 Anomaly detection
Anomaly detection
# 1. Problem Motivation
异常检测是机器学习算法的一个常见应用。
什么是异常检测呢?假想你是一个飞机引擎制造商,当你生产的飞机引擎从生产线上流出时,你需要进行 QA(质量控制测试),而作为这个测试的一部分,你测量了飞机引擎的一些特征变量,比如引擎运转时产生的热量,或者引擎的振动等等:

这样一来,你就有了一个数据集,将这些数据绘制成图表,看起来就是这个样子:
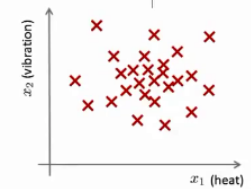
这样,异常检测问题可以定义如下:我们假设后来有一天,你有一个新的飞机引擎从生产线上流出,而你的新飞机引擎有特征变量
我们希望知道这个新数据
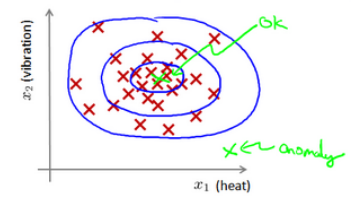
上图中,在蓝色圈内的数据属于该组数据的可能性较高,而越是偏远的数据,其属于该组数据的可能性就越低。
这种方法称为密度估计,表达如下:
if p(x) < threshold:
x is anomaly
else
x is normal
2
3
4
这种方式也可以用于做欺诈检测等。
# 2. Gaussian Distribution
# 2.1 Gaussian (Normal) Distribution
高斯分布就是正态分布。
# 2.2 Parameter estimation
给了一个 dataset:
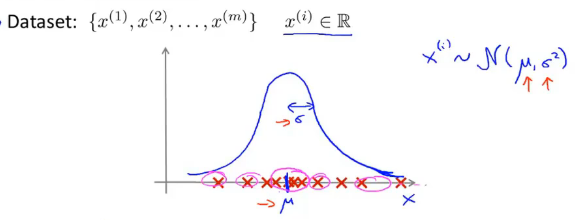
估计这两个参数的公式为:
在统计学中,为了达到无偏估计,估计
时前面的系数应该是 ,不过在机器学习中,当数据量大了之后,就无所谓用哪个了,所以在机器学习中一般是用 。
# 3. Algorithm
本节将应用 Gaussian Distribution 开发异常检测算法。
Anomaly detection algorithm

# 4. Developing and Evaluating an Anomaly Detection System
When developing a learning algorithm (choosing features, etc.), making decisions is much easier if we have a way of evaluating our learning algorithm.
假定我们有一些 labeled data,y = 0 if normal,y = 1 if anomalous. 那么划分出三个数据集:
- Training set:
- Cross validation set:
- Test set:
以之前说的飞机引擎作为例子,加入我们有 10000 个 normal example,20 个 anomalous example,可以做如下划分:
- training set:6000 good engines
- validation set:2000 good, 10 anomalous
- test set:2000 good,10 anomalous
不建议让 validation set 和 test set 使用同一个数据集。
划分了数据集后,对算法的评价方法时:
Algorithm evaluation

# 5. Anomaly detection vs. Supervised learning

- Anomaly detection 常用于 fraud detection、manufacturing、monitoring machines in a data center
- Supervised learning 常用于 Email spam classification、weather prediction、cancer classification
# 6. Choosing what features to use
# 6.1 面对 non-gaussian features 怎么办?
在刚刚介绍的算法中,我们使用 Gaussian Distribution 来对 feature 建模,所以我们需要先用直方图画出数据,以确保 feature 在进入 Anomaly detection 算法之前看上去比较接近 Gaussian Distribution。
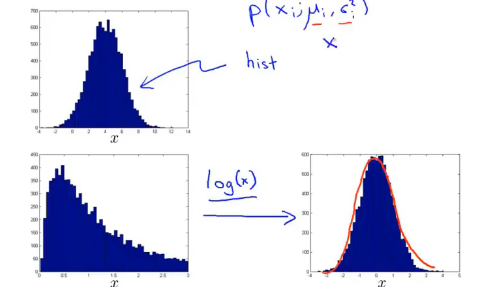
上图中的上半部分的直方图(hist)是比较接近与 Gaussian Distribution 的,但下半部分的原始数据却显然不接近,这时可以对他进行一个变换,比如
当然还存在其他变换,比如可以
# 6.2 怎样得到这些 feature?
在 Anomaly Detection 中,我们希望的是:
- 当 x 是 normal example 时
- 当 x 是 anomalous example 时
但一个问题是,很多 feature 的
仍以监控计算机作为例子。Choose features that might take on unusually large or small values in the event of an anomaly. 假如有以下 features:
如果有一台服务器的程序陷入了死循环,那么就会出现 CPU load 很大,但 network traffic 很低的情况,这时候就可以将
# 7. 多变量高斯分布
// TODO:选修,还没有学