 Meta Learning
Meta Learning
Meta Learning: Learn to learn(学习如何学习)
What does “meta” mean? meta-X = X about X
Can machine automatically determine the hyper-parameters?
# 1. 回顾 Machine Learning
Machine Learning = Looking for a function
step 1: Function with unknown
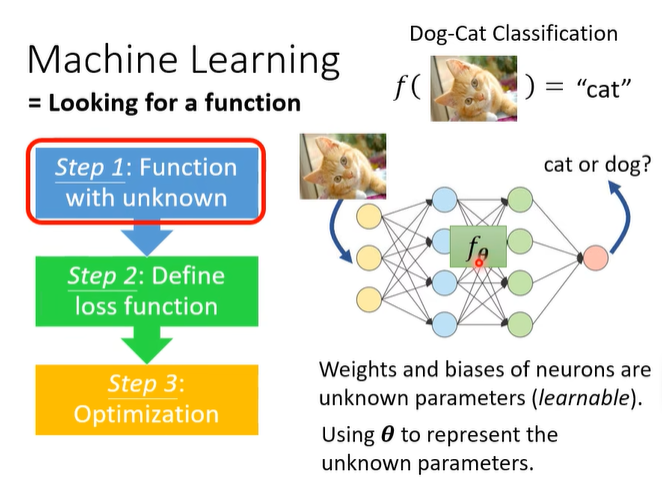
step 2: Define loss function
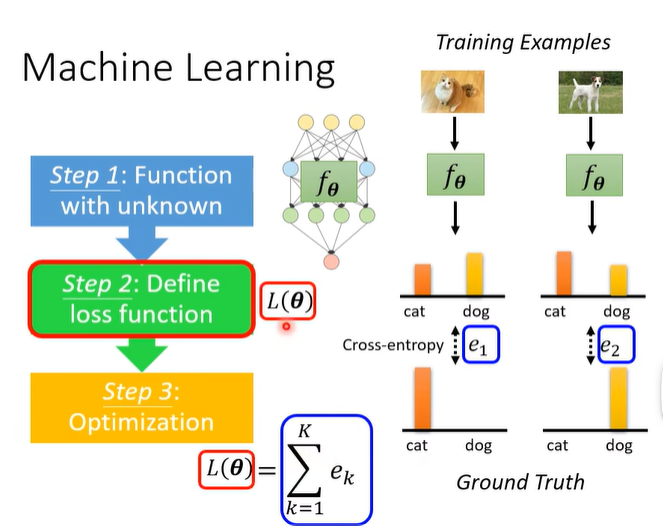
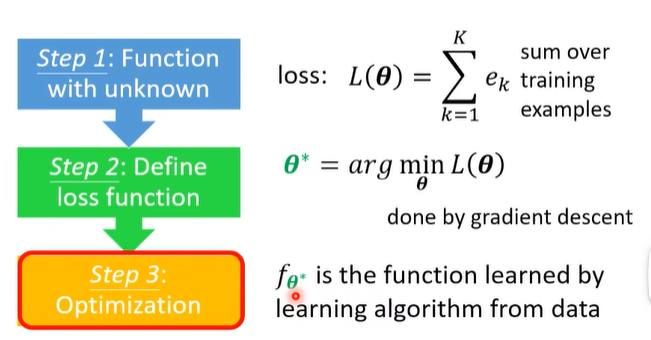
step 3: Optimization
# 2. Introduction of Meta Learning
# 2.1 What is Meta Learning?
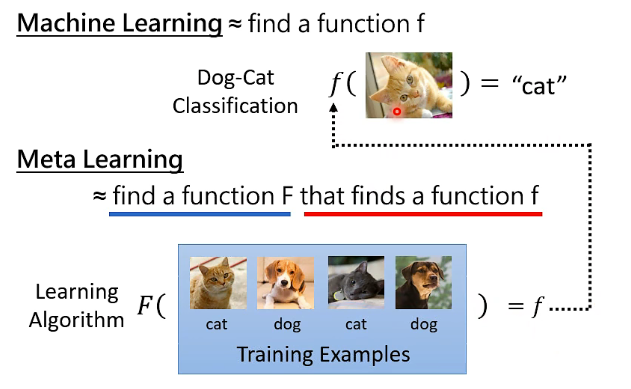
其实“学习”这件事,它本身也是一个 function F:
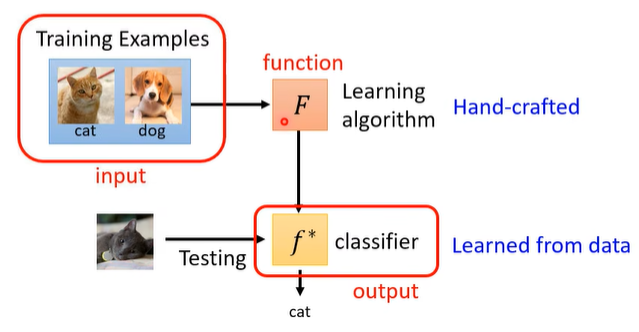
怎么找这个 F 呢?Following the same three steps in ML!
# 2.2 Meta Learning - Step 1
What is learnable in a learning algorithm?
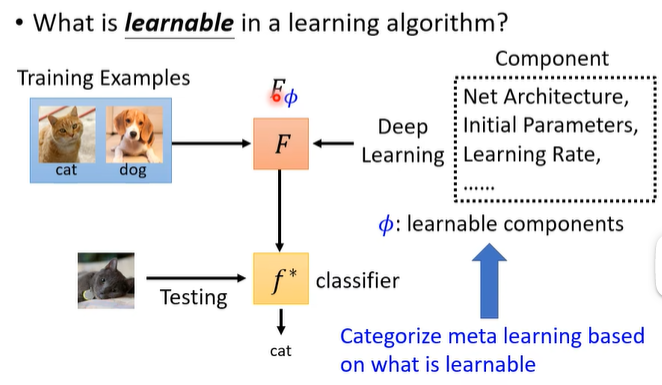
之前我们将 model 中 learnable parameters 记作
根据什么是 learnable components
# 2.3 Meta Learning - Step 2
这一步我们需要 Define loss function
How to define
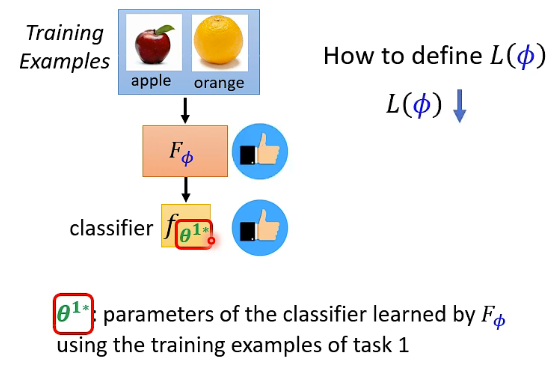
那我们怎样知道一个 classifier 是好还是坏呢?我们可以 Evaluate the classifier on testing set。图示如下:
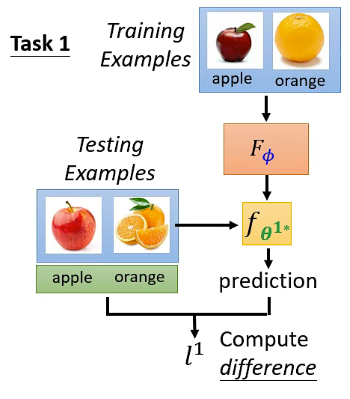
这里怎样计算 loss
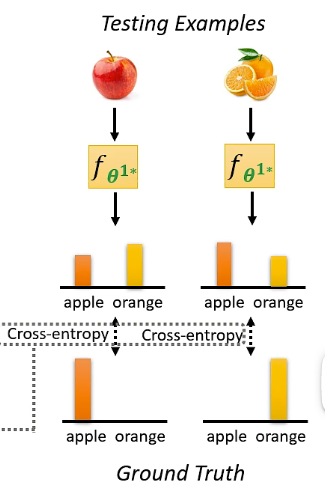
这里在测试资料上计算出来的 loss
注意这里的
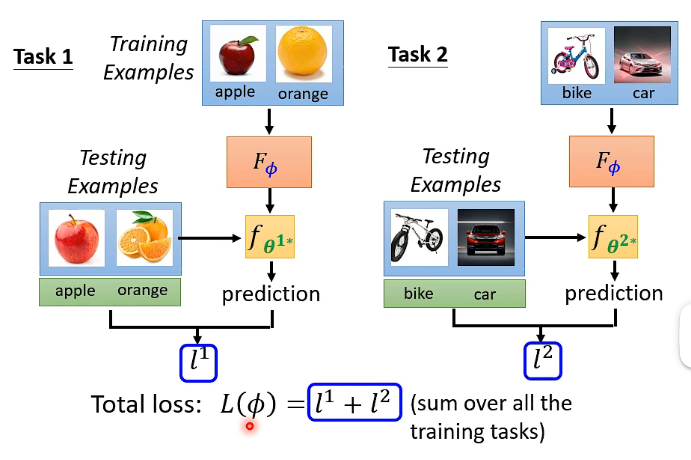
在这里,左右两个 learning algorithm
这里的举例只讲了两个 task,但实际上你会有非常多的 task,那么
到了这里,有一点你可能觉得怪怪的。在 typical ML 中,你是用 training examples 去计算 loss,但在 meta learning 中,你却是用 training tasks 的 testing example 来计算的 loss。这一点 meta learning 与 typical ML 是不同的,在做 meta learning 时,我们是拿 task 作为的训练单位,所以你是可以将 training tasks 的 testing example 用于训练过程中。在之后讲完 meta learning 的整个流程,你会更加清晰。
# 2.4 Meta Learning - Step 3
我们已经有了 learning algorithm 的 loss function
怎么做呢?Using the optimization approach you know:
- If you know how to compute
- What if
反正不管你用什么方法,你最终可以学习出一个 “learning algorithm”
整个 meta learning 的 framework 如下图所示:
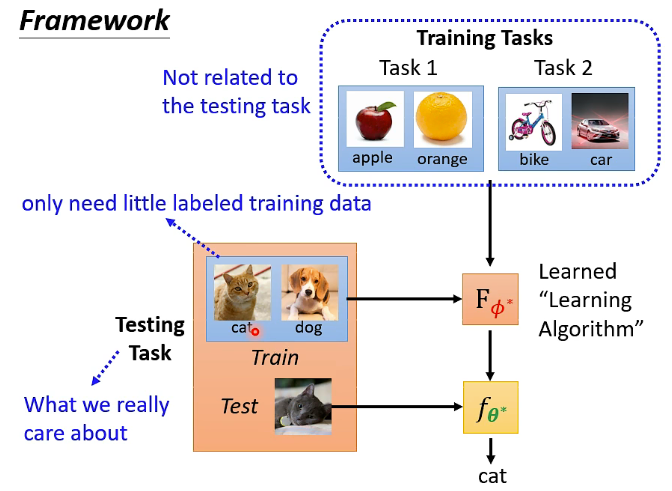
- 我们先从 training task 中学习出一个 learned “learning algorithm”
