 Transformer
Transformer
# 1. Seq2Seq 的应用
Transformer 就是一个 Sequence-to-sequence(Seq2Seq)的 model,它由机器来决定 output 的长度。
# 1)语音辨识
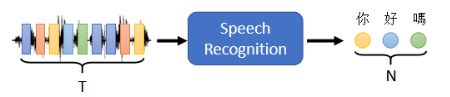
- 输入是一串 vector 表示的声音讯号,输出是语音辨识的结果,即对应的文字。这里的输出的长度由机器来决定。
# 2)机器翻译

# 3)语音翻译

- 比如把听到的英文声音讯号翻译成中文文字
# 4)语音合成
比如输入是台语声音,输出中文的文字
# 5)chat bot(聊天机器人)

# 6)QA
即 Question Answering,给机器读一段文字,然后你问机器一个问题,希望他可以给你一个正确的答案。
# 7)Syntactic Parsing(文法剖析):

# 8)multi-label classification
把它与 multi-class 的 classification 区分一下。
- multi-class classification 是说对一个东西从多个 class 中选一个出来
- multi-label classification 是说同一个东西,他可以属于多个 class,比如做文章分类:
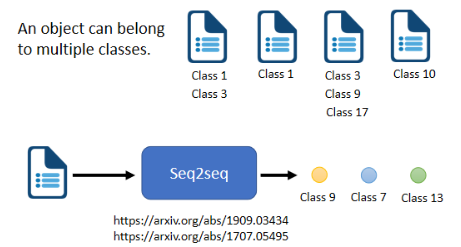
# 9)Object Detection
Object Detection 与 seq2seq model 看起来八竿子打不着,但却可以用它来硬解:
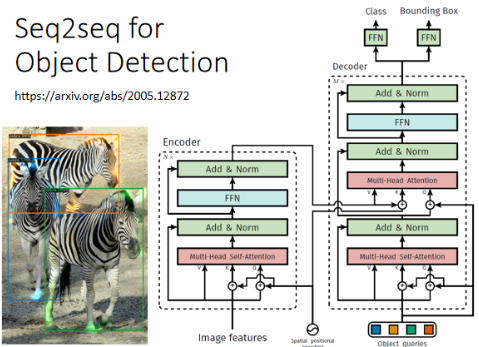
对多数 NLP 任务而言,尽管 seq2seq 可以处理,但为这些任务定制化模型,往往你会得到更好的结果。
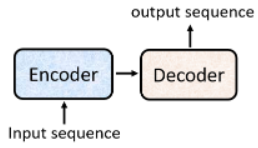
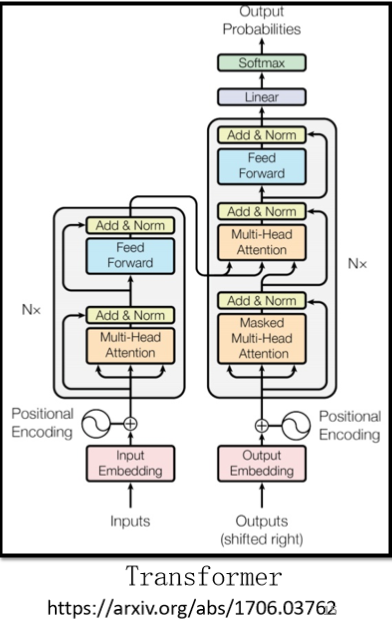
# 2. Encoder
一般的 seq2seq's model 会分成 Encoder 和 Decoder:
今天讲到 seq2seq,可能首先想到的就是 Transformer,它也是有一个 Encoder 和一个 Decoder,里面有很多花花绿绿的 block,之后会逐渐讲解。
# 2.1 简化的 Transformer Encoder
seq2seq model 的 Encoder要做的事情,就是给一排向量,输出另外一排向量:

我们先简化一下,现在 Encoder 里面会分成很多很多的 block:
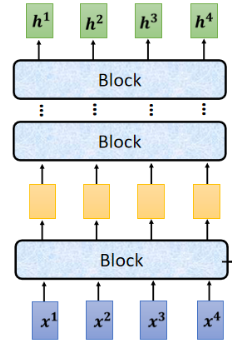
每一个 block 里面做的事情,就是好几个 layer 在做的事情,大概是这样:
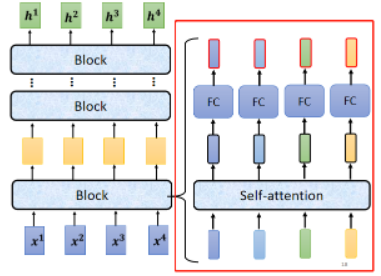
- 输入一排 vector,先做一个 self-attention 考虑整个 sequence 的资讯,输出另一排 vector,之后再丢进 fully-connected 的 network 里面,其输出作为 block 的输出。
事实上原来的 Transformer 做的事情是更复杂的。
# 2.2 加入 residual 和 layer norm
在之前说 self-attention 的时候,输出的 vector 是考虑了所有 input 后得到的结果。在 Transformer 里面,它加入了一个设计,我们不只是输出这个 vector,还要把这个 vector 加上它的 input,得到新的 output:
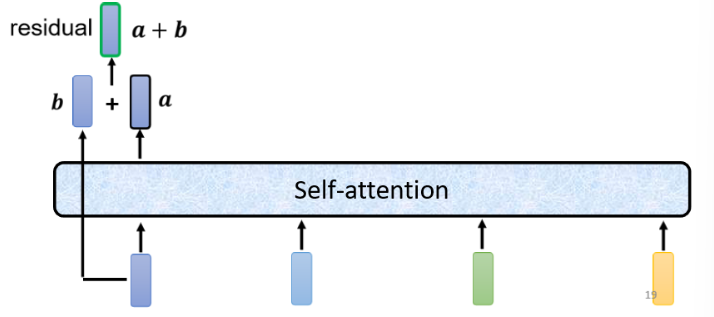
这样子的 network 架构,就叫做 residual connection(残差连接)。这种方式在 Deep Learning 领域用的还是很广泛的。
Residual Connection 在 ResNet 网络中首次提出。
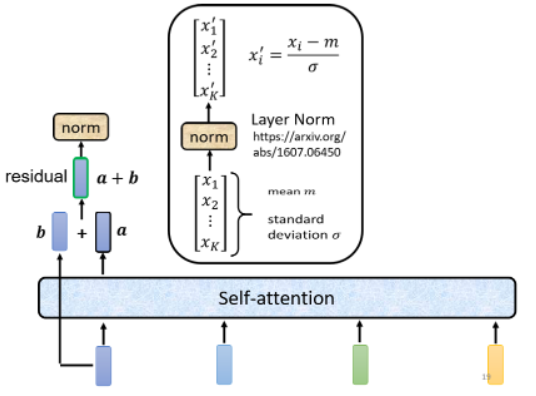
得到 residual 的结果以后,再把它做一个 layer normalization:
警告
注意区分 layer normalization 和 batch normalization。
- layer normalization 是输入一个 vector,输出另一个 vector,不需要考虑 batch。它把输入的这个 vector 计算 mean 和 standard deviation。
- bacth normalization 是对不同 example、不同 feature 的同一个 dimension 去计算 mean 和 standard deviation。
计算出 mean
计算得到 layer norm 的输出后,才把它作为 FC 的输入:
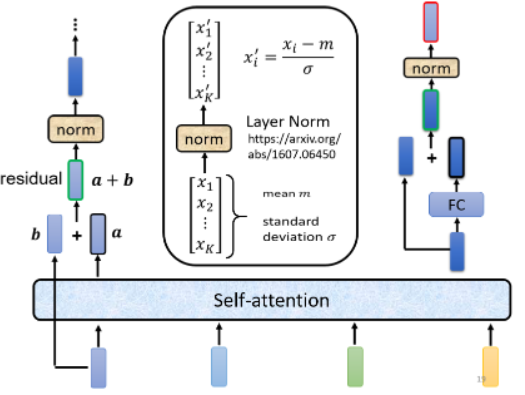
- FC Network 这边也有用到 residual 的架构:把 FC 的 input 与 output 加起来,做一下 residual 得到新的输出。
- FC 做完 residual 后,还要再把 residual 的结果再做一次 layer norm,得到的输出才是 block 的输出。
# 2.3 小结 Encoder
刚刚所讲的,总结起来就是下面这张图了:

- 光用 self-attention 是没有位置的资讯的,因此需要加上一个 positional encoding
- self-attention 用了 multi-head 的 attention
Add & Norm就是 residual + layer norm- 接下来经过 fully-connected 的 Feed Forward,之后再做一次 Add & Norm,才是一个 block 的输出
- 这个 block 会重复 N 次。这个复杂的 block 会用到之后的 BERT 里面。
# 2.4 To Learn More
也许你会问,Transformer 的 Encode 为什么要这样设计,其实也可以不这样设计。原始论文的设计不代表它是最 optimal 的设计。比如以下论文提出的:
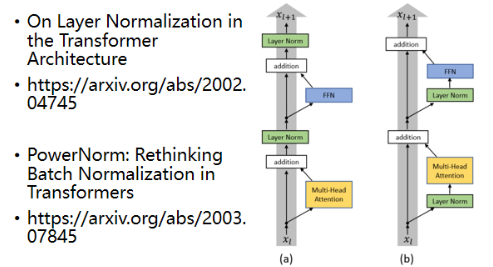
- 第一篇是说能不能把 layer norm 放到每一个 block 的 input。比如上图中左边是原始的 Transformer,右边是把 block 内部稍微更换顺序后的 Transformer。这样更换之后结果是比较好的。
- 还有一篇 paper 是说在 Transformer 里面为什么 batch norm 不如 layer norm,接下来又提了一个 power norm,它比 layer norm 的 performance 的效果稍微好一点。
# 3. Decoder
Decoder 其实分成两种,这里主要介绍常见的 Autoregressive Decoder(AT)。
# 3.1 整体上看
Encoder 所做的就是输入一个 vector sequence,输出另外一个 vector sequence,接下来轮到 Decoder,它将产生输出,比如语音辨识的结果。我们先假设 Encoder 可以将输出传给 Decoder。
Decoder 怎样产生一段文字呢?首先要给他一个代表“开始”的特殊符号(下图中即START),这个 special token 代表了“开始”这件事情:
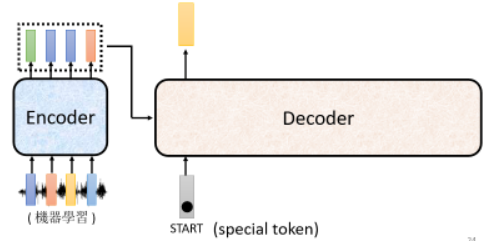
在这个机器学习里面,每一个 token 都可以用一个 one-hot 的 vector 表示,所以这个 START 也是用 one-hot vector 表示。接下来 Decoder 会吐出一个向量,这个吐出的 vector 长度与你的 Vocabulary 的 size 是一样的:
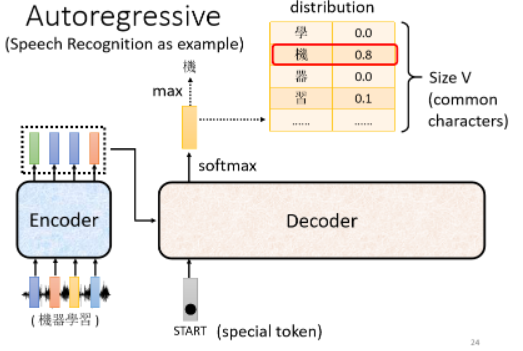
在产生所吐出的 vector 之前会先经过一个 softmax,所以这个向量里面的分数是一个 distribution,即里面的值全部加起来为 1。
在这个例子中,“机”作为首个输出,接下来把“机”当做是 Decoder 新的 input。根据这两个输入,再继续输出下一个。之后这个 process 反复持续下去,如下图:
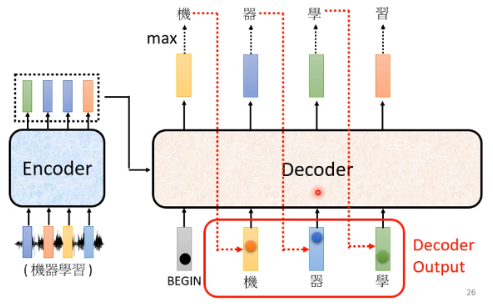
可以发现,Decoder 会把自己的输出,当做接下来的输入。但这里有个问题,如果 Decoder 看到前一步产生的错误输出再吃进去,可能会造成 Error Propagation 的问题,即一步错,步步错。在最后我们会讲一下这个问题。
# 3.2 Decoder 的运作方式
我们先把 Encoder 的部分先暂时省略掉,Transformer 的 Decoder 长这样:
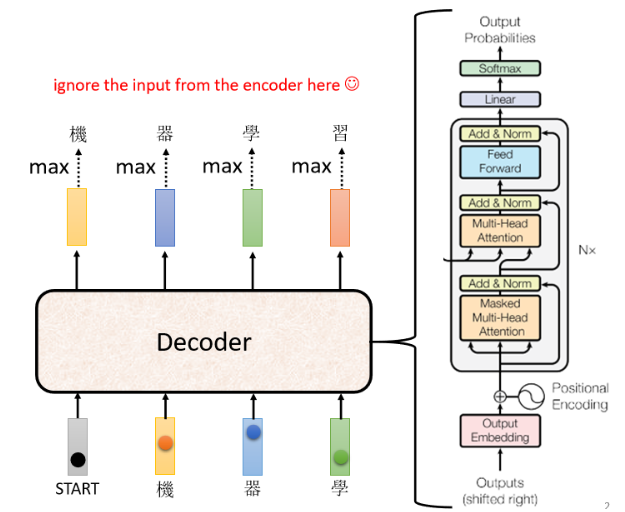
看上去比较复杂,我们把 Encoder 和 Decoder 比较一下,把中间这一块盖起来,可以看到两者并没有那么大的差别:
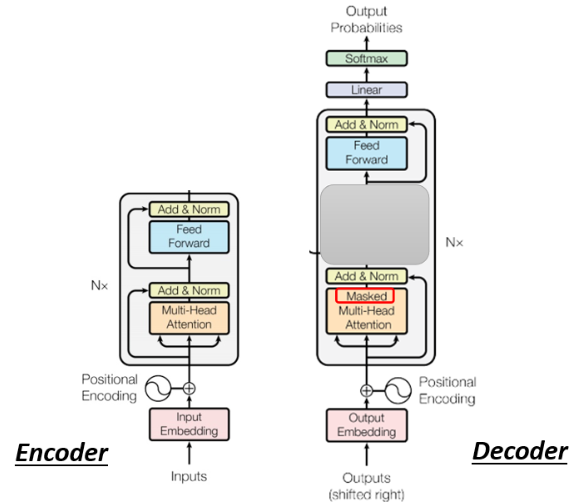
- Encoder 这边是 Multi-Head Attention -> Add & Norm -> Feed Forward -> Add & Norm,重复 N 次,其实 Decoder 也是这样,只是中间盖起来的这一块略有区别。
还有一个稍微不一样的地方是 Decoder 这边的 Multi-Head Attention 加了一个 Masked,即 Masked Multi-Head Attention。这里 Masked 的意思是说,原来的 self-attention 在输出每一个 vector 时都会看过完整的 input 才做决定,而 Masked Attention 是产生 output vector 时不能再看右边的,而是只能看左边的,比如产生
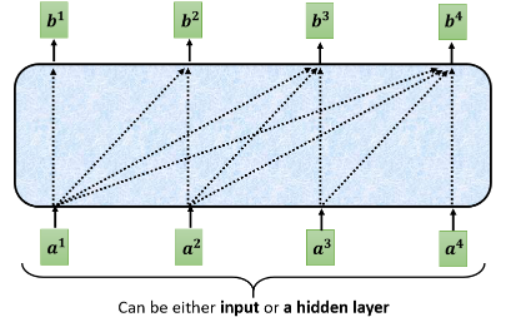
这个就是 Masked Self-Attention。具体一点,计算
为什么要加 Masked 呢?因为 Decoder 的输出 token 是一个一个产生的,它只能考虑左边的东西。
讲了 Decoder 的运作方式,还有一个关键问题,是 Decoder 必须自己决定输出的 sequence 长度。为了让 output 能停下来,我们需要准备一个特别的符号来表示“结束”,这里用 END 表示。其实这个特殊词 END 与 BEGIN 可以是同一个符号。当输出 END 时,整个 Decoder 产生 sequence 的过程就结束了。
这就是 Autoregressive Decoder。
# 3.3 另一种 Decoder - Non-autoregressive(NAT)
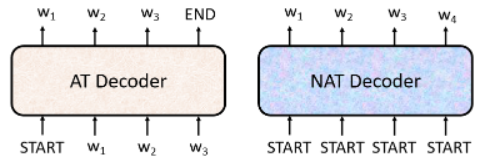
我们简短地讲一下 Non-Autoregressive 的 model,常缩写成 NAT。
我们对比一下 AT 与 NAT。AT 是先输入 START,直到输出 END 为止。但 NAT 的 output token 不是依次产生的,它是一次性把整个句子都产生出来。NAT 的 Decoder 可能吃的是一整排的 START,然后一次产生一排的 token 就结束了:
这里有一个问题,我们不知道输出的长度,那我们怎么知道 START 放多少个来当做 NAT Decoder 的输入?这是不能很直接知道的,这里有几个做法:
- 一个做法是,另外 learn 一个 Classifier,它吃 Encoder 的 input,然后输出一个数字,这个数字代表 Decoder 应该要输出的长度
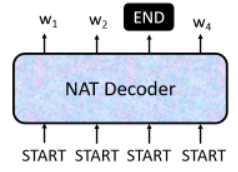
- 另一个做法是,不管三七二十一,给他一堆
START的 token,比如假设说知道输出的句子长度绝对不会超过 300 个字,那就给他 300 个 START,然后输出 300 个字,再看看什么地方输出了 END,这个 END 右边的就当做没有输出了:
NAT 的 Decoder 有什么样的好处呢?
- 并行化:不管句子长度如何,都是一个步骤就产生出完整的句子了
- 能够控制它输出的长度。这在语音合成等领域是常用 NAT 的。
NAT 的 Decoder 之所以是一个研究热点,是因为它表面看上去很厉害,但它的 performance 往往不如 AT 的 Decoder。这里不再对它进行展开了。
# 4. Encoder 与 Decoder 之间传递资讯:Cross Attention
讲 Encoder 与 Decoder 之间怎样传递资讯,就是讲之间我们刻意遮起来的一块:
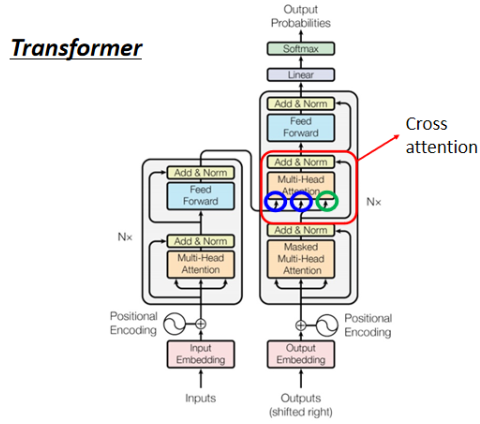
这一块叫做 Cross Attention,它是连接 Encoder 跟 Decoder 之间的桥梁。可以看到两个输入箭头来自 Encoder,一个输入箭头来自下面的 Decoder。通过左边的两个箭头,Decoder 可以读到 Encoder 的输出。
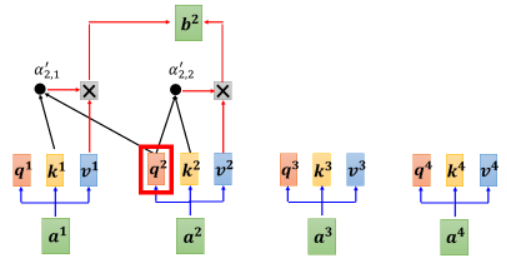
我们把这个模组的运作过程跟大家展示一下。Encoder 输入一排 vector,输出一排 vector,然后轮到 Decoder,它先吃掉 START,经过 Masked Self-Attention 后得到一个 vector,将它乘上一个矩阵,做一个 transform,得到一个 Query
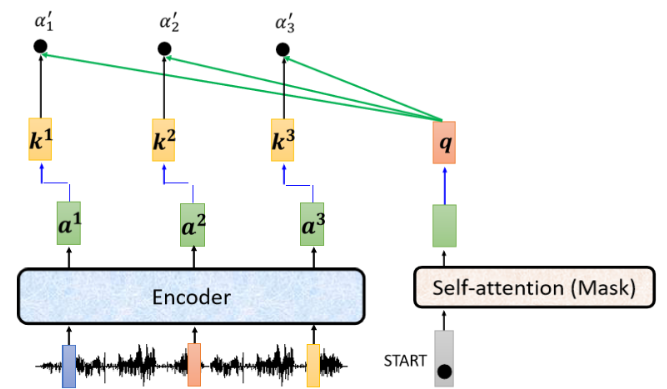
- 这里对 Attention Score
’是因为可能做过 Normalization
之后再:
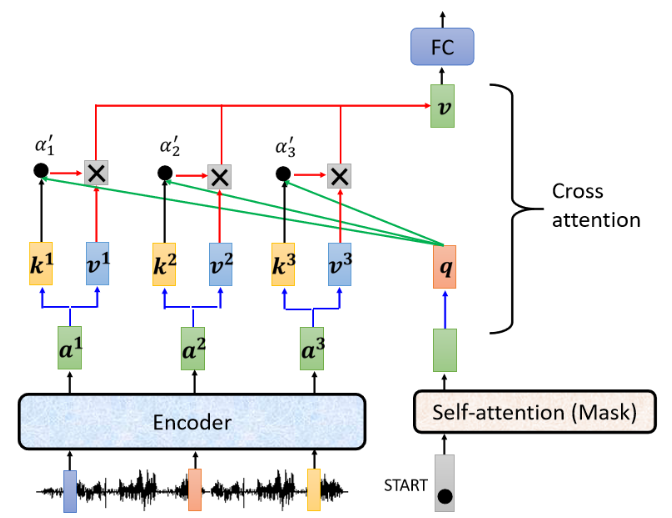
在整个过程中,

还要注意,Encoder 和 Decoder 都是有很多层的,即重复了 N 次 block,而这个 Decoder 的不管哪一 block,都会拿 Encoder 的最后一层的输出。
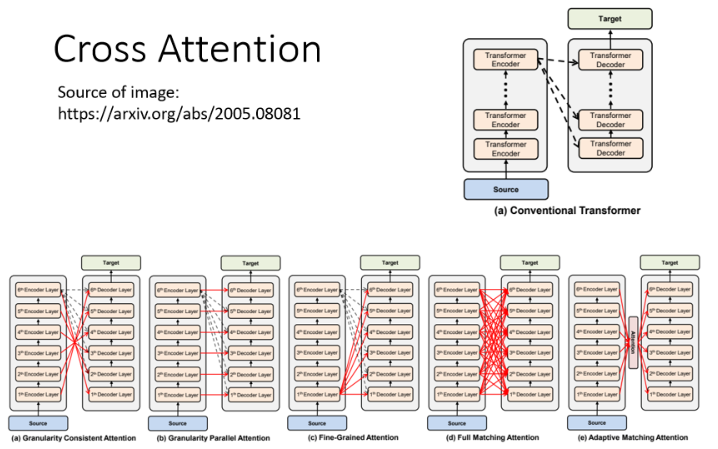
原 paper 是这样干的,但也不一定非要这么干,也有人尝试不同的 Cross Attension 的方式,也就是说有人提出 Decoder 这边的每一层不一定都要看 Encoder 的最后一层的输出,还可以有不同的连接方式:
# 5. Training 过程
已经说清楚 input 一个 seq 怎样得到 output 了,接下来就是 training 部分了。刚才说的都是假设模型已经训练好后,是怎样做 inference 的,也就是 testing 的,那该怎么 train 呢?
当 Decoder 输出一个 distribution 后,你会去计算 ground truth 与 distribution 之间的 Cross Entropy,然后我们希望这个 Cross Entropy 越小越好:
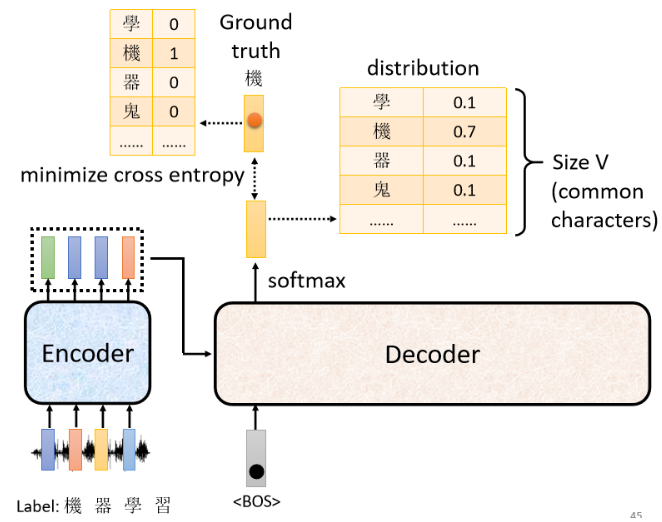
也就是我们希望模型输出的 distribution 跟答案的四个字的 one-hot vector 越接近越好。所以在训练时,每个输出都跟正确答案都有一个 Cross Entropy,我们希望所有 Cross Entropy 的总和越小越好:
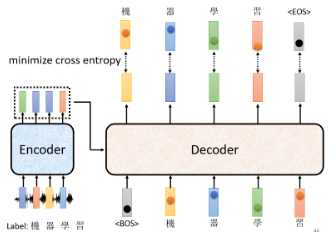
还有一种训练方式是Teacher Forcing:在 Decoder 训练的时候,我们会在输入的时候给看它正确的答案,如下图:
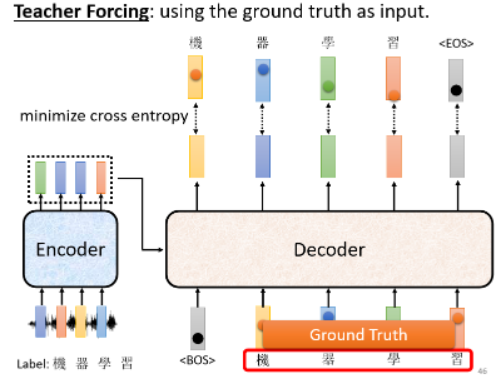
这时马上就有了另外一个问题:在训练的时候 Decoder 看到了正确答案,但在测试的时候没有正确答案可以看了,只能看自己的输入。这中间显然有一个 mismatch。之后我们会讨论一些可能的解决方式。
# 6. Tips
接下来将一些训练 seq2seq model 的一些 tips。
# 6.1 Copy Mechanism
刚刚都是 Decoder 自己产生输出,但很多任务中 Decoder 没有必要自己创造输出出来,它要做的只是从输出裡面复製一些东西出来。比如聊天机器人:

还比如对文章生成摘要,也是需要从文章里面直接复制一些资讯出来。
最早有从输入复制东西的能力的模型,叫做 Pointer Network。这里不再展开。
# 6.2 Guided Attention
机器就是一个黑盒子,有时候会犯一些非常低级的错误。
比如我们在一个语音合成的任务中用 seq2seq 的 model 来 硬 train 一发,结果还不错,比如输入 4 个连续的“发财”,它会抑扬顿挫地读出来,但输入 1 个却不念“发”。
产生上面这种莫名其妙的结果,也许是因为在训练资料里面,这种非常短的句子很少,导致机器不会念。当然这种例子也很少出现。
在上面例子中,我们发现机器居然漏字了,输入有一些东西它居然没有看到,我们能不能够强迫它,一定要把输入的每一个东西通通看过呢?这招就叫做 Guided Attention。
像在语音辨识中,讲了一句话而机器听漏了一部分,你会很难受。但如果像 chat bot,到底有没有看完整句话,其实你也不在乎。所以用不用这招,要看具体任务。
Guiding Attention 要做的事情就是,要求机器在做 Attention 的时候是有固定方式的。比如语音合成或语音辨识中,我们想象的 Attention 应该就是由左向右的。如果语音合成时 Attention 颠三倒四的,胡乱看整个句子,那显然 something is wrong,比如:
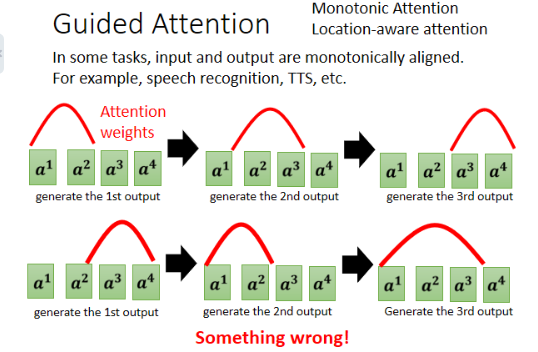
这部分也是个大坑,不再展开了。
# 6.3 Beam Search
举一个例子,加入 Decoder 只能产生两个字:A 或者 B。Decoder 要在每一个 time step 里,从 A、B 里选一个,那么 path 将是一个 Greedy Decoding,即每次选一个得分最高的:
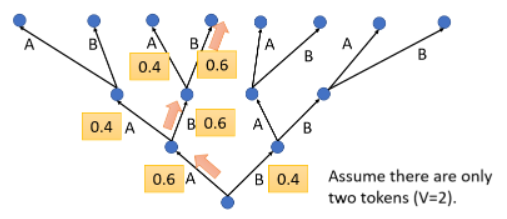
但有没有一种可能是,第一步先舍弃一些东西,之后接下来的结果却是好的。就像天龙八部的真龙棋局一样,先堵死自己一块,结果接下来反而赢了。比如下图中绿色的路径:
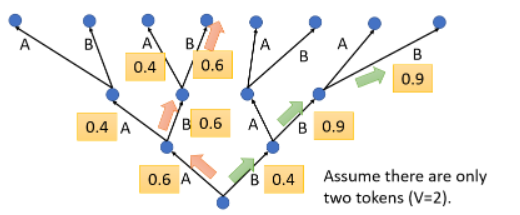
如何找到这个绿色的路径呢?有一种可能是暴力搜索所有路径,但我们没有办法真的暴力搜索全部可能路径,这怎么办呢?有一种演算法叫做 Beam Search,它用一种比较有效的方法找一个 Approximate,找一个估测的 Solution(不是精准的),这个技术就是 Beam Search。这里不再展开。
有人会说 Beam Search 很烂。比如在一个任务:给出文章上半部,让机器写出下半部。如果用了 Beam Search 的话,会发现说机器不断讲重复的话,会陷入鬼打墙。如果不是 Beam Search,带有一些随机性,得到的句子至少是正常的。所以用不用 Beam search 要看任务本身:
- 就假设一个任务,它的答案非常地明确,那通常 Beam Search 会有帮助;
- 如果你需要机器发挥一点创造力,这时候 Beam Search 就比较没有帮助。
这呼应了一个谚语,我们要接受没有事情是完美的,那真正的美也许就在不完美之中。加入一些随机性,结果反而会是比较好的。
# 6.4 Optimizing Evaluation Metrics?
我们在作业里面,对 Decoder 的评估标准用的是 BLEU Score。BLEU Score 是说先产生一个完整的句子,然后再去跟正确的答案一整句做比较,两个句子之间做比较,算出 BLEU Score。
但在我们训练时却不是这样评估的,在训练时每一个词汇是分开考虑的,最终我们 minimize 的是 Cross Entropy。那么,Minimize Cross Entropy 真的可以 Maximize BLEU Score 吗?不一定,但有一点点关联,毕竟他们就是两个不同的数值。
那么我们可不可以在训练时就让 loss 是负的 BLEU Score,这样 minimize 那个 loss,不就相当于 Maximize BLEU Score 了嘛?但这个事情没那么容易,BLEU Score 本身很复杂,它不能微分,也就无法 gradient descend。
这里教大家一个口诀:遇到你在 Optimization 无法解决的问题,用 RL 硬 train 一发就对了。把无法 Optimize 的 Loss Function 当做 RL 的 reward,把 Decoder 当做 Agent,这样就当成了一个 RL 的问题去硬做。真的有人这样试过,这里不再展开了。
# 6.5 Scheduled Sampling
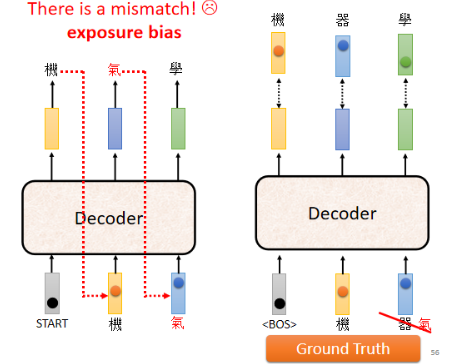
这里就要讲之前提到的一个问题:训练跟测试居然是不一致的。测试时 Decoder 看到的是自己的输出,所以测试时 Decoder 会看到一些错误的东西,但训练时 Decoder 看到的完全是正确的,这个不一致的现象叫做 Exposure Bias。
假如 Decoder 在训练的时候永远只看过正确的东西,那么在测试时只要有一个错,那就会一步错 步步错,因为对于 Decoder 来说,如果它从没有看过错的东西,一旦看到错的东西就会非常惊奇,导致步步错。
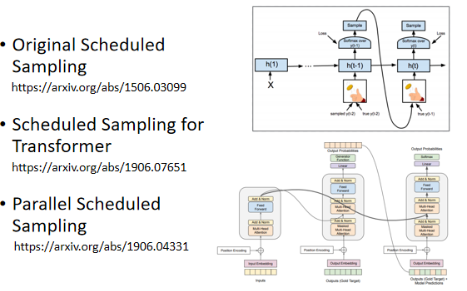
:怎么解决这个问题呢?一个方向是给 Decoder 的输入加一些错误的东西。不要永远给他看正确地答案,偶尔一些错的东西,它反而会学得更好。这一招叫做 Scheduled Sampling:
下面列出一些 Scheduled Sampling 的 paper:
以上我们就讲完了 Transformer 和种种的训练技巧。