 Decision Tree
Decision Tree
# 1. 决策树分类算法介绍
决策树算法其实不是一种机器学习算法,而是一类机器学习算法或者是一种机器学习算法的框架,它们的共同特点是都采用了树形结构,基本原理都是用一长串的 if-else 完成样本分类,区别主要在纯度度量等细节上选择了不同的解决方案。
如何选择判断条件来生成判断分支是决策树算法的核心要点,有人称之为节点划分,也有人称之为节点分裂,指的都是生成 if-else 分支的过程。
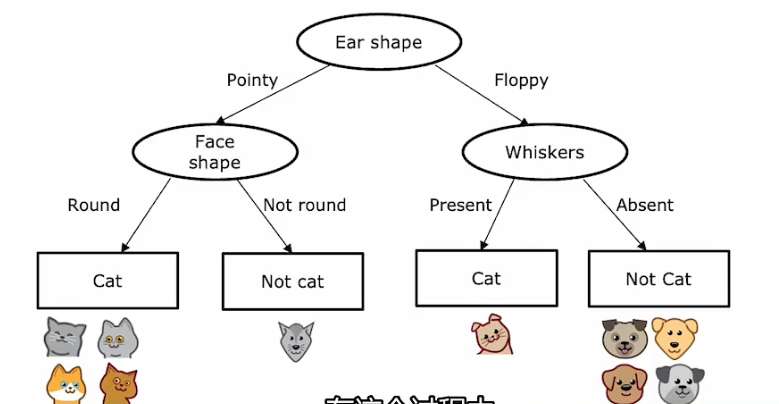
决策树的重点概念:
- 决策树的分类方法
- 分支节点的划分
- 纯度度量
要想成为真正的决策树,就得学会怎样挑选判别条件。这是决策树算法的灵魂。第一个要紧问题就是:判别条件从何而来呢?分类问题的数据集由许多样本构成,而每个样本数据又会有多个特征维度,譬如学生资料数据集的样本就可能包含姓名、年龄、班级、学号等特征维度,它们本身也是一个集合,我们称为特征维度集。数据样本的特征维度都可能与最终的类别存在某种关联关系,决策树的判别条件正是从这个特征维度集里产生的。
# 1.1 决策条件选择的艺术
不过,现实通常没有“一刀切”这么理想,总会有一些不识时务的样本“跑”到不属于自己的类别里,我们退而求其次,希望分类结果中这些不识时务的杂质越少越好,也就是希望分类结果越纯越好。
依照这个目标,决策树引入了“纯度”(purity)的概念,集合中归属同一类别的样本越多,我们就说这个集合的纯度越高。每一次使用 if-else 进行判别,二元分类问题的数据集都会被分成两个子集,那么怎么评价分类的效果呢?可以通过子集的纯度。子集纯度越高,说明杂质越少,分类效果就越好。
其实准确来说,决策树是一类算法,或者说是一套算法框架,并不只是单一一种算法。决策树分类算法都有着十分相近的算法思想,但同样存在着细节上的不同,主要就体现在怎样衡量纯度上。其中最著名的决策树算法一共有三种,分别是 ID3、C4.5 和 CART,这三种决策树算法分别采用了信息增益(information gain)、增益率和基尼指数这三种不同的指标作为决策条件的选择依据。但这些指标都有一个共同的目的:提高分支下的节点纯度。
纯度有三点需要注意:
- 当一个分支下的所有样本都属于同一个类时,纯度达到最高值。
- 当一个分支下样本所属的类别一半是正类一半是负类时(某个类占比50%时),纯度取得最低值。
- 纯度考察的是同一个类的占比,并不在乎该类究竟是正类还是负类,譬如某个分支下无论是正类占70%,还是负类占70%,纯度的度量值都是一样的。
# 1.2 决策树的剪枝
决策树算法兴起以后,剪枝算法也随之发展起来,成为决策树算法的重要组成部分。过拟合是决策树分类算法容易出现的问题,这个问题会影响决策树算法分类的有效性都说细节决定成败,决策树出现过拟合的原因则正好相反—正是因为太抠细节。在决策树中将已生成的树进行简化的过程称为剪枝(pruning)。
现实是可能由于各种原因,如数据集收集片面或随机扰动等,导致数据出现了假性关联,那么这些实际无效的属性维度就会被决策树算法当作有效的分支判断条件。用这种存在假性关联数据集训练得到的决策树模型就会出现过度学习的情况,学到了并不具备普遍意义的分类决策条件,也就是出现过拟合,导致决策树模型的分类有效性降低。
但根据剪枝操作触发时机的不同,基本可以分成两种,一种称为预剪枝,另一种称为后剪枝:
- 预剪枝,即在分支划分前就进行剪枝判断,如果判断结果是需要剪枝,则不进行该分支划分,也就是还没形成分支就进行“剪枝”,用我们更常用的说法即将分支“扼杀在萌芽状态”。
- 后剪枝,则是在分支划分之后,通常是决策树的各个判断分支已经形成后,才开始进行剪枝判断。后剪枝可能更符合我们日常中对“剪枝”一词的理解。
无论预剪枝还是后剪枝,剪枝都分为剪枝判断和剪枝操作两个步骤,只有判断为需 要剪枝的,才会实际进行剪枝操作。看来这个剪枝判断是防止决策树算法过拟合的重点了,会不会很复杂呢?剪枝判断是各款剪枝算法的主要发力点,很难一概而论,但总的来说就是遵从一个原则:如果剪枝后决策树模型的分类在验证集上的有效性能够得到提高,就判定为需要进行枝否则不剪枝。请注意这里剪枝所使用的数据集不再是训练模型所使用的训练集,而是选择使用验证集来进行相关判断。
# 2. 决策树分类的算法原理
# 2.1 决策树分类算法的基本思路
# 1)第一个问题:判别条件从何而来?
- 来源 --> feature set
- 选择 --> 基于 purity
在最开始的时候,决策树选取了一个 feature 作为判别条件,在数据结构中通常称之为“root node”,root node 通过 if-else 形成最初的分支,决策树就算“发芽”了。如果这时分类没有完成,刚刚形成的分支还需要继续形成分支,这就是决策树的第一个关键机制:节点分裂。在数据结构中,分支节点通常称为叶子节点,如果叶子节点再分裂形成节点,就称为子树。有人也把这个过程称为递归生成子树。每一次分裂都相当于一次对分类结果的“提纯”,不断重复这个过程,最终就达到分类目标了。
# 2)第二个问题:停止分裂问题
决策树能够通过节点分裂不断地对分类结果进行提纯,但“不断”总也是有“断”的时候,就如虽然 if-else 能无限嵌套 if-else,但真正写出来的 if-else 总是相当有限的。那么,决策树该在什么时候停止节点分裂呢?停止条件有以下三种:
- 到达终点:虽然我们在讨论节点分裂,但须记住节点分裂是手段而不是目的,目的是完成分类。当数据集已经完成了分类,也就是当前集合的样本都属于同一类时,节点分裂就停止了。
- 自然停止:决策树依赖特征维度作为判别条件,如果特征维度已经全部用上了,自然也就无法继续进行节点分裂。可是如果分类还没有完成则怎么办呢?决策树的处理方法很简单,就以占比最大的类别作为当前节点的归属类别。
- 选不出来:除了上述两种不难想到的停止条件,还有一种意料之外情理之中的停止条件,就是选不出来。决策树通过比较不同特征维度的提纯效果来进行判别条件的选择,但是同样可能发生的极端情况是,大家的提纯效果完全一样,这时就无法选择了,分裂也就到此为止。这时同样以占比最大的类别作为当前节点的归属类别。
以上三种是算法自身带有的停止条件,在实际使用中也可以通过外部设置一些 threshold,如决策树的深度、叶子节点的个数等来作为停止条件。
# 2.2 ID3 算法
这里用到了信息论中信息熵的概念。
熵(entropy)是表示随机变量不确定性的度量,当随机变量 X 只可能取 0、1 两个值时,此时设
此时,entropy
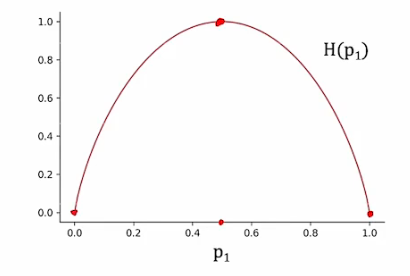
- 当 p=0 或 p=1 时,entropy
信息熵的概念其实与决策树对纯度的要求不谋而合。在分类的场景中,各种事情发生的概率可以替换成各种类别的占比。占比不相上下的时候,信息熵就比较大,当一个类别能够一家独大,信息熵就比较小。但信息熵是以整个集合作为计算对象,那么怎样利用信息熵从特征维度集中选择决策条件呢?ID3 算法使用了信息增益 G。
ID3 中选择用信息熵来衡量样本集合的纯度,那么“提纯”效果的好坏就可以通过比较划分前后集合的信息熵来判断,也就是做一个减法,具体来说是用划分前集合的信息熵减去按 feature
- 被减数
- V 是按照 feature
- |D| 是集合的元素个数,比如划分前有 10 个元素,则
用一个判别是不是“cat”的 Decision Tree 作为例子来展示 information gain:

简单地说,用原集合的 entropy,减去划分后产生的所有子集的信息熵的加权和,就得到按 feature

比较不同 feature 的 information gain,增益越大,说明提纯效果越好,提纯效果最好的那个特征属性就当选为当前 if-else 的判别条件。
ID3 算法是一个相当不错的决策树算法,能够有效解决分类问题,而且原理清晰、 实践简单。但大家很快又发现,这套算法有一个突出爱好,就是喜欢选择值比较多的特征维度作为判别条件。
# 2.3 C4.5 算法
ID3 为什么会有上述的缺点呢?决策树是以“提纯”来作为特征维度的选择标准,而特征维度的值越多,子集被切分得越细,纯度相对也是会提升的,但这种情况下的纯度提升与决策树的设计初衷不符。因此改进版的 ID3 算法,也就是 C4.5 算法应运而生。
C4.5算法可以认为是ID3算法的“plus”版本,唯一的区别就在于用信息增益比来替代信息增益。信息增益与谁比较呢?与特征维度的固有值(Intrinsic Value)比,具体数学表达式如下:
特征维度的固有值是针对 ID3 对多值特征的偏好所设计的,具体作用就是特征维度的值越多,Intrinsic Value 越大。信息增益比以固有值作为除数,就可以消除多值在选择特征维度时所产生的影响。固有值的数学表达式具体如下:
# 2.4 CART 算法
CART 算法是当前最为常用的决策树算法之一。占比各半也是最不确定的情况,所以基尼指数取得最大值 0.5。基尼指数取得最大值和最小值的情况与信息熵是非常相似的,最明显的区别在于基尼指数的最大值是 0.5 而不是 1。
使用基尼指数选择 feature 的过程与前面基本一致,首先还是计算选择某个 feature 作为判别条件的基尼指数,计算方法和计算信息增益非常类似,也是首先求得各个子集的元素占比,然后乘以该子集的基尼指数,最后全部加起来求和,公式如下:
# 2.5 决策树分类算法的具体步骤
- 选定纯度度量指标。
- 利用纯度度量指标,依次计算依据数据集中现有的各个特征得到的纯度,选取纯度能达到最大的那个特征作为该次的“条件判断”。
- 利用该特征作为“条件判断”切分数据集,同时将该特征从切分后的子集中剔除 (也即不能再用该特征切分子集了)。
- 重复第二、第三步,直到再没有特征,或切分后的数据集均为同一类。
# 3. 决策树分类算法的 Python 实现
在 Scikit-Learn 库中,基于决策树这一大类的算法模型的相关类库都在 sklearn.tree 包中。tree包中提供了 7 个类,但有 3 个类是用于导出和绘制决策树,实际的策树算法只有 4 种,这 4 种又分为两类,分别用于解决分类问题和回归问题。
- DecisionTreeClassifier 类:经典的决策树分类算法,其中有一个名为
criterion的参数,给这个参数传入字符串"gini",将使用基尼指数;传入字符串"entropy", 则使用信息增益。默认使用的是基尼指数。余下 3 个决策树算法都有这个参数。 - DecisionTreeRegressor 类:用决策树算法解决反回归问题。
- ExtraTreeClassifier 类:这也是一款决策树分类算法,但与前面经典的决策树分类算法不同,该算法在决策条件选择环节加入了随机性,不是从全部的特征维度 集中选取,而是首先随机抽取 n 个特征维度来构成新的集合,然后再在新集合中选取决策条件。n 的值通过参数
maxfeatures设置,当maxfeatures设置为 1 时,相当于决策条件完全通过随机抽取得到。 - ExtraTreeRegressor 类与 ExtraTreeClassifier类似,同样在决策条件选择环境加入随机性,用于解决回归问题。
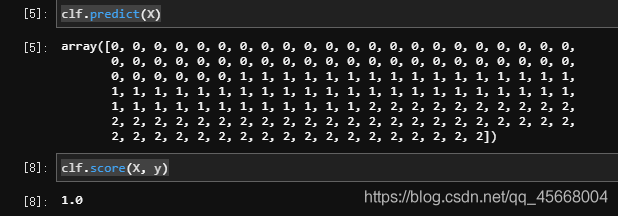
我们使用 DecisionTreeClassifier 类来编写本次代码:
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
X, y = load_iris(return_X_y=True)
clf = DecisionTreeClassifier().fit(X, y)
print(clf.predict(X))
print(clf.score(X, y))
2
3
4
5
6
7
结果如下:
# 4. 决策分类算法的优缺点
优点:分类逻辑清晰,易于理解;采用树形结构进行分类,适合可视化
缺点:
- 最大的问题是容易过拟合
- 许多经典的决策树分类算法(如本文提到的三个算法)在特征维度选择上都使用了统计学指标,这些指标有一个默认的假设,人为特征维度之间是彼此独立的。但如果特征维度实际存在关联性,则可能对预测结果产生影响