Self Supervised Learning
Self Supervised Learning
# 1. BERT 简介
# 1.1 芝麻街与进击的巨人
# 1.2 Self-supervised Learning
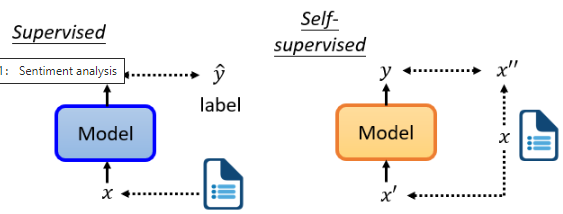
- 监督学习中我们有一个模型,输入 x 得到输出 y,此外还有一个 label
- Self-supervised(自监督学习)用另一种方式来监督,没有标签。假设我们只有一堆没有 label 的文章,但我们试图找到一种方法把它分成两部分,让其中一部分
我们以 BERT 为例来说明 Self-supervised Learning 是什么意思。
# 1)Masking Input
首先,BERT 是一个 Transformer 的 Encoder,它和 Transformer 的 Encoder 一样,里面有很多 Self-Attention、Residual connection 和 Normalization 等等,这就是 BERT。
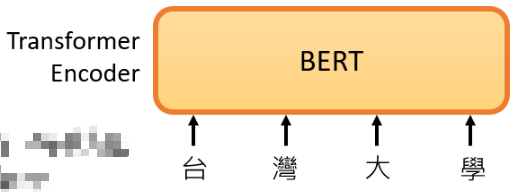
关键点是:BERT 可以输入一行向量,然后输出另一行向量,输出的长度与输入的长度相同。BERT 一般用于自然语言处理,用于文本场景,所以一般来说,它的输入是一串文本,也是一串数据。
接下来,我们随机盖住一些输入的文字,被 mask 的部分是随机决定的:
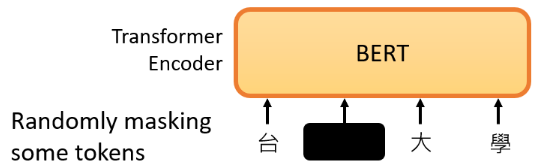
mask 的具体实现有两种方法,使用哪种方法都可以:
- 用一个特殊的符号替换句子中的一个词。我们用
MASK来作为特殊符号,这个字完全是一个新词,意味着 mask 了原文。 - 随机把某一个字换成另一个字。比如“湾”字可以随机换成“大”、“一”等字。
mask 后把序列输入 BERT,把输出看作另一个序列,从中寻找 mask 部分的相应输出,然后让这个向量通过一个 Linear transform,即矩阵相乘,再做 softmax,输出一个分布:
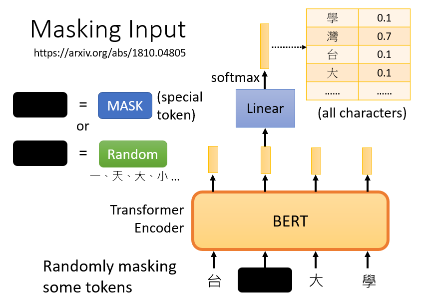
在训练过程中。我们知道被 mask 的字符是什么,而 BERT 不知道,我们可以用一个 one-hot vector 来表示这个字符,并使输出和 one-hot vector 之间的交叉熵损失最小。这其实就是在做一个分类问题,BERT 要做的就是预测什么被盖住,具体来说就是被掩盖的字符属于"湾"类。
在训练中,我们在BERT之后添加一个线性模型,并将它们一起训练。所以,BERT 里面是一个 transformer 的 Encoder,它有一堆参数。这两个需要共同训练,并试图预测被覆盖的字符是什么,这叫做 mask。
# 2)Next Sentence Prediction
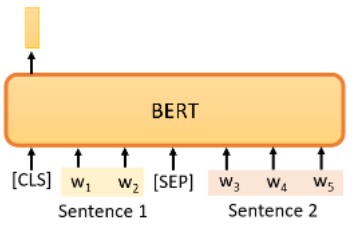
