生了奇怪的网球狗:
# 3. Theory behind GAN
接下来我们告诉你,为什么 Generator 和 Discriminator 的互动可以让 Generator 产生像是真正人脸的图片。
# 3.1 Our objective
先搞清楚我们的目标是什么。在训练 network 时,我们先定一个 loss function,然后用 gradient descent 去调参,最终 minimize 那个 loss 就结束了。我们在 Generation 问题中,要 minimize 的东西是这个样子:
- 给它一堆从 distribution 中 sample 出来的 vector
- 丢进 Generator 后,会产生一个比较复杂的 distribution,称之为
- 我们还有另一堆 data,这个真正的 data 也形成了另外一个 distribution,称之为
我们期待的是
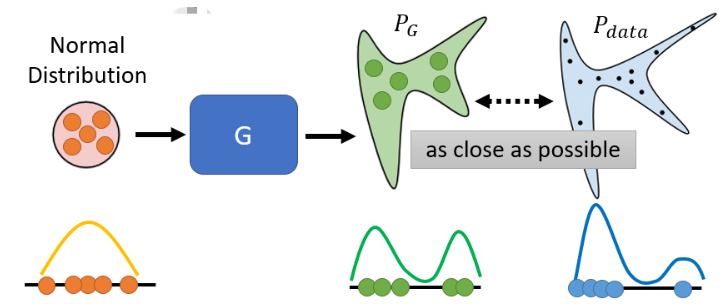
- Generator 的 input、output 和 真正的 data 都是一维 vector
我们期待的是绿色和蓝色的分布越接近越好,写成式子就是:
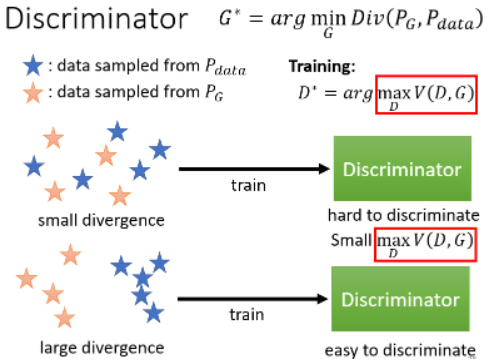
- Div 是 Divergence(散度),可以理解成两个 distribution 之间的某种距离。散度越小,就代表两个 distribution 越像。
这样其实我们就是找一个 Generator 里面的参数,使得这个 Generator 产生出来的
但我们遇到一个问题:用在这种 continues 的 distribution 上面的 Divergence 是很难算的。我们算不出这个 Divergence,那有如何去找
# 3.2 Sampling is good enough …
现在我们的问题是不知道怎样计算 Divergence,而 GAN 告诉我们,你不需要知道

- 从图库中随机 sample 出来一些图片,就得到
- 从 simple distribution 中 sample 出一些 vector,丢进 Generator 中,产生出来的图片就是从
# 3.3 Discriminator
靠 Discriminator 的力量,GAN 可以在只做 sample 的前提下去估测出 Divergence。
现在有了下面两种数据去训练 discriminator:
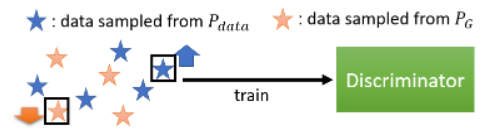
它的训练目标是:看到 real data 就给高分,看到 generative data 就给低分。这个过程可以当成一个 optimazation 的问题,写成如下的式子:
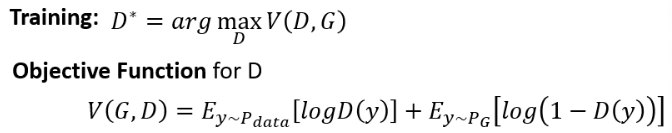
在这里,Discriminator 想要 maximize 的 function 称为 Objective Function。
我们要 maximize 的 function 叫 Objective Function,要 minimize 的 function 叫 Loss Function。
我们希望这个 objective func
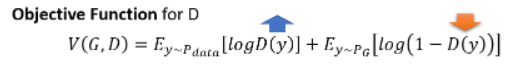
这个 objective func 不一定非要写成这样,当初写成这个样子是为了与 binary classification 扯上关系,因为这个 func 就是 Cross Entropy 乘以一个负号,所以这相当于我们想 minimize Cross Entropy,也就等于在训练一个 classifier:
最神奇的是: ,也就是这个 objective func 的最大值是跟 Divergence 有关的,因此我们不知道怎么算 Divergence 没关係,train 我们的 Discriminator,train 完之后,看看它的 Objective Function 可以到多大,那个值就跟 Divergence 有关。
,也就是这个 objective func 的最大值是跟 Divergence 有关的,因此我们不知道怎么算 Divergence 没关係,train 我们的 Discriminator,train 完之后,看看它的 Objective Function 可以到多大,那个值就跟 Divergence 有关。
我们不再证明 objective func 为什么跟 Divergence 有关,但直观上看一下:
- 假设
- 如果两者很不像,那很轻易将其分开,这个 Objective Function 就可以冲得很大。
所以既然这个 objective func 的最大值跟 Divergence 有关,即:
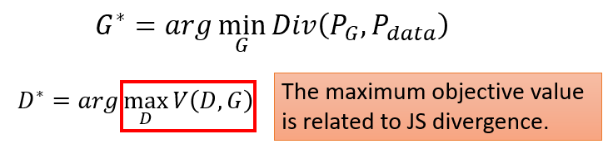
那我们可以直接把我们不会算的 Div 换成红框框的部分,于是就有了
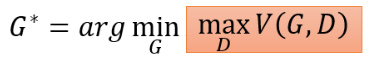
- 我们要找一个 Generator
- 而红色框框中的这件事,又是另外一个 Optimization Problem,它是在给定 Generator 的情况下,去找一个 Discriminator,这个 Discriminator 可以让
之前我们讲的 Generator 跟 Discriminator 互动、互相欺骗的过程,其实就是想解这个问题:

那你可能问,为什么用 JS Divergence 而不是别的 Divergence 呢?完全可以,只要改了 objective func 就可以量各式各样的 Divergence:

但实际上,GAN 还是很不好 train 的,所以俗话说,No Pain, No Gan。
# 4. Tips for GAN
接下来我们就要讲一些 GAN 训练的小技巧。我们只挑最知名的来讲,即 WGAN。
# 4.1 JS divergence is not suitable
我们讲讲 JS Divergence 有什么问题。
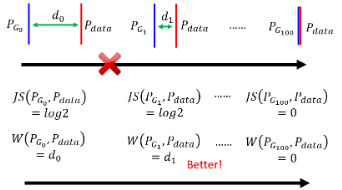
- 第一个理由是来自于 data 本身的特性:

- 其实我们从来不知道
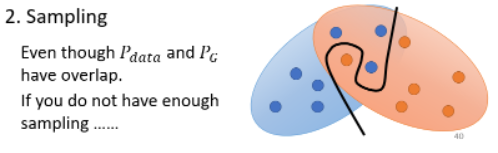
而两个没有重叠的分布,JS Divergence 算出来永远都是

- 左边两个 equally bad
而且在实际中用 JS Divergence 时,会发现 train 完后 classifier 的正确率几乎都是 100%,因为 sample 的图片根本就没几张。这样训练完的 loss 根本就没有什么意义。
所以 WGAN 出现之前,train GAN 就像巫术。既然是 JS Divergence 的问题,那我们换一个衡量两个 Distribution 的相似程度的方式,即换一个 Divergence 就可以了,于是出现了使用 Wasserstein Distance 的想法。
# 4.2 Wasserstein Distance
Wasserstein Distance 的想法是这样:假设有两个 distribution,一个叫 P,另一个叫 Q:
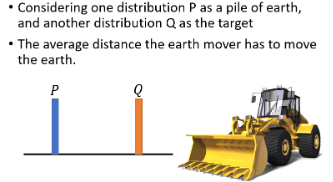
- 推土机把 P 这边的土,挪到 Q 所移动的平均距离就是 Wasserstein Distance。
比如下面例子里:
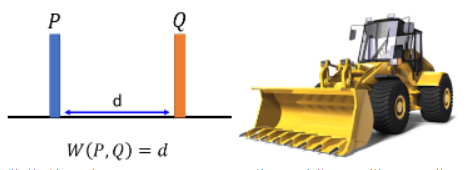
因为这里用到推土机(Earth Mover),所以也称 Wasserstein Distance 为 Earth Mover Distance。
但是如果是更复杂的 Distribution,那算 Wasserstein Distance 就困难了:

计算这个 distance 居然也要解一个 optimization 的问题。先假设我们能够计算 Wasserstein Distance,那会给我们带来怎样的好处呢?:
- 由左向右的时候,Wasserstein Distance 是越来越小的。
所以我们换一种计算 Divergence 的方式,所以我们就可以解决 JS Divergence 带来的问题。就像人类的进化,是一步一步慢慢进化出来的,JS Divergence 相当于从这一步直接跳到另一步,而 W Distance 相当于每次稍微把
当你用 Wasserstein Distance 来取代 JS Divergence 的时候,这个 GAN 就叫做 WGAN。那 Wasserstein Distance 怎么算呢?直接上结果,解下面这个 optimization problem 得到的值就是 Wasserstein Distance:
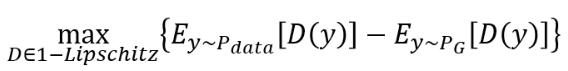
- y 如果 from
为什么要足够平滑?
如果没有这个限制,在 real data 和 generated data 没有重叠时,Discriminator 会尝试给 real data 无限大的正值,给 generated data 一个无限大的负值:
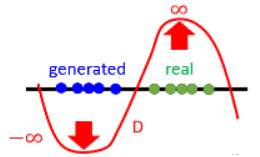
如何做到这个限制呢?最早使用 WGAN 的 paper 使用了一个比较粗糙的方法:train network 时要求训练的参数必须在 C 和 -C 之间,gradient descent update 后超过 C 就设为 C,小于 -C 就直接设为 -C。
但这个方法还不够好,有另一个想法叫 Gradient Penalty,在 Improved WGAN (opens new window) 中提出。
现在有一种方法叫 Spectral Normalization,使得真的让 D 符合 1-Lipschitz Function 的限制,在 Spectral Normalization for Generative Adversarial Networks 中提出。如果你要 train 真的非常好的 GAN,可能就会需要 Spectral Normalizaion,这就是 SNGAN。
# 4.3 GAN is still challenging ...
虽然说已经有 WGAN,GAN 仍然是很难 train 的。它有一个本质上困难的地方,Generator 跟 Discriminator 是互相砥砺才能互相成长,只要其中一者发生什么问题而停止训练,那另一者也会跟着停下训练。如果 Generator 一下子没有 train 好而失去了进步的目标,那 Generator 就没有办法再进步了,那么接着 Discriminator 就没有办法再跟着进步了。
大家都知道我们没有办法保证在 train network 时 loss 就一定会下降,你往往需要调一下 hyperparameter 才有可能把它 train 起来。但今天这个 Generator 和 Discriminator 的互动的过程是自动的,因为我们不会在中间每一次 train discriminator 的时候都换一下 hyperparameter,所以只能祈祷每次 train discriminator 的时候,它的 loss 都是有下降的,那如果有一次 loss 没有下降,那整个 training 就很有可能就会惨掉,整个 discriminator 和 generator 彼此砥砺的过程就可能会停下来。所以今天 generator 和 discriminator 在 train 的时候必须要棋逢对手,任何一个人放弃了这一场比赛,另外一个人也就玩不下去了。
所以 GAN 本质上它的 training 仍然不是一件容易的事情,当然它是一个非常重要的技术。跟 Train GAN 的诀窍有关的文献列在这里供参考:
- Tips from Soumith (opens new window)
- Tips in DCGAN: Guideline for network architecture design for image generation (opens new window)
- Improved techniques for training GANs (opens new window)
- Tips from BigGAN (opens new window)
# 4.4 GAN for Sequence Generation
Train GAN 最难的其实是要拿 GAN 来生成文字。如果你要用 GAN 来生成一段文字,那你可能会有一个 seq2seq 的 model,你有一个可以产生文字的 Decoder,现在在 GAN 里面,它就扮演了 generator 的角色,负责产生我们要它产生的东西,比如说一段文字。