 Sequence Labeling
Sequence Labeling
# 1. Sequence Labeling Problem
Sequence Labeling 的 problem 是什么呢?它也是一个 seq2seq 的问题:
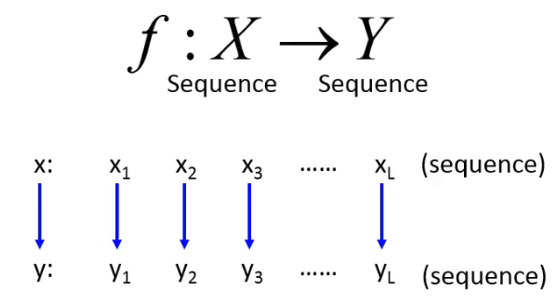
RNN 其实也可以解这个问题,但是还存在其他的基于 structured learning 的方法(two steps, three problems)。
今天用 POS tagging 任务(词性标注任务)来作为例子进行讲解。
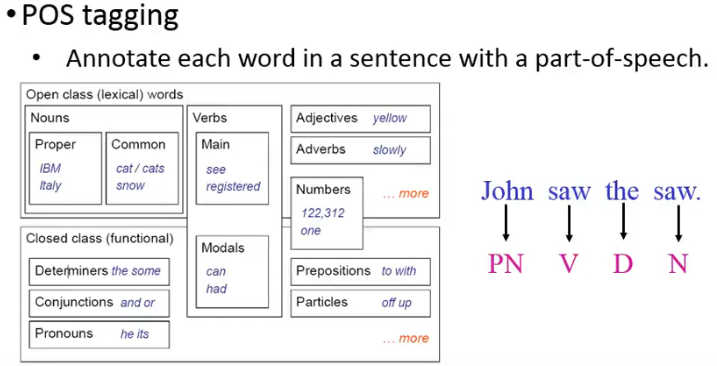
POS tagging 对于接下来的 syntactic parsing、word sense disambiguation 等任务都是很有用的。
Outline:
- Hidden Markov Model(HMM)
- Conditional Random Field(CRF )
- Structured Perceptron/SVM
- Towards Deep Learning
# 2. Hidden Markov Model (HMM)
# 2.1 HMM 的 assumption
How do you generate a sentence? HMM 做了一个 assumption:先产生一个 POS sequence,在由这个 POS seq 去产生一个 sentence:
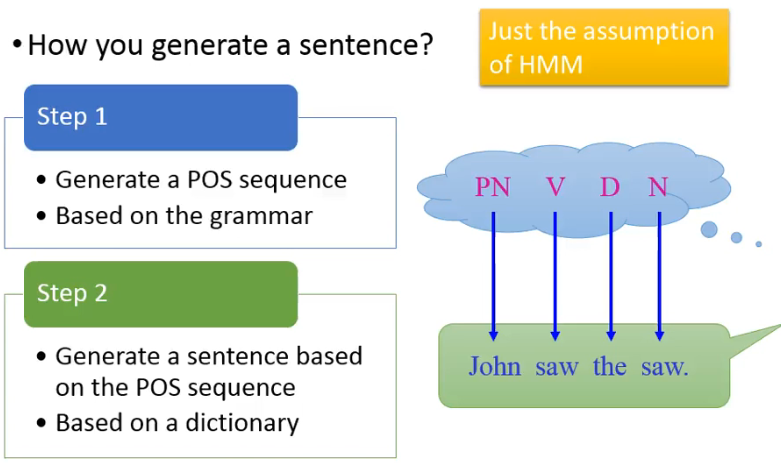
下面看一下这两个步骤:
▶️ Step 1: Generate a POS sequence based on the grammar
HMM 假设这个 grammar 就是 Markov Chain:
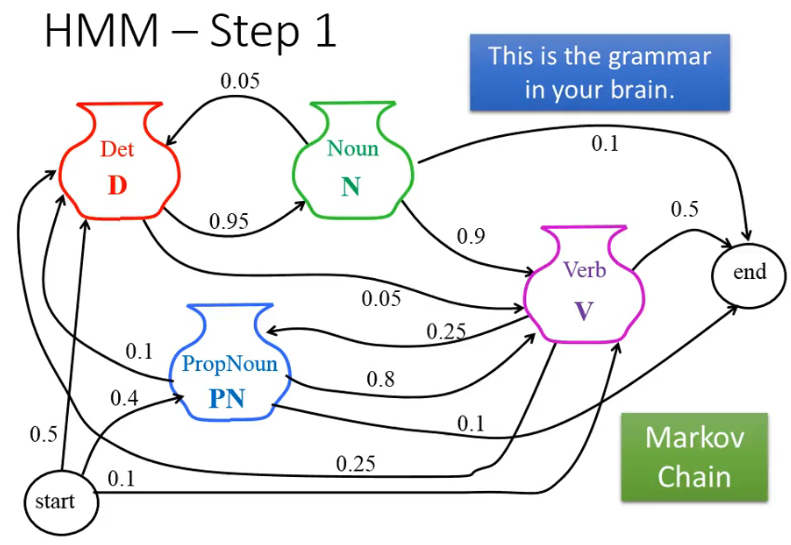
根据这个 Markov Chain,一个 POS sequence 的概率就可以这么算:
▶️ Step 2: Generate a sentence based on the POS sequence
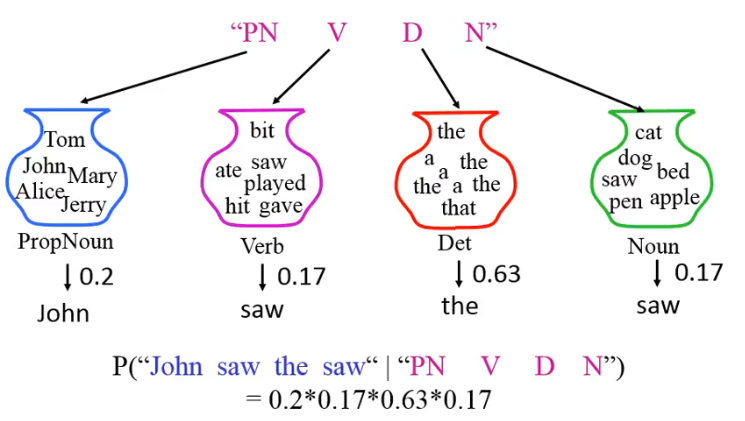
HMM 做的事情就是在帮助我们描述我们是怎样说出一句话的:

这些概率的计算也都是蛮单纯的。我们用更一般化的方式来描述一下这些概率的计算:

# 2.2 如何计算这些概率?
接下来的问题就是,我们要怎么算出这些概率呢?我们首先需要收集一大堆的 training data:

有了这些 training data,这些概率就很好计算了:
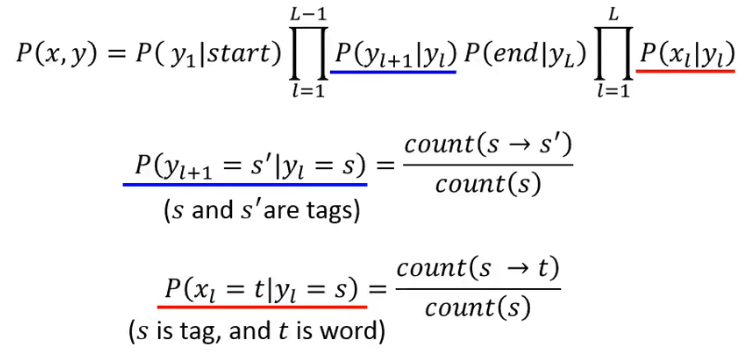
- 所以就是通过 count 来计算 probabilities,So simple!
在语音处理中使用 HMM 时,这里的计算其实要用到 EM 算法来做,但在 POS tagging 中,只需要 count 就好啦,这是没有问题的。
出现这种差别的原因在于,在一般 HMM 模型中,训练样本对应着的是一个可见的观测样本,一个隐状态序列,这个隐马尔可夫链的状态并不能像这个例子一样可以显性的写出来,因此需要 EM 算法来联合确定。
# 2.3 HMM 的 inference
有了上面的概率,那我们该如何做 POS Tagging 呢?别忘了我们可以计算 P(x, y),所以:
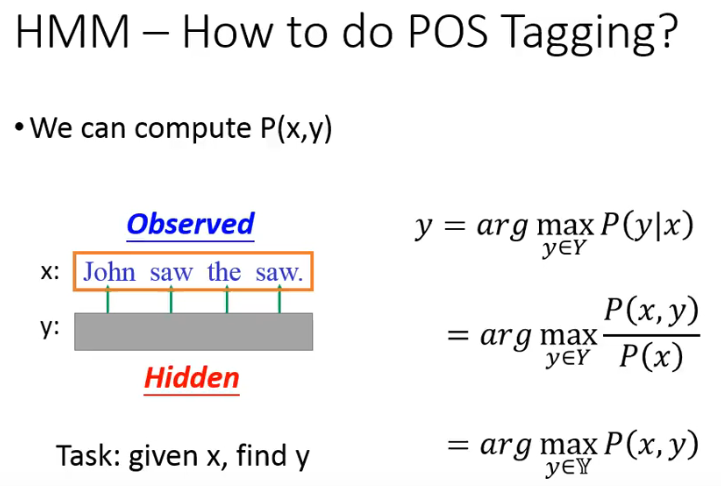
这里的求解
但这样的计算真的需要我们去遍历所有可能的 y 吗?假如我们是通过遍历 y 来做的话:
- 假如有 |S| 个 tags,并且 sequence y 的长度是 L
- 那么就一共有
幸运的是,我们有 Viterbi Algorithm,它可以把上面的问题在复杂度
# 2.4 Summary
HMM 其实也是 structured learning 的一种方法,而我们讲过,structured learning 就是要回答三个 problem,那这个 HMM 是如何回答这三个 problem 的呢?
- Problem 1: Evaluation
- HMM 中的 evaluation function 就是 x 与 y 的 joint probablties:
- HMM 中的 evaluation function 就是 x 与 y 的 joint probablties:
- Problem 2: Inference
- 就是要解
- 就是要解
- Problem 3: Training
# 2.5 Drawbacks
Inference:
为了能够得到正确的结果
原因在于:对于没有出现在 training data 中的 (x, y),HMM 不见得会给它一个低的 probability。也就 HMM 可能产生“脑补”的现象。
但这也不尽然就是它的缺点,因为可能对于现实正确的事情,可能就是没有出现在 training data 中,而 HMM 却能做到给它一个大的 probability。所以你会发现,当 training data 很小的时候,HMM 往往能比其他的 model 表现得更好,但随着 training data 的增多,HMM 就会变得没那么好了。
HMM 表现不好的一个原因是它对于 transition probability 和 emission probability 是分开 model 的,它假设了这两者是 independent 的。
- More complex model can deal with this problem.
- However, CRF can deal with this problem based on the same model.
# 3. Conditional Random Field(CRF)
CRF 一样也要描述
CRF 其实不 care
又由于有
# 3.1 P(x,y) for CRF
可能看上去 CRF 与 HMM 很不一样,其实有人证明了这俩其实是一样的。
我们把 HMM 的 P(x, y) 取一下 log 就可以得到:
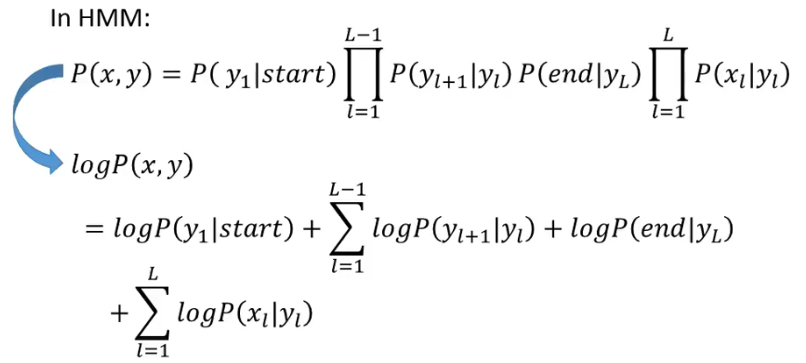
然后我们可以把下面红色方框的这一项变成另外一种形式:

为什么可以这样转换呢?下面举一个例子:

类似地,对其他也可以做几乎一样的转化:

这样写开之后又会怎么样呢?我们已经把每一项都写成了如下的形式,然后转换成两个 vector 的 inner product:
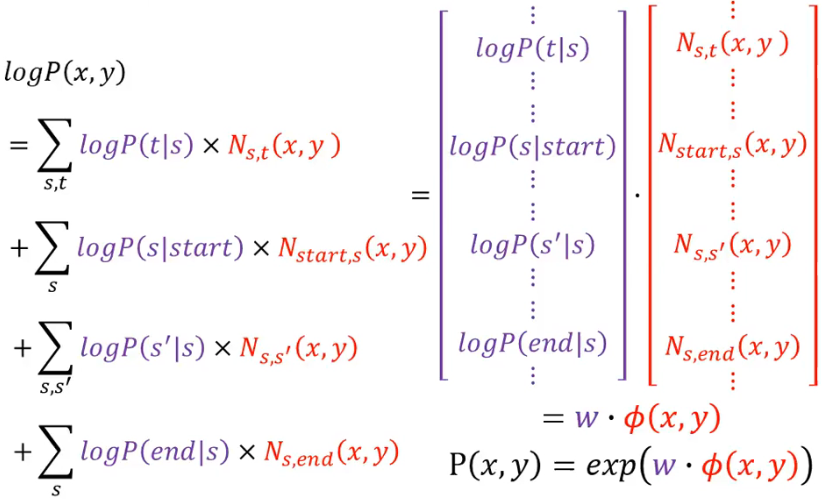
最后可以看到,我们得到了
有一个要注意的是,这里的 weight

而如果想把 weight 转回成概率,只需要它的 e 次方就可以了。
However,we do not give
🌝
如果上面没看懂 …. 就算了。就只需要记得
Feature Vector
▶️ part 1:

- 如果有 |S| 种可能的 tags,有 |L| 种可能的 words,那 part 1 就一共有
▶️ part 2:

- 如果有 |S| 种可能的 tags,那这个 part 就是
很神奇的是,CRF 可以允许 Define any
# 3.2 Training Criterion

怎么来优化呢?因为我们是想 maximize 一个 function,所以可以使用 Gradient Ascent:

O(w) 是我们想要 argmax 的,因此对 O(w) 求导计算,注意其中有的 w 是对应 word 与 tag 的 pair,有的 w 是对应 tag 与 tag 的 pair:
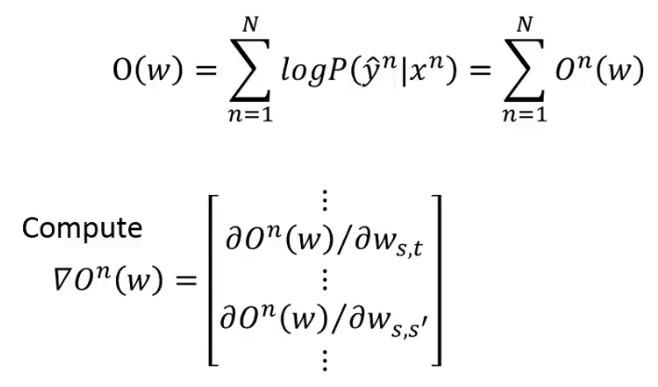
下面我们会看一下

- 这个表达式的物理含义其实还是很清晰的,其物理解释如上图所示。
这里在你训练的时候会存在一个问题,就是怎么累加所有的
所以对 w 求导的结果如下图所示:

# 3.3 Inference
我们知道
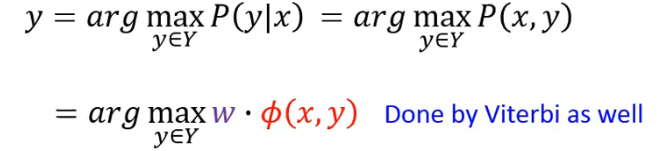
# 3.4 CRF v.s. HMM

有一个 Synthetic Data 的实验比较了 CRF 与 HMM 不一样的地方,这个实验出自于首个提出 CRF 的 paper 当中:

- input x 是 a~z,output y 是 A~E
- 数据产生自 mixed-order HMM,其转移概率和发射概率如上图所示,可以看到,当
- 在这里比较 HMM 与 CRF 时,只使用 1-st order information 的情况,也就是我们看到的最一般的 HMM 与 CRF 的情况。
实验结果如下:
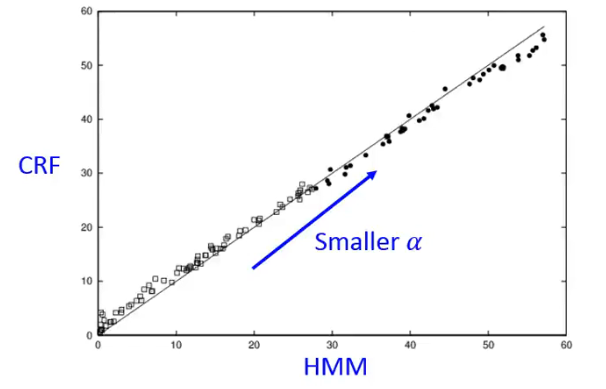
- 每一个圈圈是不同的
- 如果一个点在 45° 角的右侧,代表 CRF 的效果比较好,如果在左侧,代表 HMM 的效果比较好。
从实验结果来看:
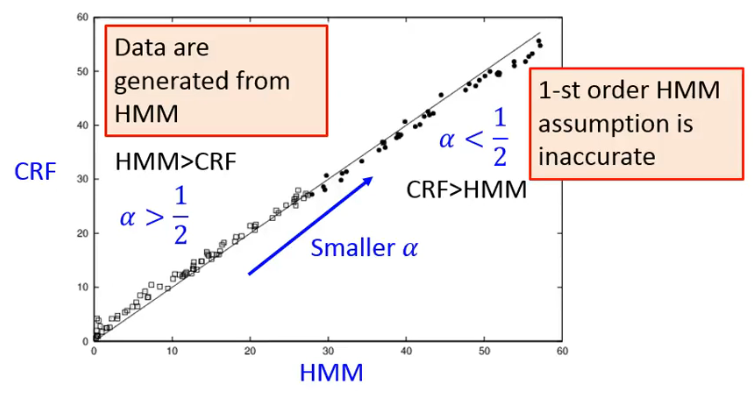
# 3.5 CRF Summary
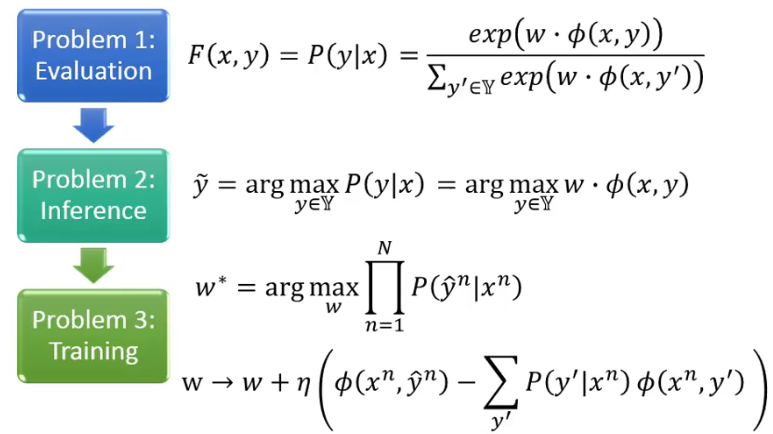
# 4. Structured Perceptron
# 5. Structured SVM
# 6. Towards Deep Learning
# 6.1 为什么不用 RNN?
- RNN, LSTM
- 单方向的 RNN 没有考虑整个 sequence,它只能从前向后
- cost and error not always related
- 但有一个好处:Deep!
- HMM、CRF、Structured Perceptron/SVM
- 使用了 Viterbi 算法,因此考虑了整个 sequence
- 可以显式地考虑 label 之间的 dependency
- cost 是 error 的 upper bound

最终是谁赢了呢?是 RNN 赢了,尽管右边这一步在很多角度上赢了,但 Deep 实在太强了。
# 6.2 Integrated together
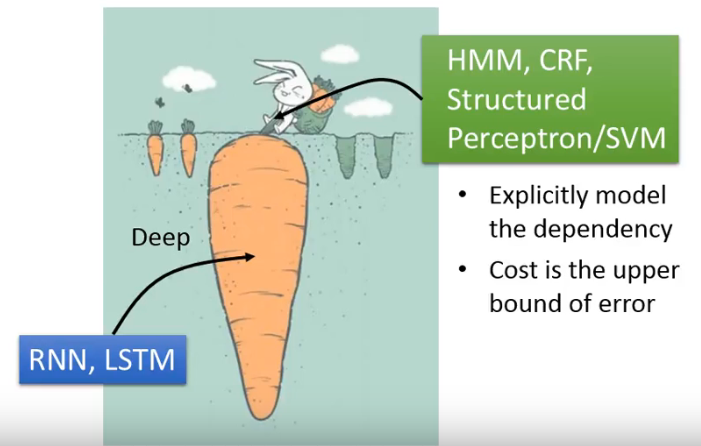
# 6.2.1 Speech Recognition 的情况
以 Speech Recognition 为例:CNN/RNN or LSTM/DNN + HMM
这是怎么做的呢?在 HMM 中,
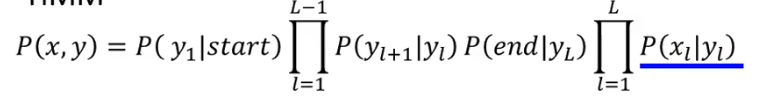
而我们可以把 RNN 的输出视为这样:
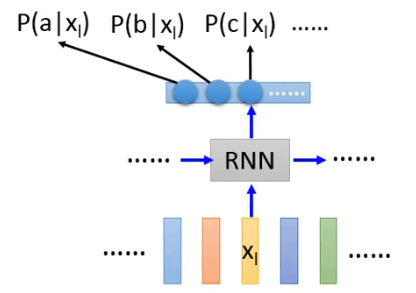
把这个输出替换掉蓝色划线部分是一个思路,但这两个的形式还不合拍,因此需要用如下一个公式在完成转换:
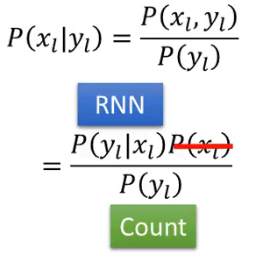
- 为什么可以删掉
# 6.2.2 Semantic Tagging 的情况
Semantic Tagging:Bi-directional RNN/LSTM + CRF/Structured SVM
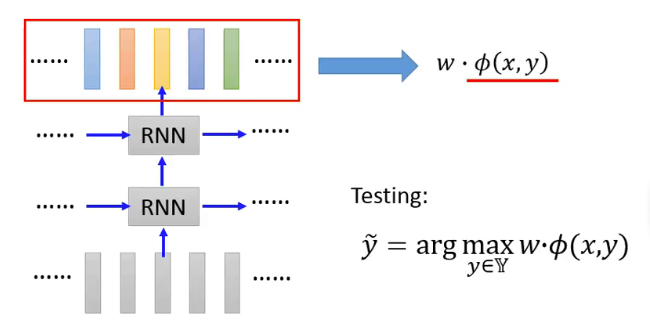
- 原本的 input feature 经过 RNN 后转换成另一个 feature,再把这个经过 RNN 转换得到的 feature 输入给 CRF 模型。因此,CRF 看到的 input feature 其实是 RNN 的 output。
# 7. Concluding Remarks

The above approches can combine with deep learning to have better performance.