当我们训练 BERT 时,除了 mask 之外,我们还会使用另一种方法:Next Sentence Prediction。它的意思是我们拿两个句子,句子之间加一个特殊标记 SEQ 作为分隔符,再在开头加一个 CLS 的特殊标记。这样我们就有了一个 <CLS> <seq1> <SEQ> <seq2> 拼成的 seq,将它输入 BERT 得到一个输出 seq,然后我们只看 output seq 中 CLS 对应的输出:
将 CLS 对应的输出乘一个 Linear transform,输出 yes or no,即预测第二句是否是第一句的后续句:
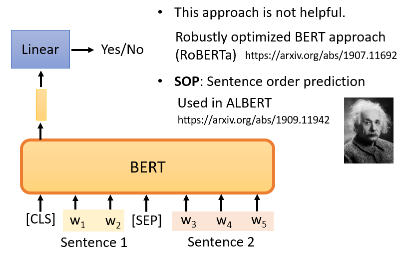
然后而来的研究发现,对于 BERT 要做的任务来说,Next Sentence Prediction 并没有真正的帮助。可能的原因是 Next Sentence Prediction 任务太简单,导致 BERT 没有学到太有用的东西。还有一种类似的方法叫作 Sentence order prediction(SOP),这个方法的思想是,选两个连续的句子,要么句子1在句子2后面相连,要么句子2在句子1后面相连,有两种可能性,我们问 BERT 是哪一种。这种方法被用在 ALBERT 模型中。
所以当我们训练时,我们要求BERT学习两个任务:
- 一个是掩盖一些字符,具体来说是汉字,然后要求它填补缺失的字符。
- 另一个任务表明它能够预测两个句子是否有顺序关系。
总的来说,BERT 学会了如何填空,但 BERT 的神奇之处在于,在你训练了一个填空的模型之后,它还可以用于其他任务,而这些任务不一定与填空有关。BERT 实际使用的任务称为 Downstream Tasks(下游任务),它是我们真正关心的任务,但当我们想让 BERT 学习做这些 Downstream Tasks 时,我们仍然需要一些标记的信息。
BERT 就像胚胎干细胞,具有各种无限潜力,虽然它还没有使用它的力量,但以后它有能力解决各种任务。我们只需要给它一点数据来激发它,它就能做到。BERT 分化成各种任务的功能细胞,被称为 Fine-tune。我们对 BERT 进行微调可以使他能够完成某种任务,在微调之前产生这个 BERT 的过程称为预训练。所以,生成 BERT 的过程就是 Self-supervised 学习。
在我们谈论如何微调 BERT 之前,我们应该先看看它的能力。为了测试 Self-supervised 学习的能力,通常,你会在多个任务上测试它,让 BERT 分化成各种任务的功能细胞,看看它在每个任务上的准确性,然后我们取其平均值,得到一个总分。这个不同任务的集合,称之为任务集。任务集中最著名的基准是 GLUE:
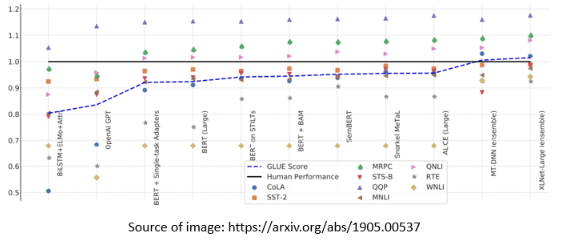
- 黑线表示人类的工作
- 蓝色曲线表示机器 GLUE 得分的平均值
# 1.3 How to use BERT
# Case 1:Sentiment analysis
第一个案例是我们的 Downstream Tasks 要输入一个序列,然后输出一个 class。比如说 Sentiment analysis 就是给机器一个句子,让它判断这个句子是正面的还是负面的:
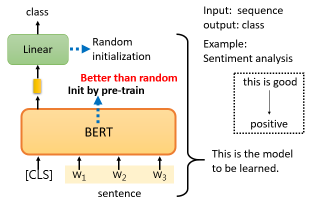
