 大规模机器学习
大规模机器学习
如果我们有一个低方差的模型,增加数据集的规模可以帮助你获得更好的结果。我们应该怎样应对一个有 100 万条记录的训练集?以 Linear Regression 为例,如果每一次 gradient descent 都要计算训练集的误差的平方和,即便需要 20 次迭代,这也已经是一个非常大的计算代价了。
# 1. 随机梯度下降法
如果我们一定需要一个大规模的训练集,我们可以尝试使用随机梯度下降法来代替批量梯度下降法。
在随机梯度下降(Stochastic Gradient Descent)中,我们定义 cost function 为单一训练实例的代价:
Stochastic gradient descent
- Randomly shuffle(reorder) training examples.
- Repeat {
for
随机梯度下降算法在每一次计算之后便更新参数
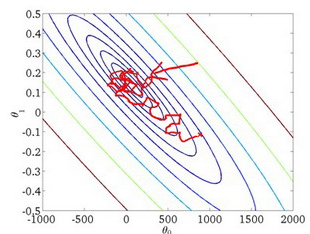
# 2. Mini-batch Gradient Descent
对比一下三种 gradient descent:
- Batch gradient descent: Use all
- Stochastic gradient descent: Use 1 example in each iteration.
- Mini-batch gradient descent: Use
Mini-batch Gradient Descent
Say
Repeat {
for
通常我们会令 b 在 2-100 之间。这样做的好处在于,我们可以用向量化的方式来循环 b 个训练实例,如果我们用的线性代数函数库比较好,能够支持平行处理,那么算法的总体表现将不受影响(与随机梯度下降相同)。
# 3. 随机梯度下降的收敛
现在我们介绍随机梯度下降算法的调试,以及学习率
在批量梯度下降中,我们可以令 cost func
在随机梯度下降中,我们在每一次更新
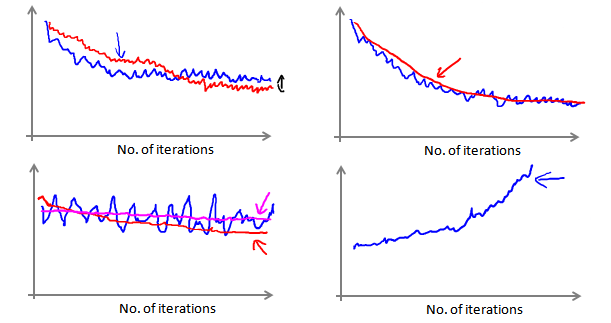
当我们绘制这样的图表时,可能会得到一个颠簸不平但是不会明显减少的函数图像(如上面左下图中蓝线所示)。我们可以增加
我们也可以令 learning rate 随着迭代次数的增加而减小,例如令:
但这样会又引入了两个额外的超参数需要去调:const1 和 const2。
# 4. Online Learning
本节讨论一种新的大规模的机器学习机制,叫做在线学习(Online Learning)机制。
如果你有一个由连续的用户流引发的连续的数据流,进入你的网站,你能做的是使用一个在线学习机制,从数据流中学习用户的偏好,然后使用这些信息来优化一些关于网站的决策。
假定你有一个提供运输服务的公司,用户们来向你询问把包裹从 A 地运到 B 地的服务,同时假定你有一个网站,让用户们可多次登陆,然后他们告诉你,他们想从哪里寄出包裹,以及包裹要寄到哪里去,也就是出发地与目的地,然后你的网站开出运输包裹的的服务价格。比如,我会收取 $50 来运输你的包裹,我会收取 $20 之类的,然后根据你开给用户的这个价格,用户有时会接受这个运输服务,那么这就是个正样本,有时他们会走掉,然后他们拒绝购买你的运输服务,所以,让我们假定我们想要一个学习算法来帮助我们,优化我们想给用户开出的价格。
在线学习算法指的是对数据流而非离线的静态数据集的学习。假使我们正在经营一家物流公司,每当一个用户询问从地点 A 至地点 B 的快递费用时,我们给用户一个报价,该用户可能选择接受(y=1)或不接受(y=0)。现在,我们希望构建一个模型,来预测用户接受报价使用我们的物流服务的可能性。因此“报价”是我们的一个特征,其他特征有距离、起始地点、目标地点以及特定的用户数据。模型的输出是:
在线学习的算法与随机梯度下降算法有些类似,我们对单一的实例进行学习,而非对一个提前定义的训练集进行循环。
对于上面的例子,feature
Online Learning Algorithm
Repeat forever {
Get
一旦对一个数据的学习完成了,我们便可以丢弃该数据,不需要再存储它了。这种方式的好处在于,我们的算法可以很好的适应用户的倾向性,算法可以针对用户的当前行为不断地更新模型以适应该用户。该算法非常适合那些数据集是数据流形式的应用。
在线学习的一个优点就是,如果你有一个变化的用户群,又或者你在尝试预测的事情,在缓慢变化,就像你的用户的品味在缓慢变化,这个在线学习算法可以慢慢地调试你所学习到的假设,将其调节更新到最新的用户行为。
# 5. MapReduce & Data Parallelism
MapReduce 和 Data Parallelism 对于大规模机器学习问题而言是非常重要的概念。我们之前使用 batch gradient descent 算法时需要对整个 training set 进行循环,计算出偏导数和代价再求和,计算代价非常大。
如果我们能够将我们的数据集分配给不多台计算机,让每一台计算机处理数据集的一个子集,然后我们将计所的结果汇总在求和。这样的方法叫做 MapReduce:
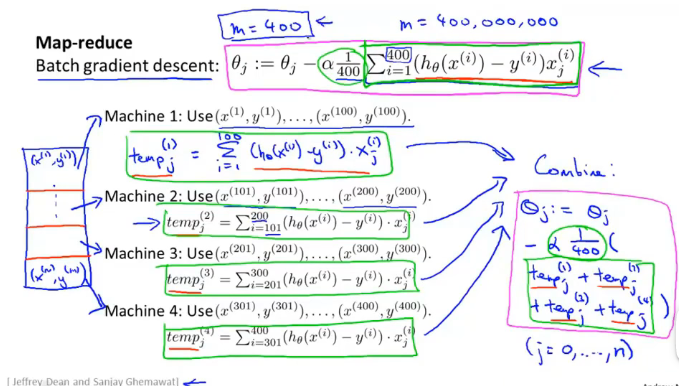
更加形象的图可以画成如下形式:
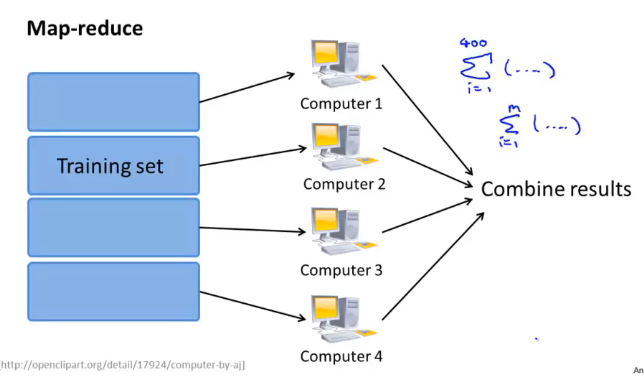
对于具备多核心处理器的计算机来说,也可以将任务分发到多个 Core 上:
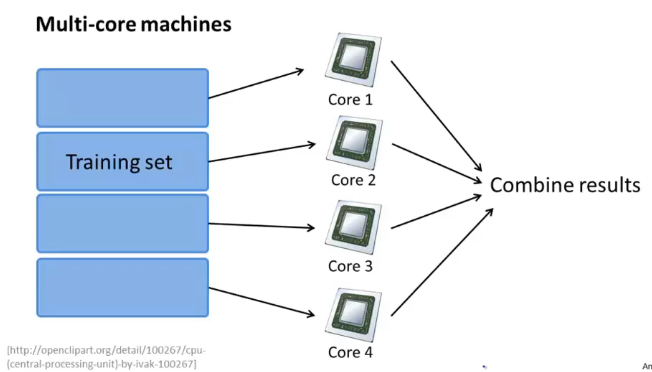
很多高级的线性代数函数库已经能够利用多核 CPU 的多个核心来并行地处理矩阵运算,这也是算法的向量化实现如此重要的缘故。