支持向量机(SVM)
支持向量机(SVM)
# 1. 线性可分定义
在二维中,线性可分表示为:
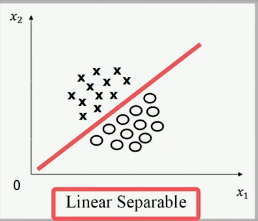
- 存在一条直线将 x 和 ○ 分开
线性不可分则表示为:
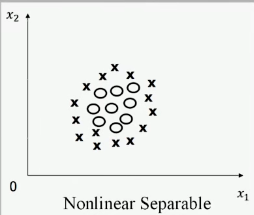
- 此时不存在一条直线将 x 与 ○ 分开
如果扩展到三维,则是用平面来分割:
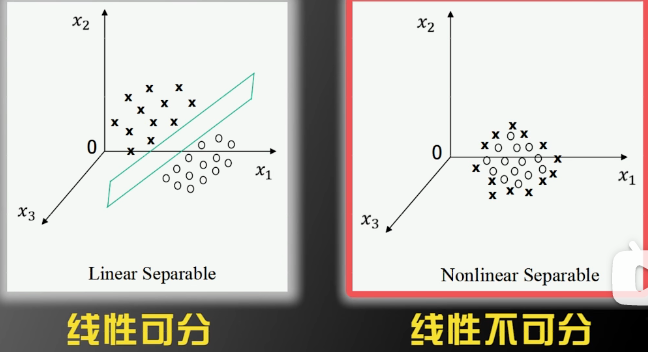
如果维度大于等于四维,那么就是用超平面(Hyperplane)来分割。
我们借助数学对 Linear Separable 和 Nonlinear Separable 进行定义,以二维为例,直线就可以表示为一个方程:
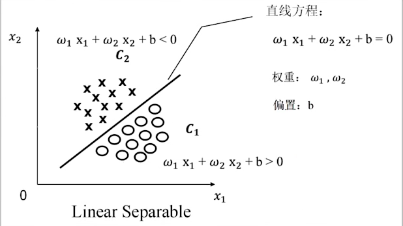
- 在直线的其中一边,
- 可不可以让右边是小于 0 呢?可以呀,只需要假设
接下来我们用数学严格定义训练样本以及他们的标签:假设我们有 N 个训练样本和他们的标签
线性可分的严格定义:一个训练样本及
- 若
- 若
若将
- 若
- 若
# 2. 线性可分时的最优分类 hyperplane
# 2.1 什么是最优分类 hyperplane?
支持向量机算法分成了两个步骤:
- 解决线性可分问题
- 再将线性可分问题中获得的结论推广到线性不可分情况
我们先看一下他是如何解决线性可分问题的。
如果一个数据集是线性可分的,那么就存在无数多个 hyperplane 将各个类别分开。
既然有上面的结论,那哪一个是最好的呢?比如一个二分类的问题:
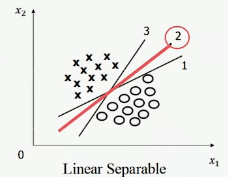
问哪一个最好呢?大多数都是说 2 号线。其实原因在于:2 号线更能低于训练样本位置的误差。那这个 2 号线怎么画出来的呢?Vapnik 给出了基于最优化理论的回答。
将这个直线向左向右移动,直到能碰上一个或几个训练样本为止:
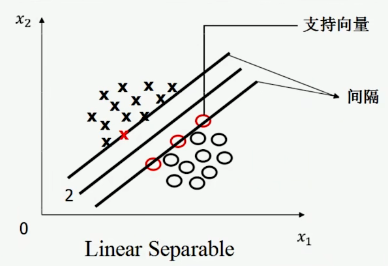
- 我们将移动后的平行线所擦到的训练样本为 support vector。
- 两条平行线之间的距离叫做 margin。
这样我们所要找的线就是使 margin 最大的线,为了是直线唯一,又规定这条线是擦到 support vector 的两个线的正中间的那条线,也就是上图中的 2 号线了。
经过上面讨论,我们知道了 SVM 寻找的最优分类直线应该满足:
- 该直线分开了两个类;
- 该直线最大化 margin;
- 该直线处于间隔的中间,到所有 support vector 的距离相等。
上面的结论是基于二维特征空间的结果,扩展到更高维度后,直线将变成 hyperplane,此时被称为最优分类 hyperplane,但结论不会变。
# 2.2 寻找最优分类 hyperplane
下面我们讲如何用严格的数学来把寻找这个最优分类 hyperplane 的过程写成一个最优化问题。
假定训练样本集是线性可分的,那么 SVM 需要寻找的是最大化 margin 的 hyperplane,这个优化问题可以写成下面的形式:
- minimize:
- 限制条件:
下面讨论为什么会这样?我们先看两个个事实:
事实 1
事实 2
一个点
借助于这两个事实,我们可以用 a 去缩放
为什么可以这样推导呢?根据事实 1 可知,用 a 缩放后的仍是同一个超平面,而根据事实 2,support vector
有上面的式子可以看出来,最大化 support vector 到 hyperplane 的距离等价于最小化
我们再来看限制条件。
support vector 到 hyperplane 的距离是
- 其中
- 右边的 1(标红)可以改成任意的正数,因为修改后计算出来的
总结一下:
总结
线性可分情况下,SVM 寻找最佳 hyperplane 的优化问题可以表示为:
- minimize:
- 限制条件:
其中
可以看到,我们所表述的这个问题是凸优化(Convex Optimization)问题中的二次规划问题。
二次规划的定义
- 目标函数(object function)是二次项
- 限制条件是一次项
而 Convex Optimization 问题中,只有唯一一个全局极值,我们可以利用 gradient descent 方法来求出这个全局极值,从而解决这个 Convex Optimization 问题。
我们这里不详细探讨如何解 Convex Optimization 问题,而是将这个寻找 hyperplane 的问题转换为一个 Convex Optimization,并直接利用解这类问题的工具包来解出这个问题。
# 3. 线性不可分情况
# 3.1 线性模型的局限
在线性不可分的情况下,不存在
放松限制条件的基本思路是,对每个训练样本及标签
可以看到,只要每个 slack var
改造后的 SVM 优化版本:
改造后的 SVM 的优化问题
- minimize:
- 限制条件:
, ,
以前的 objective function 只需要最小化
,而现在加了一个正则化项,这样是想让所有 slack var 的和越小越好,比例因子 C 起到了平衡两项的作用。
这里用于平衡两项的比例因子 C 是人为设定的,因此它是一个 hyper parameter,这个 hyper param 需要去调的。尽管如此,SVM 也是 hyper param 较少的一个算法了,因此不需要花很多时间炼丹。
到了这里,其实上面的解线性不可分的情况有时是不行的,比如下图:
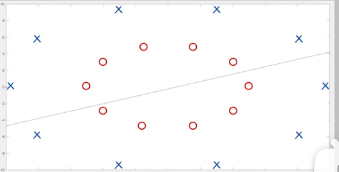
这基本和瞎猜没什么区别,问题就出在:我们假设分开两类的函数是线性的。但线性模型的表现力是不够的,面对上面这个数据集总是无法找到一个直线可以分开两类,因此我们需要扩大可选的函数范围从而应对更加复杂的线性不可分的情况。
# 3.2 从低维到高维的映射
为了达成扩大可选函数范围的目标,像神经网络或决策树等都是直接产生更多可选函数,比如神经网络是通过多层非线性函数的组合,而 SVM 做法的思想是:将特征空间从低维映射到高维,然后用线性 hyperplane 对数据进行分类。
举个例子,考察下面如图的异或问题,这两类样本是在二维空间中是线性不可分的:

而如果构造一个从二维到五维的映射
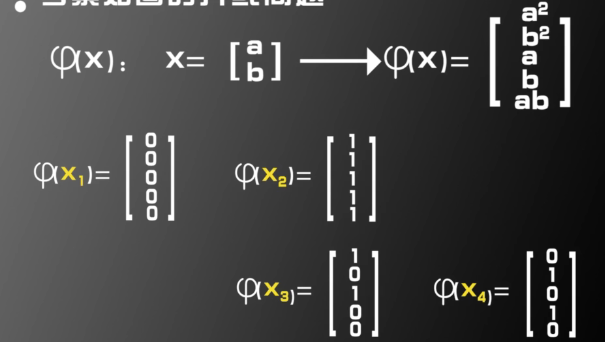
这样映射到五维空间后,
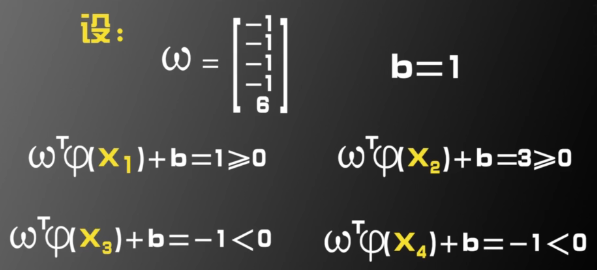
这样就是
可以看到,通过人为指定一个二维到五维的映射
THEOREM
假设在一个 M 维空间上随机取 N 个训练样本,同时随机地对每个训练样本赋予标签 +1 或 -1,同时假设这些训练样本线性可分的概率为 P(M),则有当 M 趋于无穷大时,P(M) = 1。
这个结论我们不再证明了,但可以直观理解一下。当 feature space 的 维度
增加后,待估计参数 的维度也会增加,也就是说整个算法模型的自由度也会增加,当然也就更有可能分开低维时候无法分开的数据集。
这个定理告诉我们,将训练样本从低维映射到高维后,会增大线性可分的概率。我们先放下对
改造后的 SVM 的优化问题
- minimize:
- 限制条件:
, ,
- 主要改变是
- 之前是
可以看到,高维情况下优化问题的解法和低维情况是完全类似的。
现在还剩下一个问题:在 SVM 中,低维到高维的映射
# 3.3 Kernel Function 的定义
本节具体研究
SVM 的创始人 Vapnik 对回答
我们定义
我们举两个例子来说明 Kernel Function 与低维到高维的映射
Example:已知映射求 Kernel Function
🍉 首先举一个已知映射
假设
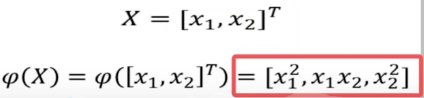
我们看一下与这个
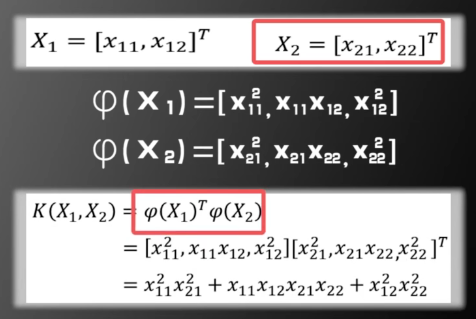
Example:已知 Kernel Function 求映射
🍉 然后举一个已知 Kernel Function 求映射
假设 X 是一个 2 dim vector,
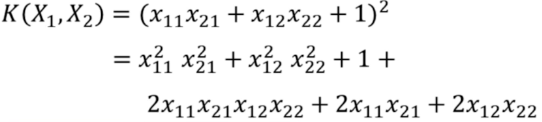
根据定义
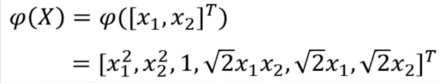
值得一提的是,如果
从上面例子中可以看出,Kernel Function
有大佬提出了如下定理:
Mercer’s Theorem
只要 K 满足交换性和半正定性,那么它就能写成

但在这个例子中却不能显式写出
虽然我们无法知道
本节总结
在这一节中,我们定义了 Kernel Function
下一节我们主要讲如何在已知 K 而不知
# 3.4 原问题和对偶问题
本节从更广泛的角度出发,来解释最优化理论中的原问题和对偶问题的定义,为后续进一步推导 SVM 的对偶问题做准备。
原问题(Prime problem)的定义如下:
Prime problem 的定义

可以看到这个定义很宽泛,自变量
然后我们定义该原问题的对偶问题。首先先定义一个函数

在此基础上,对偶问题(Dual problem)可以定义如下:
Dual problem 的定义
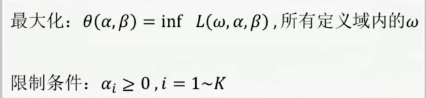
这里面的
综合 prime problem 和 dual problem 的定义可以得到:
定理 一
如果
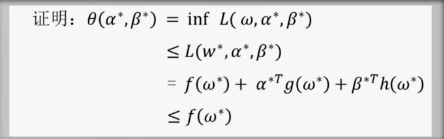
最后一步的推导中
成立是因为:
- 由于
是 prime problem 的解,所以 , - 由于
是 dual problem 的解,所以
定义对偶差距(Duality Gap)为
还有如下的一个强对偶定理:
强对偶定理(Strong Duality Theorem)
如果
简单来说就是,如果 prime problem 的目标函数是凸函数,限制条件是线性函数,那么
定理的证明可参考 《CONVEX OPTIMIZATION》
接下来说,假如强对偶定理成立,也就是有
若
KKT 条件是由 Karush、Kuhn 和 Tucker 先后独立发表出来的。
本节小结
- 定义了 prime problem 和 dual problem
- 强对偶定理
- KKT 条件
接下来,我们将利用这一节的知识,将 SVM 的 prime problem 转化为 dual problem,从而进一步完成 SVM 优化问题的求解。
# 3.5 转化为对偶问题
本节介绍把 SVM 的 prime problem 转化为 dual problem,从而进一步完成 SVM 优化问题的求解。
# 3.5.1 证明:SVM 的 prime problem 满足强对偶定理
回顾一下目前 SVM 的优化问题:
- minimize:
- 限制条件:
, ,
对比 prime problem 的定义,我们对这个版本进行改造,使它的形式成为一个 prime problem。改造的部分就是将原来的
- minimize:
- 限制条件:
, ,
可以看到上面这个版本中,目标函数是凸函数,两个限制条件都是线性的,因此满足强对偶定理。
# 3.5.2 使用对偶理论求解对偶问题
容易混淆的是,在 3.4 节讲的对偶理论的 prime problem 定义中,自变量
按照上一节对偶问题的定义,我们可以将这个 SVM 优化问题的 prime problem 转换成 dual problem,先看转换的结论,写出来的形式如下:
转换后的对偶问题
maximize:
限制条件:
注意的是,由于上一节的
再来看一下是如何转化成这个对偶问题的。
求

然后将获得的三个式子代入到
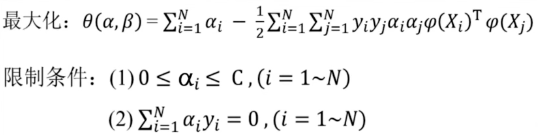
将三个式子代入到 L 从而化简成这样的推导规程可以参考浙大胡浩基老师的现场版教学视频。
在目标函数的式子中,
可以看到这个对偶问题也是一个二次规划问题,可以通过最优化理论的 SMO 算法非常方便地求解出
我们已经将 SVM 问题化成了对偶问题,但我们还没有完全结束。通过转化我们求出了
# 3.5.3 把求
其实这个事情很简单。在令
为什么呢?在 SVM 测试流程中,当来了一个样本 X,我们怎样知道它是属于哪个类呢?我们是:
- 若
- 若
在这里,我们可以不知道
所以可以借助 Kernel Function 直接算出
求 b 需要用到 KKT 条件:
KKT 条件应用到 SVM 中
- 要么
- 要么
怎么求 b 呢?我们首先要取一个
因为此时通过转化为对偶问题,已经可以将
求出来了,所以这里可以取它的一个分量 。当然也可以把所有 的可能取值都取一遍,各算出一个 b,然后计算这些这些 b 的平均值作为最终 的值,这样也许会更准确。
有了上面的推导,我们就可以最终在得到输入样本 X 后,计算
# 4. SVM 的算法总体流程
经过上面的介绍,我们得出了如下的一个结论:
核函数戏法(Kernel Trick)
有了 Kernel Trick 这个结论,我们就可以不需要知道
最终我们可以得到如下的 SVM 判别标准:
SVM 判别标准
- 如果
- 如果
基于对偶问题的求解,我们可以得出支持向量机的训练和测试的流程:
SVM 训练和测试的流程
训练过程:
输入 training data
然后再求 b:
测试过程:
一旦知道了
- 如果
- 如果
在这个过程中,完全没有用到低维到高维的映射
上面讲的是让 SVM 优化问题的目标函数是
# 5. SVM 的使用
使用支持向量机进行分类经过三个步骤:
- 选取一个合适的数学函数作为核函数;
- 核函数完成高维映射并完成计算间隔所需的内积运算,求得间隔;
- 用间隔作为度量分类效果的损失函数,使用 SMO 等算法使得间隔最大,最终找到能够让间隔最大的 hyperplane。
在 scikit-learn 库中,支持向量机算法族都在 sklearn.svm 包中,支持向量机算法总的来说就一种,只是在核函数上有不同的选择,以及用于解决不同的问题,包括分类问题、回归问题和无监督学习问题中的异常点检测。因此需要根据场景选用不同的 SVM 算法类型:
- LinearSVC 类:基于线性核函数的支持向量机分类算法。
- LinearSVR 类:基于线性核函数的支持向量机回归算法。
- SVC 类:可选择多种核函数的支持向量机分类算法,通过“kernel”参数可以传入 “linear” 选择线性函数、传入 “polynomial” 选择多项式函数、传入 “rbf” 选择径向基函数、传人 “sigmoid” 选择 Logistics 函数作为核函数,以及设置 “precomputed” 使用预设核值矩阵。默认以径向基函数作为核函数。
- SVR 类:可选择多种核函数的支持向量机回归算法。
- NuSVC 类:与 SVC 类非常相似,但可通过参数 “nu” 设置支持向量的数量。
- NuSVR 类:与 SVR 类非常相似,但可通过参数 “nu” 设置支持向量的数量。
- OneClassSVM 类:用支持向量机算法解决无监督学习的异常点检测问题。
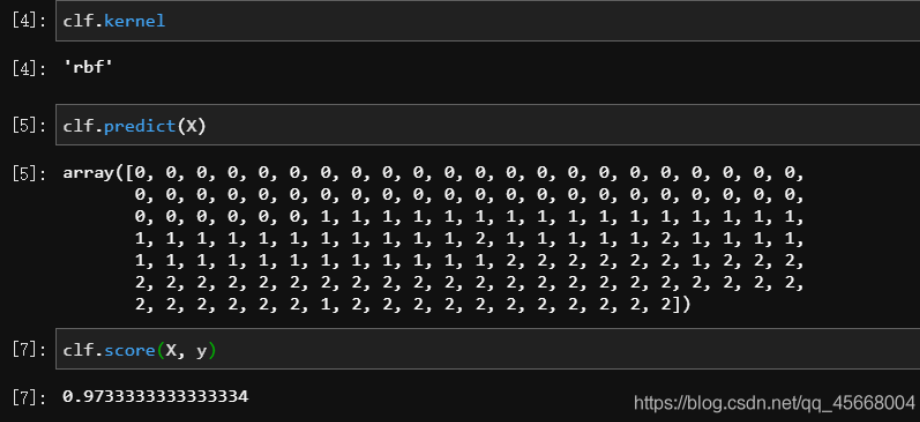
使用 SVC 类调用的例子:
from sklearn.datasets import load_iris
from sklearn.svm import SVC
X, y = load_iris(return_X_y=True)
clf = SVC().fit(X, y)
clf.kernel # 默认为径向量 rbf
clf.predict(X)
clf.score(X, y)
2
3
4
5
6
7
8
9
10
11
运行结果: