 协同过滤
协同过滤
# 1. Problem Formulation
本章主要讲一下推荐系统(Recommender Systems),它是机器学习中的一个重要的应用,在学术界也具有一定的份额。借助推荐系统,我们还将领略一下特征学习的思想,即不手动设计 feature 而是采用一个算法来进行学习。
我们从一个例子开始定义推荐系统的问题。假使我们是一个电影供应商,我们有 5 部电影和 4 个用户,我们要求用户为电影打分:
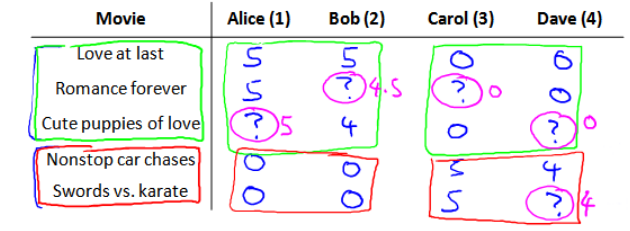
前三部电影是爱情片,后两部则是动作片,我们可以看出 Alice 和 Bob 更倾向于爱情片,而 Carol 和 Dave 更倾向于动作片,并且没有一个用户给所有的电影都打过分。我们希望构建一个算法来预测他们每个人可能会给他们没看过的电影打多少分,并以此作为推荐的依据。
下面先引入一些标记:
# 2. 基于内容的推荐系统
在一个基于内容的推荐系统算法中,我们假设对于我们希望推荐的东西有一些数据,这些数据是有关这些东西的特征。
在我们的例子中,我们可以假设每部电影都有两个 feature,
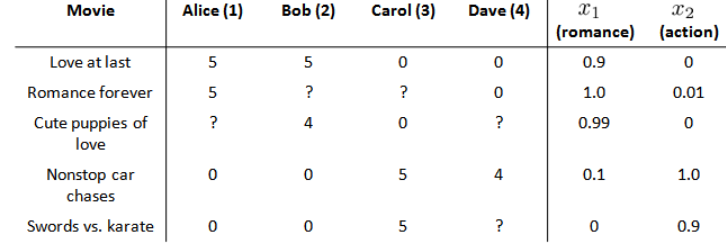
每部电影都有一个 feature vector,如第一部电影
下面我们要基于这些特征来构建一个推荐系统算法。假设我们采用线性回归模型,我们可以针对每一个用户都训练一个线性回归模型,如
预测 user
比如上例中,
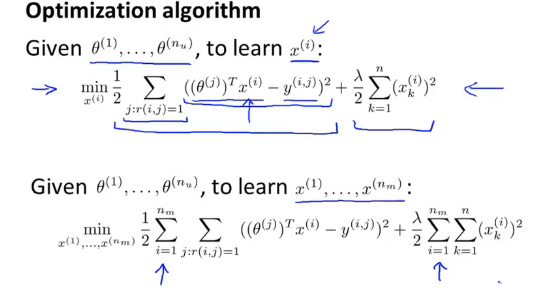
我们把问题正式的表达出来:为了 learn
- 式子的后半部分是 regularization
- 前后两部分系数中都有
所以,Optimization objective 可以写成下面这样:
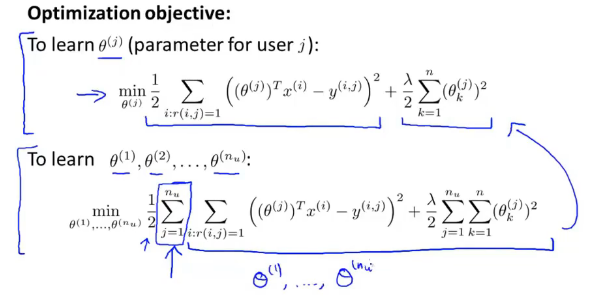
下面的就是将所有 user 的参数一块算,用 gradient descent 来做的话就是:

上面所介绍的算法就是基于内容的推荐算法,因为我们假设变量是已有的,即我们有描述电影内容的特征量,比如这个电影的爱情程度怎么样。但是对于许多电影来说,我们并没有或者很难获取这些的特征量。
下一节我们将介绍不是基于内容的算法,即不去假设我们已经得到这些所有的电影的特征。
# 3. 协同过滤算法
在之前的基于内容的推荐系统中,对于每一部电影,我们都掌握了可用的特征,使用这些特征训练出了每一个用户的参数。相反地,如果我们拥有用户的参数,我们可以学习得出电影的特征。
假设我们知道一个用户的喜好,他比较喜欢爱情片,那他的
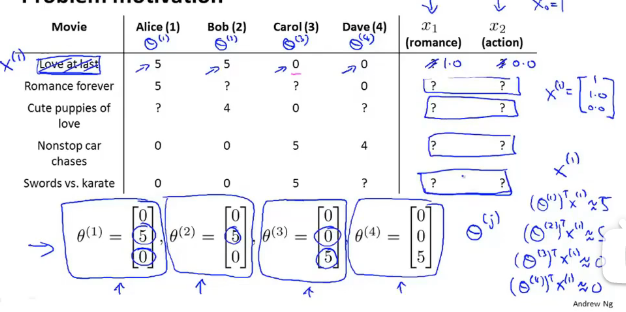
优化过程可以写成如下:
- 下面是用于计算所有电影的 feature vector 的式子。
我们先看一个基本的 Collaborative filtering 算法:
- Given
- Given
所有我们可以先随机地猜取一些
这是一个基本的协同过滤算法,但不是我们要最终应用的。下面我们来改进这个算法。
考虑如果我们既没有用户的参数,也没有电影的特征,那上面提到的两种方法都不可行了。协同过滤算法可以同时学习这两者。
我们的优化目标便改为同时针对

- 可以看到,紫色部分都一样,因此可以合并
- 其实,当固定
这里与前面的区别在于,
Collaborative filtering algorithm
- Initialize
- Minimize
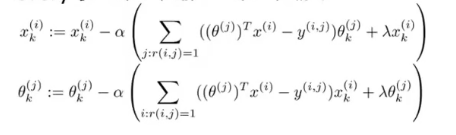
- For a user with parameters
上面介绍的就是 Collaborative filtering 算法,它可以同时算出所有电影的 feature vector 和用户的 params vector,并能预测出用户未评价部分的分数。
# 4. Vectorization: Low Rank Matrix Factorization
本节讲述协同过滤算法的向量化实现,以及说说有关该算法你可以做的其他事情。举例子:
- 当给出一件产品时,你能否找到与之相关的其它产品。
- 一位用户最近看上一件产品,有没有其它相关的产品,你可以推荐给他。
我将要做的是:实现一种选择的方法,写出协同过滤算法的预测情况。
我们有关于五部电影的数据集,我将要做的是,将这些用户的电影评分,进行分组并存到一个矩阵中:
| Movie | Alice (1) | Bob (2) | Carol (3) | Dave (4) |
|---|---|---|---|---|
| Love at last | 5 | 5 | 0 | 0 |
| Romance forever | 5 | ? | ? | 0 |
| Cute puppies of love | ? | 4 | 0 | ? |
| Nonstop car chases | 0 | 0 | 5 | 4 |
| Swords vs. karate | 0 | 0 | 5 | ? |
对应写成矩阵就是:
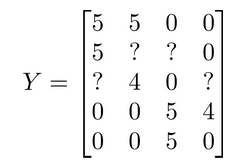
预测出评分:
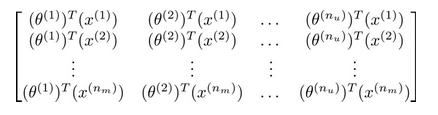
这个评分的计算过程有一个比较简单的向量化的方法来写出它们:每个
找到相关影片:

既然已经学到了电影的 feature vector
总结一下,当用户在看某部电影
通过这个方法,希望你能知道,如何进行一个向量化的计算来对所有的用户和所有的电影进行评分计算。同时希望你也能掌握,通过学习特征参数,来找到相关电影和产品的方法。
# 5. Mean Normalization
让我们来看下面的用户评分数据:
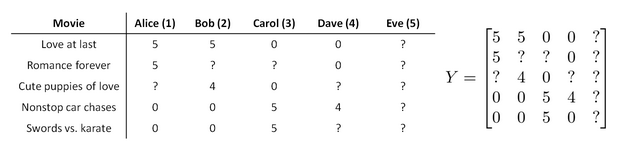
相比于之前,我们新增了一个用户 Eve,并且 Eve 没有给任何电影评分,那么我们以什么为依据为 Eve 推荐电影呢?
如果还是和之前的一样去学习该用户的参数向量的话,目标函数的正则化项会倾向于让这个向量变为零向量,而其余项对该参数向量的更新没有效果,因此最终会学出一个零向量。这显然不是我们期待的结果,因为如果这样的话,我们还是没法给该用户做推荐。
我们首先需要对结果矩阵
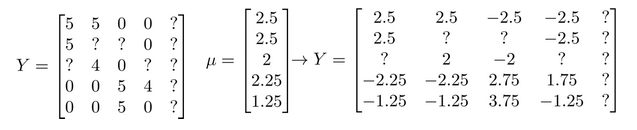
然后我们利用这个新的
这样对于 Eve,我们的新模型会认为她给每部电影的评分都是该电影的平均分。
我们刚刚讲的 Mean Normalization 就是把