 Regularization
Regularization
# 1. overfitting 问题
当我们将算法应用到特定的任务时,可能会遇到 overfitting 的问题使得效果变差。这一节将解释什么是 overfitting 问题,并在之后的几节讨论 regularization 的技术来改善或减少 overfitting 问题。
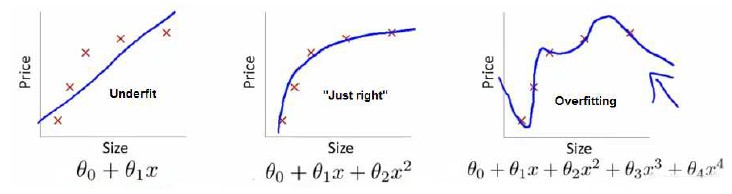
第一张图片是 undefit,具有 “high bias”,第三张图片是 overfitting,具有“high variance”。
Options of addressing overfitting:
- Reduce number of features.
- Manually select which features to keep.
- Model selection algorithm(later in course).
- Regularization
- Keep all the features, but reduce magnitude/values of parameters
- Works well when we have a lot of features, each of which contributes a bit to predicting
- Keep all the features, but reduce magnitude/values of parameters
# 2. cost function
当我们介绍 regularization 是怎么运行时,我们还将写出相应的 cost function。
下图中可以看出,正是高次项导致了 overfitting 的产生,所以有一个想法:如果能让这些高次项的系数接近于 0 的话,我们就能很好地拟合了,所以我们要做的就是在一定程度上去减小这些参数
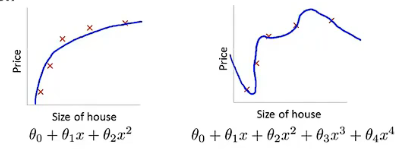
我们既然决定要修改
其中蓝色部分为惩罚项,1000 这个数只是表示很大的一个数。有了这两个惩罚项,训练的结果就会是
但假如我们有非常多的 feature
其中蓝色部分是正则化项(regularization term),
这里 model 一共有 parameters
,按照惯例只对 进行了惩罚,并不对 进行惩罚。但其实也可以对它惩罚,这影响不大,所以往往按照惯例的做法。
但如果
# 3. Regularized Linear Regression
正则化线性回归的代价函数为:
如果我们要使用梯度下降法令这个代价函数最小化,因为我们没有对
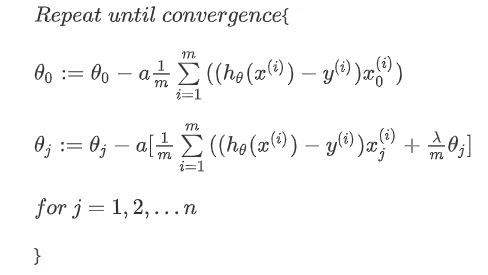
对上面的算法中的
上面式子中的