在实践中,你必须为你的 Downstream Tasks 提供标记数据,因为 BERT 没有办法从头开始解决情感分析问题,你仍然需要向 BERT 提供大量的句子,以及它们的正负标签,来训练这个 BERT 模型。
在训练的时候,Linear transform 和 BERT 模型都是利用 gradient descent 来更新参数的:
- Linear transform的参数是随机初始化的
- 而 BERT 的参数是由学会填空的BERT初始化的
我们为什么要这样做呢?最直观和最简单的原因是,当你把学会填空的BERT放在这里时,它将获得比随机初始化BERT更好的性能。
- 当你进行 Self-supervised 学习时,你使用了大量的无标记数据
- 另外在 Downstream Tasks 需要少量的标记数据
所谓的半监督就是指用大量的无标签数据和少量的有标签数据。使用 BERT 的整个过程是连续应用 Pre-Train 和 Fine-Tune,它可以被视为一种半监督方法。
# Case 2:POS tagging
第二个案例是输入输入一个序列,然后输出另一个序列,而输入和输出的长度是一样的。POS tagging(词性标记)是指你给机器一个句子,它必须告诉你这个句子中每个词的词性。
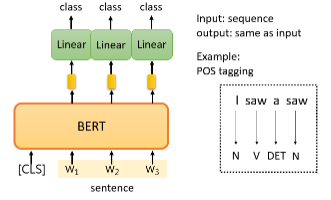
你只需向 BERT 输入一个句子。之后,对于这个句子中的每一个 token 是一个中文单词,有一个代表这个单词的相应向量。然后,这些向量会依次通过 Linear transform 和 softmax 层。最后,网络会预测给定单词所属的类别,例如,它的词性。
这是一个典型的分类问题,唯一不同的是 BERT 的参数不是随机初始化的,在预训练过程中,它已经找到了不错的参数。
# Case 3:Natural Language Inference
第三个案例以两个句子为输入,输出一个类别。在 Natural Language Inference(NLI)中,机器要做的是判断是否有可能从前提中推断出假设,即这个前提与这个假设是否相矛盾:
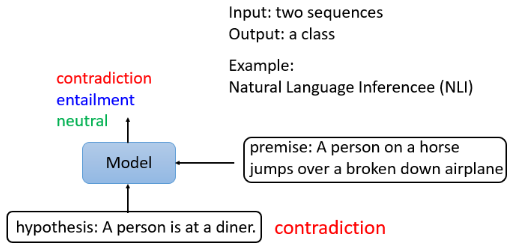
- 在上面这个例子中,我们的前提是“一个人骑着马,然后他跳过一架破飞机”,假设是“这个人在一个餐馆”,所以这个推论说这是一个矛盾。
机器要做的就是把两个句子作为输入,并输出这两个句子之间的关系。比如舆情分析中给定一篇文章和一个评论,判断这个消息是同意还是反对这篇文章。
BERT 的做法就是在这两个句子之间放一个特殊的标记,并在最开始放 CLS 标记,把这个序列作为 BERT 的输入,并只把 CLS 标记对应的 output 作为 Linear transform 的 input,从而决定这两个输入句子的类别:
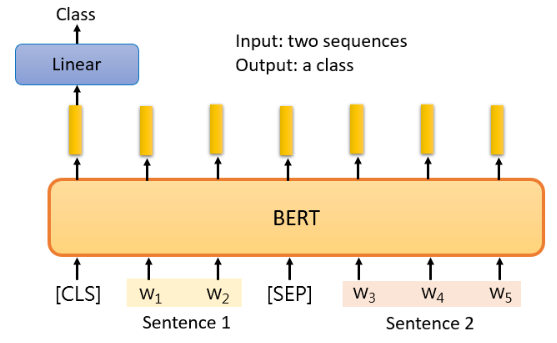
# Case 4:Extraction-based Question Answering (QA)
Extraction-based 的 AQ 是在机器读完一篇文章后,你问它一个问题,它将给你一个答案,并假设答案必须出现在文章。

在这个任务中,一个输入序列包含一篇文章和一个问题,文章和问题都是一个序列。对于中文来说,每个d代表一个汉字,每个 q 代表一个汉字。你把 d 和 q 放入 QA 模型中,我们希望它输出两个正整数 s 和 e。根据这两个正整数,我们可以直接从文章中截取一段,它就是答案。这听起来很疯狂,但是无论如何,这是今天一个非常普遍的方法。
举一个例子,这里有一个问题和一篇文章,正确答案是 "gravity"。机器如何输出正确答案:

为了训练这个QA模型,我们使用BERT预训练的模型:
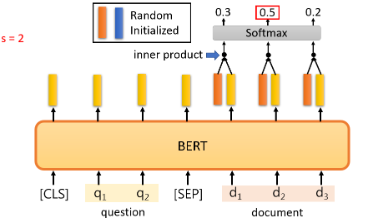
在这个任务中,你唯一需要从头训练的只有两个向量。"从头训练 "是指随机初始化。这里我们用橙色向量和蓝色向量来表示,这两个向量的长度与BERT的输出相同。首先,计算这个橙色向量和那些与文件相对应的输出向量的内积,然后将它们通过 softmax 函数,找到分数最大的位置,得到 s,代表输出的起始位置。
蓝色部分也做一样的事情,计算结果 e 代表答案的终点:
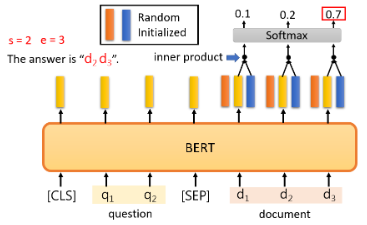
如果答案不在文章中,你就不能使用这个技巧。
# 1.4 Training BERT is challenging!
虽然 BERT 在预训练中只是做填空题,但你自己真的不能把它训练起来。谷歌最早的 BERT 中使用的数据规模已经很大了,它包括了 30 亿个词汇。更痛苦的是训练过程,这将需要大量的时间。
谷歌已经训练了 BERT,这些 Pre-Train 模型是公开的,那我们再去训练有什么意义呢?也许可能是想建立一个 BERT 胚胎学,这样可以观察到 BERT 什么时候学会填什么词汇,它是如何提高填空能力的。论文链接 (opens new window)供大家参考,不过可以提前爆冷一下就是:事实和你直观想象的不一样。
# 1.5 Pre-training a seq2seq model
BERT 只是一个预训练的 Encoder,有没有办法预训练 Seq2Seq 模型的 Decoder?有!现在我有一个 seq2seq 模型,带着一个 Encoder 和 Decoder,input 一个 seq,output 一个 seq,中间用 Cross Attention 连接。然后你故意 Encoder 的输入上做一些干扰来破坏它。这样,Encoder 看到的是被破坏的结果,那么 Decoder 应该输出句子被破坏前的结果,训练这个模型实际上是预训练一个 Seq2Seq 模型。如下图:
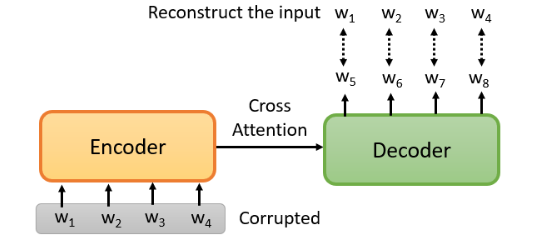
有各种破坏 Encoder 输入的方法:删除一些词,打乱词的顺序,旋转词的顺序,或者插入一个MASK,再去掉一些词。在破坏了输入的句子之后,它可以通过 Seq2Seq 模型来恢复它。
那么多 mask 方法,哪种最好呢?谷歌的一篇论文 T5(Transfer Text-To-Text Transformer)做了各种尝试,可以读一下看看结论。T5 是在一个叫做 C4 的数据集上训练的,大小有 7TB。可以看到,在 deep learning 中,数据量和模型都很惊人。
# 2. Fun Facts about BERT
# 2.1 Why does BERT work?
最常见的解释是,当我们输入 seq 后,每个文本都有一个对应的 vector,这个 vector 也称为 Embedding,它代表了输入词的含义:
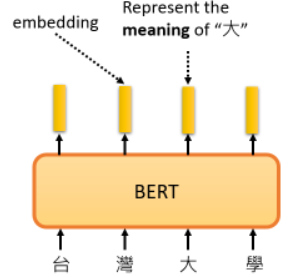
意思相近的词,他们的 vector 也比较接近。BERT 考虑上下文,水果的“苹果”和手机“苹果”含义不同,其相应的 Embedding 也会有很大不同。
为什么 BERT 有如此神奇的能力?一个词的含义取决于 context,当我们训练 BERT 做 mask 时,就是在训练 BERT 从 context 预测 masked 的部分:
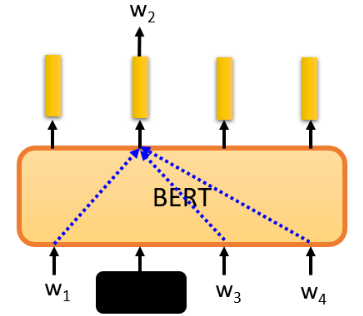
在以前,这样的想法就存在了,CBOW 所做的与 BERT 完全一样,即从 context 预测空白处的内容:
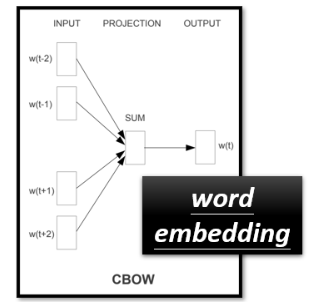
但 CBOW 是一个非常简单的模型,它只使用了两个线性变换。当时之所以选择如此简单地模型,最大的担心还是当时的算力问题。而如今的计算能力已经与几年前的技术不在一个数量级上了。今天你使用 BERT 的时候,就相当于一个深度版本的 CBOW。由于 BERT 是一个考虑到 context 的高级版本的 word embedding,BERT 也被称为 Contextualized Embedding。
这时大多数人会告诉你的解释,但这是真的吗?实验室有学生做过实验:应用为文本训练的 BERT 对蛋白质、DNA链和音乐进行分类。以DNA链的分类为例,DNA是一系列的 A、T、C 和 G 表示的脱氧核糖核酸,对他们进行分类,总之是一个分类问题:
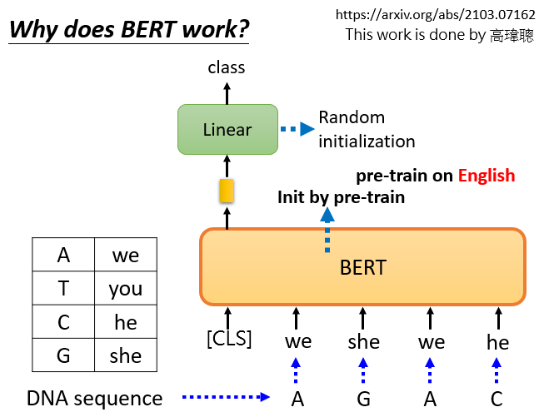
神奇的是,把我们把 ATCG 对应到四个随便的词,这样 DNA 序列就成了一个无法理解的文字序列,扔进 BERT 中,用 CLS 标记输出一个向量,经过一个 Linear transform,对它进行分类。你可能认为这个实验是一个无稽之谈,因为大家都知道 BERT 可以分析一个有效句子的语义,你怎么能给它一个无法理解的句子呢?神奇的是,这是可以的:
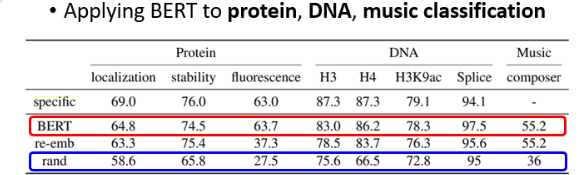
所以,BERT 的力量也许并不完全来自于对实际文章的理解,也许还有其他原因,这需要进一步的研究了。
# 2.2 Multi-lingual BERT
Multi-lingual BERT 是由很多语言用填空题训练起来的:
# 2.2.1 Zero-shot Reading Comprehension
google 训练了一个 Multi-lingual BERT,它能够做这 104 种语言的填空题。神奇的地方来了,如果你用英文问答数据训练它,它就会自动学习如何做中文问答。
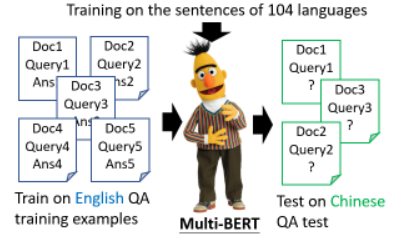
这里有个例子:
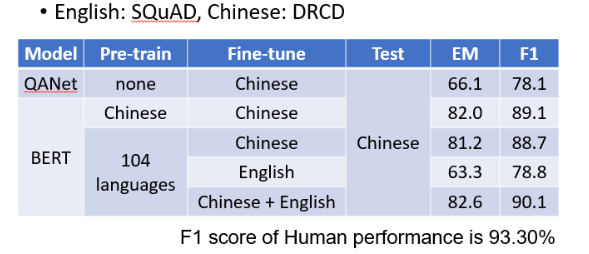
神奇的是,如果我们把一个 Multi-lingual 的 BERT,用英文 Q&A 数据进行微调,它仍然可以回答中文 Q&A 问题,并且有 78% 的正确率,这几乎与 QANet 的准确性相同。
# 2.2.2 Cross-lingual Alignment?
BERT 会了中文填空,再加上英文问答的能力,不知不觉中,它就自动学会了做中文问答。BERT 怎么做到的呢?一个简单地解释是不同的语言并没有那么大的差异。rabbit 和“兔”的 Embedding 很接近,其他也类似:

它是可以被验证的,标准是 Mean Reciprocal Rank(MRR),这里不详细说明它,只要知道MRR的值越高,不同 embedding 之间的 Alignment 就越好。更好的 Alignment 意味着,具有相同含义但来自不同语言的词将被转化为更接近的向量:
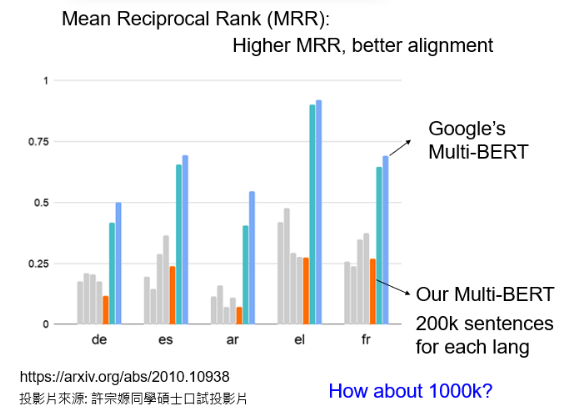
- 深蓝色的线是谷歌发布的 104 种语言的 Multi-lingual BERT 的 MRR,它的值非常高,这说明不同语言之间没有太大的差别。
还有一个很怪的现象:
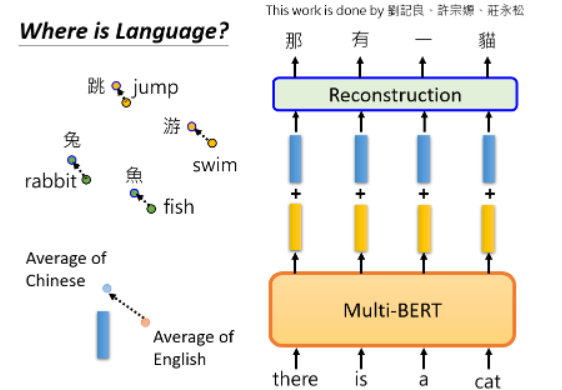
- 蓝色 vector 表示英语和汉语之间的差距。可以看到这里做了一个奇妙的无监督翻译。
再给 BERT 看句子:

在向BERT输入英文后,通过在中间加一个蓝色的向量来转换隐藏层,转眼间,中文就出来了。所以它在某种程度上可以做无监督的标记级翻译,尽管它并不完美,神奇的是,Multi-lingual BERT 仍然保留了语义信息。
# 3. GPT 的野望
# 3.1 GPT 的训练

除了 BERT 以外,另一个鼎鼎有名的模型就是 GPT 系列的模型。BERT 做的填空题,而 GPT 做的任务是 Predict Next Token。
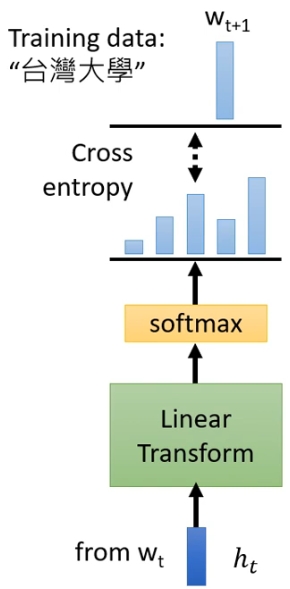
假设你的训练资料里面有个句子是“台湾大学”,GPT 拿到这笔训练资料之后会做什么呢?

首先你给 GPT 一个 begin token <BOS>,GPT 输出一个 representation
- 这个图展示了从一个 token
然后就是以此类推了:
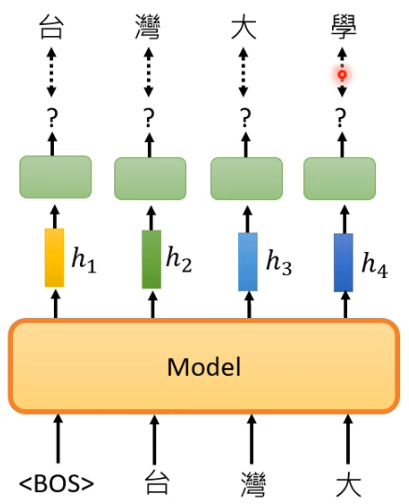
就没有然后了,,就这样!
GPT 的能力就是它可以做 generation 的事情,它的形象是一个独角兽,因为它写了一个活灵活现的独角兽的假新闻:

# 3.2 How to use GPT?
GPT 可以把一句话补完,那它是怎样用在 downstream tasks 上呢?
之前我们讲过 BERT 的使用,在 BERT 后面接一个 classifier 就好了,其实 GPT 也可以这么做,应该也是有效的。但是 GPT 有一个更狂的想法,也许因为 BERT 那种方法已经用过了,也许因为 GPT 实在太大了,大到连 fine-tuning 都有困难。那 GPT 是怎么做的呢?
假设你在考托福,你是怎样考试的?如下图,首先给你一个题目的 description,然后给几个 example,你就可以作答了:

GPT 要做的事情很类似,比如想让模型做翻译,就先给它一句 task description,然后给它几个 examples,接下来问它 “cheese =>”,然后希望它产生翻译的结果:

但这跟一般的 few-shot learning 有点区别,因为这里面其实没有 learning,这里没有 gradient descent,没有对 GPT 模型的参数做任何改动。在 GPT 的文献中,给这种训练起了一个名字:In-context Learning。
当然还有更狂的例子:

那 GPT 有没有达到这个目标呢?GPT-3 测试了 42 个 tasks,可以看到,虽然说 GPT 可以做到上面说的事情,其实正确率并没有特别高,其实效果是不如 fine-tuning 那种模型的:
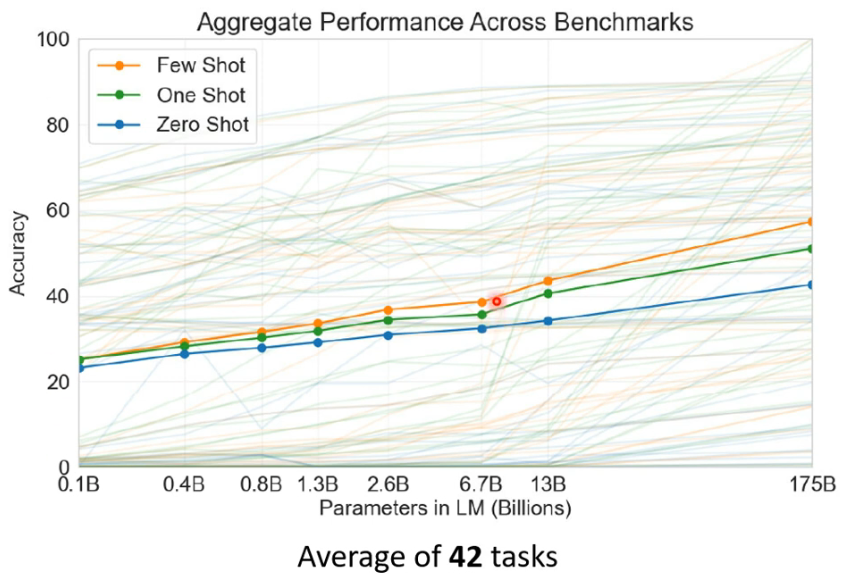
- 它们测试不同大小的模型,从 0.1B 到 175B 的参数量。
最好的效果有 60个 percent,到底 GPT 有没有算是学会这个任务,这其实算是见仁见智了。
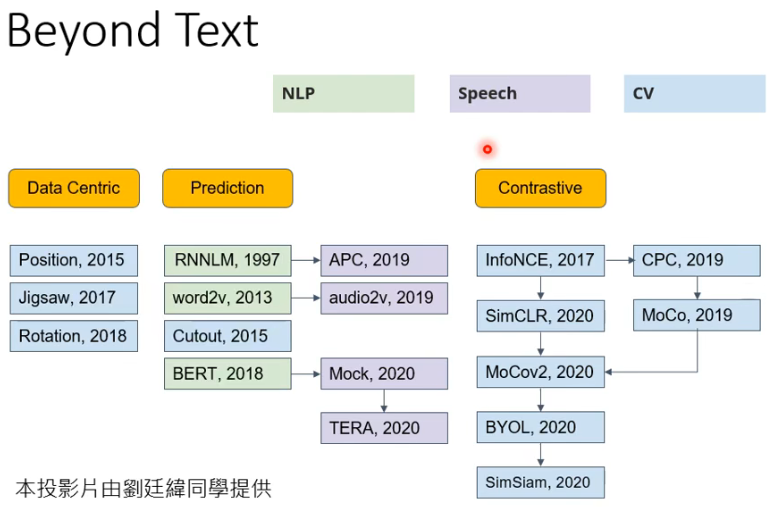
# 4. Beyond Text
Self Supervised Learning 的技术不仅可以用在 NLP 中,还可以用在 Speech 和 CV 中,在这些这么多的模型里面,BERT 和 GPT 也只是其中的两种,还有更多 Self Supervised Learning 的 model: