 K-Means
K-Means
# 1. 无监督学习
在无监督学习中,我们的 training set data 没有附带任何 label,我们拿到的数据长这样:
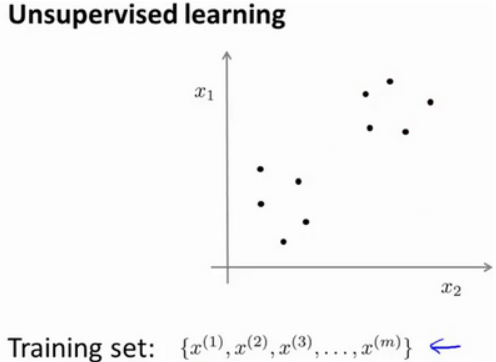
图上画的这些点都没有 label 信息。图上的数据看起来可以分成两个分开的点集(称为 cluster),一个能够找到我圈出的这些点集的算法,就被称为聚类算法。当然,其他的无监督学习也可以为我们找到其他类型的结构或者其他的一些模式,而不只是簇。
这些聚类算法有什么用呢?市场分割、社交网络分析、组织计算机集群等等。
# 2. K-Means Algorithm
K-Means 是最普及的聚类算法,算法接受一个未标记的数据集,然后将数据聚类成不同的组。
K-Means 是一个迭代算法,假设我们想要将数据聚类成 K 个组,其方法为:
K-Means 算法
Input:
- K(number of clusters)
- training set
首先根据划分聚类的个数 K,随机设置聚类中心的位置,然后遍历所有的数据,把每个数据分配到离它最近的坐标,对于同一个簇的数据计算它们坐标的中心位置,并设置为新的聚类中心,以此不断的迭代。

令
- Cluster assignment step:依次计算
- Move Centroid:计算每个 cluster 的中心位置,并赋给
这样的计算过程就能够完成如下图的聚类:
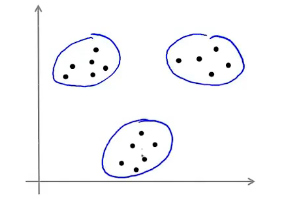
但在实际中,K-Means 也有可能用于 non-separated clusters,比如如下图:
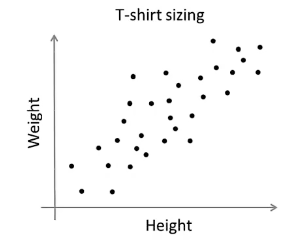
上图是收集到的人身高、体重等信息,现在我们想将衣服分成小号、中号和大号,并确定它们的尺寸大小。通过执行 K-Means 算法,可以将他们分成三个 cluster:
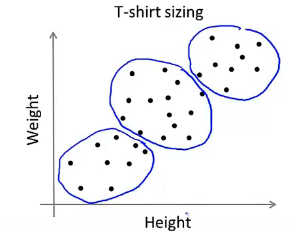
从而就可以确定每个类型的衣服的尺寸大小了。
# 3. Optimization Objective
K-Means 最小化问题,是要最小化所有的数据点与其所关联的聚类中心点之间的距离之和。因此 K-Means 的 cost function(又称为畸变函数 Distortion function)为:
回顾刚才给出 K-Means 迭代算法,可以看出第一个循环是用于减小
# 4. Random Initialization
在运行 K-Means 算法的之前,我们首先要随机初始化所有的 cluster 中心点,下面介绍怎样做:
- 我们应该选择 K < m,即聚类中心点的个数要小于所有训练集实例的数量;
- 随机选择 K 个训练实例,然后令 K 个聚类中心分别与这 K 个训练实例相等。
K-Means 的一个问题在于它有可能会停留在一个局部最小值处,而这取决于初始化的情况。
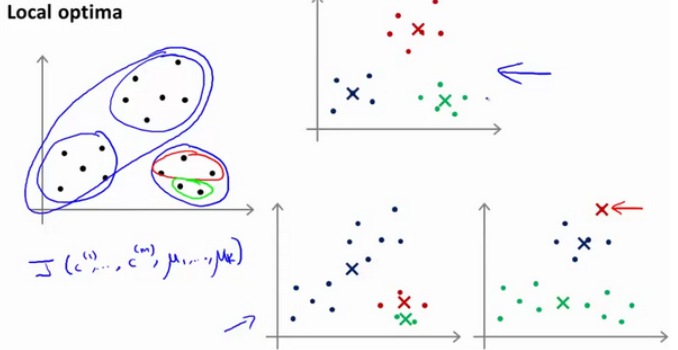
为了解决这个问题,我们通常需要多次运行 K-Means 算法,每一次都重新进行随机初始化,最后再比较多次运行 K-Means 的结果,选择代价函数最小的结果。
当然这种方法在 K 较小的时候(2--10)还是可行的,但是如果 K 较大,这么做也可能不会有明显地改善。
还有一种初始化的方法是随机选现有样本中 K 个样本作为初始的中心点。
# 5. Choosing the Number of Clusters
没有所谓最好的选择聚类数的方法,通常是需要根据不同的问题,人工进行选择的。选择的时候思考我们运用 K-Means 算法聚类的动机是什么,然后选择能最好服务于该目的标聚类数。
当人们在讨论,选择聚类数目的方法时,有一个可能会谈及的方法叫作“肘部法则”(Elbow method)。这种方法的做法是改变 K 值来运行 K-Means 算法,然后计算 cost function
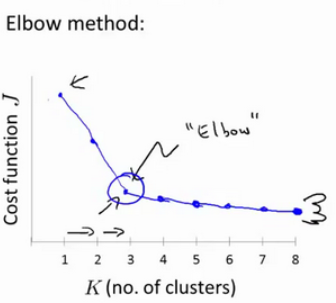
这个曲线的拐角处像一个人的肘部,这就是肘部法则的来源。当然,实际很多情况下是从图像中看不出肘部的,这时候要根据实际业务来选择了。
# 6. K-Means 的 Python 实现
在 scikit-learn 库中,聚类算法都放在 cluster 类库下。聚类算法看似都是想把对象聚成 K 个类,但方法却似百花齐放,代表性的几个类如下:
- KMeans 类:这个类就是本文介绍的 K -means 聚类算法。
- MiniBatchKMeans 类:这是 K-Means 算法的变体,使用 mini-batch 来减少一次聚类所需的计算时间。mini-batch 也是深度学习常使用的方法。
- DBSCAN 类:使用 DBSCAN 聚类算法, DBSCAN 算法的主要思想是将聚类的类视为被低密度区域分隔的高密度区域。
- MeanShift 类:使用 MeanShift 聚类算法,MeanShift 算法的主要方法是以任意点作为质心的起点,根据距离均值将质心不断往高密度的地方移动,也即所谓均值漂移,当不满足漂移条件后说明密度已经达到最高,就可以划分成簇。
- AffinityPropagation 类:使用 Affinity Propagation 聚类算法,简称 AP 算法,聚类过程是一个“不断合并同类项”的过程,用类似于归纳法的思想方法完成聚类这种方法被称为“层次聚类”。
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
# 使用 make_blobs 生成聚类测试数据集
n_samples = 1500
X, y = make_blobs(n_samples=n_samples)
# 进行聚类
y_pred = KMeans(n_clusters=3).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
2
3
4
5
6
7
8
9
10
11
12
13
14
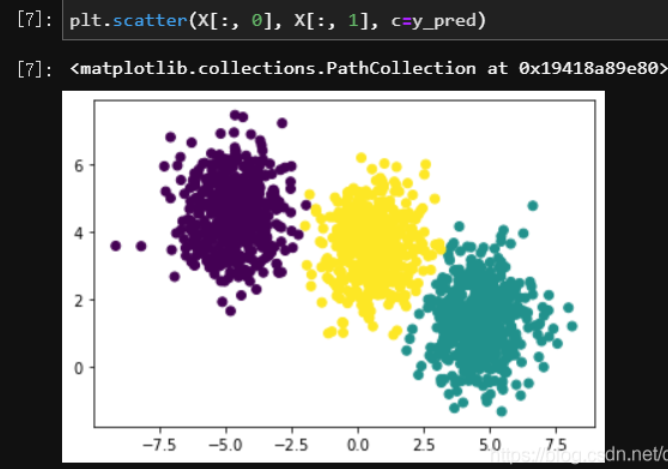
需要特别说明的是,这里的 pred 和分类算法中的 pred 不同,不应该理解成是对类别的预测,而应该作为“聚类后得到的簇的编号”来理解,本段代码中 y_pred 的值其实是每个样本对应的簇的编号,实际值如下:
array([0, 0, 1, ..., 0, 0, 0])
# 7. K-Means 的优缺点
K-Means 算法原理简单,实现容易,能够很快地实现部署;聚类过程中只涉及求均值运算,不需要进行其他太复杂的运算,执行效率较高,而且往往能取得较好的聚类效果。因此遇到聚类问题,不妨首先选择使用 K-Means算法,可能一上来就把问题给解决了,而且原理也容易说清楚。
虽然简单不是缺点,但 K-Means 算法当然还是存在缺点的,最明显的问题就是需要先验地设置“K”,也就是根据外部经验人为地设置聚类的簇的个数。同时,由于需要求均值,这就要求数据集的维度属性类型应该是数值类型。此外,K-Means 算法使用随机选择的方法初始化质心,不同的随机选择可能对最终的聚类结果产生明显影响,增加了不可控因素。最后,“K--means”中的“means”也会带来一些原生的问题,如果数据集中出现一些孤立点,也就是远离其他数据集点的数据点时,会对聚类结果产生非常明显的扰动。