- 在这个过程中,testing task 是我们真正关心的 task,而 training tasks 是与 testing task 无关的 tasks,这些 training tasks 就是用来寻找出 learned 的演算法
像这种学习的演算法厉害在哪里呢?一种东西叫做”few-shot learning“,即”小样本学习“,它期待机器只看几个 training example 就可以让 model 学会做 classification。而在这里 meta learning 中,testing task 就只需要 little labeled training data 就可以。
通常想要实现 few-shot learning,这种演算法是人类难以想象出来的,往往需要 meta learning 来把这个演算法给找出来。所以注意区分好 few-shot learning 与 meta learning 的微妙区别。
在 meta learning 中,单说”training data“是很容易造成误解的,所以使用时要小心。在很多 paper 中就很不讲究,很多说的 training data 很容易导致误解。
# 2.5 ML v.s. Meta
# 2.5.1 Goal
# 2.5.2 Training Data
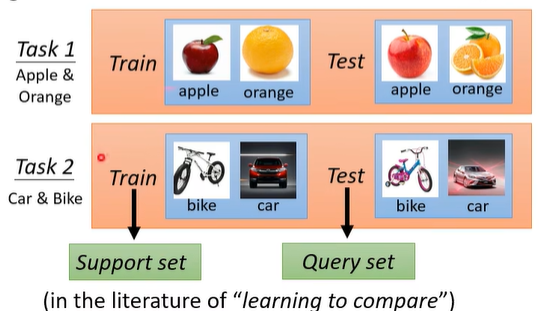
- 在 machine learning 里面,我们是拿一个 task 的 training set 来进行训练;
- 在 meta learning 里面,我们是拿“task”来进行训练,也就是用 training tasks 来进行训练,在每一个 training task 里面,都有 training data 和 testing data。
为了避免对“训练资料”这个说法产生歧义,在 meta learning 中,一个 training task 里面的 training examples 称为 Support set,testing examples 称为 Query set。在一些文献中就是这么叫的。
# 2.5.3 Training
- 在 machine learning 中,我们是有一个 hand-crafted 的 learning algorithm,然后把训练资料丢进去,得到一个训练的 classifier
- 在 meta learning 中,我们是有一堆 training tasks,然后我们是要用这一堆 training tasks 去得到一个 learned “learning algorithm”
这里,把 meta learning 的这种 involve 一大堆 tasks 的训练叫做 Across-task Training
;而把一般 ML 的训练叫做 Within-task Training。这样就可以区别两种 training 的过程了:

# 2.5.4 Testing
我们把 meta learning 中这个 testing 过程叫做 Across-task Testing,而一般 ML 的 testing 过程叫做 Within-task Testing,图示如下:
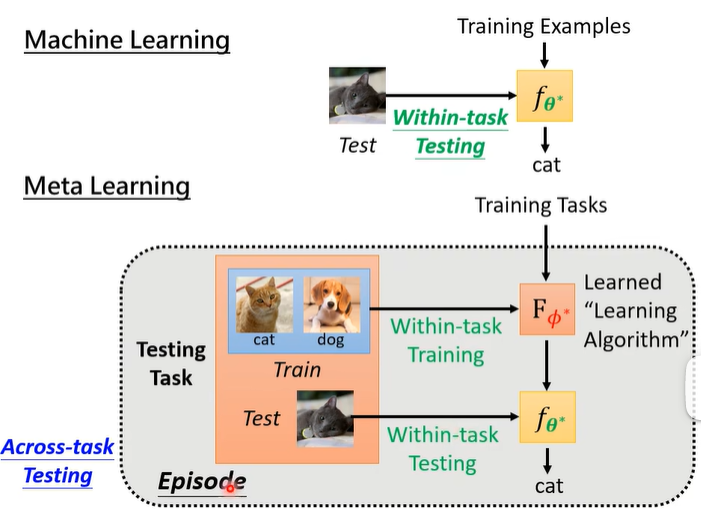
在 meta learning 中,我们要测试的不是一个 classifier 的好坏,而是一个 learning algorithm 的好坏,因此在一个 Across-task Testing 中,还包含了 Within-task Training 和 Within-task Testing 过程。在有些文献中,一次 Within-task Training 加一次 Within-task Testing 的流程叫做一个 Episode。
# 2.5.5 Loss
typical ML 与 meta learning 的 loss 计算方式也不一样:
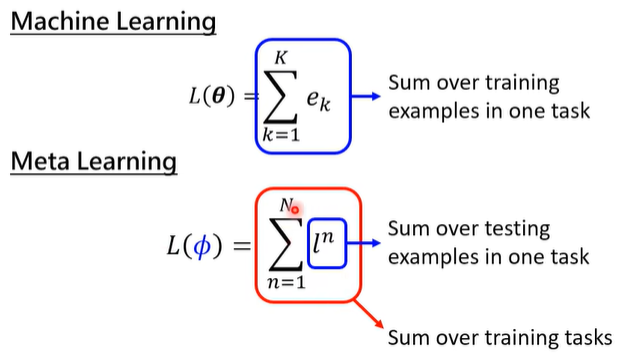
- ML 的 L 是从一个 task 中算出来的;
- Meta learning 的 L 是从一把 tasks 中算出来的。
我们单独看一下 meta learning 中
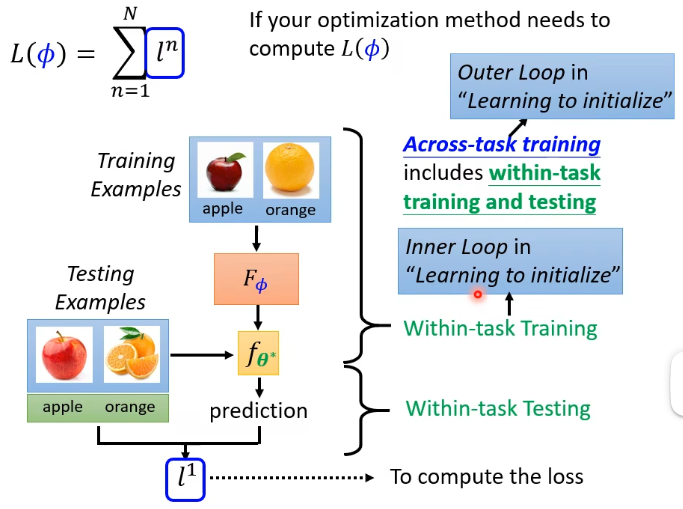
- 在进行一次 Across-task training 计算
- 在“Learning to initialize”系列的 paper 中,也称 Across-task training 叫做 Outer Loop,称 Within-task training 叫做 Inner Loop。
# 2.5.6 两者的相似点
What you know about ML can usually apply to meta learning:
- Overfitting on training tasks
- Get more training tasks to improve performance
- Task augmentation
- There are also hyperparameters when learning a learning algorithm ...... (所以做 meta learning 也是需要暴调一波参数的)
- Development task(这类似于 ML 的 validation set 用来调 hyper-parameters,在很多文献里并没有这种 task 而是只有 training tasks 和 testing task,但李老师认为应该有)
有没有可能套娃?这是个梗啦,以后可能有人会提出 meta meta learning ......
# 3. What is learnable in a learning algorithm?
# 3.1 Review: Gradient Descent
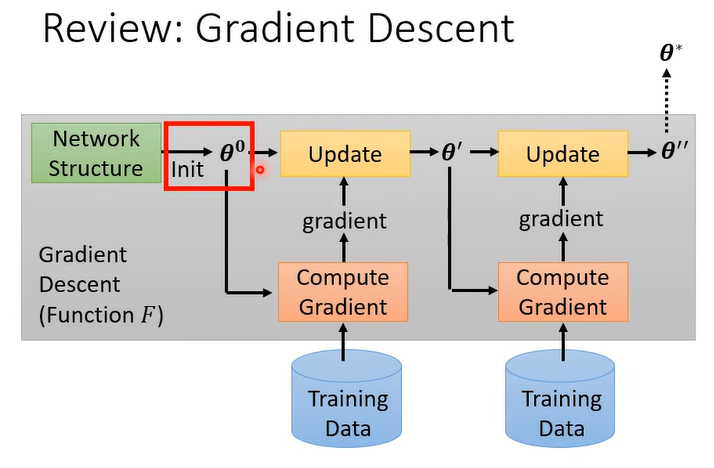
首先这里的 initial parameters
# 3.2 Learning to initialize
回答上面问题的最著名的方法就是 MAML:

- 这里不再细讲这些模型的细节,可以参考原论文,作业题会问。
# 3.3 How to train your MAML?
正如之前讲的,我们做 meta learning 时也有很多需要调的 hyper-parameters,所以在用 MAML 时,虽然你是去 learn 一个 initialize 的 parameters,但这个 learn 的过程也有很多 hyper-parameters 需要你去决定。其实最开始的 MAML 不是那么好 train 的,于是就有人发了 paper 叫 “How to train your MAML”,他用了三种 MAML random seed 来 train,发现有两次是 train 不起来的,于是这篇 peper 就新提出了一种方法叫做 MAML++:
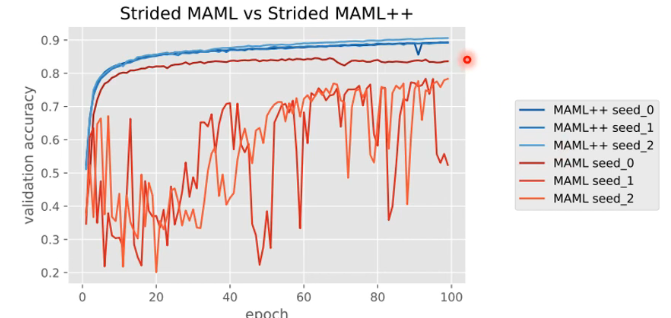
具体的细节需要再去读原文章。
# 3.4 MAML v.s. Pre-training
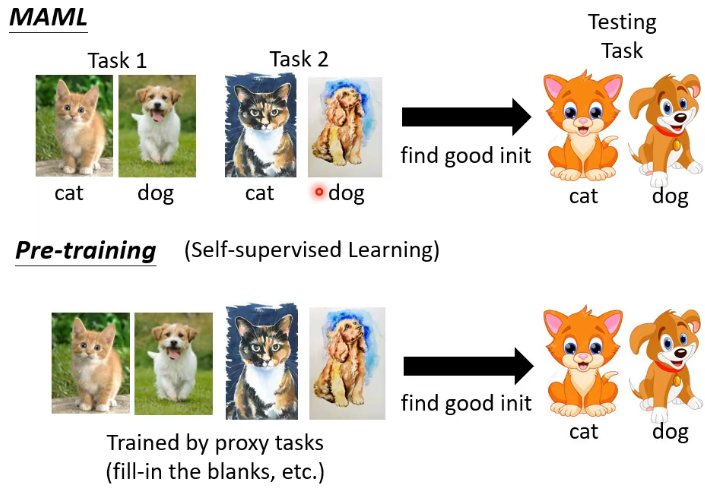
最直观的区别可能就是,MAML 中训练所用的数据是 labeled 的,而 Pre-training 中则是没有 label 的。
其实这里说的 Pre-training 是近期的做法,在更早之前,人们是把来自不同 tasks 的 data 统统放在一起里面训练一个 model,来得到一个好的初始化参数,这现在也被叫做 multi-task learning,这种 multi-task learning 往往被用作 meta learning 的 baseline。具体了解它与 MAML 的差别可以参考李老师的相关视频(链接就不放在这里了)。
在 machine learning 中,对 domain 和 task 的界限并没有那么清晰,你也可以说不同的 task 就是不同的 domain,那这 meta learning 其实也很像 domain adaptation 了。
我们读文献时不要太拘泥于这些,关键的是这个词汇背后所代表的含义。
# 3.5 MAML is good because …
MAML 为什么好呢?这里有两个假设:
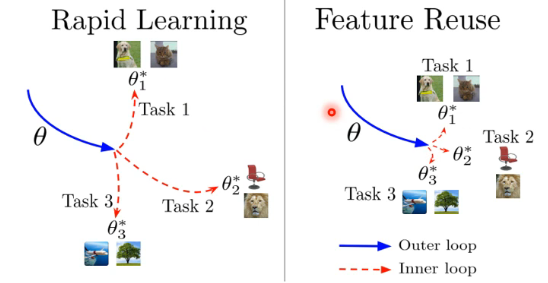
- Rapid Learning 的假设是说,MAML 找到的 initial parameter 很厉害,它可以让我们 gradient descent 这种 learning algorithm 快速地找到每一个 task 上好的参数
- Feature Reuse 的假设是说,这个 initial parameter 本来就跟每一个 task 上最终好的结果已经非常接近了
有一篇 paper 是 Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML (opens new window),它告诉我们 feature reuse 来是 MAML 好的关键,同时提出了另外一种 MAML 的变形 ANIL(Almost No Inner Loop)。
MAML 有很多变形和相关资料,More about MAML:
- More mathematical details behind MAML:https://youtu.be/mxqzGwp_Qys
- First order MAML (FOMAML): https://youtu.be/3z997JhL9Oo
- Reptile:https://youtu.be/9jJe2AD35P8
# 3.6 学习 Optimizer
刚刚讲了说我们可以学习初始化的参数,我们还可以学习 Optimizer,在 update 参数的时候,我们需要决定 learning rate、momentum 等等 hyper-parameter,那像这种 hyper-parameter 能不能用学习的方式把它用 meta learning 学习出来呢?这是可以的。
NIPS 2016 有一篇 paper “Learning to learn by gradient descent by gradient descent”,这篇 paper 里面就是直接 learn 一个 optimizer,是自动根据 learning tasks 学出来的。具体可以参考该 paper。
# 3.7 Network Architecture Search(NAS)
除了可以训练 initial parameters、optimizer,能不能也训练 Network Architecture 呢?这就是需要将 Network Architecture 当作
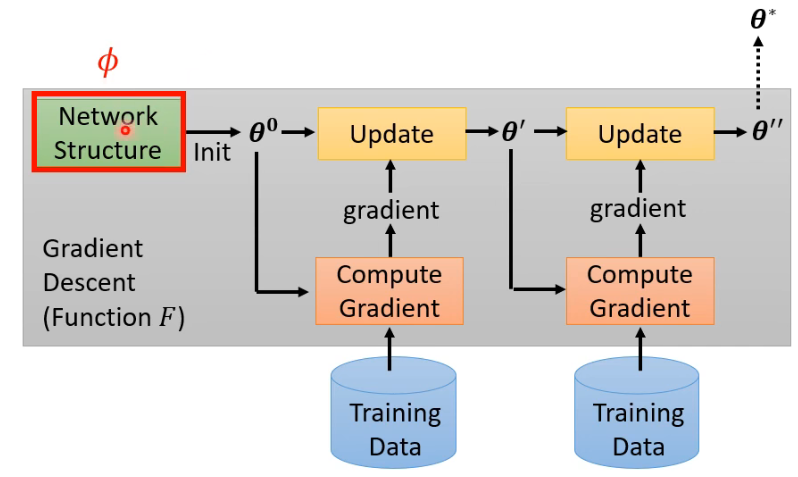
研究训练 Network Architecture 的一系列研究就是鼎鼎大名的 Network Architecture Search(NAS)。
在 NAS 里面,既然
用 RL 怎么做呢?An agent uses a set of actions to determine the network architecture:
用 RL 做 NAS 的一个早期 work 的图示如下:
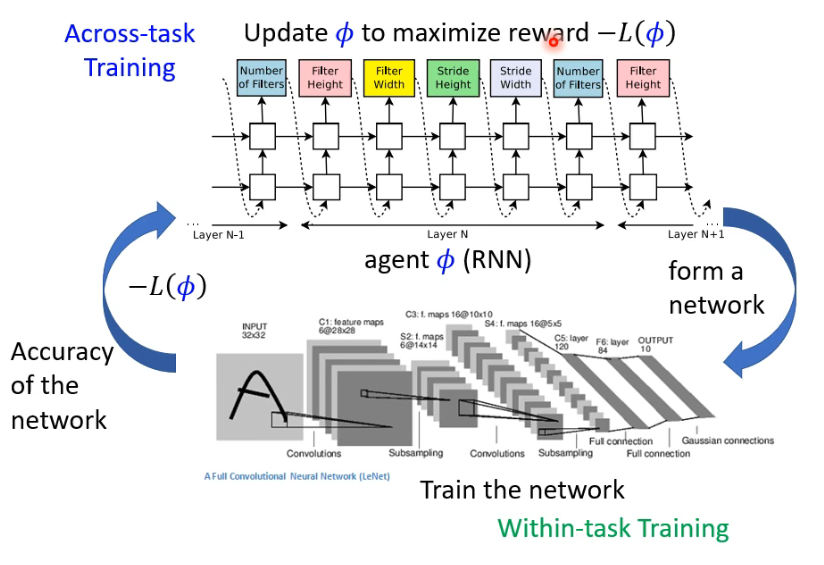
- 这里是把 agent 想成一个 RNN,每次会输出一个跟 Network Architecture 有关的参数。
RL 解 NAS 问题的相关文献:
- Neural Architecture Search with Reinforcement Learning (opens new window)
- Learning Transferable Architectures for Scalable Image Recognition (opens new window)
- Efficient Neural Architecture Search via Parameters Sharing (opens new window)
Evolution Algorithm 解 NAS 问题的相关文献:
其实,如果你硬要把 Network Architecture
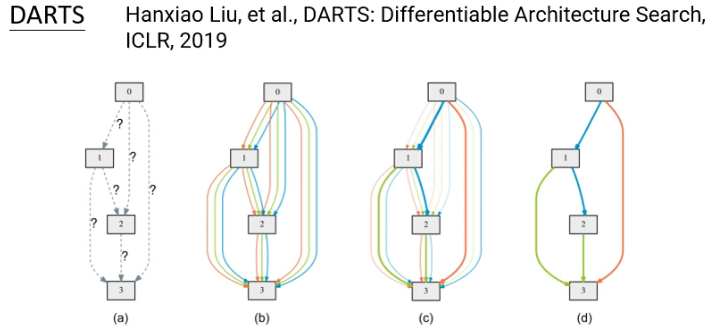
# 3.8 Data Processing
除了 Network Architecture 以外,还有 Data Process 也是可以 learn 的。比如能不能让 machine 自动找出怎样做 Data Augmentation 呢?这也是有可能的,可以参考如下文献:
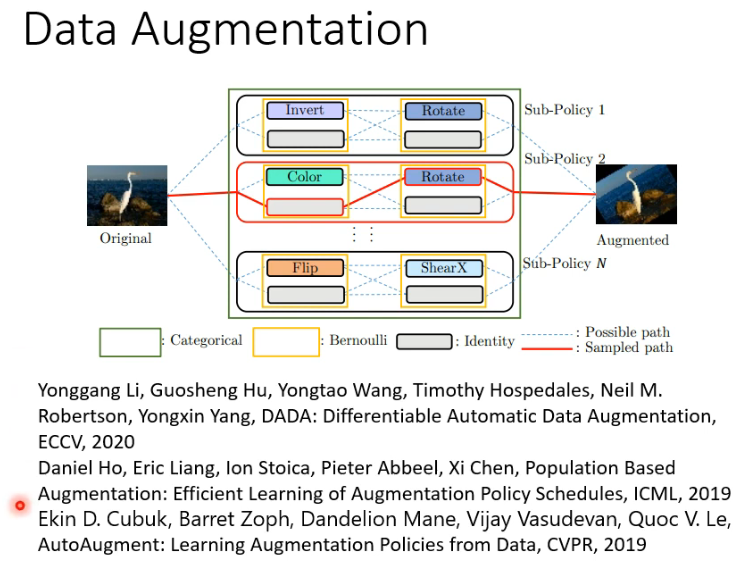
# 3.9 Sample Reweighting
有时候 training 的时候,我们需要给不同的 sample 以不同的 weight,但是要怎么给每一笔 data 不同的权重呢?比如对于离 boundary 近的 sample,有人觉得这些比较难的 sample 应该给一个 larger weights,有人觉得这些 noisy sample 应该给一个 smaller weights。这里我们期望说,可以让 machine 学到根据 data 的特性自动决定说 sample 的 weights 应该怎么设计:

- 上图的 sample weighting strategy 是 learnable 的。
# 3.10 Beyond Gradient Descent
我们刚刚讲的方法都是在围绕着 gradient descent 来做改进,刚才所有方法都是 learn 了一个 gradient descent 的其中一个 component。但我们有没有可能完全舍弃掉 gradient descent 呢?比如说我们就直接 learn 一个 network,这个 network 的 parameters 是
# 3.11 Learning to compare(metric-based approach)
到目前为止,我们都是将训练和测试分成两个阶段:先拿 training data 训练出一个 learning algorithm(function
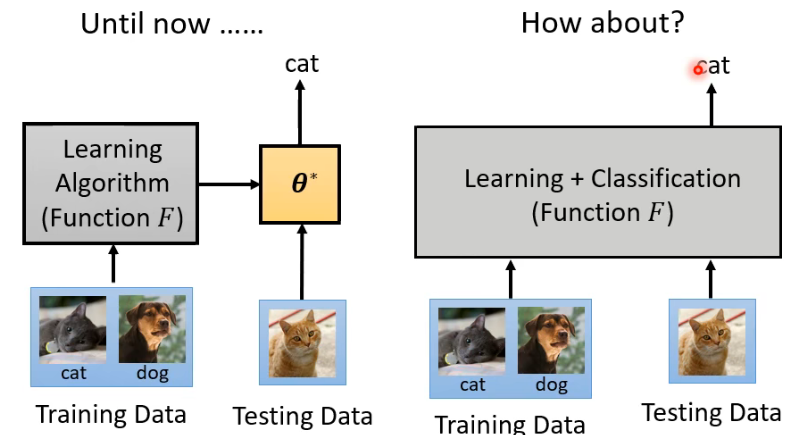
- 这种就是先把 training data 看完后,也不知道里面发生了什么,再直接把 testing data 输入进去。
有一个系列的 meta learning 的做法叫做 Learning to compare,又叫做 metric-based approach,这一系列的做法就可以看做是训练和测试没有分界。具体可以参考过去上课的录影:

# 4. Application
# 4.1 Few-shot Image Classification
今天在做 meta learning 时,最常拿来测试 meta learning 技术的任务是 Few-shot Image Classification。在这个任务里,每个 class 都只有很少的几张 image,你希望透过这样一点点的资料,就可以训练出一个 model,你给 model 一张 image,它就能告诉你这张 image 属于哪个 class:

在做这种任务时,你时常会听到一个术语:N-ways K-shot classification:
N-ways K-shot classification
N-ways K-shot classification: In each task, there are N classes, each has K examples.
在 meta learning 里面,你需要去准备许多 N-ways K-shot tasks 作为 training 和 testing tasks。那怎样去找这一堆 N-ways K-shot 的 training tasks 呢?
在文献上最常用的是使用 Omniglot 这个 corpus 当作 benchmark corpus:

- 在这个 corpus 中,有 1623 个 characters,每个 character 有 20 个 examples,比如右上角的 20 个 example 是同一个 character。
在有了 Omniglot 这个 corpus 之后,你就可以制造 N-ways K-shot 的 tasks 了。比如你选出 20 个 characters,然后每个 character 就只取一个 example,这样你就得到一个 20 ways 1 shot 的 task。测试资料的做法是,你再从那 20 个 characters 里面找一个 example 出来,然后接下来问这个 Query set 是这 20 个 class 里面的哪一个。如下图所示:
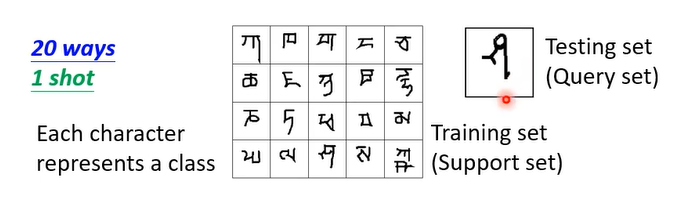
- Split your characters into training and testing characters
- Sample N training characters, sample K examples from each sampled characters -> one training task
- Sample N testing characters, sample K examples from each sampled characters -> one testing task
# 4.2 Other
Meta learning 不只是可以用在 Omniglot 上,table (opens new window) 列举了 meta learning 在语音处理、NLP 等方向的应用。至于 meta learning 能走多远,我们拭目以待。