 Life Long Learning
Life Long Learning
Life Long Learning(LLL)比较符合人们对 AI 的幻想:
- 人们教他一个 task,他就学会一个 task,最终他就变成了“天网”从而统治人类。
Life Long Learning 有很多很潮的名字:Continual Learning、Never Ending Learning、Incremental Learning。
在 real-world application 中,LLL 也是有用处的:
# 1. Catastrophic Forgetting
# 1.1 Catastrophic Forgetting 是什么
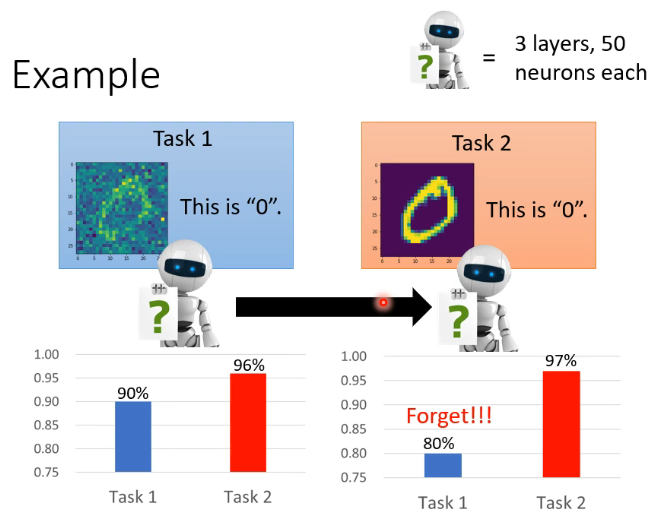
下面通过一些 example 来说明 Life Long Learning 的一个难点:Catastrophic Forgetting。如下图所示,假设我们有如下两个 task(这看起来像是同一 task 的两个不同 domain,但目前文献上说的就是这样,还做不到真的两个完全不同的任务),我们现在 task 1 上训练一个 model,可以看到其结果在 task 2 也已经达到了 96% 的正确率了,效果非常好,然后我们继续把这个学好的 model 放到 task 2 上去继续学,学完后分析结果发现,这个 model 预期般地在 task 2 上 performance 更好了,但 task 1 上的 performance 却变得很差了,它发生了遗忘:
也许你会认为可能是因为 model 大小有限,导致其能力有限,从而导致其学完 task 2 后就忘了 task 1。那接下来看另外一个实验:如下图,我们把 task 1 和 task 2 的训练资料倒在一起同时去训练这个 model,可以发现这个 model 是可以同时学好两个 task 的:
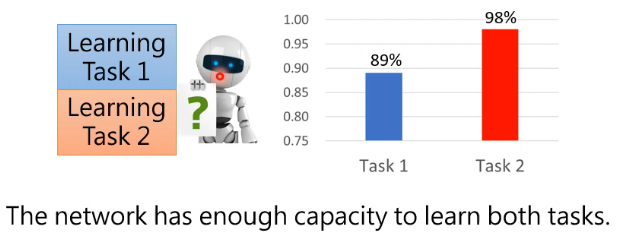
这说明这个 model 有能力同时学好两个 task,但如果依次去学习这两个 task,它会遗忘旧的 task。
这种现象是很普遍的,在一个 QA 的任务上,这个任务是 Given a document, answer the question based on the document. 这个任务使用的是 bAbi corpus,它是一个很小的数据集,包含了 20 个 QA task,如下图:

用该数据集训练 model,结果如下:
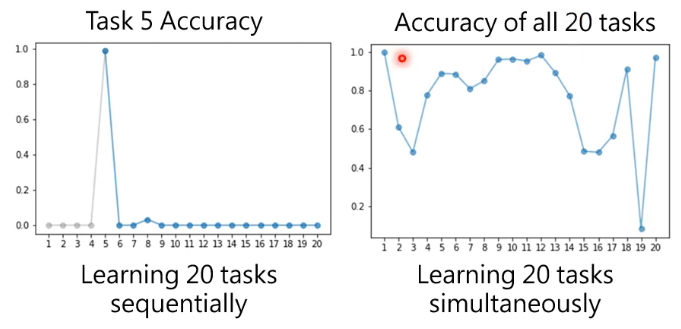
- 左图表示一次用 20 个 task 来训练 model,纵轴表示它在 task 5 上的 accuracy,可以看到当训练完 task 5 后 performance 很好,但一旦用 task 6 训完,它在 task 5 上的 accuracy 就直接掉到 0 了
- 右图表示同时训练这 20 个 task,每个点表示在某个 task 上的 accuracy,可以看到这个 model 是可以在多个 task 上都表现很好的。
所以我们说 machine “是不为也,非不能也”。这种遗忘很厉害的现象称为 Catastrophic Forgetting(灾难性遗忘):

# 1.2 为什么不用 multi-task training 来解决
根据刚刚说的,那你可能觉得将多个 task 的资料一块训练就可以了,这种方式叫做 Multi-task training,但这会导致 Computation issue 和 Storage issue:
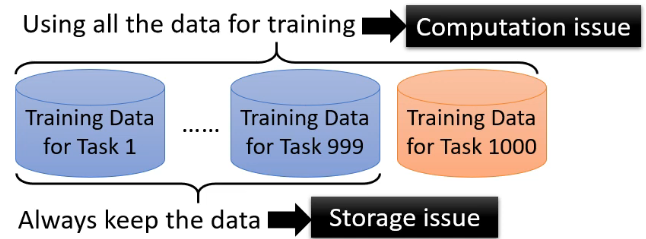
这就好比说,你要让一个人学一门新的课,他学的时候还得把以前学过的也再看一遍才不至于遗忘。
Multi-task training can be considered as the upper bound of LLL. 因此在做 LLL 研究时,往往先跑个 multi-task training 的结果,知道它的 upper bound 在哪里,然后再比较新的技术和这个 upper bound。
# 1.3 为什么不 train a model for each task
- Eventually we cannot store all the models …
- Knowledge cannot transfer across different tasks.
# 1.4 Life-Long learning v.s. Transfer learning
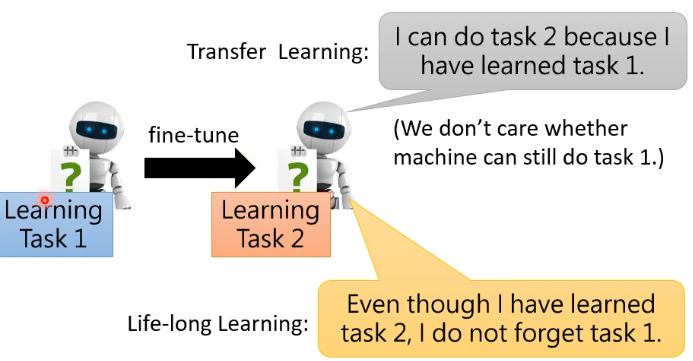
- transfer learning 只关注在 task 2 上的 performance
- life-long learning 同时关注在 task 1 上的 performance
# 2. Evaluation
在讲 life-long learning 之前,我们先讲一下对 LLL performance 的评估方法。
首先我们需要一系列的 task:
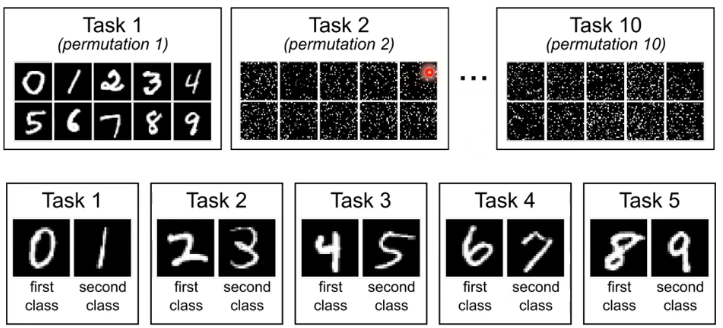
- 在图片的上面部分中,task 1 是正常的手写数字辨识,task 2 其实也是,只不过这里面的图片是 task 1 中的图片经过某种固定规律转换过来的。甚至有的直接将图片旋转个 15 度来作为新的 task。
- 图片的下面部分中,task 1 是分类 0 和 1,task 2 是分类 2 和 3 …
然后我们就可以进行 life-long learning,并对 model 建立如下 evaluation:
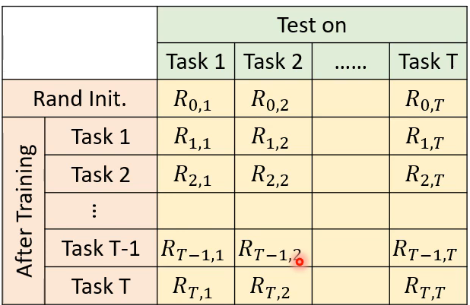
其中
- If
- If
最常见的评价方法是 Accuracy:
- 也就是将上表中最后一行的 R 全部累加起来求平均,用这个值来代表 life long learning 的方法的好坏。
- 其中,
还有一种评估方法是 Backward Transfer:
- 它表示一系列值的平均,上表中的每一列产生一个差值,是用最下面一行的 R 减去这一列上对角线上的 R 得到的,这个过程如下图所示:
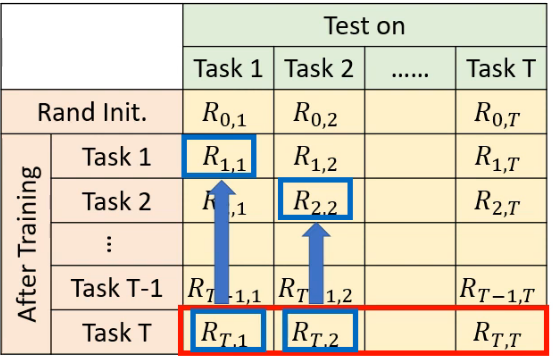
因此每一个差值也就代表着,对 task i 来说,在刚学完 task i 上的正确率,和学完 T 个 task 后在 task i 上的正确率差多少。
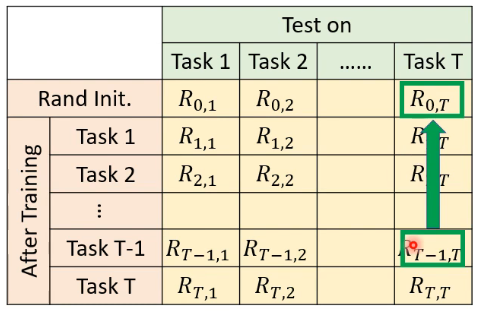
还有一种评估方式是 Forward Transfer:
这个指标想要问的问题是说,在看过一系列的任务后,在还没有看过 task i 而学完 task 1 ~ task i-1 后,你的模型到底可以学出什么样的成果:
下面,我们就要讲 life long learning 的解法了,这里讲三种解法:
- Selective Synaptic Plasticity
- Additional Neural Resource Allocation
- Memory Reply
# 3. Selective Synaptic Plasticity
# 3.1 Why Catastrophic Forgetting?
我们先来想一下为什么 Catastrophic Forgetting 这件事情会发生呢?如下图所示,我们有两个 task,model 有两个参数
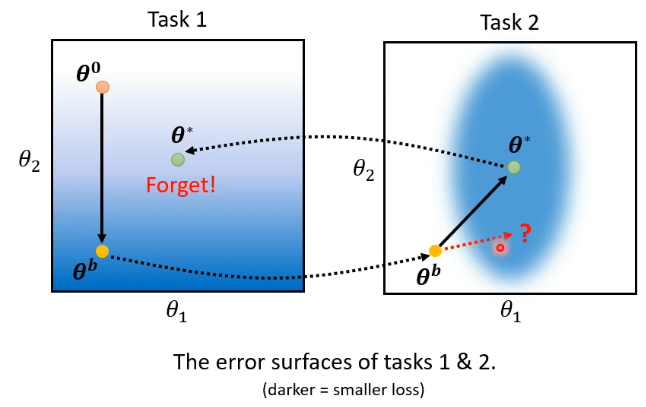
- 在 task 1 上学习时,参数变化
- 那我们在 task 2 上学习时,可不可以是让
# 3.2 regularization-based 的基本想法
Basic Idea: Some parameters in the model are important to the previous tasks. Only change the unimportant parameters.
那我们假设
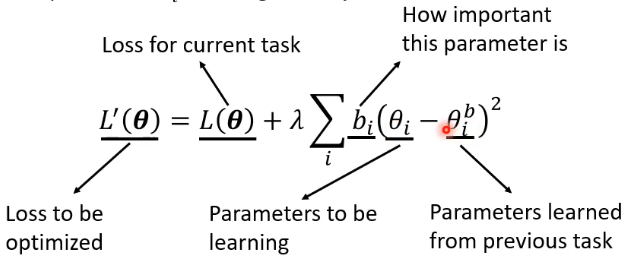
注意,我们并不要求所有参数都与原来很接近,而只是要求部分参数与原来的很接近,具体要求哪些是由
- If
- If
# 3.3
对
以下图为例,我们可以让
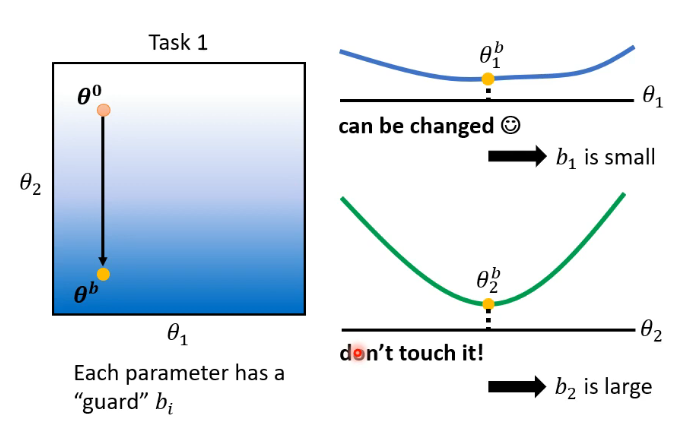
如果按照上面分析,我们将

可以看到在 task 2 上
接下来的图片就是 paper 中一个真实的实验结果,这种图在 life-long learning 中是非常常见的:
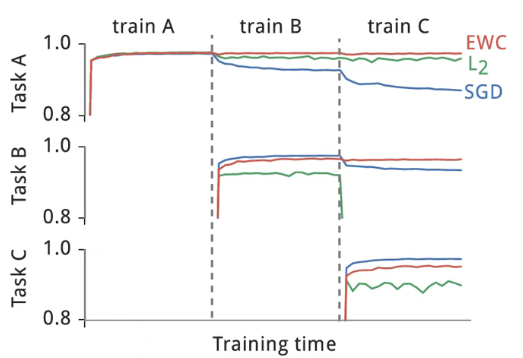
- 横轴代表依序训练的过程,纵轴代表在不同 task 上的正确率
- 来看不同颜色的线,SGD 的蓝线代表
- 再来看红色这条线,如果我们给不同的参数不用的
其实我们没有真的告诉你
- Elastic Weight Consolidation(EWC) (opens new window)
- Synaptic Intelligence(SI) (opens new window)
- Memory Aware Synapses(MAS) (opens new window)
- RWalk (opens new window)
- Sliced Cramer Preservation(SCP) (opens new window)
# 3.4 Gradient Episodic Memory(GEM)
除了以上讲的 regularization-based 的方法以外,更早期的一个做法叫做 Gradient Episodic Memory(GEM),它也是一个很有效的方法,但它不是在参数上做限制,而是在 gradient update 的方向上做限制。如下图所示:
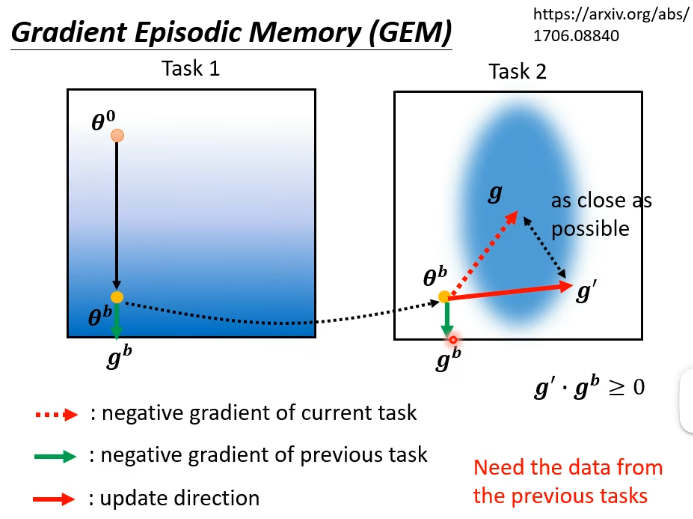
绿色箭头
讲到这边,有没有感觉这个方法有点有猫腻的地方呢?我们要算
# 4. Additional Neural Resource Allocation
# 4.1 Progressive Neural Networks
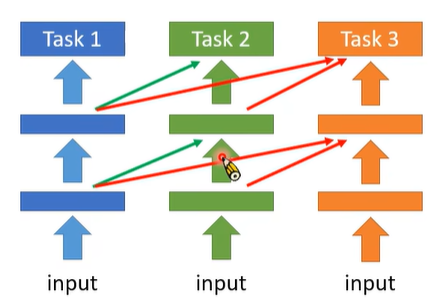
它的想法是,训练 task 1 时有一个蓝色的 network,然后训练 task 2 时就不要再动 task 1 学到的那个模型,而是另外再多开一个绿色的 network,这个新开的 network 也会吃之前的 network 的 hidden layer 的 output 作为输入,这样 task 1 有学到什么有用的资讯的话,也是可以被 task 2 的 network 所利用,但是就是不要再变动 task 1 学出来的模型的参数了。task 3 也是如此,需要再开一个 network。
这样的做法就不会再产生 catastrophic forgetting 的问题,因为旧的 network 就完全没有再动它了。但这产生的新的问题是,每一次训练一个新的 task 时,就需要额外的一块空间来产生一个新的 network,这样整个模型会随着学习的 task 的增多而长大,这样模型会最终过大而使得 memory 无法存下它了。
# 4.2 PackNet
PackNet 的思想就与 Progressive Neural Networks 相反了,它是先有一个很大的 network,然后每次 pruning 掉一部分,并只准用所允许的其中一部分参数来训练。如下图所示:

我们把圈圈想象成参数,当有 task 1 的资料进来时,就只准用有黑色框的圈圈的参数;然后 task 2 再进来,就只准用这个橙色的参数 ......
这个方法的好处是,你的参数量不会随着 task 的增多而不断增加。但其实相较于 Progressive Neural Networks 的方法来说,这个方法也只是朝三暮四而已,因为它只不过是一开始就开了一个很大的 network。
# 4.3 Compacting, Picking, and Growing(CPG)
刚刚讲的 PackNet 与 Progressive Neural Networks 其实是可以结合在一起的,这就是很出名的 CPG。这个 model 是既可以增加新的参数,每一次又都只保留部分的参数用来拿来做训练。至于方法的细节可以参考论文 (opens new window)。
# 5. Memory Reply
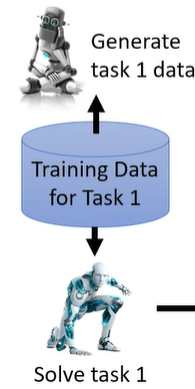
这个方法非常直觉,我们之前讲过说只要把所有的资料统统倒在一起,就不会有 catastrophic forgetting 的问题,但我们又说,不能够去存储过去的资料,那我们就干脆直接训练一个 generative model,它可以产生 previous task 的 pseudo-data。
这就是说,我们在 solve task 1 时,不仅训练一个 classifier 来解 task 1,同时还训练了一个 generator,它可以产生 task 1 的资料:
接下来再训练 task 2 的时候,如果只把 task 2 的资料给 model 看,那么可能会产生 catastrophic forgetting 的问题,这个时候就可以让 task 1 训练的 generator 产生 task 1 的 pseudo-data 混合着给 task 2 的 classifier 来训练:
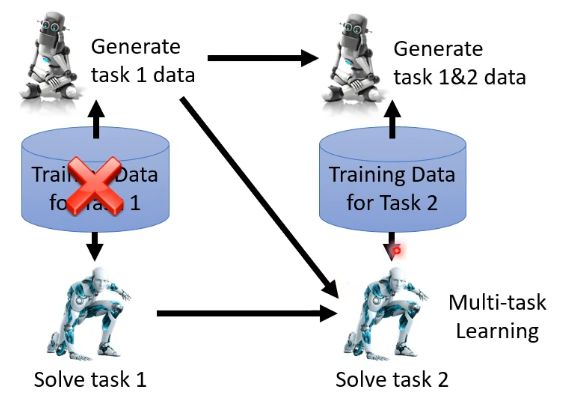
那这个方法合不合理呢?这个其实见仁见智了,因为额外训练的 generator 也会占用额外的空间。但如果这些 generator 所占用的空间比你储存 previous task 的 training data 所需要的空间更小的话,那也许这也是一个有效的方法。事实上,从经验上来看,这种方法其实是非常有效的,这种方法的实验结果往往都可以逼近 life long learning 的 upper bound 了。
可以参考一下文献详细了解:
- https://arxiv.org/abs/1705.08690
- https://arxiv.org/abs/1711.10563
- https://arxiv.org/abs/1909.03329
# 6. 其他 continual learning 的 scenarios
其实回看我们刚刚讲的 life long learning 的 scenario,我们都是假设说每个任务需要的模型都是一样的,甚至我们强迫说每一个任务所要训练的 classifier 所需要的 class 的量都是一样的。那假设不同的任务中 class 的数目不一样,也就是说新的任务需要“adding new classes”,那有没有办法解呢?也是有的,下面列着一些参考文献:
- Learning without forgetting(LwF) (opens new window)
- iCaRL: Incremental Classifier and Representation Learning (opens new window)
其实我们今天讲的 life long learning,也就是 continual learning,其实只是整个该领域研究里面的其中一个 scenario,其实 continual learning 还有很多不同的 scenario,可以阅读文献 Three scenarios for continual learning (opens new window),它将 continual learning 分成了三种 scenario,而今天讲的只是其中最简单的一种。
# 7. Curriculum Learning
之前遗留着一个问题,交换 task 的训练顺序,会不会有非常不一样的结果呢?确实是会有的,来看下面这个例子。
我们之前是让机器先学有杂讯的图片 task 1,再学没有杂讯的图片 task 2;现在反过来,先学没有杂讯的图片 task 2,再学有杂讯的图片 task 1,结果如下:
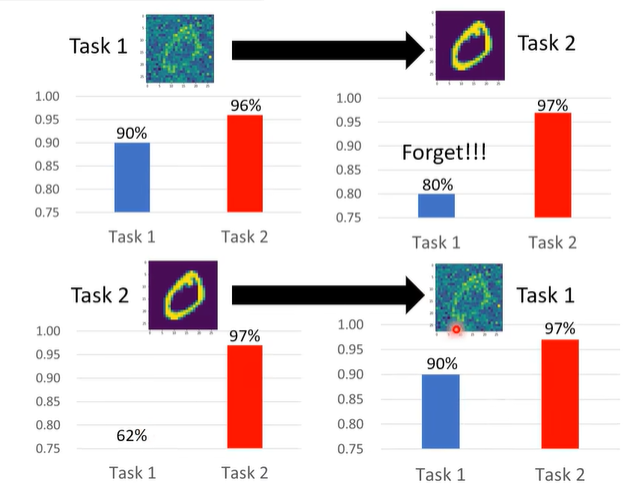
会发现下面这种训练顺序没有产生 catastrophic forgetting 的问题。
所以看起来,task 的顺序是重要的。这种研究 what is the proper learning order 的方向叫做 Curriculum Learning。