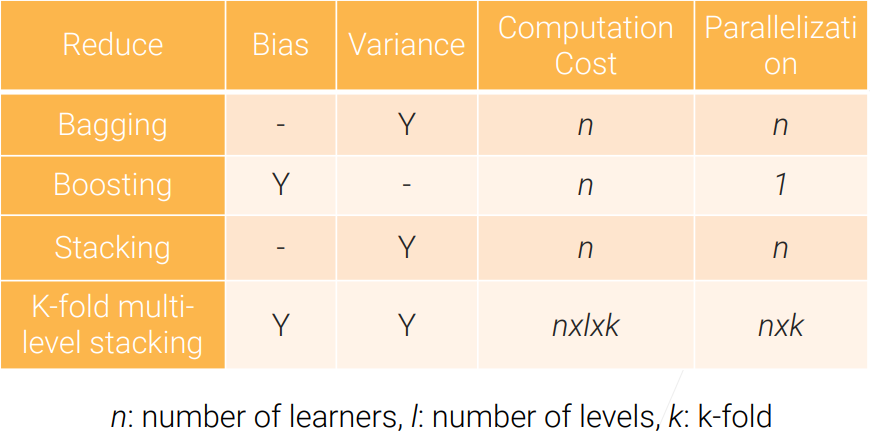
Model Combination(Bagging & Boosting, etc)
Model Combination(Bagging & Boosting, etc)
# 1. Bias & Variance
# 1.1 What is Bias & Variance?
In statistical learning, we measure a model in terms for bias and variance:
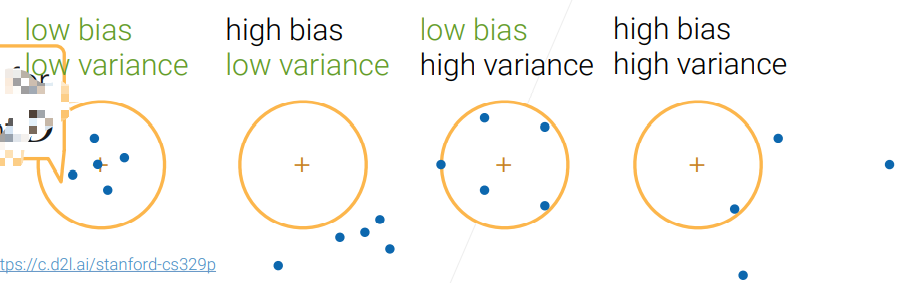
- 圆圈代表一个可容忍的区域,蓝色的圆点指的是训练的模型得出的结果,蓝色的点的个数代表了所训练模型的个数
# 1.2 Bias-Variance Decomposition
当你的 model 出现了除了 low bias and low variance 以外的其余三种情况时,应当想办法通过别的方法来使得 bias 或者 variance 降低。
假设我们从
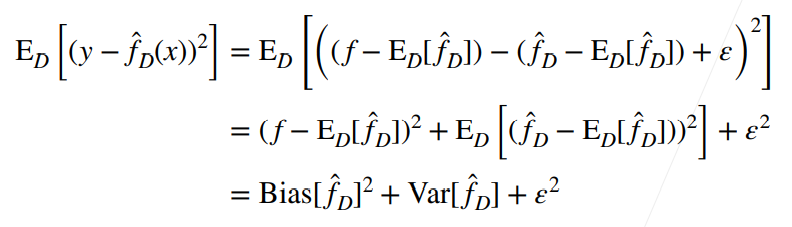
- 由于
所以可以说,在这个简单的假设之下,假设模型采用与它,那么我们的模型的泛化误差就可以写成这样:
这是统计学习里面非常重要而且非常深刻的一个公式。
# 1.3 Bias-Variance Tradeoff
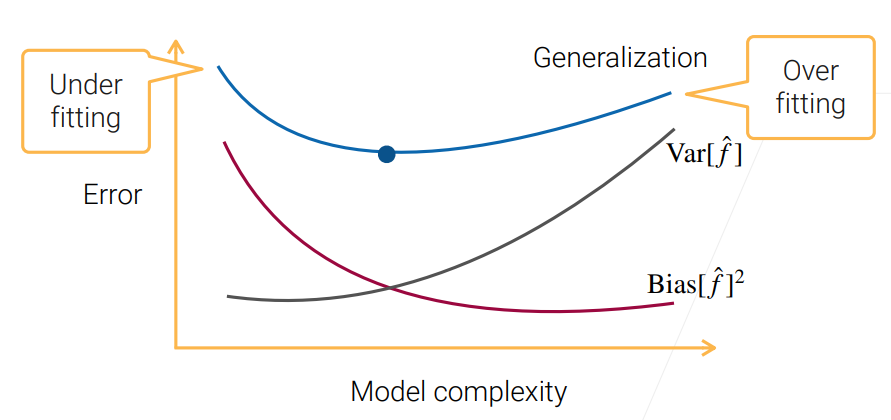
- 当 model complexity 过小时,model 过于简单导致学不到真实数据所要表达的东西,这时 bias 自然很高了;
- 当 model complexity 过大时,模型比数据还要复杂,导致出现了学习结果的多样性,导致了 variance 的变高。
# 1.4 Reduce Bias & Variance
# 1.4.1 Reduce bias
- A more complex model
- e.g. increase #layers, #hidden units of MLP
- Boosting
- Stacking
# 1.4.2 Reduce variance
- A simpler model
- e.g. regularization
- Bagging
- Stacking
# 1.4.3 Reduce
在机器学习中,
- improve data
Ensemble learning
Ensemble learning(集成学习): train and combine multiple models to improve predictive performance.
上面提到的 Bagging、Boosting 和 Stacking 都是 Ensemble Learning 的方法。
# 2. Bagging
# 2.1 What is Bagging?
Bagging - Bootstrap AGGregatING。
Bagging
Bagging trains
- 在 regression 问题中,每一个学习的 model 得出一个分数,然后计算平均作为最终结果;
- 在 classification 问题中,通过 majority voting 的方式来选出最终的结果,即多数表决原则。
Each learner is trained on data by bootstrap sampling:
- Assume
- Around
# 2.2 Bagging Code
代码是按照 scikit-learn 的风格来的:
class Bagging:
def __init__(self, base_learner, n_learners):
self.learners = [clone(base_learner) for _ in range(n_learners)]
def fit(self, X, y):
for learner in self.learners:
examples = np.random.choice(
np.arange(len(X)), int(len(X)), replace=True)
learner.fit(X.iloc[examples, :], y.iloc[examples])
def predict(self, X):
preds = [learner.predict(X) for learner in self.learners]
return np.array(preds).mean(axis=0)
2
3
4
5
6
7
8
9
10
11
12
13
- base learner 是所要训练的多个 model 的每一个是什么类型的。
- line 3 的
clone()是因为不能让每个小模型共享权重,所以需要 clone 一下。这个函数在 scikit-learn 中有。 - line 8 的
replace=True表示这是有放回抽样出 - scikit-learn 中学习的函数基本都是
fit(),而预测是predict()
# 2.3 Random Forest
Random Forest 是 Bagging 最重要的一个应用:
- Use decision tree as the base learner.
- Often randomly select a subset of features for each learner.
- Results on house sale data:
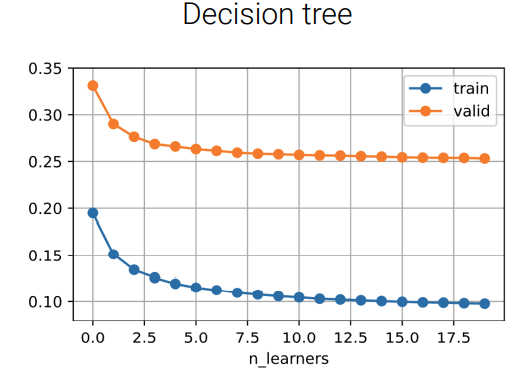
观察上图,在一开始只有一颗 decision tree 时有一点过拟合,随着 tree 的数量的增加,training error 和 valid error 都在下降,但有趣的是,即便把数量加到上千个,也不会看到有什么下降了,这是因为增加 tree 的数量只是降低了 variance,但并没有改善 bias 等。
增加模型的个数来做 Bagging 通常不会让你变差,但有可能也不会变好。那什么时候会变好,什么时候不会变得更好呢?
# 2.4 Apply bagging with unstable Learners
Bagging 对降低 variance 有效,那该技术自然对 variance 较大的 model 有效,variance 较大的 model 叫做 Unstable Learner。
Bagging reduces model variance, especially for unstable learners.
Given ground truth
Given
- 最左边的这个
所以 Bagging reduces more variance when base learners are unstable.
Decision tree is unstable, linear regression is stable:
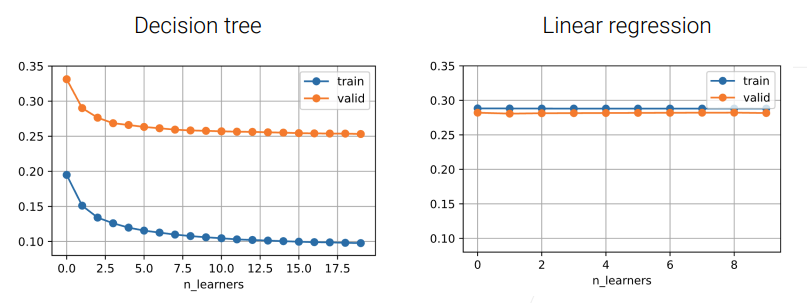
Summary
- Bagging train multiple learner on data by bootstrap sampling.
- Bagging reduce variance, especially for unstable learners.
# 3. Boosting
# 3.1 What is Boosting?
Boosting: Learn
At step
- Evaluate the existing learners’ error
- Train a weak leaner
- AdaBoost: Re-sample data according to
- Gradient boosting: Train learner to predict
- AdaBoost: Re-sample data according to
- Additively combining existing weak learners with
这里主要讲述 Gradient boosting,AdaBoost 可以参考李航老师的统计学习方法。
# 3.2 Gradient Boosting
Gradient Boosting:
- Denote by
- At step
- Train a new model
- Combine:
- The learning rate
- The learning rate
- Train a new model
- The residuals
- 残差(residuals)的意思是,有一个函数
,我们想求其中 x 的值,现在有一个 x 的近似值 ,那么 , 残 差 。 误 差 表示一个有 m 个元素的集合,表达式中用 i 作为下标写出了每个元素的通式。 - learning rate
的存在是为了防止过拟合,如果 的话,每次用残差来训练,这样最终会把训练数据完全拟合进去了,而这个 learning rate 的存在就是说,我们就算能完全拟合,我们也不要全信它。这个技术也叫做 shrinking。
我们之所以讲 Gradient Boosting,是因为你可以认为别的一些 Boosting 函数很多时候都可以换到这个 Gradient Boosting 的框架里面,这取决于 loss function
# 3.3 Gradient Boosting Code
scikit-learn 风格的代码:
class GradientBoosting:
def __init__(self, base_learner, n_learners, learning_rate):
self.learners = [clone(base_learner) for _ in range(n_learners)]
self.lr = learning_rate
def fit(self, X, y):
residual = y.copy()
for learner in self.learners:
learner.fit(X, residual)
residual -= self.lr * learner.predict(X)
def predict(self,X):
preds = [learner.predict(X) for learner in self.learners]
return np.array(preds).sum(axis=0) * self.lr
2
3
4
5
6
7
8
9
10
11
12
13
14
# 3.4 Gradient Boosting Decision Trees(GBDT)
Use decision tree as a learner. 因为我们需要用 weak learner,但 decision tree 并不 weak,因为它很容易 overfitting,所以我们对它限制一下:设置一个小的 max_depth;randomly sampling features,也就是只用到部分 feature 来做 decision tree。
这里设置 max_depth = 3,对 decision tree 应用 Gradient Boosting 后往往称之为 Gradient Boosting Decision Trees(GBDT),对比一下 GBDT 和 Random Forest:
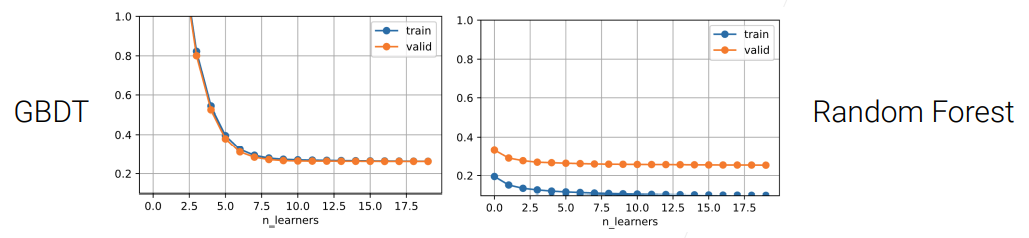
- 由于我们限制了 max-depth,所以我们的每一个 decision tree 都比较 weak,而且将 learning rate 设为 0.1,所以在图中可以看到随着 n_learners 的增加,整个 model 并没有出现过拟合的现象。
Gradient Boosting 一个有趣的地方是,当 weak learner 和 learning rate 控制得比较好的时候,它的 overfitting 现象不那么严重。
与 random forest 一个明显不同的地方是,在 random forest 里面可以每个 tree 都并行训练,但在 Gradient Boosting 中每棵树要顺序地训练,这导致在比较大的数据集上运行很慢,即 Sequentially constructing trees run slow。所以在实际用的时候,往往会使用一些 accelerated algorithms,比如 XGBoost、lightGBM,它们都是对 Gradient Boosting 加入了一些加速的算法。
Summary
- Boosting combines weak learners into a strong one to reduce bias.
- Gradient boosting learns weak learners by fitting the residuals.
# 4. Stacking
# 4.1 What is Stacking?
Stacking
- Combine multiple base learners to reduce variance.
- Base learners can be different model types.
- Linearly combine base learners outputs by learned parameters.
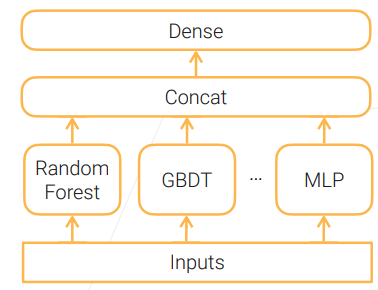
Stacking 技术广泛应用在竞赛中,是一个刷榜利器。
bagging VS stacking:
- Bagging: use same type models, bootstrap samples to get diversity.
- Stacking: different types of models extract different features.
# 4.2 Stacking Results
Evaluate on house sales data, compare to bagging and GBDT we implemented before:
| Test Error | |
|---|---|
| GBDT | 0.259 |
| Random Forest | 0.243 |
| Stacking | 0.229 |
看一下不同模型的表现:
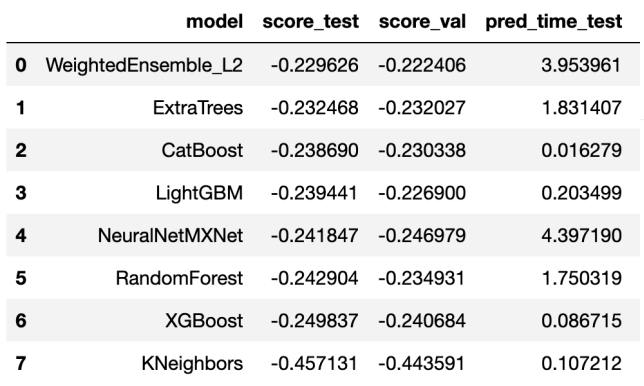
- 第一行的就是 Ensemble 之后的,可以看到它的效果是最好的
- 后面的 NeuralNetMXnet 在做 pred 时花费时间比较多,这种昂贵的模型可以不用集成进来;
- 可以看到 KNeighbors 的效果也不太好,这也可以不把它集成进来。
所以在做 stacking 的时候,你无法保证每一个 model 的效果都很好,如果一个 model 加进来之后不能提升精度或者集成进来会让整个变得特别贵的话,就可以考虑不把它们集成进来了。
# 4.3 Multi-layer Stacking
之前讲的方法主要是降低 variance,其实还有一个办法来降低 bias,这种方法就是 Multi-layer Stacking:
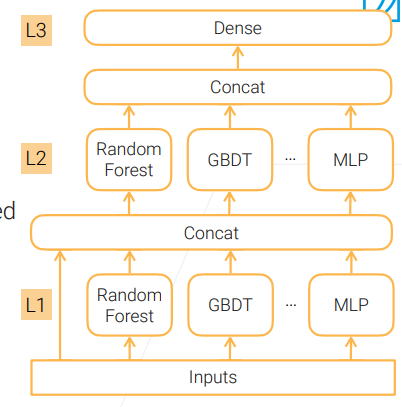
Stacking base learners in multiple levels to reduce bias.
- Can use a different set of base learners at each level.
Upper levels (e.g. L2) are trained on the outputs of the level below (e.g. L1)
- ✨ Concatenating original inputs helps. 这样也许可以把之前那份数据中没有学习到东西重新学习出来。
同一份数据同时进入 layer 1 和 layer 2 进行学习的时候非常容易 overfitting,所以我们需要采取一些手段来避免 overfitting。
Train leaners from different levels on different data to alleviate overfitting.
- Split training data into A and B, train L1 learners on A, predict on B to generate training data for L2 learners.
但按上面这种思路,每一层只用了一半的数据训练,相对来说是比较亏的,所以这里经常使用的一种方法叫做 Repeated k-fold bagging:
- 一个 training set 分成 k 份,每次在 k-1 份上训练,在剩余的一个上做验证,这样可以训练 k 个模型。假设第 i 个模型在第 i 份数据上做了验证,我们把第 i 个模型在第 i 份数据做验证时的 output 留下来,这样 k 个模型有 k 个预测的 output 被留下来了,最后把这些预测并起来会得到一个跟原始数据样本数一样多的数据集,而且这里面的预测数据都是没有再参与到当前模型训练的一个东西。把这个新拼成的数据集输入到下一层再做训练。
其实即使做了上面的 k-fold 交叉验证,也还是会有一定的 overfitting,这时你还有一个更加昂贵但效果挺不错的方法来进一步降低 overfitting 现象:
- 对每一层模型,把上面的步骤重复 n 次,比如 n=3 时就是做 3 次 k-fold 交叉验证,这样就可以得到 n 个新的数据集,也就是每一个样本有了 n 个预测值,这时再对这 n 个预测值做一次平均,进一步降低了 variance,然后再输入到下一层里面。
# 4.4 Multi-layer Stacking Results
Use 1 additional staked level, with 5-fold repeated bagging:
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(label=label).fit(
train, num_stack_levels=1, num_bag_folds=5)
2
3
4
- label 就是房价预测数据集的 label
num_stack_levels相当于 MLP 中多加了一个 hidden layer,这里就是多了一层 Stacking。num_bag_folds表示使用 5 折交叉验证,这里没有使用做那个重复 n 次。
这样做了之后:
- Error:0.229 –> 0.227
- Training time:39 sec –> 207 sec (5x)
看一下 model 的效果:
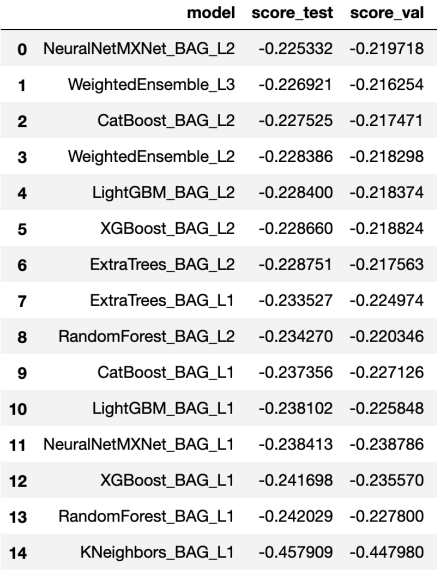
- model 名称最后的那个 L 几代表它是第几层。
- 可以看到,除了 NeuralNetMXnet_BAG_L2 这个特例之外,越高层的效果越好,当然这个特例花费的时间也多。
Summary
- Stacking combine multiple learners to reduce variance.
- Stacking learners in multiple levels to reduce bias.
- Repeated k-fold bagging: fully utilize data and alleviate overfitting.
总的来说,Stacking 技术还是很强大的,在竞赛中能够有效提升精度,但它训练成本也很高。
# 5. Model Combination Summary
The goal is to reduce bias and variance.